编译原理蒋守旭教材勘误教材勘误
校勘学

2、因注疏文字而衍。
是指误把注疏文字当作正文,或者依据注疏
文字而误增正文。 如《淮南子· 人间训》:‚非其事者,勿仞也; 非其名者,勿就也;无故有显名者,勿处也; 无功而富贵者,勿居也‛。 王引之《读书杂志· 淮南内篇第十八》说: ‚无故有显名者勿处也,义与上句无别,当 即是上句之注,而今本误入正文也。‛
校勘虽然源远流长,但校勘学的形成一般 认为是在清代。正如梁启超先生说: ‚清儒之有功于史学者,更一端焉,则校勘也。 古书传习愈希者,其传抄踵刻讹谬愈甚,驯致不可 读,而其书以废。清儒则博征善本以校勘之,校勘 遂成一专门学。‛(《清代学术概论》) 随着校勘事业的发展,清代也出现了校勘学这一 专门术语。朱一新说:“国朝人于校勘之学最精。” (朱一新《无邪堂答问》卷3)
如《史记· 廉颇蔺相如列传》廉颇说:‚我为赵将, 有攻城野战之大功,而蔺相如徒以口舌为劳,而位 居我上‛。 王念孙《读书杂志· 史记第四》说:‚‘大’后人所 加,攻城野战之功,对下文徒以口舌为劳言之,而 其大自见,无庸更加‘大’字。‛ 而唐宋人著作中引用此段文字时,就没有‚大‛字。 王念孙从道理上,并通过丰富的例证,足以证明 ‚大‛字确为后人所加,当为衍文。
顾炎武《日知录》,现在看到的本子是经过
后人删改的。著名学者黄侃曾根据清朝雍正 年间的一个旧抄本进行核对,发现刻本因为 怕触犯清廷禁忌,而删改的地方不少,卷六 的‚素夷狄行乎夷狄‛、卷二十八的‚胡 眼‛,整条都被删去。
3、衍文
原稿本无而传写、刻印、排印误增的文字 称衍文,又称羡文、衍字。 如,《后汉书· 郑玄传》所载《戒子书》: “吾家旧贫,不为父母昆弟所容。去厮役之吏, 游学周、秦之都,往来幽、并、兖、豫之域。” 阮元在郑玄墓地看到金代刻《后汉大司农 郑公碑》,碑文无‚不‛字,后来陈鳣见到元 大 德本《后汉书》,‚不为父母昆弟所容‛句中 也
编译原理(第2版)课后习题答案详解

第1 章引论第1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
蒋立源编译原理第三版第四章 习题与答案2

第五章习题5-1 设有文法G[S]:S→A/ A→aA∣AS∣/(1)找出部分符号序偶间的简单优先关系。
(2)验证G[S]不是简单优先文法。
5-2 对于算符文法G[S]:S→E E→E-T∣T T→T*F∣F F→-P∣P P→(E)∣i(1) 找出部分终结符号序偶间的算符优先关系。
(2) 验证G[S]不是算符优先文法。
5-3 设有文法G′[E]:E→E1E1→E1+T1|T1T1→TT→T*F|FF→(E)|i其相应的简单优先矩阵如题图5-3所示,试给出对符号串(i+i)进行简单优先分析的过程。
题图5-3 文法G′[E]的简单优先矩阵5-4 设有文法G[E]:E→E+T|TT→T*F|FF→(E)|i其相应的算符优先矩阵如题图5-4所示。
试给出对符号串(i+i)进行算符优先分析的过程。
题图5-4 文法G[E]的算符优先矩阵5-5 对于下列的文法,试分别构造识别其全部可归前缀的DFA和LR(0)分析表,并判断哪些是LR(0)文法。
(1) S→aSb∣aSc∣ab(2) S→aSSb∣aSSS∣c(3) S→A A→Ab∣a5-6 下列文法是否是SLR(1)文法?若是,构造相应的SLR(1)分析表,若不是,则阐明其理由。
(1)S→Sab∣bR R→S∣a(2)S→aSAB∣BA A→aA∣B B→b(3)S→aA∣bB A→cAd∣ε B→cBdd∣ε5-7 对如下的文法分别构造LR(0)及SLR(1)分析表,并比较两者的异同。
S→cAd∣b A→ASc∣a5-8 对于文法G[S]:S→A A→BA∣ε B→aB∣b(1) 构造LR(1)分析表;(2) 给出用LR(1)分析表对输入符号串abab的分析过程。
5-9 对于如下的文法,构造LR(1)项目集族,并判断它们是否为LR(1)文法。
(1) S→A A→AB∣ε B→aB∣b(2) S→aSa∣a第4章习题答案25-1 解:(1) 由文法的产生式和如答案图5-1(a)所示的句型A//a/的语法树,可得G中的部分优先关系如答案图5-1(b)所示。
蒋立源编译原理第三版第三章习题与答案(修改后)
3-1 试构造一右线性文法,使得它与如下的文法等价 S→AB A → UT U → aU|a D →bT|b B → cB|c
并根据所得的右线性文法,构造出相应的状态转换图。
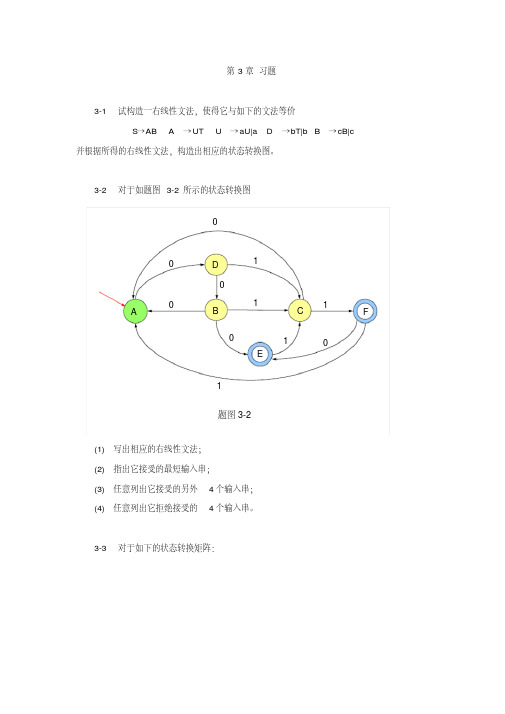
3-2 对于如题图 3-2 所示的状态转换图 0
0 0 A
D
1
0 1
B
C1
F
0
1
0
E
1 题图 3-2
(1) 写出相应的右线性文法; (2) 指出它接受的最短输入串; (3) 任意列出它接受的另外 4 个输入串; (4) 任意列出它拒绝接受的 4 个输入串。
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(3) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(3) 之 (a) 所示, 给各状态重新命名,即令:
[S]=1, [A]=2, [S,B]=3 且由于 3 的组成中含有 M的终态 B,故 3 为 DFAM′的终态。于是,所构造之 DFAM′的 状态转换矩阵和状态转换图如答案图 3-4-(3) 之(b) 及(c) 所示。
π0:{1,2}, {3}
( ⅱ) 为得到下一分划,考察子集 {1,2} 。因为
{2} b ={3}
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(4) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(4) 之 (a) 所示, 给各状态重新命名,即令:
致误原因的分析和校勘通例的归纳

第五章致误原因的分析和校勘通例的归纳分析致误原因、使用校勘通例,是区别校勘的考证与其他考证、衡量是否遵循校勘原则的重要方法。
一、分析致误原因、归纳校勘通例,是校勘学的重要组成部分*认识致误原因、归纳校勘通例的过程,也就是校勘学理论从萌生到逐渐成熟的过程。
*从校勘实践来看,不成功的校勘在很大程度上缘于对异文、错误本身缺少具体的分析、解释,不能很好地把握校勘解决的是流传过程中出现的错误这一宗旨。
*校勘通例,虽然是从实践中得出的规律性的东西,却不是放之四海而皆准的普遍规律,而是有条件的、具体的,是对某种具体条件下出现的某类错误的情形所做的归纳,每一条都是具体条件下产生的现象。
校勘的准则是:根据所校书所属时代的实际情况,字形、语音、语言习惯等等,来找出最符合原貌的文字。
要关心的是当时具体的字形、字义、语音、作者的思想、表达上的习惯等等。
*不是替作者改文章*不是著作内容正误真伪的考订*不是正字法意义上的订正*不是为传播中便读的需要对古籍进行的加工——而是:力求与原稿文字一致。
分析致误原因,要注意三点:1)校勘原则:存真复原2)历史观念:何时之书、何人所作、所见版本的时代,是具体分析某一部书、某一版本的错误的前提。
3)具体性:校勘中遇到的问题都是具体的,对文字形式发生影响、造成错误的因素也各不相同,具体分析所处理问题的具体致误原因,也是避免武断的一个重要方面。
在完整地论证一个异文的正误时,要做到:版本依据知识理由校勘通例(致误原因)三者一致,才是避免主观臆断的坚实保证。
*不能用分析致误原因代替其他考证所谓致误原因、校勘通例,或云“误例“,不过是一些容易致误的路子,可以帮助解释某字何以讹变为某字,而不能够证明某字一定是、或必须改为某字。
其他书中的同类误例可以为分析提供帮助,但也不能证明必然如此(提供的是可能性,而不是必然性)。
二、疑误和异文疑误和异文是就古籍中存在的错误和问题的形式而言的。
*异文:不同的文字。
2-3-习题(含解答)

2-3 习题(含解答)目录第1章编译原理概述 (1)第2章PL/O编译程序的实现 (4)第3章文法和语言 (4)第4章词法分析 (13)第5章自顶向下语法分析方法 (28)第6章自底向上优先分析 (39)第7章LR分析 (42)第8章语法制导翻译和中间代码生成 (60)第9章符号表 (67)第10章目标程序运行时的存储组织 (70)第11章代码优化 (73)第12章代码生成 (76)综合练习一 (79)综合练习二 (84)综合练习三 (90)综合练习四 (95)综合练习五 (101)综合练习六 (107)第1章编译原理概述一、选择题1.一个编译程序中,不仅包含词法分析,语法分析,中间代码生成,代码优化,目标代码生成等五个部分,还应包括 (1) 。
其中, (2) 和代码优化部分不是每个编译程序都必需的。
词法分析器用于识别 (3) ,语法分析器则可以发现源程序中的 (4) 。
(1) A.模拟执行器 B.解释器 C.表格处理和出错处理 D.符号执行器(2) A.语法分析 B.中间代码生成 C.词法分析 D.目标代码生成(3) A.字符串 B.语句 C.单词 D.标识符(4) A.语义错误 B.语法和语义错误 C.错误并校正 D.语法错误2.程序语言的语言处理程序是一种 (1) 。
(2) 是两类程序语言处理程序,他们的主要区别在于 (3) 。
(1) A.系统软件 B.应用软件 C.实时系统 D.分布式系统(2) A.高级语言程序和低级语言程序 B.解释程序和编译程序C.编译程序和操作系统D.系统程序和应用程序(3) A.单用户与多用户的差别 B.对用户程序的查错能力C.机器执行效率D.是否生成目标代码3.汇编程序是将翻译成,编译程序是将翻译成。
A.汇编语言程序B.机器语言程序C.高级语言程序D. A 或者BE. A 或者CF. B或者C4.下面关于解释程序的描述正确的是。
(1) 解释程序的特点是处理程序时不产生目标代码(2) 解释程序适用于COBOL 和 FORTRAN 语言(3) 解释程序是为打开编译程序技术的僵局而开发的A. (1)(2)B. (1)C. (1)(2)(3)D.(2)(3)5.高级语言的语言处理程序分为解释程序和编译程序两种。
丘维声高等代数勘误-概述说明以及解释

丘维声高等代数勘误-概述说明以及解释1.引言1.1 概述在概述部分,我们将介绍丘维声高等代数一书中可能存在的勘误问题。
丘维声高等代数是一本经典的数学教材,被广大学生和教师所喜爱和使用。
然而,由于任何一本书都难免存在一些错误或者疏漏,本文将针对此书可能存在的勘误进行深入探讨和修正。
首先,我们将对已经发现的勘误问题进行逐一分析和解释。
这些问题可能涉及到错别字、符号错误、公式推导错误等。
我们将通过具体的实例来说明这些问题的出现原因,并提供正确的内容以供读者参考和理解。
其次,我们将对读者们在使用丘维声高等代数这本教材时可能遇到的疑惑进行专门解答。
我们将解析一些常见的疑问,如某个定理证明的过程不够详细、某个步骤的推导不完整等。
同时,我们还将针对教材中可能存在的一些模糊或难以理解的概念进行解释和澄清,以帮助读者更好地掌握高等代数的知识。
最后,我们将对这些勘误问题的修正进行总结,并展望将来丘维声高等代数可能出现的改进方向。
我们希望通过本文的撰写和勘误工作,能够为读者们提供一个更准确、更完善的丘维声高等代数学习指南,并为教材的进一步优化提供宝贵的意见和建议。
在接下来的篇章中,我们将更详细地介绍并分析这些勘误问题,以期能给读者们带来更高质量的学习体验。
同时,我们也欢迎读者们积极参与讨论和反馈,一起致力于打造一本更加完美的丘维声高等代数教材。
1.2文章结构【1.2 文章结构】本文将按照以下结构展开对丘维声高等代数一书的勘误进行说明和整理:1. 引言:在引言部分,将对本文的概述、文章结构和目的进行简要介绍。
2. 正文:正文部分将分为两个要点,分别对丘维声高等代数一书中出现的错误进行勘误和修正。
2.1 第一个要点:在此部分,我们将详细列举和说明发现在丘维声高等代数一书中的错误,并提供正确的解释和修正方法。
这些错误可能涉及数学概念的解释不准确、公式的推导错误、证明过程的漏洞等等。
通过纠正这些错误,我们将确保读者对丘维声高等代数一书内容的准确理解和正确应用。
李尚志《线性代数》勘误表

《线性代数》勘误表位置错误更正p.24习题4第3个方程组第3个方程p.91倒数第1行W1∩W2=r=0dim(W1∩W2)=r=0 p.213第3行Binet-Caucht公式Binet-Cauchy公式p.233第4行r+s−n r+s−mp.241习题6x=x−c y=x−cp.248习题62n+12n−1p.293习题1a+b+c a,b,cp.305定理6.1.2线性空间的一组基线性空间U的一组基p.317习题4f∈R[x]f∈R n[x]p.330习题2diag(1,0,...,0)diag(a,0, 0p.337第15行至少为1n i至少为1p.345定义6.7.1化零多项式零化多项式p.383习题2前n−1列第1列p.383习题5Fα1⊕···⊕Fαt F[A]α1⊕···⊕F[A]αt p.383习题6F[α+β]F[A](α+β)p.387第4行当i=k时当i=k时,p.394习题5方阵A可逆方阵Ap.404习题3λm A m+λm−1A m−1+···λk A k+λk−1A k−1+···p.404习题3A m∈F m×n A k∈F m×np.404习题4{α1,...,αn}下的线性变换{α1,...,αn}下的矩阵p.405习题5α,β∈V⇒α+β∈Vα,β∈W⇒α+β∈Wp.446习题1(1)x22+x22x21+x22p.463习题3(1)矩阵Q为正定矩阵Q是正定的p.463习题3(2)矩阵Q为半负定矩阵Q是半负定的p.463习题5矩阵Q为半正定Q是半正定的p.466第3行O=X0=Xp.466习题2n∑i=1(x−s)2n∑i=1(x i−s)2p.466习题5设S是设A是p.466习题5X0=O X0=0p.466习题6实线性函数f1,f2非零实线性函数f1,f2的乘积p.474习题4.且,且p.488命题9.2.5欧氏空间n 维欧氏空间p.491习题2已知求p.492习题9(3)δ=Ax −βδ=AX −βp.504倒数第3行每个n −1阶实方阵每个n −1阶实对称方阵p.506定理9.4.3欧氏空间n 维欧氏空间p.507定理9.4.5欧氏空间n 维欧氏空间p.508习题64y 210y 2p.508命题9.5.1V 是欧氏空间V 是n 维欧氏空间p.523习题1ax 1¯y 1+bx 1¯y 2+cx 2¯y 1+dx 2¯y 2a ¯x 1y 1+b ¯x 1y 2+c ¯x 2y 1+d ¯x 2y 2p.523习题2,4,5XY ∗X ∗Yp.523习题3|xα+yβ|=|xα|+|yβ||xα+yβ|2=|xα|2+|yβ|2p.524命题9.7.2酉空间V n 维酉空间V p.532习题4(2)为Hermite 方阵为反Hermite 方阵p.536倒数第8行由于不能f 不一定正定由于f 不一定正定p.544第18行第7章§7.2第8章§8.2p.547习题2(3)(A (α),A (β))=(α,β)f (A (α),A (β))=f (α,β)p.547习题3rank f =1rank f 1p.547习题5f ((10),(01))f ((10),(01))=1p.547习题7证明:设设p.548习题7(2)H =(O I (m )I (m )O )H =(OI (m )−I (m )O )p.548习题7(3)⇔A⇔Ap.555习题6每个奇异值都是特征值全体奇异值都是特征值(包括重数)p.555习题8det(AX 0−β)|AX 0−β|p.555习题9Morre-PenroseMoore-Penrose。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
“蒋宗礼,姜守旭,编译原理,高等教育出版社,2010年2月第1版”教材勘误1.20页的图1.15修改如下:(也就是右上角T形框中的L应该改为L'。
)(a) 用L编制L'的编译程序C-L'(b) 再用AC-L编译C-L',得到AC-L'2.31页第13行“∀L∈∑*”改为“∀L⊆∑*”3.34页第15行“G=({A,B,E,C,D,P},{a,b,c,m[1],m[2],m[3],+,-,=},P,A)”改为“G=({A,B,E,C,D,O},{a,b,c,m[1],m[2],m[3],+,-,=},P,A)”4.41页倒数第1行“G4:S→A|B|BB,A→0,B→1,CACS→21,C→11,C→2”改为“G4:S→A|B|BB,A→0,B→1,C→21,C→11,C→2”5.51页倒数第2行“ε、ε、()、ε、ε、()、ε (())、()(()),(()(()))”改为“ε、ε、()、ε、ε、()、ε、()(()),(()(()))”6.52页第1行“ε、(S)、((S))、(S)((S)),其中,ε、ε是直接短语,第一个ε是句柄。
”改为“ε、(S)、(S)((S)),其中,ε、ε是直接短语,第一个ε是句柄。
”7.56页倒数第1-2行“该树有8个中间节点,其中有3个节点是只有一个中间节点为其子节点的节点,这3个节点为根的2级子树,对应的产生式分别是:E→T,T→F和T→F。
”改为“该树有11个中间节点,其中有6个节点是只有一个中间节点为其子节点的节点,这6个节点为根的2级子树对应的产生式分别是:E→T,T→F,F→P,T→F,F→P 和F→P。
”8.60页倒数第15行,在“相应的语法树”后增加“,如果不能画出,请说明理由”9.101页第13行“if check[next[base[s]+a]] = a”改为“if check[next[base[s]+a]] ==a”10.129页倒数第14行“for k=1 to i-1 do”改为“for k=2 to i do”11.130页第14行“FOLLOW(S) := ∅;”改为“FOLLOW(X) := ∅;”12.130页倒数第7行“又因为存在产生式E→TE'且E'*⇒ε”改为“又因为存在产生式E→TE'”13.130页倒数第4行“FOLLOW(T) = FIRST(E')∪FOLLOW(E)∪FOLLOW(E')= {+,),#}”改为“FOLLOW(T) = {FIRST(E')-{ε}}∪FOLLOW(E)∪FOLLOW(E')= {+,),#}”14.131页第9行“亦即FIRST(E)∩FIRST(id) =∅”改为“亦即FIRST((E))∩FIRST(id) =∅”15.133页表4.1中倒数第4行的两个“T '→ε”均改为“E '→ε”16.142页倒数第13行“/*T的子程序(T→F(*F)*) */”改为“/*T的子程序(T→F(*F)*) */”17.154页第16行“<expr_list>→<expr_list, expr>”改为“<expr_list>→<expr_list>, <expr>”18.157页倒数第10行“LASTOP(B)={a|B+⇒…b或B+⇒…aC,a∈T,C∈V}”改为“LASTOP(B)={a|B+⇒…a或B+⇒…aC,a∈T,C∈V}”19. 159页倒数第17行“若有产生式B →…b 或B →…Cb ,则b ∈LASTOP(B )”改为“若有产生式B →…b 或B →…bC ,则b ∈LASTOP(B )” 20. 159页倒数第12行“FIRSTOP()a A ∈未知或”改为“FIRSTOP()a A ∉未知或” 21. 160页5-12行存在缩进错误:第5行的while 语句和第11行的for 语句均应和第2行的for 语句对齐。
22. 161页第3行“else if i <n -2 & X i X i +1X i +2∈T ⨯V ⨯T then M [X i , X i +1]:=‘≡’;”改为“else if i <n -2& X i X i +1X i +2∈T ⨯V ⨯T then M [X i , X i +2]:=‘≡’;” 23. 165页第10-12行中的g (a )均改为g (b ),倒数第3行“注意,虽然f (id )>g (id )意味着id ≯id ,但事实上id 之间不存在优先关系。
类似地,表”改为“注意,虽然f (id )<g (id )意味着id ≮id ,但事实上id 之间不存在优先关系。
类似地,表”24. 173页倒数16行“据(分析栈)的当前状态……”改为“据(分析栈的)当前状态……” 25. 177页第6行改为“if B →.γ不在C 中then J:= J ∪{B →. γ};” 26. 178页第11行“其中,I 0 = CLOSURE({S '→.S }),C = {I 0}∪{I |#J ∈C , X ∈V ∪T , I = GO(J ,X )},C 称为G '的”改为“其中,I 0 = CLOSURE( {S '→.S } ),C = {I 0}∪{I |∃J ∈C , X ∈V ∪T , I = GO(J ,X )},C 称为G '的” 27. 180页第6行改为“⑴ E →E +T ⑵ E →T ⑶ T →T *F ⑷ T →F ⑸ F →(E ) ⑹F →id ”28. 180页第8行改为“(0) E '→E ⑴ E →E +T ⑵ E →T ⑶ T →T *F ⑷ T →F ⑸F →(E ) ⑹ F →id ”29. 184页倒数第1行改为“CLOSURE(I )={ [B →.η,b ] | ∃ [A →α.Bβ,a ]∈CLOSURE(I ) &B →η∈P & b ∈”30. 185页倒数第1行“C :=C ∪{CLOSURE(GO(I , X ))};”改为“C :=C ∪GO(I , X );” 31. 186页第7-8行“η=BB ”改为“η=L=R 或R ” 32. 192页表5.12中的倒数第3行的r 5改为r 633. 192页图5.11中,去掉项目集I 10,并将从I 6指向I 10的L 边改为I 6指向I 8/10的L 边。
34. 225页倒数第4行改为“称为L-属性定义,L 是Left 的首字母。
一般地,可以将L-属性定义定义如下。
” 35. 229页图6.5修改如下:(也就是:最左边的节点F .node 下面的节点标记从原来的id 改为num ,中间的F .node 下面的节点标记从原来的num 改为id )到x 的表项36. 243页倒数第7行至倒数第14行的T 均改为F37. 247页表38. 265页第239. 272页图7.17修改如下:(也就是:右侧的 “left .addr = t 4”改为“left .addr = t 2”)Elist .addr =t 1Elist .ndim = 2Elist .array = base A:=xLeft .addr= xLeft.offset = nullE .addr = z ]E .addr = t 4SLeft.addr = t 2Left .offset = t 3Left.addr Left .offset =nullz,Elist .addr=y Elist .ndim = l Elist .array= AA [E .addr = yLeft .= y Left .offset =null40. 279页图7.23中倒数第1行改为“106:goto 108 113:t 5 := t 1 or t 4” 41. 284页图7.25中倒数第3行改为“||gencode ('goto'nextquad +2)” 42. 284页倒数第4行改为“goto nextquad +2”43. 287页图7.27第1个M .quad =104应该为M .quad =102 44. 291页图7.29修改如下:(也就是左侧的节点a 和b 之间,c 和5之间目前空着的节点,应该加一个标记<,x 和y 之间目前空着的节点,应该加一个标记>)whileM 1.quad =100εS.nextlist ={101}B .truelist ={100}B .falselist ={101}badoM 2.quad =102εS 1.nextlist ={105,109}ifB .truelist ={102}B .falselist ={103}5cthenM 1.quad =104εS 1.nextlist ={105}N .nextlist ={109}else M 2.quad =110εS 2.nextlist =nil :=yxwhile M 1.quad =104εB .truelist ={104}B .falselist ={105}yxdo M 2.quad =106εS 1.nextlist =nil E .addr =t 1z+1x<<>45.291页正文第1行和第2行的“c<d”改为“a<b”46.292页第4行改为“108:goto 104”47.294页第1行改为“S→ for id:= E1to E2step E3do M S1{backpatch(S1.nextlist,M.nextlist);”48.294页第16行“其语义为:反复执行语句S1直到布尔表达式B为假为止。
”改为“其语义为:反复执行语句S1直到布尔表达式B为真为止。
”49.298页图7.33 “S n-1的代码;”下加一行“goto S.nextlist;”50.301页第19行改为gencode(‘call’, ‘SYSIN’, n, -);}51.330页倒数第9行“打印出的值就是1”改为“打印出的值就是2”52.330页倒数第7行“打印出的值将是2”改为“打印出的值将是3”53.372页第5行改为“for N–{n0}中的n do D(n) := ;”。