探索性研究设计:二手数据
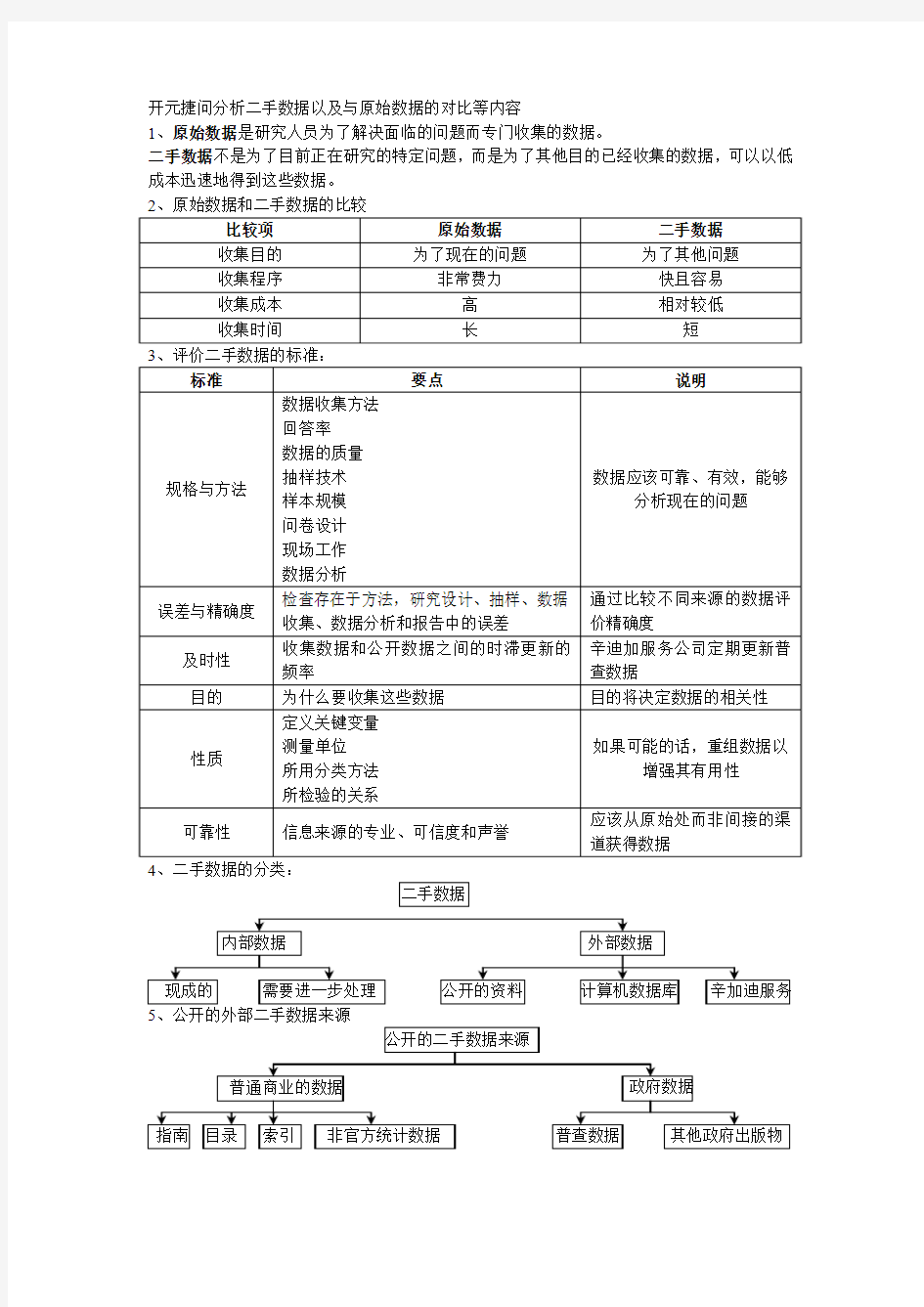
开元捷问分析二手数据以及与原始数据的对比等内容
1、原始数据是研究人员为了解决面临的问题而专门收集的数据。
二手数据不是为了目前正在研究的特定问题,而是为了其他目的已经收集的数据,可以以低成本迅速地得到这些数据。
4、二手数据的分类:
二手数据
二手资料调查法有哪些
竭诚为您提供优质文档/双击可除二手资料调查法有哪些 篇一:调研资料一手二手的区别 1.调研资料一手二手的区别 一手 二手资料是由他人收集并整理的现成资料。 2.介绍期成熟期产品市场有什么特点 1.highpercentageofproductfailures;highcost;lowsales ;volumenetloss;limited distribution;risky;expensive;littledirect;competiti on 2.salesincreaseslowly;profitsdeclineforproductandre tailer;pricecompetitionintensifiesmarginalproductsl eave;greatershareofthetotalpromotionaleffecttoretai ndealersandshelfspaceintheirstore 3.政治与法律环境问题通过调研人员实际调查所得到
的直接信息及时准确,可靠程度高,成本高、风险大不懂╮(╯_╰)╭ 政治环境 国际企业开展的活动都是经济活动。但是,经济和政治许多时候都是不可分,因为企业开展国际市场营销,必然要受目标市场上政治环境的影响,每个国家的政治环境都有其独特性,企业在进入一个新的外国市场之前,必须对其政治环境进行细致考察,以了解可能遇到的阻力和风险。 政治环境包括本国(母国homecountry)、目标市场国(东道国hostcountry)和国际(世界)的政治形势(局势),重大、突发性政治事件,政治稳定性和政治风险,政治制度和体制(国体、政体),政党和政府的作用,党政方针、政策、措施,政府办事作风、效率,国家政府之间的关系,地方政府之间的关系,参加国际组织的情况,等等。 2、法律环境: 法律是由国家制定并由国家强制力保证实施的各种行 为规则。迄今为止,世界上不存在一部统一的法律涵括所有的商业活动,所以熟悉国际营销的法律环境,对营销人员来说非常重要。法律环境包括各国 法律体系的基础——法系,本国和目标市场国的宪法、法律和行政法规,实体法和程序法,国内法和涉外法(国际私法),立法、司法、执法机构与程序,国际法(国际公法),
探索性数据分析
分布的概念 一个变量的分布是该变量的取值的具体表现形式,它不仅描述了该变量的不同取值,同时也描述了其每个值的可能性。 一、变量类型及其分布 1、首先我们打开life expectancy这个数据表。本例中的每个国家都有13年的年度观察数据, 并且每个国家的13年数据都是以年份为序依次排序。JMP将这种编排方式称为堆叠数据。 区分四类变量:定类变量(定名型、定序型),定量变量(定距型、定比型) 二、定类变量的分布 2、选择菜单---分析。将region作为Y,列变量。点击确定,得到如下结果。 JMP构造出了一个简单的矩形条形图,列出了六个大陆地区,并用直方条显示出相应区域在数据中出现的次数。虽然不能在图表中准确的获悉每个区域中国家的数目,却能清晰的得知south Asia国家数目最少,Europe&Central Asia国家数目最多。 图形下方的频数分布表提供了一个更加详细的变量概要。 3、菜单选择图形---图表。图表对话框如下图,可生成很多其他格式的图表。默认设置是竖 直方向的条形图。
4、选择列框中点击Region,并点击按钮统计量,选择数量。结果得到一张可以显示每个区域观察对象数量的条形图。 可以通过点击图表右侧的红色三角形按钮进行更改和自定义图形。
5.JMP自动按照字母顺序对定类数据进行结果输出。我们也可以修改输出结果。 6.在数据表格中或者在列框中右击Region,选择列信息。 7.点击列属性,选择值排序。 8.选择一个变量值名,使用按钮上移和下移,最后确定。 9.需要点击图表标题右侧的红色三角形按钮,选择脚本——重新运行分析。最后才得到我们需要的顺序的图形。 三、定量变量的分布 1、选择数据表的一部分 某些时候我们需要从数据表中选择某一些特定的行进行分析。JMP为我们提供了在分析包含和剔除行的多种方法。 菜单选择行—行选择—选择符合条件的行。 如下图所示,选择那些year等于2010的行,点击添加条件,最后点击确定。 菜单选择表---子集。在子集对话框中要确保做出的选择是选定行选项,并点击确定。 窗口中会显示出第二张打开的数据表。该表中有与第一张表相同的四个变量,但仅有195行。在每个案例中,观察年份都是2010年,并且每个国家只有一行数据。 2、连续型数据直方图的构建 ●菜单选择分析——分布。将LifeExp选入Y,列框中。 ●当分布窗口打开时,点击LifeExp左侧的红色三角形按钮,选择直方图选项——垂 直。该操作会清空垂直选项前的复选框,将直方图变成更加符合传统的水平方向。
二手市场调查报告
广州商学院 课程论文 调研主题:大学生关于二手市场看法 课程名称市场调查与预测 考查学期 2015/2016学第一学期考查方式课程论文 专业经济系网络营销 小组第一小组 姓名及分工报告编写:刘海石4号 问卷编写及收集:李世雄5号 图表制作与整合:李启健10号 资料整理及分析:钟伟强14号 报告审核与修改:林炜鑫15号指导教师赵曙光 日期:2015年 11月 23 日
目录 摘要 (3) 报告目录 一、调查概况 (4) 1、调查背景 (4) 2、调查方案 (4) 3、调查实施 (5) 二、样本结构 (5) 1、性别结构 (5) 2、月生活费情况 (6) 3、消费者态度结构 (7) 三、基本结果 (7) 1、男女比例............................................................. (7) 2、二手物品处理手段 (8) 3、学生对于了解二手市场的途径分析........................... ............ ..8 4、学生所感兴趣的类别和所能支付比例分析 (9) 5、学生购买二手商品理由和注重问题分析........................... .. (10) 6、学生对于二手市场建议分析........................... . .. (11) 四、必要说明 (11) 五、结论与建议 (11) 1、结论.......................................................... ... ..11 2、建议............................. . (12) 附录 (13)
临床试验的数据管理与统计分析SOP
临床试验的数据管理与统计分析SOP I目的:建立临床试验中数据管理与统计分析的流程,使其规范化、标准化。 II适应范围:所有的临床试验 III规程: 一、临床试验的数据管理 1、数据库的创建,录入、核查程序的编写。 1)根据CRF的内容,利用数据管理系统建立数据库,编写录入程序。 2)对数据库及录入程序进行数据的预录入测试,错误之处进行修改调试。 3)利用SAS或APSS等专业统计软件编写数据核查程序,并对预录入的数据进行核查,错误之处进行修改调试。 2、交接已完成的CRF,交接双方清点CRF数量,确认无误后双方签收; 3、由两名录入员分别录入本次接收的所有CRF,录入完成后进行双录入的程序比对,不同之处要查阅CRF进行修改,直至双录入比对无差异。 4、待所有CRF已录入并已完成双录入比对后,利用核查程序对数据库进行随机化、计算、逻辑等方面的核查,核查出的问题,先查阅CRF,若属录入错误可直接对数据库进行修改,若录入无误,则应就此问题发出疑问表,疑问表的基本内容应包括问题所在CRF的试验药物编号、问题所在位置、问题描述、研究者修改项、签字项及时间。 5、在进行程序核查的同时,对数据库进行人工复核,人工复核的数量不少于5份CRF,或不低于CRF总量的5%。 6、数据库所有疑问均已返回,重复程序核查无问题后,则可将数据递交生物统计人员。 二、临床试验的统计分析 1、由生物统计专业人员撰写统计分析计划书并不断修订完善。统计分析计划书的主要内容包括: 1)临床试验概述; 2)统计分析集的定义; 3)缺失值与离群值的处理; 4)数据变换方法; 5)主要指标及次要指标的统计分析方法等。 2、生物统计专业人员收到数据管理员提交的试验数据库后,进行数据的盲态核查。
数据探索性分析方法
数据探索性分析方法 1.1数据探索性分析概述 探索性数据分析(Exploratory Data Analysis,简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们对这些数据中的信息没有足够的经验,不知道该用何种传统统计方法进行分析时,探索性数据分析就会非常有效。探索性数据分析在上世纪六十年代被提出,其方法由美国著名统计学家约翰·图基(John Tukey)命名。 EDA的出现主要是在对数据进行初步分析时,往往还无法进行常规的统计分析。这时候,如果分析者先对数据进行探索性分析,辨析数据的模式与特点,并把它们有序地发掘出来,就能够灵活地选择和调整合适的分析模型,并揭示数据相对于常见模型的种种偏离。在此基础上再采用以显著性检验和置信区间估计为主的统计分析技术,就可以科学地评估所观察到的模式或效应的具体情况。 所以概括起来说,分析数据可以分为探索和验证两个阶段。探索阶段强调灵活探求线索和证据,发现数据中隐藏的有价值的信息,而验证阶段则着重评估这些证据,相对精确地研究一些具体情况。在验证阶段,常用的主要方法是传统的统计学方法,在探索阶段,主要的方法就是EDA。 EDA的特点有三个:一是在分析思路上让数据说话,不强调对数据的整理。传统统计方法通常是先假定一个模型,例如数据服从某个分布(特别常见的是正态分布),然后使用适合此模型的方法进行拟合、分析及预测。但实际上,多数数据(尤其是实验数据)并不能保证满足假定的理论分布。因此,传统方法的统计结果常常并不令人满意,使用上受到很大的局限。EDA则可以从原始数据出发,深入探索数据的内在规律,而不是从某种假定出发,套用理论结论,拘泥于模型的假设。二是EDA分析方法灵活,而不是拘泥于传统的统计方法。传统的统计方法以概率论为基础,使用有严格理论依据的假设检验、置信区间等处理工具。EDA处理数据的方式则灵活多样,分析方法的选择完全从数据出发,灵活对待,灵活处理,什么方法可以达到探索和发现的目的就使用什么方法。这里特别强调的是EDA更看重的是方法的稳健性、耐抗性,而不刻意追求概率意义上的精确性。三是EDA分析工具简单直观,更易于普及。传统的统计方法都比较抽象和深奥,一般人难于掌握,EDA则更强调直观及数据可视化,更强调方法的多样性及灵活性,使分析者能一目了然地看出数据中隐含的有价值的信息,显示出其遵循的普遍规律及与众不同的突出特点,促进发现规律,得到启迪,满足分析者的多方面要求,这也是EDA对于数据分析的的主要贡献。 1.2数据基本描述及可视化 1.2.1数据的类型 按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数
探索性数据分析
探索性数据分析 探索性数据分析是利用ArcGIS提供的一系列图形工具和适用于数据的插值方法,确定插值统计数据属性、探测数据分布、全局和局部异常值(过大值或过小值)、寻求全局的变化趋势、研究空间自相关和理解多种数据集之间相关性。探索性空间数据分析对于深入了解数据,认识研究对象,从而对与其数据相关的问题做出更好的决策。 一数据分析工具 1.刷光(Brushing)与链接(Linking) 刷光指在ArcMap数据视图或某个ESDA工具中选取对象,被选择的对象高亮度显示。链接指在ArcMap数据视图或某个ESDA工具中的选取对象操作。在所有视图中被选取对象均会执行刷光操作。如在下面章节将要叙述的探索性数据分析过程中,当某些ESDA工具(如直方图、V oronoi图、QQplot图以及趋势分析)中执行刷光时,ArcMap数据视图中相应的样点均会被高亮度显示。当在半变异/协方差函数云中刷光时,ArcMap数据视图中相应的样点对及每对之间的连线均被高亮度显示。反之,当样点对在ArcMap数据视图中被选中,在半变异/协方差函数云中相应的点也将高亮度显示。 2.直方图 直方图指对采样数据按一定的分级方案(等间隔分级、标准差分级)进行分级,统计采样点落入各个级别中的个数或占总采样数的百分比,并通过条带图或柱状图表现出来。直方图可以直观地反映采样数据分布特征、总体规律,可以用来检验数据分布和寻找数据离群值。 在ArcGIS中,可以方便的提取采样点数据的直方图,基本步骤为: 1)在ArcMap中加载地统计数据点图层。 2)单击Geostatistical Analyst模块的下拉箭头选择Explore Data并单击Histogram。 3)设置相关参数,生成直方图。 A.Bars:直方图条带个数,也就是分级数。 B.Translation:数据变换方式。None:对原始采样数据的值不作变换,直接生成直方图。 Log:首先对原始数据取对数,再生成直方图。Box-Cox:首先对原始数据进行博克斯-考克斯变换(也称幂变换),再生成直方图。 https://www.360docs.net/doc/2116022243.html,yer:当前正在分析的数据图层。 D.Attribute:生成直方图的属性字段。 从图3.1a和图3.1b的对比分析可看出,该地区GDP原始数据并不服从正态分布,经过对数变换处理,分布具有明显的对数分布特征,并在最右侧有一个明显的离群值。 在直方图右上方的窗口中,显示了一些基本统计信息,包括个数(count)、最小值(min)、最大值(max)、平均值(mean)、标准差(std. dev.)、峰度(kurtosis)、偏态(skewness)、
二手资料调查法
竭诚为您提供优质文档/双击可除 二手资料调查法 篇一:《市场调查与分析》阶段作业一 一、判断题(共5道小题,共50.0分) 1.观察调查法是指调查者在现场对被调查者的情况间接观察,以取得市场资料信息的方法。 a.正确 b.错误 知识点:阶段作业一 学生答案:[b;] 得分: 提示: 2.[10]试题分值:10.0 3.观察法只包括对人的行为的观察。 a.正确 b.错误 知识点:阶段作业一 学生答案:[b;] 得分:
提示: 4.[10]试题分值:10.0 5.广告调查是指在广告之后的一段时间里,对广告的目标对象所进行的较大规模和较广泛范围 的调查。 a.正确 b.错误 知识点:阶段作业一 学生答案:[b;] 得分: 提示: 6.[10]试题分值:10.0 7.在确定市场调查工作费用预算的时候明细法一定比参考法准确。 a.正确 b.错误 知识点:阶段作业一 学生答案:[b;] 得分:[10]试题分值:10.0 提示: 8. 9.确定营销方案之前的小规模测试属于探索性调研。
a.正确 b.错误 知识点:阶段作业一 学生答案:[a;] 得分:[10]试题分值:10.0提示: 10. 二、单项选择题(共5道小题,共50.0分) 1.下列调查方法中能够实现即时反馈的有()。 a.邮寄问卷调查法 b.入户访谈法 c.留置问卷调查法 d.网络调查法 知识点:阶段作业一 学生答案:[b;] 得分:[10]试题分值:10.0提示: 2. 3.下列有关信息,可通过实验调查法获得的是()。 a.国民收入的变动对消费的影响 b.物价指数的变动对消费行为的影响 c.股价对房价的影响 d.改变包装对消费行为的影响 知识点:阶段作业一
临床试验数据管理工作技术指南
附件 临床试验数据管理工作技术指南 一、概述 临床试验数据质量是评价临床试验结果的基础。为了确保临床试验结果的准确可靠、科学可信,国际社会和世界各国都纷纷出台了一系列的法规、规定和指导原则,用以规范临床试验数据管理的整个流程。同时,现代新药临床试验的发展和科学技术的不断进步,特别是计算机、网络的发展又为临床试验及其数据管理的规范化提供了新的技术支持,也推动了各国政府和国际社会积极探索临床试验及数据管理新的规范化模式。 (一)国内临床试验数据管理现状 我国的《药物临床试验质量管理规范》(Good Clinical Practice,GCP)对临床试验数据管理提出了一些原则要求,但关于具体的数据管理操作的法规和技术规定目前还处于空白。由于缺乏配套的技术指导原则,我国在药物临床试验数据管理方面的规范化程度不高,临床试验数据管理质量良莠不齐,进而影响到新药有效性和安全性的客观科学评价。此外,国内临床试验中电子化数据管理系统的开发和应用尚处于起步阶段,临床试验的数据管理模式大多基于纸质病例报告表(Case Report Form,CRF)的数据采集阶段,电子化数据采集与数据管理系统应用有待推广和普及。同时,由于缺乏国家数据标准,同类研究的数据库之间难以做到信息共享。
(二)国际临床试验数据管理简介 国际上,人用药品注册技术要求国际协调会议的药物临床研究质量管理规范(以下简称ICH E6 GCP)对临床试验数据管理有着原则性要求。对开展临床试验的研究者、研制厂商的职责以及有关试验过程的记录、源数据、数据核查等都直接或间接地提出了原则性的规定,以保证临床试验中获得的各类数据信息真实、准确、完整和可靠。 各国也颁布了相应的法规和指导原则,为临床试验数据管理的标准化和规范化提供具体的依据和指导。如:美国21号联邦法规第11部分(21 CFR Part 11)对临床试验数据的电子记录和电子签名的规定(1997年),使得电子记录、电子签名与传统的手写记录与手写签名具有同等的法律效力,从而使得美国食品药品管理局(FDA)能够接受电子化临床研究材料。据此,美国FDA 于2003年8月发布了相应的技术指导原则,对Part 11的规定作了具体阐释,并在计算机系统的验证、稽查轨迹,以及文件记录的复制等方面提出明确的要求。 2007年5月,美国FDA颁布的《临床试验中使用的计算机化系统的指导原则》(Guidance for Industry: Computerized Systems Used in Clinical Investigations)为临床试验中计算机系统的开发和使用提供了基本的参照标准。 而且由国际上相关领域专家组成的临床试验数据管理学会(Society of Clinical Data Management, SCDM)还形成了一部《良好的临床数据管理规范》(Good Clinical Data Management Practice,GCDMP),该文件为临床试验数据管理工作的每个关键环节都规
探索性空间数据分析
研究生课程探索性空间数据分析 杜世宏 北京大学遥感与GIS研究所
提纲 一、地统计基础 二、探索性数据分析
?地统计(Geostatistics)又称地质统计,是在法国著名统计学家Matheron大量理论研究的基础上逐渐形成的一门新的统计学分支。 它是以区域化变量为基础,借助变异函数,研究既具有随机性又具有结构性,或空间相关性和依赖性的自然现象的一门科学。凡是与空间数据的结构性和随机性,或空间相关性和依赖性,或空间格局与变异有关的研究,并对这些数据进行最优无偏内插估计,或模拟这些数据的离散性、波动性时,皆可应用地统计学的理论与方法。 ?地统计学与经典统计学的共同之处在于:它们都是在大量采样的基础上,通过对样本属性值的频率分布或均值、方差关系及其相应规则的分析,确定其空间分布格局与相关关系。但地统计学区别于经典统计学的最大特点是:地统计学既考虑到样本值的大小,又重视样本空间位置及样本间的距离,弥补了经典统计学忽略空间方位的缺陷。?地统计分析理论基础包括前提假设、区域化变量、变异分析和空间估值。
? 1. 前提假设 –⑴随机过程。与经典统计学相同的是,地统计学也是在大量样本的基础上,通过分析样本间的规律,探索其分布规 律,并进行预测。地统计学认为研究区域中的所有样本值 都是随机过程的结果,即所有样本值都不是相互独立的, 它们是遵循一定的内在规律的。因此地统计学就是要揭示 这种内在规律,并进行预测。 –⑵正态分布。在统计学分析中,假设大量样本是服从正态分布的,地统计学也不例外。在获得数据后首先应对数据 进行分析,若不符合正态分布的假设,应对数据进行变换,转为符合正态分布的形式,并尽量选取可逆的变换形式。
SPSS探索性因子分析的过程
SPSS探索性因子分析的过程
现要对远程学习者对教育技术资源和使用情况进行了解,设计一个李克特量表,如下图所示: 一. 因子分析的定义
在现实研究过程中,往往需要对所反映事物、现象从多个角度进行观测。因此研究者往往设计出多个观测变量,从多个变量收集大量数据以便进行分析寻找规律。多变量大样本虽然会为我们的科学研究提供丰富的信息,但却增加了数据采集和处理的难度。更重要的是许多变量之间存在一定的相关关系,导致了信息的重叠现象,从而增加了问题分析的复杂性。 因子分析是将现实生活中众多相关、重叠的信息进行合并和综合,将原始的多个变量和指标变成较少的几个综合变量和综合指标,以利于分析判定。用较少的综合指标分析存在于各变量中的各类信息,而各综合指标之间彼此是不相关的,代表各类信息的综合指标成为因子。因子分析就是用少数几个因子来描述许多指标之间的联系,以较少几个因子反应原资料的大部分信息的统计方法。 二. 数学模型 Z i i1F1 i2^ i3F3 …im F m U i 乙为第i个变量的标准化分数;(标准分是一种由原始分推导出来的相对地位量数,它是用来说明原始分在所属的那批分数中的相对位置的。) F m为共同因子; m为所有变量共同因子的数目; U为变量Z的唯一因素; i个变量与第im为因子负荷。(也叫因子载荷,统计意义就是第 m个公共因子的相关系数,它反映了第i个变量在第m个公共因子上的相对重要性也就是第m个共同因子对第i个变量的解释程
度。) 因子分析的理想情况,在于个别因子负荷im不是很大就是很小,这样每个变量才能与较少的共同因子产生密切关联,如果想要以最少的共同因素数来解释变量间的关系程度,则U彼此间不能有关联存在。 所谓的因子负荷就是因子结构中原始变量与因子分析时抽取出共同因子的相关,即在各个因子变量不相关的情况下,因子负荷.就是第i个原有变量和第m个因子变量间的相关系数,也就是Z在第m个共同因子变量上的相对重要性,因此,.绝对值越大则公共因子和原有变量关系越强。在因子分析中有两个重要指针:一为“共同性”,二为“特征值”。 所为共同性,也称变量共同度或者公共方差,就是每个变量在每个共同因子的负荷量的平方总和(一横列中所有因子负荷的的平方和),也就是个别变量可以被共同因子解释的变异量百分比,这个值是个别变量与共同因子间多元相关的平方。从共同性的大小可以判断这个原始变量与共同因子间的关系程度。如果大部分变量的共同度都高于0.8,则说明提取出的共同因子已经基本反映了各原始变量80%以上的信息,仅有较少的信息丢失,因子分析效果较好。而各变量的唯一因素就是1减掉该变量共同性的值,就是原有变量不能
二手资料的市场调查是指
竭诚为您提供优质文档/双击可除二手资料的市场调查是指 篇一:()又称为二手资料或文献调查,指将已经存在的 各种资料档案,以查阅和归纳 一、整体解读 试卷紧扣教材和考试说明,从考生熟悉的基础知识入手,多角度、多层次地考查了学生的数学理性思维能力及对数学本质的理解能力,立足基础,先易后难,难易适中,强调应用,不偏不怪,达到了“考基础、考能力、考素质”的目标。试卷所涉及的知识内容都在考试大纲的范围内,几乎覆盖了高中所学知识的全部重要内容,体现了“重点知识重点考查”的原则。 1.回归教材,注重基础 试卷遵循了考查基础知识为主体的原则,尤其是考试说明中的大部分知识点均有涉及,其中应用题与抗战胜利70 周年为背景,把爱国主义教育渗透到试题当中,使学生感受到了数学的育才价值,所有这些题目的设计都回归教材和中学教学实际,操作性强。 2.适当设置题目难度与区分度
选择题第12题和填空题第16题以及解答题的第21题,都是综合性问题,难度较大,学生不仅要有较强的分析问题和解决问题的能力,以及扎实深厚的数学基本功,而且还要掌握必须的数学思想与方法,否则在有限的时间内,很难完成。 3.布局合理,考查全面,着重数学方法和数学思想的 考察 在选择题,填空题,解答题和三选一问题中,试卷均对高中数学中的重点内容进行了反复考查。包括函数,三角函数,数列、立体几何、概率统计、解析几何、导数等几大版块问题。这些问题都是以知识为载体,立意于能力,让数学思想方法和数学思维方式贯穿于整个试题的解答过程之中。 篇二:()又称为二手资料或文献调查,指将已经存在的 各种资料档案,以查阅和归纳 一、整体解读 试卷紧扣教材和考试说明,从考生熟悉的基础知识入手,多角度、多层次地考查了学生的数学理性思维能力及对数学本质的理解能力,立足基础,先易后难,难易适中,强调应用,不偏不怪,达到了“考基础、考能力、考素质”的目标。试卷所涉及的知识内容都在考试大纲的范围内,几乎覆盖了高中所学知识的全部重要内容,体现了“重点知识重点考查”的原则。
空间数据探索性分析与地统计分析
1.数据检查,即空间数据探索分析(ESDA) 在地统计分析中,克里格方法是建立在平稳假设的基础上,这种假设在一定程度上要求所有数据值具有相同的变异性。另外,一些克里格插值(如普通克里格法、简单克里格法和泛克里格法等)都假设数据服从正态分布。如果数据不服从正态分布,需要进行一定的数据变换使其服从正态分布。因此,在用地统计分析创建表面之前,了解数据的分布状况十分重要。在ArcGIS GA模块中,主要提供了两种方法检验数据的分布:直方图法和正态QQPlot 图法。 (1)直方图显示数据的概率分布特征以及概括性的统计指标 图1 上图中所展示的数据,中值接近均值、峰值指数接近3。从图中观察可认为近似于正态分布。 (2)正态QQ Plot 图 图2 正态QQ 图上的点可指示数据集的单变量分布的正态性。如果数据是正态分布的,点将落在45 度参考线上。如果数据不是正态分布的,点将会偏离参考线。所以正态QQ 图可以用来检查数据的正态分布情况。作图原理是用分位图思想。直线表示正态分布,从图中可以看出数据很接近正态分布。 该研究通过地统计分析工具生成35个样本点的直方图和正态QQPlot 图,分别如图1、图2所示。从图1及其各种统计指标值可以看出,该样本点近乎于正态分布。在图2中,该例选取的35个样本点基本沿直线分布,也说明样本点接近于服从正态分布。在本研究区的样本点近乎于正态分布,而且区域化变量NO2的期望值是未知的,经过分析,在后期预测表面时,采用普通克里格插值是最为合适的。
(3)趋势分析图 上图为NO2的空间分布趋势图,x 轴正向指向东,y 轴正向指向北,z 轴正向指向属性(此处为NO2浓度)值增大的方向,采样点(即空气质量监测站)位于xy 平面上,黑色的垂直杆的高度代表NO2浓度的大小,分别将散点投影到xz 平面和yz 平面上,然后分别用二次曲线拟合,xz 平面上的绿色曲线代表东西方向的趋势,yz 平面上的蓝色曲线代表南北方向的趋势。从图中可以看到,NO2的浓度南北方向呈现出倒U 型的趋势,东西方向也呈现出倒U 型的趋势,说明在该地区的中部地区NO2浓度最高。 趋势分析工具提供用户研究区平面上的采样点转化为以感兴趣的属性值为高度的三维视图,然后用户从不同视角分析采样数据集的全局趋势。趋势分析图中的每一根竖棒代表了一个数据点的值(该实验中是NO2的浓度)和位置。这些点被投影到一个东西向的和一个南北向的正交平面上。通过投影点可以做出一条最佳拟合线,并用它来模拟特定方向上存在的趋势。此实验中的趋势分析图中南北方向和东西方向上有明显的趋势出现,因此需要用二次曲面拟合,即在后续剔除趋势的操作中选择二次(second)。可见,使用趋势分析来分析样本点数据的走向,可以使后续的表面拟合更加客观,拟合的结果具有更大的可信程度。 (4)Voronoi 图 Voronoi 图可以用来发现离群值。Voronoi 图的生成方法:每个多边形内有一个样点,多变形内任一点到该点的距离都小于其他多边形到该点的距离,生成多边形后。某个样点的相邻样点便会与该样点的多边形有相邻边。 利用相邻点的这个定义,可计算多种局部统计量。“Voronoi 图”工具提供下列方法来指定或计算面的值。 简单:指定给面的值是在该面内的采样点处记录的值。 平均值:指定给面的值是根据面及其相邻面计算出的平均值。 众数:利用五个组距对所有多边形进行分类。指定给面的值是面及其相邻面的众数(最常出现的组)。 聚类:利用五个组距对所有多边形进行分类。如果面的组距与其每个相邻面的组距都不同,则该面将灰显并放进第六组以区分该面与其相邻面。 熵:所有的面都利用基于数据值(小分位数)的自然分组的五个组进行分类。
二手资料分析报告
二手资料分析报告 ——关于福州市政府公信力调研 一、二手资料收集情况 此次收集关于政府公信力的二手资料,与以往不同的是,要从众多材料中找出与我们组调研主题相关度较高的材料。 在进行收集二手资料之前,首先我们对调研内容和调研方案进行分析,得出本次调研方案中有所欠缺的方面和本次调研的主要调研内容。 接着就分析得到结果,在百度、谷歌等网络搜索工具进行搜索,并分析所搜索到的文件和材料,筛选出与本次调研内容相关度较高的材料。同时我们还利用图书馆多媒体教室搜索引擎,搜索历年来与本次调研内容有关的论文、文献等。 本组对二手资料的收集主要是通过网络收集,本小组有4个成员,所以每个人负责收集至少20份二手资料,最后从92份的资料中整理、筛选出20份相关度较高的资料。 二、二手资料重要观点整理 1、政府公信力的定义以及重要性(政府实力等) 2、判断政府公信力的指标、测评体系、影响因素 3、关于公信力的调查问卷 4、当前我国政府公信力的情况 5、影响政府公信力的因素 6、政府公信力缺失的表现、主要原因以及解决办法 7、信息公开、职能转变、官员作风、选人用人、民生问题、执法力度、社会体制与政府公信力的关系 8、提升政府公信力的方法与途径 三、对调研内容的启示 1、二手资料的搜集有助于我们对于调研项目的了解,使我们明确和改进本次调研内容,让调研更加合理、完善 2、通过本次的资料搜集使我们小组的成员更加明确本小组的选题,知其内涵,使调研思路更加的清晰 3、为调研实施提供依据,使调研具有全面性 4、应该对相关的资料进行拓展,不能太过狭隘 四、对焦点小组访谈的启示 1、小组成员特别是主持人,应总体把握资料的内容,以便掌握讨论方向,能够保证访谈时不会发生偏题现象 2、各成员应为拟定访谈的提纲做好相应的资料熟悉准备,这样可以在访谈或其他阶段调研主题发生偏离时,及时纠正 3、在进行焦点小组访谈时所谈论的内容不能仅限于资料上的,最好能够脱离材料,多发表自己的看法,最大限度的激发被访谈者的思维,从而发掘出资料里没有的新方向,新思路 五、对调查问卷设计的启示 1、二手资料的搜集使问卷的内容更加真实,有理有据
描述性统计分析与探索性统计分析
第一章 描述性统计 我们把对某一个问题的研究对象的全体称为总体,总体就是一个具有确定分布的随机变量.我们统计分析的目的是通过从总体中抽得的样本,对总体分布进行推断,要想较准确的推断出总体的分布,首先要对样本的分布状况有一个基本的了解,这一章就是介绍用以描述样本分布状况的一些常用统计分析方法,这些方法既直观又简单,而且也很实用. 1.1频数分析与图形表示 一、总体X 为只取少数个值的离散型随机变量 例1.1.1考察一枚骰子是否均匀,设计实验如下: 独立地掷这枚骰子42次,所得点数纪录如下: 3 2 4 1 5 1 5 3 4 3 5 6 4 2 5 3 1 3 4 1 4 3 1 6 3 3 1 2 4 2 6 3 4 6 6 1 6 2 4 5 2 6 X 为掷一枚均匀的骰子一次所得的点数 二、当总体X 取较多离散值或X 为连续取值时 设x x x n ,,21是总体X 的一组样本观测值,具体做法如下:
1 求出x )1(和x n )(,取a 略小于x )1(,b 略大于x n )(; 2 将区间[a ,b]分成m 个小区间(m <n ),小区间长度可以不等,分点分别为 a =t t t m <<< 10=b 注意:使每个小区间中都要有一定量的观测值,且观测值不在分点上。 划分区间个数的确定: 区间过少:分布信息混杂,丢失信息. 区间过多:出现很多空区间. 区间划分个数m 依赖于样本总数n ,理论上有如下两个公式可参考: Moore(1986) : m ≈C n 5/2,C = 1~3; Sturges(1928) : m ≈1+3.322(lg n ); 3 用n j 表示落在小区间(t j 1-,t j ]中观测值的个数(频数)并计算频率f j = n n j (j=1,2,…,m ); 4 在直角坐标系x-o-y 的x 轴上标出t t t m ,,,10 , 分别以(t j 1-,t j ]为底边,以n j 为高作矩形,即得频数条形图。 例1.1.2下表是某大学总数为从352名学生的“普通统计学”考试的成绩中,随机抽取的60位学生的成绩 63 76 83 91 45 81 93 30 72 80 82 83 81 76 67 84 72 58 83 64 93 63 75 99 74 76 95 91 83 61 82 85 83 44 88 72 66 94 68 78 88 71 94 85 82 79 100 90 83 88 84 48 72 80 85 80 87 76 62 96 对上述数据作频数分析并画出条形图。 解 分析 区间个数:n =60 , 用Moore 公式计算得C*5.123,这里C=1合适,取区间m = 6 用Sturges 公式计算得区间m = 6.907, 取区间m = 6 区间划分 10分一区间 重新划分
《临床试验数据管理工作技术指南》
临床试验数据管理工作技术指南 2012年3月12日
目录 一、概述 (1) 1.1国内临床试验数据管理现状 (1) 1.2国际临床试验数据管理简介 (2) 1.2.1ICH-GCP 对临床试验数据管理的原则性指导 (2) 1.2.221 CFR Part 11对电子记录和电子签名的基本要求 (3) 1.2.3“临床试验中采用计算机系统的指导原则”提供计算机系统开发的参照标准 (3) 1.2.4GCDMP (Good Clinical Data Management Practice)提供全面具体的数据管理要求 (4) 二、数据管理相关人员的责任、资质及培训 (5) 2.1相关人员的责任 (5) 2.1.1申办者 (5) 2.1.2研究者 (6) 2.1.3监查员 (6) 2.1.4数据管理员 (6) 2.1.5合同研究组织(CRO) (7) 2.2数据管理人员的资质及培训 (8) 三、临床试验数据管理系统 (9) 3.1临床试验数据管理系统的重要性 (9) 3.2数据质量管理体系的建立和实施 (9) 3.3临床试验数据管理系统的基本要求 (10) 3.3.1系统可靠性 (10) 3.3.2临床试验数据的可溯源性(Traceability) (11) 3.3.3数据管理系统的权限管理(Access Control) (12) 四、试验数据的标准化 (12) 4.1临床数据标准化的现状与发展趋势 (12) 4.2临床试验的数据标准化 (13) 4.2.1CDISC和HL7 (14) 4.2.2医学术语标准 (16) 4.2.3临床试验报告的统一标准(CONSORT) (20) 五、数据管理工作的主要内容 (21) 5.1CRF的设计与填写 (21) 5.1.1CRF的设计 (21) 5.1.2CRF填写指南 (22) 5.1.3注释CRF (22) 5.1.4CRF的填写 (22) 5.2数据库的设计 (22) 5.3数据接收与录入 (23) 5.4数据核查 (23) 5.5数据质疑表的管理 (25)
调研资料 一手二手的区别
1.调研资料一手二手的区别 一手通过调研人员实际调查所得到的直接信息及时准确,可靠程度高,成本高、风险大 二手资料是由他人收集并整理的现成资料。 2.介绍期成熟期产品市场有什么特点1.high percentage of product failures;high cost; low sales ;volume net loss;limited distribution;risky;expensive;little direct;competition 2.Sales increase slowly ;profits decline for product and retailer;price competition intensifies marginal products leave;greater share of the total promotional effect to retain dealers and shelf space in their store 3.政治与法律环境问题 不懂╮(╯_╰)╭ 政治环境 国际企业开展的活动都是经济活动。但是,经济和政治许多时候都是不可分,因为企业开展国际市场营销,必然要受目标市场上政治环境的影响,每个国家的政治环境都有其独特性,企业在进入一个新的外国市场之前,必须对其政治环境进行细致考察,以了解可能遇到的阻力和风险。 政治环境包括本国(母国home country)、目标市场国(东道国host country)和国际(世界)的政治形势(局势),重大、突发性政治事件,政治稳定性和政治风险,政治制度和体制(国体、政体),政党和政府的作用,党政方针、政策、措施,政府办事作风、效率,国家政府之间的关系,地方政府之间的关系,参加国际组织的情况,等等。 2、法律环境: 法律是由国家制定并由国家强制力保证实施的各种行为规则。迄今为止,世界上不存在一部统一的法律涵括所有的商业活动,所以熟悉国际营销的法律环境,对营销人员来说非常重要。法律环境包括各国
大数据探索性分析考试题
1 / 9 以附件1中上海市药械化稽查办案数据,利用抽样的方法(抽取容量为200的样本),对其某一方面的特性进行分析、研究。 这里在R 里采用简单随机抽样抽取容量为200的样本数据,程序如下: #####简单随机抽样 data=read.csv("G:/d.csv") head(data)#将数据集读入R 中,并查看前六行数据 library(sampling)#加载抽样包 N=length(data[,3])#总体个数 n=200#需要抽取样本个数 set.seed(1) yangben=srswor(n,N)#在总样本量N 中抽取n 个样本,返回其位置 yangben=getdata(data,yangben)#取出抽到样本的数据 write.csv(srs,file="药械化稽查办案信息抽取样本1.csv")#将抽到的数据读入本地文件 class(yangben)#查看抽到的数据类型 抽到的样本前几个部分展示如下: 接下来,我们对其中某些特性进行统计分析,首先,我关注的是所在区县,程序展示如下: a=table(yangben$所属区县)#统计17个区县出现的频数 barplot(a,main = "区县出现频数分布图")#绘出所在区县分布图,x 轴所对应的区县分别为(NA 宝山 长宁 崇明 奉贤 虹口 黄浦 嘉定 金山 静安 闵行 浦东 普陀 青浦 松江 徐汇 杨浦 闸北 ) a1=sort(a)#按升序排列 a2=sort(a,decreasing =T)#按降序排列 barplot(a1,main = "区县出现频数升序分布图")#绘出所在区县按升序排列的分布图,x 轴所对应的区县分别
中医慢性病临床研究中数据管理的质量调查
中医慢性病临床研究中数据管理的质量调查 目的研究“中医慢病临床科研体系及其成果转化应用模式研究”项目在数据管理方面的科学性、合理性,为本项目的后续工作改进提供参考。方法依据国内外有关临床研究数据管理工作的法规、规范和指南等相关文件,编制“中医慢病防治临床科研数据管理评估清单”。使用该问卷在10个临床课题稽查过程中进行现场调查,收回有效问卷20份,并进行统计分析。结果在数据管理和统计方面有50%~60%的课题由第三方进行,有70%的课题由自己中心进行监察;50%的课题采用与他人合作的方式开发相应的数据管理系统;7家單位具有数据管理的制度和计划;数据管理执行中,培训、数据库建立、病例报告表追踪等7个方面执行度较低。结论中医慢性病临床研究的数据管理的质量情况还需要从各个方面加以完善,提高大规模临床试验的数据管理的质量。 Abstract:Objective To study the scientificity and rationality in data management of the project of Chinese Chronic Disease Clinical Research System and its Achievements Application Mode;To provide evidence and reference for the improvement of follow-up work. Methods According to the relevant management regulations,guidelines,and other relevant documents of national and international clinical research data,“Questionnaire for Research Data Management Assessment of Chinese Chronic Disease Prevention” was designed. The questionnaires were used in 10 clinical topics during the on-site inspection survey,and 20 valid questionnaires were retrieved and analyzed statistically. Results 50-60 percentage of subjects in data management and statistics were performed by the third party;70 percentage of subjects were performed by their own central monitoring;50 percentage of the subjects adopted a cooperative manner with others to develop appropriate data management systems;7 centers had system and plan for data management;Data management was carried out;implementation degree of training,database,CRF tracing,and others 7 aspects was low. Conclusion Improving the quality of data management of TCM clinical research still needs to be perfected from many aspects,and quality mode of large-scale clinical trials should be improved. Key words:Chinese medicine chronic disease;data management;GCP 由于慢性病治疗周期长、随访时间长、数据量大, 数据质量难以保障。临床研究中,科学、合理地收集和管理原始数据,是研究结论可靠性、真实性的重要保证。临床研究数据管理的主要目标是及时获取正确、有效的数据,符合《药物临床实验质量管理规范》(GCP)及统计分析与报告的要求。为此,笔者对中医慢性病临床研究的数据管理质量进行了调查分析,以评估数据管理质量,提出管理过程中的缺陷,寻找解决途径,增强数据的真实性、准确性、可靠性。1 资料与方法 1.1 问卷编制