ascii字符 字库的建立
计算机中的常用编码

计算机中的常用编码计算机中的常用编码字符又称为符号数据,包括字母和符号等。
计算机除处理数值信息外,大量处理的是字符信息。
例如,将高级语言编写的程序输入到计算机时,人与计算机通信时所用的语言就不再是一种纯数字语言而是字符语言。
由于计算机中只能存储二进制数,这就需要对字符进行编码,建立字符数据与二进制数据之间的对应关系,以便于计算机识别、存储和处理。
1. ASSII码目前,国际上使用的字母、数字和符号的信息、编码系统种类很多,但使用最广泛的是ASCII码(American Standard Code for Interchange)。
该码开始时是美国国家信息交换标准字符码,后来被采纳为一种国际通用的信息交换标准代码。
ASCII码总共有128个元素,其中包括32个通用控制字符,10个十进制数码,52个英文大、小写字母和34个专用符号。
因为ASCII码总共为128个元素,故用二进制编码表示需用7位。
任意一个元素由7位二进制数D7D6D5D4D3D2D1表示,从0000000到1111111共有128种编码,可用来表示128个不同的字符。
ASCII码是7位的编码,但由于字节(8位)是计算机中常用单位,故仍以1字节来存放一个ASCII字符,每个字节中多余的最高位D7取为0。
表1-3所示为7位ASCII编码表(省略了恒为0的最高位D7)。
表1-3 7位ASCII编码表要确定某个字符的ASCII码,在表中可先查到它的位置,然后确定它所在位置相应的列和行,最后根据列确定高位码(D6D5D4),根据行确定低位码(D3D2D1D0),把高位码与低位码合在一起就是该字符的ASCII码(高位码在前,低位码在后)。
例如,字母A的ASCII码是1000001,符号"+"的ASCII码是0101011。
ASCII码的特点如下。
编码值0~31(0000000~0011111)不对应任何可印刷字符,通常为控制符,用于计算机通信中的通信控制或对设备的功能控制;编码值为32(0100000)是空格字符,编码值为127(1111111)是删除控制DEL码;其余94个字符为可印刷字符。
计算机中信息的表示方法

计算机中信息的表示方法计算机要处理的信息是多种多样的,如日常的十进制数、文字、符号、图形、图像和语言等。
但是计算机无法直接“理解”这些信息,所以计算机需要采用数字化编码的形式对信息进行存储、加工、和传送。
信息的数字化表示就是采用一定的基本符号,使用一定的组合规则来表示信息。
计算机中采用的二进制编码,其基本符号是“0”和“1”。
一、进制计数的方法有很多种,在日常生活中我们最常见的是国际上通用的计数方法——十进制计数法。
但是除了十进制外还有其他计数制,如一天24小时,称为24进制,一小时60分钟,称为60进制,这些称为进位计数制。
计算机中使用的是二进制。
这几种进制采用的都是带权计数法,它包含两个基本要素:基数、位权。
基数是一种进位计数制所使用的数码状态的个数。
如十进制有十个数码:0、1、2……7、8、9,因此基数为10。
二进制有两个数码:0和1,因此基数为2。
位权表示一个数码所在的位。
数码所在的位不同,代表数的大小也不同。
如十进制从右面起第一位是个位,第二位是十位,第三位是百位,……。
“个(100)、十(101)、百(102)、千(103)……”就是十进制位的“位权”。
每一位数码与该位“位权”的乘积表示该位数值的大小。
如十进制中9在个位代表9,在十位上代表90。
二进制的表示一般一个长度为n 的二进制数a n-1……a1a0,用科学计数法表示为:a n-1……a1a0= a n-1×2n-1+……a1×21+a0×20。
例如,二进制数10101用科学计数法表示:10101=1×24+0×23+1×22+0×21+1×20。
进制转换在计算机世界中还涉及到八进制、十进制和十六进制。
下面将讲述这几种进制之间的转换。
1.二进制与十进制的转换(1)二进制转十进制方法:“按权展开求和”例:(1011.01)2=(1×23+0×22+1×21+1×20+0×2-1+1×2-2)10=(8+0+2+1+0+0.25)10=(11.25)10(2)十进制转二进制·十进制整数转二进制数:“除以2取余,逆序输出”例:(89)10=(1011001)22 892 44 (1)2 22 02 11 02 5 (1)2 2 (1)2 1 00 (1)·十进制小数转二进制数:“乘以2取整,顺序输出”例:(0.625)10= (0.101)20.625X 21.02.八进制与二进制的转换例:将八进制的37.416转换成二进制数:3 7 .4 1 6011 111 .100 001 110即:(37.416)8 =(11111.10000111)2例:将二进制的10110.0011 转换成八进制:0 1 0 1 1 0 .0 0 1 1 0 02 6 .1 4即:(10110.011)2=(26.14)83.十六进制与二进制的转换例:将十六进制数5DF.9 转换成二进制:5 D F .90101 1101 1111 .1001即:(5DF.9)16=(10111011111.1001)2例:将二进制数1100001.111 转换成十六进制:0110 0001 .11106 1 . E即:(1100001.111)2=(61.E)16二进制的运算:算术运算:加法:0+0=0 ,0+1=1,1+0=1,1+1=10减法:0-0=0,1-0=1,1-1=0,10-1=1乘法:0*0=0,0*1=0,1*0=0,1*1=1位运算与:0 and 0=0 , 0 and 1=0 , 1 and 0=0 , 1 and 1=1或:0 or 0 =0 , 0 or 1=1 , 1 or 0=1 , 1 or 1=1非:not 0=1 , not 1=0异或:0 xor 0=0 , 0 xor 1=1 , 1 xor 0 =1 , 1 xor 1 =0位移运算左移(二进制数k左移n位):k shl n = k * 2n右移(二进制数k右移n位):k shr n = k div 2n例:求下列二进制数运算的结果101+101=1010101*11=11111000-11=1011001 shl 2=1001001100110 shr 2 =11001二、计算机中数的表示在普通数字中,用“+”或“—”符号在数的绝对值之前来区分数的正负。
ascii字符字库的建立

开发环境:Win7,Eclipse,MinGW1、生成ASCII字符文件ASCII编码的可打印字符是0x20~0x7E,先用运行下面这段代码,生成一个包含全部可打印字符的txt文件:#include <stdio.h>#include <stdlib.h>int main(int argc,char *argv[]){FILE * fp;unsigned char i = 0;fp = fopen("ascii.txt","w");if(fp == 0){perror("open");return -1;}for(i=0x20;i<0x7F;i++){fputc(i,fp);}return 0;}运行后,用记事本打开ascii.txt文件,会看到如下文本:!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ [\]^_`abcdefghijklmnopqrstuvwxyz{|}~2、生成字模数据使用字模提取V2.1软件,设置字体为宋体、12,纵向取模,字节倒序(即高位在下)。
这些设置可以根据实际情况设置。
用C51格式生成字模,大小是8*16,每个字符用16个字节表示。
如字符A的显示如下:取模数据为:0x00,0x00,0xC0,0x38,0xE0,0x00,0x00,0x00,0x20,0x3C,0x23,0x02,0x02,0x27,0x38,0x20,然后将所有的字模数据复制到一个文本文件,删除其中的空行,换行,注释等与字模数据无关的内容,并将文件最后的一个逗号改为ASCII字符的句号,得到一个纯字模数据文件ascii_zk.txt3、将字模数据文件转换为二进制文件将ascii_zk.txt文件中的每个字模数据转换为占一个字节的数,将所有的数据填充为一个二进制文件ascii_zk.bin。
字库显示方法

我们知道英文字母数量比较少,我们只要用一个字节(8位)就足以表达。
但是汉字非常多。
要怎么表达呢?前人采用的一个方法就是把ASCII码的高128位作为汉字的内码,低128位仍然作为英文字母的内码,然后用两个字节来表示一个汉字。
通过这个内码,我们可以获取汉字的字模信息。
然后再根据这些字模的信息,把相应的汉字显示出来。
二、什么是汉字字库?如何寻址?点阵字库其实就是按照汉字内码的顺序,把汉字的字模信息存起来。
16×16的点阵字库有94区,每个区有94个汉字的字模。
这样总的有94×94个汉字。
我们之前说了,一个汉字由两个ASCII扩展码构成。
第一个ASCII扩展码用来存放汉字的区码,第二个ASCII扩展码用来存放汉字的位码。
具体是这样的:第一个扩展ASCII码= 128 + 汉字的区码第二个扩展ASCII码= 128 +汉字的位码这样,如果我们用char HZ[2]来表示一个汉字。
则:区码= HZ[0] - 128位码= HZ[1] - 128这样,算出区位码之后,我们就可以用它在汉字库里面寻址找字模了。
具体的方式是:该汉字的偏移地址 = (区码-1)×94×一个字占用的字节数+位码×一个字占用的字节数这样我们就很容易的写出显示汉字字模的函数:INT8U *HZK = (INT8U *)0x801c0000; /* 汉字字库的存储地址*/INT8U *ASCII = (INT8U *)0x801fba00; /* ASCII码字库的存储地址 */INT8U const cmp_w[8]={128,64,32,16,8,4,2,1};/********************************************************************************** ************************* Function : DisplayHZ()** Description: 该函数用于在F DGK/GUI上显示一个汉字。
AscII码字模提取方法
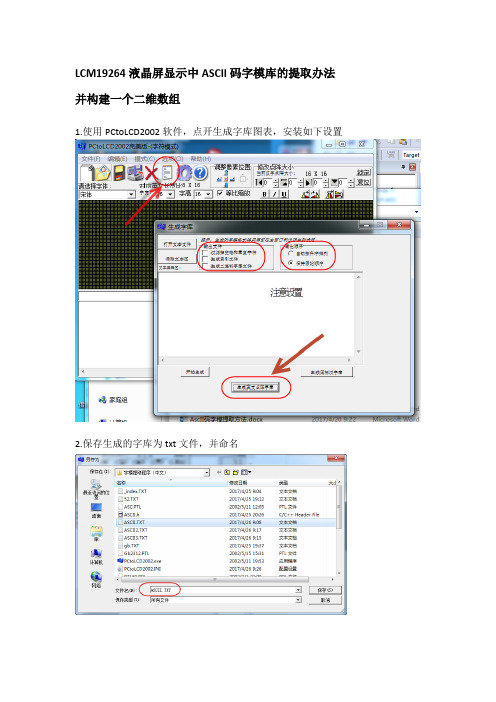
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。
ASCII

我们需要了解的最早编码是ASCII码。它用7个二进制位来表示,由于那个时期生产的大多数计算机使用8位大小的字节,因此用户不仅可以存放所有可能的 ASCII字符,而且有整整一位空余下来。如果你技艺高超,可以将该位用做自己离奇的目的:WordStar中那个发暗的灯泡实际上设置这个高位,以指示一个单词中的最后一个字母,同时这也宣示了WordStar只能用于英语文本。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包含了很多的英文字符。
英文名:ChineseInternal Code Specification
中文名:汉字内码扩展规范1.0版
双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容
范围:8140~FEFE(剔除xx7F)共23940个码位
2. 国家标准汉字交换码
我国制定了“中华人民共和国国家标准信息交换汉字编码”,标准代号为GB2312—80,这种编码又称为国标码。在国标码的字符集中共收录了一级汉字3755个,二级汉字3008个,图形符号682个,三项字符总计7445个。
在国标GD2312—80中规定,所有的国标汉字及符号分配在一个94行、94列的方阵中,方阵的每一行称为一个“区”,编号为01区到94区,每一列称为一个“位”,编号为01位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。区位码的前两位是它的区号,后两位是它的位号。用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。汉字“母”字的区位码是3624,表明它在方阵的36区24位,问号“?”的区位码为0331,则它在03区3l位。
【实训】谈一谈你所理解的汉字信息在计算机里的存储与表达的过程与原理,并同英文的处理做比较。

一、汉字信息在计算机中的处理与存储计算机对每一个字符进行编码形成其对应的唯一一个内码就是汉字的存储,然而同一个字符(例如“中”字)不同编码对应的内码不一样。
计算机中汉字编码一般采用两个高位( 左边第一位)为1 的ASCⅡ码表示一个汉字,即用两个字节表示一个汉字。
汉字在计算机内的编码很复杂,涉及汉字的各种代码,如汉字输入码,汉字机内码,汉字交换码,汉字字形码等。
1、汉字输入码汉字输入码也叫外码,是为了通过键盘字符把汉字输入计算机而设计的一种编码。
汉字的输入码种类繁多,大致有4种类型,即音码、形码、数字码和音形码。
2、汉字机内码汉字机内码又称内码或汉字存储码。
该编码的作用是统一了各种不同的汉字输入码在计算机内的表示。
汉字机内码是计算机内部存储、处理的代码。
3、汉字交换码汉字交换码主要是用作汉字信息交换的。
4、汉字字形码汉字字形码是指确定一个汉字字形点阵的代码(汉字字形码)。
一般采用点阵字形表示字符.普遍使用的汉字字型码是用点阵方式表示的 称为“点阵字模码”。
所谓“点阵字模码” 就是将汉字像图像一样置于网状方格上 每格是存储器中的一个位 16×16点阵是在纵向16点、横向16点的网状方格上写一个汉字 有笔画的格对应1 无笔画的格对应0。
这种用点阵形式存储的汉字字型信息的集合称为汉字字模库 简称汉字字库。
通常汉字显示使用16×16点阵 而汉字打印可选用24×24点阵、32×32点阵、64×64点阵等。
汉字字形点阵中的每个点对应一个二进制位 1字节又等于8个二进制位 所以16×16点阵字形的字要使用32个字节 16×16÷8字节 32字节 存储 64×64点阵的字形要使用512个字节。
在16×16点阵字库中的每一个汉字以32个字节存放 存储一、二级汉字及符号共8836个 需要282.5KB磁盘空间。
而用户的文档假定有10万个汉字 却只需要200KB的磁盘空间 这是因为用户文档中存储的只是每个汉字 符号 在汉字库中的地址 内码 。
字库生成程序使用方法

字库生成程序使用方法MakeFontLibV34.exe可用来生成SCL2008/SuperComm播放文本文件或直接输出文字所需要的字库文件。
1. 运行该程序2. 生成英文字库2.1 在Width和Height中输入英文文字大小(一般英文字符占半个汉字位置)2.2 如果显示屏要旋转90度使用,则选中Rotate 90 d2.3 点ASCII按钮弹出字体对话框,选择所需的字体,注意字体大小应与2.1中输入的大小一致,否则程序会自动缩放到2.1中输入的大小2.4 点确定后显示你所选择的字体信息,若正确则点Accept按钮弹出另存为对话框,选择或输入文件名点保存生成英文字库文件2.5 程序在窗口的最下方编辑框里输出字库定义字符串,须添加到CONFIG.LY文件中3. 生成中文字库3.1 在Width和Height中输入中文文字大小3.2 在1st Byte和2nd Byte处选择文字编码的起始位置:GB2312简体字编码,在1st Byte处选A0H,在2nd Byte处选A0H;Big5繁体字编码,在1st Byte处选80H,在2nd Byte处选40H。
其它编码请查阅其编码表3.3 点Local Languange按钮弹出字体对话框,选择所需的字体,注意字体大小应与2.1中输入的大小一致,否则程序会自动缩放到2.1中输入的大小3.4 点确定后显示你所选择的字体信息,若正确则点Accept按钮弹出另存为对话框,选择或输入文件名点保存生成中文字库文件3.5 程序在窗口的最下方编辑框里输出字库定义字符串,须添加到CONFIG.LY文件中4. 加载字库到控制卡4.1 修改CONFIG.LY文件,将生成字库后最下方编辑框里输出的文字添加到CONFIG.LY文件中。
并根据实际字库数量修改FontCount 的值4.2 将CONFIG.LY文件和所生成的字库上传到控制卡上即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0x00,0x00,0xC0,0x38,0xE0,0x00,0x00,0x00,0x20,0x3C,0x23,0x02,0x02,0x27,0x38,0x20,
然后将所有的字模数据复制到一个文本文件,删除其中的空行,换行,注释等与字模数据无关的内容,并将文件最后的一个逗号改为ASCII字符的句号,得到一个纯字模数据文件ascii_zk.txt
#include <stdio.h>
#include <stdlib.h>
/*
*将一个ascii字符转换为数
*/
unsigned char c2x(char ch)
{
unsigned char temp=0;
if(ch>=0x30 && ch<=0x39)
temp = ch-0x30;
else if(ch>=0x41 && ch<=0x46)
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
2、生成字模数据
使用字模提取V2.1软件,设置字体为宋体、12,纵向取模,字节倒序(即高位在下)。这些设置可以根据实际情况设置。用C51格式生成字模,大小是8*16,每个字符用16个字节表示。如字符A的显示如下:
int displaychar(FILE *fp,char dispch,char fillch,char start_x,char start_y);
int main(void)
{
FILE* fp=0;
int i = 0;
const char * teststring="I love Julia";
return 0;
}
/*
*以点阵方式显示一个ASCII字符
* dispch是要显示的字符,fillch是填充点阵的字符
* start_x,start_y是显示的起始坐标
*/
int displaychar(FILE *fp,char dispch,char fillch,char start_x,char start_y)
4、字库文件ascii_zk.bin的使用
ascii_zk.bin文件从ASCII码的空格(0x20)开始,每16个字节表示一个字符的点阵字模。以字母A为例,它的ASCII码是0x41,那么,它的字模数据的开始位置就是:
(0x41-0x20)*16
从这个位置开始依次读取16个字节,就是字母A的字模数据,将其显示即可。
例:用Linux的终端模拟显示点阵字符,终端屏幕中的每个字符位置就是一个点,程序如下。
[cpp] view plain copy
#include <stdio.h>
#include <unistd.h>
#include <curses.h>
#define START 0x20
#define DATANUM 0x10
unsigned char ch=0;
int i=0;
FILE *frp=0;
FILE *fwp=0;
for(i=0; i<5; i++)
buffer[i] = 0;
frp=fopen("ascii_zk.txt","r");
fwp=fopen("ascii_zk.bin","w");
while(buffer[4] != 0x2e) //全部数据以句号结尾
{
FILE * fp;
unsigned char i = 0;
fp = fopen("ascii.txt","w");
if(fp == 0)
{
perror("open");
return -1;
}
for(i=0x20;i<0x7F;i++)
{
fputc(i,fp);
}
return 0;
}
运行后,用记事本打开ascii.txt文件,会看到如下文本:
{
int location = ((dispch-START) * DATANUM);
char x=start_x;
char y=start_y;
int i=0;
int j=0;
char buf=0;
//将文件流指针移到到dispch字符点阵数据的起始位置
fseek(fp,location,SEEK_SET);
}
else
{
x++;
}
}
return 0;
}
该程序在Fedora12的终端中运行,效果如下:
fp=fopen("ascii_zk.bin","r");
initscr();
for(i=0;(teststring[i]!=0);i++)
{
displaychar(fp,teststring[i],'*',0+(i*8),0);
}
refresh();
while(1);
endwin();
fclose(fp);
开发环境:
Win7,Eclipse,MinGW
1、生成ASCII字符文件
ASCII编码的可打印字符是0x20~0x7E,先用运行下面这段代码,生成一个包含全部可打印字符的txt文件:
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char *argv[])
{
for(i=0; i<5; i++)
buffer[i]=fgetc(frp);
ch = c2x(buffer[2]);
ch = ch*16;
ch = ch+c2x(buffer[3]);
fputc(ch,fwp);
}
fclose(frp);
fclose(fwp);
return 0;
}
字库文件制作完毕。
3、将字模数据文件转换为二进制文件
将ascii_zk.txt文件中的每个字模数据转换为占一个字节的数,将所有的数据填充为一个二进制文件ascii_zk.bin。这样,按照ASCII码的顺序,ascii_zk.bin中每16个字节就可以绘制一个字符。文件转换的程序如下:
[cpp] view plain copy
for(i=0;i<DATANUM;i++)
{
buf = fgetc(fp);
//显示一个字节
for(j=0;j<8;j++)
{
move(y+j,x);
if(buf & (0x01<<j))
addch(fillch);
}
if(x == (start_x+7))
{
x = start_x;
y = (start_y+8);
temp = 0x0a+(ch-0x41);
else if(ch>=0x61 && ch<=0x66)
temp = 0x0a+(ch-0x61);
else
temp =0xff;
retuБайду номын сангаасn temp;
}
//将ascii_zk.txt转换为二进制文件
int main(void)
{
char buffer[5];