2012信息编码实验
信源编码的实验报告

一、实验目的1. 理解信源编码的基本原理和过程。
2. 掌握几种常见的信源编码方法,如哈夫曼编码、算术编码等。
3. 分析不同信源编码方法的编码效率。
4. 培养动手实践能力和分析问题、解决问题的能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 实验工具:PyCharm IDE三、实验内容1. 哈夫曼编码2. 算术编码四、实验步骤1. 实验一:哈夫曼编码(1)读取信源数据,统计每个字符出现的频率。
(2)根据字符频率构建哈夫曼树,生成哈夫曼编码表。
(3)根据哈夫曼编码表对信源数据进行编码。
(4)计算编码后的数据长度,并与原始数据长度进行比较,分析编码效率。
2. 实验二:算术编码(1)读取信源数据,统计每个字符出现的频率。
(2)根据字符频率构建概率分布表。
(3)根据概率分布表对信源数据进行算术编码。
(4)计算编码后的数据长度,并与原始数据长度进行比较,分析编码效率。
五、实验结果与分析1. 实验一:哈夫曼编码(1)信源数据:{a, b, c, d, e},频率分别为{4, 2, 2, 1, 1}。
(2)哈夫曼编码表:a: 0b: 10c: 110d: 1110e: 1111(3)编码后的数据长度:4a + 2b + 2c + 1d + 1e = 4 + 2 + 2 + 1 + 1 = 10(4)编码效率:编码后的数据长度为10,原始数据长度为8,编码效率为10/8 = 1.25。
2. 实验二:算术编码(1)信源数据:{a, b, c, d, e},频率分别为{4, 2, 2, 1, 1}。
(2)概率分布表:a: 0.4b: 0.2c: 0.2d: 0.1e: 0.1(3)编码后的数据长度:2a + 2b + 2c + 1d + 1e = 2 + 2 + 2 + 1 + 1 = 8(4)编码效率:编码后的数据长度为8,原始数据长度为8,编码效率为8/8 = 1。
六、实验总结1. 哈夫曼编码和算术编码是两种常见的信源编码方法,具有较好的编码效率。
信息论与编码实验2-实验报告

信息论与编码实验2-实验报告信息论与编码实验 2 实验报告一、实验目的本次信息论与编码实验 2 的主要目的是深入理解和应用信息论与编码的相关知识,通过实际操作和数据分析,进一步掌握信源编码和信道编码的原理及方法,提高对信息传输效率和可靠性的认识。
二、实验原理(一)信源编码信源编码的目的是减少信源输出符号序列中的冗余度,提高符号的平均信息量。
常见的信源编码方法有香农编码、哈夫曼编码等。
香农编码的基本思想是根据符号出现的概率来分配码字长度,概率越大,码字越短。
哈夫曼编码则通过构建一棵最优二叉树,为出现概率较高的符号分配较短的编码,从而实现平均码长的最小化。
(二)信道编码信道编码用于增加信息传输的可靠性,通过在发送的信息中添加冗余信息,使得在接收端能够检测和纠正传输过程中产生的错误。
常见的信道编码有线性分组码,如汉明码等。
三、实验内容与步骤(一)信源编码实验1、选取一组具有不同概率分布的信源符号,例如:A(02)、B (03)、C(01)、D(04)。
2、分别使用香农编码和哈夫曼编码对信源符号进行编码。
3、计算两种编码方法的平均码长,并与信源熵进行比较。
(二)信道编码实验1、选择一种线性分组码,如(7,4)汉明码。
2、生成一组随机的信息位。
3、对信息位进行编码,得到编码后的码字。
4、在码字中引入随机错误。
5、进行错误检测和纠正,并计算错误纠正的成功率。
四、实验结果与分析(一)信源编码结果1、香农编码的码字为:A(010)、B(001)、C(100)、D (000)。
平均码长为 22 比特,信源熵约为 184 比特,平均码长略大于信源熵。
2、哈夫曼编码的码字为:A(10)、B(01)、C(111)、D (00)。
平均码长为 19 比特,更接近信源熵,编码效率更高。
(二)信道编码结果在引入一定数量的错误后,(7,4)汉明码能够成功检测并纠正大部分错误,错误纠正成功率较高,表明其在提高信息传输可靠性方面具有较好的性能。
信息论与编码技术实验报告
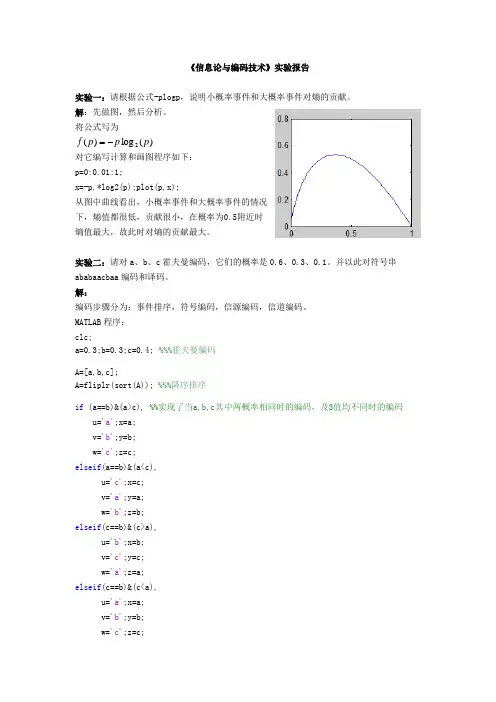
《信息论与编码技术》实验报告实验一:请根据公式-plogp ,说明小概率事件和大概率事件对熵的贡献。
解:先做图,然后分析。
将公式写为)(log )(2p p p f -=对它编写计算和画图程序如下:p=0:0.01:1;x=-p.*log2(p);plot(p,x);从图中曲线看出,小概率事件和大概率事件的情况下,熵值都很低,贡献很小,在概率为0.5附近时熵值最大,故此时对熵的贡献最大。
实验二:请对a 、b 、c 霍夫曼编码,它们的概率是0.6、0.3、0.1。
并以此对符号串ababaacbaa 编码和译码。
解:编码步骤分为:事件排序,符号编码,信源编码,信道编码。
MATLAB 程序:clc;a=0.3;b=0.3;c=0.4; %%%霍夫曼编码A=[a,b,c];A=fliplr(sort(A)); %%%降序排序if (a==b)&(a>c), %%实现了当a,b,c 其中两概率相同时的编码,及3值均不同时的编码 u='a';x=a;v='b';y=b;w='c';z=c;elseif (a==b)&(a<c),u='c';x=c;v='a';y=a;w='b';z=b;elseif (c==b)&(c>a),u='b';x=b;v='c';y=c;w='a';z=a;elseif (c==b)&(c<a),u='a';x=a;v='b';y=b;w='c';z=c;elseif(a==c)&(a>b),u='a',x=a;v='c',y=c;w='b',z=b;elseif(a==c)&(a<b),u='b';x=b;v='a';y=a;w='c';z=c;elseif A(1,1)==a,u='a';x=a;elseif A(1,1)==b,u='b';x=b;elseif A(1,1)==c,u='c';x=c;endif A(1,2)==a,v='a';y=a;elseif A(1,2)==b,v='b';y=b;elseif A(1,2)==c,v='c';y=c;endif A(1,3)==a,w='a';z=a;elseif A(1,3)==b,w='b';z=b;elseif A(1,3)==c,w='c';z=c;endend %%%x,y,z按从大到小顺序存放a,b,c的值,u,v,w存对应字母if x>=(y+z),U='0';V(1)='0';V(2)='1';W(1)='1';W(2)='1';else U='1';V(1)='0';V(2)='0';W(1)='1';W(2)='0';enddisp('霍夫曼编码结果:')if u=='a',a=fliplr(U),elseif u=='b',b=fliplr(U),else c=fliplr(U),end if v=='a',a=fliplr(V),elseif v=='b',b=fliplr(V),else c=fliplr(V),end if w=='a',a=fliplr(W),elseif w=='b',b=fliplr(W),else c=fliplr(W),end %%%编码步骤为:信源编码,信道编码disp('信源符号序列:')s='ababaacbaa' %%%信源编码q=[];for i=s;if i=='a',d=a;elseif i=='b';d=b;else d=c;end;q=[q,d];endm=[]; %%%符号变数字for i=q;m=[m,str2num(i)];endP=[1,1,1,0;0,1,1,1;1,1,0,1];G=[eye(3),P];%%%信道编码%%%接下来的for循环在程序中多次使用,此处作用是将已编码组m每3个1组放入mk中进行运算之后存入Ck数组中,每次mk中运算结束之后清空,再进行下一组运算,而信道编码结果数组C则由C=[C,Ck]存入每组7个码。
CMI码编码与译码-A11-2012通信大型实验报告

实验报告题目:CMI码编码译码实验报告组员通信901 李虹毅通信901 潘凯波通信901 韦磊组号A112012年2月目录一概述 (1)1.1 CMI码的简介 (1)1. 2 CMI码的优点 (1)二实验原理 (1)2.1 编码原理 (1) (2)2.2 译码原理 (2)三实验设计步骤(含程序及仿真图、测试图等) (3)3.1 实验模块程序 (3)3.2 综合电路图 (7)3.3 仿真波形 (8)四硬件调试下载 (8)五实验总结和心得体会 (9)一概述1.1 CMI码的简介1、CMI码是传号反转码的简称,它是一种应用于PCM四次群和光纤传输系统中的常用线路码型,具有码变换设备简单、有较多的电平跃变,含有丰富的定时信息,便于时钟提取,有一定的纠错能力等优点。
在高次脉冲编码调制终端设备中广泛应用作接口码型,在速率低于8 448 Kb/s的光纤数字传输系统中也被建议作为线路传输码型。
在CMI编码中,输入码字0直接输出01码型,较为简单。
对于输入为1的码字,其输出CMI码字存在两种结果00或11码,因而对输入1的状态必须记忆。
同时,编码后的速率增加一倍,因而整形输出必须有2倍的输入码流时钟。
在CMI解码端,存在同步和不同步两种状态,因而需进行同步。
同步过程的设计可根据码字的状态进行:因为在输入码字中不存在10码型,如果出现10码,则必须调整同步状态。
在该功能模块中,可以观测到CMI在译码过程中的同步过程。
1. 2 CMI码的优点1、不存在直流分量,并且具有很强的时钟分量,有利于在接收端对时钟信号进行恢复;2、具有检错能力,这是因为1码用00或11表示,而0码用01码表示,因而CMI码流中不存在10码,且无00与11码组连续出现,这个特点可用于检测CMI的部分错码。
二实验原理2.1 编码原理编码流程框图:m序列输入根据编码规则2位并行输出经过并串转换模块,并输出结束CMI编码规则见表4.2.1所示:因而在CMI编码中,输入码字0直接输出01码型,较为简单。
信息论与编码实验报告

信息论与编码实验报告一、实验目的本实验主要目的是通过实验验证信息论与编码理论的基本原理,了解信息的产生、传输和编码的基本过程,深入理解信源、信道和编码的关系,以及各种编码技术的应用。
二、实验设备及原理实验设备:计算机、编码器、解码器、信道模拟器、信噪比计算器等。
实验原理:信息论是由香农提出的一种研究信息传输与数据压缩问题的数学理论。
信源产生的消息通常是具有统计规律的,信道是传送消息的媒体,编码是将消息转换成信号的过程。
根据信息论的基本原理,信息的度量单位是比特(bit),一个比特可以表示两个平等可能的事件。
信源的熵(Entropy)是用来衡量信源产生的信息量大小的物理量,熵越大,信息量就越多。
信道容量是用来衡量信道传输信息的极限容量,即信道的最高传输速率,单位是比特/秒。
编码是为了提高信道的利用率,减少传输时间,提高传输质量等目的而进行的一种信号转换过程。
常见的编码技术有霍夫曼编码、香农-费诺编码、区块编码等。
三、实验步骤1.运行编码器和解码器软件,设置信源信息,编码器将信源信息进行编码,生成信道输入信号。
2.设置信道模拟器的信道参数,模拟信道传输过程。
3.将信道输出信号输入到解码器,解码器将信道输出信号进行解码,恢复信源信息。
4.计算信道容量和实际传输速率,比较两者的差异。
5.改变信道参数和编码方式,观察对实际传输速率的影响。
四、实验结果与分析通过实验,我们可以得到不同信道及编码方式下的信息传输速率,根据信道参数和编码方式的不同,传输速率有时会接近信道容量,有时会低于信道容量。
这是因为在真实的传输过程中,存在信噪比、传输距离等因素导致的误码率,从而降低了实际传输速率。
在实验中,我们还可以观察到不同编码方式对传输速率的影响。
例如,霍夫曼编码适用于信源概率分布不均匀的情况,可以实现数据压缩,提高传输效率。
而区块编码适用于数据容量较大的情况,可以分块传输,降低传输错误率。
此外,通过实验我们还可以了解到信息论中的一些重要概念,如信源熵、信道容量等。
视觉编码实验报告

2.1登录并打开PsyTech心理实验软件主界面,选中实验列表中的“短时记忆的视觉和听觉编码”,点击“进入实验”到“操作向导”窗口。使用默认参数设置“72次”,即重复呈现2遍。然后点击“开始实验”按钮进入指导语界面。也可以直接点击”正式实验”按钮开始。
2.2指导语如下:
这是一个比较字母异同的实验。实验开始后屏幕将呈现多组大小写字母(每组一对)请你使用1号反应盒对呈现的每组字母进行判断,判断原则如下:1、形状相同或形状不同读音相同,按“+”键;2、如果形状和读音都不同,则按“-”号键。要求在判断准确的前提下反应越快越好。
本实验的目的是通过测定被试对短时记忆信息的编码,掌握反应时测量技术在认知研究中的应用以及探讨短时记忆的信息编码方式和编码过程。
2方法
2.1被试
两名在校大学生,男,21岁,应用心理学专业
2.2仪器、材料
仪器:计算机与PsyTech心理实验系统。
材料:英文字母大写A、B和小写a、b的不同组合,其中AA(6次)、BB(6次)。Aa(6次)、Bb(6次)、AB(3次)、BA(3次),Ab(3次)、Ba(3次)共36次(参数设置中选72次则重复呈现2遍;108次则重复呈现3遍)。
实验编号
032107201317*
实验名称
短时记忆的视觉和听觉编码
实验类型
综合性
实验时间
2012-3-14
实验地点
北6-528
小组成员
倪安品、诸葛一朔
短时记忆的视觉和听觉编码
10应用心理学倪安品诸葛一朔
摘要:实验基于Posner的经典实验,通过字母的视觉匹配和名称匹配的实验证实:至少在部分时间里,信息在短时记忆中是以视觉编码的。通过被试不同刺激(同音同形、同音异形、异音异形)的呈现进行判断一致与否,记录反应时,根据所得数据测出被试正确判断的平均反应时,分析不同刺激条件下的反应时差异,以及说明差异的问题。结果再次证实了已有的经典结论。
信息论与编码实验报告
信息论与编码实验报告实验课程名称:赫夫曼编码(二进制与三进制编码)专业信息与计算科学班级信息与计算科学1班学生姓名李林钟学号 2013326601049指导老师王老师一、实验目的利用赫夫曼编码进行通信可以大大提高通信利用率,缩短信息传输时间,降低传输成本。
赫夫曼编码是信源编码中最基本的编码方法。
●理解赫夫曼编码,无论是二进制赫夫曼编码,还是m 进制赫夫曼编码,都要理解其编码原理和编码步骤。
● 回顾无失真信源编码定理,理解无失真编码的基本原理和常用编码方法。
●掌握二进制赫夫曼编码和m 进制赫夫曼编码的基本步骤,能计算其平均码长,编码效率等。
●应用二进制赫夫曼编码或m 进制赫夫曼编码处理简单的实际信源编码问题。
二、实验环境与设备1、操作系统与编程软件:windows 操作系统,cfree5.0, Visual C++ 6.0。
2、编程语言:C 语言以及C++语言 三、实验内容1. 二进制赫夫曼编码原理及步骤: (1)信源编码的计算设有N 个码元组成的离散、无记忆符号集,其中每个符号由一个二进制码字表示,信源符号个数n 、信源的概率分布P={p(s i )},i=1,…..,n 。
且各符号xi 的以li 个码元编码,在变长字编码时每个符号的平均码长为∑==ni li xi p L 1)( ;信源熵为:)(log )()(1xi p xi p X H ni ∑=-= ;唯一可译码的充要条件:11≤∑=-ni Ki m ;其中m 为码符号个数,n 为信源符号个数,Ki 为各码字长度。
(2)二元霍夫曼编码规则(1)将信源符号依出现概率递减顺序排序。
(2)给两个概率最小的信源符号各分配一个码位“0”和“1”,将两个信源符号合并成一个新符号,并用这两个最小的概率之和作为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源。
称为信源的第一次缩减信源,用s1 表示。
(3)将缩减信源 s1 的符号仍按概率从大到小顺序排列,重复步骤(2),得到只含(n-2)个符号的缩减信源s2。
信息论综合性实验报告 Huffman编码及译码 代码
Xx大学yy学院综合性设计性实验报告专业班级:学号:姓名:实验所属课程:信息论与编码技术实验室(中心):信息科学与工程学院软件中心指导教师:实验完成时间: 2012 年 12 月 9 日一、设计题目:Huffman编码及译码二、实验内容及要求:<一>实验内容:对所给的字符串进行huffman的编译码;译码对应原始序列,在将编码进行移位操作时,再进行译码输出,得出误码率。
<二>实验要求:自己设计一段信源序列,利用Huffman编码对其进行编码,然后利用相应的译方法进行译码,同时考察译码错误对后续序列带来的影响。
三、实验过程(详细设计):<一> huffman编码原理:Huffman编码是一种紧致编码,但编码序列的码并非是唯一的。
它是根据源数据各信号发生的概率进行编码,在源数据中出现的概率越大的信号,分配的码字越短;出现概率越小的信号,其码字越长,从而达到用尽可能少的码字表示源数据的目的。
Huffman编码的步骤如下:设信源X有m个符号(消息),信源概率分布如下:X = ⎧ x1, x2 ,..., x m ⎫⎩ p1 2 ,..., p m ⎭(1)把信源X 中的消息按概率从大到小的顺序排列;(2)把最后两个出现概率最小的消息合并成一个消息,从而使信源的消息数减少,并同时再按信源符号(消息)出现的概率从大到小排列;(3)重复上述2 个步骤,直到信源最后为一个序列只有一个1;(4)将被整合的消息分别赋予1 和0,并对最后的两个消息也相应地赋予1 和0.(5)通过以上步骤即可完成编码操作。
<二> huffman译码原理:通过在刚开始生成的随机编码序列,得到列出的0 1 序列与源字符串一一对应,就完成了译码。
而对错位后的编码序列,我只是只错位了前两个进行译码,效果不是很明显。
<三>算法设计:1、编码部分:(1)主函数主要用于调用前面所编写的各个函数模块,按照主函数(主函数代码如下)所列出来的调用顺序,进行一一叙述。
通信原理实验报告--脉冲编码调制与解调实验
本科实验报告课程名称:通信原理实验项目:脉冲编码调制与解调实验实验地点:通信原理实验室专业班级:学号:学生姓名:指导教师:2012年6 月16 日一、实验目的和要求:1.掌握脉冲编码调制与解调的原理。
2.掌握脉冲编码调制与解调系统的动态范围和频率特性的定义及测量方法。
3.了解脉冲编码调制信号的频谱特性。
二、实验内容:1.观察脉冲编码调制与解调的结果,观察调制信号与基带信号之间的关系。
2.改变基带信号的幅度,观察脉冲编码调制与解调信号的信噪比的变化情况。
3.改变基带信号的频率,观察脉冲编码调制与解调信号幅度的变化情况。
4.观察脉冲编码调制信号的频谱。
三、主要仪器设备:信号源模块、PAM、AM模块、终端模块、频谱分析模块四、实验原理:模拟信号进行抽样后,其抽样值还是随信号幅度连续变化的,当这些连续变化的抽样值通过有噪声的信道传输时,接收端就不能对所发送的抽样准确地估值。
如果发送端用预先规定的有限个电平来表示抽样值,且电平间隔比干扰噪声大,则接收端将有可能对所发送的抽样准确地估值,从而有可能消除随机噪声的影响。
脉冲编码调制(PCM)简称为脉码调制,它是一种将模拟语音信号变换成数字信号的编码方式。
脉码调制的过程如图4-1所示。
PCM主要包括抽样、量化与编码三个过程。
抽样是把时间连续的模拟信号转换成时间离散、幅度连续的抽样信号;量化是把时间离散、幅度连续的抽样信号转换成时间离散幅度离散的数字信号;编码是将量化后的信号编码形成一个二进制码组输出。
国际标准化的PCM码组(电话语音)是八位码组代表一个抽样值。
编码后的PCM 码组,经数字信道传输,在接收端,用二进制码组重建模拟信号,在解调过程中,一般采用抽样保持电路。
预滤波是为了把原始语音信号的频带限制在300-3400Hz左右,所以预滤波会引入一定的频带失真。
图4-1 PCM 调制原理框图在整个PCM系统中,重建信号的失真主要来源于量化以及信道传输误码,通常,用信号与量化噪声的功率比,即信噪比S/N来表示,国际电报电话咨询委员会(ITU-T)详细规定了它的指标,还规定比特率为64kb/s ,使用A 律或μ律编码律。
信息论与编码课程实验报告
福建农林大学计算机与信息学院信息工程类信息论与编码课程实验报告实验项目列表实验名称1:信源建模一、实验目的和要求(1)进一步熟悉信源建模;(2)掌握MATLAB程序设计和调试过程中数值的进制转换、数值与字符串之间的转换等技术。
二、实验内容(1)假设在一个通信过程中主要传递的对象以数字文本的方式呈现。
(2)我们用统计的方式,发现这八个消息分别是由N1,N2,…,N8个符号组成的。
在这些消息是中出现了以下符号(符号1,符号2,…,符号M)每个符号总共现了(次数1,次数2,…,次数M)我们认为,传递对象的信源模型可表示为:X为随机变量(即每次一个字符);取值空间为:(符号1,符号2,…,符号M);其概率分布列为:(次数1/(N1+…+N8),…,次数M/( N1+…+N8))三、实验环境硬件:计算机软件:MATLAB四、实验原理图像和语声是最常用的两类主要信源。
要充分描述一幅活动的立体彩色图像,须用一个四元的随机矢量场X(x,y,z,t),其中x,y,z为空间坐标;t 为时间坐标;而X是六维矢量,即表示左、右眼的亮度、色度和饱和度。
然而通常的黑白电视信号是对平面图像经过线性扫描而形成。
这样,上述四元随机矢量场可简化为一个随机过程X(t)。
图像信源的最主要客观统计特性是信源的幅度概率分布、自相关函数或功率谱。
关于图像信源的幅度概率分布,虽然人们已经作了大量的统计和分析,但尚未得出比较一致的结论。
至于图像的自相关函数,实验证明它大体上遵从负指数型分布。
其指数的衰减速度完全取决于图像类型与图像的细节结构。
实际上,由于信源的信号处理往往是在频域上进行,这时可以通过傅里叶变换将信源的自相关函数转换为功率谱密度。
功率谱密度也可以直接测试。
语声信号一般也可以用一个随机过程X(t)来表示。
语声信源的统计特性主要有语声的幅度概率分布、自相关函数、语声平均功率谱以及语声共振峰频率分布等。
实验结果表明语声的幅度概率分布可用伽玛(γ)分布或拉普拉斯分布来近似。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第8章上机实验8.1常用C语言函数简介本小节主要介绍一下后面将会用到的几个C语言函数。
8.1.1动态内存分配函数1.malloc函数用于动态分配内存void*m allo c(size-t size);其中参数size表示所需内存的大小,以字节为单位。
2.calloc函数用于动态分配内存void*c allo c(size-t n m e m b,s ize-t size);其中参数nmemb表示元素的个数,size表示每个元素的大小(以字节为单位)。
3.realloc函数用于动态调整所分配的内存的大小void*re allo c(void*ptr,size-t size);realloc 函数将指针ptr 所指向的内存区域的大小修改为size 个字节。
4.free 函数用于释放所分配的内存void free (void *ptr );free 函数释放指针ptr 所指向的内存。
pt r 必须是由malloc ,calloc 或realloc 返回的指针。
上述3个函数的原型定义在头文件stdlib .h 中。
malloc 和calloc 函数将返回一个指向分配出来的内存区域的指针,如果失败将返回一个空指针NULL 。
realloc 函数将返回一个指向调整大小后的内存区域的指针,如果失败将返回一个空指针NULL 。
如果参数size 为0,则将返回一个空指针或一个适合于作为free 函数参数的指针。
当函数realloc 失败时,原来的内存区域不会受到影响。
8.1.2 输入输出函数1.fscanf 函数用于输入数据int fsc a nf (FILE *fp ,c o nst c h ar *f mt ,…);fscanf 函数用于从指定的流fp 中依照格式fmt 读入数据,从第三个参数开始是待读入数据对应的地址变量的列表。
其中参数“流”通常是stdin (标准输入,即键盘)或之前以ASCII 读模式打开的文件。
此函数成功时返回读入的变量个数,失败时返回EOF 。
2.fprintf 函数用于输出数据int fprintf (FILE *fp ,co nst c h ar *fm t ,…);fprintf 函数将变量的值依照格式fmt 输出到流fp 中。
其中参数“流”通常是stdout (标准输出,即显示器)、stderr (标准错误,即显示器)或之前以ASCII 写模式打开的文件。
此函数成功时返回输出的字符个数,失败时返回一个负数。
上述两个函数的原型定义在头文件stdio .h 中。
参数fmt 称为格式描述字符串,由普通字符串和格式描述符组成,所有的格式描述符都以百分号(%)开头。
常用的格式描述符如表8.1所示。
711第8章 上机实验811信息论基础教程习题解答与实验指导表8.1标准I/O格式描述符描述符含义%输出百分号,即格式字符串%%的输出为%c输出字符型数据s输出C字符串(以‘\0’结尾的字符串)d,i输出整型数据,缺省为十进制o,u,x,X分别表示以八进制、十进制、小写十六进制和大写十六进制输出整型数据f输出浮点型数据e以科学记数法输出浮点型数据8.1.3字符串处理函数1.strcpy函数用于字符串复制c h ar*strc py(c h ar*dst,c o nst c h ar*src);它将由src指向的字符串拷贝到dst指向的字符串中,包括字符串终止符‘\0’。
目的缓冲区dst的大小必须足以接受复制。
此函数的返回值为指向目的字符串dst的指针。
2.strncpy函数用于指定长度的字符串复制c h ar*strn cpy(c h ar*dst,co nst c h ar*src,size-t n);此函数与st rcpy的唯一区别就是指定了复制的字符个数n。
如果在src的前n个字符中没有字符串终止符,则复制的结果也将没有字符串终止符。
当src的长度小于dst 时,dst中剩余的位置将被空字符填充。
此函数的返回值为指向目的字符串dst的指针。
3.strcmp函数用于字符串比较int strc m p(co nst c h ar*s1,co nst c h ar*s2);根据字符串s1按照字典顺序大于、等于或小于字符串s2,此函数分别返回一个大于、等于或小于零的整数。
4.strncmp函数用于指定长度的字符串比较int strc m p(co nst c h ar*s1,co nst c h ar*s2,size-t n);此函数与st rcmp的唯一区别是只比较两个字符串的前n个字符。
5.strcat函数用于字符串串接c h ar*strc at(c h ar*dst,co nst c h ar*src);此函数首先去掉字符串dst末尾的字符串终止符‘\0’,然后将src追加到其后的位置,串接为一个新的字符串返回。
目的字符串的大小必须足够大以容纳串接的结果。
此函数的返回值为指向目的字符串dst 的指针。
6.strlen 函数返回字符串的长度size -t strle n (c o nst c h ar *str );此函数计算字符串st r 的长度,不包括字符串终止符‘\0’并返回。
8.2 信道容量的迭代算法1.实验目的(1)进一步熟悉信道容量的迭代算法;(2)学习如何将复杂的公式转化为程序;(3)掌握C 语言数值计算程序的设计和调试技术。
2.实验要求(1)已知:信源符号个数r 、信宿符号个数s 、信道转移概率矩阵P 。
(2)输入:任意的一个信道转移概率矩阵。
信源符号个数、信宿符号个数和每个具体的转移概率在运行时从键盘输入。
(3)输出:最佳信源分布P *,信道容量C 。
3.算法Algorithm 1:信道容量的迭代算法1:procedure CHAN NEL CAPACITY (r ,s ,(p ji ))2: initialize :信源分布p i =1r,相对误差门限δ,C =-∞3: repeat4: ij ←p i p ji∑ri =1p ip ji5: p i ←exp ∑sj =1p ji log 2ij ∑r i =1exp ∑sj =1p ji log 2ij6: C ←log 2∑r i =1exp∑s j =1pji log 2ij911第8章 上机实验7:until |ΔC|C≤δ8:output P*=(p i)r,C9:end procedure4.代码1/***************************************************** 2*Auth or:Hop Le e3*D ate:2003.06.254*C opyrig ht:GPL5*Purpose:C a c ulate th e c a pa city of a give n c h a nn el6*****************************************************/ 7#in clu d e<stdio.h>8#in clu d e<m ath.h>9#in clu d e<stdlib.h>10#in clu d e<unistd.h>11#in clu d e<valu es.h>1213#defin e DEL TA1e-6/*delta,th e thresh old*/1415int m ain(void)16{17re gister int i,j;18re gister int k;19int r,s;2021flo at*p-i=NULL;22flo at**p-ji=NULL;23flo at**p hi-ij=NULL;24flo at C,C-pre,valid ate;2526flo at*su m=NULL;27flo at p-j;2829/*Re ad th e n u m ber of in p ut sym b ol:r,021信息论基础教程习题解答与实验指导30*a n d th e nu m b er of o utp ut sy m bol:s*/31fsc a nf(stdin,″%d″,&r);32fsc a nf(stdin,″%d″,&s);3334/*Alloc ation m e m ory for p-i,p-ji a n d phi-ij*/35p-i=(float*)c allo c(r,sizeof(float));3637p-ji=(flo at**)c allo c(r,size of(flo at));38for(i=0;i<r;i++)39p-ji[i]=(float*)c allo c(s,sizeof(float));4041p hi-ij=(flo at**)c allo c(r,size of(flo at*));42for(i=0;i<r;i++)43p hi-ij[i]=(float*)c allo c(s,sizeof(float))4445/*Rea d th e c h a n n el tra nsitio n prob ability m atrix p-ji*/ 46for(i=0;i<r;i++)47for(j=0;j<s;j++)48fsc a nf(stdin,″%f″,&p-ji[i][j]);4950/*V alid ate th e in p ut data*/51for(i=0;i<r;i++)52{53validate=0.0;54for(j=0;j<s;j++)55{56validate+=p-ji[i][j];57}58if(fa bs(valid ate-1.0)>DELTA)59{60fprintf(stdo ut,″Invalid in p ut data.\n″);61exit(-1);62}63}64121第8章上机实验221信息论基础教程习题解答与实验指导65fprintf(stdo ut,″Startin g...\n″);6667/*Initialize th e p-i a nd p hi-ij*/68for(i=0;i<r;i++)69{70p-i[i]=1.0/(flo at)r;71}72/*Initialize C a n d iteratio n c o unter:k,a n d te m prory varia ble*/73C=-MAXFLOAT;/*MAXFLOAT was d efin ed in<valu es.h>*/74k=0;75su m=(flo at*)c alloc(r,sizeof(flo at));7677/*Start iterate*/78do79{80k++;8182/*C alc ulate p hi-ij(k)first*/83for(j=0;j<s;j++)84{85p-j=0.0;86for(i=0;i<r;i++)87p-j+=p-i[i]*p-ji[i][j];8889if(fa bs(p-j)>=DEL TA)90for(i=0;i<r;i++)91p hi-ij[i][j]=p-i[i]*p-ji[i][j]/p-j;92else93for(i=0;i<r;i++)94p hi-ij[i][j]=0.0;95}9697/*C alc ulate p-i(k+1)the n*/98p-j=0.0;99for(i=0;i<r;i++)100{101su m[i]=0.0;102for(j=0;j<s;j++)103{104/*Preve nt divid ed by zero*/105if(fa bs(p hi-ij[i][j])>=DEL TA)106su m[i]+=p-ji[i][j]*lo g2(p hi-ij[i][j])/lo g2(2.0);107}108su m[i]=pow(2.0,su m[i]);109p-j+=su m[i];110}111112for(i=0;i<r;i++)113{114p-i[i]=su m[i]/p-j;115}116/*An d C(k+1)*/117C-pre=C;118C=log2(p-j)/lo g2(2.0);119}120while(fabs(C-C-pre)/C>DEL TA);121122123free(su m);124su m=NULL;125126/*O utp ut th e result*/127fprintf(stdo ut,″The iteratio n n u m ber i s%d.\n\n″,k);128fprintf(stdo ut,″The c a pa city of th e c h a nn el is%.6f bit/sym b ol.\n\n″,C); 129fprintf(stdo ut,″The best in p ut prob ability distrib utio n is:\n″);130for(i=0;i<r;i++)131fprintf(stdo ut,″%.6f″,p-i[i]);132fprintf(stdo ut,″\n″);133134/*Free th e m e m ory we allo c atio n before with sta ck se q u e n c e*/321第8章上机实验421信息论基础教程习题解答与实验指导135for(i=s-1;i>=0;i--)136{137free(p hi-ij[i]);138p hi-ij[i]=NULL;139}140free(p hi-ij);141p hi-ij=NULL;142143for(i=r-1;i>=0;i--)144{145free(p-ji[i]);146p-ji[i]=NULL;147}148free(p-ji);149p-ji=NULL;150free(p-i);151p-i=NULL;152153exit(0);154}8.3唯一可译码判决准则1.实验目的(1)进一步熟悉唯一可译码判决准则;(2)掌握C语言字符串处理程序的设计和调试技术。