开源搜索引擎的比较
开源搜索引擎的比较 收藏

开源搜索引擎的比较收藏A Comparison of Open Source Search EnginesChristian Middleton, Ricardo Baeza-Yates作者:Christian Middleton/in/cmiddletHi5的高级工程师。
Ricardo Baeza-Yates/Ricardo_Baeza-YatesYahoo的高级研究人员。
翻译:史春奇,搜索工程师,中科院计算所毕业,chunqi.shi@原文:/WRG/dctos/Middleton-Baeza.pdf目录开源搜索引擎的比较 (1)A Comparison of Open Source Search Engines. 1目录 (1)第1章简介 (2)第2章背景 (3)2.1 文档收集 (4)2.1.1网页抓取 (4)2.1.2文本检索大会TREC. 42.2 索引 (5)2.3 查询和排序 (5)2.4 检索评估 (6)第3章搜索引擎 (7)3.1 特征 (8)3.2 评估 (9)第4章比较方法 (11)4.1 文档收集 (11)4.2 测试比较 (12)4.3引擎安装 (12)第5章测试 (12)5.1 索引 (12)5.1.1 TREC-4数据集的索引测试 (12)5.1.2 索引WT10g的分组。
(14)5.2 查询 (15)5.2.1 TREC-4数据集的查询实验 (17)5.2.2 准确率和召回率的比较 (19)5.3整体评估 (19)第6章结论 (20)参考书目 (21)第1 章简介随着互联网信息量的激增,为用户提供网上相关信息的检索成为迫切需求。
而当你准备在网站上提供这种检索服务的时候,你可以选择,要么利用商业搜索引擎,要么选择开源搜索引擎。
对于很多站点,采用商业搜索引擎,可能没预期的那么便捷,你得花钱,而且呀,你可能没大站点那样受人家重视。
另一方面,开源搜索引擎也能提供商业搜索引擎的同类功能(部分能够处理大数据量),同时拥有开源理念带来的好处:不花钱,可以更主动地来维护软件,也通过二次开发来满足个人的需求。
六大搜索引擎的比较

一、界面、广告以及速度搜索引擎在我们日常操作中的使用频率非常高,大家使用它的目的都非常明确,就是用它来搜寻需要的内容,而不会为搜索引擎的页面做过多的停留,因此搜索引擎的界面设计和速度就对我们的使用产生不小的影响,下面来看看这六款搜索引擎在界面和速度上的表现。
谷歌、百度和微软的Live Search,这三大搜索引擎的界面大家都已经相当熟悉,它们有着共同的特点,就是简洁至极:网站LOGO、搜索框和按钮以及个别功能服务链接,除此以外,页面上就没有其他多余和花哨的东西了,给人的感觉非常清爽,界面一目了然,特别是Live Search在不失简洁的同时还通过一些小脚本和背景图片使得页面整体更加美观。
三者使用起来都很方便,并且首页界面上没有任何第三方的广告。
搜索结果页面,三者同样是采用简洁的风格,页面左侧排列着搜索结果,百度搜索结果页面右侧有不少广告,谷歌视关键词的不同也可能出现右侧广告。
Live Search的界面十分简洁且美观百度搜索结果页面右侧的广告与上面三者相比,雅虎全能搜在界面上显得更为活泼、色彩更加多样,并且在首页内容上也更丰富。
首页上除了常规的搜索所需组成部分外,雅虎全能搜还加入了天气预报、邮箱登录的显示区域。
虽然这些占据了一点点页面,但是它们功能实用且不影响正常使用。
雅虎全能搜的搜索主页搜狗搜索的界面可谓结合了谷歌和Live Search:在布局上与谷歌类似,而在细节上与Live Search有着异曲同工之妙;而搜索新军——网易有道的界面与谷歌、百度站在同一阵线,风格、版式都十分一致。
在搜索结果页面中,搜狗搜索页面左侧有少量广告。
总的来说,六款搜索引擎的界面设计都比较合理、美观、大方。
雅虎全能搜的界面稍有不同,加入了天气预报和邮箱模块,而其他五款都尽量精简,其中谷歌、百度和有道趋于一致,采用最简的风格,而Live Search和搜狗在首页的一些细节上多加以了一些修饰。
此外,值得一提的是一些搜索引擎对于Logo文化的重视,在传统的节日或者一些特殊的纪念日时都会将首页的Logo徽标换成与该日子相关的设计。
国外7个源代码库搜索引擎网站

国外7个源代码库搜索引擎网站转——国外7个源代码/库搜索引擎网站2011-10-25 16:16 146人阅读评论(0) 收藏举报现如今编程似乎成为一种潮流,程序员越来越多,任何一个程序员都必须学习至少一门编程语言,但是学习编程语言总是不那么容易的,前些时候在SitePoint社区进行的如何更好的学习编程语言的讨论中,大家一致认为认真学习别人的代码是一种非常有效的方法,以下七个源代码搜索引擎网站是由网友们提供的、寻找源代码最高效的地方!让我们一起来了解一下吧!1 . GitHubGitHub是非常受欢迎的开源代码库和版本控制服务提供者,前段时间推出了一项新的源代码搜索服务,虽然GitHub才刚刚进入源代码搜索服务领域不久,但是GitHub已经成为了这一领域非常受欢迎的搜索服务提供者,并且已经拥有了数以亿计的代码储存量,正如一篇博客中提到的,GitHub中的确有”很多东西”!2 . KrugleKrugle声称他们的搜索包含超过25亿行代码,这一数量使他们成为互联网上最大的源代码搜索引擎之一,并且还称他们的搜索结果包含了全球三分之一开发者的源代码!同时他们还分别为全球多家大型公司或企业,如Amazone、IBM、、、Yahoo!等提供企业级的代码搜索服务!3 . KodersKoders号称其能够搜索的代码数目超过10亿行,并且深受Ruby 程序员的青睐!在Koders被黑鸭软件公司(Black Duck Software)收购之后,该网站关于Ruby的搜索比过去四年的总和激增了20倍,超过了该站PHP、Perl和Python的搜索数目!并且Ruby已成为该网站继Java、 C/C、和 C#之后搜索次数最多的语言。
4 . CodaesCodaes在这个源代码搜索领域似乎并不起眼,能够搜索到的代码数量也只有2.5亿条,究其原因可能是该网站的搜索服务发展似乎已经停滞好几年了。
Codaes主要关注的是关于Linux方面的C/C++项目代码,但这在今天似乎有些过时了!除非这就是你要找的内容,否则除此之外你有更好的搜索选择。
四种搜索引擎的比较研究

参考内容
基本内容
基本内容
随着互联网的快速发展,搜索引擎在人们的生活中扮演着越来越重要的角色。 传统的搜索引擎如Google、Bing等已经为广大网民所熟知,而近年来,智能搜索 引擎也逐渐崭露头角。本次演示将对传统搜索引擎和智能搜索引擎进行比较研究, 分析它们的优缺点,并探讨未来的发展趋势。
4、未来发展方向
(2)个性化搜索:通过对用户历史搜索记录、行为偏好等数据的分析,为每个 用户提供定制化的搜索结果,提高用户体验。
4、未来发展方向
(3)多模态搜索:融合文字、图片、音频、视频等多种信息形态,使搜索引擎 能够处理和理解更为丰富的信息,满足用户多样化的搜索需求。
4、未来发展方向
(4)交互式搜索:增强搜索引擎与用户的交互能力,允许用户在搜索过程中进 行实时反馈和调整,以获得更符合需求的搜索结果。
基本内容
基本内容
随着互联网的飞速发展,搜索引擎作为信息检索的重要工具,一直受到广泛。 按照搜索原理和技术特点,搜索引擎可分为传统搜索引擎和语义搜索引擎。本次 演示将对两者进行详细比较,并探讨未来发展趋势。
1、引言
1、引言
搜索引擎是一种自动化的信息检索系统,它通过爬取互联网上的信息,建立 索引数据库,为用户提供快速、准确的信息查询服务。从20世纪90年代初的目录 导航型搜索引擎,到后来的元搜索引擎和垂直搜索引擎,再到21世纪的语义搜索 引擎,搜索引擎的发展经历了多个阶段。
4、未来发展方向
(5)跨语言搜索:提高搜索引擎对不同语言的支持能力,使其能够理解和处理 多种语言的信息,满足全球用户的需求。
4、未来发展方向
综上所述,传统搜索引擎和语义搜索引擎各有优劣,未来的发展趋势是以语 义搜索引擎为主导,传统搜索引擎将逐渐向智能化方向转型。随着技术的不断发 展,搜索引擎将更好地理解用户需求,提供更为精准、个性化的搜索服务。
21款开源搜索引擎项目介绍

21款开源搜索引擎项目介绍搜索引擎的主流语言是Java,要研究和开发搜索引擎,最好从Lucene开始,下面介绍一些开源搜索引擎系统,包含开源Web搜索引擎和开源桌面搜索引擎。
Lucene一个全文搜索引擎工具包,但只支持文本文件以及少量语种的索引;通过Lucene提供的接口,我们可以自己开发具体语言的分词器,针对具体文档的文本解析器等;Lucene是索引数据结构事实上的标准;Apache Lucene是一个基于Java全文搜索引擎,利用它可以轻易地为Java软件加入全文搜寻功能。
Lucene的最主要工作是替文件的每一个字作索引,索引让搜寻的效率比传统的逐字比较大大提高,Lucen提供一组解读,过滤,分析文件,编排和使用索引的API,它的强大之处除了高效和简单外,是最重要的是使使用者可以随时应自已需要自订其功能。
Sphider Sphider是一个轻量级,采用PHP开发的web spider和搜索引擎,使用mysql来存储数据。
可以利用它来为自己的网站添加搜索功能。
Sphider非常小,易于安装和修改,已经有数千网站在使用它。
RiSearch PHPRiSearch PHP是一个高效,功能强大的搜索引擎,特别适用于中小型网站。
RiSearch PHP非常快,它能够在不到1秒钟内搜索5000-10000个页面。
RiSearch是一个索引搜索引擎,这就意味着它先将你的网站做索引并建立一个数据库来存储你网站所有页面的关键词以便快速搜索。
Risearch是全文搜索引擎脚本,它把所有的关键词都编成一个文档索引除了配置文件里面的定义排除的关键词。
RiSearch使用经典的反向索引算法(与大型的搜索引擎相同),这就是为什么它会比其它搜索引擎快的原因。
Xapian使用C++编写,提供绑定程序使得其他语言能够方便地使用它;便于进行二次开发PhpDigPhpDig是一个采用PHP开发的Web爬虫和搜索引擎。
通过对动态和静态页面进行索引建立一个词汇表。
三大搜索引擎对比分析表
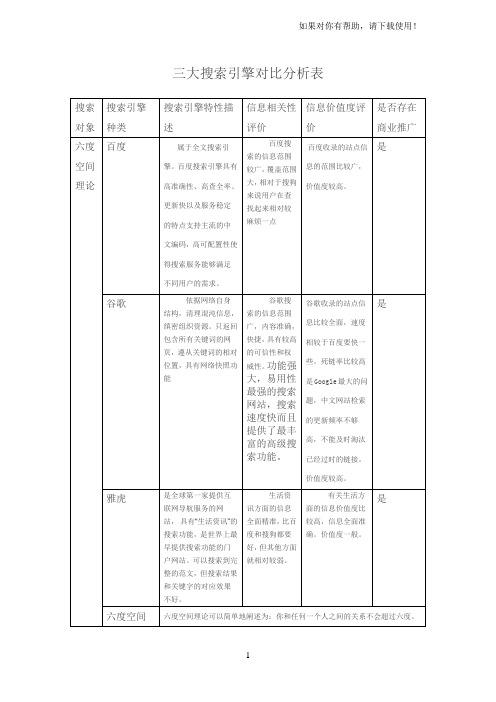
三大搜索引擎对比分析表
六度空间理论:
六度空间理论是一个数学领域的猜想,名为Six Degrees of Separation,中文翻译包括以下几种:六度分割理论或小世界理论等。
理论指出:你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。
这就是六度分割理论,也叫小世界理论。
这种现象,并不是说任何人与人之间的联系都必须要通过六个层次才会产生联系,而是表达了这样一个重要的概念:任何两位素不相识的人之间,通过一定的联系方式,总能够产生必然联系或关系。
显然,随着联系方式和联系能力的不同,实现个人期望的机遇将产生明显的区别。
手持移动电视市场:
移动电视是指采用数字广播技术(主要指地面传输技术)播出,接收终端一是安装在公交汽车、地铁、城铁、出租车、商务车和其他公共场所的电视系统,二是手持接收设备(如手机、笔记本、PMP、超便携PC等)等满足移动人群收视需求的电视系统。
本文主要讨论支持第二类的移动终端,即手持移动电视的技术应用状况。
目前手持移动电视产品中占绝对数量的是手机电视。
国外典型元搜索引擎特性比较与分析

关键词 : 索引擎; 元搜 索 引擎;信 息检 索;检 索; 特性 搜
中图法 分类号 : P 9.9 T 33 0 文 献标识 码 : A 文章编 号 :0 07 2 2 1) 9 13 -4 10 —0 4(00 0 —9 10
计算 机 工程 与设 计 C m u r n i en d ei o pt E g er g n D s n e n i a g ・网 络 与 通信 技 术 ・
2 1,1 9 00 () 3
13 91
国外典型元搜索引擎特性比较与分析
李灵 华 , 米 守 防
( 大连 民族 学院 计 算机 科 学 与工程 学 院,辽 宁 大连 16 0 ) 16 0
d n r e r h u e s s a c e t r s f we t e r s n ai ef r i nme a s a c n i e esu id c n r si ey I i o n e u a i a y s a c s r , e r h f au e t n yr p e e t t eg t — e r h e gn sa t d e o ta t l. t s i t do t h t o v o r v p t ag o t —e r h e g n s h ss me f au e , i cu i g wh c dv d a e r h e g n ss o l e c v r d wh c f r t n o d me a s a c n i e mu t a o e t r s n l dn ih i i i u l a c n i e h u d b o e e , n s i h i o ma i n o ee n s s o l e i c u e n t e r tiv l e u t a e , wh c ip s l y h u d b u p s d i o sr c i g a r tiv l u r , lme t h u d b n l d d i h ere a s l p g s r ih d s o a wa s s o l e s p o e c n tu t e r a ey n n e q wh c p i n h u d b e e s n l e ere a , a d mu t ig a ere a h u d b u p se , e c ih o t ss o l es t n ap r o ai d r t v l n l l u l tiv l o l e s p o d o i z i in r s t.
开源搜索引擎比较

开源搜索引擎的比较1.N utch简介:Nutch是一个用java实现的基于Lucene的开源搜索引擎框架,主要包括爬虫和查询两部分组成。
Nutch所使用的数据文件主要有以下三种:1)是webDb,保存网页链接结构信息,只在爬虫工作中使用。
2)是segment,存储网页内容及其索引,以产生的时间来命名。
segment文件内容包括CrawlDatum、Content、ParseData、ParseText四个部分,其中CrawlDatum保存抓取的基本信息,content 保存html脚本,ParseData和ParseText这两个部分是对原内容的解析结果。
3)是index,即索引文件,它把各个segment的信息进行了整合。
爬虫的搜索策略是采用广度优先方式抓取网页,且只获取并保存可索引的内容。
Nutch0.7需要java1.4以上的版本,nutch1.0需要java1.6。
特点:1、遵循robots.txt,当爬虫访问一个站点时,会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
2、采用基于Hadoop的分布式处理模型,支持分布式的实现。
3、Nutch可以修剪内容,或者对内容格式进行转换。
4、Nutch使用插件机制,可以很好的被用户定制和集成。
5、Nutch采用了多线程技术。
6、将爬取和建索引整合在了一起,爬取内容的存储方式是其自己定义的segment,不便于对爬取的内容进行再次处理,需要进行一定的修改。
7、因为加入了对页面分析,建索引等功能其效率与heritrix相比要相对较低。
2.H eritrix简介:Heritrix是一个用Java实现的基于整个web的可扩展的开源爬虫框架。
Heritrix主要由三大部件:范围部件,边界部件,处理器链组成。
范围部件主要按照规则决定将哪个URI入队;边界部件跟踪哪个预定的URI将被收集,和已经被收集的URI,选择下一个 URI,剔除已经处理过的URI;处理器链包含若干处理器获取URI,分析结果,将它们传回给边界部件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
开源搜索引擎的比较
1. Nutch
简介:
Nutch是一个用java实现的基于Lucene的开源搜索引擎框架,主要包括爬虫和查询两部分组成。
Nutch所使用的数据文件主要有以下三种:1)是webDb,保存网页链接结构信息,只在爬虫工作中使用。
2)是segment,存储网页内容及其索引,以产生的时间来命名。
segment文件内容包括CrawlDatum、Content、ParseData、ParseText四个部分,其中CrawlDatum保存抓取的基本信息,content保存html脚本,ParseData和ParseText这两个
部分是对原内容的解析结果。
3)是index,即索引文件,它把各个segment的信息进行了
整合。
爬虫的搜索策略是采用广度优先方式抓取网页,且只获取并保存可索引的内容。
Nutch0.7需要java1.4以上的版本,nutch1.0需要java1.6。
特点:
1、遵循robots.txt,当爬虫访问一个站点时,会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
2、采用基于Hadoop的分布式处理模型,支持分布式的实现。
3、Nutch可以修剪内容,
或者对内容格式进行转换。
4、 Nutch使用插件机制,可以很好的被用户定制和集
成。
5、 Nutch采用了多线程技术。
6、将爬取和建索引整合在了一起,爬取内容的存储方式是其自己定义的segment,不便
于对爬取的内容进行再次处理,需要进行一定的修改。
7、因为加入了对页面分析,建索
引等功能其效率与heritrix相比要相对较低。
全国注册建筑师、建造师考试备考资料历年真题考试心得模拟试题
2. Heritrix
简介:
Heritrix是一个用Java实现的基于整个web的可扩展的开源爬虫框架。
Heritrix主要由三大
部件:范围部件,边界部件,处理器链组成。
范围部件主要按照规则决定将哪个URI入队;边界部件跟踪哪个预定的URI将被收集,和已经被收集的URI,选择下一个 URI,剔除已
经处理过的URI;处理器链包含若干处理器获取URI,分析结果,将它们传回给边界部件。
采用广度优先算法进行爬取。
heritrix用来获取完整的、精确的、站点内容的深度复制。
包括获取图像以及其他非文本内容。
抓取并存储相关的内容。
对内容来者不拒,不对页面进行内容上的修改。
重新爬行对
相同的URL不针对先前的进行替换。
特点:
1、各个部件都具有较高的可扩展的,通过对各个部件的修改可以实现自己的抓取逻辑。
2、可以进行多种的配置,包括可设置输出日志,归档文件和临时文件的位置;可设置下
载的最大字节,最大数量的下载文档,和最大的下载时间;可设置工作线程数量;可设置
所利用的带宽的上界;可在设置之后一定时间重新选择;包含一些可设置的过滤机制,表
达方式,URI路径深度选择等等。
3、采用多线程技术。
4、保存的内容是原始的内容,采用镜像方式存储,即按照斜杠所划分出的层次结构进行
存储,同时也会爬取图片等信息。
5、同样也遵守robots.txt规范。
6、在硬件和系统失败时,恢复能力很差。
3. WebSPHINX
简介:
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。
WebSPHINX由两部分组成:
爬虫工作平台和WebSPHINX类包。
爬虫工作台提供接口实现对爬虫的配置;类包则提供
对爬虫进行扩展需要的一些支持。
其工作原理为从一个基点网站出发,遍历其中的所有有用信息,同时抽去其中的链接信息
放入队列,以待有空闲蠕虫(worm)时,从队列中读取,发出request 请求,继续进行信
息抽取和链接入队列的工作。
特点:
1、保存网页的原始内容。
2、采用多线程技术。
3、采用广度优先遍历算法进行爬取。
4、支持HTML解析,URL过滤,页面配置,模式匹配等等。
5、适用于爬取小规模的网页,例如爬取单一的个人站点。
4. Weblech
简介:
WebLech是一个用Java实现的功能强大的Web站点下载与镜像工具。
它支持按功能需求
来下载web站点并能够尽可能模仿标准Web浏览器的行为。
WebLech有一个功能控制台
并采用多线程操作。
特点:
1、支持多线程技术。
2、可维持网页的链接信息,可配置性较强,配置较为灵活,可设置需获取的网页文件的
类型、起始地址、抓取策略等14 项内容。
3、采用广度优先遍历算法爬取网页。
4、保存网页的原始内容。
5. Jspider
简介:
JSpider是一个完全用Java实现的可配置和定制的Web Spider引擎.你可以利用它来检查网站的错误(内在的服务器错误等),网站内外部链接检查,分析网站的结构(可创建一个网站地图),下载整个Web站点,你还可以写一个JSpider插件来扩展你所需要的功能。
Jspider主要由规则、插件和事件过滤器三部分组成,规则决定获取和处理什么资源;插件可以根据配置叠加和替换功能模块;事件过滤器选择处理什么事件或则独立的插件。
特点:
1、扩展性较强,容易实现对爬虫功能的扩展。
2、目前只支持下载HTML,不支持下载动态网页。
3、保存原始网页内容。
6. Spindle
简介:
spindle是一个构建在Lucene工具包之上的Web索引和搜索工具.它包括一个用于创建索引的HTTPspider和一个用于搜索这些索引的搜索类。
spindle项目提供了一组JSP标签库使得那些基于JSP的站点不需要开发任何Java类就能够增加搜索功能。
该项目长期没有更新且功能不完善。
7. Jobo
简介:
JoBo是一个用于下载整个Web站点的简单工具。
它本质是一个WebSpider。
与其它下载工具相比较它的主要优势是能够自动填充form(如:自动登录)和使用cookies来处理session。
JoBo还有灵活的下载规则(如:通过网页的URL,大小,MIME类型等)来限制下载。
8. Snoics-reptile
简介:
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方式获取到的资源全部抓取到本地,包括网页和各种类型的文件,如:图片、flash、mp3、zip、rar、exe等文件。
可以将整个网站完整地下传至硬盘内,并能保持原有的网站结构精确不变。
只需要把抓取下来的网站放到web服务器(如:Apache)中,就可以实现完整的网站镜像。
9. Arachnid
简介:
Arachnid是一个基于Java的webspider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Webspiders并能够在Web站上的每个页面被解析之后增加几行代码调用。