面板数据分析
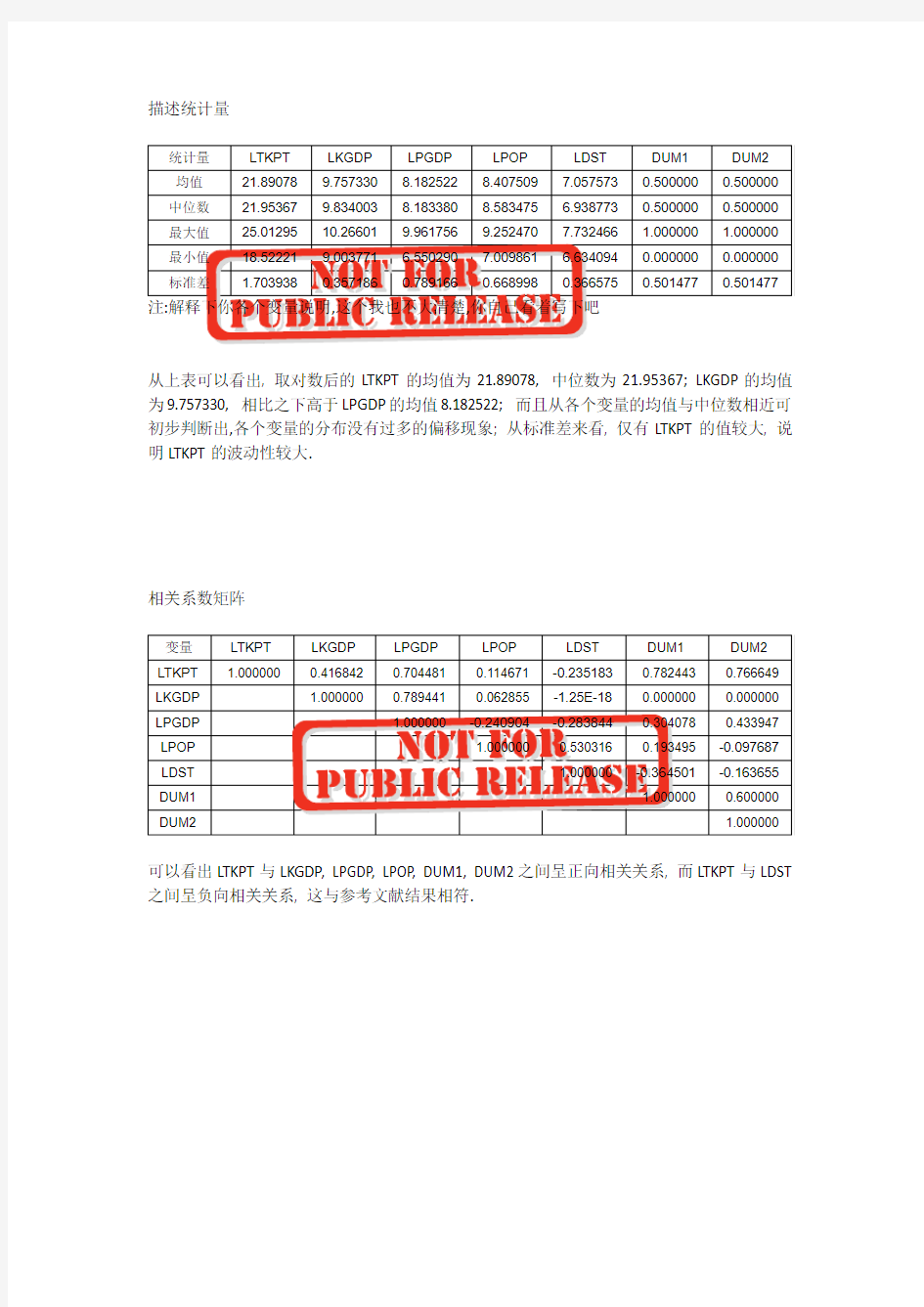

从上表可以看出, 取对数后的LTKPT的均值为21.89078, 中位数为21.95367; LKGDP的均值为9.757330, 相比之下高于LPGDP的均值8.182522; 而且从各个变量的均值与中位数相近可初步判断出,各个变量的分布没有过多的偏移现象; 从标准差来看, 仅有LTKPT的值较大, 说明LTKPT的波动性较大.
相关系数矩阵
可以看出LTKPT与LKGDP, LPGDP, LPOP, DUM1, DUM2之间呈正向相关关系, 而LTKPT与LDST 之间呈负向相关关系, 这与参考文献结果相符.
具体单位根与协整的简单的理论解释,参考报告3里的内容,这里就不重复解释了.
上表结果显示, LTKPT的水平值在IPS检验, ADF检验中未能在5%显著水平拒绝LTKPT存在单位根的原假设, 而一阶差分后的LTKPT的4个检验中,均能在5%显著水平拒绝LTKPT一阶差分值存在单位根的原假设, 表示LTKPT为一阶差分平稳序列; 同理我们可以看出LKGDP, LPGDP, LPOP均为一阶差分平稳序列, 因此可以进行协整检验.
Johansen协整检验
注:这个我就不多写了,参考文献
从上述结果可以看出, 四个变量之间在5%显著水平存在1个协整关系, 因此可以利用水平值建立回归分析.
回归结果
注:*, **, ***分别表示在10%, 5%, 1%显著水平显著.
从Hausman检验结果显示, Prob=1.0000, 因此选择随机效应模型, 着重以随机效应模型结果进行解释.
从随机效应模型结果可以看出, LKGDP的系数为1.188770, 而且在1%显著水平显著, 表示其他条件不发生变化时, KGDP变化1%时, TKPT将变化1.188770%, 即KGDP对TKPT存在正影响关系; LPGDP的系数为0.432548, 且在1%显著水平显著, 表示其他条件不发生变化时, PGDP变化1%时, TKPT将变化0.432548%, 即PGDP对TKPT存在正影响关系; LPOP的系数为0.384872, 且在5%显著水平显著, 表示其他条件不发生变化时, POP变化1%时, TKPT将变化0.384872%; LDST的系数为-0.162346, 虽然从符号上来看, DST对TKPT存在负影响关系, 但未能通过显著性检验; DUM1的系数为1.413823, 且在1%显著水平显著, 表示相比DUM1为0, 1的TKPT相对较高; DUM2的系数为1.492003, 且在1%显著水平显著, 表示相比DUM2为0,1的TKPT相对较高.
可以看出,虽然在系数大小上与参考文献不一致, 但从随机效应的结果中系数的符号, 以及显著性来看与参考文献的结果是一致的.
面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)
面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析) 面板数据分析方法: 面板单位根检验—若为同阶—面板协整—回归分析 —若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。不是时间序列那种接近0.8为优秀。另外,建议回归前先做stationary。很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。该如何选择呢? 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al.(2002)的改进,提出了检验面板单位根的LLC法。Levin et al.(2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250之间,截面数介于10~250之间)的面板单位根检验。Im et al.(1997)还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T、IPS-W、ADF-FCS、PP-FCS、H-Z分别指Levin,Lin&Chu t*
数据分析的思维技巧
数据分析的思维技巧 在我对数据分析有限的认识上(因为无知到没有认知),往往会看到一些秀技性的数据分析图表,以及好看的词云等等。年少无知的我,只想啪啪啪鼓掌伴随一声“卧槽,真牛逼”,然后在被秀了一脸后,并没有明白对方想说什么,空有一副好皮囊而没有灵魂。分析是为了给出偏好的,也是洗脑的一种重要手段,洗不洗的成功就要靠本事了。于是问题产生了,你的分析是为了干啥,通过哪几个角度达到哪几方面的目的。以下为我对几个技巧的认识想法: 一、象限法 就是划定几个坐标轴,让每一个数据在象限中找到自己的角色,比如打工这个事吧,就是要让你忙,就是要给你一堆事,于是重点出来了,这么多事孰重孰轻,孰急孰缓,跟打工皇帝学时间管理,事情要按照紧急程度和重要程度进行划分,以此给自己做事排序。 二、多维法 从个人理解来看,多维法和象限法联系紧密,无非就是象限法之间的界限清晰明显,多维法之间的维度不是严格意义的隔开,比如高度、富有、颜值,这到底算象限分类还是维度分类,或者说当象限多了,采用多维来理解效果更好,比如富有的家庭一般孩纸整体相对更高一些,维度与维度之间是有相对联系的,虽然不是那么绝对,但是也不是完全不相关。
但是多维法呢,正是由于维度与维度之间的关系,会导致整体维度情况和细分维度情况来看起来会有失真,最典型的例子是田忌赛马,上中下三个维度的马均是齐王更厉害,那么跑马结果田忌胜了。性别歧视在工作学习中经常会碰到,但是通过男女入取率判断性别歧视合适么,每个学院的女生录取率都高,但是整体入取率女生低的情况也不是不能出现,那么这到底是哪种性别歧视呢,数字不会骗人,但是分析洗脑会骗人,分析思维不对容易骗自己。为了解决辛普森悖论,可以通过切方块的方式,不断缩小分析的维度,不断深入挖掘,可以有效了解真实情况。 三、假设法 数据分析对下是有一系列材料做支撑,对上是为决策或了解情况提供支撑,只有下面有素材,才能为上面提供科学合理研判。那么问题出来了,如果没有材料做支撑,那怎么办。简单,没有条件那就为它创建条件嘛,我先假设一个基础,然后根据这个基础大肆分析,水平体现出来了,偏好结论也体现出来了,其实很多现实问题是没有那么多切实完整的基础资料的,有的就是一个感觉,有的就是一个偏好。这也是咨询圈常见的套路,虽然不是严格意义的1+1=2,但是可以严谨告诉别人1+1>1,而且面对那么多的未知,不将几个未知进行假设,如何区解决更多的未知。 四、指数法 一直觉得,指数法是一个装逼指数最高的方法,首先指数就已经狠专业了,在专业的基础上进行专业的分析,还有什么更专业的事情么。但是
面板数据分析简要步骤与注意事项面板单位根面板协整回归分析
面板数据分析简要步骤与注意事项 面板单位根—面板协整—回归分析) 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实 际意义的。这种情况称为称为虚假回归或伪回归( spurious regression )。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中 ,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布 , 这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002) 的改进, 提出了检验面板单位根的LLC法。Levin et al. (2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25?250之间,截面数介于10?250之间)的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的 IPS 法, 但 Breitung(2000) 发现 IPS 法对限定性趋势的设定极为敏感 , 并提出了面板单位根检验的 Breitung 法。Maddala and Wu(1999)又提出了 ADF-Fisher 和 PP-Fisher 面板单位根检验方法。 由上述综述可知,可以使用 LLC、IPS、Breintung 、ADF-Fisher 和 PP-Fisher5 种方法进行面板单位根检验。其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS、H-Z 分 别指 Levin, Lin & Chu t* 统计量、 Breitung t 统计量、 lm Pesaran & Shin W 统 量、计 ADF- Fisher Chi-square 统计量、PP-Fisher Chi-square 统计量、Hadri Z 统计 量,并且 Levin, Lin & Chu t* 统计量、 Breitung t 统计量的原假设为存在普通的单位根过程, lm Pesaran & Shin W 统计量、 ADF- Fisher Chi-square 统计量、 PP-Fisher Chi-square 统计量的原假设为存在有效的单位根过程, Hadri Z 统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验 LLC(Levin-Lin-Chu )检验和不同根单位根检验 Fisher-ADF 检验(注:对普通序列(非面板序列)的单位根检验方法则常用 ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我 们说此序列是平稳的,反之则不平稳。 如果我们以 T(trend )代表序列含趋势项,以 I (intercept )代表序列含截距项, T&I 代表两项都含,N (none)代表两项都不含,那么我们可以基于前面时序图得出的结论,在单位根检验中选择相应检验模式。 但基于时序图得出的结论毕竟是粗略的,严格来说,那些检验结构均需一一检验。具体操作可以参照李子奈的说法:ADF检验是通过三个模型来完成,首先从含有截距和趋势项的模型开始,再检验只含截距项的模型,最后检验二者都不含的模型。并且认
人教版初中数学数据分析技巧及练习题附答案
人教版初中数学数据分析技巧及练习题附答案 一、选择题 1.如图是根据我市某天七个整点时的气温绘制成的统计图,则这七个整点时气温的中位数和众数分别是() A.中位数31,众数是22 B.中位数是22,众数是31 C.中位数是26,众数是22 D.中位数是22,众数是26 【答案】C 【解析】 【分析】 根据中位数,众数的定义即可判断. 【详解】 七个整点时数据为:22,22,23,26,28,30,31 所以中位数为26,众数为22 故选:C. 【点睛】 此题考查中位数,众数的定义,解题关键在于看懂图中数据 2.某校组织“国学经典”诵读比赛,参赛10名选手的得分情况如表所示: 分数/分80859095 人数/人3421 那么,这10名选手得分的中位数和众数分别是() A.85.5和80 B.85.5和85 C.85和82.5 D.85和85 【答案】D 【解析】 【分析】 众数是一组数据中出现次数最多的数据,注意众数可以不只一个; 找中位数要把数据按从小到大的顺序排列,位于最中间的一个数(或两个数的平均数)为中位数. 【详解】 数据85出现了4次,最多,故为众数;
按大小排列第5和第6个数均是85,所以中位数是85. 故选:D. 【点睛】 本题主要考查了确定一组数据的中位数和众数的能力.一些学生往往对这个概念掌握不清楚,计算方法不明确而误选其它选项.注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数,如果数据有奇数个,则正中间的数字即为所求.如果是偶数个则找中间两位数的平均数. 3.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5, 则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 4.多多班长统计去年1~8月“书香校园”活动中全班同学的课外阅读数量(单位:本),绘制了如图折线统计图,下列说法正确的是() A.极差是47 B.众数是42 C.中位数是58 D.每月阅读数量超过40的有4个月 【答案】C 【解析】 【分析】 根据统计图可得出最大值和最小值,即可求得极差;出现次数最多的数据是众数;将这8
面板数据分析步骤
转载:面板数据分析的思路和Eviews操作: 面板数据一般有三种:混合估计模型;随机效应模型和固定效应模型。首先,第一步是作固定效应和随机效应模型的选择,一般是用Hausman检验。 如果你选用的是所有的企业,反映的是总体的效应,则选择固定效应模型,如果你选用的是抽样估计,则要作Hausman检验。这个可以在Eviews 5.1里头做。 H0:应该建立随机效应模型。 H1:应该建立固定效应模型。 先使用随机效应回归,然后做Hausman检验,如果是小概率事件,拒绝原假设则应建立固定效应模型,反之,则应该采用随机效应模型进行估计。 第二步,固定效应模型分为三种:个体固定效应模型、时刻固定效应模型和个体时刻固定效应模型(这三个模型的含义我就不讲了,大家可以参考我列的参考书)。如果我们是对个体固定,则应选择个体固定效用模型。但是,我们还需作个体固定效应模型和混合估计模型的选择。所以,就要作F值检验。相对于混合估计模型来说,是否有必要建立个体固定效应模型可以通过F检验来完成。 H0:对于不同横截面模型截距项相同(建立混合估计模型)。SSEr H1:对于不同横截面模型的截距项不同(建立时刻固定效应模型)。SSEu
F统计量定义为:F=[( SSEr - SSEu)/(T+k-2)]/[ SSEu/(NT-T-k)] 其中,SSEr,SSEu分别表示约束模型(混合估计模型的)和非约束模型(个体固定效应模型的)的残差平方和(Sum squared resid)。非约束模型比约束模型多了T–1个被估参数。需要指出的是:当模型中含有k 个解释变量时,F统计量的分母自由度是NT-T- k。通过对F统计量我们将可选择准确、最佳的估计模型。 在作回归是也是四步:第一步,先作混合效应模型:在cross-section 一栏选择None ,Period也是None;Weights是cross-section Weights,然后把回归结果的Sum squared resid值复制出来,就是SSEr 第二步:作个体固定效用模型:在cross-section 一栏选择Fixed ,Period也是None;Weights是cross-section Weights,然后把回归结果的Sum squared resid值复制出来,就是SSEu 第三步:根据公式F=[( SSEr - SSEu)/(T+k-2)]/[ SSEu/(NT-T-k)]。计算出结果。其中,T为年数,不管我们的数据是unbalance还是balance 看observations就行了,也即Total pool (balanced) observations:的值,但是如果是balance我们也可以计算,也即是每一年的企业数的总和。比如说我们研究10年,每一年又500加企业,则NT=10×500=5000。K为解释变量,不含被解释变量。 第四步,根据计算出来的结果查F值分布表。看是否通过检验。检验准则:当F> Fα(T-1, NT-T-k) , α=0.01,0.05或0.1时,拒绝原假设,则结论是应该建立个体固定效应模型,反之,接受原假设,则不能建立个体固定效应模型。
eviews面板数据实例分析
1、已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)与人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。 年人均消费(consume)与人均收入(income)数据以及消费者价格指数(p)分别见表9、1,9、2与9、3。 表9、1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607、43 3693、55 3777、41 3901、81 4232、98 4517、65 4736、52 CONSUMEBJ 5729、52 6531、81 6970、83 7498、48 8493、49 8922、72 10284、6 CONSUMEFJ 4248、47 4935、95 5181、45 5266、69 5638、74 6015、11 6631、68 CONSUMEHB 3424、35 4003、71 3834、43 4026、3 4348、47 4479、75 5069、28 CONSUMEHLJ 3110、92 3213、42 3303、15 3481、74 3824、44 4192、36 4462、08 CONSUMEJL 3037、32 3408、03 3449、74 3661、68 4020、87 4337、22 4973、88 CONSUMEJS 4057、5 4533、57 4889、43 5010、91 5323、18 5532、74 6042、6 CONSUMEJX 2942、11 3199、61 3266、81 3482、33 3623、56 3894、51 4549、32 CONSUMELN 3493、02 3719、91 3890、74 3989、93 4356、06 4654、42 5342、64 CONSUMENMG 2767、84 3032、3 3105、74 3468、99 3927、75 4195、62 4859、88 CONSUMESD 3770、99 4040、63 4143、96 4515、05 5022 5252、41 5596、32 CONSUMESH 6763、12 6819、94 6866、41 8247、69 8868、19 9336、1 10464 CONSUMESX 3035、59 3228、71 3267、7 3492、98 3941、87 4123、01 4710、96 CONSUMETJ 4679、61 5204、15 5471、01 5851、53 6121、04 6987、22 7191、96 CONSUMEZJ 5764、27 6170、14 6217、93 6521、54 7020、22 7952、39 8713、08 表9、2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512、77 4599、27 4770、47 5064、6 5293、55 5668、8 6032、4 INCOMEBJ 7332、01 7813、16 8471、98 9182、76 10349、69 11577、78 12463、92 INCOMEFJ 5172、93 6143、64 6485、63 6859、81 7432、26 8313、08 9189、36 INCOMEHB 4442、81 4958、67 5084、64 5365、03 5661、16 5984、82 6679、68 INCOMEHLJ 3768、31 4090、72 4268、5 4595、14 4912、88 5425、87 6100、56 INCOMEJL 3805、53 4190、58 4206、64 4480、01 4810 5340、46 6260、16 INCOMEJS 5185、79 5765、2 6017、85 6538、2 6800、23 7375、1 8177、64 INCOMEJX 3780、2 4071、32 4251、42 4720、58 5103、58 5506、02 6335、64 INCOMELN 4207、23 4518、1 4617、24 4898、61 5357、79 5797、01 6524、52 INCOMENMG 3431、81 3944、67 4353、02 4770、53 5129、05 5535、89 6051 INCOMESD 4890、28 5190、79 5380、08 5808、96 6489、97 7101、08 7614、36 INCOMESH 8178、48 8438、89 8773、1 10931、64 11718、01 12883、46 13249、8 INCOMESX 3702、69 3989、92 4098、73 4342、61 4724、11 5391、05 6234、36 INCOMETJ 5967、71 6608、39 7110、54 7649、83 8140、5 8958、7 9337、56 INCOMEZJ 6955、79 7358、72 7836、76 8427、95 9279、16 10464、67 11715、6 表9、3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109、9 101、3 100 97、8 100、7 100、5 99
如何自学数据分析方法介绍
如何自学数据分析方法介绍 如何自学数据分析方法介绍 想要成为数据分析师,最快需要七周?七周信不信? 这是一份数据分析师的入门指南,它包含七周的内容,Excel、 数据可视化、数据分析思维、数据库、统计学、业务、以及Python。 每一周的内容,都有两到三篇文章细致讲解,帮助新人们快速掌握。这七周的内容刚好涵盖了一位数据分析师需要掌握的基础体系,也是一位新人从零迈入数据大门的知识手册。 第一周:Excel 每一位数据分析师都脱离不开Excel。 Excel的学习分为两个部分。 掌握各类功能强大的函数,函数是一种负责输入和输出的神秘盒子。把各类数据输入,经过计算和转换输出我们想要的结果。 在SQL,Python以及R中,函数依旧是主角。掌握Excel的函数有助于后续的学习,因为你几乎在编程中能找到名字一样或者相近 的函数。 在「数据分析:常见的Excel函数全部涵盖在这里了」中,介绍了常用的Excel函数。 清洗处理类:trim、concatenate、replace、substitute、 left/right/mid、len/lenb、find、search、text 关联匹配类:lookup、vlookup、index、match、row、column、offset 逻辑运算类:if、and、or、is系列
计算统计类:sum/sumif/sumifs、sumproduct、 count/countif/countifs、max、min、rank、rand/randbetween、averagea、quartile、stdev、substotal、int/round 时间序列类:year、month、weekday、weeknum、day、date、now、today、datedif 搜索能力是掌握Excel的不二窍门,工作中的任何问题都是可以找到答案。 第二部分是Excel中的工具。 在「数据分析:Excel技巧大揭秘」教程,介绍了Excel最具性 价比的几个技巧。包括数据透视表、格式转换、数组、条件格式、 自定义下拉菜单等。正是这些工具,才让Excel在分析领域经久不衰。 在大数据量的处理上,微软提供了Power系列,它和Excel嵌套,能应付百万级别的数据处理,弥补了Excel的不足。 Excel需要反复练习,实战教程「数据分析:手把手教你Excel 实战」,它通过网络上抓取的数据分析师薪资数据作为练习,总结 各类函数的使用。 除了上述要点,下面是附加的知识点,铺平数据分析师以后的道路。 了解单元格格式,数据分析师会和各种数据类型打交道,包括各类timestamp,date,string,int,bigint,char,factor, float等。 了解数组,以及相关应用(excel的数组挺难用),Python和R也会涉及到list,是核心概念之一。 了解函数,深入理解各种参数的作用。它会在学习Python中帮 助到你。 了解中文编码,UTF8、GBK、ASCII,这是数据分析师的坑点之一。
大数据处理技术的总结与分析
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。
面板数据的分析步骤
面板数据的分析步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square 统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC (Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们
基于面板数据模型及其固定效应的模型分析
基于面板数据模型及其固定效应的模型分析 在20世纪80年代及以前,还只有很少的研究面板数据模型及其应用的文献,而20世纪80年代之后一直到现在,已经有大量的文献使用同时具有横截面和时间序列信息的面板数据来进行经验研究(Hsiao,20XX)。同时,大量的面板数据计量经济学方法和技巧已经被开发了出来,并成为现在中级以上的计量经济学教科书的必备内容,面板数据计量经济学的理论研究也是现在理论计量经济学最热的领域之一。 面板数据同时包含了许多横截面在时间序列上的样本信息,不同于只有一个维度的纯粹横截面数据和时间序列数据,面板数据是同时有横截面和时序二维的。使用二维的面板数据相对于只使用横截面数据或时序数据,在理论上被认为有一些优点,其中一个重要的优点是面板数据被认为能够控制个体的异质性。在面板数据中,人们认为不同的横截面很可能具有异质性,这个异质性被认为是无法用已知的回归元观测的,同时异质性被假定为依横截面不同而不同,但在不同时点却是稳定的,因此可以用横截面虚拟变量来控制横截面的异质性,如果异质性是发生在不同时期的,那么则用时期虚拟变量来控制。而这些工作在只有横截面数据或时序数据时是无法完成的。 然而,实际上绝大多数时候我们并不关心这个异质性究竟是多少,我们关心的仍然是回归元参数的估计结果。使用面板数据做过实际研究的人可能会发现,使用的效应①不同,对回归元的估计结果经常有十分巨大的影响,在某个固定效应设定下回归系数为正显着,而另外一个效应则变为负显着,这种事情经常可以碰到,让人十分困惑。大多数的研究文献都将这种影响解释为控制了固定效应后的结果,因为不可观测的异质性(固定效应)很可能和回归元是相关的,在控制了这个效应后,由于变量之间的相关性,自然会对回归元的估计结果产生影响,因而使用的效应不同,估计的结果一般也就会有显着变化。 然而,这个被广泛接受的理论假说,本质上来讲是有问题的。我们认为,估计的效应不同,对应的自变量估计系数的含义也不同,而导致估计结果有显着变化的可能重要原因是由于面板数据是二维的数据,而在这两个不同维度上,以及将两个维度的信息放到一起时,样本信息所显现出来的自变量和因变量之间的相关关系可能是不同的。因此,我们这里提出另外一种异质性,即样本在不同维度上的相关关系是不同的,是异质的,这个异质性是发生在回归元的回归系数上,而
数据整理分析方法
数据梳理主要是指对数据的结构、内容和关系进行分析 大多数公司都存在数据问题。主要表现在数据难于管理,对于数据对象、关系、流程等难于控制。其次是数据的不一致性,数据异常、丢失、重复等,以及存在不符合业务规则的数据、孤立的数据等。 1数据结构分析 1元数据检验 元数据用于描述表格或者表格栏中的数据。数据梳理方法是对数据进行扫描并推断出相同的信息类型。 2模式匹配 一般情况下,模式匹配可确定字段中的数据值是否有预期的格式。 3基本统计 元数据分析、模式分析和基本统计是数据结构分析的主要方法,用来指示数据文件中潜在的结构问题。 2 数据分析 数据分析用于指示业务规则和数据的完整性。在分析了整个的数据表或数据栏之后,需要仔细地查看每个单独的数据元素。结构分析可以在公司数据中进行大范围扫描,并指出需要进一步研究的问题区域;数据分析可以更深入地确定哪些数据不精确、不完整和不清楚。 1标准化分析 2频率分布和外延分析 频率分布技术可以减少数据分析的工作量。这项技巧重点关注所要进一步调查的数据,辨别出不正确的数据值,还可以通过钻取技术做出更深层次的判断。 外延分析也可以帮助你查明问题数据。频率统计方法根据数据表现形式寻找数据的关联关系,而外延分析则是为检查出那些明显的不同于其它数据值的少量数据。外延分析可指示出一组数据的最高和最低的值。这一方法对于数值和字符数据都是非常实用的。 3业务规则的确认 3 数据关联分析 专业的流程模板和海量共享的流程图:[1] - 价值链图(EVC) - 常规流程图(Flowchart) - 事件过程链图(EPC) - 标准建模语言(UML) - BPMN2.0图 数据挖掘 数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题, 所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。 ①分类。分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为
大数据分析及其在医疗领域中的应用-图文(精)
第7期 24 2014年4月10日 计算机教育 ComputerEducation ◆新视点 文章编号:1672.5913(2014)07—0024-06 中图分类号:G642 大数据分析及其在医疗领域中的应用 邹北骥 (中南大学信息科学与工程学院,湖南长沙410083) 摘要:互联网和物联网技术的快速发展给数据的上传与下载带来了前所未有的便利,使得互联网上 的数据量急剧增长,由此产生了针对大数据的存储、计算、分析、处理等新问题,尤其是对大数据的挖掘。文章分析当前大数据产生的背景,阐述大数据的基本特征及其应用,结合医疗领域,论述医疗 大数据分析的目的、意义和主要方法。 关键词:大数据;物联网;医疗;大数据挖掘 1 大数据早已存在,为何现在称之为大
数据时代 计算与数据是一对孪生姐妹,计算需要数据,数据通过计算产生新的价值。数据是客观事 物的定量表达,来自于客观世界并早已存在。例 如,半个世纪前,全球的人口数量就有数十亿,与之相关的数据就是大数据;但是在那个时代,由于技术的局限性,大数据的采集、存储和处理 还难以实现。 互联网时代之前,采集世界各地的数据并让它们快速地进入计算系统几乎是一件不可想象的 事情。20世纪80年代兴起的互联网技术在近30 年里发生了翻天覆地的变化,彻底地改变了人们的工作和生活方式【l】。通过互联网人们不仅可以下载到新闻、小说、论文等各类文字数据,而且可以轻而易举地下载到音乐、图像和视频等多媒体数据,这使得互联网上的数据流量急剧增长。据统计,现在互联网上每分钟流人流出的数 据量达到1 000 PB,即10亿 GBt21。 推动大数据产生的另一个重要因素是物联网技术。近几年发展起来的物联网技 术通过给每个物品贴上标签 并应用RFID等技术实现了
面板数据分析方法步骤
1.面板数据分析方法步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、
面板数据分析方法步骤全解
面板数据分析方法步骤全解 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结, 和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈 曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归, 尽管有较高的R 平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正 含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势 以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时 有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性, 我们必须对各面板序 列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项, 从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中丄evin
an dLi n(1993)很早就发现这些估计量的极限分布是高斯分布,这些结 果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002的改进,提出了检验面板单 位根的LLC法。Levin et al. (2002)指出,该方法允许不同截距和时间趋 势,异方差和高阶序列相关,适合于中等维度(时间序列介于25?250 之间,截面数介于10?250之间)的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对 限定性趋势的设定极为敏感,并提出了面板单位根检验的Breit ung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位 根检验方法。 由上述综述可知,可以使用LLC IPS Breintung、ADF-Fisher和 PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T IPS-W、ADF-FCS PP-FCS H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、Im Pesaran & Shin W 统计量、 ADF- Fisher Chi-square统计量、PP-FisherChi-square统计量、Hadri Z 统计量,并且Levin, Lin & Chu t*统计量、Breitung t统计量的原假设 为存在普通的单位根过程,Im Pesaran & Shin W统计量、ADF- Fisher Chi-square统计量、PP -Fisher Chi-square统计量的原假设为存在有效 的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根 过程。