DOM
什么是DOM及DOM操作?

什么是DOM及DOM操作?什么是 DOM ?DOM(⽂档对象模型)是针对于xml但是扩展⽤于html的应⽤程序编程接⼝,定义了访问和操作html的⽂档的标准。
W3C⽂档对象模型是中⽴于平台和语⾔之间的接⼝,它允许程序和脚本动态的访问和更新⽂档的内容、结构、样式。
总之HTML是关于如何获取、修改、添加和删除HTML元素的标准。
DOM 分层节点DOM的分层节点⼀般被称作是DOM树,树中的所有节点都可以通过脚本语⾔例如js进⾏访问,所有HTMlL元素节点都可以被创建、添加或者删除。
在DOM分层节点中,页⾯就是⽤分层节点图表⽰的。
整个⽂档是⼀个⽂档节点,就想是树的根⼀样。
每个HTML元素都是元素节点。
HTML元素内的⽂本就是⽂本节点。
每个HTML属性时属性节点。
当咱们访问⼀个web页⾯时,浏览器会解析每个HTML元素,创建了HTML⽂档的虚拟结构,并将其保存在内存中。
接着,HTML页⾯被转换成树状结构,每个HTML元素成为⼀个叶⼦节点,连接到⽗分⽀。
考虑以下 Html 结构:<!DOCTYPE html><html lang="en"><head><title>A super simple title!</title></head><body><h1>A super simple web page!</h1></body></html>在这个结构的顶部有⼀个document,也称为根元素,它包含另⼀个元素:html。
html元素包含⼀个head,⽽ head ⼜有⼀个title。
然后body 包含⼀个h1。
每个HTML元素都由特定类型(也称为接⼝)表⽰,并且可能包含⽂本或其他嵌套元素:document (HTMLDocument)|| --> html (HTMLHtmlElement)|| --> head (HtmlHeadElement)| || | --> title (HtmlTitleElement)| | --> text: "A super simple title!"|| --> body (HtmlBodyElement)| || | --> h1 (HTMLHeadingElement)| | --> text: "A super simple web page!"每个HTML元素都来⾃Element,但其中很⼤⼀部分都是专⽤的。
dom 分子组成

dom 分子组成
DOM,全称为溶解有机物,是水生生态系统中一种重要的化学组成部分。
它是由各种生物过程产生的复杂混合物,主要包括蛋白质、碳水化合物、脂肪酸、氨基酸等有机化合物。
DOM的分子组成相当复杂,且因来源和降解程度的不同而有所差异。
首先,蛋白质是DOM中重要的组成部分。
蛋白质由氨基酸通过肽键连接而成,而氨基酸的结构特点是至少含有一个氨基和一个羧基,并且它们都连接在同一个碳原子上。
这个碳原子还连接一个氢原子和一个侧链基团,这个侧链基团决定了氨基酸的种类。
在DOM中,蛋白质可能经过水解等过程,形成各种大小的肽段和游离的氨基酸。
其次,碳水化合物也是DOM的重要组成部分。
碳水化合物是由碳、氢、氧三种元素组成的,其中氢氧的比例通常为2:1,与水的比例一致,因此称为碳水化合物。
在DOM中,碳水化合物可能以单糖、寡糖和多糖的形式存在,它们是由糖苷键连接而成的。
此外,DOM中还含有各种脂肪酸和氨基酸等有机化合物。
这些化合物可能来自于生物的代谢过程,也可能来自于外界环境的输入。
它们在DOM中的存在形式和比例,受到许多因素的影响,如温度、pH值、氧化还原条件等。
总的来说,DOM的分子组成非常复杂,包括蛋白质、碳水化合物、脂肪酸、氨基酸等各种有机化合物。
这些化合物在DOM中的存在形式和比例,对于水生生态系统的物质循环和能量流动具有重要的影响。
因此,对DOM的分子组成进行深入的研究,有助于我们更好地理解水生生态系统的功能和过程。
什么是DOM

什么是DOM???DOM 是Document Object Model的缩写,即文档对象模型!理解为一套浏览器解读和显示的标准!dom提供了很多标签和页面样式标准,一定的接口(方法)规定浏览器需要完成一定的操作,单单javascript只能组成一些算法,实际上没法操作页面!只有通过DOM对HTML 和XML文档进行读取,搜索,修改,添加和删除等操作来间接操作页面样式。
DOM是独立于语言和平台的一套标准接口,定义了构成DOM的不同对象,比恩没有提供特定的实现,可以用任何编程语言实现。
利用DOM中的对象,开发人员可以对HTML和XML文档进行读取,搜索,修改,添加和删除等操作。
W3C DOM提供了一组描述HTML及XML文件的标准对象和一个用来访问和操作这类文件的标准界面。
从面向对象的角度看,可以把HTML文档和XML文档看成是一个对象。
一个XML文档对象可以包含其他的对象,如节点对象。
在DOM中有相应的对象来对应实际XML文档的对象。
DOM规范中提供了一组对象用来实现对文档结构的访问。
各种基于DOM规范的解析器必须按照DOM规范在内存中建立数据模型。
DOM规范的核心是树模型。
解析XML文件的解析器,通过读入XML文件在内存中建立一个树模型,(通过特定算法存储数据,也通过相应的算法操作数据)DOM是一组API接口,接口里面存放的不同类型的未实例化对象对应着XML文档中不同类型的节点和数据。
用编程语言实现这些接口,就可以通过对象来操作相应的XML文档。
DOM为一套规范(包括代码解析标准和代码组织标准)如:DOM文档:interface document{.//有很多方法,每个方法的实现文本也都给出来了}interface Node{}interface NodeList{}interfact NamedNodeMap{}interfact Element{}interfact Text{}通过每个接口的方法的实现来创建对象(这些对象也都已经定义好了)如通过document接口创建document对象,一个document对象其本质就是一个HMTL文档,即为一个htnl标记。
DOM详解——精选推荐

DOM详解⼀、简介DOM即(Document Object Model):⽂档对象模型,⽤来将标记型⽂档封装成对象,并将标记型⽂档中的所有内容(标签、⽂本、属性等)都封装成对象。
即标记型⽂档的⼀种解析⽅式。
因为封装为对象就可以对其中的属性和⾏为进⾏调⽤,以便于对这些⽂档及⽂档中的内容进⾏更⽅便的操作。
DOM解析⽅式:将标记型⽂档解析为⼀颗dom树,⽽树中的内容都封装为节点对象。
按照标签的层次关系体现出标签的所属,形成⼀个树状结构。
所以我们将DOM解析⽂档形成的document对象称为dom树,⽽树中的标签以及⽂本甚⾄属性称为节点。
这个节点也称为对象。
标签通常也称为页⾯中的元素。
注意:这个DOM解析的好处是可以对树中的节点进⾏任意操作,如增删查改。
但也有弊端:这种解析需要将标记型⽂档加载进内存。
意味着如果⽂档体积很⼤时较为浪费空间。
⼆、另⼀种解析⽅式:SAX是由⼀些组织定义的⼀种民间常⽤的解析⽅式,并不是w3c标准,⽽DOM是w3c的标准。
SAX的解析⽅式:基于事件驱动的解析。
好处:获取数据的速度快。
弊端:不遵从增删查改操作。
三、DOM三种模型DOM level 1:将html⽂档封装成对象。
DOM level 2:在level1的基础上加⼊了新功能,⽐如解析名称空间。
DOM level 3:将xml⽂档封装成了对象。
四、DHTML:动态html不是⼀门语⾔,⽽是多项技术综合体的简称,这些技术包括HTML、CSS、DOM、JavaScript。
四种技术(语⾔)在动态html中扮演的⾓⾊:HTML:⽤标签封装数据。
即负责提供标签,对数据进⾏封装,⽬的是便于对该标签中的数据进⾏操作。
CSS:对数据样式进⾏定义。
即负责提供样式属性,对标签中的数据进⾏样式的定义。
DOM:将⽂档和标签等所有内容进⾏解析。
即负责将标记型⽂档及⽂档中的内容进⾏解析。
并封装成对象,在对象中定义了更多的属性和⾏为,便于对对象进⾏操作。
dom基本概念

dom基本概念DOM基本概念DOM(Document Object Model)是一种用于处理HTML和XML文档的编程接口。
它将文档表示为一个树形结构,其中每个节点都是一个对象,每个对象都有其自身的属性和方法。
DOM的基本概念包括节点、元素、属性、文本、注释、文档对象等。
节点节点是DOM中最基本的单位,它可以是元素、属性、文本、注释等。
每个节点都有其自身的类型、名称、值等属性。
节点之间可以存在父子关系、兄弟关系等。
在DOM中,节点可以通过节点类型来进行分类,例如元素节点、属性节点、文本节点等。
元素元素是DOM中的一种节点类型,它表示HTML或XML文档中的标签。
每个元素都有其自身的标签名、属性、子元素等。
在DOM中,元素节点可以通过标签名来进行访问,例如document.getElementsByTagName()方法可以获取文档中指定标签名的所有元素。
属性属性是DOM中的一种节点类型,它表示HTML或XML文档中的属性。
每个属性都有其自身的名称和值。
在DOM中,属性节点可以通过元素节点来进行访问,例如element.getAttribute()方法可以获取元素节点的指定属性值。
文本文本是DOM中的一种节点类型,它表示HTML或XML文档中的文本内容。
每个文本节点都有其自身的文本值。
在DOM中,文本节点可以通过元素节点来进行访问,例如element.firstChild.nodeValue 可以获取元素节点的文本内容。
注释注释是DOM中的一种节点类型,它表示HTML或XML文档中的注释内容。
每个注释节点都有其自身的注释值。
在DOM中,注释节点可以通过元素节点来进行访问,例如element.childNodes可以获取元素节点的所有子节点,其中包括注释节点。
文档对象文档对象是DOM中的一种节点类型,它表示整个HTML或XML文档。
文档对象是DOM树的根节点,它包含了整个文档的所有元素、属性、文本、注释等节点。
什么是DOM

什么是DOM1. 什么是DOM: document object modelDOM: 专门操作⽹页内容的⼀套函数和对象DOM还是⼀个标准,由W3C制定为什么:⼴义JS=ECMAScript + DOM + BOM核⼼语法操作⽹页内容访问浏览器软件要想操作⽹页内容,为页⾯添加交互效果,其实只能⽤DOM函数和对象。
问题: 早起的DOM没有标准解决: W3C制定了统⼀的DOM函数和对象的标准。
⼏乎所有浏览器100%兼容。
特例: IE8何时: 只要操作⽹页内容,为⽹页添加交互⾏为,只能⽤DOM包括: 5件事: 增删改查事件绑定2. DOM树:什么是: 在内存中,集中保存⼀个⽹页中所有内容的树形结构为什么: 树形结构是最直观的保存上下级包含关系的数据结构。
⽽⽹页中的HTML标签,刚好也是⽗⼦嵌套的上下级包含关系。
所以,⽹页中每⼀项内容,在内存中,都是存在⼀棵树形结构上的。
如何:1. 当浏览器读取到⼀个.html⽂件时,会先在内存中创建⼀个document对象,作为整棵树的树根对象2. 开始扫描.html中每个元素,⽂本等内容。
每扫描到⼀项内容,就在document下对应位置创建⼀个节点(node)对象。
3. 查找元素:1. 不需要查找,就可直接获得:document.documentElement <html>document.head <head>document.body <body>2. 按节点间关系查找:树上的每个节点都不是孤⽴存在的。
都和上下左右的节点之间有各种各样的关系,可以互相访问到。
包括:节点树: 包含所有节点内容的完整树结构2⼤类关系:1. ⽗⼦关系:节点.parentNode获得当前节点的⽗节点⽗节点.childNodes 获得当前⽗节点下的所有直接⼦节点的集合。
强调: childNodes返回的是⼀个类数组对象,今后我都简称集合。
⽗节点.firstChild 获得当前⽗节点下的第⼀个直接⼦节点。
什么是Dom?
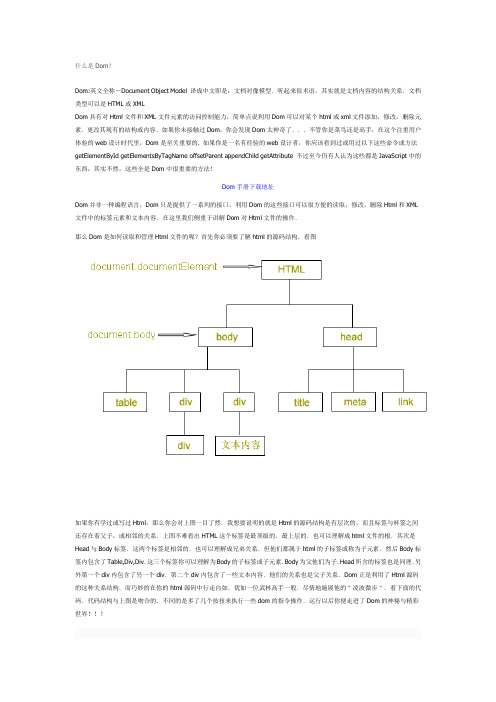
什么是Dom?Dom:英文全称-Document Object Model 译成中文即是:文档对像模型.听起来很术语,其实就是文档内容的结构关系.文档类型可以是HTML或XMLDom具有对Html文件和XML文件元素的访问控制能力,简单点说利用Dom可以对某个html或xml文件添加,修改,删除元素.更改其现有的结构或内容.如果你未接触过Dom,你会发现Dom太神奇了...不管你是菜鸟还是高手,在这个注重用户体验的web设计时代里,Dom是至关重要的. 如果你是一名有经验的web设计者,你应该看到过或用过以下这些命令或方法getElementById getElementsByTagName offsetParent appendChild getAttribute 不过至今仍有人认为这些都是JavaScript中的东西,其实不然,这些全是Dom中很重要的方法!Dom手册下载地址Dom并非一种编程语言,Dom只是提供了一系列的接口,利用Dom的这些接口可以很方便的读取,修改,删除Html和XML 文件中的标签元素和文本内容.在这里我们侧重于讲解Dom对Html文件的操作.那么Dom是如何读取和管理Html文件的呢?首先你必须要了解html的源码结构.看图如果你有学过或写过Html,那么你会对上图一目了然.我想要说明的就是Html的源码结构是有层次的,而且标签与杯签之间还存在着父子,或相邻的关系.上图不难看出HTML这个标签是最顶级的.最上层的.也可以理解成html文件的根.其次是Head与Body标签.这两个标签是相邻的.也可以理解成兄弟关系.但他们都属于html的子标签或称为子元素.然后Body标签内包含了Table,Div,Div.这三个标签你可以理解为Body的子标签或子元素.Body为父他们为子.Head所含的标签也是同理.另外第一个div内包含了另一个div.第二个div内包含了一些文本内容.他们的关系也是父子关系.Dom正是利用了Html源码的这种关系结构.而巧妙的在你的html源码中行走自如.犹如一位武林高手一般.尽情地施展他的"凌波微步".看下面的代码.代码结构与上图是吻合的.不同的是多了几个按扭来执行一些dom的指令操作.运行以后你便走进了Dom的神秘与精彩世界!!!<html><head><title>这是网页的标题</title><link/><meta/><body><table border="1"><table><div><div></div></div><div>文本内容</div><input type="button"value="弹出html标签"onclick="alert_HTML()"/><input type="button"value="弹出body标签"onclick="alert_Body()"/><input type="button"value="弹出head标签"onclick="alert_Head()"/><input type="button"value="修改网页标题"onclick="up_Title()"/><input type="button"value="更改表格"onclick="up_Table()"/><input type="button"value="获取第一个div和他的子元素"onclick="get_Div()"/><input type="button"value="更改第二个div中的文本内容"onclick="up_div_text()"/> </body></html><script type="text/javascript">function alert_HTML(){ //弹出html标签函数var html = document.documentElement;alert(html.tagName);}function alert_Body(){ //弹出body标签函数var body = document.body;alert(body.tagName);}function alert_Head(){//弹出head标签函数,var html = document.documentElement;//head是html标签中的第一个子元素//childNodes可以获取某一标签内的所有子元素var head = html.childNodes[0].tagName;alert(head);}function up_Title(){//注意title标签内的"这是网页的标题"将被改变.document.title = "Web圈提提供的Dom图解入门教程";}function up_Table(){//为表格添加行,添加列并写入文本内容var Table = document.getElementsByTagName("table")[0];//获取网页内第一个表格var Tr = Table.insertRow(0);//为表格添加一行var Td = Tr.insertCell(0);//为新建的行,添加一列Td.innerHTML = "我是表格中的文本"; //利用innerHTML属性向td写入文本}function get_Div(){//获取第一个div和他的孩子var div = document.getElementsByTagName("div")[0];alert("我是第一个"+div.tagName);var child_div = div.childNodes[0];//虽然是子div,但是按解析顺序他在该页内是第二个出现的div,alert("我是第一个div的子元素.我也是"+child_div.tagName);}function up_div_text(){var div = document.getElementsByTagName("div")[2];//其实如果按解析顺序该div在本页应该是第3个,div.innerHTML = "欢迎阅读web圈提供的Dom图解入门教程. 作者:康董";}</script>上面演示的代码实例.略有繁琐.并非是Dom最优秀的使用方法.但足以让你了解Dom是怎样工作的.下面将演示Dom迅速访问某个标签的方法.可以让你在成千上万个html标签中迅速找到你想的某个标签.比如你可以为你的html标签添加一个ID属性.在Dom中有一个getElementById方法.该方法可以根据html标签的ID属性值,迅速找到这个标签.然后对其进行更改或其他操作.下面的代码我只为table和第一个div添加一个id属性值.利用getElementByid迅速向able和第一个div的子div添加内容<html><head><title>这是网页的标题</title><link/><meta/><body><table id="a"border="1"><table><div id="b"><div></div></div><div>文本内容</div><input type="button"value="更改table"onclick="up_table()"/><input type="button"value="为第一个div的子div写入文本"onclick="up_div()"/></body></html><script type="text/javascript">function up_table(){//更改table函数var Table = document.getElementById("a");//根据id获取标签元素var Tr = Table.insertRow(0);var Td = Tr.insertCell(0);Td.innerHTML = "欢迎光临Web圈,网址:";}function up_div(){//为第一个div的子div添加文本内容var div = document.getElementById("b");div.childNodes[0].innerHTML="我是子div,我被写入文本了";}</script>上面的两个例子中分别使用了Dom的以下方法:document:对当前整个Html网页的引用documentElement:获取html和xml文件中的根元素.在html文件中总是返回Html标签.在xml文件中总是返回最顶层的那个元素getElementsByTagName:根据指定的标签名称,来获取网页中所有相同的标签元素.如:table,或div.则会找出网页中所有table 元素,或所有div元素.以一个类似数组的方式来返回对这些元素的引用.getElementById:根据指定的标签id值.来寻找标签元素.并返回对该标签的引用childNodes:获取某个标签下所有的子标签元素,也就是我所说的孩子元素.并以一个类似数组的方式来返回对所有子元素的引用insertRow:为表格增加一行insertCell:为表格的某行增加一列该入门教程只讲解了Dom中的一部份知识,请了解更多关于Dom的内容Dom可以在网页中做什么?HTML Dom中最常用的几个方法之查找元素1.Dom之引用当前整个网页文档:document2.Dom如何快速在网页中查找某一元素:getElementById3.Dom中查找一组标签,具有相同名称的标签元素:getElementsByTagName4.根据标签的Id属性值或name属性来查找多个元素:getElementsByNameDom中创建,添加,删除,修改,替换,复制,网页中的标签和文本内容的方法如下.1.在网页中的创建一个标签元素:createElement2.创建一段文本内容:createTextNode3.向网页中添加元素:appendChild4.删除元素的Dom方法是:removeChild5.修改网页中标签元素的属性:setAttribute6.替换已存在的标签或元素:replaceChild7.复制克隆已存在的标签或元素:cloneNode8.获取和修改元素内的html标签与文本内容:innerHTML9.获取或修改元素的文本内容,仅支持IE:innerText10.获取或修改元素的文本内容,支持FF:textContentHTML Dom中还专门提供了一组接口用来操作网页中的表格Table元素1.HTML Dom中的insertRow方法可以为表格增加一行2.删除表格中一行的方法是:deleteRow3.HTML Dom中的insertCell方法可以为表格某行中增加一列4.删除行中的一列的方法是:deleteCell5.HTML Dom中的createCaption方法可以为表格创建一个标题6.HTML Dom中的createTHead方法可以为表格创建一个Thead7.HTML Dom中的createTFoot方法可以为表格创建一个TFoot8.引用表格中所有行的属性为:rows9.引用表格中某行的所有列:cells10.移动表格中的行,只支持IE:moveRow Dom中操作父元素,子元素,兄弟元素的相关命令1.获取父元素的指令是:parentNode2.获取元素中第一个子元素:firstChild3.获取元素中最后面的那个子元素:lastChild4.获取元素中所有的子元素:childNodes5.获取前一个兄弟元素:previousSibling6.获取后一个兄弟元素作者:康董2010-10-22。
dom的提取方法

dom的提取方法一、DOM是什么?1.1 DOM的概念。
DOM啊,就是文档对象模型(Document Object Model)的简称。
这就好比是网页的一个大地图,把网页里的各种元素,像文字、图片、链接这些啊,都当作一个个小物件放在这个地图里,每个小物件都能被找到、被操作。
它是一种让我们可以通过脚本语言(像JavaScript)来和网页交互的接口。
比如说,你看到一个网页上有个按钮,你想让这个按钮在被点击的时候变色,那就要靠DOM来找到这个按钮元素,然后对它进行操作。
1.2 DOM的重要性。
这DOM的重要性可大了去了。
它就像一把万能钥匙,能打开网页里各个元素的大门。
没有它,网页就像是一个封闭的城堡,我们只能看,不能做任何改变。
对于开发者来说,DOM就是他们施展魔法的魔杖。
就像“巧妇难为无米之炊”,没有DOM,再厉害的开发者也没法让网页变得更加生动、交互性更强。
二、DOM的提取方法。
2.1 通过标签名提取。
最常见的一种方法就是通过标签名来提取DOM元素。
比如说,网页里有好多段落(<p>标签),你想把这些段落都找出来。
那就可以使用像JavaScript里的document.getElementsByTagName('p')这样的方法。
这就像是在一群人里按照衣服颜色(这里就是标签名)来找人一样。
一下子就能把所有穿同样颜色衣服(相同标签名)的人(元素)都找出来。
不过呢,这种方法有时候可能会找出来太多元素,就像一网下去捞了好多鱼,有些可能不是你想要的。
2.2 通过类名提取。
还有一种办法是通过类名来提取。
如果网页里有些元素被设置了特定的类名,那我们就可以用这个类名来找到它们。
就好比在一个班级里,你要找那些戴眼镜的同学(这里戴眼镜就相当于类名)。
在JavaScript里可以用document.getElementsByClassName('类名')。
但是要注意哦,一个类名可能被多个元素使用,就像可能有好几个同学都戴眼镜,所以得到的结果可能是一个元素集合。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DOM
Document Object Model 文档对象模
型
Document = 文档,平面文件
Object = 对象化,将平面文件抽象Model = 模型,指从文档到对象的建模过程
查看DOM树
节点类型nodeType
●ELEMENT_NODE=1
●ATTRIBUTE_NODE=2
●TEXT_NODE=3
●COMMENT_NODE=8
●DOCUMENT_NODE=9
DOM标准总共有12种节点类型nodeType属性是只读的
节点值nodeValue
●如果给定节点是属性节点,nodeValue是
这个属性的值(读/写)
●如果给定节点是文本节点,nodeValue是
这个文本节点的值(读/写)
●如果给定节点是元素节点, nodeValue
则会返回null(只读)
创建元素节点
document.createElement(‘tagNam
e’);
此方法创建出来的新元素节点,nodeType为1,nodeName则是tagName 或者是其大写形式。
新节点没有nodeParent属性,只是存在于javascript上下文环境中的
DocumentFragment对象。
暂时还没有添加到document节点树中。
添加元素节点到节点树中
var para = document.createElement("p"); para.setAttribute("title","My paragraph"); document.body.appendChild(para);
or
var para = document.createElement("p"); document.body.appendChild(para);
para.setAttribute("title","My paragraph");
创建文本节点
var message =
document.createTextNode("hello world");
var container =
document.getElementById("intro ");
container.appendChild(message);
将会创建一个包含着文本“hello world”
的文本节点,并且追加在了id= intro的元素里面
复制节点
reference =
node.cloneNode(deep);
deep是一个boolean类型
deep==true时,新节点将包含与子节点一摸一样的节点
deep==false时,新节点的子节点将不会被复制
同样,克隆出来的节点也是一个片段,需要手工添加到dom树中
插入节点
reference =
elment.appendChild(newChild)如上所示,给定子节点newChild将成为元素节点的最后一个子节点,返回的是新增的子节点的指针
返回值多用于newChild是即时创建的时候。
移动Dom树中的节点
var message =
document.createTextNode("hello world");
var container =
document.getElementById("headli ne");
container.appendChild(message);
id=fineprint的元素先从dom树中被删除,然后作为content元素的最后一个子元素被添加到新的位置上面
前向插入节点
reference =
element.insertBefore(newNode,targetN ode)
targetNode必须是element的子节点
var container =
document.getElementById("content"); var message =
document.getElementById("fineprint"); var para =
document.createElement("p"); container.insertBefore(para,message);
删除节点
reference =
element.removeChild(node)
node节点的父节点必须是element
想删除某个节点,但又不知道它的父节点,则可以使用parentNode属性
var message =
document.getElementById("finepr int");
var container =
message.parentNode;
container.removeChild(message);
替换节点
reference =
element.replaceChild(newChild,o ldChild)
将一个给定父节点元素里面的一个子节点替换为另外一个节点
当然,该方法也可以用dom树上现有的节点替换另一个现有节点。
这时会先删除它然后再用它去替换oldChild
设置节点属性
element.setAttribute(attributeNa me,attributeValue)
这里属性的键值对必须以字符串的形式给出。
如果这个属性已经存在,则属性值会被替
换,如果没有,则系统会先创建
Attribute节点,然后再设置
查找相关
查找属性
attributeValue =
element.getAttribute(attributeN ame)
给定属性的名字必须是以字符串形式给出,返回值也是以字符串形式返回的
查找相关
查找节点
element =
document.getElementById(ID)
返回单个节点
elements =
document.getElementsByTagName(t agName)
返回节点数组。
返回只有一个元素的特殊用法
document.getElementsByTagName(tagNa
me)[0]
节点属性
●nodeName 属性名称(只读)
属性节点将返回属性名称
文本节点返回#text
元素节点返回元素名,有可能大写●nodeType属性类型
●nodeValue
dom树的遍历
●nodeList = node.childNodes
●reference = node.firstChild
reference = node.childNodes[0]
●reference = stChild
[elementNode.childNodes.length-1]●reference = node.nextSibling
●reference = node.parentNode
●reference = node.previousSibling
作业
用console.log遍历html文档。