SPSS非线性回归案例

SPSS—非线性回归(模型表达式)案例解析
由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二!非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型
非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型
还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?
答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:
第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”
1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型
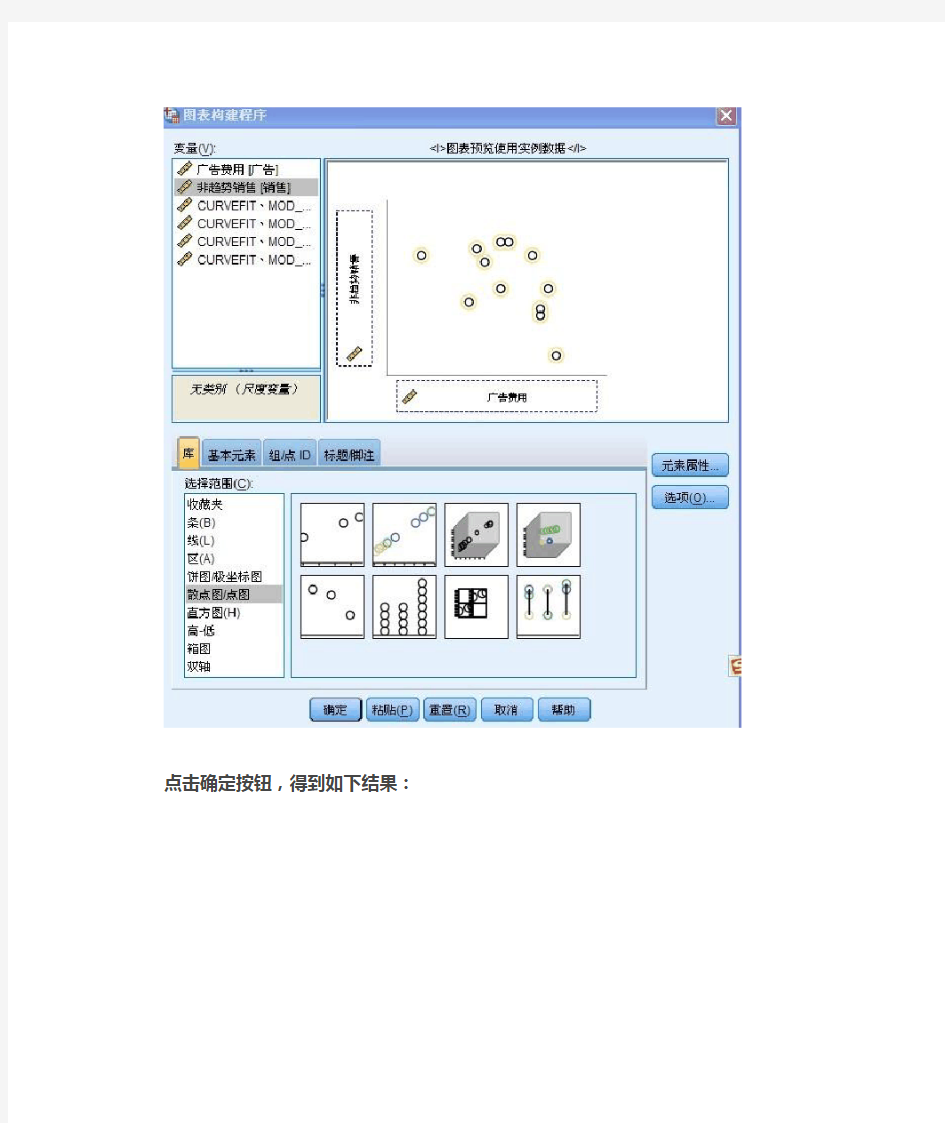
点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!
点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:
通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近
接着,我们采用S 模型,得到如下所示的结果:
结果分析:
1:从ANOVA表中可以看出:总体误差= 回归平方和+ 残差平方和(共计:0.782)F 统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)
2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672
所以S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量)= e^(-0.957/广告费用)
下面,我们直接采用“非线性”模型来进行操作
第一步:确定“非线性模型”
从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。
从图形可以看出:它符合The asymptotic regression model (渐近回归模型)
表达式为:Y(销售量)= b1 + b2*e∧b3*(广告费用)
当b1>0, b2<0, and b3<0,时,它符合效益递减规律,我们称之为:Mistcherlich's model
第二步:确定各参数的初始值
1:b1参数值的确定,从表达式可以看出:随着”广告费用“的增加,销售量也会增加,最后达到一个峰值,由于:b2<0, b3<0 ,随着广告费用的增加:b2*e∧b3*(广告费用)会逐
渐趋向于“0”而此时Y(销售量)将接近于b1值,从上图可以看出:Y(销售量)的最大值为12点多,接近13,所以,我们设定b1的初始值为13
2:b2参数值确定:当Y(销售量)最小时,此时应该广告费用最小,基本等于“0”,可以得出:b1+b2= Y(销售量)此时Y销售量最小,从图中可以看出:第一个值为6.7左右,接近7这个值,所以:b2=7-13=-6
3: b3参数值确定:可以用图中两个分离点的斜率来确定b3的值,例如取
(x1=2.29,y1=8.71) 和( x2=5.75, y2=12.74) 通过公式y2-y1/x2-x1=1.16,(此处可以去整数估计值来算b3的值)
确定参数初始值和参数范围的方法如下所示:
1:通过图形确定参数的取值范围,然后在这个范围里选择初始值。
2:根据非线性方程的数学特性进行某些变换后,再通过图形帮助判断初始值的范围。3:先使用固定的数代替某些参数,以此来确定其它参数的取值范围。
4:通过变量转换,使用线性回归模型来估计参数的初始值
第三步:建立模型表达式和选择损失函数
点击“分析”—回归——非线性,进入如下所示界面:
如上图中,点击参数,分别添加b1,b2,b3进入参数框内,在模型表达式中输入:b1 + b2*Exp(b3*广告费用)(步骤为:选择“函数组”—算术——Exp函数),将“销售量”变量拖入“因变量”框内
“损失函数”默认选项为“残差平方和” 如果有特需要求,可以自行定义
点击“约束”进入如下所示的界面:
点击“继续”按钮,此时会弹出警告信息,提示用户是否接受建议, 建议内容为:将采用序列二次编程进行参数估计,点击确定,接受建议即可
参数的取值范围指在迭代过程中,将参数限制在有意义的范围区间内,提供两种对参数范围约束的方法:
1:线性约束,在约束表达式里只有对参数的线性运算
2:非线性约束,在约束表达式里,至少有一个参数与其它参数进行了乘,除运算,或者自身的幂运算
在“保存”选项中,勾选“预测值”和“残差”即可,点击继续
点击“选项”得到如下所示的界面:
此处的“估计方法”选择“序列二次编程”的方法,此方法主要利用的是双重迭代法进行求解,每一步迭代都建立一个二次规划算法,以此确定优化的方向,把估计参数不断的带入损失函数进行求值运算,直到满足指定的收敛条件为止
点击继续,再点击“确定”得到如下所示的结果:
上图结果分析:
1:从“迭代历史记录”表中可以看出:迭代了17次后,迭代被终止,已经找到最优解
此方法是不断地将“参数估计值”代入”损失函数“求解,而损失函数采用的是”残差平方和“最小,在迭代17次后,残差平方和达到最小值,最小值为(6.778)此时找到最优解,迭代终止
2:从参数估计值”表中可以看出:
b1= 12.904 (标准误为0.610,比较小,说明此估计值的置信度较高)b2=-11.268 (标准误为:1.5881,有点大,说明此估计值的置信度不太高) b3=-0.496(标准误为:0.138,很小,说明此估计值的置信度很高)
非线性模型表达式为:Y(销售量)= 12.904-11.268*e^(-0.496*广告费用)
3:从“参数估计值的相关性”表中可以看出:b1 和b3的相关性较强,b2和b1或b3的相关性都相对弱一些,其中b1和b2的相关性最弱
4:从anova表中可以看出:R方= 1- (残差平方和)/(已更正的平方和)= 0.909,拟合度为0.909,说明此模型能够解释90多的变异,拟合度已经很高了
前面已经提到过,S行曲线的拟合度更高,为(0.916)那到底哪个更合适呢?如果您的数据样本容量够大,我想应该是“非线性模型”的拟合度会更高!
其实想想,我们是否可以将“非线性”转换为“线性”后,再利用线性模型进行分析了?后期有时间的话,将还是以本例为说明,如何将“非线性”转换为“线性”后进行分析!!
spss多元回归分析报告案例
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
最新利用SPSS拟合非线性回归模型
利用S P S S拟合非线性回归模型
利用SPSS拟合非线性回归模型 ——以S型曲线为例 1.原始数据 下表给出了某地区1971—2000年的人口数据(表1)。试用SPSS软件对该地区的人口变化进行曲线拟合,并对今后10年的人口发展情况进行预测。 表1 某地区人口变化数据 年份时间变量t=年份-1970 人口y/人 1971133 815 1972233 981 1973334 004 1974434 165 1975534 212 1976634 327 1977734 344 1978834 458 1979934 498 19801034 476 19811134 483 19821234 488 19831334 513 19841434 497 19851534 511 19861634 520 19871734 507 19881834 509 19891934 521 19902034 513 19912134 515 19922234 517 19932334 519 19942434 519 19952534 521 19962634 521 19972734 523
1998 28 34 525 1999 29 34 525 2000 30 34 527 根据上表中的数据,做出散点图,见图1。 , 33700 33800 3390034000341003420034300 3440034500346001970197219741976197819801982198419861988199019921994199619982000 年份 人口 图1 某地区人口随时间变化的散点图 从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,近似S 曲线。 下面,我们用SPSS 软件进行非线性回归分析拟合计算。 2.用SPSS 进行回归分析拟合计算 在SPSS 中可以直接进行非线性拟合,步骤如下(假定已经进行了数据输入,关于数据输入方法见SPSS 相关基础 教程):
SPSS线性回归分析案例
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: 2010年中国各地区城市居民人均年消费支出和可支配收入
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 表3 相关性 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4 系数a 3、结果分析 表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128 表3是相关分析结果。消费性支出Y与可支配收入X相关系数为0.965,相关性很高。 表4是回归分析中的系数:常数项b=704.824,可支配收入X的回归系数a=0.668。a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。得线性回归方程Y=0.668X+704.824. 【实验结论】 (1)结果显示,变量之间具有如下关系式:Y=0.668X+704.824.也就是说消费与收入之间存在稳定的函数关系。随着收入的增加,消费将增加,但消费的增长低于收入的增长。这与凯尔斯的绝对收入消费理论刚好吻合。但为了研究方便,这里假设边际消费倾向为常数。由公式知X每增长1个单位,Y增加0.668个单位。
spss中多元回归分析实例
SPSS中多元回归分析实例在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量xj(j=1,2,3,…,n)之间的多元线性回归模型: Y=b+bx+bx+...+bx+e k210k12其中:b0是回归常数;bk(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级; x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
数据保存在“DATA6-5.SA V”文件中。 1)准备分析数据 在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后的数据显示如图2-1。
实验7相关及回归分析SPSS应用
实验7 相关与回归分析 7.1实验目的 熟练掌握一元线性回归分析的SPSS应用技能,掌握一元非线性回归分析的SPSS应用技能,对实验结果做出解释。 7.2相关知识(略) 7.3实验内容 7.3.1一元线性回归分析的SPSS实验 7.3.2一元非线性回归分析的SPSS实验 7.4实验要求 7.4.1准备实验数据 1.线性回归分析数据 (The Wall 美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》 Street Journal Almanac 1999)上。航班正点到达的比率和每10万名乘客投诉 的次数的数据,见表7-1所示。 表7-1 美国航空公司航空正点率与乘客投诉次数资料 2.非线性回归分析数据 1992~2013年某国保费收入与国内生产总值的数据,试研究保费收入与国内生产
总值的关系的数据,见表7-2所示。 表7-2 1992~2013年某国保费收入与国内生产总值数据 单位:万元 7.4.2完成一元线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.4.3完成一元非线性回归分析的SPSS 实验,对实验结果作出简要分析。 7.5实验步骤 7.5.1 完成一元线性回归分析的SPSS 实验步骤 1.运用SPSS 绘制散点图散点图。 第一步:在excel 中输入数据 图7-1 第二步:将excel 数据导入spss 单击打开数据文档按钮(或选择菜单文件→打开)→选择文件航空公司航班
正点率与投诉率.xls 图7-2 第三步:选择菜单图形→旧对话框→散点/点状,在散点图/点图对话框中, 选择简单分布按钮 图7-3 第三步:在简单散点图对话框中,将候选变量框中的投诉率添加到Y轴,航班正点率添加到X轴,点击确定:
SPSS多元线性回归分析实例操作步骤
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
实验六-用SPSS进行非线性回归分析
实验六用SPSS进行非线性回归分析 例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系
图1原始数据和散点图分析 一、散点图分析和初始模型选择 在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中的Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power和Exponential四个复选框,确定后输出分析结果,见表1。 分析各模型的R平方,选择指数模型较好,其初始模型为 但考虑到在线性变换过程可能会使原模型失去残差平方和最小的意义,因此进一步对原模型进行优化。 模型汇总和参数估计值 因变量: 单位成本 方程模型汇总参数估计值 R 方 F df1 df2 Sig. 常数b1 线性.912 104.179 1 10 .000 158.497 -1.727 对数.943 166.595 1 10 .000 282.350 -54.059 幂.931 134.617 1 10 .000 619.149 -.556 指数.955 212.313 1 10 .000 176.571 -.018 自变量为月产量。 表1曲线估计输出结果
二、非线性模型的优化 SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方和达到最小。从Statistic下选Regression菜单中的Nonlinear命令;按Paramaters按钮,输入参数A:176.57和B:-.0183;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。SPSS输出结果见表2。 由输出结果可以看出,经过6次模型迭代过程,残差平方和已有了较大改善,缩小为568.97,误差率小于0.00000001, 优化后的模型为: 迭代历史记录b 迭代数a残差平方和参数 A B 1.0 104710.523 176.570 -.183 1.1 5.346E+133 -3455.813 2.243 1.2 30684076640.87 3 476.032 .087 1.3 9731 2.724 215.183 -.160 2.0 97312.724 215.183 -.160 2.1 83887.036 268.159 -.133 3.0 83887.036 268.159 -.133 3.1 59358.745 340.412 -.102 4.0 59358.745 340.412 -.102 4.1 26232.008 38 5.967 -.065 5.0 26232.008 385.967 -.065 5.1 7977.231 261.978 -.038 6.0 797 7.231 261.978 -.038 6.1 1388.850 153.617 -.015 7.0 1388.850 153.617 -.015 7.1 581.073 180.889 -.019 8.0 581.073 180.889 -.019 8.1 568.969 182.341 -.019 9.0 568.969 182.341 -.019 9.1 568.969 182.334 -.019 10.0 568.969 182.334 -.019 10.1 568.969 182.334 -.019 导数是通过数字计算的。 a. 主迭代数在小数左侧显示,次迭代数在小数右侧显示。 b. 由于连续残差平方和之间的相对减少量最多为SSCON = 1.000E-008,因此在 22 模型评估和 10 导数评估之后,系统停止运行。
spss-非线性回归分析
实验三非线性回归分析(2学时) 一、实验重点 掌握非线性回归分析的方法。 二、实验难点 模型的选择及对SPSS软件的输出结果进行分析和整理。 三、实验举例 例1、对GDP(国内生产总值)的拟合。选取GDP指标为因变量,单位为亿元,拟合GDP关于时间t的趋势曲线。以1981年为基准年,取值为t=1,1998年t=18,1991-1998年的数据如下: 解:分析过程 (一)画散点图
图3.1:Y 与t 的散点图 图3.2:Ln Y 与t 的散点图 (二)根据画散点图,及经济背景可选用模型 复合函数: 01t y b b = (也称增长模型或半对数模型) 同时,做简单线性回归 01y b b t =+ 以作比较。 (三)模型求解 直接用SPSS 软件的Curve Estimation 命令计算。(也可以用线性化的方法求解,结果基本一致。) 运行结果如下:
(四)结果分析 线性回归方程:2?133754417.520.856 y t R =-+= 复合函数回归方程: ?3603.06(1.1924)t y = ………(*) 2?ln 8.190.1760.992y t R =+= 注意:不能直接比较两模型的拟合优度,需要对复合函数模型处理,利用(*)式,得到复合函数的残差,计算该模型的残差平方和RSS=2.1696×108 ,并计算y 的离差平方和TSS=1.1×1010 ,得到非线性回归的相关指数 82 10 2.169610110.981.110 RSS R TSS ?=-=-≈? 由于该相关指数大于线性回归的拟合优度,所以可以判断复合函数模型比线性回归模型要好。 例2 、一位药物学家是用下面的非线性模型对药物反应拟合回归模型 1 02 1() i i c i c y c u c =- ++ 其中,自变量x 为药剂量,用级别表示; 因变量y 为药物反应程度,用百分 数表示。三个参数c 0 ,c 1 ,c 2都是非负的, c 0 的上限是100%,三个参数的初始值取为c 0 =100,c 1=5 ,c 2=4.8.测得9个数据如下表: 解: 分析过程: (一)画散点图
SPSS—非线性回归(模型表达式)案例解析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:
多元线性回归实例分析
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
第八章 回归分析-SPSS
第六章回归分析 一、基本概念 变量之间的联系可以分为两类: 1.一类是确定性的关系 确定型的关系是指某一个或某几个现象的变动必然会引起另一个现象确定的变动,它们之间的关系可以使用数学函数式确切地表达出来,即函数关系y=f(x)。 2.另一类是非确定关系 称为统计关系或相关关系。 3.回归分析和相关分析的区别 区别主要是模型的假设以及研究的目的有所不同。在模型的假设方面,大致可分为两类: (1)第一类是两个变量一个是非随机变量,而另一个是随机变量。 (2)第二类是两个变量都是不能控制的随机变量,形成一个二维分布。统计学中把前者的分析称为回归分析,把后者的分析称为相关分析。 概括地说,线性回归分析是处理两个或两个以上变量间线性依存关系的统计方法。 二、SPSS提供了丰富的回归分析,内容分为以下几种: Linear: 线性回归分析 Curve Estimation: 曲线拟合估计 Binary Logistic:二维logistic回归分析
Multinomial Logistic:多维logistic回归分析 Ordinal: Ordinal回归分析 Probit:概率单位回归分析 Nonline:非线性回归分析 Weight Estimation:加权估测分析 2-Stage least Squares:两阶最小二乘法分析 本章主要介绍Linear Regression线性回归分析,它包括一元线性回归和多元线性回归,其他不做要求。 第一节一元线性回归 一、一元线性回归模型及假设 一元线性回归模型是两个变量之间的关系可以通过有关的参数直接用直线关系来表达,其模型是: Yi=a+bXi+εi 式中:Yi表示变量Y在总体中的某一个具体的观察值; Xi表示在研究总体中相应的另一个变量的x的具体观察数值; a与b是参数,分别称为回归常数和回归系数; εi是一个随机变量,其均值为0,方差为σ2。 对一元线性回归模型做出以下的几点假设: 1.Xi为一自变量,是预先确定的,因而是一个非随机变量。 2.当确定某一个Xi时,相应的Y就有许多Yi与之对应。Yi是一个随机变量,这些Yi构成一个在X取值为Xi条件下的条件分布,并假设其服从正态分布。
SPSS多元回归分析报告实例
多元回归分析 在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型: 其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1 x1 x2 x3 x4 y 年蛾量级别卵量级别降水量级别雨日级别幼虫密 度 级别 1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3
SPSS实验报告 线性回归 曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++ 上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对
多元线性回归实例分析报告
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,
利用SPSS拟合非线性回归模型
利用SPSS拟合非线性回归模型 ——以S型曲线为例 1.原始数据 下表给出了某地区1971—2000年的人口数据(表1)。试用SPSS软件对该地区的人口变化进行曲线拟合,并对今后10年的人口发展情况进行预测。 表1 某地区人口变化数据 年份时间变量t=年份-1970人口y/人 1971133 815 1972233 981 1973334 004 1974434 165 1975534 212 1976634 327 1977734 344 1978834 458 1979934 498 19801034 476 19811134 483 19821234 488 19831334 513 19841434 497 19851534 511 19861634 520 19871734 507 19881834 509 19891934 521 19902034 513 19912134 515 19922234 517 19932334 519 19942434 519 19952534 521 19962634 521
1997 27 34 523 1998 28 34 525 1999 29 34 525 2000 30 34 527 根据上表中的数据,做出散点图,见图1。, 33700 3380033900340003410034200343003440034500346001970197219741976197819801982198419861988199019921994199619982000 年份 人口 图1 某地区人口随时间变化的散点图 从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,近似S 曲线。 下面,我们用SPSS 软件进行非线性回归分析拟合计算。 2.用SPSS 进行回归分析拟合计算 在SPSS 中可以直接进行非线性拟合,步骤如下(假定已经进行了数据输入,关于数据输入方法见SPSS 相关基础 教程): Analysis->Regression->Cubic,在弹出的对话框(见图一)中选择拟合的变量和自变量,本例分别选择y (人口),t (时间变量)为变量(Dependent )和自变
多元回归分析SPSS案例
多元回归分析 在大多数得实际问题中,影响因变量得因素不就就是一个而就就是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间得多元线性回归模型: 其中:b0就就是回归常数;b k(k=1,2,3,…,n)就就是回归参数;e就就是随机误差。 多元回归在病虫预报中得应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10、0毫米为1级,10、1~13、2毫米为2级,13、3~17、0毫米为3级,17、0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1
数据保存在“DATA6-5、SAV”文件中。 1)准备分析数据 在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”与“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日与幼虫密度得分级变量“x1”、“x2”、“x3”、“x4”与“y”,它们对应得分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后得数据显示如图2-1。 图2-1 或者打开已存在得数据文件“DATA6-5、SAV”。 2)启动线性回归过程 单击SPSS主菜单得“Analyze”下得“Regression”中“Linear”项,将打开如图2-2所示得线性回归过程窗口。
实验六 用SPSS进行非线性回归分析
实验六用SPSS进行非线性回归分析 例:通过对比12个同类企业得月产量(万台)与单位成本(元)得资料(如图1),试配合适当得回归模型分析月产量与单位成本之间得关系
图1原始数据与散点图分析 一、散点图分析与初始模型选择 在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以瞧出,该数据配合线性模型、指数模型、对数模型与幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中得Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power与Exponential四个复选框,确定后输出分析结果,见表1。 分析各模型得R平方,选择指数模型较好,其初始模型为 但考虑到在线性变换过程可能会使原模型失去残差平方与最小得意义,因此进一步对原模型
自变量为月产量。 表1曲线估计输出结果 二、非线性模型得优化 SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方与达到最小。从Statistic下选Regression菜单中得Nonlinear命令;按Paramaters按钮,输入参数A:176、57与B:-、0183;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。SPSS输出结果见表2。 由输出结果可以瞧出,经过6次模型迭代过程,残差平方与已有了较大改善,缩小为568、 97,误差率小于0、00000001, 优化后得模型为: 迭代历史记录b 迭代数a残差平方与参数 A B 1、0104710、523 176、570-、183 1、15、346E+133 -3455、 813 2、243 1、2 306840766 40、873 476、032 、087 1、3 9731 2、724215、183 -、160 2、0 97312、724 215、183 -、160 2、1 83887、036268、159 -、133 3、083887、036 268、159 -、133 3、159358、745 340、412-、102 4、0 59358、745 340、412 -、102 4、126232、008385、967 -、065 5、0 26232、008 385、967 -、065 5、17977、231261、978 -、038 6、07977、231 261、978-、038 6、11388、850 153、617-、015 7、0 1388、850153、617-、015 7、1 581、073 180、889 -、019 8、0 581、073 180、889 -、019 8、1 568、969 182、341 -、019 9、0 568、969 182、341 -、019 9、1 568、969 182、334 -、019 10、0 568、969 182、334 -、019 10、1 568、969 182、334 -、019 导数就就是通过数字计算得。 a、主迭代数在小数左侧显示,次迭代数在小数右侧显示。
(推荐下载)SPSS线性回归分析案例
(完整word版)SPSS线性回归分析案例 编辑整理: 尊敬的读者朋友们: 这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整word版)SPSS线性回归分析案例)的内容能够给您的工作和学习带来便利。同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。 本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整word版)SPSS线性回归分析案例的全部内容。
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归 分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等.为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1:
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
实验六用spss进行非线性回归分析
实验六 用SPSS 进行非线性回归分析 例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的 回归模型分析月产量与单位成本之间的关系 10.00 20.00 30.00 40.00 50.00 G0 00 70.00 月产最 150.00H 140.00- 120.00^ 100.00- SO.QO - 60.00-
丈肆回 SSt? ^00 l!!g ( DJ R?(Tj 余祈对 直诵观 ?^[C )賈用程序妙 運口曲 那就 出. I 可见'2WM2 耳产f 单悅咸本 r i ? i SB id 00 14&00 2 1E.OO 151(H) g 2C.O O 11400 4 25.00 121 00 C 3C QO 94 00 G 31.00 1 7 40.00 35 00 6 2] 址00 76 0& a d> 5C.O O 56.00 Jf.OO 50.00 11 6C QO □1 CO 1? fif QO 50 00 n 二 r I* ■■一 匚 1L 图1原始数据和散点图分析 一、散点图分析和初始模型选择 在SPSS 数据窗口中输入数据,然后插入散点图 (选择Graphs ^ Scatter 命令),由散点图 可以看出,该数据配合线性模型、指数模型、 对数模型和幕函数模型都比较合适。 进一步进 行曲线估计:从 Statistic 下选Regression 菜单中的 Curve Estimation 命令;选因变量单位成 本到 Depe nde nt 框中,自变量月产量到 In depe nde nt 框中,在 Models 框中选择 Li near 、 Logarithmic 、Power 和Exponential 四个复选框,确定后输出分析结果,见表 1。 分析各模型的R 平方,选择指数模型较好,其初始模型为 但 尸二】7657 *广 考虑到在线性变换过程可能会使原模型失去残差平方和最小 的 意义,因此进一步对原模型进行优化。 JS SPSS stat st cs Prcc&Esor 船建
多元线性回归分析案例
SPSS19.0实战之多元线性回归分析 (2011-12-09 12:19:11) 转载▼ 分类:软件介绍 标签: 文化 线性回归数据(全国各地区能源消耗量与产量)来源,可点击协会博客数据挖掘栏:国泰安数据服务中心的经济研究数据库。 1.1 数据预处理 数据预处理包括的内容非常广泛,包括数据清理和描述性数据汇总,数据集成和变换,数据归约,数据离散化等。本次实习主要涉及的数据预处理只包括数据清理和描述性数据汇总。一般意义的数据预处理包括缺失值填写和噪声数据的处理。于此我们只对数据做缺失值填充,但是依然将其统称数据清理。 1.1.1 数据导入与定义 单击“打开数据文档”,将xls格式的全国各地区能源消耗量与产量的数据导入SPSS中,如图1-1所示。 图1-1 导入数据 导入过程中,各个字段的值都被转化为字符串型(String),我们需要手动将相应的字段转回数值型。单击菜单栏的“ ”-->“ ”将所选的变量改为数值型。如图1-2所示:
图1-2 定义变量数据类型 1.1.2 数据清理 数据清理包括缺失值的填写和还需要使用SPSS分析工具来检查各个变量的数据完整性。单击“ ”-->“ ”,将检查所输入的数据的缺失值个数以及百分比等。如图1-3所示: 图1-3缺失值分析
表1-1 能源消耗量与产量数据缺失值分析 SPSS提供了填充缺失值的工具,点击菜单栏“ ”-->“ ”,即可以使用软件提供的几种填充缺失值工具,包括序列均值,临近点中值,临近点中位数等。结合本次实习数据的具体情况,我们不使用SPSS软件提供的替换缺失值工具,主要是手动将缺失值用零值来代替。 1.1.3 描述性数据汇总 描述性数据汇总技术用来获得数据的典型性质,我们关心数据的中心趋势和离中趋势,根据这些统计值,可以初步得到数据的噪声和离群点。中心趋势的量度值包括:均值(mean),中位数(median),众数(mode)等。离中趋势量度包括四分位数(quartiles),方差(variance)等。 SPSS提供了详尽的数据描述工具,单击菜单栏的“ ”-->“ ”-->“ ”,将弹出如图2-4所示的对话框,我们将所有变量都选取到,然后在选项中勾选上所希望描述的数据特征,包括均值,标准差,方差,最大最小值等。由于本次数据的单位不尽相同,我们需要将数据标准化,同时勾选上“将标准化得分另存为变量”。