VS2013_C#64程序编译
C#编译为64位程序
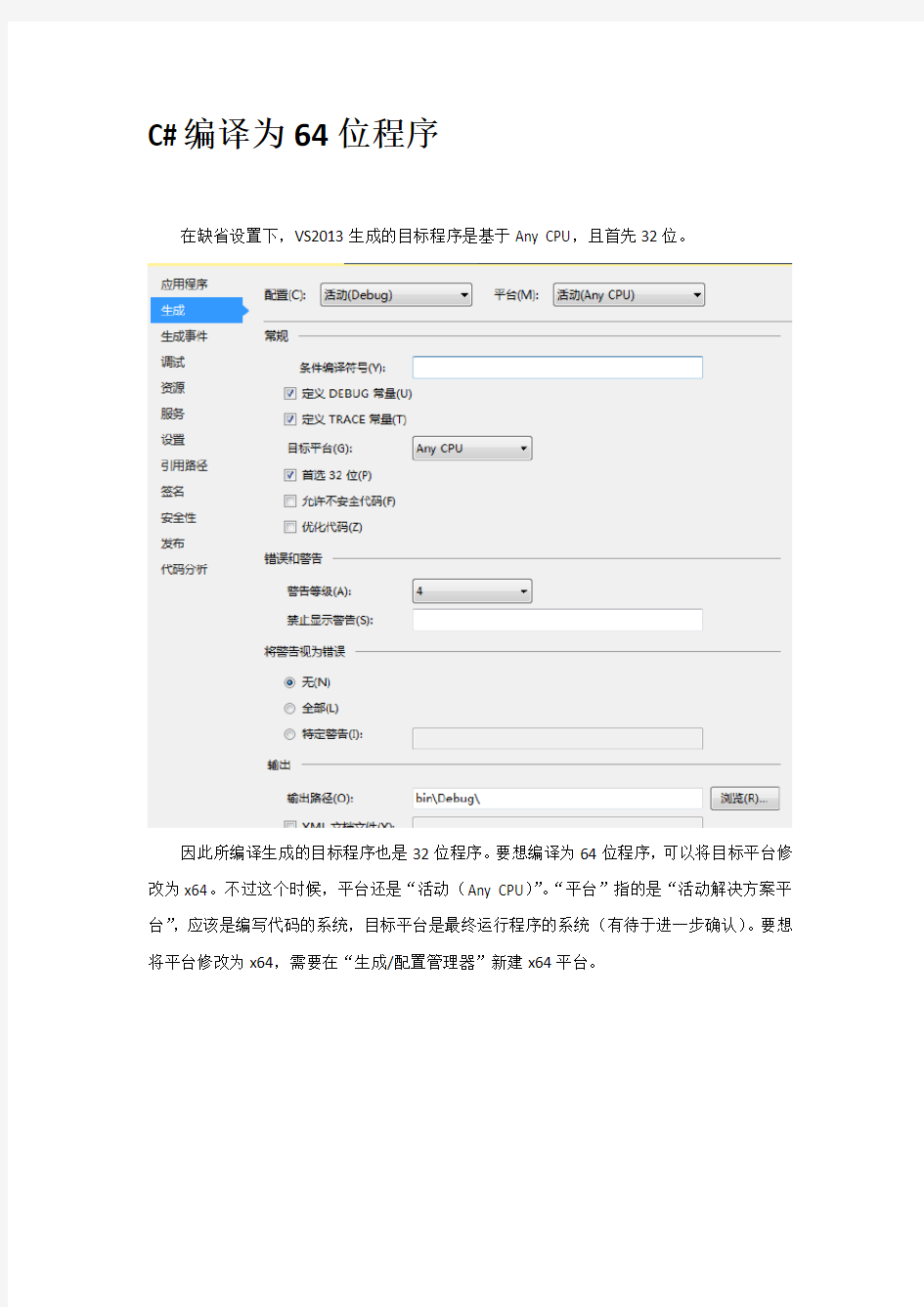
在缺省设置下,VS2013生成的目标程序是基于Any CPU,且首先32位。
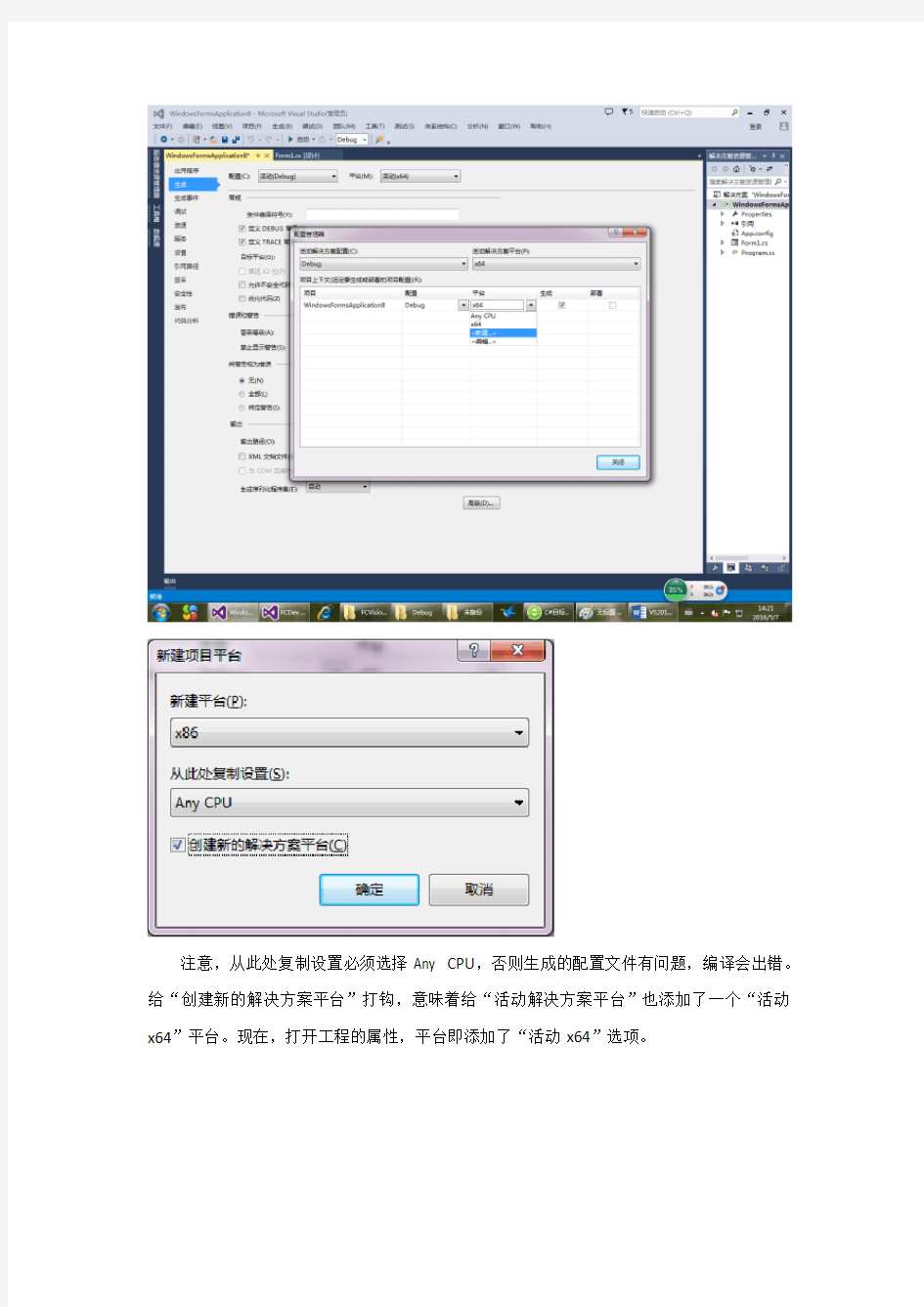
因此所编译生成的目标程序也是32位程序。要想编译为64位程序,可以将目标平台修改为x64。不过这个时候,平台还是“活动(Any CPU)”。“平台”指的是“活动解决方案平台”,应该是编写代码的系统,目标平台是最终运行程序的系统(有待于进一步确认)。要想将平台修改为x64,需要在“生成/配置管理器”新建x64平台。
注意,从此处复制设置必须选择Any CPU,否则生成的配置文件有问题,编译会出错。给“创建新的解决方案平台”打钩,意味着给“活动解决方案平台”也添加了一个“活动x64”平台。现在,打开工程的属性,平台即添加了“活动x64”选项。
同一个软件有多个程序或DLL的问题
由于系统调用栈结构的原因,同一个软件中的程序或DLL只能调用与其相同目标平台的DLL,不能交叉调用。以C#程序为例,如果一个程序使用了一个用户控件在DLL中,我们在开发过程中将目标平台修改为x64,在开发环境中,使用用户控件的窗口就无法打开了,显示用户控件未声明或未赋值。
C#程序属于解释执行的程序,在开发过程中,VS2013会根据用户的操作解释执行相关代码,用户控件和执行程序的平台不同,导致于解释执行失败。要想避免上面的问题,最好是把主程序和用户控件都配置为Any CPU。但是有时我们需要调用VC动态库,如果VC动态库是64为的话,C#程序必须配置为64位才可以运行。比较复杂的情况是,用户控件DLL 调用64位的VC动态库。针对这种情况,我们有个成熟的方案:C#主程序的“平台”配置为“活动x64”,“目标平台”配置为“x64”,用户控件的平台配置为“活动x64”,目标平台配置为Any CPU。
基于C#的解释执行特征,在用户控件的构造函数和初始化函数中,尽量避免编写调用VC动态库或COM的代码,否则的话,在VS2013中打开窗口时,可能会由于平台问题,造成解释执行失败,进而导致打不开窗口。
对平台的修改最好在“配置管理器”中修改,在属性中修改有时不起作用。
如果程序引用了某个DLL,在打开界面设计器的时候VS2013会加载此DLL,如果此DLL 不在相关的目录下,设计器也不能打开。VS2013一般从输出路径中加载DLL,然而,有时输出路径和目标程序的实际输出路径却不在同一个路径里,比如输出路径是“bin\x64\Debug”,而编译后,目标程序却放在“bin\Debug”中了,在这种情况下,我们需要在“bin\x64\Debug”
中拷贝一份DLL,否则VS2013就因为无法加载相关DLL而不能打开界面设计器。
编译实验报告+源代码
课程设计报告 ( 2013-- 2014年度第1学期) 名称:编译技术课程设计B 题目:简单编译程序的设计与实现院系:计算机系 班级:XXX 学号:XXX 学生姓名:XXX 指导教师:XXX 设计周数:XXX 成绩: 日期:XX 年XX 月
实验一.词法分析器的设计与实现 一、课程设计(综合实验)的目的与要求 1.1 词法分析器设计的实验目的 本实验是为计算机科学与技术专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。通过这个实验,使学生应用编译程序设计的原理和技术设计出词法分析器,了解扫描器的组成结构,不同种类单词的识别方法。能使得学生在设计和调试编译程序的能力方面有所提高。为将来设计、分析编译程序打下良好的基础。 1.2 词法分析器设计的实验要求 设计一个扫描器,该扫描器是一个子程序,其输入是源程序字符串,每调用一次识别并输出一个单词符号。为了避免超前搜索,提高运行效率,简化扫描器的设计,假设该程序设计语言中,基本字(也称关键词)不能做一般标识符用,如果基本字、标识符和常数之间没有确定的运算符或界符作间隔,则用空白作间隔。 单词符号及其内部表示如表1-1所示,单词符号中标识符由一个字母后跟多个字母、数字组成,常数由多个十进制数字组成。单词符号的内部表示,即单词的输出形式为二元式:(种别编码,单词的属性值)。 表1-1 单词符号及其内部表示
二、设计(实验)正文 1.词法分析器流程图 2.词法分析器设计程序代码 // first.cpp : 定义控制台应用程序的入口点。// #include"stdafx.h" #include
C语言编译过程中的错误分析
C语言编译过程中的错误分析 语言的最大特点是:功能强、使用方便灵活。C编译的程序对语法检查并不象其它高级语言那么严格,这就给编程人员留下“灵活的余地”,但还是由于这个灵活给程序的调试带来了许多不便,尤其对初学C语言的人来说,经常会出一些连自己都不知道错在哪里的错误。看着有错的程序,不知该如何改起,本人通过对C的学习,积累了一些C编程时常犯的错误,写给各位学员以供参考。 1.书写标识符时,忽略了大小写字母的区别。 main() { int a=5; printf("%d",A); } 编译程序把a和A认为是两个不同的变量名,而显示出错信息。C认为大写字母和小写字母是两个不同的字符。习惯上,符号常量名用大写,变量名用小写表示,以增加可读性。 2.忽略了变量的类型,进行了不合法的运算。 main() { float a,b; printf("%d",a%b); } %是求余运算,得到a/b的整余数。整型变量a和b可以进行求余运算,而实型变量则不允许进行“求余”运算。 3.将字符常量与字符串常量混淆。 char c; c="a"; 在这里就混淆了字符常量与字符串常量,字符常量是由一对单引号括起来的单个字符,字符串常量是一对双引号括起来的字符序列。C规定以“”作字符串结束标志,它是由系统自动加上的,所以字符串“a”实际上包含两个字符:‘a'和‘',而把它赋给一个字符变量是不行的。 4.忽略了“=”与“==”的区别。 在许多高级语言中,用“=”符号作为关系运算符“等于”。如在BASIC程序中可以写 if (a=3) then … 但C语言中,“=”是赋值运算符,“==”是关系运算符。如: if (a==3) a=b; 前者是进行比较,a是否和3相等,后者表示如果a和3相等,把b值赋给a。由于习惯问题,初学者往往会犯这样的错误。 5.忘记加分号。 分号是C语句中不可缺少的一部分,语句末尾必须有分号。 a=1 b=2 编译时,编译程序在“a=1”后面没发现分号,就把下一行“b=2”也作为上一行语句的一部分,这就会出现语法错误。改错时,有时在被指出有错的一行中未发
编译原理(PL0编译程序源代码)
/*PL/0编译程序(C语言版) *编译和运行环境: *Visual C++6.0 *WinXP/7 *使用方法: *运行后输入PL/0源程序文件名 *回答是否将虚拟机代码写入文件 *回答是否将符号表写入文件 *执行成功会产生四个文件(词法分析结果.txt符号表.txt虚拟代码.txt源程序和地址.txt) */ #include
linux实验报告3 Linux上C程序编译,调试和工程文件管理
深圳大学实验报告 课程名称:Linux操作系统 实验项目名称:Linux上C程序编译,调试和工程文件管理学院:计算机与软件学院 专业:软件工程 指导教师:冯禹洪 报告人:文成学号:2011150259 班级:02 实验时间:2013/12/31 实验报告提交时间:2013/12/31 教务处制
一、实验目标: 熟悉Linux上C程序设计环境,包括以下内容: 1. 联机帮助man命令 2. 编译工具gcc的使用 3. 熟悉使用gdb来调试程序 4. 熟悉C工程文件的管理工具makefile 二、实验环境与工件 湖边Linux实验室 Fedora 13 三、实验内容与步骤 1.动态库函数可以在多个应用程序之间共享,可以减少应用程序文件的容量和 应用程序的装载时间。因此,熟悉构建动态库可以提高软件的编写质量。请跟随以下步骤构建动态库message,并用其编写程序、编译和运行。(40分) 1.1编写源程序message.c(见图1)和main.c(见图2) 图1. message.c源程序 图2.main.c源程序 1.2用以下命令对message.c进行编译,其中,“-fPIC”选项是告诉gcc产生的 代码不要包含对函数和变量具体内存位置的引用。
1.3以上命令将获得目标文件message.o,使用以下命令建立共享函数库 message: 1.4使用1.3获得的共享函数库来编译main.c文件 1.5设置共享函数库搜索路径 1.6运行程序并附上结果 1.7构建静态可执行程序 1.7.1$gcc –c message.c 1.7.2$ar –crv libmsg.a message.o 1.7.3$gcc –o main main.c –L./ -lmsg 1.7.4$./main 1.8运行以下两个命令并截图说明结果: $ldd goodbye $ldd main $ls –l goodbye main /*附加题:经观察,如果用ubuntu, main 和googbye的大小在一些发行版本下没有区别,如果实验如此,请尝试解释这一现象。附加题目,平时成绩+5分,超过40分不算。*/ 2.图3-4中的reverse程序是有bug的,请使用gdb去观察程序的行为,对关键 行为截图说明,定位错误(截图说明)并修正程序bug。附上修正的程序及其运行结果。(40分) 图3. reverse.h头文件
VC++6.0中如何编译运行及调试C语言程序
VC++6.0中如何编译运行调试C语言程序1.启动VC++6.0 (如下图) 2.单个源文件的编译运行 例如下面的源代码 #include
打开VC++6.0,如图1所示 (图1)选择“文件”→“新建”,打开如图2所示 (图2)
选择“文件”项,如图3所示 (图3) 选择“C++ Source File”项,并在“文件名”项目下输入“sum.c”如图4所示 (图4)
单击“确定”,打开如图5所示 (图5) 输入如上源代码,如图6所示 (图6) 选择按编译按钮调试程序,看看有没有错误,有的话改正,没有的话就可以再按连接按钮检查连接(多文件工程时常用,检查文件间是否正常连接)。
(图7) 在下端的输出窗口会有错误和警告的提示,如果没有错误选择“执行”(或按Ctrl+F5组合键)即可出现运行结果,如图8所示 (图8)
3.多个源文件的编译运行 以上是运行单个源文件的情况,但是在程序设计时,往往是由几个人各自独立编写不同的程序,显然这些程序是不能写在一起进行编译的,这时就需要建立项目工作区来完成几个独立程序的编译,具体方法如下。 首先建立两个文本文件,分别命名为“file1.c”和“file.c”,分别在两个文件中输入如下两个源代码,然后保存。 源代码1: #include
C语言编程要点程序的编写和编译
C语言编程要点程序的 编写和编译 Document serial number【LGGKGB-LGG98YT-LGGT8CB-LGUT-
C语言编程要点---第18章程序的编写和编译 第18章程序的编写和编译 本章讲述在编译程序时可以使用的一些技术。在本章中,你将学到专业C程序员在日常编程中所使用的一些技巧。你将会发现,无论是对小项目还是大项目,把源代码分解成几个文件都是很有益处的。在生成函数库时,这一点更为重要。你还将学到可以使用的各种存储模式以及怎样为不同的项目选择不同的存储模式。如果你的程序是由几个源文件组成的,那么你可以通过一个叫MAKE的工具来管理你的项目(project)。你还将学到“.COM"文件和".EXE"文件的区别以及使用“.COM”文件的一个好处。 此外,你还将学到用来解决一个典型的DOS问题的一些技巧,这个问题就是“没有足够的内存来运行DOS程序”。本章还讨论了扩展内存、扩充内存、磁盘交换区、覆盖管理程序和DOS扩展程序的用法,提出了解决"RAM阻塞”这一问题的多种方法,你可以从中选择一种最合适的方法 . 程序是应该写成一个源文件还是多个源文件? 如果你的程序确实很小又很紧凑,那么当然应该把所有的源代码写在一个“.C”文件中。然而,如果你发现自己编写了许多函数(特别是通用函数),那么你就应该把程序分解成几个源文件(也叫做模块)。 把一个程序分解成几个源文件的过程叫做模块化程序设计(modular programming)。模块化程序设计技术提倡用几个不同的结构紧凑的模块一起组成一个完整的程序。例如,如果一个程序中有几种实用函数、屏幕函数和数据库函数,你就可以把这些函数分别放在三个源文件中,分别组成实用模块、屏幕模块和数据库模块。 把函数放在不同的文件中后,你就可以很方便地在其它程序中重复使用那些通用函数。如果你有一些函数还要供其它程序员使用,那么你可以生成一个与别人共享的函数库(见18.9)。 你永远不必担心模块数目“太多”——只要你认为合适,你可以生成很多个模块。一条好的原则就是保持模块的紧凑性.即在同一个源文件中只包含那些在逻辑上与其相关的函数。如果你发现自己把几个没有关系的函数放在了同一个源文件中,那么最好停下来检查一下程序的源代码结构,并且对模块做一下逻辑上的分解。例如,如果要建立一个通信管理数据库,你可能需要有这样一个模块结构: --------------------------------------------------------- 模块名内容 --------------------------------------------------------- Main.c maln()函数 Screen.c 屏幕管理函数 Menus.c 菜单管理函数 Database.c 数据库管理函数 Utility.c 通用功能函数 Contact.c 通信处理函数 Import.c 记录输入函数 Export.c 记录输出函数 Help.c 联机帮助支持函数 ---------------------------------------------------------- 请参见: 18.10 如果一个程序包含多个源文件,怎样使它们都能正常工作? . 各种存储模式之间有什么区别? DOS用一种段地址结构来编址计算机的内存,每一个物理内存位置都有一个可通过段地址一偏移量的方式来访问的相关地址。为了支持这种段地址结构,大多数C编译程序都允许你用以下6种存储模式来创建程序: ----------------------------------------------------------------------- 存储模式限制所用指针 ----------------------------------------------------------------------- Tiny(微) 代码、数据和栈一64KB Near
TurboC程序设计的基本步骤及如何编译、调试和运行源程序
Turbo C程序设计的基本步骤及如何编译、调试和运行源程序 本节主要介绍Turbo C程序设计的基本步骤及如何编译、调试和运行源程序。并给出Turbo C的常用编辑命令。最后介绍Turbo C编译、连接和运行时的常见错误。 一、Turbo C程序设计基本步骤 程序设计方法包括三个基本步骤: 第一步:分析问题。 第二步:画出程序的基本轮廓。 第三步:实现该程序。 3a.编写程序 3b.测试和调试程序 3c.提供数据打印结果 下面,我们来说明每一步的具体细节。 第一步:分析问题 在这一步,你必须: a. 作为解决问题的一种方法,确定要产生的数据(输出)。作为这一子步的一部分你应定义表示输出的变量。 b. 确定需产生输出的数据(称为输入),作为这一子步的一部分,你应定义表示输入的变量。 c. 研制一种算法,从有限步的输入中获取输出。这种算法定义为结构化的顺序操作,以便在有限步解决问题。就数字问题而言,这种算法包括获取输出的计 Word文档资料
算,但对非数字问题来说,这种算法包括许多文本和图象处理操作。 第二步:画出程序的基本轮廓 在这一步,你要用一些句子(伪代码)来画出程序的基本轮廓。每个句子对应一个简单的程序操作。对一个简单的程序来说,通过列出程序顺序执行的动作,便可直接产生伪代码。然而,对复杂一些的程序来说,则需要将大致过程有条理地进行组织。对此,应使用自上而下的设计方法。 当使用自上而下的设计方法时,你要把程序分割成几段来完成。列出每段要实现的任务,程序的轮廓也就有了,这称之为主模块。当一项任务列在主模块时,仅用其名加以标识,并未指出该任务将如何完成。这方面的容留给程序设计的下一阶段来讨论。将程序分为几项任务只是对程序的初步设计。整个程序设计归结为下图所示的流程图1. 0 1 1主模块 1 I 1 1 I 输入数据I 1主模块I I计算购房所需的金额I 1 I I计算装修所需的金额I 1任务1I I计算总金额I 1任务2I I输出计算结果I 1任务3I I I 1任务4I 1 ---------------- 1 -------------------- 1 I I I——1II——1II——1II1II——1I 1 ---------------------- 1 I输入数据II购房额?? II装修额..I I总额..I I输出 Word文档资料
编译原理C语言词法分析器
编译原理 C语言词法分析器 一、实验题目 编制并调试C词法分析程序。 a.txt源代码: ?main() { int sum=0 ,it=1;/* Variable declaration*/ if (sum==1) it++; else it=it+2; }? 设计其词法分析程序,能识别出所有的关键字、标识符、常数、运算符(包括复合运算符,如++)、界符;能过滤掉源程序中的注释、空格、制表符、换行符;并且能够对一些词法规则的错误进行必要的处理,如:标识符只能由字母、数字和下划线组成,且第一个字符必须为字母或下划线。实验要求:要给出所分析语言的词法说明,相应的状态转换图,单词的种别编码方案,词法分析程序的主要算法思想等。 二、实验目的 1、理解词法分析在编译程序中的作用; 2、掌握词法分析程序的实现方法和技术; 3、加深对有穷自动机模型的理解。 三、主要函数 四、设计 1. 主函数 void main ( )
2. 初始化函数 void load ( ) 3. 保留字及标识符判断函数 void char_search(char *word) 4. 整数类型判断函数 void inta_search(char *word) 5. 浮点类型判断函数 void intb_search(char *word)
6. 字符串常量判断函数 void cc_search(char *word) 7. 字符常量判断函数 void c_search(char *word) 同4、5函数图 8.主扫描函数 void scan ( ) 五、关键代码 #include <> #include <> #include <> char *key0[]={"
(完整word版)PL0源代码(C语言版)
/*PL/0 编译系统C版本头文件pl0.h*/ # define norw 13 //a number of reserved word /*关键字个数*/ # define txmax 100 //length of identifier table /*名字表容量*/ # define nmax 14 //max number of digits in numbers /*number的最大位数*/ # define al 10 //length of identifier /*符号的最大长度*/ # define amax 2047 //maximum address /*地址上界*/ # define levmax 3 //max depth of block nesting /*最大允许过程嵌套声明层数[0,lexmax]*/ # define cxmax 200 //size of code array /*最多的虚拟机代码数*/ /*符号*/ enum symbol{ nul, ident, number, plus, minus, times, slash, oddsym, eql, neq, //slash斜线 lss, leq, gtr, geq, lparen, //leq :less than or equal to; gtr: great than;lparen:left parenthesis rparen, comma, semicolon,period, becomes,//comma逗号semicolon分号period句号becomes赋值号 beginsym, endsym, ifsym, thensym, whilesym, writesym, readsym, dosym, callsym, constsym, varsym, procsym, }; #define symnum 32 /*-------------*/ enum object{ //object为三种标识符的类型 constant, variable, procedur, }; /*--------------*/ enum fct{ //fct类型分别标识类PCODE的各条指令 lit, opr, lod, sto, cal, inte, jmp, jpc, //书本P23 }; #define fctnum 8 /*--------------*/ struct instruction //指令 { enum fct f; //功能码 int l; //层次差 int a; //P23 }; FILE * fas; //输出名字表
交叉编译与调试!!!
交叉编译与调试方法 一、交叉编译 1. 建立工作目录 2. 编写源代码 3. 编写makefile文件 4. 编译应用程序 #arm-linux-gcc -g hello.c -o hello 5. 启动NSF,挂载共享文件目录 将光盘中的gdbserver与gdb程序拷贝到共享目录 二、调试步骤 1、在Target Board开启gdbserver 进入共享目录 #gdbserver
注意的是要用“c”来执行命令,不能用“r”。因为程序已经在Target Board上面由gdbserver 启动了。结果输出是在Target Board端,用超级终端查看。 4. 交叉调试 (gdb)list (gdb)break func (gdb)break 22 (gdb)info br (gdb)c (这里不能用run) (gdb) n (gdb) p result (gdb) finish (跳出func 函数) (gdb) next (gdb) quit 建立连接后进行gdb 远程调试和gdb 本地调试方法相同
C语言的编译链接过程的介绍
C语言的编译链接过程的介绍 发布时间:2012-10-2600:00:00来源:中国IT实验室作者:佚名 关键字:C语言 C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可执行代码的过程。过程图解如下:
从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过程。 编译过程 编译过程又可以分成两个阶段:编译和会汇编。 编译 编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段: 第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。如 #include指令就是一个预处理指令,它把头文件的内容添加到.cpp文件中。这个在编译之前修改源文件的方式提供了很大的灵活性,以适应不同的计算机和操作系统环境的限制。一个环境需要的代码跟另一个环境所需的代码可能有所不同,因为可用的硬件或操作系统是不同的。在许多情况下,可以把用于不同环境的代码放在同一个文件中,再在预处理阶段修改代码,使之适应当前的环境。 主要是以下几方面的处理:
(1)宏定义指令,如#define a b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的a则不被替换。还有#undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。 (2)条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif 等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译 程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。 (3)头文件包含指令,如#include"FileName"或者#include等。 在头文件中一般用伪指令#define定义了大量的宏(最常见的是字符常量),同时包含有各种外部符号的声明。采用头文件的目的主要是为了使某些定义可以供多个不同的C源程序使用。因为在需要用到这些定义的C源程序中,只需加上一条#include语句即可,而不必再在此文件中将这些定义重复一遍。预编译程序将把头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。包含到c源程序中的头文件可以是系统提供的,这些头文件一般被放在 /usr/include目录下。在程序中#include它们要使用尖括号(<>)。
C语言条件编译及编译预处理阶段
C语言条件编译及编译预处理阶段 一、C语言由源代码生成的各阶段如下: C源程序->编译预处理->编译->优化程序->汇编程序->链接程序->可执行文件其中编译预处理阶段,读取c源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理。或者说是扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。预处理过程先于编译器对源代码进行处理。 在C 语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。 二、伪指令(或预处理指令)定义 预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。下面是部分预处理指令: 指令用途 # 空指令,无任何效果 #include 包含一个源代码文件 #define定义宏 #undef取消已定义的宏 #if如果给定条件为真,则编译下面代码 #ifdef 如果宏已经定义,则编译下面代码 #ifndef 如果宏没有定义,则编译下面代码 #elif如果前面的#if给定条件不为真,当前条件为真,则编译下面代码, 其实就是elseif的简写 #endif结束一个#if……#else条件编译块 #error停止编译并显示错误信息 三、预处理指令主要包括以下四个方面: 1、宏定义指令 宏定义了一个代表特定内容的标识符。预处理过程会把源代码中出现的宏标识符替换成宏定义时的值。宏最常见的用法是定义代表某个值的全局符号。宏的第二种用法是定义带参数的宏(宏函数),这样的宏可以象函数一样被调用,但它是在调用语句处展开宏,并
C语言基础知识(详细版)
C语言程序的结构认识 用一个简单的c 程序例子,介绍c 语言的基本构成、格式、以及良好的书写风格,使小伙伴对 c 语言有个 初步认识。 例1:计算两个整数之和的c 程序: #include main() { int a,b,sum; /* 定义变量a,b ,sum 为整型变量*/ a=20; /* 把整数20 赋值给整型变量a*/ b=15; /* 把整数15 赋值给整型变量b*/ sum=a+b; /* 把两个数之和赋值给整型变量sum*/ printf( “ a=%d,b=%d,sum=%d\n” ,a,b,sum); /* 把计算结果输出到显示屏上*/ } 重点说明: 1、任何一个c 语言程序都必须包括以下格式: main() { } 这是c 语言的基本结构,任何一个程序都必须包含这个结构。括号内可以不写任何内容,那么该程序将不执行任何结果。 2、main() - 在c 语言中称之为“主函数” ,一个c 程序有且仅有一个main 函数,任何一个c 程序总是从 main 函数开始执行,main 函数后面的一对圆括号不能省略。 3、被大括号{ }括起来的内容称为main 函数的函数体,这部分内容就是计算机要执行的内容。 4、在{ }里面每一句话后面都有一个分号(; ),在c 语言中,我们把以一个分号结尾的一句话叫做一个 c 语 言的语句,分号是语句结束的标志。 5、printf( “ a=%d,b=%d,sum=%d\n” ,a,b,sum); 通过执行这条c 语言系统提供给我们直接使用的屏幕输出 函数,用户即可看到运行结果,本程序运行后,将在显示器上显示如下结果: a=20,b=15,sum=35 6、#include 注意:(1)以#号开头 (2)不以分号结尾这一行没有分号,所以不是语句,在c 语言中称之为命令行,或者叫做“预编译处理命令” 。 7、程序中以/* 开头并且以*/ 结尾的部分表示程序的注释部分,注释可以添加在程序的任何位置,为了提高程序的可读性而添加,但计算机在执行主函数内容时完全忽略注释部分,换而言之就是计算机当做注释部分不存在于主函数中。 C程序的生成过程 C程序是先由源文件经编译生成目标文件,然后经过连接生成可执行文件。 源程序的扩展名为.c ,目标程序的扩展名为.obj , 可执行程序的扩展名为.exe 。
编译原理实验 简单词法分析(含源代码和实验结果)
附录一实验报告样式 《编译原理》实验报告 实验2 简单词法分析 姓名陈婷婷学号1009050121 班级计科1001班 时间:2012/4/5 地点:文波 同组人:无 指导教师:朱少林 实验目的 通过设计调试词法分析程序,实现从源程序中分出各种单词的方法;加深对课堂教学的理解;提高词法分析方法的实践能力。掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法;掌握词法分析的实现方法;上机调试编出的词法分析程序。 实验内容 ⑴掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 ⑵掌握词法分析的实现方法。 ⑶上机调试编出的词法分析程序。 ⑷为简单起见,假设编译语言为具有下特征的C_minus。该词法分析器要求至少能够识别C_minus中的以下几类单词: a.关键字:else if int return void while共6个,所有的关键字都是保留字,并且必须是小写; b.标识符:识别与C语言词法规定相一致的标识符,通过下列正则表达式定义:ID = letter (letter | digit)*; c.常数:NUM=(+ | - |ε)digit digit*(.digit digit* |ε)(e(+ | - |ε) digit digit* |ε),letter = a|..|z|A|..|Z|,digit = 0|..|9,包括整数,如123, -123, +123等;小数,如123.45, +123.45, -123.45;科学计数法表示的常数,如+1.23e3,-2.3e-9; d.专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */;
C语言编译过程总结详解
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可执行代码的过程。过程图解如下: 从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过程。 编译过程 编译过程又可以分成两个阶段:编译和会汇编。 编译 编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段: 第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。如#include指令就是一个预处理指令,它把头文件的内容添加到.cpp文件中。这个在编译之前修改源文件的方式提供了很大的灵活性,以适应不同的计算机和操作系统环境的限制。一个环境需要的代码跟另一个环境所需的代码可能有所不同,因为可用的硬件或操作系统是不同的。在许多情况下,可以把用于不同环境的代码放在同一个文件中,再在预处理阶段修改代码,使之适应当前的环境。 主要是以下几方面的处理: (1)宏定义指令,如 #define a? b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a 则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。 (2)条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。 (3)头文件包含指令,如#include "FileName"或者#include
C源程序调试方法
C源程序调试方法: 所谓源程序调试是指对程序的查错和排错,一般应经过以下几个步骤: 1进行静态检查 写好一个程序后,不要匆忙用编译器编译,应对写好的源程序进行人工检查,这一步是十分重要的,它能发现程序设计人员由于疏忽而造成的大多错误。为了减少编程错误,在编写程序中应力求做到以下几点: ①应当采用结构化程序方法编程,以增加可读性。 ②应尽可能多加注释,以帮助理解每段程序的作用。 ③在编写复杂的程序时,不要将全部的语句都写在main函数中,而要多利 用函数,用一个函数来实现单独的功能,既易于阅读也便于调试。各函数之间除了用参数传递数据这一渠道外,能够不用其他的渠道就尽量不用,数据间应尽量减少耦合的关系。 2、上机动态检查调试, 根据编译器提示的语法错误,提出编译器提示的全部错误(error)并一一改正,直到通过编译,生成下载文件或调试文件,还应该仔细检查编译器的警告(warning)信息,确认所有的警告信息并不会影响编译结果的正确性。有时,编译器的错误提示并非正确,而且出错的情况繁多且各种错误相互关联,因此要善于分析,找出真正的错误。 3、 Studio环境中进行硬件仿真或软件仿真。 测试的目的是为了测试软硬件能否在各处复杂的情况下正常工作,在测试时应当尽可能地将程序流程中的各分支和各种极限情况都测试一次,程序运行结果不对,大多属于逻辑错误,应将源程序与流程图仔细对照,是很容易发现错误的。 软件思想:本系统主要是用Mega 16主控单片机,控制液晶显示,输入键盘和电机的运行,Mega 16单片机根据键盘输入指令,运行相应的程序。当选择学习示教程序时,就是运用键盘控制电机的运行,然后记录电机运行的相关速度和最终的坐标到相应的寄存器,并在液晶显示器中显示学习示教程序运行状态,使用户更好的进行电机设置和了解电机的运行状态。
编译原理课程设计----C语言编译器的实现
$ 编译原理课程设计报告 设计题目编译代码生成器设计 、 学生姓名 班级 学号 指导老师 成绩 `
一、课程设计的目的 编译原理课程兼有很强的理论性和实践性,是计算机专业的一门非常重要的专业基础课程,它在系统软件中占有十分重要的地位,是计算机专业学生的一门主修课。为了让学生能够更好地掌握编译原理的基本理论和编译程序构造的基本方法和技巧,融会贯通本课程所学专业理论知识,提高他们的软件设计能力,特设定该课程的课程设计,通过设计一个简单的PASCAL语言(EL语言)的编译程序,提高学生设计程序的能力,加深对编译理论知识的理解与应用。 二、课程设计的要求 1、明确课程设计任务,复习编译理论知识,查阅复印相关的编译资料。 2、按要求完成课程设计内容,课程设计报告要求文字和图表工整、思路清晰、算法正 确。 3、@ 4、写出完整的算法框架。 5、编写完整的编译程序。 三、课程设计的内容 课程设计是一项综合性实践环节,是对平时实验的一个补充,课程设计内容包括课程的主要理论知识,但由于编译的知识量较复杂而且综合性较强,因而对一个完整的编译程序不适合平时实验。通过课程设计可以达到综合设计编译程序的目的。本课程的课程设计要求学生编写一个完整的编译程序,包括词法分析器、语法分析器以及实现对简单程序设计语言中的逻辑运算表达式、算术运算表达式、赋值语句、IF语句、While语句以及do…while语句进行编译,并生成中间代码和直接生汇编指令的代码生成器。 四、总体设计方案及详细设计 总体设计方案: 1.总体模块
【 2. \ 详细设计: 界面导入设计 (1)一共三个选项: ①choice 1--------cifafenxi ②choice 2--------yufafenxi ③choice 3--------zhongjiandaima (2)界面演示 } 图一
第2章 PL0编译程序的实现 完整课后习题答案+吕映芝编
第2章 PL/0编译程序的实现 第1题 PL/0语言允许过程嵌套定义和递归调用,试问它的编译程序如何解决运行时的存储管理。 答案: PL/0语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储管理。(数组CODE存放的只读目标程序,它在运行时不改变。)运行时的数据区S是由解释程序定义的一维整型数组,解释执行时对数据空间S的管理遵循后进先出规则,当每个过程(包括主程序)被调用时,才分配数据空间,退出过程时,则所分配的数据空间被释放。应用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题。 第2题 若PL/0编译程序运行时的存储分配策略采用栈式动态分配,并用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题,试写出下列程序执行到赋值语句b∶=10时运行栈的布局示意图。 var x,y; procedure p; var a; procedure q; var b; begin (q) b∶=10; end (q); procedure s; var c,d; procedure r; var e,f; begin (r) call q; end (r); begin (s) call r; end (s); begin (p) call s;
end (p); begin (main) call p; end (main). 答案: 程序执行到赋值语句b∶=10时运行栈的布局示意图为: 第3题 写出题2中当程序编译到r的过程体时的名字表table的内容。 size name kind level/val adr 答案: 题2中当程序编译到r的过程体时的名字表table的内容为: name kind level/val adr size x variable 0 dx y variable 0 dx+1 p procedure 0 过程p的入口(待填) 5