BatteryMon使用方法详解
1
BatteryMon 使用方法详解(转)
关于BatteryMon 相信大家都很熟悉了,一款购买笔记本电脑必备的电池检测软件。带上BatteryMon 在购买笔记本电池时,我们常常须要了解是否为厂家原配产品、电池的容量、最长待机时间等。BatteryMon 以图形化的方式,可以让我们直观的看到电池的各种性能参数。装入笔记本电池断开外接电源后,运行BatteryMon 后点击“Start”按钮,在坐标图中可以看到电池电量的下降曲线。其中纵坐标表示当前所剩电池电量百分比,横坐标表示电池使用时间。在左边的详细信息中,“Totaltime”表示软件测试出电池充满电时所能使用的最长时间。一般在3小时左右,即表示此电池充
电性能还是不错的。
2
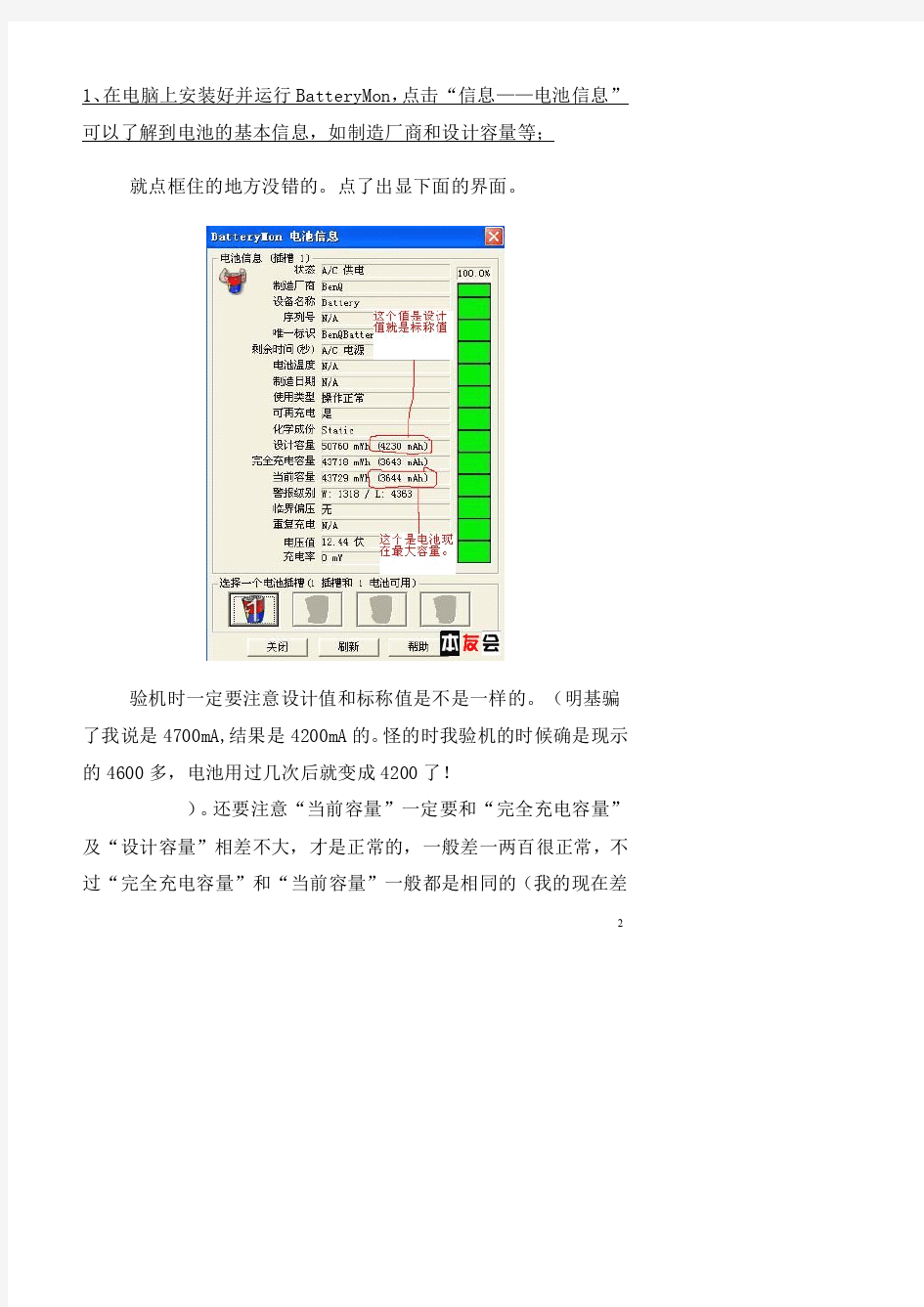
1、在电脑上安装好并运行BatteryMon,点击“信息——电池信息”可以了解到电池的基本信息,如制造厂商和设计容量等;
就点框住的地方没错的。点了出显下面的界面。
验机时一定要注意设计值和标称值是不是一样的。(明基骗了我说是4700mA,结果是4200mA 的。怪的时我验机的时候确是现示的4600多,电池用过几次后就变成4200了!
)。还要注意“当前容量”一定要和“完全充电容量”
及“设计容量”相差不大,才是正常的,一般差一两百很正常,不过“完全充电容量”和“当前容量”一般都是相同的(我的现在差
大了!电池损坏得真快!还没用多少次呢)。
2、在主界面中点击“开始”按钮,进行放电测试,其中纵坐标代表当前所剩电池电量百分比,横坐标表示电池使用时间,在左边的信息栏的“放电率”中显示了电池饱和时所能使用的最长时间。
估计值,实际使用时间与具体使用方式有关。这样你需要花多少时间就大概知道一些情况了。
比如说您要购买一款二手的笔记本电脑电池,那么如何才能在最短的时间内发现这款电池目前的性能如何哪?
放电曲线就会帮到你的大忙,为什么哪?因为一款性能良好的电池一定会有着非常平滑的放电曲线,每下降一格的时间大概都是相同的,如果说您购买的二手电池在放电的时候有着突然的下滑,那么无疑,这块电池的寿命已近,能去换就去换掉吧,这就是BatteryMon的放电曲线功能所能带给大家的便利,当然刚才所说到的是放电时候的情况,充电的时候同样能够利用到放电曲线功能,一般来说,充电的曲线也应该很平稳,但是有一点需要注意,当电池容量达到90%之后,外界电源会改成小电流来对电池继续充电,那么在最后的10%电量的充电区县就会非常的直,并且会延续很上的时间,这样的情况才说明这款电池的活性依然很好,在很好的充放电状态之中,反之则应该注意了。
3
另外一个非常鲜明的特点就是,这款软件可以直接看到笔记本电池的设计容量、目前容量和满充容量,这一点以前只有IBM的笔记本可以做得到,那么借助这款软件,任何笔记本都可以轻轻松松的看到电池的容量情况。一般来说电池的背面会标有电池的设计容量,这一点与我们的对比有指导意义,首先看点后后面的参数中容量的数值,比如说笔者的这款电池标称1900mWh,然后看到BatteryMon电池信息选项中的数值同样是1900mWh,这基本上说明这款电池没有问题,没有达不到标称数值的问题(这在购买二手笔记本时尤为有用,有些不良JS会拿容量小的电池印上大的容量数值来蒙骗消费者,这时候这一点功能就有助于辨别电池),有一点需要注意,这款软件有一个小小的BUG,就是在刚开始安装的时候
往往电池设计容量会显示的很大,但是在完全充放电几次之后就可
4
以正常显示了,这一点小问题大家也需要注意,不要像笔者一样,刚开始总以为自己占到便宜了,买了一块容量大的电池,其实在电池完全充放电几次之后就会显示出正确的数值。
除了显示设计容量之外,这款电池还可以显示电池的目前容量,用户可以非常明了的了解电池的放电情况。其实最重要的一点是这款软件可以显示电池的满充容量,这一点非常有用处,如果一块设计容量为1900mWh的电池完全充放电几次之后只剩下1700mWh 的满充容量了,那么很有可能,这块电池寿命已经差不多了,如果说像IBM的BATTERY INFORMATION软件里显示的那样,这款电池就会显示出黄色的寿命状态,说明电池有老化的迹象。如果是新买回来的电池,那么很有可能会超过设计容量达到2000mWh或者更高的容量,这也是属于正常状态,电池之所以是一种消费品,电池容量的消耗就是非常重要的一点体现。
这款软件的主要特色就在于上面所说到的两点,也是真正意义上的帮助没有PM芯片和软件的机型达到电池监视目的的重要表现,下面要说到的一些小的细节就是这款软件的增色之处了。首先BatteryMon支持高达四块电池同时监视,并且可以单独显示每块电池的情况,这一点对于那些可以同时支持多块电池的机型提供了支
5
持。另外BatteryMon可以显Array示某块电池的化学成分,帮
助你了解自己电池的一些特
性。电芯的温度监控也是非
常有用处的,无需质疑,高
温是锂电池的致命杀手,如
何能够更好的监视电芯温度
成了维护电池的最好方法,
这款电池就可以时刻显示电
池温度,帮助你进行维护,
但是这款软件的这个功能只
对于一些品牌的电池有效,
像笔者老机型M300的电池就
不支持显示,但是朋友的COMPAQ2839就可以显示,估计是对于老
电池的兼容性不好,但是主流机型基本都可以兼容。
这款软件还可以验证你的机器的充电电路是否正常,这样才能
有效的保护你的电池。
你可以留意一下,当充电完成,充电指示灯已经熄灭的时候,
Charge rate的数值,当放电的时候,这个数值是负数,说明正在
放电,当充电的时候,这个数值将变为正数,说明正在充电,那么
当充满电的时候,这里县是什么哪?正常的充电电路在电池充满的
6
时候,电池的管理芯片Array会自动切开电池充电,
改为由AC电源单独供
电,电池之作为后备电
源使用,如何来验证这
点,其实BatteryMon就
可以达到这样的目的。
呵呵,没错,这里显示
为0,这说明了什么哪?
无需质疑,这充分说明
了,当充电动作完成的
时候,电池已经没有的
充电动作,这也消除了
一些朋友问到的,不用
笔记本电池是否要将电池取下的疑惑,事实证明完全不需要,这是
多此一举的事情,但是对于那些质量不良的国产品牌来说,笔者可
不敢保证了。因为他可能根本就没有这个充电保护功能,所以在你
选购笔记本的时候,也可以检查一下你的笔记本的充电电路是否合
格,不正常的充电电路会是你的笔记本电池的寿命大幅缩短。
7
NCBI在线BLAST使用方法与结果详解
N C B I在线B L A S T使用方法与结果详解 IMB standardization office【IMB 5AB- IMBK 08- IMB 2C】
N C B I在线B L A S T使用方法与结果详解 BLAST(BasicLocalAlignmentSearchTool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。BLAST程序能迅速与公开数据库进行相似性序列比较。BLAST结果中的得分是对一种对相似性的统计说明。 BLAST采用一种局部的算法获得两个序列中具有相似性的序列。 Blast中常用的程序介绍: 1、BLASTP是蛋白序列到蛋白库中的一种查询。库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。 2、BLASTX是核酸序列到蛋白库中的一种查询。先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。 3、BLASTN是核酸序列到核酸库中的一种查询。库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。 4、TBLASTN是蛋白序列到核酸库中的一种查询。与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。 5、TBLASTX是核酸序列到核酸库中的一种查询。此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。 NCBI的在线BLAST: 下面是具体操作方法 1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。不同的blast程序上面已经有了介绍。这里以常用的核酸库作为例子。 2,粘贴fasta格式的序列。选择一个要比对的数据库。关于数据库的说明请看NCBI在线blast数据库的简要说明。一般的话参数默认。 3,blast参数的设置。注意显示的最大的结果数跟E值,E值是比较重要的。筛选的标准。最后会说明一下。 4,注意一下你输入的序列长度。注意一下比对的数据库的说明。 5,blast结果的图形显示。没啥好说的。 6,blast结果的描述区域。注意分值与E值。分值越大越靠前了,E值越小也是这样。7,blast结果的详细比对结果。注意比对到的序列长度。评价一个blast结果的标准主要有三项,E值(Expect),一致性(Identities),缺失或插入(Gaps)。加上长度的话,就有四个标准了。如图中显示,比对到的序列长度为1405,看Identities这一值,才匹配到1344bp,而输入的序列长度也是为1344bp(看上面的图),就说明比对到的序列要长一
Python py2exe使用方法
一、简介 py2exe是一个将python脚本转换成windows上的可独立执行的可执行程序(*.exe)的工具,这样,你就可以不用装python而在windows系统上运行这个可执行程序。 py2exe已经被用于创建wxPython,Tkinter,Pmw,PyGTK,pygame,win32com client和server,和其它的独立程序。py2exe是发布在开源许可证下的。 二、安装py2exe 从https://www.360docs.net/doc/3a16191594.html,/py2exe下载并运行与你所安装的Python对应的py2exe 版本的installer,这将安装py2exe和相应的例子;这些例子被安装在lib\site-packages\py2exe\samples目录下。 三、py2exe的用法 如果你有一个名为helloworld.py的python脚本,你想把它转换为运行在windows上的可执行程序,并运行在没有安装python的windows系统上,那么首先你应写一个用于发布程序的设置脚本例如mysetup.py,在其中的setup函数前插入语句import py2exe 。 mysetup.py示例如下: # mysetup.py from distutils.core import setup import py2exe setup(console=["helloworld.py"]) 然后按下面的方法运行mysetup.py: python mysetup.py py2exe 上面的命令执行后将产生一个名为dist的子目录,其中包含了helloworld.exe,python24.dll,library.zip这些文件。 如果你的helloworld.py脚本中用了已编译的C扩展模块,那么这些模块也会被拷贝在个子目录中,同样,所有的dll文件在运行时都是需要的,除了系统的dll文件。 dist子目录中的文件包含了你的程序所必须的东西,你应将这个子目录中的所有内容一起发布。 默认情况下,py2exe在目录dist下创建以下这些必须的文件: 1、一个或多个exe文件。 2、python##.dll。 3、几个.pyd文件,它们是已编译的扩展名,它们是exe文件所需要的;加上其它的.dll文件,这些.dll是.pyd所需要的。 4、一个library.zip文件,它包含了已编译的纯的python模块如.pyc或.pyo 上面的mysetup.py创建了一个控制台的helloword.exe程序,如果你要创建一个图形用户界的程序,那么你只需要将mysetup.py中的console=["helloworld.py"]替换为windows=["myscript.py"]既可。
ncbi的使用方法
NCBI(美国国立生物技术信息中心)资源介绍及使用手册 作者:未知来源:中科院上海生命科学研究院生物信息中心时间:2006-12-27 NCBI 资源介绍 本文目录: NCBI(美国国立生物技术信息中心) 简介 NCBI 站点地图 NCBI癌症基因组研究 NCBI-Coffee Break NCBI-基因和疾病 NCBI-UniGene Cluster of Orthologous Groups of proteins (COG)介绍 Gene Expression Omnibus (GEO)介绍 LocusLink介绍 关于RefSeq:NCBI参考序列 NCBI(美国国立生物技术信息中心)简介 介绍 理解自然无声但精妙的关于生命细胞的语言是现代分子生物学的要求。通过只有四个字母来代表DNA化学亚基的字母表,出现了生命过程的语法,其最复杂形式就是人类。阐明和使用这些字母来组成新的“单词和短语”是分子生物学领域的中心焦点。数目巨大的分子数据和这些数据的隐秘而精细的模式使得计算机化的数据库和分析方法成为绝对的必须。挑战在于发现新的手段去处理这些数据的容量和复杂性,并且为研究人员提供更好的便利来获得分析和计算的工具,以便推动对我们遗传之物和其在健康和疾病中角色的理解。 国立中心的建立 后来的参议员Claude Pepper意识到信息计算机化过程方法对指导生物医学研究的重要性,发起了在1988年11月4日建立国立生物技术信息中心(NCBI)的立
法。NCBI是在NIH的国立医学图书馆(NLM)的一个分支。NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。它的使命包括四项任务: 建立关于分子生物学,生物化学,和遗传学知识的存储和分 析的自动系统 实行关于用于分析生物学重要分子和复合物的结构和功能 的基于计算机的信息处理的,先进方法的研究 加速生物技术研究者和医药治疗人员对数据库和软件的使用。 全世界范围内的生物技术信息收集的合作努力。 NCBI通过下面的计划来实现它的四项目的: 基本研究 NCBI有一个多学科的研究小组包括计算机科学家,分子生物学家,数学家,生物化学家,实验物理学家,和结构生物学家,集中于计算分子生物学的基本的和应用的研究。这些研究者不仅仅在基础科学上做出重要贡献,而且往往成为应用研究活动产生新方法的源泉。他们一起用数学和计算的方法研究在分子水平上的基本的生物医学问题。这些问题包括基因的组织,序列的分析,和结构的预测。目前研究计划的一些代表是:检测和分析基因组织,重复序列形式,蛋白domain 和结构单元,建立人类基因组的基因图谱,HIV感染的动力学数学模型,数据库搜索中的序列错误影响的分析,开发新的数据库搜索和多重序列对齐算法,建立非冗余序列数据库,序列相似性的统计显著性评估的数学模型,和文本检索的矢量模型。另外,NCBI研究者还坚持推动与NIH内部其他研究所及许多科学院和政府的研究实验室的合作。 数据库和软件
py2exe使用方法
py2exe使用方法 一、简介 py2exe是一个将python脚本转换成windows上的可独立执行的可执行程序(*.exe)的工具,这样,你就可以不用装python而在windows系统上运行这个可执行程序。 py2exe已经被用于创建wxPython,Tkinter,Pmw,PyGTK,pygame,win32com client和server,和其它的独立程序。py2exe是发布在开源许可证下的。 二、安装py2exe 从https://www.360docs.net/doc/3a16191594.html,/py2exe下载并运行与你所安装的Python对应的py2exe 版本的installer,这将安装py2exe和相应的例子;这些例子被安装在lib\site-packages\py2exe\samples目录下。 三、py2exe的用法 如果你有一个名为helloworld.py的python脚本,你想把它转换为运行在windows上的可执行程序,并运行在没有安装python的windows系统上,那么首先你应写一个用于发布程序的设置脚本例如mysetup.py,在其中的setup函数前插入语句import py2exe 。 mysetup.py示例如下: # mysetup.py from distutils.core import setup import py2exe setup(console=["helloworld.py"]) 然后按下面的方法运行mysetup.py: python mysetup.py py2exe 上面的命令执行后将产生一个名为dist的子目录,其中包含了helloworld.exe,python24.dll,library.zip这些文件。 如果你的helloworld.py脚本中用了已编译的C扩展模块,那么这些模块也会被拷贝在个子目录中,同样,所有的dll文件在运行时都是需要的,除了系统的dll文件。 dist子目录中的文件包含了你的程序所必须的东西,你应将这个子目录中的所有内容一起发布。 默认情况下,py2exe在目录dist下创建以下这些必须的文件: 1、一个或多个exe文件。 2、python##.dll。 3、几个.pyd文件,它们是已编译的扩展名,它们是exe文件所需要的;加上其它的.dll文件,这些.dll是.pyd所需要的。 4、一个library.zip文件,它包含了已编译的纯的python模块如.pyc或.pyo 上面的mysetup.py创建了一个控制台的helloword.exe程序,如果你要创建一个图形用户界的程序,那么你只需要将mysetup.py中的console=["helloworld.py"]替换为windows=["myscript.py"]既可。 py2exe一次能够创建多个exe文件,你需要将这些脚本文件的列表传递给console或windows 的关键字参数。如果你有几个相关联的脚本,那么这是很有用的。 运行下面个命令,将显示py2exe命令的所有命令行标记。 python mysetup.py py2exe --help
Python对Excel操作详解
Python对Excel操作 详解 文档摘要: 本文档主要介绍如何通过python对office excel进行读写操作,使用了xlrd、xlwt 和xlutils模块。另外还演示了如何通过Tcl tcom包对excel操作。 关键字: Python、Excel、xlrd、xlwt、xlutils、TCl、tcom
1Python简介 Python是一种面向对象、直译式电脑编程语言,具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用縮进来定义语句块。 与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。 2Python安装 Python目前的版本已经更新到3.4.0,本文使用的版本为2.7.5,所有的版本都可以在python官网https://www.360docs.net/doc/3a16191594.html,/下载,至于2.x和3.x版本的具体区别也可以在官网查看。 从官网下载了python 2.7.5安装文件python-2.7.5.msi后,直接双击就可以安装python了,可以选择安装路径,我改为C:\Python2.7.5\了,然后一路next就完成安装了,安装完成后在C盘下就多了一个文件夹Python2.7.5。 Python也是一种实时交互语言,可以通过自带的IDLE编写python语句并反馈回显信息,可以通过图1方式调出python IDLE。 图1
ncbi中文说明书
NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心 [url]https://www.360docs.net/doc/3a16191594.html,/[/url] NCBI是NIH的国立医学图书馆(NLM)的一个分支。 NCBI提供检索的服务包括: 1.GenBank(NIH遗传序列数据库):一个可以公开获得所有的DNA序列的注释过的收集。GenBank是由NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库的。它同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。这三个组织每天交换数据。其中的数据以指数形式增长,最近的数据为它已经有来自47000个物种的30亿个碱基。 2.Molecular Databases(分子数据库): Nucleotide Sequence(核酸序列库):从NCBI其他如Genbank数据库中收集整理核酸序列,提供直接的检索。 Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI多个不同资源中编译整理的,方便研究者的直接查询。 Structure(结构)-——关于NCBI结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray晶体衍射和NMR色谱分析。 Taxonomy(分类学)——NCBI的分类数据库,包括大于7万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。其目的是为序列数据库建立一个一致的种系发生分类学。 3.Literature Databases(文献数据库) (1)PubMed是NLM提供的一项服务,能够对MEDLINE上超过1200万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。 (2)PMC/PubMed Center:也是NLM的生命科学期刊文献的数字化存储数据库,用户可以免费获取PMC的文章全文,除了部分期刊要求对近期的文章付费。 (3)OMIM(孟德尔人类遗传):有关人类基因和无序基因的目录数据库由Victor A.McKusick和他的同事共同创造和编辑的,由NCBI网站负责开发,其中也包括对MEDINE众多资源和Entrez系统的序列记录,以及NCBI中其他有关资源的链接。
使用 PYTHON 开发 WINDOWS 桌面程序
使用python 开发windows 应用程序 本人以前一直用的是C++,MFC,毕业到了公司以后,公司用python做流程,我 顺便最近研究了一下用python开发windows 应用程序的整个流程,大体如下: 一、开发前期准备 1.boa-constructor-0.6.1.bin.setup.exe #一个wxWidges 的集成开发环境,简单如Delphi,可以直接拖拽控件,并且和其他集成环境不一样, #它不与集成开发环境的MainLoop冲突,用pythonwin,pyScripter都会冲突,典型 报错就是运行第二次 #程序的时候,直接导致 集成开发环境的强制退出,因为MainLoop冲突了 2.wxPython2.8-win32-unicode-2.8.10.1-py26.exe #wxPython库,提供了用C++写的 windows 组件库wx 3.py2exe-0.6.9.win32-py2.6.exe #打包发布工具,将python写的windows 程序或控 制台程序直接打包成exe 可执行文件,供用户使用 上述三个软件都是基于python2.6的,软件版本一定要配套,因为他们默认的安装路径和python版本有关系,否则会找不到相关库的存在。 二、开发 软件安装完以后,打开BOA,哇塞,拖控件真简单,而且属性啥的和Dephi差 不多,你只要改改属性,代码会自动生成,它生成的控件很漂亮,记得以前用C++6.0开发软件的时候,那个控件真丑,都需要我重新用控件库去绑定优化, 现在不用了~BOA生成的控件,视觉效果相当好~开发软件速度相当快,再也 不用为了软件界面而写太多代码,也不用为了生成一个小程序而生成了很多的 文件,python开发的程序,没有多余的文件,而且文件很小。 三、发布 很多人都想在自己的软件程序写好以后,发布给其他人使用,一方面不希望自 己的代码泄露,一方面以此显出一点成就感,呵呵,可以使用py2exe将你的windows 程序打包发布了!当然,首先你得写个如下的setup.py文件: 代码 1 from distutils.core import setup 2 import py2exe 3 includes = ["encodings", "encodings.*"] 4 options = {"py2exe": 5 { "compressed": 1, 6 "optimize": 2, 7 "includes": includes, 8 "bundle_files": 1 9 } 10 } 11 setup( 12 version = "0.1.0",
一步一步教你使用NCBI
一步一步教你使用NCBI 查找DNA、mRNA、cDNA、Protein、promoter、引物设计、BLAST序列比对等 作者:urbest 2007-8-1 苏州大学生命科学学院
最近看到很多战友在论坛上询问如何查询基因序列、如何进行引物设计、如何使用BLAST进行序列比对……,这些问题在NCBI上都可以方便的找到答案。现在我就结合我自己使用NCBI的一些经历(经验)跟大家交流一下BCBI的使用。希望大家都能发表自己的使用心得,让我们共同进步! 我分以下几个部分说一下NCBI的使用: Part one 如何查找基因序列、mRNA、Promoter Part two 如何查找连续的mRNA、cDNA、蛋白序列 Part three 运用STS查找已经公布的引物序列 Part four 如何运用BLAST进行序列比对、检验引物特异性 特别感谢本版版主,将这个帖子置顶! 从发帖到现在,很多战友对该帖给与了积极的关注,在此向给我投票的(以及想给我投票却暂时不能投票的)各位战友表示真诚的感谢,谢谢各位战友! 请大家对以下我发表的内容提出自己的意见。关于NCBI其他方面的使用也请水平较高的战友给予补充 First of all,还是让我们从查找基因序列开始。 第一部分 利用Map viewer查找基因序列、mRNA序列、 启动子(Promoter) 下面以人的IL6(白细胞介素6)为例讲述一下具体的操作步骤 1.打开Map viewer页面,网址为:https://www.360docs.net/doc/3a16191594.html,/mapview/index.html 在search的下拉菜单里选择物种,for后面填写你的目的基因。操作完毕如图所示: 2.点击“GO”出现如下页面:
UVB使用方法与详解
UVB使用方法与详解 1.使用剂量 具体操作步骤:先用几天每天一次照射来找到每个人的亚红斑量剂量,方 法是第一次每个部位都先照射60秒左右,脸可以40开始,照射后并等第2天是皮肤反应的时候,如果皮肤不红就递增10到20秒,第二天再看皮肤反应直到能出现红润色皮肤症状就是你需要的治疗时间,基本上以后就是红——几天后红消退后照射——第2天红——几天后红消退后循环照射的治疗过程了,具体治疗中还需要注意细节,请自己看以下说明。 当找到能红的时间就进入治疗期,第一次使用的时候,必须从最小的能红 的量使用,然后逐渐增大;一周三次就足够了。但是,这里有一个重要的细节要指出:绝对不是每次都一定要比上次增加一个单位量(10秒左右)。是否增加,完全取决于你的皮肤的承受力。那么如何判断皮肤是否需要加量了呢。 一般来说,正常的、有效的照射后,皮肤的感受是“在照射后8个小时到 一天开始微微发痒,皮肤有点微红”(注意,都是“微”,而不是很痒,很红)。当你是这种感觉的时候,表明你的皮肤对于当前量是能够承受的,并且是有反 应的。因此,当你等2到3天后红消退第二次使用的时候,仍然保持这个量,而不要加量。如果你下次皮肤在照射以后,仍然微微发痒,有点微红,那么说 明依然有效,你第三次还应该坚持这个量。如果这次皮肤没有反应了,即不痒 不红,那么就说明量不够了;那么第三次就应该增加一个单位的使用量。用量
逐渐增加,假如长期好几个月治疗甚至半年后可能增加到好几分钟甚至15-20 分钟的时候,就不要再增加了,因为按照临床大夫来说,这是上限了。当然这 个15到20分钟是说的极限,是最大量,假如长期能在几十秒、几分钟内能每次正常反应是不会使用到最大量的。注意牛皮癣每次用时间比白癜风要多的多,可以80起步,每次加30秒,以皮肤红,有点疼为准。 假如不小心没有把握好照多了时间起泡也不要紧,很快会恢复,这就是有 些病人理解的光疗不好控制,容易起泡的说法,其实仅仅是医院里按死板的方 法加上去不考虑皮肤的耐力。从红到起泡还有一个时间跨度缓冲时间段,所以 按标准来治疗不会产生照射过量的问题,万一自己照多了可以摸点红霉素软膏,照多了起泡也不是大问题,有些机构还故意让起泡,来加快色素的生成,只是 绝大部分人不能忍受这个过程。照射的每次稍微红和很红到起泡都有效果,起 泡后生成色素快点,但是不让皮肤起泡总效果是一样的。 连续照射多次后会产生掉皮现象是正常的,掉皮后可能需要减一个数量级,牛皮癣可以不减少量。当你感觉一个阶段内每次照射后皮肤反应比较足就可以 适当在随后的几次照射减少治疗频率让两次照射间隔时间长点,目的给皮肤一 个恢复的过程,然后再治疗频率再密集点,然后再减少,让皮肤在中间产生一 个恢复的机会。使用过程中出现了治疗中断。比如出差,中断了2个星期。此时,当你继续治疗的时候,必须适度减量。因为停止使用一段时间会导致皮肤 的耐受能力下降,如果还保持中断前的量,可能会导致皮肤无法承受而受到损
NCBI在线BLAST使用方法与结果详解
NCBI在线BLAST使用方法与结果详解 BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA 数据库中进行相似性比较的分析工具。BLAST程序能迅速与公开数据库进行相似性序列比较。BLAST结果中的得分是对一种对相似性的统计说明。 BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。 Blast中常用的程序介绍: 1、BLASTP是蛋白序列到蛋白库中的一种查询。库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。 2、BLASTX是核酸序列到蛋白库中的一种查询。先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。 3、BLASTN是核酸序列到核酸库中的一种查询。库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。 4、TBLASTN是蛋白序列到核酸库中的一种查询。与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。 5、TBLASTX是核酸序列到核酸库中的一种查询。此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。 NCBI的在线BLAST:下面是具体操作方法 1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。不同的blast程序上面已经有了介绍。这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。选择一个要比对的数据库。关于数据库的说明请看NCBI在线blast数据库的简要说明。一般的话参数默认。 3,blast参数的设置。注意显示的最大的结果数跟E值,E值是比较重要的。筛选的标准。最后会说明一下。
使用 PYTHON 开发 WINDOWS桌面程序
使用python 开发windows 应用程序12312412512312 本人以前一直用的是C++,MFC,毕业到了公司以后,公司用python做流程,我 顺便最近研究了一下用python开发windows 应用程序的整个流程,大体如下: 一、开发前期准备 1.boa-constructor-0.6.1.bin.setup.exe #一个wxWidges 的集成开发环境,简单如Delphi,可以直接拖拽控件,并且和其他集成环境不一样, #它不与集成开发环境的MainLoop冲突,用pythonwin,pyScripter都会冲突,典型 报错就是运行第二次 #程序的时候,直接导致 集成开发环境的强制退出,因为MainLoop冲突了 2.wxPython2.8-win32-unicode-2.8.10.1-py26.exe #wxPython库,提供了用C++写的 windows 组件库wx 3.py2exe-0.6.9.win32-py2.6.exe #打包发布工具,将python写的windows 程序或控 制台程序直接打包成exe 可执行文件,供用户使用 上述三个软件都是基于python2.6的,软件版本一定要配套,因为他们默认的安装路径和python版本有关系,否则会找不到相关库的存在。 二、开发 软件安装完以后,打开BOA,哇塞,拖控件真简单,而且属性啥的和Dephi差 不多,你只要改改属性,代码会自动生成,它生成的控件很漂亮,记得以前用C++6.0开发软件的时候,那个控件真丑,都需要我重新用控件库去绑定优化, 现在不用了~BOA生成的控件,视觉效果相当好~开发软件速度相当快,再也 不用为了软件界面而写太多代码,也不用为了生成一个小程序而生成了很多的 文件,python开发的程序,没有多余的文件,而且文件很小。 三、发布 很多人都想在自己的软件程序写好以后,发布给其他人使用,一方面不希望自 己的代码泄露,一方面以此显出一点成就感,呵呵,可以使用py2exe将你的windows 程序打包发布了!当然,首先你得写个如下的setup.py文件: 代码 1 from distutils.core import setup 2 import py2exe 3 includes = ["encodings", "encodings.*"] 4 options = {"py2exe": 5 { "compressed": 1, 6 "optimize": 2, 7 "includes": includes, 8 "bundle_files": 1 9 } 10 } 11 setup( 12 version = "0.1.0",
Python对Excel操作教程
Python 对Excel 操作详解文档摘要: 本文档主要介绍如何通过python 对office excel 进行读写操作,使用了xlrd 、xlwt 和xlutils 模块。另外还演示了如何通过Tcl tcom 包对excel 操作。 关键字: Python、Excel、xlrd 、xlwt 、xlutils、TCl 、tcom 1 Python 简介 Python 是一种面向对象、直译式电脑编程语言,具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用缩进来定义语句块。 与Scheme、Ruby、Perl 、Tcl 等动态语言一样,Python 具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python 虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller 之类的工具可以将Python 源代码转换成可以脱离Python 解释器运行的程序。 2 Python 安装 Python 目前的版本已经更新到3.4.0 ,本文使用的版本为2.7.5 ,所有的版本都可以在python 官网下载,至于 2.x 和 3.x 版本的具体区别也可以在官网查看。 从官网下载了python 2.7.5 安装文件后,直接双击就可以安装python
Python 也是一种实时交互语言,可以通过自带的IDLE 编写python 语句并反馈回显信息,可以通过图 1 方式调出python IDLE 。 图1 也可以在cmd下输入python ,但默认情况下python并没有添加到windows 环境变量中,导致在cmd下输入python的时候出现提示“ 'python'不是内部或外部命令,也不是可运行的程序或批处理文件。”,windows 下可执行文件在运行时首先在当前目录下搜索,因为进入cmd 下默认路径一般为C:\Documents and Settings\Administrator> ,而在这个路径下是找不到python 的,所以提示出错,可以进入到python 安装目录下,然后执行python 就可以进入交互命令行模式下。如果懒的每次都进入python 安装,此时需要将python 安装路径添加到系统变量中,然后windows 在执行命令的时候会去环境变量中查找路径,具体配置如图 2 所示,在Path 中添加python 的安装路径 “C:\Python2.7.5; ”,主要路径后面要加”;”分号表面这是一个路径的结束,此时无论在哪个路径下都可以执行python 调出交互命令行。 图2 3 Python 语法入门 在Python 简介中提到Python 是一种直译式电脑编程语言,体现在语法中,如要将变量 a 赋值为1,Tcl 使用命令%set a 1(本文中为了区分Tcl 和Python 的命令,Tcl 命令前会加上“ %”,否则默认为Python 命令),在python 中命令为a = 1,输出a的值可以直接输入a,也可以通过print语句输出a的值, 命令为print a (在python 3.0 以后版本中,print 不再是一个语句,而是一个函数,所以如果想要输出a,用法为print(a))。在Tel中求1和10的和或者变量之间
NCBI资源介绍及使用手册
NCBI资源介绍及使用手册 NCBI资源介绍 本文目录: NCBI(美国国立生物技术信息中心) 简介 NCBI站点地图 NCBI癌症基因组研究 NCBI-Coffee Break NCBI-基因和疾病 NCBI-UniGene Cluster of Orthologous Groups of proteins(COG)介绍 Gene Expression Omnibus (GEO)介绍 LocusLink介绍 关于RefSeq:NCBI参考序列 NCBI(美国国立生物技术信息中心)简介 介绍 理解自然无声但精妙的关于生命细胞的语言是现代分子生物学的要求。通过只有四个字母来代表DNA化学亚基的字母表,出现了生命过程的语法,其最复杂形式就是人类。阐明和使用这些字母来组成新的“单词和短语”是分子生物学领域的中心焦点。数目巨大的分子数据和这些数据的隐秘而精细的模式使得计算机化的数据库和分析方法成为绝对的必须。挑战在于发现新的手段去处理这些数据的容量和复杂性,并且为研究人员提供更好的便利来获得分析和计算的工具,以便推动对我们遗传之物和其在健康和疾病中角色的理解。 国立中心的建立 后来的参议员Claude Pepper意识到信息计算机化过程方法对指导生物医学研究的重要性,发起了
在1988年11月4日建立国立生物技术信息中心(NCBI)的立法。NCBI是在NIH的国立医学图书馆(NLM)的一个分支。NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。它的使命包括四项任务: 建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统 实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究 加速生物技术研究者和医药治疗人员对数据库和软件的使用。 全世界范围内的生物技术信息收集的合作努力。 NCBI通过下面的计划来实现它的四项目的: 基本研究 NCBI有一个多学科的研究小组包括计算机科学家,分子生物学家,数学家,生物化学家,实验物理学家,和结构生物学家,集中于计算分子生物学的基本的和应用的研究。这些研究者不仅仅在基础科学上做出重要贡献,而且往往成为应用研究活动产生新方法的源泉。他们一起用数学和计算的方法研究在分子水平上的基本的生物医学问题。这些问题包括基因的组织,序列的分析,和结构的预测。目前研究计划的一些代表是:检测和分析基因组织,重复序列形式,蛋白domain和结构单元,建立人类基因组的基因图谱,HIV感染的动力学数学模型,数据库搜索中的序列错误影响的分析,开发新的数据库搜索和多重序列对齐算法,建立非冗余序列数据库,序列相似性的统计显著性评估的数学模型,和文本检索的矢量模型。另外,NCBI研究者还坚持推动与NIH内部其他研究所及许多科学院和政府的研究实验室的合作。 数据库和软件 在1992年10月,NCBI承担起对GenBank DNA序列数据库的责任。NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库。同美国专利和商标局的安排使得专利的序列信息也被整合。 GenBank是NIH遗传序列数据库,一个所有可以公开获得的DNA序列的注释过的收集。GenBank同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。这三个组织每天交换数据。 GenBank以指数形式增长,核酸碱基数目大概每14个月就翻一个倍。最近,GenBank拥有来自47,000个物种的30亿个碱基。 孟德尔人类遗传(OMIM),三维蛋白质结构的分子模型数据库(MMDB),唯一人类基因序列集合
Python对Ecel操作教程
Python对Excel操作详解 文档摘要: 本文档主要介绍如何通过python对office excel进行读写操作,使用了xlrd、xlwt和xlutils模块。另外还演示了如何通过Tcl tcom 包对excel操作。 关键字: Python、Excel、xlrd、xlwt、xlutils、TCl、tcom 1Python简介 Python是一种面向对象、直译式电脑编程语言,具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法简捷和清晰,尽量使用无异
义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用縮进来定义语句块。 与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。 2Python安装 Python目前的版本已经更新到3.4.0,本文使用的版本为2.7.5,所有的版本都可以在python官网https://www.360docs.net/doc/3a16191594.html,/下载,至于2.x和3.x版本的具体区别也可以在官网查看。 从官网下载了python 2.7.5安装文件python-2.7.5.msi后,直接双击就可以安装python了,可以选择安装路径,我改为C:\Python2.7.5\了,然后一路next就完成安装了,安装完成后在C 盘下就多了一个文件夹Python2.7.5。 Python也是一种实时交互语言,可以通过自带的IDLE编写python 语句并反馈回显信息,可以通过图1方式调出python IDLE。
怎么使用NCBI[1]
怎么使用NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心 [url][/url] NCBI是NIH的国立医学图书馆(NLM)的一个分支。 NCBI提供检索的服务包括: 1.GenBank(NIH遗传序列数据库):一个可以公开获得所有的DNA序列的注释过的收集。GenBank是由NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库的。它同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。这三个组织每天交换数据。其中的数据以指数形式增长,最近的数据为它已经有来自47000个物种的30亿个碱基。 2.Molecular Databases(分子数据库): Nucleotide Sequence(核酸序列库):从NCBI其他如Genbank数据库中收集整理核酸序列,提供直接的检索。 Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI多个不同资源中编译整理的,方便研究者的直接查询。 Structure(结构)-——关于NCBI结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray晶体衍射和NMR色谱分析。 Taxonomy(分类学)——NCBI的分类数据库,包括大于7万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。其目的是为序列数据库建立一个一致的种系发生分类学。 3.Literature Databases(文献数据库) (1)PubMed是NLM提供的一项服务,能够对MEDLINE上超过1200万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。 (2)PMC/PubMed Center:也是NLM的生命科学期刊文献的数字化存储数据库,用户可以免费获取PMC的文章全文,除了部分期刊要求对近期的文章付费。 (3)OMIM(孟德尔人类遗传):有关人类基因和无序基因的目录数据库由Victor A.McKusick 和他的同事共同创造和编辑的,由NCBI网站负责开发,其中也包括对MEDINE众多资源和Entrez系统的序列记录,以及NCBI中其他有关资源的链接。
基于esky实现python应用的自动升级详解
基于esky实现python应用的自动升级 一、esky介绍 Esky is an auto-update framework for frozen Python applications. It provides a simple API through which apps can find, fetch and install updates, and a bootstrapping mechanism that keeps the app safe in the face of failed or partial updates. Updates can also be sent as differential patches. Esky is currently capable of freezing apps with py2exe, py2app, cxfreeze and bbfreeze. Adding support for other freezer programs should be easy; patches will be gratefully accepted. We are tested and running on Python 2.7 Py2app will work on python3 fine, the other freezers not so much. Esky是一个python编译程序的自动升级框架,提供简单的api实现应用的自动更新(包括比较版本、更新版本),esky支持py2exe,py2app,cxfreeze以及bbfreeze等多种python打包框架。 二、esky安装及说明 1、pip安装 pip install esky 2、esky说明 https://https://www.360docs.net/doc/3a16191594.html,/cloudmatrix/esky/ 3、esky教学视频 https://www.360docs.net/doc/3a16191594.html,/pycon-au-2010/pyconau-2010--esky--keep-your-frozen-apps-fresh.html 三、esky用法示例 esky用起来比较简单,我们这里以常用的基于wx的windows应用举例。 wxpython下有个wx.lib.softwareupdate 类,对wxpython应用的esky升级进行了二次封装。 网上有个现成的示范例子,具体网址:https://www.360docs.net/doc/3a16191594.html,/2013/07/12/wxpython-updating-your-application-with-esky/ 代码很简单,对其中的关键部分进行注释说明(红色字体部分): 复制代码 # ---------------------------------------- # image_viewer2.py #