oracle行列转换
oraclesql一列转多行最简单的方法

oraclesql一列转多行最简单的方法在Oracle SQL中,一列转换为多行的最简单方法是使用UNION ALL 操作符结合SELECT语句。
下面给出一个例子来说明该方法。
假设我们有一个包含员工姓名和城市的表格,我们想将这些信息分开显示在不同的行上。
首先,我们创建一个示例表格并插入一些数据。
CREATE TABLE employeesemployee_id NUMBER,employee_name VARCHAR2(100),city VARCHAR2(100)INSERT INTO employees VALUES (1, 'John Doe', 'New York');INSERT INTO employees VALUES (2, 'Jane Smith', 'Los Angeles');INSERT INTO employees VALUES (3, 'Mike Johnson', 'Chicago');现在,我们可以使用UNIONALL操作符来将姓名和城市分开显示在不同的行上。
SELECT employee_name AS data FROM employeesUNIONALLSELECT city AS data FROM employees;在这个例子中,我们先选择员工姓名并将其命名为"data",然后使用UNION ALL操作符将结果与选择城市结果进行合并。
最终的结果是将一列数据转换为多行数据。
结果如下:DATA---------John DoeJane SmithMike JohnsonNew YorkLos AngelesChicago这种方法非常简单直观,但需要注意的是,UNIONALL操作符合并结果时会保留重复的行。
如果你希望去除重复的值,可以使用UNION操作符代替UNIONALL。
Oracle行转列,列转行

先来个简单的用法列转行Create table test (name char(10),km char(10),cj int)insert test values('张三','语文',80)insert test values('张三','数学',86)insert test values('张三','英语',75)insert test values('李四','语文',78)insert test values('李四','数学',85)insert test values('李四','英语',78)select name,sum(decode(km,'语文',CJ,0)) 语文,sum(decode(km,'数学',cj,0)) 数学,sum(decode(km,'英语',cj,0)) 英语from test1group by name姓名语文数学英语张三80 86 75李四78 85 78行转列with x as( selectname,sum(decode(km,'语文',CJ,0)) 语文 ,sum(decode(km,'数学',cj,0)) 数学,sum(decode(km,'英语',cj,0)) 英语fromtestgroupbyname)selectname,decode(rn,1, '语文', 2, '数学', 3,'英语') 课程, decode(rn, 1, 语文, 2, 数学, 3,英语) 分数from x, (selectlevel rn from dual connectby1=1andlevel<=3) (from 后面接两个表,是笛卡尔积)多行转字符串这个比较简单,用||或concat 函数可以实现?1 2 3 selectconcat(id,username) str fromapp_userselectid||username str fromapp_user字符串转多列实际上就是拆分字符串的问题,可以使用 substr 、instr 、regexp_substr 函数方式字符串转多行使用union all 函数等方式wm_concat 函数首先让我们来看看这个神奇的函数wm_concat (列名),该函数可以把列值以","号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据?1 2 3 4 5 6 7 createtabletest(id number,namevarchar2(20));insertintotest values(1,'a');insertintotest values(1,'b');insertintotest values(1,'c');insertintotest values(2,'d');insertintotest values(2,'e');效果1 : 行转列 ,默认逗号隔开?1 s electwm_concat(name) namefromtest;效果2: 把结果里的逗号替换成"|"?1 s electreplace(wm_concat(name),',','|') fromtest;效果3: 按ID 分组合并name?1 s electid,wm_concat(name) namefromtest groupbyid;sql 语句等同于下面的sql 语句?1 2 3 4 5 6 7 8 9 10 11 -------- 适用范围:8i,9i,10g 及以后版本 ( MAX + DECODE ) selectid, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ','|| name, null)) || max(decode(rn, 3, ','|| name, null)) str from(selectid,name,row_number() over(partition byid orderbyname) asrn fromtest) t groupbyid orderby1;-------- 适用范围:8i,9i,10g 及以后版本 ( ROW_NUMBER + LEAD ) selectid, str from(selectid,row_number() over(partition byid orderbyname) asrn,name|| lead(','|| name, 1) over(partition byid orderbyname) ||lead(','|| name, 2) over(partition byid orderbyname) ||12 13 14 15 lead(','|| name, 3) over(partition byid orderbyname) asstr fromtest) wherern = 1 orderby1;-------- 适用范围:10g 及以后版本 ( MODEL )selectid, substr(str, 2) str fromtest model returnupdatedrowspartition by(id) dimension by(row_number() over(partition byid orderbyname) asrn)measures (cast(nameasvarchar2(20)) asstr) rules upsertiterate(3) until(presentv(str[iteration_number+2],1,0)=0) (str[0] = str[0] || ','|| str[iteration_number+1])orderby1;-------- 适用范围:8i,9i,10g 及以后版本 ( MAX + DECODE ) selectt.id id,max(substr(sys_connect_by_path(,','),2)) str from(selectid, name, row_number() over(partition byid orderbyname) rn fromtest) tstart withrn = 1 connectbyrn = priorrn + 1 andid = priorid groupbyt.id;</span>懒人扩展用法:案例: 我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 当然有了,看我如果应用wm_concat 来让这个需求变简单,假设我的APP_USER 表中有(id,username,password,age )4个字段。
oracle实现行转列功能,并使用逗号进行隔开拼接,成为一条数据

oracle实现⾏转列功能,并使⽤逗号进⾏隔开拼接,成为⼀条数据有两种⽅式1、第⼀种:使⽤WM_CONCAT函数,不过这个函数已经被oracle弃⽤了,不建议使⽤,如果数据库中还有这个函数也可以使⽤select sfc_no,wm_concat(mark_operation_id) from bp_marking where create_date>sysdate-1/24group by sfc_no简单说⼀下就是查询bp_marking表中的sfc_no与对应的所有的mark_operation_id的字段,并且合并到⼀列中结果显⽰如下:实现去重:就是把重复的去掉直接加⼀个distinct即可select sfc_no,wm_concat(distinct mark_operation_id) from bp_marking where create_date>sysdate-1/24group by sfc_no如果没有这个函数也想添加的话,可以试⼀下如下的⽅法(具体是否能⽤我没试过)2、第⼆种:使⽤LISTAGG函数select sfc_no,LISTAGG(mark_operation_id,',') within group (order by mark_operation_id) from bp_marking where create_date>sysdate-1/24group by sfc_no结果跟上⾯的结果是⼀样的。
如何实现去重:把表再嵌套⼀层即可。
即先把重复的数据去掉,然后再对这个表进⾏listagg操作。
select sfc_no,LISTAGG(mark_operation_id,',') within group (order by mark_operation_id) from (select distinct sfc_no,mark_operation_id from bp_marking where create_date 执⾏完之后有时候会显⽰字符串连接过长的问题,因为listagg设定的字符串长度只有4000,超过4000就会报错。
Oracle-casewhen用法-行列转换
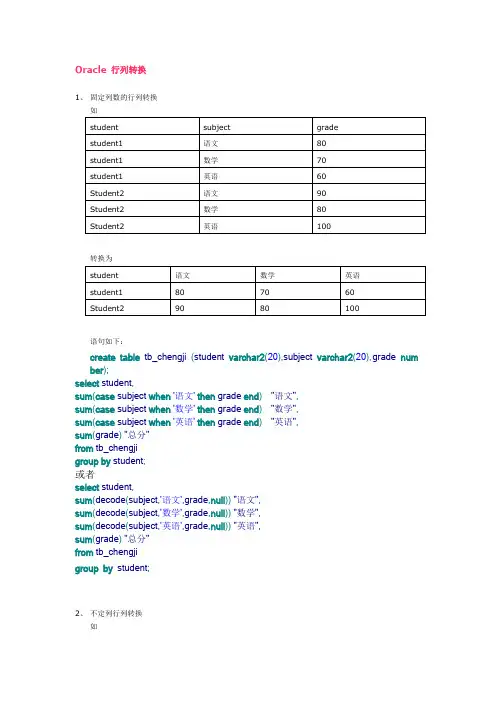
Oracle 行列转换1、固定列数的行列转换如转换为语句如下:create table tb_chengji (student varchar2(20),subject varchar2(20),g rade num ber);select student,sum(case subject when'语文'then grade end)"语文",sum(case subject when'数学'then grade end)"数学",sum(case subject when'英语'then grade end)"英语",sum(grade) "总分"from tb_chengjigroup by student;或者select student,sum(decode(subject,'语文',grade,null)) "语文",sum(decode(subject,'数学',grade,null)) "数学",sum(decode(subject,'英语',grade,null)) "英语",sum(grade) "总分"from tb_chengjigroup by student;2、不定列行列转换如c1 c2--- -----------1 我1 是1 谁2 知2 道3 不……转换为1 我是谁2 知道3 不这一类型的转换可以借助于PL/SQL来完成,这里给一个例子create table ttt (c1 number,c2 varchar2(10));select*from ttt;create or replace function get_c2(tmp_c1 number)return varchar2iscol_c2 varchar2(4000);beginfor cur in(select c2 from ttt where c1=tmp_c1)loopcol_c2 := col_c2||cur.c2;end loop;col_c2 := rtrim(col_c2,1);return col_c2;end;select distinct c1 ,get_c2(c1) cc2 from tttorder by c1;或者不用pl/sql,利用分析函数和CONNECT_BY 实现:select c1, substr (max(sys_connect_by_path (c2,';')),2)name from(select c1, c2, rn, lead (rn) over (partition by c1 order by rn) rn1 from(select c1, c2, row_number () over (order by c2) rnfrom ttt))start with rn1 is nullconnect by rn1 =prior rngroup by c1;3、列数不固定(交叉表行列转置)这种是比较麻烦的一种,需要借助pl/sql:原始数据:CLASS1 CALLDATE CALLCOUNT1 2005-08-08 401 2005-08-07 62 2005-08-08 773 2005-08-09 333 2005-08-08 93 2005-08-07 21转置后:CALLDATE CallCount1 CallCount2 CallCount3------------ ---------- ---------- ----------2005-08-09 0 0 332005-08-08 40 77 92005-08-07 6 0 21试验如下:1). 建立测试表和数据CREATE TABLE t22(class1 VARCHAR2(2BYTE),calldate DATE,callcount INTEGER);INSERT INTO t22(class1, calldate, callcount)VALUES('1', TO_DATE ('08/08/2005','MM/DD/YYYY'),40); INSERT INTO t22(class1, calldate, callcount)VALUES('1', TO_DATE ('08/07/2005','MM/DD/YYYY'),6); INSERT INTO t22(class1, calldate, callcount)VALUES('2', TO_DATE ('08/08/2005','MM/DD/YYYY'),77); INSERT INTO t22(class1, calldate, callcount)VALUES('3', TO_DATE ('08/09/2005','MM/DD/YYYY'),33); INSERT INTO t22(class1, calldate, callcount)VALUES('3', TO_DATE ('08/08/2005','MM/DD/YYYY'),9); INSERT INTO t22(class1, calldate, callcount)VALUES('3', TO_DATE ('08/07/2005','MM/DD/YYYY'),21);COMMIT ;select calldate,nvl(max(case when class1 =1then callcount end),0)a1, nvl(max(case when class1 =2then callcount end),0) a2, nvl(max(case when class1 =3then callcount end),0)a3 from t22group by calldateorder by calldate desc;CALLDATE CallCount1 CallCount2 CallCount3------------ ---------- ---------- ----------2005-8-9 0 0 332005-8-8 40 77 92005-8-7 6 0 21。
oracle的行转列函数

oracle的行转列函数Oracle是一种现代化、高效的数据库管理系统,它在行列转换方面有着强大的转换函数和工具。
行列转换函数是Oracle数据库中的一个重要组成部分,它可以用来将行数据转换为列数据,或将列数据转换为行数据,这在业务分析、数据挖掘等方面都有着极大的用处。
本文将简要介绍Oracle中的行列转换函数。
1. UNPIVOT函数UNPIVOT函数可以将一张带有多个列的表,转换为只有两列的表,其中一列是原来表格的列名,另一列是原来表格这一列的值。
UNPIVOT函数的语法如下:```SELECT *FROM table_name UNPIVOT((value1, 'column1') FOR column1 IN (column2, column3, ...),(value2, 'column2') FOR column2 IN (column3, column4, ...),...);```其中,table_name代表要转换的表格的名称,columnX代表原表格中的列名,valueX代表原表格中的值。
例如,若原表格中有A、B、C、D四个列,包含多行数据,那么可以使用以下语句将其转换为只有两列的表:该语句将生成两列,一列为name,包含了A、B、C、D四个列的名称,另一列为value,包含了相应列的值。
这样就可以方便地进行数据分析了。
该语句将生成一列key,表示原表格中的唯一关键字列,另外还有A、B、C三列,表示原表格中包含的三个列,每行记录表示一个唯一的key值和对应的A、B、C三个列的值。
3. CROSS JOIN函数CROSS JOIN函数可以将两个表中的每一个记录都做一个笛卡尔积,生成一个新表。
例如,若有两个表T1和T2,T1有列A、B,T2有列C、D,可以使用以下语句将它们进行笛卡尔积,生成一个新表:```SELECT *FROM T1CROSS JOIN T2;```该语句将生成一个新表,包含了所有T1和T2中的记录的笛卡尔积。
Oracle行列转换函数--Pivot和Unpivot

Oracle⾏列转换函数--Pivot和UnpivotPivot 和 Unpivot使⽤简单的 SQL 以电⼦表格类型的交叉表报表显⽰任何关系表中的信息,并将交叉表中的所有数据存储到关系表中。
Pivot如您所知,关系表是表格化的,即,它们以列-值对的形式出现。
假设⼀个表名为 CUSTOMERS。
COPYCopied to ClipboardError: Could not CopySQL> desc customersName Null? TypeCUST_ID NUMBER(10)CUST_NAME VARCHAR2(20)STATE_CODE VARCHAR2(2)TIMES_PURCHASED NUMBER(3)选定该表:select cust_id, state_code, times_purchasedfrom customersorder by cust_id;输出结果如下:CUST_ID STATE_CODE TIMES_PURCHASED1 CT 12 NY 103 NJ 24 NY 4...and so on ...SQL> desc customersName Null? TypeCUST_ID NUMBER(10)CUST_NAME VARCHAR2(20)STATE_CODE VARCHAR2(2)TIMES_PURCHASED NUMBER(3)选定该表:select cust_id, state_code, times_purchasedfrom customersorder by cust_id;输出结果如下:CUST_ID STATE_CODE TIMES_PURCHASED1 CT 12 NY 103 NJ 24 NY 4...and so on ...注意数据是如何以⾏值的形式显⽰的:针对每个客户,该记录显⽰了客户所在的州以及该客户在商店购物的次数。
oracle行转列decode写法
在Oracle中,可以使用DECODE函数将行数据转换为列数据。
DECODE函数的语法如下:sql复制代码DECODE(expression, search, result [, search, result]... [, default])该函数将expression的值与search参数进行比较,如果找到匹配的值,则返回result参数的值。
如果没有找到匹配的值,则返回default参数的值(如果提供)。
以下是一个示例,演示如何使用DECODE函数将行数据转换为列数据:假设有一个名为"sales"的表,包含以下列:customer_id、product_id和sales_amount。
现在想要将每个客户的销售数据按产品汇总,并按照销售金额降序排列。
首先,使用DECODE函数将产品ID转换为产品名称:sql复制代码SELECT customer_id,DECODE(product_id, 1001, 'Product A', 1002, 'Product B', 1003, 'Product C', 'Other') AS product_name,sales_amountFROM salesORDER BY customer_id, product_name, sales_amount DESC;上述查询中,DECODE函数将product_id列的值与1001、1002和1003进行比较,如果找到匹配的值,则返回对应的字符串,否则返回'Other'。
这样就可以将产品ID转换为产品名称。
接下来,使用GROUP BY和SUM函数对每个客户的销售数据进行汇总:sql复制代码SELECT customer_id,product_name,SUM(sales_amount) AS total_salesFROM (SELECT customer_id,DECODE(product_id, 1001, 'Product A', 1002, 'Product B', 1003, 'Product C', 'Other') AS product_name,sales_amountFROM sales) tGROUP BY customer_id, product_name;上述查询中,内部查询将产品ID转换为产品名称,外部查询对每个客户的销售数据进行汇总,并按照产品名称和销售金额降序排列。
oraclesql一列转多行最简单的方法
oraclesql一列转多行最简单的方法在Oracle SQL中,有多种方法可以将一列数据转换为多行。
以下是几种最简单的方法:1.使用UNIONALL操作符:可以使用UNIONALL操作符将多个SELECT语句的结果合并成一个结果集,从而将一列数据转换为多行。
每个SELECT语句都应该只返回一行数据,并且列数和数据类型必须匹配。
例如,假设我们有一个表单名为employees,其中有一个列名为name,包含多个员工的姓名。
我们可以使用以下语句将该列转换为多行:```sqlSELECT name FROM employeesUNIONALLSELECT name FROM employeesUNIONALLSELECT name FROM employees;```这将返回一个包含所有姓名的结果集。
2.使用CONNECTBYLEVEL子句:CONNECTBYLEVEL子句可以用于生成指定的行数,然后通过连接其他表获取相关的数据。
在这种情况下,我们可以使用CONNECTBYLEVEL子句生成多行,然后连接到原始表以获取实际数据。
例如,使用以下语句生成从1到10的数字序列:```sqlSELECTLEVELFROM dualCONNECTBYLEVEL<=10;```然后,我们可以使用该序列连接到原始表中获取实际数据:```sqlSELECT FROM employees eJOIN (SELECT LEVEL AS numFROM dualCONNECTBYLEVEL<=10)lON l.num = e.employee_id;```这将返回一个包含10个姓名的结果集,每个重复10次。
3.使用PIVOT操作:如果我们希望将一列数据转换为多行,并且我们知道有限的可能值,可以使用PIVOT操作。
这要求我们事先知道有多少个可能的值,并且使用CASE语句或PIVOT运算符将每个可能的值转换为一个列。
oracle的行转列函数
oracle的行转列函数Oracle的行转列函数是指将一些列的多个行值转换为一行,通常用于将多行数据合并成单行数据,以便于进行数据汇总或者分析。
在Oracle中,行转列的主要方法有使用PIVOT和UNPIVOT函数以及使用CASE语句进行条件判断。
1.使用PIVOT函数PIVOT函数用于将行数据转换为列数据。
它的语法如下:PIVOT聚合函数FOR列名IN('列值1'AS'新列名1','列值2'AS'新列名2',...);例如,假设有一个表student,包含了姓名(name)、课程(course)和分数(score)三个字段,如下所示:name course score-----------------------Alice Math 85Alice Chinese 90Alice English 95Bob Math 80Bob Chinese 75Bob English 85现在我们希望将每个学生的课程及其对应的分数转换为一行数据,可以使用如下的PIVOT语句:SELECT*FROMSELECT name, course, scoreFROM studentPIVOTAVG(score) -- 可以是其他聚合函数,如SUM、MAX等FOR courseIN ('Math' AS Math, 'Chinese' AS Chinese, 'English' AS English);执行该查询后,将得到如下的结果:name Math Chinese English-------------------------------Alice 85 90 95Bob 80 75 852.使用UNPIVOT函数UNPIVOT函数是PIVOT函数的逆操作,用于将列数据转换为行数据。
它的语法如下:UNPIVOT转换列名FOR列名IN(新列名1AS'列值1',新列名2AS'列值2',...);例如,假设有一个表student,包含了姓名(name)、Math、Chinese 和English三个科目的分数,我们希望将这三个科目的分数转换为一列数据,可以使用如下的UNPIVOT语句:SELECT*FROMSELECT name, Math, Chinese, EnglishFROM studentUNPIVOTscoreFOR courseIN (Math AS 'Math', Chinese AS 'Chinese', English AS'English');执行该查询后,将得到如下的结果:name course score---------------------Alice Math 85Alice Chinese 90Alice English 95Bob Math 80Bob Chinese 75Bob English 853.使用CASE语句进行条件判断除了使用PIVOT和UNPIVOT函数外,我们还可以使用CASE语句进行条件判断,实现行转列的功能。
oracle同时多行转多列函数
oracle同时多行转多列函数Oracle中没有直接提供将多行转换为多列的函数。
但是可以使用一些技巧和功能来实现这样的转换。
下面将介绍一种常见的实现方法。
一、场景描述假设有一个表格名为"example_table",具有以下结构:```ID | Name | Value---+-------+-------1 | John | 101 | John | 201 | John | 302 | Alice | 152 | Alice | 25```我们需要将上述表格中的数据按照ID和Name两个列进行分组,并将对应的Value值转换为多列。
如下所示:```ID | Name | Value_1 | Value_2 | Value_3---+-------+---------+---------+--------1 | John | 10 | 20 | 302 | Alice | 15 | 25 |```二、解决方案我们可以使用Oracle中的PIVOT功能以及ROW_NUMBER()函数来实现上述转换。
具体步骤如下:Step 1:使用ROW_NUMBER()函数为每个ID和Name对应的Value值分配序号。
```SELECT ID, Name, Value, ROW_NUMBER() OVER (PARTITION BY ID, Name ORDER BY Value) AS rnFROM example_table;```Step 2:使用PIVOT函数将序号为1、2、3的Value值分别转换为Value_1、Value_2、Value_3列。
```SELECT ID, Name, Value_1, Value_2, Value_3FROM (SELECT ID, Name, Value, ROW_NUMBER() OVER (PARTITION BY ID, Name ORDER BY Value) AS rnFROM example_table)PIVOT (MAX(Value)FOR rn IN (1 as Value_1, 2 as Value_2, 3 as Value_3));```三、实际示例为了更加直观地展示上述解决方案的实际效果,我们可以将其应用到一个真实的示例中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
行列转换
在数据处理中,我们常会遇到行列转换的需求,通常我们是写函数或存储过程来实现。
Oracle在OLAP的支持上添加了蛮多的支持,有许多分析函数可以使用。
我们也可以使用分析函数来实现行列转换的。
测试数据如下
一、使用max及decode语法
rn列是使用ritem列对应的值进行分组,并对其编号。
这样91.2918W.220就会有1、2、3、4四个小项;91.2919W.220只有1一个小项,使用聚合函数就可以处理了。
结果呈现如下:
二、使用row_number及lead语法
三、Model
10g以后版本
通过建立多维度分析模型,将cell单元格进行修改达到目的。
四、sys_connect_by_path
9i、10g等版本
结果呈现:
10g版本
结果呈现:
五、wmsys.wm_concat
10g更简单。