16统计量计算
统计学课后答案

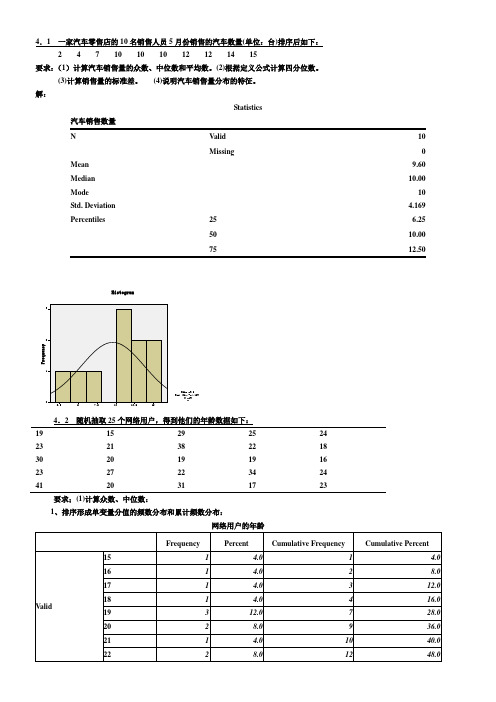
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid10Missing0 MeanMedianMode10 Std. DeviationPercentiles2550754.2 随机抽取25个网络用户,得到他们的年龄数据如下:19152925242321382218302019191623272234244120311723要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=,因此Q1=19,Q3位置=3×25/4=,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+×2=。
(3)计算平均数和标准差; Mean=;Std. Deviation= (4)计算偏态系数和峰态系数: Skewness=;Kurtosis=(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K=+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=,取53、分组频数表网络用户的年龄 (Binned)分组后的均值与方差:分组后的直方图:要求:(1)计算120家企业利润额的平均数和标准差。
统计学第6章统计量及其抽样分布

整理ppt
16
2. T统计量
设X1,X2,…,Xn是来自正态总体N~ (μ,σ2 )
n
的一个样本,
X
1 n
n i 1
Xi
(Xi X )2 s 2 i1
n 1
则 T(X) ~t(n1)
S/ n
称为T统计量,它服从自由度为(n-1)的t分布。
整理ppt
17
F分布
定义:设随机变量Y与Z相互独立,且Y和Z分别服 从自由度为m和n的c2分布,随机变量X有如下表达式:
整理ppt
8
中心极限定理
设从均值为,方差为2的一个任意总 体中抽取容量为n的样本,当n充分大时, 样本均值的抽样分布近似服从均值为μ、 方差为σ2/n的正态分布。
当样本容量足够大时
(n≥30),样本均值的抽样
分布逐渐趋于正态分布
整理ppt
9
标准误差
标准误差:样本统计量与总体参数之间的平均差异
1. 所有可能的样本均值的标准差,测度所有样本 均值的离散程度
因此,估计这100名患者治愈成功的比 例在85%至95%的概率为90.5%
整理ppt
22
6.5 两个样本平均值之差的分布
设
X
1
是独立地抽自总体
X1 ~N(1,12)
的一个容量
为n1的样本的均值。 X 2 是独立地抽自总体
X2 ~N(2,22)的一个容量为n2的样本的均值,则有
E (X 1X 2)E (X 1) E (X 2)12
2. 样本均值的标准误差小于总体标准差
3. 计算公式为
x
n
整理ppt
10
【例】设从一个均值μ=8、标准差σ=0.7的总 体中随机抽取容量为n=49的样本。要求:
统计学(第五版)课后答案
7.02377
Variance
49.333
Skewness
1.163
Kurtosis
1.302
分组后的直方图:
4.6在某地区抽取120家企业,按利润额进行分组,结果如下:
按利润额分组(万元)
企业数(个)
200~300
300~400
400~500
500~600
600以上
19
解:已知μ0=250,σ= 30,N=25, =270这里是小样本分布,σ已知,用Z统计量。右侧检验,α=0.05,则Zα=1.645
提出假设:假定这种化肥没使小麦明显增产。即H0:μ≤250H1:μ>250
计算统计量:Z =( -μ0)/(σ/√N)=(270-250)/(30/√25)= 3.33
(1) =25,σ=3.5,n=60,置信水平为95%(2) =119.6,s=23.89,n=75,置信水平为95%
(3) =3.419,s=0.974,n=32,置信水平为90%
解:∵
∴1)1-=95%, 其置信区间为:25±1.96×3.5÷√60= 25±0.885
2)1-=98%,则=0.02,/2=0.01, 1-/2=0.99,查标准正态分布表,可知: 2.33
解:已知μ0=4.55,σ²=0.108²,N=9, =4.484,
这里采用双侧检验,小样本,σ已知,使用Z统计。假定现在生产的铁水平均含碳量与以前无显著差异。则,
H0:μ=4.55;H1:μ≠4.55α=0.05,α/2 =0.025,查表得临界值为 1.96
计算检验统计量: = (4.484-4.55)/(0.108/√9)= -1.833
解:H0:μ≥700;H1:μ<700已知: =680 =60
第6章-统计量及其抽样分布

对应于每个数值的相对出现频数排成另一列, 由此,全部可能的样本统计量值形成了一个概 率分布,这个分布就是我们想要得到的抽样分 布。
样本均值的抽样分布 与中心极限定理
当总体服从正态分布N(μ,σ2)时,来自该总体的所有 容量为n的样本的均值x也服从正态分布,x 的数
1.0 1.5 2.0 2.5 3.0 3.5 4.0 x
样本均值的抽样分布
所有样本均值的均值和1.0 1.5 4.0 16
2.5 m
n
(xi mx )2
s
2 x
i 1
M
M为样本数目
(1.0 2.5)2
(4.0 2.5)2
s2
0.625
16
n
1. 样本均值的均值(数学期望)等于总体均值 2. 样本均值的方差等于总体方差的1/n
从检查一部分得知全体。
复习 抽样方法
抽样方式
概率抽样
非概率抽样
简单随机抽样 整群抽样
多阶段抽样
分层抽样 系统抽样
方便抽样 自愿样本 配额抽样
判断抽样 滚雪球抽样
6.2.1 抽样分布 (sampling distribution)
1. 样本统计量的概率分布,是一种理论分布
在重复选取容量为n的样本时,由该统计量的所有可 能取值形成的相对频数分布
2. 随机变量是 样本统计量
样本均值, 样本比例,样本方差等
3. 结果来自容量相同的所有可能样本
4. 提供了样本统计量长远而稳定的信息,是进行推 断的理论基础,也是抽样推断科学性的重要依据
抽样分布的形成过程 (sampling
distribution)
第六章 统计量及其抽样分布

样本均值的抽样分布
样本均值的抽样分布
1. 容量相同的所有可能样本的样本均值的概率分 布
2. 一种理论概率分布 3. 进行推断总体总体均值的理论基础
样本均值的抽样分布
(例题分析)
【例】设一个总体,含有4个元素(个体) ,即总体单位 数N=4。4 个个体分别为x1=1、x2=2、x3=3 、x4=4 。 总体的均值、方差及分布如下
第 一
16个样本的均值(x)
个
第二个观察值
观 察值1 2
3
4
11
1.
20.
52. 0.
5
21
2.
25.
03. 5.
0
23
2.
30.
53. 0.
5
24
3.
35.
04. 5.
0
.3 P (X ) .2 .1 0
1.0 1.5 2.0 2.5 3.0 3.5 4.0 X
第六章 统计量及其抽样分布
抽样理论依据: 1、大数定律 (1)独立同分布大数定律:证明当N足够大时,平均数据有稳定性,为用样本平 均数估计总体平均数提供了理论依据。 (2)贝努力大数定律:证明当n足够大时,频率具有稳定性,为用频率代替概率 提供了理论依据 2、中心极限定律 (1)独立同分布中心极限定律:设从均值为u、方差为s2(有限)的任意一个总体 中抽取样本量为n的样本,但n充分大时,样本均值X的抽样分布近似服从均值为u, 方差为s2/n的正态分布。 (2)德莫佛-拉普拉斯中心极限定律:证明属性总体的样本数和样本方差,在n足 够大时,同样趋于正态分布。
(central limit theorem)
常用统计量与计算方法

代入公式(3—5)得:
Md
L
i
n
15 68
( c) 57 ( 16) 70.5
(天)
f2
20 2
即间隔时间的中位数为70.5天。
L — 频数最多所在组的下限
i — 组距 (即全距/组数)
f — 频数最多所在组的频数
n — 总频数(即总次数)
c — 小于频数最多所在组的累加频数
19
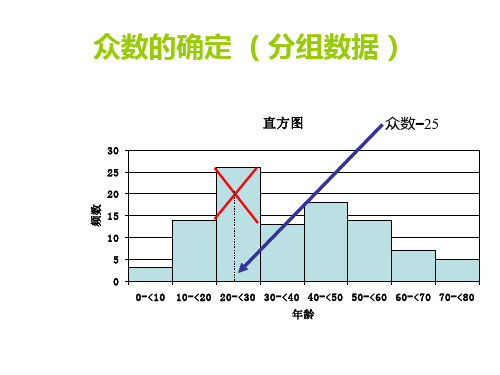
(三)众数 (mode) M0 (书 P17)
26
为 了 准 确 地 表示样本内各个观测值的变异 程度 ,人们 首 先会考虑到以平均数为标准,求 出各个观测值与平均数的离差,(x x) ,称为 离均差。
虽然离均差能表示一个观测值偏离平均数的 性质和程度,但因为离均差有正、有负 ,离均 差之和 为零,即Σx( x ) = 0 ,因 而 不 能 用离均差之和Σ(x x )来 表 示 资料中所有观 测值的总偏离程度。
注: 小样本的自由度为n-1
x x 2
n 1
n 30
35
标准差的计算方法
上述计算方法需先求出平均数(一般为约数),容易 引起计算误差,因此采用原始数据进行计算 (书P20)
大样本: S x 2 x 2 / n
n
小样本: S x 2 x 2 / n
n -1
为简化计算过程,若试验观测数值较大(小)时,可将各观测值
乙组的变异明显低于甲组, R 不能反映 组内其它数据的 变异度 25
二、变异数
缺点
c. 样本较大时, 抽到较大值与较小值的可能性也较大, 因而样本极差也较大,故样本含量相差较大时,不宜用 极差来比较分布的离散度。
当资料很多,而又要迅速对资料的变异程度作出判断 用途 时,有时可先利用极差判断。
统计学计算题复习
市场个数(fi)
4 9 16 27 20 17 10 8 4 5
∑fi= 120
Mi fi
580 1395 2640 4725 3700 3315 2050 1720
900 1175
∑Mi fi =22200
k
X
Mi fi
i 1
22 200 185(台)
n
120
样本方差和标准差
(Sample Variance and Standard Deviation)
适用于总体资料经过分组整理形成变量数列的情况
• 总体均值
• 样本均值 (未分组)
K
x1 f1 x2 f2 xK f1 f2 fK
fK
xi fi
i1 K
fi
k i1
x
x1 f1 x2 f2 xk fk f1 f2 fk
xi fi
i1 n
fi
i 1
• 公X式中: 为均值; f为相应频数;Xi为第i个单位的变量值。
解 : 已 知 X ~N( , 102) , n=25, 1- = 95% ,
z/2=1.96。根据样本数据计算得:x 105.36。由
于是正态总体,且方差已知。总体均值在1-置
信水平下的置信区间为
10
x z 2
105.36 1.96 n
25
105.36 3.92
101.44,109.28
频数 5 7 12 18 22 16 10 8
Frequency
Koala Sightings 25
Line 1
20
Line 2
15
10
5
0 10 – 14 15 – 19 20 – 24 25 – 29 30 – 34 35 – 39 40 – 44 45 – 49 Number of koalas se2 fi
数理统计课后题答案完整版(汪荣鑫)

数理统计习题答案第一章1.解:()()()()()()()12252112222219294103105106100511100519210094100103100105100106100534n i i n i i i i X x n S x x x n ===++++====-=-⎡⎤=-+-+-+-+-⎣⎦=∑∑∑ 2. 解:子样平均数 *11li i i X m x n ==∑()118340610262604=⨯+⨯+⨯+⨯=子样方差 ()22*11l i i i S m x x n ==-∑()()()()222218144034106422646018.67⎡⎤=⨯-+⨯-+⨯-+⨯-⎣⎦= 子样标准差4.32S == 3. 解:因为i i x ay c-=因此 i i x a cy =+11ni i x x n ==∑()1111ni i ni i a cy n na cy n ===+⎛⎫=+ ⎪⎝⎭∑∑1nii c a y n a cy==+=+∑ 因此 x a cy =+ 成立()2211n x i i s x x n ==-∑()()()22122111ni i ini i nii a cy a c y n cy c yn c y y n====+--=-=-∑∑∑因为 ()2211nyi i s y y n ==-∑ 因此222x ys c s = 成立 ()()()()()172181203.2147.211.2e n n e nM X X R X X M X X +⎛⎫ ⎪⎝⎭⎛⎫+ ⎪⎝⎭====-=--====4. 解:变换 2000i i y x =-11n i i y y n ==∑()61303103042420909185203109240.444=--++++-++=()2211n y i i s y y n ==-∑()()()()()()()()()222222222161240.444303240.4441030240.4449424240.44420240.444909240.444185240.44420240.444310240.444197032.247=--+--+-+⎡⎣-+-+-+⎤--+-+-⎦=利用3题的结果可知2220002240.444197032.247xyx y s s =+===5. 解:变换 ()10080i i y x =-13111113n i i i i y y y n ====∑∑[]12424334353202132.00=-++++++-+++++=()2211nyi i s y y n ==-∑()()()()()()22222212 2.0032 2.005 2.0034 2.001333 2.003 2.005.3077=--+⨯-+-+⨯-⎡⎣⎤+⨯-+--⎦= 利用3题的结果可知2248080.021005.30771010000yx yx s s -=+===⨯6. 解:变换()1027i i y x =-11li i i y m y n ==∑()13529312434101.5=-⨯-⨯+⨯+=-2710yx =+= ()2211lyi i i s m y y n ==-∑()()()()22221235 1.539 1.5412 1.534 1.510440.25⎤=⨯-++⨯-++⨯+++⎡⎣⎦= 221 4.4025100x y s s ==7解: 154158162178*11li i i x m x n ==∑ ()1156101601416426172121682817681802100166=⨯+⨯+⨯+⨯+⨯+⨯+⨯=()22*11l i i i s m x x n ==-∑()()()()()()()2222222110156166141601662616416628168166100121721668176166218016633.44=⨯-+⨯-+⨯-+⨯-⎡⎣⎤+⨯-+⨯-+⨯-⎦= 8解:将子样值从头排列(由小到大)-4,,,,,0,0,,,,,,()()()()()172181203.2147.211.2e n n e nM X X R X X M X X +⎛⎫ ⎪⎝⎭⎛⎫+ ⎪⎝⎭====-=--====9解: 121211121211n n i ji j n x n x n n x n n ==+=+∑∑112212n x n xn n +=+()12221121n n ii s x x n n +==-+∑()()()1212221122111122121222222111222112212122222211221122112212121222211211122121n n i i n n iji j x xn n x xn x n x n n n n n s x n sx n x n xn n n n n s n s n x n x n x n x n n n n n n n n n x n n s n sn n +====-++⎛⎫+=- ⎪++⎝⎭+++⎛⎫+=-⎪++⎝⎭⎛⎫+++=+- ⎪+++⎝⎭+++=++∑∑∑()()()()()()22212211222122222112212112212122121222212121122212122n n x n x n x n n n s n s n n x n n x n n x x n n n n n n x x n s n s n n n n +-++++-=+++-+=+++10.某射手进行20次独立、重复的射手,击中靶子的环数如下表所示:试写出子样的频数散布,再写出体会散布函数并作出其图形。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
频数过程
频数过程(FREQ)用于计算各种形式的频数及 一些检验统计量。
频数过程句法
PROC FREQ options; OUTPUT <OUT= SAS-data-set><output-statistic-list>; TABLES requests / options; WEIGHT variable; EXACT statistic-keywords; BY variable-list;
例16.13 创建包含卡方统计量的数据集。
options nodate pageno=1 pagesize=60; proc freq data=ResDat.color order=data; weight count; tables eyes*hair /chisq expected cellchi2 norow nocol; output out=chisqdat pchi lrchi n nmiss; title 'Chi-Square Tests for 3 by 5 Table of Eye and Hair Color'; run;
表格没有轮廓线和分隔线的FORMCHAR=选项: FORMCHAR(1,2,7)= ' ' ; /* 三个空格 */
例16.6 按格式化值的顺序排列。 proc format; value $sfmt 'M' = 'male ' 'F ' ='female'; proc freq data=ResDat.class order=formatted; table sex; format sex $sfmt.; run;
语句说明:
BY EXACT OUTPUT TABLES TEST WEIGHT 对BY变量定义的观测组分别计算其相应的频数或相等交叉制表 对特定统计量作精确检验 产生包含特定统计量的数据集 产生多变量交叉表并对关联度进行度量和检验 要求对关联度和一致性度量进行近似检验 规定一个变量,其值为每一观测的权数
PROC CORR <option(s)>; BY <DESCENDING> variable-1<...<DESCENDING> variable-n> <NOTSORTED>; FREQ frequency-variable; PARTIAL variable(s); VAR variable(s); WEIGHT weight-variable; WITH variable(s);
其它语句
VAR语句 VAR variable-list; 列出要计算相关系数的变量。 WITH语句 WITH variable-list; 该语句和VAR语句联合使用计算变量间特殊组合的相关系数。用 VAR语句列出的变量放在相关阵的上方,而用WITH语句列出的 变量放在相关阵左边。 PARTIAL语句 PARTIAL variable-list; 计算Pearson偏相关,Spearman偏秩序相关,或Kendall偏tau-b。该 语句给出偏相关变量的名子。
例中,产生区间[0, 1]上均匀分 布的随机数1000个,分别将区间 [0, 1]均分成3和4个小区间,并把 产生的随机数按所属区间转换为整 数。然后对这些整数作频数分析。
例16.10 对One-Way频率表作卡方检验。
proc sort data=ResDat.color; by region; run; proc freq data=ResDat.color order=data; weight count; tables hair/nocum testp=(30 12 30 25 3); by region; title 'Hair Color of European Children'; run;
PROC FREQ语句
PROC FREQ options;
选项说明:
Data= Compress Formchar= Noprint Order= Page 规定输入数据集 在下一个单向频数表不适合页面的空间时强迫在当前页输出 规定用来构造列联表单元的轮廓线和分隔线的字符 规定不输出任何描述统计量 规定输出频数表时分类变量的排序方式 规定每页只输出一张表,否则按每页行数允许的空间输出多张表
proc print data=chisqdat noobs; title 'Chi-Square Statistics for Eye and Hair Color'; title2 'Output Data Set from the FREQ Procedure'; run;
第16章 统计量计算
清华大学经管学院 朱世武 Zhushw@ Resdat样本数据: SAS论坛:
本章将介绍的统计量计算过程包括:
相关过程; 频数过程; 均值过程; 单变量过程。
相关过程
相关过程(CORR)用于计算变量间的相关系数。 相关过程句法
BY语句 BY variable-list; 对BY变量定义的观测组分别计算其相应的简单统计量。当使用BY 语句时,要求输入数据集已按BY变量排序的次序排列,除非指定 NOTSORTED。
应用举例
例16.1 计算Pearson相关系数及其它关联测度。 proc corr data=ResDat.fitness pearson spearman hoeffding; var weight oxygen runtime; title 'Measures of Association for'; title2 'a Physical Fitness Study'; run;
例中,计算数据集ResDat.CLASS中变量SEX的分布,并以格 式化值的顺序排列。
FREQ 过程 累积 累积 Sex 频数 百分比 频数 百分比 --------------------------------------------------female 9 47.37 9 47.37 male 10 63 19 100.00
例16.3 计算两个数据集中相同变量之间的相关系数。 data a; /*数据集准备 */ merge ResDat.Idx000001(keep=date oppr clpr) ResDat.szcz(keep=date oppr clpr rename=(oppr=oppr_sz clpr=clpr_sz) ); by date; run; proc corr data=a nomiss cov; var oppr_sz clpr_sz; with oppr clpr; title2 '长方形的COV和CORR阵'; run; proc corr data=a cov csscp outp=oup; title2 '从含有缺失值的数据集中计算CSSCP和COV'; run; 例中,对上证指数ResDat.Idx000001和深证成指ResDat.SZCZ中的变 量开盘价和收盘价作相应的计算。
WEIGHT语句
WEIGHT variable; 该语句规定一个WEIGHT变量,它的值表示相应 观测的权数。该变量的值应大于零。若这个值<0 或缺失,假定该值为0。
BY语句
BY variable-list; 对BY变量定义的观测组分别计算其相应的简单统计 量。当使用BY语句时,要求输入数据集已按BY变 量排序的次序排列,除非指定NOTSORTED。
应用举例
例16.8 随机数频数分析。 data a; do I=1 to 1000; X=int(uniform(8888)*3)+1; Y=int(uniform(8888)*4)+1; output; end; proc freq data=a(drop=i); title '没有TABLES语句'; run; title; proc freq; tables x x*y/chisq; run; proc freq; tables x*y/list; run;
语句说明:
BY FREQ PARTIAL VAR WEIGHT WITH 分别对每一BY组计算相关系数 规定一个数值变量, 其值为每一观测值出现的频数 给出Pearson, Spearman或Kendall偏相关系数的变量名 给出要计算相关系数矩阵的变量和顺序 计算加权的乘积矩相关系数时给出权数变量名字 计算变量组合之间的相关系数
OUTPUT语句
OUTPUT <OUT= SAS-data-set><output-statistic-list>; 该语句创建一个由PROC FREQ过程输出统计量的SAS数据 集。OUTPUT创建的数集可以包括由TABLES语句规定的任 意统计量。 PROC FREQ过程每一次只允许使用一个OUTPUT语句。当 规定多个TABLES语句时,OUTPUT语句创建的数据集内容 对应于最后那个TABLES语句,当一个TABLES语句中规定多 个表时,OUTPUT创建的数据集内容对应于最后那个表。 选项说明: OUT=规定输出数据集; output-statistic-list规定输出数据集中所包含的统计量。
PROC CORR语句
PROC CORR <option(s)>; PROC CORR语句选项<option(s)>说明由下页表给出。
选项说明:
ALPHA COV DATA= NOPRINT OUTP= OUTS= PEARSON 输出Cronbach系数 输出协方差 输入数据集名 禁止打印输出 规定创建存放Pearson相关系数的数据集 规定创建存放Spearman相关系数的数据集 输出Pearson相关系数
ORDER=选项及说明: