面板协整-FMOLS--DOLS分析
【国家自然科学基金】_面板协整检验_基金支持热词逐年推荐_【万方软件创新助手】_20140802
科研热词 经济增长 协整检验 面板数据模型 面板数据 截面相关 单位根检验 面板协整 面板 误差修正模型 碳排放 比较研究 农机总动力 granger因果关系 高技术产业 面板误差修正模型 面板数据协整模型 面板协整分析 面板var模型 集聚 金融规模 金融效率 金融支持 贸易收支 购买力平价 西部地区 行驶里程数 能源消费 能源强度 结构突变 系统广义矩估计 福利 电力消费 珠江三角洲 现房 环境规制政策 森林碳汇 期房 有效性 旅游经济 技术创新能力 技术创新 弹性系数 市场化 工业行业 城乡收入差距 固定效应模型 因果检验 向量误差修正模型 变截距模型 制度变迁 创新能力 农机购置投入结构
科研热词 面板协整 环境库兹涅茨曲线 环境-经济空间格局 dols 面板数据 面板因果 面板协整检验 进出口贸易 资本流动 行业集中度 行业经济特性 统计检验 经济增长 模型设定 检验水平 标准化 新进展 投资 技术创新 序列相关 外商直接投资 因果分析 动态广义最小二乘法 出口地理方向 全要素生产率 储蓄 专利 fmols fdi
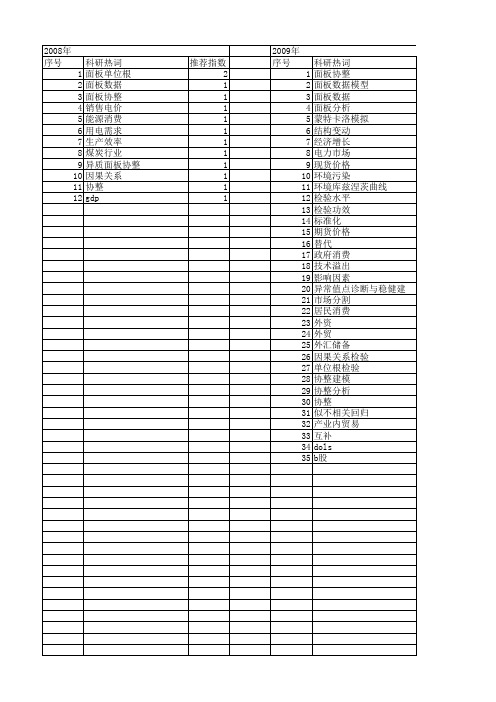
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12
科研热词 面板单位根 面板数据 面板协整 销售电价 能源消费 用电需求 生产效率 煤炭行业 异质面板协整 因果关系 协整 gdp
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
面板数据模型的检验方法研究优秀毕业论文

-
I尹
学位论文作者签名:隐蠡墨 签字日期:卅一年歹月旷日
0
学位论文版权使用授权书
本学位论文作者完全了解天津大学 有关保留、使用学位论文的规定。
特授权天津大学可以将学位论文的全部或部分内容编入有关数据库进行检
索,并采用影印、缩印或扫描等复制手段保存、汇编以供查阅和借阅。同意学校 向国家有关部门或机构送交论文的复印件和磁盘。
N or T is relatively large;and unit root tests in panel data with trend shift are
●
uneffective and will lead to spurious result in most cases.They show that neglect of
theory and method of panel heteroskedasticity and serial dependence tests,panel unit
root tests and panel cointegration tests,and to perfect and expand the tests in panel
卜
structural breaks will iead to test failure.
、
(3)This paper proposes a LSTR-IPS panel data unit root test with structural
change,by modifying the traditional IPS unit test with nonlinear smooth transition
(4)Taking into account the progressive nature and smooth asymptotic
面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)

面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析)面板数据分析方法:面板单位根检验—若为同阶—面板协整—回归分析—若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。
先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。
不是时间序列那种接近0.8为优秀。
另外,建议回归前先做stationary。
很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。
fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。
该如何选择呢?步骤一:分析数据的平稳性(单位根检验)按照正规程序,面板数据模型在回归前需检验数据的平稳性。
李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。
这种情况称为称为虚假回归或伪回归(spurious regression)。
他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。
因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。
而检验数据平稳性最常用的办法就是单位根检验。
首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。
单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。
面板数据协整分析

面板数据协整分析面板数据协整分析在计量经济学中被广泛应用于研究变量之间的长期均衡关系。
该方法结合了面板数据的特点和协整分析的思想,对于探讨变量之间的长期关系具有重要意义。
本文将以面板数据协整分析为题,探讨其基本原理、应用场景及操作步骤。
一、基本原理面板数据协整分析基于协整理论,该理论由格兰杰(Granger)和约翰森(Johansen)提出。
协整分析强调变量之间的长期均衡关系,即在长期内,变量之间的差异会被一组线性关系所消除,使得变量之间呈现出稳定的关系。
面板数据是经济学研究中常用的数据格式,具有个体和时间两个维度。
相比于截面数据或时间序列数据,面板数据包含了更多的信息,能够更好地捕捉个体和时间的异质性。
因此,面板数据协整分析更适用于考察个体之间的关系和长期的动态变化。
二、应用场景面板数据协整分析可以应用于多个领域,如经济学、金融学、环境科学等。
以下是一些典型的应用场景:1. 经济增长与贸易关系分析面板数据协整分析可以用于研究不同国家之间的贸易关系和经济增长的关联性。
通过分析面板数据,可以确定是否存在长期均衡关系,以及对经济增长的贡献度。
2. 教育投资与经济发展的影响面板数据协整分析可以帮助研究者探究教育投资对经济发展的影响。
通过分析面板数据,可以建立教育投资与经济发展之间的长期关系模型,从而评估教育政策的效果。
3. 环境污染与经济增长的关系研究面板数据协整分析可以帮助研究者了解环境污染与经济增长之间的关联性。
通过分析面板数据,可以估计环境污染对经济增长的影响,并提出相关政策建议。
三、操作步骤进行面板数据协整分析需要以下几个基本步骤:1. 数据准备首先,需要收集相关面板数据,并对数据进行清洗和整理,确保数据的可靠性和一致性。
同时,还需要进行面板数据的单位根检验,以判断是否需要进行协整分析。
2. 变量选择在进行面板数据协整分析时,需要选择适当的变量作为分析对象。
变量选择应基于理论基础和实际需求,并考虑到变量之间的相关性。
5.3 Panel Data 单位根和协整检验

– 按照Choi (2001)的总结,上述单位根检验存在四个缺 陷(或前提假设);一是都需要截面单元数是无限的 ,否则检验的渐近正态性不存在;二是假定所有截面 单元有同样的非随机成份;三是假设所有的截面单元 拥有同样的时间序列跨度;四是备择假设都是所有截 面单元没有单位根,一些截面单元有单位根而另一些 没有的情形将不能被处理。
– Choi and Chue ( 2007)运用子抽样技术来处理面板数 据的截面相关,研究了非平稳、截面相关和截面协整 面板数据的子抽样假设检验。 – Pesaran (2007) 提出了一个简单的面板单位根检验。 将DF/ADF回归扩展到了水平滞后的截面平均和截面单 元序列一阶差分的情形(简称,CADF,Cross Sectionally Augmented ADF),然后基于截面单元 CADF统计量的简单平均或者对联合拒绝概率的合适变 换,便形成了Pesaran的标准面板单位根检验。
)
2
Under H0 : δ = 0 , tδ N ( 0,1) for model 1. but diverges to ∞ for model 2 and 3. A proper standardized test is given by
tδ =
*
* % tδ NTSNσu 2STD δ mT%
Where W1 ( r ) = W ( r ) is standard wiener process,
W2 ( r ) = W ( r ) ∫0W ( r ) dr is demeaned wiener process,
1
W3 ( r ) =W ( r ) 4 ∫0W ( r ) 1.5∫0 rW ( r ) dr + 6r ∫0W ( r ) dr 2∫0 rW ( r ) dr
面板数据的模型(panel data model)

面板数据的模型(panel data model)王志刚 2004年11月11日一. 混合数据模型和面板数据模型如果扰动项it ε服从独立同分布假定,而且和解释变量不相关,那么就可以采用混合最小二乘法估计(Pooled OLS ),但是这里要注意POLS 暗含着一个假定就是,截距项和解释变量的系数是相同的,不随着个体和时间而变化。
我们一般采用单因子(one-way effects )模型,假定截距项具有个体异质性,也就是:这种模型是最常见的面板模型(又称为纵列数据longitudinal data ),因为面板数据往往要求个体纬度 N>>T(时间纬度),下面我们基本上以这种模型为例。
it u 是独立同分布,而且均值为0,方差为2u σ。
如对截距项和解释变量系数均有个体的异质性,那么要采用随机系数模型(Random coefficient model ),stata 的xtrchh 过程提供了相应的估计。
双因子模型(two-way ):it t i it u ++=γαε二. 固定效应(Fixed effects ) vs 随机效应(Random effects)如果个体效应i α是一个均值为0,方差为2ασ的独立同分布的随机变量,也就是()0,cov =it i x α,该模型就称为随机效应模型(又称为error component model );如果相关,则称为固定效应模型。
1.在随机效应模型中,it ε在每个个体内部存在着一阶自相关,因为他们都包含着相同的个体效应;此时OLS 无效,而且标准差也失真,应该采用广义最小二乘估计(GLS)其中:是个体按时间的均值;有待估计;我们可以通过对组内和组间估计得到相应的残差,从而可以计算出方差;T k n e e e e nnk nT ubetween between between between within within u 22222,,ˆˆ1σσσσσα-=-'='--=;组间估计:εβ+=..i i x y ;组内估计如下;2.如果个体效应和解释变量相关,OLS 和GLS 都将失效,此时要采用固定效应模型。
(最新整理)stata上机实验第五讲——面板数据的处理..

• corr(u_i, Xb) 个体效应与解释变量的相关系数,相关 系数为0或者接近于0,可以使用随机效应模型;相 关系数不为0,需要使用固定效应模型。u-i不表示残 差,表示个体效应。
2021/7/26
19
模型选择
• 固定效应还是混合OLS? 可以直接观测F值
• 随机效应还是混合OLS? 先用随机效应回归,然后运行xttest0
• xtgls Panel-data models using GLS
• xtpcse OLS or Prais-Winsten models with panelcorrected standard errors
• xtrchh Hildreth-Houck random coefficients models
fmols方法

fmols方法FMOLS(Fully Modified Ordinary Least Squares)方法是一种常用的计量经济学方法,用于解决时间序列数据的回归分析问题。
在本文中,我们将介绍FMOLS方法的原理、应用领域以及实施步骤。
让我们来了解一下FMOLS方法的原理。
FMOLS方法是对OLS (Ordinary Least Squares)方法的改进,主要用于解决存在内生性问题的回归模型。
内生性问题指的是回归模型中自变量与误差项之间存在相关性,从而导致OLS估计结果的不一致性。
FMOLS方法通过引入滞后自变量和误差项的滞后项,从而消除内生性问题,得到一致且有效的估计结果。
接下来,我们来看一下FMOLS方法的应用领域。
FMOLS方法广泛应用于经济学研究中,特别是时间序列数据的分析。
例如,研究经济增长与投资之间的关系、汇率与贸易之间的关系等都可以使用FMOLS方法进行分析。
此外,FMOLS方法还可以用于解决面板数据的内生性问题。
然后,我们来了解一下FMOLS方法的实施步骤。
首先,需要确定回归模型的形式,并进行变量的选择。
接下来,进行FMOLS估计,这包括两个主要步骤:首先,进行OLS估计,得到初始的残差项;然后,对残差项和自变量进行滞后处理,得到滞后自变量和滞后残差项。
最后,利用滞后自变量和滞后残差项进行FMOLS估计,得到一致且有效的参数估计结果。
在实施FMOLS方法时,还需要考虑一些问题。
首先,需要进行滞后阶数的选择,一般可以通过信息准则(如AIC、BIC等)进行选择。
其次,需要进行滞后残差项的检验,以确保滞后项的使用是合理的。
最后,需要进行模型的诊断检验,以评估模型的拟合效果和估计结果的可靠性。
FMOLS方法是一种常用的计量经济学方法,用于解决时间序列数据的回归分析问题。
它通过引入滞后自变量和滞后残差项,消除了内生性问题,得到一致且有效的估计结果。
FMOLS方法在经济学研究中有广泛的应用领域,可用于分析经济增长、汇率与贸易等问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
Tradtional v.s Panel Unit Root Tests
3
Various Types of Panel Unit Root Tests
v
The main limit of these tests is that they are all constructed under the assumption that the individual time series in the panel are crosssectionally independently distributed, when on the contrary a large amount of literature provides evidence of the comovements between economic variables. 4
Levin, Lin and Chu (2002) Test for Panel Unit
LLC test, like Breitung’s (2000) test, assume homogeneous autoregressive coefficients between individual, i.e. ρ = ρi for all i , Limitations: 1. test depends crucially on the independence assumption across individuals; 2. AR coefficient is assumed to be equal across the panel (The null makes sense under some circumstances, but as Maddala and Wu (1999) pointed out, the alternative is too strong to be held in any interesting empirical cases.) 5
7
Comparisons between Tests for Panel Unit Root
Monte Carlo simulations show that IPS test is more powerful than LLC Breitung (2000) finds that both tests suffer for a dramatic loss of power if individual specific trends are included A direct comparison between LLC and t-bar (IPS) test is not possible because they present some relevant differences. Even if both tests have the same null hypothesis, the alternatives are quite different: in LLC test the alternative provides for individual stationary series with identical first order autoregressive coefficient, while in IPS test it provides for different individual first order autoregressive coefficients.
6
Breitung’s (2000) Test for Panel Unit
Narayan and Narayan (2008) Does environmental quality influence health expenditures? Empirical evidence from a panel of selected OECD countries. Ecological Economics 65, 367-374.
Panel Unit Root, Cointegration, FMOLS, DOLS
Yihua Yu Renmin University of China
1
Backrgound Starting with the working paper versions of Quah (1994) and Breitung and Meyer (1994) that were available already in 1989, the literature concerned with the analysis of unit roots in panel data covers more than 20 years Some of these are well-known, others are not But they all have in common that if ignored the effects can be very serious via methods of either simulations or theoretical reasoning
Im, Pesaran and Shin (2003) Test for Panel Unit
This test allows for residual serial correlation and heterogeneity of the dynamics and error variances across groups IPS, ADF–Fisher, and PP tests presented by Maddala and Wu (1999) assume an individual unit root process, that’s, ρ is assumed to be different for each province. Requires a balanced panel (same as that in the ADFFisher)