调查数据分析二元Logistic回归
二元logistic回归结果表达

二元logistic回归结果表达通常会包括以下关键部分:1.模型系数: 这是模型中每个自变量的估计系数。
对于二元Logistic回归,系数通常不会像线性回归那样直接解释为每单位自变量增加导致的因变量变化。
相反,它们是用来计算因变量的预测概率的。
2.Odds Ratio: Odds Ratio是模型系数的解释性描述。
它是预测概率变化与基线概率变化的比率,当一个自变量增加一个单位时(其他自变量保持不变)。
例如,如果一个自变量的系数是0.5,那么它的Odds Ratio是exp(0.5) = 1.65,意味着这个自变量每增加一个单位,事件发生的相对风险是1.65倍。
3.显著性: 这表示该自变量是否对模型的预测有统计显著影响。
通常使用p值来表示,如果p值小于预定的显著性水平(如0.05或0.01),则认为该变量对模型的贡献是显著的。
4.置信区间: 这表示预测的Odds Ratio的上下限。
它提供了关于估计的精确性的信息。
5.接受域概率: 这是模型预测为阳性的概率阈值。
例如,如果接受域概率设置为0.5,那么所有预测概率大于0.5的观察值将被归类为阳性。
6.似然比检验: 这是一种比较模型拟合优度的统计检验,通过比较模型中的参数数量和自由度数量来评估模型质量。
7.混淆矩阵: 这是一个表格,显示模型预测和实际观察结果之间的比较。
它提供了真正例(True Positives)、假正例(FalsePositives)、真反例(True Negatives)和假反例(False Negatives)的数量。
8.AUC (Area Under the Curve): 对于二元分类问题,AUC是ROC曲线下的面积,用于评估模型的性能。
AUC值越接近1,表示模型性能越好;AUC值越接近0.5,表示模型性能越差。
9.Akaike's Information Criterion (AIC)和Bayesian InformationCriterion (BIC): 这些准则用于比较不同模型之间的拟合优度,考虑到模型的复杂性和拟合数据的程度。
二元logistics回归霍斯曼检验拟合度差原因

二元logistics回归霍斯曼检验拟合度差原因二元logistics回归是一种常用的分类分析方法,通过建立逻辑回归模型,对二分类问题进行预测和判断。
在进行二元logistics回归时,我们经常会使用霍斯曼检验(Hosmer-Lemeshow test)来评估模型的拟合程度。
然而,当发现模型的拟合度差时,我们需要深入分析,找出造成拟合度差的原因。
本文将围绕这一问题展开讨论。
一、二元logistics回归模型回顾在开始讨论拟合度差的原因之前,我们先回顾一下二元logistics回归模型的基本原理。
二元logistics回归模型是一种广义线性回归模型。
它基于Logistic 函数,将自变量与因变量之间的关系映射为一个概率值。
该模型的数学表达式如下:P(Y=1|X) = 1 / (1 + e^-(β0 + β1X1 + β2X2 + ... + βnXn))其中,Y为因变量的取值,X为自变量的取值,β为模型的回归系数。
通过最大似然估计等方法,我们可以得到回归系数的估计值,从而建立模型。
二、霍斯曼检验的原理霍斯曼检验是一种用于评估二元logistics回归模型拟合度的统计检验方法。
该检验通过将样本按照预测概率值进行分组,然后计算预测值与实际值之间的残差来衡量模型的拟合程度。
具体而言,霍斯曼检验的步骤如下:1. 将样本按照预测概率值进行分组,通常将预测概率分为10个组。
2. 对每个组内的样本,计算实际值与预测值之间的残差,可以使用对数似然残差(log-likelihood residual)或分位数残差(quantile residual)。
3. 计算每个组内的残差平均值,得到每个组的平均残差。
4. 使用卡方检验或其它拟合优度检验方法,比较实际值与预测值之间的残差平均值是否存在显著差异。
如果在拟合度检验中发现存在显著差异,即拒绝原假设,说明模型的拟合不理想。
三、拟合度差的可能原因在进行霍斯曼检验时,如果发现模型的拟合度较差,我们需要深入分析,找出可能的原因。
SPSS—二元Logistic回归结果分析报告
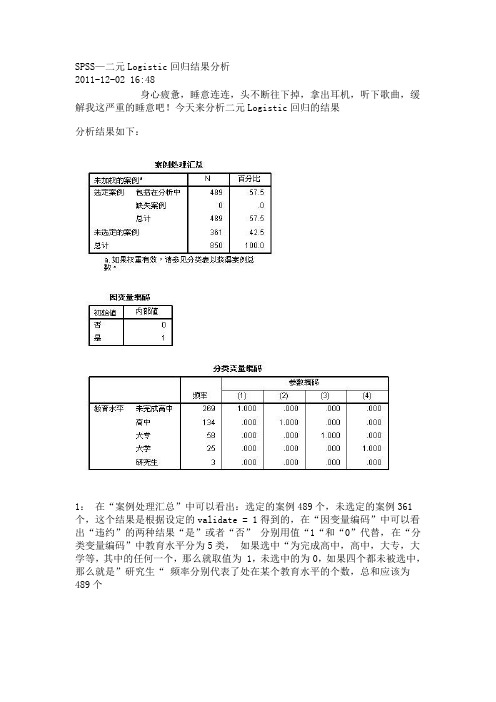
SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.16x¯ = 16951 / 489 = 34.2所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.16 *(1-0.16 )=0.216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.216 * 30074.9979 = 5 840.9044060372 则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.76 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
stata二元logistic回归结果解读

stata二元logistic回归结果解读在Stata中进行二元Logistic回归分析后,你将得到一系列的输出结果。
以下是如何解读这些结果的简要指南:1.模型拟合信息:●Pseudo R-squared :伪R方值,表示模型对数据的拟台程度。
其值介于0和1之间,越接近1表示模型拟合越好。
●Lkliloo ratio test :似然比检验,用于检验模型的整体拟台优度。
2.系数估计值:●B:回归系数,表示自变显每变化-一个单位时,因变显的预测值的变化。
●odds Ratio :优势比。
表示自变量变化-个单位时。
事件发生与不发生的比率的倍数。
计算公式为exp(B) 。
3.显菩性检验:●Pr(>2D:P值,用于检验回归系数的显著性。
通常,如果P值小于预设的显著性水平(如0.05) ,则认为该变量在统计上是显著的。
4. 95%置信区间:●Lower 和Upper:分别为回归系数的95%置信区间的下限和上限。
如果这个区间不包含0,那么我们可以认为该变量对事件的发生有影响。
5.变量信息:●x:自变量名称。
●e(b): Stata自动计算并给出的回归系数估计值。
●(exp(b) :优势比的计算值。
● 伊用:参考类别。
对于分类变量,Stata默认使用第一个类别作为参考类别。
6.模型假设检验:●Heteroskedasticiy:异方差性检验,用于检验误差项的方差是否恒定。
如果存在异方差性,可能需要考虑其他的回归模型或者对模型进行修正。
●Linearity:线性关系检验,用于检验自变量和因变量之间是否为线性关系。
如果不是线性关系,可能需要考虑其他形式的模型或者使用其他转换方法。
7.模型诊断信息:● AlIC, BIC:用于评估模型复杂度和拟合优度的统计星。
较低的值表示更好的拟合。
●Hosmer-Lemeshow test: 霍斯默勒梅肖检验,用于检验模型是否符合Logistic回归的前提假设(比如比例优势假设)。
二元logistics回归分析操作详解

5、准备进行概率计算
6、进行自变量筛选,一般使用向后LR方法。
7、进行精确判别。当Sig of the Change:大于0.1,该自变量可以去除;小于0.1,该自变量应该保留。
8、二元回归方程p=1.811+0.985Xlwt+1.896Xsmoke+6.332Xht+2.214Xui
一般认为:大于2是明显因数,0.5-2是保护因数。
9、
二元logistics回归分析1交叉表大概分析自变量是否对模型有影响2行是因变量列是自变量进行卡方分析3根据pearsonchisquare进行检验
二元logistics回归分析
1、交叉表大概分析自变量是否对模型有影响
2、行是因变量,列是自变量进行卡方分析
3、根据Pearson Chi-Square进行检验。当值小于得到大概的情况。
SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS—二元Logistic回归结果分析.docx
SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
二元logistic回归分类变量结果解读 -回复
二元logistic回归分类变量结果解读-回复二元logistic回归是一种常用的分类算法,适用于解决二分类问题。
在进行二元logistic回归建模后,我们可以得到许多变量的系数和p值等结果,用于解读和分析模型的效果和变量的影响。
在本文中,我们将以二元logistic回归分类变量结果解读为主题,详细讨论如何解读和理解这些结果,并分析变量的影响。
第一步:理解二元logistic回归首先,我们需要了解二元logistic回归的基本原理。
二元logistic回归是一种广义线性模型,主要用于预测二分类变量。
在建模过程中,我们将自变量(预测变量)与因变量(目标变量)之间的关系通过一个logistic函数进行建模。
通过最大似然估计法,我们可以得到各个自变量的系数(coefficient),这些系数表示了每个自变量对于预测变量的影响程度。
此外,我们还可以得到每个系数的标准误差和p值等统计信息。
第二步:解读系数的符号在进行二元logistic回归之后,我们首先需要看一下各个自变量的系数的符号。
系数的符号可以告诉我们自变量与因变量之间的关系是正相关还是负相关。
如果系数为正,意味着自变量的增加将增加目标变量的概率。
相反,如果系数为负,意味着自变量的增加将减少目标变量的概率。
例如,如果我们的自变量是年龄,系数为正,那么意味着年龄的增加将增加目标变量发生的概率。
这个解读过程可以帮助我们理解模型中各个变量的作用。
第三步:解读系数的大小在解读系数之后,我们还需要考虑系数的大小。
系数的大小反映了自变量对目标变量的影响程度。
通常情况下,我们关注的更多是系数的绝对值,而不是具体数值。
系数的绝对值越大,说明该自变量对目标变量的影响越大。
当我们比较两个自变量时,可以通过系数的绝对值来判断它们对目标变量的相对影响大小。
第四步:解读系数的显著性在进行二元logistic回归之后,我们还需要查看每个系数的p值来判断其显著性。
通常情况下,我们将p值小于0.05的系数视为显著。
二元logistic回归 量表
二元Logistic回归是一种用于处理因变量为二分类的回归分析方法。
在量表分析中,可以应用二元Logistic回归来分析自变量与因变量之间的关系,并预测因变量的概率。
以下是二元Logistic回归的步骤:
1. 确定因变量和自变量:在量表分析中,因变量通常是二分类的,如满意或不满意、有用或无用等。
自变量可以是连续变量或分类变量,如年龄、性别、教育程度等。
2. 数据准备:将量表中的数据整理成适合进行Logistic回归的数据格式。
通常需要将分类变量转换为虚拟变量或哑变量,同时处理缺失值和异常值。
3. 模型拟合:使用二元Logistic回归模型拟合数据,选择适当的自变量进入模型,并使用似然比检验、伪R方值等指标评估模型的拟合优度。
4. 结果解释:根据模型结果解释自变量对因变量的影响程度和方向,以及各自变量的显著性水平。
可以使用图形化工具,如ROC曲线和决策曲线等,来评估模型的预测性能和实际应用价值。
需要注意的是,在应用二元Logistic回归时,需要注意自变量的选择和多重共线性问题。
同时,对于连续型自变量,需要进行适当的变换和处理,以适应Logistic回归的分析需求。
此外,还需要注意模型的假设条件,如比例优势假设和独立性假设等,以确保模型的有效性和可靠性。
spss二元logistic回归分析结果解读
spss的二元logistic回归
SPSS(Statistical Product and Service Solutions)是一款数据统计与分析软件。
SPSS软件可以提供全面高级的统计分析,方便易用可快速操作,可缩小数据科学与数据理解之间的差距;在具体的应用方向方面,SPSS提供了高级统计分析、大量机器学习算法、文本分析等功能,具备开源可扩展性,可与大数据的集成,并能够无缝部署到应用程序中。
Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
OR(OddsRatio):比值比,优势比。
二元logistic回归是研究二分类反应变量和多个解释变量间回归关系的统计学分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
9
线性回归模型的基本假定: (1)随机误差项具有0均值: (2)随机误差项具有同方差: (3)随机误差项在不同样本点之间是独立的,不存
在序列相关: (4)随机误差项与解释变量(自变量)之间不相关
: (5)随机误差项服从0均值、同方差的正态分布
回归建模——二元Logistic回归模型
37
ln1pp2.6292.224性别0.102年龄
exp2.6292.224性别0.102年龄 pˆi 1exp2.6292.224性别0.102年龄
回归建模——二元Logistic回归模型
Logistic回归可直接预测事件发生的概率, 若预测概率大于0.5,则预测发生(Y=1); 若预测概率小于0.5,则不发生(Y=0)。
ln L() n
e β0β1xi
β1 i1 yi1eβ0β1xi xi0
求得 0,的1估计值
, 从0 ,而1 得到
(pi的pˆ极i
大似然估计),这个值是在给定xi的条件下yi=1的条 件概率的估计,它代表了Logistic回归模型的拟合
值。
21
Logistic 回归系数的解释
ln1 piPi 0km 1kxki
Logistic回归系数的显著性检验
为了确定哪些自变量能进入方程,还 需要对每个自变量的回归系数进行假 设检验,判断其对模型是否有贡献。
检验方法常用Wald X2检验。
Logistic回归系数的显著性检验
Wald检验
该检验是基于在大样本情况下β值服从正态
分布的性质。
ZK SEK
WKSEK2~2(1)
因此每个
代表当保持其他变量不变时,每
k
单位量的增加对对数发生比的影响
发生比率 ORodds1ek
odds2
若发生比率>1,则说明该变量增大时,
则Y=1事件发生的比例也就越高。
22
Logistic回归模型估计:极大似然估计
Logistic回归模型的评价
1 拟合优度检验(Goodness of fit) 1.1 皮尔逊检验 1.2 Hosmer-Lemeshow检验
其 中 yi取 值 为 0或 者 1
由于各项观测相互独立,其联合分布为:
n
L
pyi i
1pi 1yi
i1
19
Logistic回归模型估计:极大似然估计
求似然函数的极大值
ln L(θ ) ln
n
p
y i
i
(
1
pi
)1 yi
i1
ln
n
p
yi i
(
1
pi
) yi(1
pi
)
i1
ln1ppβ0 β1x
模型的拟合优度检验方法有偏差检验(Deviance)、皮 尔逊(pearson)检验、统计量(Homser-Lemeshow),分 别计算统计量X2D、X2 P、X2HL值。统计量值越小,对应 的概率越大。原假设H0:模型的拟合效果好。
模型拟合优度信息指标有:-2lnL、AIC、SC。这3个指 标越小表示模型拟合的越好。
许多社会科学的观察都只分类而不是连续 的.比如,政治学中经常研究的是否选举某 候选人;经济学研究中所涉及的是否销售或 购买某种商品、是否签订一个合同等等.这 种选择量度通常分为两类,即“是’与 “否”. 在社会学和人口研究中,人们的社 会行为与事件的发生如犯罪、逃学、迁移、 结婚、离婚、患病等等都可以按照二分类变 量来测量。
研究目的:X1,X2,X3等因素对因变量 (使用什么交通方式)有无影响?
建立Y与X的多元线性回归模型?
Y ˆ01 X 12 X 23 X 3
(取值0和1)
8
回归建模——二元Logistic回归模型
建立p(Y=1|X)与X的多元线性回归模型?
p ( Y 1 |X ) 0 1 X 1 2 X 2 3 X 3
Logistic回归模型的诊断 多重共线性的诊断 异常值的诊断
43
多重共线性的诊断
相关系数矩阵 容忍度
TOL 1R2 xk
方差膨胀因子
VIF 1 TOL
由于只关心自变量之间的关系,所以可以 通过线性回归得到容忍度指标。
44
异常值的诊断(一)
标准化残差(Pearson残差)
ej
yj njpj njpj(1pj)
通过比较包含与不包含某一个或几个待检验观察因素 的两个模型的对数似然函数变化来进行,其统计量为 G (又称Deviance)。 G=-2(ln Lp-ln Lk) 样本量较大时,G近似服从自由度为待检验因素个数的 2分布。
似然比检验
当G大于临界值时,接受H1,拒绝无效假设 ,认为从整体上看适合作Logistic回归分析 ,回归方程成立。
根据线性回归模型,选择参数估计值,使得模型
的估计值与真值的离差平方和最小。 极大似然估计( MLE ):
选择使得似然函数最大的参数估计值。
18
Logistic回归模型估计:极大似然估计
假 设 n个 样 本 观 测 值 y1,y2, ,yn,得 到 一 个 观 察 值 的 概 率 为
PYyipiyi 1pi1yi
p1e 1 ( 01X1+ 2X2+ + kXk)
15
Logistic回归模型估计:极大似然估计
Logistic回归模型估计的假设条件与OLS的不同 (1)logistic回归的因变量是二分类变量 (2)logistic回归的因变量与自变量之间的关系是非线 性的 (3)logistic回归中无相同分布的假设 (4)logistic回归没有关于自变量“分布”的假设(离 散,连续,虚拟)
Qln p 1p
pLogit变 换 Q取 值 范 围 为 ,
回归建模——二元Logistic回归模型
0.8 0.6 pP 0.4 0.2
-4
-2
0
2
Logiyt(P)
4
13
回归建模——二元Logistic回归模型
建立logit(p)与X的多元线性回归模型:
loigt(p)ln(p ) 1p
优势比(odds) 机会比(odds)
ln ( 1 p ( p Y ( Y 1 |1 X |X )))0 1 X 1 2 X 2 3 X 3
(取值范围-∞~+∞)
14
logistic回归模型
Logistic回归模型: lo ( p ) g 0 + i 1 X 1 + t = 2 X 2 k X k
e01X1+ 2X2+ + kXk p1e01X12X2 kXk
16
Logistic回归模型估计:极大似然估计
多元回归采用最小二乘估计,使因变量的 真实值和预测值差异值的平方和最小化; Logistic变换的非线性特征使得在估计模型的 时候采用极大似然估计的迭代方法,找到 系数的“最可能”的估计,在计算整个模型 拟合度时,采用似然值。
Logistic回归模型估计:极大似然估计 最小二乘估计(OLS):
Forward:condi 向前逐步 条件参数估计似然比 tional
Forward:LR 向前逐步 最大偏似然估计似然比
Forward:Wald 向前逐步
Backward:cond 向后逐步 itional
Backward:LR 向后逐步
Wald统计量 条件参数估计似然比
最大偏似然估计似然比
Backward:Wald 向后逐步 Wald统计量
2.1 Logistic回归模型的预测准确性
类R2是预测准确性的粗略近似,在自 变量与因变量完全无关时,类R2值趋 近于0;当和模型能够完美预测时,类 R2趋近于1.
26
2 Logistic回归模型的预测准确性
Cox & Snell R Square指标
2
R2
1
L0
LS
n
其中 L 0 与 L S 表示零假设模型与所设模型各自的似然值,n
test )、比分检验(score test)和Wald检验
(wald test)。三种方法中,似然比检验最
可靠,比分检验一般与它相一致,但两者
均要求较大的计算量;而Wald检验未考虑
各因素间的综合作用,在因素间有共线性
时结果不如其它两者可靠。
31
似然比检验( likehood ratio test )
▪ yj为第j个协变量组合的阳性(取值为1)观察
值个数
▪ nj为第j个协变量组合的观察单位数
▪ Pj为第j个协变量组合的概率估计值
▪ 一般认为残差值超过2则可能为异常点
45
异常值的诊断(二)
Deviance残差
d i sg y j n n jp j 2 y jl n n y jp jj n j y jl n n n jj1 y p jj
其中
SE
K为
K
的标准误。
原假设:
该自变量下的回归系数=0
35
Logistic回归参数的的置信区间
Logistic回归系数
k的置信区间为:
k
Z/
2
SE
k
发生比率的置信区间
kZ/2SE e ,e k
kZ/ 2SE
k
36
二分类Logistic回归
method 中文名称
剔除依据
Enter
全部进入
1、发生概率p的大小取值范围[0,1],p与自变 量的关系难以用多元线性模型来描述。
2、当p接近0或者1时,p值的微小变化用普 通的方法难以发现和处理好。
总:能不能找到一个p的严格单调函数Q,就 会比较方便;同时要求Q对在p=0或p=1的 附近的微小变化很敏感。
回归建模——二元Logistic回归模型