Oracle Database 10g - DataPump
用Oracle 10g Data Pump重组表空间

Oracle 10g版本对数据输入与输出的操作功能进行重新设计,在输入或输出工作中增加断开和连接的功能。
对这些功能做微小改动,就可利于DBA表空间的操作。
作为整体单元输出表空间过去的输出和输入功能有3种模式:依赖于对象输出,如索引的单个表格;输出某个用户所有的对象;输出整个数据库。
但是表空间是一个难于处理的问题。
不同用户的对象存储在给定的表空间中,但是某些对象可能存储在其它表空间。
因此,唯一的解决方法则是使用查询数据字典查找列表及其从属主,然后使用“table-mode export”输出单个整体单元。
Oracle 10g版本中,由于包含输出“Data Pump”(expdp),可以直接从表空间输出所有对象。
TABLESPACES参数允许指定需要输出的表空间。
TABLESPACES=name [,...]如果数据库继承很多基于字典的表空间,以上方法显得更加非常有用。
并且,可在本地重新创建表空间而减少碎片,然后再重新导入内容。
在输入时重命名数据文件名如果将数据库从一平台转移到另一平台,在数据文件导入之前,DBA需要预先创建表空间。
为什么呢?因为在转储文件中包含原始数据库操作系统格式的数据文件路径,将转储文件输入到其他操作系统时,则有可能产生错误。
在Oracle 10g版本的输入(impdp)功能,其REMAP_DATAFILE参数可重命名数据文件,以消除以上问题。
其格式如下:REMAP_DATAFILE=source_datafile:target_datafile这一选项只作用于FULL输入,并且指定的userID必须为IMP_FULL_DATABASE。
输入时更改表空间名称Impdp功能允许向不同的表空间加载对象。
在10g版本出现以前,这一操作非常复杂。
首先,因为没有写操作权限,必须移除原始表空间的限额,然后再设置表空间。
再输入过程中,原始表空间中的对象可以存储在设置后的表空间中。
当任务完成后,必须进行将表空间恢复到原来状态。
OracleDatabase10g数据库安装及配置教程
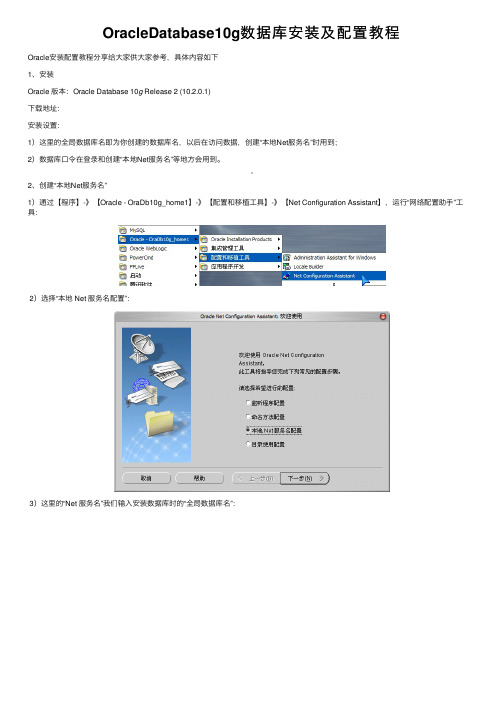
OracleDatabase10g数据库安装及配置教程Oracle安装配置教程分享给⼤家供⼤家参考,具体内容如下1、安装Oracle 版本:Oracle Database 10g Release 2 (10.2.0.1)下载地址:安装设置:1)这⾥的全局数据库名即为你创建的数据库名,以后在访问数据,创建“本地Net服务名”时⽤到;2)数据库⼝令在登录和创建“本地Net服务名”等地⽅会⽤到。
2、创建“本地Net服务名”1)通过【程序】-》【Oracle - OraDb10g_home1】-》【配置和移植⼯具】-》【Net Configuration Assistant】,运⾏“⽹络配置助⼿”⼯具:2)选择“本地 Net 服务名配置”:3)这⾥的“Net 服务名”我们输⼊安装数据库时的“全局数据库名”:4)主机名我们输⼊本机的IP地址:5)测试数据库连接,⽤户名/密码为:System/数据库⼝令(安装时输⼊的“数据库⼝令”):默认的⽤户名/密码错误:更改登录,输⼊正确的⽤户名/密码:测试成功:3、PLSQL Developer 连接测试输⼊正确的⽤户名/⼝令:成功登陆:数据库4、创建表空间打开sqlplus⼯具:sqlplus /nolog连接数据库:conn /as sysdba创建表空间:create tablespace camds datafile 'D:\oracle\product\10.2.\oradata\camds\camds.dbf' size 200m autoextend on next 10m maxsize unlimited;5、创建新⽤户运⾏“P/L SQL Developer”⼯具,以DBA(⽤户名:System)的⾝份登录:1)新建“User(⽤户):2)设置⽤户名、⼝令、默认表空间(使⽤上⾯新建的表空间)和临时表空间:3)设置⾓⾊权限:4)设置”系统权限“:5)点击应⽤后,【应⽤】按钮变灰,新⽤户创建成功:6)新⽤户登录测试:输⼊新⽤户的“⽤户名/⼝令”:新⽤户“testcamds”成功登陆:6、导⼊导出数据库先运⾏cmd命令,进⼊命令⾏模式,转到下⾯的⽬录:D:\oracle\product\10.2.0\db_1\BIN【该⽬录下有exp.exe⽂件】1)导⼊命令语法:imp userid/pwd@sid file=path/file fromuser=testcamds touser=userid命令实例:imp testcamds/123@camds file=c:\testcamds fromuser=testcamds touser=testcamds导⼊结果:2)导出:命令语法:exp userid/pwd@sid file=path/file owner=userid命令实例:exp testcamds/123@camdsora file=c:\testcamds owner=testcamds 导⼊结果://创建临时表空间create temporary tablespace zfmi_temptempfile 'D:\oracle\oradata\zfmi\zfmi_temp.dbf'size 32mautoextend onnext 32m maxsize 2048mextent management local;//tempfile参数必须有//创建数据表空间create tablespace zfmiloggingdatafile 'D:\oracle\oradata\zfmi\zfmi.dbf'size 100mautoextend onnext 32m maxsize 2048mextent management local;//datafile参数必须有//删除⽤户以及⽤户所有的对象drop user zfmi cascade;//cascade参数是级联删除该⽤户所有对象,经常遇到如⽤户有对象⽽未加此参数则⽤户删不了的问题,所以习惯性的加此参数//删除表空间前提:删除表空间之前要确认该表空间没有被其他⽤户使⽤之后再做删除drop tablespace zfmi including contents and datafiles cascade onstraints;//including contents 删除表空间中的内容,如果删除表空间之前表空间中有内容,⽽未加此参数,表空间删不掉,所以习惯性的加此参数//including datafiles 删除表空间中的数据⽂件//cascade constraints 同时删除tablespace中表的外键参照如果删除表空间之前删除了表空间⽂件,解决办法: 如果在清除表空间之前,先删除了表空间对应的数据⽂件,会造成数据库⽆法正常启动和关闭。
oracle使用数据泵导出和导入

使用数据泵导出和导入几乎所有DBA都熟悉oracle的导出和导入实用程序,它们将数据装载进或卸载出数据库,在oracle database 10g和11g中,你必须使用更通用更强大的数据泵导出和导入(Data Pump Export and Import)实用程序导出和导入数据。
以前的导出和导入实用程序在oracle database 11g中仍然可以使用,但是Oracle强烈建议使用数据泵(Data Pump)技术,因为它提供了更多的高级特性。
例如,你可以中断导出/导入作业,然后恢复它们;可以重新启动已失败的导出和导入作业;可以重映射对象属性以修改对象;可以容易地从另一个会话中监控数据泵的作业,甚至可以在作业过程中修改其属性;使用并行技术很容易快速移动大量的数据;因为oracle提供了针对数据泵技术的API,所以可以容易地在PL/SQL 程序中包含导出/导入作业;可以使用更强大的可移植表空间特性来快速移植大量的数据,甚至可在不同操作系统平台之间移动。
与旧的导出和导入实用程序不同,数据泵程序有一组可以在命令行中使用的参数以及一组只能以交互方式使用的特殊命令,你可以通过在命令行中输入expdp help = y 或者impdp help = y快速获取所有数据泵参数及命令的概述。
一.数据泵技术的优点原有的导出和导入技术基于客户机,而数据泵技术基于服务器。
默认所有的转储,日志和其他文件都建立在服务器上。
以下是数据泵技术的主要优点:1.改进了性能2.重新启动作业的能力3.并行执行的能力4.关联运行作业的能力5.估算空间需求的能力6.操作的网格方式7.细粒度数据导入功能8.重映射能力二.数据泵导出和导入的用途1.将数据从开发环境转到测试环境或产品环境2.在不同的操作系统平台上的oracle数据库直接的传递数据3.在修改重要表之前进行备份4.备份数据库5.把数据库对象从一个表空间移动到另一个表空间6.在数据库直接移植表空间7.提取表或其他对象的DDL注意:数据库不建立完备的备份,因为在导出文件中没有灾难发生时的最新数据。
Oracle数据库10g中的数据泵

Oracle 应用程序种子数据库: 应用程序种子数据库:
密集的元数据:392K 个对象,200 个模式,10K 个表,总共 2.1 Gb 的数据 原来的 exp / imp 总共花费:32 小时 50 分钟
–
exp 2 exp:2 小时 13 分钟
imp imp: 30 小时 37 分钟
数据泵 expdp / impdp 总共花费:15 小时 40 分 钟
扩展 I/O! Parallel= 不超过两倍的 CPU 数量: 不要超过磁盘最高容量。
–
必然的结果:扩展
I/O!!!
为 AQ 消息发送和元数据 API 查询提供足够的 SGA 为长时间运行的查询提供足够的回滚
这就是性能调整!
大型的互联网公司
2 个事实表: 16.2M 行,2 Gb 个事实表:
程序
特性:检查点 重新启动 特性:检查点/重新启动
作业进度记录在一个“主表”中 可以显式地停止并在以后重新启动:
–
在当前项目完成后停止或立即停止
异常终止的作业也可以重新启动 如果有问题可以在重启时跳过当前的对象
特性: 特性:网络模式
网络导入:直接从一个数据库加载 另一个数据库 网络导出:将一个远程数据库卸载至一个本地的转储文 件集中
Oracle 数据库 10g 中的数据泵: 超高速数据转移实用工具的基础
甲骨文公司
数据泵: 数据泵:概述
什么是数据泵? 主要特性 体系结构 性能 要记住的事情 对原来的 exp / imp 的一些看法
数据泵:什么是数据泵? 数据泵:什么是数据泵?
基于服务器的工具,用于在加载和卸载数据和元数 据时获得高性能 可调用:DBMS_DATAPUMP。在内部使用 DBMS_METADATA 以直接路径 (Direct Path) 流的格式写入数据。以 XML 的格式写入元数据 新的客户端程序 expdp 和 impdp:原来的 exp / imp 的扩展集 流、逻辑备用、网格、可移动表空间和数据挖掘初 始实例化的基础。
数据库Oracle10g简介及事故数据库的创建

Oracle10g的应用领域
金融
Oracle10g在金融行业得到了 广泛应用,如银行、证券、保
险等。
制造
Oracle10g在制造业中也有着 广泛的应用,如航空、汽车、 电子等。
政府
Oracle10g在政府机构中也有 着广泛的应用,如税务、公安 、交通等。
其他
除了以上领域,Oracle10g还 广泛应用于医疗、教育、物流
测试
对数据库进行功能和性能测试,确 保满足业务需求。
03
02
导入数据
将事故数据导入到数据库中,并进 行数据清洗和转换。
上线运行
将数据库正式上线运行,并持续监 控和维护数据库的运行状态。
04
03
CATALOGUE
Oracle10g的事故数据库管理
事故数据的存储和管理
事故数据存储
Oracle10g提供了高效的事故数据存储机制,支持海 量数据的存储和检索。
THANKS
感谢观看
归档日志优化
合理配置归档日志模式和存储路径,确保数据安全和恢复效率。
事故数据库的网络优化
网络架构优化
采用合理的网络架构,如使用多网卡、负载均衡 等,提高网络传输效率。
网络参数优化
根据实际需求调整网络参数设置,如TCP/IP协议 参数、网络带宽等,提高网络传输性能。
数据压缩
对传输数据进行压缩,减少网络传输量,提高数 据传输效率。
支持数据可视化技术,如图表、 仪表盘等,直观展示事故数据和 趋势。
事故数据的备份和恢复
数据备份策略
根据实际情况制定合理的事故数 据备份策略,确保数据安全和可
靠。
数据恢复方法
提供多种数据恢复方法,如全量备 份、增量备份等,确保数据快速恢 复。
oracle10g数据库安装

oracle10g数据库安装ORACLE10G数据库的安装注意:此教程分为四部分,第一部分教你安装数据库,比较简单。
第二部分教你如何在安装好的数据库上创建新的数据库,过程比较复杂,请认真完成,掌握每一步操作的实际内涵。
第三部分教你创建一个数据库监听器和oracle服务的管理。
第四部分教你使用数据库管理工具SQLDeveloper连接数据库。
第一部分:安装数据库单击“开始安装”,就可以安装ORACLE10g,一般会检查系统配置是否符合要求,然后出现“OracleDataBae10g安装”对话框,如下图所示:在安装OracleDataBae10g时可以选择“基本安装”和“高级安装”两种方法。
选择“基本安装”时,“Oracle主目录位置”用于指定OracleDataBae10g软件的存放位置;“安装类型”用于指定Oracle产品的安装类型(企业版、标准版和个人版)。
如果选择“创建启动数据库”,那就要指定全局数据库名称和数据库用户的口令。
注意我们不选择创建数据库:然后一直默认点击下一步,下一步,最后就安装完成了。
注意:如果对ORACLE比较熟悉的同学可以选择高级安装。
但是在安装的时候建议不添加数据库,建议在安装完成后再创建数据库。
第二部分:创建数据库(一些基本概念:数据库名(databaename):就是数据库的名称标识,如myOracle,这种叫法一般只适用于单机;全局数据库名(globaldatabaename):就是数据库处于一个网络中的名称标识。
比如数据库宿主机的域为mydomain,则数据库的全局数据库名为myOracle.mydomain;实际上myOracle和myOracle.mydomain两者指的是同一个数据库.即:全局数据库名=数据库名+"."+网络位置(宿主机所在的域)SID=Oracle实例SID是Oracle实例的唯一名称标识,用户去访问数据库,实际上是向某一个Oracle实例发送请求,oracle实例负责向数据库获取数据。
Oracle数据库Data Pump的使用

Oracle数据库Data Pump的使用第1章Data Pump简介1.1使用Data Pump的优势Data Pump是Oracle 10g版本开始支持的新特性,支持并行处理导入、导出任务;支持暂停和重启动导入、导出任务;支持导入时通过加入参数实现导入过程中修改对象属主、数据文件和表空间等。
现在的数据规模和数据量增长迅速,以前几百M或者几G可以使用IMP/EXP 工具导入导出,也花不了多久,但对于现在动不动就几十G或上百G的数据量,再使用IMP/EXP工具就显得力不从心了,大量时间浪费在等待上。
而Data Pump 的执行速度比IMP/EXP要快数倍,也是Oracle推荐的数据导入导出工具。
第2章使用Data Pump的需求和权限2.1环境要求1.数据库必须是Oracle 10g以上版本(包括10g)2.Data Pump使用expdp生成的.dmp文件,只能使用impdp导入,不能使用imp来进行导入;反之,exp生成的dmp文件,也不能使用impdp进行导入。
2.2在数据库中创建Directory和赋予相应的角色权限(注意:需要使用sys或system用户创建)1.Directory是在数据库中创建的一个指向操作系统中的一个路径目录,导出的数据文件“.dmp”会保存在这里。
(注:先在操作系统上创建目录D:\BACKUP)SQL> create directory dump_file_dir as 'D:\BACKUP';2.创建完后授予用户在此目录读和写的权限SQL> grant read,write on directory dump_file_dir to topo6;3.赋予用户角色权限SQL> grant exp_full_database to topo6;下面以一个例子做示范:例:第3章执行数据的导出3.1导出命令(导出前停止应用程序)C:\>expdp topo6/topo6 directory=dump_file_dir dumpfile=YW_NCC6.0R2_130521 .dmp logfile=YW_NCC6.0R2_130521.log例:(数据文件占用了系统实际空间13G,由于Data Pump在导出时只会对真实已写入的数据块进行导出,空块不会计算在内,这也是速度快的关键)开始导出:导出完毕:对应的操作系统目录中的文件:第4章执行数据的导入1.在需要执行导入的数据库中创建Directory目录,把要导入的.dmp文件拷贝到该目录下SQL> create directory dump_file_dir as 'D:\BACKUP';2.创建完后授予用户在该目录读写的权限SQL> grant read,write on directory dump_file_dir to topo6;3.赋予用户角色权限SQL> grant imp_full_database to topo6;例子:(导入的时间会比较久一些,该例中最后花费30分钟,因为数据导入后,要处理索引和约束)导入前操作系统上对应目录的.dmp文件开始导入:第5章Data Pump的扩展使用5.1并行导入、导出5.1.1并行导出并行可以指定多个dumpfile,parallel的值等于指定dumpfile的数量。
Oracle Database 10g基础教程 第3章 Oracle Database 10g的新增

清华大学出版社
3.1 服务器可管理性
服务器的可管理性提高,就是指数据库管理人员管理数据库的操作变 得更加简单和方面。
在服务器可管理性方面,Oracle Database 10g系统新增的主要内容 包括:
– 统计采集 – 刷新高速缓冲存储器 – 数据库资源管理器的新功能 – 调度器的改变 – 用户可配置的默认标空间 – 重命名表空间 – 删除数据库 – 大LOB – 自动化撤销保留 – 压缩联机段 – 使用新的联机重定义功能
05.11.2020
第3页
Oracle Database 10g基础教程
教学过程
3.1 服务器可管理性 3.2 性能调整 3.3 安全性 3.4 可用性和可恢复性 3.5 商业智能 3.6 应用程序开发方面 3.7 其他新增的数据库功能
05.11.2020
清华大学出版社
第4页
Oracle Database 10g基础教程
一旦配置了一个新的默认表空间,那么所 有新用户将被指向该默认的表空间,而不 是system表空间。
这种功能增强了使用表空间的灵活性。
05.11.2020
第10页
Oracle Database 10g基础教程
其他新增功能
清华大学出版社
在服务器管理方面,除了前面讲述的新增 功能之外,还包括:
– 删除数据库 – 提高LOB对象的限制 – 自动化重做保留 – 联机压缩段等
– 创建从指定消费者组到指定会话的映射
05.11.2020
第8页
Oracle Database 10g基础教程
调度器的改变
清华大学出版社
Oracle Database 10g提供了一种新的调度 作业的方法,即提供了调度器(Scheduler)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
O R A C L E D A T A B A S E10G D A T A P U M P:F O U N D A T I O N F O R U L T R A-H I G H S P E E D D A T A M O V E M E N T U T I L I T I E SGeorge H. Claborn, Oracle CorporationD ATA P UMP O VERVIEWData Pump is a new facility in the Oracle Database 10g Server that enables very high speed data and metadata loading and unloading to / from the Oracle Database. It automatically manages and schedules multiple, parallel streams of load or unload for maximum throughput. Data Pump infrastructure is callable via the PL/SQL packageDBMS_DATAPUMP. Thus, custom data movement utilities can be built using Data Pump. Oracle Database 10g will see four of these: New command line export and import clients (expdp & impdp), a web-based Enterprise Manager export / import interface and a custom interface for the movement of complex Data Mining models. Data Pump is also the foundation for several other key features in the Oracle server: Streams-based Replication, Logical Standby, and Transportable Tablespaces.When gathering requirements for Data Pump with large customers, we repeatedly heard, “Time is money. If you do nothing else, make the export / import operation much faster for large amounts of data”. We took that to heart. Data Pump dramatically decreases the elapsed time for most large export / import operations; in some data-intensive cases, by more than two orders of magnitude. In addition to increased performance, our customers enumerated many other requirements. As a result, Data Pump-based export and import clients support all the functionality of the originalexp/imp as well as many new features such as checkpoint restart, job size estimation, very flexible, fine-grained object selection, direct loading of one instance from another and detailed job monitoring.Data Pump is an integral feature of Oracle Database 10g and therefore is available in all configurations. However, parallelism with a degree greater than one is only available in Enterprise Edition.This paper will start with an overview of Data Pump’s architecture then describe its main features along with some best-use practices, then provide a brief comparison to the original export and import facilities.A RCHITECTUREM ASTER T ABLEAt the heart of every Data Pump operation is the “Master Table” (MT). This is a table created in the schema of the user running a Data Pump job. It is a directory which maintains all facets about the job: The current state of every object exported or imported and their locations in the dumpfile set, the job’s user-supplied parameters, the status of every worker process, the current set of dumpfiles, restart information, etc.The MT is built during a file-based export job and is written to the dumpfile set as the last step. Conversely, loading the MT into the current user’s schema is the first step of a file-based import operation and is used to sequence the creation of all objects imported.During export, note that the MT cannot span files (as other written objects can). If dumpfile sizes are being limited by the FILESIZE parameter, this must be large enough to contain the master table. As a reference point, a database with approximately 400,000 objects including 10000 tables creates a master table 189 Mb in size.The MT is the key to Data Pump’s restart capability in the event of a planned or unplanned job stoppage. Since it maintains the status of every object comprising the job, upon restarting, Data Pump knows what objects were currently being worked on and if they completed successfully or not.P ROCESS S TRUCTUREThere are various processes that comprise a Data Pump job. They are described in the order of their creation.Client Process – This is the process that makes calls to Data Pump’s API. As mentioned earlier, Oracle Database 10gships four clients of this API. This paper will only discuss the new export / import clients, expdp and impdp. They have a very similar look and feel to the original exp and imp, but have far more capabilities as will be described later. Since Data Pump is completely integrated into the Oracle Database server, a client is not required once a job is underway. Multiple clients may attach and detach from a job as necessary for monitoring and control.Shadow Process – This is the standard Oracle shadow (or foreground) process created when a client logs in to the Oracle server. The shadow services Data Pump API requests.1Upon receipt of a DBMS_DATAPUMP.OPEN request, the shadow creates the job which primarily consists of creating the master table, creating the AQ queues used for communication among the various processes and creating the Master Control Process. Once a job is running, the shadow’s main task usually consists of servicing GET_STATUS requests from the client. If the client detaches, the shadow goes away, too.Master Control Process (MCP) – There is one MCP per job and as the name implies, the MCP controls the execution and sequencing of a Data Pump job. A job is divided into various metadata and data unloading or loading phases, and the MCP hands out work requests to the worker processes appropriate for the current phase. It mainly sits in this work dispatch loop during a job’s execution. It also performs central file management duties, maintaining the active dump file list and handing out file pieces as requested by processes unloading data or metadata. An MCP has a process name of the form: <instance>_DMnn_<pid>. The MCP maintains job state, job description, restart and dumpfile information in the master table.Worker Process – Upon receipt of a START_JOB request, the MCP creates N worker processes where N is the value of the PARALLEL parameter. The workers perform the tasks requested by the MCP that consist primarily of unloading / loading of metadata and data. The workers maintain the object rows in the master table which comprise the bulk of the table: As database objects are unloaded or loaded, these rows are written and updated with the objects’ current status: pending, completed, failed, etc. The workers also maintain what are called “type completion rows” which describe what type of object is currently being worked on: tables, indexes, views, etc. These are used during restart. A worker has a name of the form: <instance>_DWnn_<pid>.Parallel Query (PQ) Process – If External Tables (ET) is chosen as the data access method for loading or unloading a table or partition, N PQ processes are created by the worker given the load or unload assignment, and the worker acts as the query coordinator. These are standard parallel execution slaves exploiting the Oracle server’s parallel execution architecture, thus enabling intra-partition loading and unloading. In a RAC, PQ processes may be created on an instance other than where the Data Pump job was initiated. All other processes described thus far are created on that initial instance.D ATA M OVEMENTTwo access methods are supported: Direct Path (DP) and External Tables (ET). DP is the faster of the two but does not support intra-partition parallelism. ET does and therefore may be chosen to load or unload a very large table or partition. Each also has certain restrictions requiring the use of the other: For example, a table being loaded with active referential constraints or global indexes must be loaded via ET. A table with a column of data type LONG must be unloaded and loaded with DP. Both methods write to the dumpfile set in a compact, binary stream format that is approximately 15% smaller than original export’s data representation.M ETADATA M OVEMENTThe Metadata API (DBMS_METADATA) is used by worker processes for all metadata unloading and loading. Database object definitions are extracted and written to the dumpfile set as XML documents rather than as SQL DDL as was done by original export. This allows great flexibility to apply XSL-T transformations when creating the DDL at import time. For example, an object’s ownership, storage characteristics and tablespace residence can be changed easily during import. Necessarily, XML takes up more dumpfile space than DDL, but the flexibility gained by deferring DDL creation until import is worth the trade-off. Since metadata is typically dwarfed by data in a dumpfile set, the reduction in binary stream size typically produces dumpfile sets the same as or smaller than those produced by 1 The Data Pump’s public API is embodied in the PL/SQL package DBMS_DATAPUMP. It will not be described in detail here.Full documentation may be found in the Oracle Database 10g Utilities Guide and Supplied PL/SQL Packages manuals.original export.One other small point: The XML representing table metadata is stored within the MT rather than being written immediately to the dumpfile set. This is because it is used for several downstream operations, thus avoiding multiple fetches.I NTER-PROCESS C OMMUNICATIONAdvanced Queuing (AQ) is used for communicating among the various Data Pump processes. Each job has two queues:•Command and control queue: All processes (except clients) subscribe to this queue. All API commands, work requests and responses, file requests and log messages are processed on this queue.•Status queue: Only shadow processes subscribe to this queue to receive work in progress and error messages queued by the MCP. The MCP is the only writer to this queue.F ILE M ANAGEMENTThe file manager is a distributed component: As mentioned earlier, the actual creation of new files and allocation of file segments is handled centrally within the MCP. However, each worker and PQ process make local process requests to the file manager to request space, read a file chunk, write a buffer or update progress statistics. The local file manager determines if the request can be handled locally and if not, forwards it via the command and control queue to the MCP. Reading file chunks and updating file statistics in the master table are handled locally. Writing a buffer is typically handled locally, but may result in a request to the MCP for more file space.D IRECTORY M ANAGEMENTBecause all dumpfile set I/O is handled by Oracle background server processes, the operating system persona doing the I/O is “oracle”, not the user running the job. This presents a security dilemma since “oracle” is typically a privileged account. Therefore, all directory specifications are made using Oracle directory objects with read / write grants established by the DBA. For example, the DBA may set up a directory as follows:Create directory dmpdir1 as ‘/private1/data/dumps’;Grant read, write on directory dmpdir1 to scott;Then SCOTT can specify a dumpfile on the expdp command line as:expdp scott/tiger dumpfile=dmpdir1:scott.dmpIf the file size is limited for manageability by the FILESIZE parameter, then potentially many dump files can be created. The file manager automatically maintains dumpfile set coherency via a globally unique identifier and other information written into the file headers. An import or SQL file job cannot start until all members of the job’s dumpfile set are present in DUMPFILE parameter specificationsM AJOR F EATURESThis section will briefly describe some of the major new features in Data Pump.P ERFORMANCEData Pump based export / import operations are typically much faster than their original exp / imp counterparts. A single thread of Data Pump’s direct path data unload is about twice as fast as original exp’s direct path unload. A single thread of Data Pump data load is 15X – 45X faster than original imp. And of course, Data Pump operations can be specified with parallel threads of execution2. Also note that parallel threads can be dynamically added and removed to/from running jobs to tailor the job to the changing execution environment.During export, when there are two or more workers, data and metadata unloading proceed in parallel.I/O BANDWIDTH IS MOST IMPORTANT FACTORIt is important to make sure there is sufficient I/O bandwidth to handle the number of parallel threads specified;2 Only on Oracle Database Enterprise Editionotherwise performance can actually degrade with additional parallel threads. Care should be taken to make sure the dumpfile set is located on spindles other than those holding the instance’s data files. Wildcard file support makes it easy to spread the I/O load over multiple spindles. For example, a specification such as:Dumpfile=dmpdir1:full1%u.dmp,dmpdir2:full2%u.dmpDumpfile=dmpdir3:full3%u.dmp,dmpdir4:full4%u.dmpwill create files named full101.dmp, full201.dmp, full301.dmp, full401.dmp, full102.dmp, full202.dmp, full302.dmp, etc. in a round-robin fashion across the four directories pointed to by the four directory objects.I NITIALIZATION P ARAMETERSThere is very little tuning required to achieve maximum Data Pump performance. Initialization parameters should be sufficient out of the box. Make sure disk_asynch_io remains TRUE and that db_block_checksum remains FALSE. Data Pump’s AQ-based communication and the metadata API both require some amount of SGA… make sure shared_pool_size is sufficient.Both the metadata API during export and the worker process during import may execute some fairly long-running queries that have the potential for exhausting rollback segments. This is mostly an issue in jobs affecting many objects. Make sure these are configured sufficiently large. For example, export / import of a database containing 400,000 objects required two rollback segments, each 750 Mb in size.M ETADATA APIMetadata performance is about the same as the original exp and imp utilitities, but much more flexible and extensible. However, since most operations are dominated by data movement, most see a dramatic overall improvement.N ETWORK M ODEData Pump supports the ability to load one instance directly from another (network import) and unload a remote instance (network export). Rather than using network pipes which are not supported on all platforms, network mode uses DB links.During network import, the Metadata API executes on the remote node, extracting object definitions and sending them to the local instance for creation where the Data Pump job is executing. Data is fetched and loaded using insert as select statements such as:Insert into foo (a,b,c,…) select (a,b,c,…) from foo@remote_service_nameThese statements incorporate hints on both sides to access the direct path engine for maximum performance. Network export enables the ability to export read-only databases. Data Pump export cannot run locally on a read-only instance because maintaining the master table, writing messages to queues and creating external tables all require writes to the instance. Network export creates the dumpfile set on the instance where the Data Pump job is running and extracts the metadata and data from the remote instance, just as network import does. Data movement in network export is done exclusively by External Tables since ‘create as select@service’ style DML statements are required. With either network mode operation, it is expected that network bandwidth will become the bottleneck. Be careful that the parallel setting does not saturate the network. We discovered that many of our customers would implement a sort of ‘network mode’ with original exp and imp by exporting into a network pipe and importing out the other end. This overlapped the export and import operations, thus improving elapsed time. Given the dramatic improvement in the performance of file-based Data Pump operations, it is unclear if network mode can provide a significant reduction in elapsed time for instance initialization as it did with original exp and imp.R ESTARTAll stopped Data Pump jobs can be restarted without loss of data as long as the master table and dumpfile set remain undisturbed while the job is stopped. It doesn’t matter if the job was stopped voluntarily with the clients’ STOP_JOB command or the stoppage was involuntary due to a crash, power outage, etc. Sufficient context is maintained in the master table to know where to pick up. A client can attach to a stopped job with the ATTACH=<job name> parameter, then start it with the interactive START command.During import, sometimes an unforeseen, repeating problem with a particular object occurs that prevents further progress. START=SKIP_CURRENT will skip the current object and continue with the next, thus allowing progressto be made.F INE-GRAINED O BJECT S ELECTIONOne could only choose to include or ignore indexes, triggers, grants and constraints with original exp and imp. With various client parameters, a Data Pump job can include or exclude virtually any type of object and any subset of objects within a type.E XCLUDEThe exclude parameter allows any database object type to be excluded from an export or import operation. The optional name qualifier allows you finer selectivity within each object type specified. For example, the following three lines in a parameter file:Exclude=functionExclude=procedureExclude=package:”like ‘PAYROLL%’ “Would exclude all functions, procedures and packages with names starting with ‘PAYROLL’ from the job.I NCLUDEThe include parameter includes only the specified object types and objects in an operation. For example, if the above three specifications were INCLUDE parameters in a full database export, only functions, procedures and packages with names starting with ‘PAYROLL’ would be written to the dumpfile set..C ONTENTThe content parameter allows one to request for the current operation just metadata, just data or both. Original exp’s ‘ROWS=N’ parameter was equivalent to content=metadata_only, but there is no equivalent forcontent=data_only.Q UERYThe query parameter operates much as it did in original export, but with two significant enhancements:1.It can be qualified with a table name such that it only applies to that table2.It can be used during import as well as export.M ONITORING AND E STIMATESAnother requirement we heard from our customers was to provide better, more detailed monitoring capabilities. In addition to the standard progress and error messages printed by the client and into the log file, the new client interactive command STATUS will show detailed job information including overall percent done, the status of each worker process, the current objects being worked on and the percent done for each one. You can also specify a time interval in seconds for an automatic update of detailed status rather than manually requesting it.The start of every export job now also includes an estimate phase where the approximate amount of all data to be unloaded is determined. The default method for determining this is to estimate the size of a partition by counting the number of blocks currently allocated to it. If tables have been analyzed, statistics can also be used which should provide a more accurate estimate. This serves two purposes: 1) You get an idea of how much dumpfile space will be consumed. 2) All the information needed to start unloading tables is retrieved and ordered by size descending. This allows the MCP to schedule the unloading of metadata and data in parallel. The objects retrieved during this estimate phase are called table data objects with each representing a partition or the entire table if the table is unpartitioned. Since 0-N clients may be attached to a running job, one may start a job at work, detach from it, go home, re-attach and monitor it throughout the evening.N EW C LIENTS: EXPDP AND IMPDPAlthough the new export and import clients retain a similar look and feel to the original exp and imp clients, 100% parameter compatibility was not a goal since there are so many inconsistencies in the original clients’ parameters. Where a concept makes sense for both an export and import operation, we made sure the parameter is the same for both. The new clients also support far greater capabilities:Interactive command mode – Typing control-C (^C) will invoke the interactive command mode and an ‘export>’ or ‘import>’ prompt will appear. From this prompt, you can request help, detailed job status, change monitoring parameters, dynamically add files (including wildcard specifications) to the job’s dumpfile set, stop the job leaving it restartable, kill the job leaving it not restartable, change the degree of parallelism for the job, return to logging mode to continue receiving progress messages or exit the client and leave the job running.All modes of operation are supported: Full, schema, table, tablespace and transportable tablespace. Data Pump and its new expdp and impdp clients are a complete superset of original exp/imp’s functionality3.Flashback is supported for exports and imports as of a certain time.WHERE clause predicates may be applied to individual tables by both expdp and impdp.Privileged users (those with either the EXP_FULL_DATABASE or IMP_FULL_DATABASE roles) may attach to and control jobs initiated by other users even if the job is stopped.O THER U SEFUL F EATURESDDL T RANSFORMATIONS – Because object metadata is stored as XML in the dumpfile set, it is easy to apply transformations when DDL is being formed (via XSL-T) during import. Impdp supports several transformations: REMAP_SCHEMA provides the old ‘FROMUSER / TOUSER’ capability to change object ownership.REMAP_TABLESPACE allows objects to be moved from one tablespace to another. This changes the tablespace definition as well. REMAP_DATAFILE is useful when moving databases across platforms that have different file system semantics. One can also specify via the TRANSFORM parameter that storage clauses should not be generated in the DDL. This is useful if the storage characteristics of the target instance are very different from those of the source.SQL FILE - Impdp can also perform a SQL file operation. Rather than creating database objects, this merely outputs the equivalent DDL to file in a form of a SQL script almost ready for execution. Only the embedded ‘connect’ statements are commented out.TABLE_EXISTS_ACTION– Original imp would allow rows to be appended to pre-existing tables ifIGNORE=Y was specified. Impdp’s TABLE_EXISTS_ACTION parameter provides four options:1.SKIP is the default: A table is skipped if it is found to exist.2.APPEND will append rows if the target table’s geometry is compatible.3.TRUNCATE will truncate the table, then load rows from the source if: 1) The geometries are compatible 2)A truncate is possible; for example, it is not possible if the table is the target of referential constraints.4.REPLACE will drop the existing table then create and load it from the source.CONTENT–This new parameter, applicable to both clients allows the movement of DATA_ONLY, METADATA_ONLY or BOTH (the default).VERSION–expdp supports the VERSION parameter which tells the server-based Data Pump to generate a dumpfile set compatible with the specified version. This will be the means to perform downgrades in the future. There is no need (as there was with original exp) to run older versioned Data Pump clients.E NTERPRISE M ANAGER supports a fully functional interface to Data Pump.D ATA P UMP V IEWS – Data Pump maintains a number of user and DBA accessible views to monitor the progress of jobs:DBA_DATAPUMP_JOBS: This view shows a summary of all active Data Pump jobs on the system.USER_DATAPUMP_JOBS: This view shows a summary of the current user’s active Data Pump jobs.DBA_DATAPUMP_SESSIONS: This shows all sessions currently attached to Data Pump jobs.3 With one exception: In Oracle Database 10g, the Data Pump does not yet support the export and import of XML Schemas. This includes the schemas themselves and tables and views based on XML Schemas.V$SESSION_LONGOPS: A row is maintained in the view showing progress on each active Data Pump job. The OPNAME column displays the Data Pump job name.O RIGINAL EXP AND IMPBoth original export and import will ship with Oracle Database 10g:•Original imp will be supported forever and will provide the means to import dumpfiles from earlier releases: V5 through V9i. Original and Data Pump-based dumpfiles are not compatible: Neither client can read theother’s dump files.•Original exp will ship and be supported in Oracle Database 10g to provide at least 9i functionality, but will eventually be deprecated. Data Pump-based export will be the sole supported means of export movingforward. New features in Oracle Database 10g are not supported in original exp. The Oracle 9i version of exp may be used with version 10g for downgrade purposes. Beyond version 10g, expdp’s VERSION parameter should be used for downgrade.D IFFERENCES B ETWEEN D ATA P UMP AND O RIGINAL EXP/IMPThis section highlights some of the main differences you will notice when first running Data Pump-based export and import:Data Pump is designed for big jobs with lots of data. This has a number of implications:•Startup time is longer. All of the process and communication infrastructure must be initialized before a job can get underway. This could take about 10 seconds. Also, export start time includes retrieval and ordering of all table data objects so the MCP can start immediately scheduling table unloads.•Data Pump export must write the master table to the dumpfile set and the end of a job and import must locate and load the master table at the job start.. This is normally a few seconds, but if the master table is very large, could take longer. Direct path is used to unload and load the MT.•Importing a subset of a dumpfile set deletes non-pertinent rows from the master table: If the subset is very small compared to the export set, this can take a noticeable amount of time to perform the required deletes.•Performance of metadata extraction and creation is about on-par with original exp / imp: It’s very difficult to make DDL go faster. The greatest performance improvement in Data Pump occurs when unloading andloading data.•XML metadata in dumpfiles is about 7X bigger than exp’s DDL and Data Pump’s data stream format is about 13% smaller than exp’s row/column format. Standalone compression tools like gzip work quite nicely on dumpfiles dominated by metadata.•Data Pump is as resource-intense as you wish: Reducing elapsed time per-job is first and foremost in the design. Data Pump will consume as much CPU, memory, I/O bandwidth and network bandwidth (innetwork mode) as your setting of PARALLEL will allow.The user running Data Pump must have sufficient tablespace quota to create the master table.Be cognizant of rollback configuration in jobs containing many objects.The progress messages displayed by the clients are different than those displayed by the original clients, but still reflect what the object type currently being worked on is. Also note that ‘Already exists’ errors are flagged as such and included in the total errors count issued at the end of the job.A log file is generated by default with a name ‘export.log’ or ‘import.log’.C ONCLUSIONData Pump is a new, callable facility in the Oracle 10g database that provides very high speed loading and unloading of data and metadata. New export and import clients, expdp and impdp that fully exploit Data Pump’s infrastructure arealso provided in this release. They are implemented as complete supersets of original exp / imp functionality and will eventually replace them.。