Deep Security Antimalware 性能调整设置
Deep Security Anti-malware 性能调整设置
在执行Deep Security 性能测试前需要对产品执行以下配置进行优化:
1. 根据DSVA 保护虚拟机的数量,适当调整DSVA 的物理内存,调整参数请参考Deep
Security Installation Guide 中的内容。
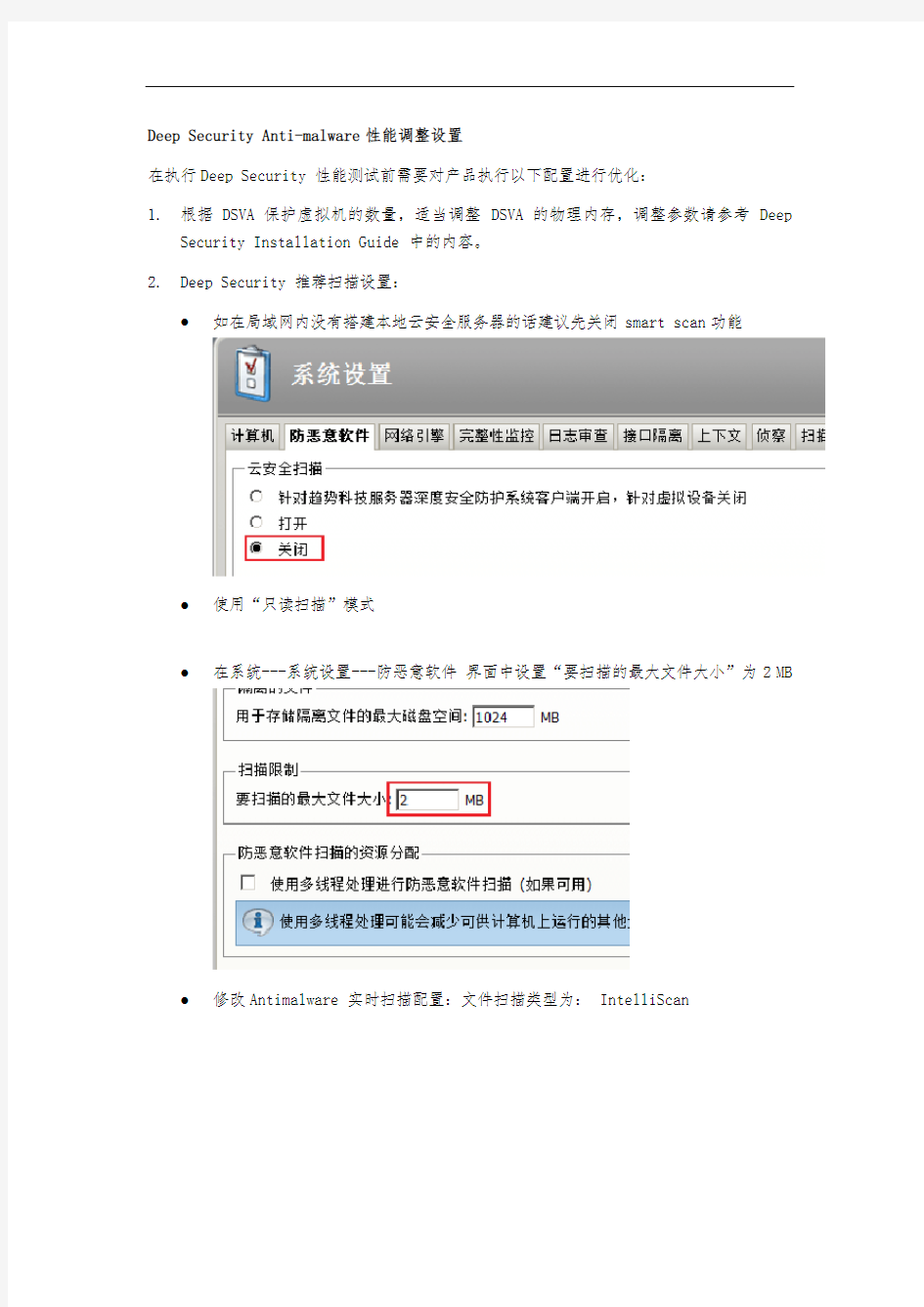
2. Deep Security 推荐扫描设置:
● 如在局域网内没有搭建本地云安全服务器的话建议先关闭smart scan 功能
● 使用“只读扫描”模式
● 在系统---系统设置---防恶意软件 界面中设置“要扫描的最大文件大小”为2 MB
● 修改Antimalware 实时扫描配置:文件扫描类型为:
IntelliScan
DataStage BASIC 语言开发实践
本文着重介绍了如何使用 DataStage BASIC 语言开发一个用户自定义的功能函数,并且以一个完整的 Server Job 实例为读者讲解在 Transformer Stage 中如何使用内置的和自定义的函数来转化数据。文章的最后介绍了如何重用自定义的功能函数。读者定位为具有一定 DataStage 使用经验的开发人员。 DataStage 概述 IBM WebSphere DataStage是一个图形化的进行数据整合的开发环境,可以用来实现数据抽取,转化,净化,加载到目标数据库或者数据仓库中, 即ETL过程(Extract, Transform, Cleansing, Load)。DataStage使用Stage实现对数据的操作。在整个操作数据的过程中,需要创建从不同的数据源抽取数据的Stage,以及用来转化和净化数据的Stage,还需要一些Stage将数据加载到目标数据库中,一个ETL job就是一些被连线连接在一起的Stages,数据则是从一个Stage 流向下一个Stage。关于DataStage的基本使用方法,读者可以参考发表在developWorks中国网站上的《用 IBM WebSphere DataStage 进行数据整合》系列文章。 回页首 Transformer Stage 介绍 在数据整合的整个过程中,很重要的一步就是对抽取数据的格式或者内容进行必要的转化。用户可以在Transformer Stage中,对传入的数据进行任何必要的处理,再把处理好的数据传给下一个Stage。 图1就是一个正在被编辑的Transformer Stage,窗口的上半部分显示了输入与输出的字段之间的对应关系,其中DSLink13是输入的连线名称,DSLink4是输出的连线名称。而窗口下半部分详细说明了每一个输入或者输出字段的定义。
ETL开发指南(DataStage EE)V2.0
DataStage Enterprise Edition 开发指南v2.0
目录 目录.................................................................................................................................................. I 1. 引言.. (1) 1.1编写目的 (1) 1.2帮助使用 (1) 2. 产品概述 (2) 3. 常规应用 (3) 3.1常用组件使用方法 (3) 3.1.1 Sequential file (3) 3.1.2 Annotation (7) 3.1.3 Change Capture Stage (8) 3.1.4 Copy Stage (10) 3.1.5 Filter Stage (11) 3.1.6 Funnel Stage (12) 3.1.7 Tansformer Stage (13) 3.1.8 Sort Stage (14) 3.1.9 LookUp Stage (15) 3.1.10 Join Stage (16) 3.1.11 LookUp Stage 和Join Stage的区别 (17) 3.1.12 Merge Stage (18) 3.1.13 Modify Stage (19) 3.1.14 Data Set Stage (20) 3.1.15 File Set Stage (22) 3.1.16 Lookup File Set Stage (23) 3.1.17 Oracle Enterprise Stage (26) 3.1.18 Aggregator Stage (28) 3.1.19 Remove Duplicates Stage (30) 3.1.20 Compress Stage (31) 3.1.21 Expand Stage (32) 3.1.22 Difference Stage (33) 3.1.23 Compare Stage (36) 3.1.24 Switch Stage (37) 3.1.25 Column Import Stage (39) 3.1.26 Column Export Stage (41) 3.1.27 Teradata Enterprise Stage (43) 3.2常用数据库的连接 (45) 3.2.1 Informix数据库连接 (45) 3.2.2 Oracle数据库连接 (46) 4. 高级应用 (48) 4.1D ATA S TAGE BASIC接口 (48) 4.2自定义S TAGE T YPE (49) 4.2.1 Wrapped Stage (49) 4.2.2 Build Stage (49) 4.2.3 Custom Stage (49) 4.3性能调优 (49) 4.3.1 优化策略 (49) 4.3.2 关键问题分析 (54)
DataStage 工作笔记
1.安装与配置 参考文档:《Planning, Installation, and Configuration Guide.pdf》 1.1服务端与客户端的安装 1.1.1安装拓扑 采用简单的两层部署进行安装,安装拓扑如下图所示: Host1环境如下: (1)硬件环境 CPU:Inetel Core Duo P8600 内存:4GB (2)软件环境 操作系统:Windows Server 2003 EE SP2 C++编译器:Microsoft Visual Studio .NET 2008 Express Edition C++ 1.1.2安装 参考文档:《Planning, Installation, and Configuration Guide.pdf》[pages 198-200] 1.1.3C++编译器配置 参考链接: https://www.360docs.net/doc/d52184626.html,/infocenter/iisinfsv/v8r5/index.jsp?topi
c=/com.ibm.swg.im.iis.productization.iisinfsv.install.doc/topics/wsis inst_set_envars_cpp.html (1)支持的C++编译器,见如下链接的系统要求说明: https://www.360docs.net/doc/d52184626.html,/support/docview.wss?rs=14&uid=swg27016382 1.1.4登陆与安装语言选择 登陆(会话)语言选择中文,DataStage安装语言选择英文,结果Designer里同时有中文和英文,而DB2和WAS都是中文版,如何安装纯英文版的? 解决方法1: 登陆语言选择和安装语言全部选择英文即可安装上纯英文版。 解决方法2: 通过控制面板->区域和语言选项,将语言设置为英语,安装完成后将语言再修改为中文即可。 1.1.5新建用户与凭证(Credentials) 参考文档:《Day 1 Exercise-DS.doc》[Exercise 1: Administration Console] (1)通过Web浏览器登陆Web Console for IBM Information Server,地址如下 (localhost为server端主机名): http://localhost:9080/ibm/iis/console/loginForm.jsp?displayForm=true (2)新建两个用户dsadmin和dsuser,如下图: 权限设置如下: dsadmin:Suite User、DataStage and QualityStage Administrator/User dsadmin:Suite User、DataStage and QualityStage User dsadmin 可以正常使用,但dsuser 只能登陆 Administrator,登陆Designer
数据处理师岗位职责范本
岗位说明书系列 数据处理师岗位职责(标准、完整、实用、可修改)
编号:FS-QG-39727数据处理师岗位职责 Data processor position duties 说明:为规划化、统一化进行岗位管理,使岗位管理人员有章可循,提高工作效率与明确责任制,特此编写。 数据处理工程师全日制本科以上学历(985/211),计算机科学与技术/软件工程/数据相关专业 1、3年以上ETL开发经验,熟悉ETL开发规范和流程; 2、熟练使用DataStage、Informatica、Kettle、Hive、PLSQL、SPARK、MapReduce等工具中的一个或多个,有开发、维护经验; 3、熟练编写存储过程,擅长SQL优化; 4、熟悉Oracle、SQLServer等常用数据库中的一个或多个; 5、熟悉perl、shell脚本,Linux操作系统; 6、有大型数据仓库、BI相关项目的开发经验,精通架构、建模者优先; 7、熟练使用Erwin或PowerDesigner等进行数据建模;
8.以下经验优先考虑:流式处理、日志处理、数据仓库全日制本科以上学历(985/211),计算机科学与技术/软件工程/数据相关专业 1、3年以上ETL开发经验,熟悉ETL开发规范和流程; 2、熟练使用DataStage、Informatica、Kettle、Hive、PLSQL、SPARK、MapReduce等工具中的一个或多个,有开发、维护经验; 3、熟练编写存储过程,擅长SQL优化; 4、熟悉Oracle、SQLServer等常用数据库中的一个或多个; 5、熟悉perl、shell脚本,Linux操作系统; 6、有大型数据仓库、BI相关项目的开发经验,精通架构、建模者优先; 请输入您公司的名字 Foonshion Design Co., Ltd
主流ETL工具选型
主流ETL工具选型 ETL(extract, transform and load)产品乍看起来似乎并不起眼,单就此项技术本身而言,几乎也没什么特别深奥之处,但是在实际项目中,却常常在这个环节耗费太多的人力,而在后续的维护工作中,更是往往让人伤透脑筋。之所以出现这种状况,恰恰与项目初期没有正确估计ETL工作、没有认真考虑其工具支撑有很大关系。 做ETL产品的选型,仍然需要从以前说的四点(即成本、人员经验、案例和技术支持)来考量。在此,主要列举三种主流ETL产品: Ascential公司的Datastage、 Informatica公司的Powercenter、 NCR Teradata公司的ETL Automation、 Oracel 公司的ODI、 国产udis睿智ETL、 其中,ETL Automation相对其他两种有些特别之处,放在后面评述。 旗鼓相当:Datastage与Powercenter: 就Datastage和Powercenter而言,这两者目前占据了国内市场绝大部分的份额,在成本上看水平相当,虽然市面上还有诸如Business Objects公司的Data Integrator、Cognos公司的DecisionStream,但尚属星星之火,未成燎原之势。 谈Datastage和Powercenter,如果有人说这个就是比那个好,那听者就要小心一点了。在这种情况下有两种可能:他或者是其中一个厂商的员工,或者就是在某个产品上有很多经验而在另一产品上经验缺乏的开发者。为什么得出这一结论?一个很简单的事实是,从网络上大家对它们的讨论和争执来看,基本上是各有千秋,都有着相当数量的成功案例和实施高手。确实,工具是死的,人才是活的。在两大ETL工具技术的比对上,可以从对ETL流程的支持、对元数据的支持、对数据质量的支持、维护的方便性、定制开发功能的支持等方面考虑。 一个项目中,从数据源到最终目标表,多则上百个ETL过程,少则也有十几个。这些过程之间的依赖关系、出错控制以及恢复的流程处理,都是工具需要重点考虑。在这一方面,Datastage的早期版本对流程就缺乏考虑,而在6版本则加入Job Sequence的特性,可以将Job、shell脚本用流程图的方式表示出来,依赖关系、串行或是并行都可以一目了然,就直
高级数据分析师工作的基本职责
高级数据分析师工作的基本职责 高级数据分析师需要协助业务数据收集整理,撰写数据分析报告,结合业务对多种数据源进行深度诊断性组合分析。下面是小编整理的高级数据分析师工作的基本职责。 高级数据分析师工作的基本职责1 职责: 1. 负责出行平台层面司乘用户分析,给平台相关业务及策略建设输入洞察和方法; 2. 形成天、周和月度的分析报告,传递给公司管理层并进行定期汇报; 3. 可独立完成针对特定问题的分析解读,支持临时型研究项目,产出用户留存及迁移的分析结论,用于输出给各品类优化营销产品的运营策略; 4. 参与产品上线前的预估,上线时的数据埋点,上线后的效果评估及优化,构建乘客端营销工具的分析体系。
5. 保持数据敏感,监控与发现问题、将数据转化为可落地的和有说服力的洞察,辅助推进业务决策 岗位要求: 1、数据分析相关工作经验,了解用户需求,互联网相关领域优先,应用数学,统计学,计算机, 经济学相关专业硕士优先; 2、具备大数据的处理能力,掌握hive、SQL等相关数据提取工具,熟练使用R或Python、excel、SAS/SPSS、PPT等工具; 3、具有较强的思维逻辑能力,良好的数据敏感度,能从海量数据提炼核心结果;有丰富的数据分析、挖掘、建模的经验; 4、具备良好的沟通协调能力,有独立开展分析研究项目经验; 5、一定的抗压能力和和团队精神;能有效的推动数据结论的落地 高级数据分析师工作的基本职责2 职责: 1.对海量业务数据进行处理和分析,发现和跟踪其中的问题。能够从业务和产品的角度出发,利用数据发现产品、系统或是业务的瓶颈,并提出优化的方案
2.分析海量用户行为数据,优化用户生命周期流程,提升用户规模 3.利用数据挖掘,机器学习等技术解决实际问题,比如实现模块或流程自动化,业务报表系统的建设,离线数据流程的建设,数据可视化等 4.建立各种业务逻辑模型和数学模型,帮助公司改善运营管理,节省成本 任职要求 1.计算机、数学、统计相关专业,本科及以上学历 2.熟练掌握:mysql、hdfs/hive/数据库使用,较强的数据库及SQL 能力,并对Hadoop 技术体系有所了解和研究 3.具备数据敏感性和探知欲、分析、解决问题的能力,能够承受工作中的压力,专注数据的价值发现和变现转化 4.工作认真、负责、仔细,有良好的团队合作精神,良好的分析问题能力、沟通技巧及数据呈现能力 高级数据分析师工作的基本职责3 职责: 1、研究大数据新技术分析发展方向;
数据仓库工程师岗位的主要职责说明
数据仓库工程师岗位的主要职责说 明 数据仓库工程师负责数据仓库系统与业务系统的接口设计和确认工作。下面是小编为您精心整理的数据仓库工程师岗位的主要职责说明。 数据仓库工程师岗位的主要职责说明1 职责: 1、负责数据仓库建模和ETL技术工作,确保项目实施过程中的数据源分析,能顺利有序地进行; 2、熟练掌握ETL设计过程,参与数据平台架构的设计、开发、流程优化及解决ETL相关技术问题; 3、与用户和项目组进行有效沟通,采集项目需求,并提出相应的解决方案; 4、有ERP开发或实施经验者优先; 5、参与海量数据情况下的数据库调优等工作;
6、按照项目推进情况,完成主管交付的临时性任务; 7、能够按照公司全面质量管理的要求,高质量完成各类技术支持工作。 岗位要求: 1、计算机相关专业本科以上学历,2年工作经验; 2、具备独立完成ETL开发、设计数据仓库流程,精通Oracle, MS SQL Server 等主流数据库,具备独立设计数据库和编写存储过程的能力; 3、掌握Java,Python等任意一门开发语言,可以独立开发模块; 4、精通数据库SQL调优; 5、有多维数据仓库工作经验优先; 6、具备财务基础知识或者ERP基础知识者优先; 7、有DataStage,informatica,kettle经验者优先; 8、逻辑思维能力强,对数据敏感,有较强学习能力和创新思维; 9、可以独立与客户进行需求沟通,工作认真负责,团队意识强;
数据仓库工程师岗位的主要职责说明2 职责: 1、负责金融数据的收集、整理与分析; 2、负责oracle数据仓库的设计、开发搭建及运行维护; 3、依据业务需求优化数据存储结构; 4、协助项目其他成员设计关键的SQL语句和触发器、存储过程、表等; 5、通过数据库的日常检查,对性能较差的SQL语句提出优化方案; 6、协助搭建量化投资策略平台。 要求: 1、计算机网络、统计、数学或信息技术本科及以上学历; 2、能编写Oracle简单脚本,可以独立在windows和linux环境下搭建管理oracle服务器数据库; 3、对linux,unix 操作系统有了解,熟练使用shell,python等脚本语言处理数据; 4、至少一年以上的的数据分析、挖掘、清洗和建模的经验;
华为各平台技能要求
华为各平台技能要求 说明:下面各平台级别及技能要求都是华为项目所需要的,未列出的级别及技能华为10年还没有需求。 J2EE平台 三级 计算机相关专业,本科三年以上本领域工作经验;技能要求:掌握J2EE架构;熟练掌握IBM WSAD 版本5.1以上或IBM RAD开发工具;熟练掌握Struts框架开发技术;熟练掌握Java 语言编程技术;熟悉UML语言,能够理解UML设计图;熟练掌握Oracle SQL开发与存储过程开发。具有三年以上的Java开发经验,2年以上的基于J2EE技术规范的WEB开发经验 二级 计算机相关专业,本科两年以上或大专四年以上本领域工作经验;技能要求:掌握Java编程语言;了解J2EE架构;熟练掌握java script,html、Jsp、Servlet、JavaBean等web 开发技术;掌握标准SQL语言,有Oracle Sql开发经验。了解UML语言;掌握IBM WSAD 版本5.1以上或IBM RAD开发工具或Eclipse开发工具;熟悉WEB/J2EE服务器的使用,可熟练配置使用Tomcat,Apache。参与过系统的设计与开发工作,2年以上Java开发经验。 Net平台 三级 计算机相关专业,本科三年以上本领域工作经验,技能要求:除满足二级人员要求外,熟练掌握.Net开发框架,熟练掌握https://www.360docs.net/doc/d52184626.html,开发和C#开发;熟悉IIS服务器配置与管理;熟悉Web Service,精通XML文件的解析。具有三年以上的.Net开发经验,1年以上的基于.Net 技术规范的WEB开发经验。有能力解决项目组内重大问题、能指导设计开发 二级 计算机相关专业,本科两年以上或大专四年以上本领域工作经验,技能要求:掌握C#开发语言;熟悉.Net多层架构;熟练掌握java script,html、https://www.360docs.net/doc/d52184626.html,等web开发技术;有COM/COM+的开发经验;掌握标准SQL语言,有较好的基于Oracle或Sql Server的 Sql开发经验。了解UML语言;掌握Microsoft Visual Studio (版本 2003,2005)开发工具;熟悉配置使用IIS服务器。参与过中等规模系统的设计与开发工作;与他人能够保持良好沟通与合作。 Oracle(开发)平台 三级 1、沟通能力强,理解能力强,工作态度好; 2、Oracle Form,Oracle Report,Oracle数据库开发3年以上工作经验; 3、至少参与1个基于oracle开发的中大型项目; 4、使用过版本管理工具;
Datastage开发经验
NEUSOFT Datastage开发经验 开发手册 刘石磊 2014/7/23
目录 第一章 Datastage连接配置 (3) 1.配置DS连接 (3) 2.打开DS designer,选择服务层主机名,输入用户名密码,然后在项目中选择对应的开发项目,确定后进入DS开发界面 (3) 第二章 Datastage Designer开发 (4) 1.在Jobs目录下建立自己的开发目录层级 (4) 2.job调用关系 (4) 3.job能调用的组件 (5) 4.开发一个job (6) 5.导入表定义(Table Definitions) (17) 6.开发一个sequence (20) a.新建Sequence,将并行job拖入设计面板 (20) b.保存编译后即可运行 (20) 7.运行job (21) 8.全局参数&环境变量设置 (23) 9.在job和sequence中调用参数 (24) a.Job中变量参数设置 (24) b.Sequence中变量参数设置 (27) 10.调用存储过程 (28) a.新建一个job,作业属性配置如下图 (28) b.调用存储过程,在查询存储过程运行状态的表的sql前—Before SQL,调用存储 过程CALL ETL.SP_IPRO_ETL_ALL('#$p_etl_date#'); (28) 11.运行job失败时怎么办 (29) 第三章 Datastage Director使用 (30) a.只有处于已编译和已完成状态的job或sequence才能直接运行 (30) b.查看报错日志 (30) c.job日志过滤 (31) d.再次运行job (32) 第四章 Datastage Designer其它功能 (33)
数据仓库面试题
数据仓库及BI工程师面试题集锦 前言 1、介绍一下项目经验、项目中的角色。 一、数据库 1、Oracle数据库,视图与表的区别?普通视图与物化视图的区别?物化视图的作 用? 2、Oracle数据库,有哪几类索引,分别有什么特点? 3、Union与Union All的区别? 4、对游标的理解?游标的分类?使用方法? 5、如何查找和删除表中的重复数据?给出方法或SQL。 6、不借助第三方工具,怎么查看SQL的执行计划? 7、创建索引有哪些需要注意的要点? 8、Oracle数据库中,有哪几种分区?各自特点是什么?作用是什么?分区索引的分 类和作用? 9、表T(a,b,c,d),要根据字段c排序后取第21—30条记录显示,请给出sql。 10、备份如何分类?归档是什么含义? 11、如果系统现在需要在一个很大的表上创建一个索引,需要考虑那些因素,如何做到 尽量减小对应用的影响? 12、是否有海量数据处理经验?有何方法? 二、ETL工具 1、Informatica中,Update组件叫什么?更新机制? 2、Informatica中,LookUp组件有哪几类?区别是什么? 3、Informatica中,如何调用存储过程? 4、Informatica中,工作流控制有哪些组件? 5、Informatica优化方案? 6、DataStage的JOB有哪些类型?特点分别是什么?
7、DataStage中,如何设置parallel job并行运行? 8、DataStage中,Join Stage 与Lookup Stage组件在使用上有何区别? 9、DataStage的优化方案? 三、模型设计 1、有哪几种模型设计方法?特点分别是什么? 2、模型设计的步骤? 3、维度模型的设计方法? 4、模型设计的思路?业务需求驱动?数据驱动? 3、模型设计经验说明。在概念模型设计、逻辑模型设计以及物理模型设计几个阶段主 要的工作是什么? 四、Cognos开发 1、Cube刷新方案? 2、报表数据权限控制方案? 3、Cube增量刷新方案? 五、Shell开发 1、在Unix/Linux中,查看磁盘空间可以用哪些命令? 2、在Unix/Linux中,压缩和解压缩文件可以用哪些命令? 3、sed命令的作用? 4、在Unix/Linux中,添加用户用什么命令? 5、在Unix/Linux中,查看文件行数什么命令? 六、数据仓库设计 1、增量数据获取方案? 2、请解释以下概念:数据集市、事实表、维度表、OLAP 3、元数据管理在数据仓库中的运用有何心得?
informatica与datastage对比
Informatica VS IBM-DataStage
对比项Informatica PowerCenter IBM Datastage 产品完整性对 比 数据整合部分:PowerCenter,是业界公认领导者 数据质量管理:Data Quality,成熟稳定技术,在 中国有大规模应用的成功案例。 实时数据捕获:PowerExchange,业界领先实时 采集技术,支持广泛数据源的CDC和Realtime, 与PowerCenter无缝集成。 元数据管理:Metadata Manager,是业界领先的 企业级元数据管理平台,可做到字段级的元数据 各项分析,有广泛的元数据采集接口,图形化无 需编程,并可自动维护变更。 数据整合部分:Datastage,属于业 界一类产品 数据质量管理:QualityStage,收购 的技术,不是主要其主要产品组成 实时数据捕获:MQ和DataMirror 的技术,技术复杂,与DataStage 是不同风格产品,产品的耦合度极 差。 元数据管理:MetaStage,几乎免费 的产品,应用性极差,并不能管理 企业级的元数据。而新推出的产品 与旧有产品线耦合度差,并未经过 市场的考验。 开发人员的使用效率 Informatica 是全图形化的开发模式,不需要编 码,工具易使用,界面友好、直观。 专业的三天培训,可使开发人员快速入门,进行 开发设计。 开发人员只要懂得数据库知识,即可。 Informatica 产品是以元数据为核心的,其开发过 程中,所有的元数据,包括规则和过程,均是可 复用,共享的。 经过简单配置即可支持大数据量的处理。 Informatica是完全基于引擎级别的,所有功能模 块化,扩展性强,维护成本低。 虽然也是图形化的界面,但复杂的 转换过程,里面嵌入了很多类Basic 脚本的成份。 要求开发人员,有编程语言基础。 在处理大数据量,必须使用 Datastage企业版。但如果客户原先 使用的Datastage 标准版,其作业 的版本移植问题很大。这两个版本 的工作平台、机制完全不同。作业 移植,大概要有70%左右需要重新 开发定义。 Datastage是基于脚本级的,底层基 于PICK BASIC和COBOL(Main Frame上)内核开发,要求不同的 平台需要不同的系统环境变量配 置。 应用需求的改变和拓展的支 持 Informatica 是以元数据为核心的平台,现在完全 支持SOA的思想,其最大特点就是完全支持松 耦合.可拆分成Service 进行调用.这样需求变 化,其需改动的部分,其影响会很小。 开发转换过程,均为共享的、可复用的。 元数据发生变化,可通过View Dependencies功 能,生成所有相关对象的报表,方便跟踪、校验, 以应对需求的变化。 应用需求变化,调整作业后,直接可以运行,不 需要重新编译。 作业移植等,也不需要重新编译。与平台和数据 库无关。 支持跨操作系统的集群技术,可方便的进行平台 级的扩展。 需求发生变化,需调整相应的作 业。如果是复杂需求,改动已有的 脚本,其维护成本相对比较高。 每次作业变化调整,均需重新编 译,才可执行。 Datastage企业版与Datastage 标准 版,其作业的版本移植问题很大。 这两个版本的工作平台、机制完全 不同。作业移植,大概要有70%左 右需要重新开发定义。一旦新的需 求,需要企业版,其移植和再次开 发,工作量要增加很多。 也因为两个版本的不兼容和脚本 编译的开发模式,使之产品面对变
datastage经验总结
目录 1 如何重新启动DataStage服务器, 步骤如下: (4) 2 DataStage开发经验积累: (5) 2.1模板开发 (5) 2.2通过S ERVER S HARED C ONTAINER在P ARALLEL J OB中添加S ERVER J OB S TAGE (5) 2.3去除不需要的字段 (5) 2.4T RANSFORMER S TAGE的使用 (5) 2.5L OOK UP/JOIN 空值处理 (6) 2.6D ATA S TAGE中默认和隐式类型转换时注意的问题 (6) 2.7配置一个INPUT或OUTPUT,就VIEW DATA一下,不要等到RUN时再回头找ERROR (6) 2.8D ATA型数据是比较麻烦的 (6) 2.9行列互换之H ORIZONTAL P IVOT(P IVOT S TAGE) (6) 2.10行列互换之V ERTICAL P IVOT (7) Server Job的做法: (7) Sequence File--- Transform--- Hash File (7) Parallel Job的做法:(按照SERVER JOB的做法,然后改成串行方式也能实现) (8) 2.11O RACLE EE S TAGE在VIEW数据时出现的错误及解决方法 (9) 2.12D ATA S TAGE SAP S TAGE的使用 (10) 2.13C OLUM I MPORT S TAGE的使用 (10) 2.14C OLUM E XPORT S TAGE的使用 (12) 2.15G OT ERROR:C ANNOT FIND ANY PROCESS NUMBER FOR STAGES IN J OB J OBNAME解决 (13) 2.16U NABLE TO CREATE RT_CONFIG NNN (14) 2.17查看JOB和CLIENT的对应的后台进程 (14)
DS开发经验总结
DS开发经验总结
目录 1、特定控件.................................................................................................................................- 3 - 1.1、Aggregator(简称AGG) ......................................................................................................- 3 - 1. 2、Lookup( 简称LKP) ............................................................................................................- 5 - 1. 3、Funnel(简称FNL) ..............................................................................................................- 5 - 1.4 Remove_Duplicates ..........................................................................................................- 6 - 1.5 Join ....................................................................................................................................- 6 - 1.6 ABAP_EXE_for_R3 Stage ......................................................................................................- 7 - 1.7、文件的使用: ..................................................................................................................- 9 - 1.7.1、DateSet(简称DS) .......................................................................................................- 9 - 1.7.2、Sequential File(简称SQ) ............................................................................................- 9 - 1.8、DB2 API .......................................................................................................................... - 10 - 1.9、Oracle Enterprise ........................................................................................................... - 11 - 2、非特定控件.......................................................................................................................... - 12 - 2.1、关于分区清除 ............................................................................................................... - 12 - 2.2、Runtime column propagation选项 ............................................................................... - 12 - 2. 3、ETL开发过程中产生的问题......................................................................................... - 12 - 2.4 关于程序中使用手工文件 ............................................................................................. - 13 -