spss相关分析案例多因素方差分析
本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。
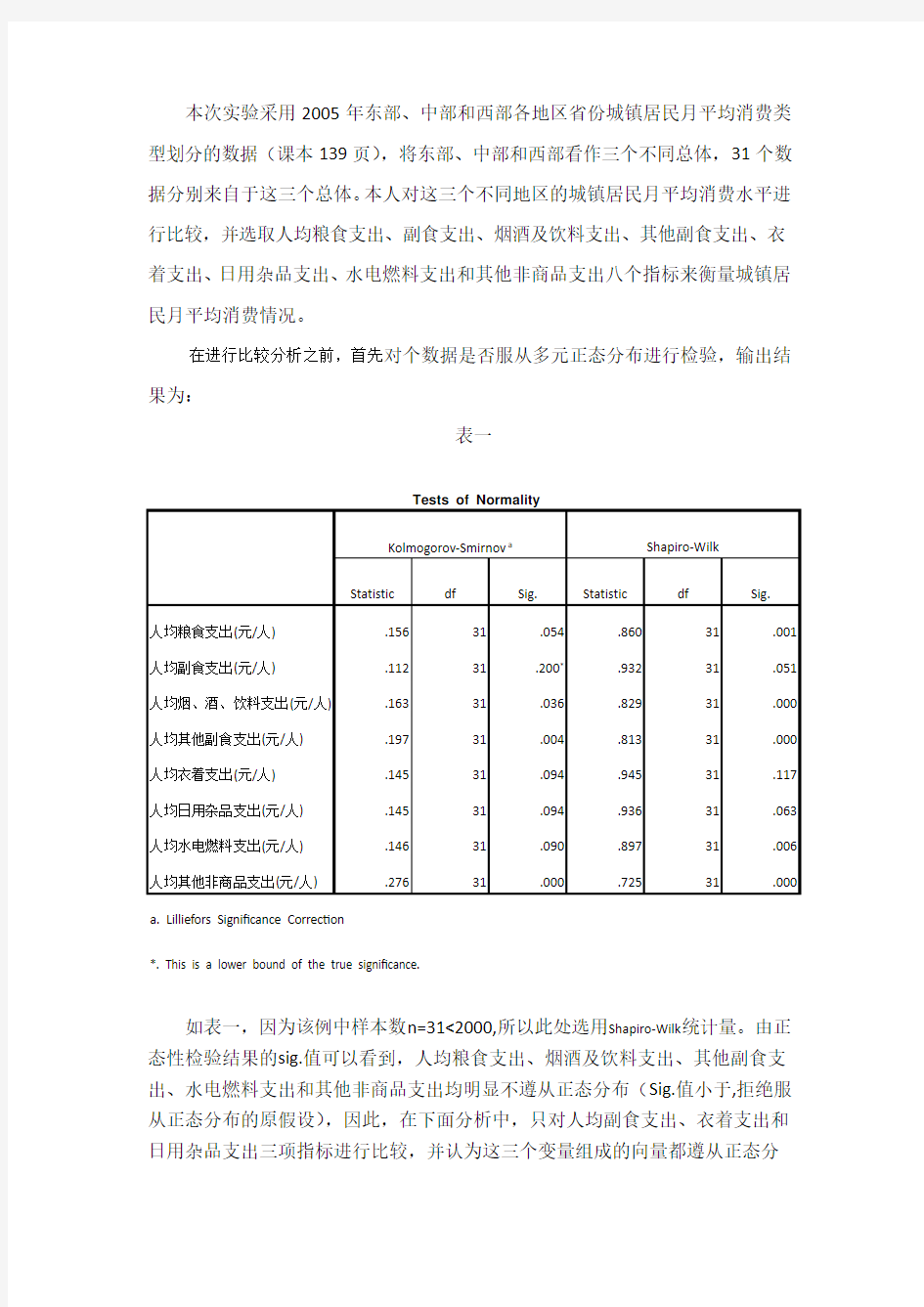
在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为:
表一
如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分
布,并对城镇居民月平均消费状况做出近似的度量。另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。具体情况这里不再赘述。
下面进行多因素方差分析:
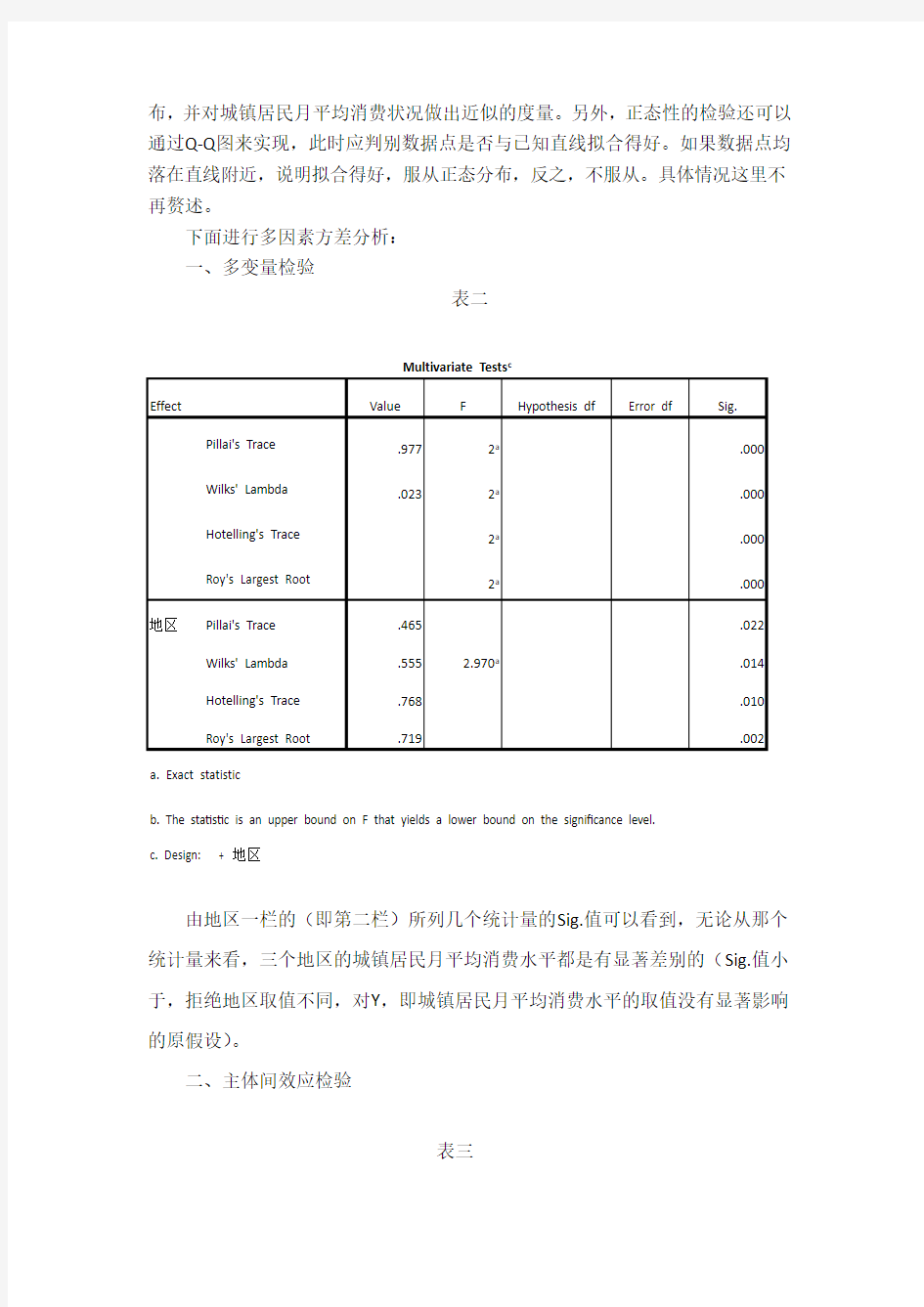
一、多变量检验
表二
由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。
二、主体间效应检验
表三
如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。
三、多重比较
表四
Contrast Results (K Matrix)
地区Simple Contrast a
Dependent Variable
人均副食支出(元/人)
人均日用杂品支出(元
/人)人均衣着支出(元/人)
Level 1 vs. Level 3Contrast Estimate
Hypothesized Value000
Difference (Estimate - Hypothesized)
Std. Error
Sig..001.036.517
95% Confidence Interval for Difference Lower
Bound
.173 Upper
Bound
Level 2 vs. Level 3Contrast Estimate
Hypothesized Value000
Difference (Estimate - Hypothesized)
Std. Error
Sig..668.343.638
95% Confidence Interval for Difference Lower Bound Upper Bound
表四Contrast Results (K Matrix)
地区Simple Contrast a
Dependent Variable
人均副食支出(元/人)
人均日用杂品支出(元
/人)人均衣着支出(元/人)
Level 1 vs. Level 3Contrast Estimate
Hypothesized Value000
Difference (Estimate - Hypothesized)
Std. Error
Sig..001.036.517
95% Confidence Interval for Difference Lower
Bound
.173 Upper
Bound
Level 2 vs. Level 3Contrast Estimate
Hypothesized Value000
Difference (Estimate - Hypothesized)
Std. Error
Sig..668.343.638
95% Confidence Interval for Difference Lower Bound Upper Bound
a. Reference category = 3
如表四,在显著水平下,东部和西部的人均副食支出(Sig.值为)和日用杂品支出(Sig.值为)指标有明显差别(小于,拒绝原假设),而在人均衣着支出(Sig.
值为)指标上没有明显的差别。并且东部的人均副食支出、衣着支出和日用杂品
支出三项指标均高于西部地区,说明东部的城镇居民月平均消费水平较西部来说,高出很多,符合实际的情况。另外,中部和西部的人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于显著水平)三个指标均无明显差别,但中部的人均副食支出和日用杂品支出指标低于西部地区,人均衣着支出指标高于西部,说明中、西部的城镇居民月平均消费水平差不多,但消费结构有差异,符合实际的情况。
表五
表五是上面多重比较可信性的度量,由Sig.的值可以看到(均小于),比较检验是可信的。
四、协方差阵相等检验
表六
Box's Test of Equality of
Covariance Matrices a
Box's M
F
df112
df2
Sig..085
Tests the null hypothesis that the
observed covariance matrices of
the dependent variables are equal
across groups.
a. Design: + 地区
如表六,是协方差阵相等检验,检验统计量是Box’s M,由Sig.值>可以看到,可以认为三个地区(总体)的协方差阵是相等的。
表七
表七给出了各地区同一指标误差的方差检验,在水平下,人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于)三个指标的误差平方在三个地区间均没有显著差别,这说明,除了地区因素外,其他因素对人均副食支出、衣着支出和日用杂品支出三个指标的影响很小。
综上所述,对三个地区的城镇居民月平均消费水平进行了具体的比较分析,所得结果表明,东部地区较中、西部地区的城镇居民月平均消费水平差别较大,远高于中、西部两个地区。而中部和西部之间的城镇居民月平均消费水平差别不太明显,主要是消费结构有所不同,这说明西部地区在国家施行西部大开发政策之后发展很快,人民生活水平显著提高,赶上中部地区,体现政策的有效性。
spss多元回归分析报告案例
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
SPSS单因素方差分析步骤
SPSS单因素方差分析步骤
spss教程:单因素方差分析 用来测试某一个控制变量的不同水平是否给观察变量造成显著差异和变动。 方差分析前提:不同水平下,各总体均值服从方差相同的正态分布。所以方差分析就是研究不同水平下各个总体的均值是否有显著的差异。统计推断方法是计算F统计量,进行F检验,总的变异平方和 SST,控制变量引起的离差SSA(Between Group离差平方和),另一部分随机变量引起的SSE(组内Within Group离差平方和),SST=SSA+SSE。方法/步骤 1.计算检验统计量的观察值和概率P_值:Spss自动计算F统计 值,如果相伴概率P小于显著性水平a,拒绝零假设,认为控制变量不同水平下各总体均值有显著差异,反之,则相反,即没有差异。
2.方差齐性检验:控制变量不同水平下各观察变量总体方差是否 相等进行分析。采用方差同质性检验方法(Homogeneity of variance),原假设“各水平下观察变量总体的方差无显著差异,思路同spss两独立样本t检验中的方差分析”。图中相伴概率 0.515大于显著性水平0.05,故认为总体方差相等。 趋势检验:趋势检验可以分析随着控制变量水平的变化,观测变量值变化的总体趋势是怎样的,线性变化,二次、三次等多项式。趋势检验可以帮助人们从另一个角度把握控制变量不同水平对观察
变量总体作用的程度。图中线性相伴概率为0小于显著性水平0.05,故不符合线性关系。
3.多重比较检验:单因素方差分析只能够判断控制变量是否对观 察变量产生了显著影响,多重比较检验可以进一步确定控制变量的不同水平对观察变量的影响程度如何,那个水平显著,哪个不显著。 常用LSD、S-N-K方法。LSD方法检测灵敏度是最高的,但也容易导致第一类错误(弃真)增大,观察图中结果,在LSD项中,报纸与广播没有显著差异,但在别的方法中,广告只与宣传有显著差异。
SPSS皮尔逊相关分析实例操作步骤
SPSS皮尔逊相关分析实例操作步骤 选题: 对某地29名13岁男童的身高(cm)、体重(kg),运用相关分析法来分析其身高与体重是否相关。 实验目的: 任何事物的存在都不是孤立的,而是相互联系、相互制约的。相关分析可对变量进行相关关系的分析,计算29名13岁男童的身高(cm)、体重(kg),以判断两个变量之间相互关系的密切程度。 实验变量: 编号Number,身高height(cm),体重weight(kg) 原始数据: 实验方法: 皮 尔 逊 相 关 分 析 法 软件: 操作过程与结果分析:
第一步:导入Excel 数据文件 1.open data document ——open data ——open ; 2. Opening excel data source ——OK. 第二步:分析身高(cm )与体重(kg )是否具有相关性 1. 在最上面菜单里面选中Analyze ——correlate ——bivariate ,首先使用Pearson ,two-tailed ,勾选flag significant correlations 进入如下界面: 2. 点击右侧options ,勾选Statistics ,默认Missing Values ,点击Continue 输出结果: 图为基本的描述性统计量的输 出表格,其中身高的均值(mean ) 为、标准差(standard deviation ) 为、样本容量(number of cases ) 为29;体重的均值为、标准差为、 样本容量为29。两者的平均值和标准差值得差距不显着。 图为相关分析结果表,从表中可以看出体重和身高之间的皮尔逊相关系数为,即 |r|=,表示体重与身高呈正相关关系,且两变量是显着相关的。另外, 两者之间不相关的双侧检验值为,图中的双星号标 记的相关系数是在显着性水平为以下,认为标记的相关系数是显着的,验证了两者显着相关的关系。所以可以得出结论:学生的体重与身高存在显着的 Descriptive Statistics Mean Std. Deviation N 身高(cm ) 29 体重(kg) 29 Correlations 身高(cm ) 体重(kg) 身高(cm ) Pearson Correlation 1 .719** Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 体重(kg) Pearson Correlation .719** 1 Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 **. Correlation is significant at the level (2-tailed).
熟练使用SPSS进行双因素方差分析
2. 统计分析。 依次选取“Analyze”、“General Linear Model”、“Univariate” 。 图2 选择分析工具 展开对话框如下图,将x选入Dependent V ariable(因变量框),g、id 选入Fixed Factors(固定因素框)。 图3 选择变量进入右侧的分析列表
对话框右边有一排按钮Mode、Contrasts 、Plots、Post Hoc、Save 和Options,下面分别对其子对话框选项作一简单介绍: Model:指定不同的模型,除方差分析外General Linear Model可作其他统计分析; Contrasts:指定一种要用t 检验来检验的priori 对比; Plots:指定作某种图; Post Hoc:指定两两比较的方法; Save:指定将产生的一些指标保存为新的变量; Options:指定要输出的一些选项,如数据的描述方差齐性检等 单击Model 展开其子对话框如下图,最上方Specify Model 定义模型,有两个选项:Full factorial(全因子)和Custom,选取Custom(自定义),Build Terms (选取模型中各项)下方有一选项,单击下拉箭头将其展开,选择Main Effects(主效应因)(本例不考虑交互作用),再将Factors 框中的g、id 选入Model:框,按Continue返回主对话框,单击Post Hoc 按钮展开其子对话框,将g 选入Post Hoc Test for,即要做两两比较的因素框,选取SNK 即q检验,返回主对话框,单击OK 键提交执行。 图4 Model对话框设置
SPSS方差分析案例实例
SPSS 第二次作业——方差分析 1、案例背景: 在一些大型考试中,为了保证结果的准确和一致性,通常针对一些主观题,都采取由多个老师共同评审的办法。在评分过程中,老师对学生的信息不可见,同时也无法看到其他评分,保证了结果的公正性。然而也有特殊情况的发生,导致了成绩的不稳定,这就使得对不同教师的评分标准考察变得十分必要。 2、案例所需资料及数据的获取方式和表述,变量的含义以及类型: 所需资料:抽样某地某次考试中不同教师对不同的题目的学生成绩的评分; 获取方式:让一组学生前后参加四次考试,由三位教师进行批改后收集数据; 变量含义、类型:一份试卷的每道主观题由三名教师进行评定,3个教师的评定结果可看成事从同一总体中抽出的3个区组,它们在四次评定的成绩是相关样本。 表1如下: 3、分析方法: 用方差分析的方法对四个总体的平均数差异进行综合性的F 检验。 4、数据的检验和预处理: a) 奇异点的剔除:经检验得无奇异点的剔除; b) 缺失值的补齐:无; c) 变量的转换(虚拟变量、变量变换):无; d) 对于所用方法的假设条件的检验:进行正态性和方差齐性的检验。 正态性,用QQ 图进行分析得下图: 教师 题目 1 2 3 a 27.3 28.5 29.1 b 29.0 29.2 28.3 c 26.5 28.2 29.3 d 29.7 25.7 27.2
得到近似满足正态性。 ?对方差齐性的检验: 用SPSS对方差齐性的分析得下表: Test of Homogeneity of Variances 分数 Levene Statistic df1 df2 Sig. .732 2 9 .508 易知P〉0.05,接受方差齐性的假设。 5、分析过程: a) 所用方法:单因素方差分析;方差分析中的多重比较。 b) 方法细节: ●单因素方差分析 第一步,提出假设: H0:μ1=μ2=μ3;(教师的评定基本合理,即均值相同) H1:μi(i=1,2,3)不全相等;(教师的评定不够合理,均值有差异)第二步,为检验H0是否成立,首先计算以下统计量:
SPSS处理多元方差分析例子
实验三多元方差分析 一、实验目的 用多元方差分析说明民族和城乡对人均收入和文化程度的影响。 二、实验要求 调查24个社区,得到民族与城乡有关数据如下表所示,其中人均收入为年 均,单位百元。文化程度指15岁以上小学毕业文化程度者所占百分比。试依此 数据通过方差分析说明民族和城乡对人均收入和文化程度的影响。 三、实验内容 1.依次点击“分析”---- “常规线性模型”----“多变量”,将“人均收入”和“文化程度” 加到“因变量”中,将“民族”和“居民”加到“固定因子”中,如下图一所示。 民族农村城市 人均收入文化程度人均收入文化程度 1 46,50,60,68 70,78,90,93 52,58,72,75 82,85,96,98 2 52,53,63,71 71,75,86,88 59,60,73,77 76,82,92,93 3 54,57,68,69 65,70,77,81 63,64,76,78 71,76,86,90
【图一】 2.点击“选项”,将“输出”中的相关选项选中,如下图二所示: 【图二】 3.点击“继续”,“确定”得到如下表一的输出:
【表一】 常规线性模型 主体间因子 值标签N 民族 1.00 1 8 2.00 2 8 3.00 3 8 居民 1.00 农村12 2.00 城市12 描述性统计量 民族居民均值标准差N 人均收入1 农村56.0000 9.93311 4 城市64.2500 11.02648 4 总计60.1250 10.66955 8 2 农村59.7500 8.99537 4 城市67.2500 9.10586 4 总计63.5000 9.28901 8 3 农村62.0000 7.61577 4 城市70.2500 7.84750 4 总计66.1250 8.40812 8 总计农村59.2500 8.45442 12 城市67.2500 8.89458 12 总计63.2500 9.41899 24 文化程度1 农村82.7500 10.68878 4 城市90.2500 7.93200 4 总计86.5000 9.59166 8
SPSS线性回归分析案例
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: (
2010年中国各地区城市居民人均年消费支出和可支配收入
} 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
SPSS 重复测量的多因素方差分析
1、概述 重复测量数据的方差分析是对同一因变量进行重复测量的一种试验设计技术。在给予一种或多种处理后,分别在不同的时间点上通过重复测量同一个受试对象获得的指标的观察值,或者是通过重复测量同一个个体的不同部位(或组织)获得的指标的观察值。重复测量数据在科学研究中十分常见。 分析前要对重复测量数据之间是否存在相关性进行球形检验。如果该检验结果为P﹥0.05,则说明重复测量数据之间不存在相关性,测量数据符合Huynh-Feldt条件,可以用单因素方差分析的方法来处理;如果检验结果P﹤0.05,则说明重复测量数据之间是存在相关性的,所以不能用单因素方差分析的方法处理数据。在科研实际中的重复测量设计资料后者较多,应该使用重复测量设计的方差分析模型。 球形条件不满足时常有两种方法可供选择:(1)采用MANOVA(多变量方差分析方法);(2)对重复测量ANOVA检验结果中与时间有关的F值的自由度进行调整。 2、问题 新生儿胎粪吸入综合征(MAS)是由于胎儿在子宫内或着生产时吸入了混有胎粪的羊水,从而导致呼吸道和肺泡发生机械性阻塞,并伴有肺泡表面活性物质失活,而且肺组织也会发生化学性炎症,胎儿出生后出现的以呼吸窘迫为主,同时伴有其他脏器受损现象的一组综合征。血管内皮生长因子(vascular endothelial growth factor,VEGF)是一种有丝分裂原,它特异作用于血管内皮细胞时,能够调节血管内皮细胞的增殖和迁移,从而使血管通透性增加。而本实验旨在通过观察分析给予外源性肺表面活性物质治疗前后胎粪吸入综合征患儿血清中VEGF的含量变化,评价药物治疗的效果。 将收治的诊断胎粪吸入综合症的新生儿共42名。将患儿随机分为肺表面活性物质治疗组(PS组)和常规治疗组(对照组),每组各21例。PS组和对照组两组所有患儿均给予除用药外的其他相应的对症治疗。PS组患儿给予牛肺表面活性剂PS 70mg/kg治疗。采集PS 组及对照组患儿0小时,治疗后24小时和72小时静脉血2ml,离心并提取上清液后保存备用并记录血清中VEGF的含量变化情况。 结果如下: 3、统计分析
(整理)SPSS 方差分析过程.
One-Way ANOVA过程 One-Way ANOVA过程用于进行两组及多组样本均数的比较,即成组设计的方差分析,如果做了相应选择,还可进行随后的两两比较,甚至于在各组间精确设定哪几组和哪几组进行比较。 界面说明 【Dependent List框】 选入需要分析的变量,可选入多个结果变量(应变量)。 【Factor框】 选入需要比较的分组因素,只能选入一个。 【Contrast钮】 弹出Contrast对话框,用于对精细趋势检验和精确两两比较的选项进行定义。 o Polynomial复选框定义是否在方差分析中进行趋势检验。 o Degree下拉列表和Polynomial复选框配合使用,可选则从线
性趋势一直到最高五次方曲线来进行检验。 o Coefficients框定义精确两两比较的选项。这里按照分组变量升序给每组一个系数值,注意最终所有系数值相加应为0。如果不为0仍可检验,只不过结果是错的。比如有三组数据,要对第 一、三组进行单独比较,则在这里给三组分配系数为1、0、-1, 就会在结果中给出相应的检验内容。 【Post Hoc钮】 弹出Post Hoc Multiple Comparisons对话框,用于选择进行各组间两两比较的方法,有: o Equar Variances Assumed复选框组当各组方差齐时可用的两两比较方法,共有14中种这里不一一列出了,其中最常用的为LSD和S-N-K法。 o Equar Variances Not Assumed复选框组一组当各组方差不齐时可用的两两比较方法,共有4种,其中以Dunnetts's C法较常用。
典型相关分析报告SPSS例析
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关, 而不是 两个变量组个别变量之间的相关。 典型相关与主成分相关有类似, 不过主成分考虑的是一组变量,而典型相关考虑的是两 组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的 成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设: 两组变量间是线性关系, 每对典型变量之间是线性关系,每 个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共 线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因 变量。 典型相关会找出一组变量的线性组合 * *= i i j j X a x Y b y 与,称为典型变量;以 使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。 i a 和j b 称为典型系数。如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关; 原来所有 变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变 量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关, 共同代表 两组变量间的整体相关。 典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数, 指的是一个典型变量与本组所有变量的简单相关系数,
用SPSS进行单因素方差分析和多重比较
方差分析 方差分析可以用来检验来多个均值之间差异的显著性,可以看成是两样本t检验的扩展。统计学原理中涉及的方差分析主要包括单因素方差分析、两因素无交互作用的方差分析和两因素有交互作用的方差分析三种情况。虽然Excel可以进行这三种类型的方差分析,但对数据有一些限制条件,例如不能有缺失值,在两因素方差分析中各个处理要有相等的重复次数等;功能上也有一些不足,例如不能进行多重比较。而在方差分析方面SPSS的功能特别强大,很多输出结果已经超出了统计学原理的范围。 用SPSS检验数据分布的正态性 方差分析需要以下三个假设条件:(1)、在各个总体中因变量都服从正态分布;(2)、在各个总体中因变量的方差都相等;(3)、各个观测值之间是相互独立的。 在SPSS中我们很方便地对前两个条件进行假设检验。同方差性检验一般与方差分析一起进行,这一小节我们只讨论正态性的检验问题。 [例7.4] 检验生兴趣对考试成绩的影响的例子中各组数据的正态性。 在SPSS中输入数据(或打开数据文件),选择Analyze→Descriptive Statistics→Explore,在Explore对话框中将统计成绩作为因变量,兴趣作为分类变量(Fator),单击Plots按钮,选中“Histogram”复选框和“Normality plots with Test”,单击“Continue”按钮,在单击主对话框中的“OK”,可以得到分类别的描述统计信息。从数据的茎叶图、直方图和箱线图都可以对数据分布的正态性做出判断,由于这些内容前面已经做过讲解,这里就不再进一步说明了。 图7-2 用Expore过程进行正态性检验 top↑
多元方差分析spss实例
多元方差分析 1992年美国总统选举的三位候选人为布什、佩罗特、克林顿。从支持三位候选人的选民中分别 分析:该题自变量为三位候选人,因变量为年龄段和受教育程度。从自变量来看要进行方差分析,从因变量来看是二元分析,所以最终确定使用多变量分析 具体操作(spss) 1、打开spss,录入数据,定义变量和相应的值在此不作详述。结果如图1
图1 被投票人:1、布什2、佩罗特3、克林顿 2、在spss窗口中选择分析——一般线性模型——多变量,调出多变量分析主界面,将年龄段和受 教育程度移入因变量框中,被投票人移入固定因子框中。如图2 图2 多变量分析主界面 3、点击选项按钮在输出框中选择方差齐性分析(既包括协方差矩阵等同性分析也包括误差方差齐 性分析),其它使用默认即可,点击继续返回主界面。如图3
图3 选项子对话框 4、点击确定,运行多变量分析过程。 结果解释 1、协方差矩阵等同性的Box检验结果,如图4 图4 协方差矩阵检验 结果说明:此Box检验的协方差矩阵为三位候选人每个人的支持者的年龄段和受教育程度的协方差矩阵。因为sig>0.05,所以差异不显著,即各个因变量的协方差矩阵在所有三个候选人组中是相等的。可以对其进行多元方差分析。 2、多变量检验结果,如图5
图5 多变量检验 结果说明:被投票人在四种统计方法中的sig均小于0.05,所以差异显著,即三组的总体均值有显著性差异 3、误差方差等同性的Levene检验结果,如图6 图6 Levene检验 结果说明:只考虑单个变量,年龄段或者受教育程度,每位候选人的20名支持者的随机误差是否有显著性差异。因为sig>0.05,差异不显著,所以三位候选人的20名支持者的随机误差相等。 可以进行单因素方差分析。 4、主体间效应的检验结果,如图7 图7 主体间效应的检验 结果说明:被投票人一行中,年龄段的sig<0.05,差异显著,即支持三位候选人的选民中,年龄段之间存在显著差异;而受教育程度的sig>0.05,差异不显著,即支持三位候选人的选民中,受教育程度差异不显著。
SPSS相关分析案例讲解
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 多因素方差分析 多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同水平组合之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作用,以及分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差相同。但也可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量,可以是数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因素。 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。 表5-7 不同温度与不同湿度粘虫发育历期表 数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。 1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输入对应的数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因变量多因素方差分析设置窗口如图5-7。 图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。 设置因素变量:在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量。由于内存容量的限制,选择的因素水平组合数(单元数)应该尽量少。 SPSS- 单因素方差分析( ANOVA) - 案例解 析 SPSS单因素方差分析(ANOVA)案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近习SPSS单因素方差分析(ANOVA分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠b代表雌性老鼠0代表死亡1代表着tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”一一比较均值-------- 单因素AVOVA,如下所示: 从上图可以看出,只有“两个变量”可选,对于“组别(性别)”变量不可选, 进行“转换”对数据重新进行编码, 点击“转换”一“重新编码为不同变量”将a,b"分别用8,9进行替换,得到如下结果”这里可能需 此时的8代表a(雄性老鼠)9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示: “勾选“将定方差齐性”下面的项 点击继续 LSD选项,和“未假定方差齐性”下面的Tamhane's T2 选点击“选项”按钮,如下所示: I固疋和随枫效果(号 IN有建同備性檯验迥) 匚旦rown-Forsythe(B) El Welches} 姑朱値 ?按分析顺序排麒个案? 「I I S3 Affifi 勾选“描述性”和“方差同质检验”以及均值图等选项,得到如下结果: SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费 作业8:多因素方差分析 1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的? 打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate 打开: 把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model 打开: 选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择, 结果输出: 因无法计算MM e rror,即无法分开MM intercept和MM error,无法检测interaction的影响,无法进行方差分析, 重新Analyze->General Linear Model->Univariate打开: 选择好Dependent Variable和Fixed Factor(s),点击Model打开: 点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate主对话框,点击Plots: Univariate对话框,点击Options: 把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框, 输出结果: 可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534; Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01; 所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。 第五节方差分析的SPSS操作 一、完全随机设计的单因素方差分析 1.数据 采用本章第二节所用的例1中的数据,在数据中定义一个group变量来表示五个不同的组,变量math表示学生的数学成绩。数据输入格式如图6-3(为了节省空间,只显示部分数据的输入): 图 6-3 单因素方差分析数据输入 将上述数据文件保存为“6-6-1.sav”。 2.理论分析 要比较不同组学生成绩平均值之间是否存在显著性差异,从上面数据来看,总共分了5个组,也就是说要解决比较多个组(两组以上)的平均数是否有显著的问题。从要分析的数据来看,不同组学生成绩之间可看作相互独立,学生的成绩可以假设从总体上服从正态分布,在各组方差满足齐性的条件下,可以用单因素的方差分析来解决这一问题。单因素方差分析不仅可以检验多组均值之间是否存在差异,同时还可进一步采取多种方法进行多重比较,发现存在差异的究竟是哪些均值。 3.单因素方差分析过程 (1)主效应的检验 假如我们现在想检验五组被试的数学成绩(math)的均值差异是否显著性,可依下列操作进行。 ①单击主菜单Analyze/Compare Means/One-Way Anova…,进入主对话框,请把math选入到因变量表列(Dependent list)中去,把group选入到因素(factor)中去,如图6-4所示: 图6-4:One-Way Anova主对话框 ②对于方差分析,要求数据服从正态分布和不同组数据方差齐性,对于正态性的假设在后面非参数检验一章再具体介绍;One-Way Anova可以对数据进行方差齐性的检验,单击铵钮Options,进入它的主对话框,在Homogeneity-of-variance项上选中即可。设置如下图6-5所示: 图6-5:One-Way Anova的Options对话框 点击Continue,返回主对话框。 ③在主对话框中点击OK,得到单因素方差分析结果 4.结果及解释 (1)输出方差齐性检验结果 Test of Homogeneity of Variances MATH Levene Statistic df1 df2 Sig. 1.238 4 35 .313 上表结果显示,Levene方差齐性检验统计量的值为1.238,Sig=0.313>0.05,所以五个组的方差满足方差齐性的前提条件,如果不满足方差齐性的前提条件,后面方差分析计算F统计量的方法要稍微复杂,本章我们只考虑方差齐性条件满足的情况。 (2)输出方差分析主效应检验结果(方差分析表) 本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。 在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为: 表一 如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分布,并对城镇居民月平均消费状况做出近似的度量。另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。具体情况这里 不再赘述。 下面进行多因素方差分析: 一、多变量检验 表二 由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。 二、主体间效应检验 如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。 三、多重比较 SPSS-单因素方差分析(ANOVA) 案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近学习SPSS单因素方差分析(ANOVA)分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察老鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠 b代表雌性老鼠 0代表死亡 1 代表活着 tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”——比较均值———单因素AVOVA, 如下所示: 从上图可以看出,只有“两个变量”可选, 对于“组别(性别)”变量不可选,这里可能需要进行“转换”对数据重新进行编码, 点击“转换”—“重新编码为不同变量” 将a,b"分别用8,9进行替换,得到如下结果” 此时的8 代表a(雄性老鼠) 9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表”框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示: “ 勾选“将定方差齐性”下面的 LSD 选项,和“未假定方差齐性”下面的Tamhane's T2选项点击继续 点击“选项”按钮,如下所示: 勾选“描述性”和“方差同质检验” 以及均值图等选项,得到如下结果: 结果分析:方差齐性检验结果,“显著性”为0,由于显著性0<0.05 所以,方差齐性不相等,在一般情况下,不能够进行方差分析 但是对于SPSS来说,即使方差齐性不相等,还是可以进行方差分析的, 由于此样本组少于三组,不能够进行多重样本对比 从结果来看“单因素ANOVA” 分析结果,显著性0.098,由于 0.098>0.05 所以可以得出结论: 生存结局受性别的影响不显著 很多人,对这个结果可能存在疑虑,下面我们来进一步进行论证,由于“方差齐性不相等”下面我们来进行“非参数检验”检验结果如下所示:(此处采用的是“Kruskal-Wallis "检验方法) 本科教学实验报告 (实验)课程名称:数据分析技术系列实验 实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。 1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1.分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze\DescriptiveStatistics\Crosstabs Step2.将性别(Gender)和收入(CurrentSalary)分别移入Rows列表框和Columns 列表框。 Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。 2.分析教育程度与工资之间是否存在相关关系。 分析:教育程度为定序变量,工资为连续变量,可使用Spearman和Kendall秩相关系数检验。 Step1.用散点图初步判断二变量的相关性,操作为Graphs/LegacyDialogs/Scatter,选择SimpleScatter,教育程度为自变量,工资为因变量,做散点图。 散点图结果如图示,二者存在线性相关关系。只有线性相关的关系确定后才能继续进行下一步分析。因此,在进行相关分析之前的预分析过程也是十分重要的。 Step2.两变量相关分析,操作为Analyze/Correlate/Bivariate,选择Kendall和Spearman 相关系数。 六、实验器材(设备、元器件): 计算机、打印机、硒鼓、碳粉、纸张 七、实验数据及结果分析 1.分析性别与工资之间是否存在相关关系。 卡方检验结果为 显着性水平为,即至少有%的把握认为性别和工资之间存在显着的相关系。SPSS教程-多因素方差分析
SPSS-单因素方差分析(ANOVA)-案例解析资料讲解
SPSS统计分析分析案例
spss 多因素方差分析例子
spss方差分析操作示范-步骤-例子
spss相关分析案例多因素方差分析
SPSS-单因素方差分析(ANOVA) 案例解析
SPSS相关分析实验报告精选