中科院分词系统分析
小学语文实验教材词汇构成系统分析

No ., 0 6 v 20
V . 7 No 6 o1 2 .
第2 7替第 6期
小 学 语 文实验 教 材词 汇 构成 系统 分 析
陈 波
( 襄樊学院 中文 系, 湖北 襄樊 4 15 ; 403 武汉大学 语 言与信息研 究中心, 湖北 武汉 40 7 ) 30 2
摘要: 小学语文教材 自实施改革 以来, 新版本诸 多, 对其进行规 范, 势在必行 。笔者分析 了
20 新版 的人教 版 、 师大版 、 苏版 三套 教 材 的词 汇 状 况 , 用 统计 语 言 学方 法 。 “ 频 ” 03年 北 江 运 对 词
做 了新的界定, 分析 了 教材的词汇构成情况 , 并构拟 了教材的特殊词汇构成——“ 词汇构成的三 个世界” 成人世界词汇、 : 儿童世界词汇、 学术语词汇。分析结果显示: 教 三套教材 的词汇构成 比 较合理 , 基本词汇占绝大多数, 一般词汇较少; 词性构成也符合儿童认知规律。不足之处在于: 教
为了解决这些问题本课题组选取了人教版北师大版江苏版三套新版小学语文改革试验教材运用统计方法数据库方法和先进的分词软件对其词汇构成的状况进行了较为细致地考察和分析对词汇实际数据和现有的教学理论进行了详细的分析对比和思考
维普资讯
2行教学改革后 , 新版小学语文教材层出不穷 , 为数众多 , 这些教材本身是否合乎规范将对小学 生产生直接影响。这些教材 的编写者们知道一个小学生最需要掌握哪些词吗?哪些词应该最先学习?同 义词中哪一个应该首先学习, 学生最容易掌握?常用词 的哪一个义项应该 首先掌握 了解?为了解决这些 问题 , 本课题组选取了人教版、 北师大版、 江苏版三套新版小学语文改革试验教材 , 运用统计方法, 数据库 方法和先进的分词软件( 对其词汇构成的状况进行 了较为细致地考察 和分析 , 3 i , 对词汇实际数据和现有的 教学理论进行了详细的分析 、 比和思考。本文就是希望通过对词汇构成 的科学性及系统性考察 , 对 能够为 我国小学语文教材的编写提供一个可以参考 的依据 , 使我们 的小学语文教材更具科学性和系统性。
中文分词技术的研究现状与困难

四、解决方案
为了克服中文分词技术的研究困难,以下一些解决方案值得:
1、优化分词算法:针对分词算法的复杂性问题,可以尝试优化算法的设计和 实现,提高其效率和准确性。例如,可以通过引入上下文信息、利用语言学知 识等方式来改进算法。
2、改进信息检索技术:在信息检索领域,可以尝试将先进的排序算法、推荐 系统等技术引入到检索过程中,以提高检索效果。此外,还可以研究如何基于 用户行为和反馈来优化检索结果。
3、缺乏统一的评价标准:中文分词技术的评价标准尚未统一,这使得不同研 究之间的比较和评估变得困难。建立通用的中文分词技术评价标准对于推动相 关研究的发展至关重要。
4、特定领域的应用场景:中文分词技术在不同领域的应用场景中面临着不同 的挑战。例如,在金融领域中,需要分词技术对专业术语进行精确识别;在医 疗领域中,需要处理大量未登录词和生僻字。如何针对特定领域的应用场景进 行优化,是中文分词技术的重要研究方向。
3、建立大型标注语料库:通过建立大型标注语料库,可以为分词算法提供充 足的训练数据,提高其准确性和自适应性。此外,标注语料库也可以用于开发 基于规则的分词方法和测试集的构建。
4、研究跨领域的应用场景:针对不同领域的应用场景,可以研究如何将中文 分词技术进行迁移和适配。例如,可以通过知识图谱等技术将不同领域的知识 引入到分词过程中,以提高分词效果。
然而,各种分词方法也存在一定的局限性和不足。例如,基于规则的分词方法 需要人工编写规则和词典,难以维护和更新;基于统计的分词方法需要大量标 注语料库,而且训练模型的时间和计算成本较高;基于深度学习的分词方法虽 然取得了较好的效果,但也需要耗费大量的时间和计算资源进行训练。
三、研究困难
中文分词技术的研究面临着诸多困难和挑战,以下是一些主要词方法:该方法主要依靠人工编写的分词规则来进行分词。 代表性的工作包括台湾大学开发的中文分词系统“THULAC”和北京大学开发 的“PKU中文分词系统”。这些系统均基于词典和规则,具有较高的准确率和 召回率。
ICTCLAS分词系统研究
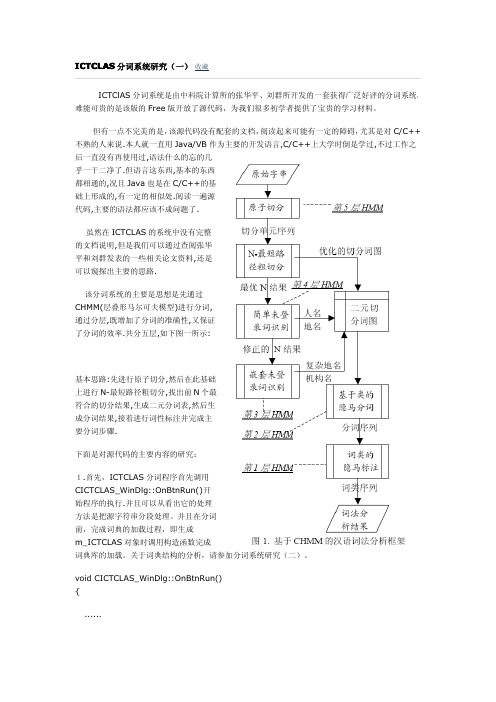
ICTClAS 分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统, 难能可贵的是该版的 Free 版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是,该源代码没有配套的文档,阅读起来可能有一定的障碍,尤其是对 C/C++ 不熟的人来说.本人就一直用 Java/VB 作为主要的开发语言,C/C++上大学时倒是学过,不过工作之 后一直没有再使用过,语法什么的忘的几 乎一干二净了.但语言这东西,基本的东西 都相通的,况且 Java 也是在 C/C++的基 础上形成的,有一定的相似处.阅读一遍源 代码,主要的语法都应该不成问题了.
void CICTCLAS_WinDlg::OnBtnRun() {
......
//在此处进行分词和词性标记
if(!m_ICTCLAS.ParagraphProcessing((char *)(LPCTSTR)m_sSource,sResult)) m_sResult.Format("错误:程序初始化异常!");
wordLen:6 frequency:0 handle:26880 word:(黯)然失色 块 6760
count:1 wordLen:2 frequency:0 handle:28160 word:(鼢)鼠
块 6761 count:2 wordLen:4 frequency:0 handle:28160 word:(鼬)鼠皮 wordLen:2 frequency:0 handle:28160 word:(鼬)獾
//对图一中所示的 6768 个数据块进行遍历 for(i=0;i<CC_NUM;i++) { pCur=NULL; if(m_pModifyTable) {
汉语词法分析系统ICTCLAS在Nutch-0.9中的应用与实现

Absr c : hi p ra a y e h i g itc a ay i tu t r fNu c whih o l e me t n s n o t a t T spa e n lz st e ln u si n l sssr c u e o th, c n y s g n sChie e i t a sn l h r c e .To s l e t s p o l m ,h p r c mbn s Ch n s e i a n lss y tm CTCL i g e c a a tr ov hi r b e t e pa e o ie i e e l xc a a y i s se I l AS
第2 0卷第 5期 20 0 8年 1 0月
军
械
工
程
学
院
学
报
Vo_ 0 . l2 No 5
J un lo d a c gn eigColg o ra fOr n n eEn ie r l e n e
0c..2 0 t 08
文章编号 :10 2 5 (0 8 5— 0 3— 4 0 8— 9 6 20 )0 0 6 0
Th e App ia in n aia in fI lc to a d Re lz to o CTCLA S o n Nuth 一0. c 9
CAIXio y n a . a , KOU n —ha , S Yi g z n HEN e , ZHEN e W i W i
me t teChn s o ds g nain T ee p rme t h wsta eC ie ewods g nainu igJ — ns h ieew r e me tt . h x ei n o h th hn s r e me tt sn a o s t o
自然语言理解-词法分析

06
词是语言中最小的能独立运用的单位,是信息处理的基本单位。
界定词的困难所在
单字词与语素之间的划界
词与短语之间的划界
汉语自动分词
把没有明显分界标志的字串自动切分为词串
06
什么是词?
背 景
汉语的特点:
汉语是大字符集的语言 英语有26个字母,而常用的汉字就有六七千个,总数超过五万 书面汉语的词与词之间没有明确的分隔标记
01
02
专有名词的识别
研 究 进 展
中文词语的分析过程:
预处理过程的词语粗切分
切分排歧与未登录词识别
词性标注 在实际的系统中,这三个过程可能相互交叉,反复融合,也可能不存在明显的先后次序
研 究 进 展
01
主要的汉语自动分词系统有:
02
北航的CDWS系统,国内公开的第一个实用性汉字分词系统,采用的自动分词方法为最大匹配法,辅助以词尾字构词检错技术,使用知识库进行纠错。
链长为6:努力学习语法规则
07
链长为7:治理解放大道路面积水
交集型歧义字段的链长
真实语料中歧义字段的分布
材料一:孙茂松等1999
材料二:刘开瑛2000,第4章
伪歧义:94%
一个1亿字真实汉语语料库中抽取出的前4,619个高频交集型歧义切分覆盖了该语料库中全部交集型歧义切分的59.20%,其中4279个属伪歧义(占92.63%,如“和软件”、“充分发挥”、“情不自禁地”),覆盖率高达53.35%。
研 究 进 展
中科院计算所的词语分析系统ICTCLAS,采用N-最短路径方法进行词语粗分(概率统计),然后用HMM的方法进行分词和标注的一体化处理。
国家语委文字所应用句法分析技术的汉语自动分词,此分词模型考虑了句法分析在自动分词系统中的作用,以更好地解决切分歧义。切词过程考虑到了所有的切分可能,并运用汉语句法等信息从各种切分可能中选择出合理的切分结果。
《人世间》语料库检索分析

《人世间》语料库检索分析作者:徐超来源:《现代交际》2020年第17期摘要:《人世间》是当代著名作家梁晓声的长篇小说。
以语料库文体学为理论基础,利用AntConc语料库检索软件和ICTCLAS汉语分词系统,通过量化的方式对小说的主人公和故事情节进行分析。
首先通过词频表分析小说的高频词,然后选定参照语料库,提取小说关键词,最后借助软件的Concordance功能分析主人公的性格特征,发现小说具有人物角色丰富、形象刻画细腻等特点,且该书与作家的其他作品之间具有很强的延续性。
关键词:《人世间》语料库 ;检索中图分类号:I06 ;文献标识码:A ;文章编号:1009-5349(2020)17-0104-03梁晓声是当代著名作家,他曾创作出版过大量的小说、散文和影视作品。
在创作过程中,知青经历带给他無限的灵感。
他的多部作品都涉及知青话题,如《这是一片神奇的土地》《今夜有暴风雪》《雪城》等。
2017年由中国青年出版社出版的《人世间》[1]是其最具影响力的长篇小说之一,该书曾获第二届吴承恩长篇小说奖,同年8月获第十届茅盾文学奖。
小说展示了北方某省会城市背景下普通工人子弟之间的亲情和友情,以及他们之间既相互影响又各自独立的人生,也描绘出中华人民共和国成立后波澜壮阔的社会巨变。
文章基于语料库,首先利用分词系统对小说的全部文本进行分词处理,然后通过AntConc 语料库检索软件进行词频统计、主题词提取并归类,分析小说的主题和情节,利用软件的索引功能对主人公“秉昆”进行检索,并对其搭配词进行整理分析,探讨主人公的个性特点。
本研究的目的在于,借助语料库检索软件,对《人世间》的文本进行量化分析,在此基础上挖掘小说在人物塑造、情节叙事等方面的特点,为该书的研究提供一个新的视角[2]。
一、理论基础虽然出版时间不长,但已有多位学者对《人世间》进行分析研究。
在中国知网中以“《人世间》”为关键词进行检索,共有论文23篇,这些研究以对书中某一人物性格特征的分析、小说的叙事方式为主,如李贵成(2019)《“永恒的女性,引领我们向上”——梁晓声〈人世间〉中的女性形象与社会变迁》、高心悦(2019)《论梁晓声〈人世间〉的情爱叙事》等。
自然语言处理中的中文分词工具推荐

自然语言处理中的中文分词工具推荐在自然语言处理(Natural Language Processing,NLP)领域中,中文分词是一个重要的任务,它将连续的中文文本切分成有意义的词语序列。
中文分词对于机器翻译、信息检索、文本分类等应用具有重要意义。
然而,中文的复杂性和歧义性使得中文分词成为一个具有挑战性的任务。
为了解决这个问题,许多中文分词工具被开发出来。
本文将推荐一些常用的中文分词工具,并对它们的特点进行简要介绍。
1. 结巴分词(jieba)结巴分词是目前最流行的中文分词工具之一。
它基于基于前缀词典和HMM模型的分词算法,具有高效、准确的特点。
结巴分词支持三种分词模式:精确模式、全模式和搜索引擎模式,可以根据具体需求选择不同的模式。
此外,结巴分词还提供了用户自定义词典的功能,可以根据特定领域的需求进行词汇扩充。
2. LTP分词(Language Technology Platform)LTP分词是由哈尔滨工业大学自然语言处理与社会人文计算实验室开发的中文分词工具。
它采用了基于统计的分词算法,具有较高的准确率和鲁棒性。
LTP分词还提供了词性标注、命名实体识别等功能,可以满足更多的自然语言处理需求。
3. THULAC(THU Lexical Analyzer for Chinese)THULAC是由清华大学自然语言处理与社会人文计算研究中心开发的一种中文词法分析工具。
它采用了一种基于词汇和统计的分词算法,具有较高的分词准确率和速度。
THULAC还提供了词性标注和命名实体识别功能,并支持用户自定义词典。
4. Stanford中文分词器Stanford中文分词器是由斯坦福大学自然语言处理小组开发的一种中文分词工具。
它使用了条件随机场(Conditional Random Fields,CRF)模型进行分词,具有较高的准确率和鲁棒性。
Stanford中文分词器还提供了词性标注和命名实体识别功能,可以满足更复杂的NLP任务需求。
中科院分词

导入其DATA文件配置文件和其它文件调用程序:package com.kingdee.eas.custom.deppon.gis.app;import ICTCLAS.I3S.AC.ICTCLAS30;import ICTCLAS.I3S.AC.Resul;import org.apache.log4j.Logger;import javax.ejb.*;import java.rmi.RemoteException;import com.kingdee.bos.*;import com.kingdee.bos.util.BOSObjectType;import com.kingdee.bos.metadata.IMetaDataPK;import com.kingdee.bos.metadata.rule.RuleExecutor;import com.kingdee.bos.metadata.MetaDataPK;//import com.kingdee.bos.metadata.entity.EntityViewInfo;import com.kingdee.bos.framework.ejb.AbstractEntityControllerBean; import com.kingdee.bos.framework.ejb.AbstractBizControllerBean; //import com.kingdee.bos.dao.IObjectPK;import com.kingdee.bos.dao.IObjectValue;import com.kingdee.bos.dao.IObjectCollection;import com.kingdee.bos.service.ServiceContext;import com.kingdee.bos.service.IServiceContext;import java.io.ByteArrayInputStream;import java.io.DataInputStream;import java.io.Serializable;import ng.String;public class WordSegmentationFacadeControllerBean extends AbstractWordSegmentationFacadeControllerBean{private static Logger logger =Logger.getLogger("com.kingdee.eas.custom.deppon.gis.app.WordSegmentationFacadeController Bean");protected Object _getKeyWord(Context ctx, String address)throws BOSException{return null;}public Object getKeyWord(Context ctx, String address) throws BOSException { Resul[] res=null;try{//String sInput = "上海市青浦区徐泾镇明路豪都国际花园";//分词//Split(sInput);//关键词提取res=KeyExtract(address);}catch (Exception ex){}return res;}public static void Split(String sInput){ try{ICTCLAS30 testICTCLAS30 = new ICTCLAS30();String argu = ".";if (testICTCLAS30.ICTCLAS_Init(argu.getBytes("GB2312")) == false){System.out.println("Init Fail!");return;}/** 设置词性标注集ID 代表词性集1 计算所一级标注集0 计算所二级标注集2 北大二级标注集3 北大一级标注集*/testICTCLAS30.ICTCLAS_SetPOSmap(2);//导入用户词典前byte nativeBytes[] = testICTCLAS30.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 1);String nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");System.out.println("未导入用户词典:" + nativeStr);//导入用户词典String sUserDict = "userdic.txt";int nCount = testICTCLAS30.ICTCLAS_ImportUserDict(sUserDict.getBytes("GB2312"));testICTCLAS30.ICTCLAS_SaveTheUsrDic();//保存用户词典System.out.println("导入个用户词:" + nCount);nativeBytes = testICTCLAS30.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 1);nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");System.out.println("导入用户词典后:" + nativeStr);//动态添加用户词String sWordUser = "973专家组组织的评测ict";testICTCLAS30.ICTCLAS_AddUserWord(sWordUser.getBytes("GB2312"));testICTCLAS30.ICTCLAS_SaveTheUsrDic();//保存用户词典nativeBytes = testICTCLAS30.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 1);nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");System.out.println("动态添加用户词后: " + nativeStr);//文件分词String argu1 = "Test.txt";String argu2 = "Test_Resul.txt";testICTCLAS30.ICTCLAS_FileProcess(argu1.getBytes("GB2312"),argu2.getBytes("GB2312"), 1);//释放分词组件资源testICTCLAS30.ICTCLAS_Exit();}catch (Exception ex){}}public static Resul[] KeyExtract(String sInput){Resul[] ResulArr = null;try{ICTCLAS30 testICTCLAS30 = new ICTCLAS30();String argu = ".";if (testICTCLAS30.ICTCLAS_Init(argu.getBytes("GB2312")) == false){System.out.println("Init Fail!");return null;}//分词高级接口byte nativeBytes[];nativeBytes = testICTCLAS30.nativeProcAPara(sInput.getBytes("GB2312"));int nativeElementSize = testICTCLAS30.ICTCLAS_GetElemLength(0);//size of Resul_t in native codeint nElement = nativeBytes.length / nativeElementSize;byte nativeBytesTmp[] = new byte[nativeBytes.length];//关键词提取int nCountKey = testICTCLAS30.ICTCLAS_KeyWord(nativeBytesTmp, nElement);ResulArr = new Resul[nCountKey];DataInputStream dis = new DataInputStream(newByteArrayInputStream(nativeBytesTmp));int iSkipNum;for (int i = 0; i < nCountKey; i++){ResulArr[i] = new Resul();ResulArr[i].start = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(1) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}ResulArr[i].length = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(2) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}dis.skipBytes(testICTCLAS30.ICTCLAS_GetElemLength(3));ResulArr[i].posId = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(4) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}ResulArr[i].wordId = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(5) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}ResulArr[i].word_type = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(6) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}ResulArr[i].weight = reverseBytes(dis.readInt());iSkipNum = testICTCLAS30.ICTCLAS_GetElemLength(7) - 4;if (iSkipNum > 0){dis.skipBytes(iSkipNum);}}dis.close();/*for (int i = 0; i < ResulArr.length; i++){System.out.println("start=" + ResulArr[i].start + ",length=" + ResulArr[i].length + "pos=" + ResulArr[i].posId + "word=" + ResulArr[i].wordId + " weight=" + ResulArr[i].weight);}*///释放分词组件资源testICTCLAS30.ICTCLAS_Exit();}catch (Exception ex){}return ResulArr;}public static void FingerPrint(String sInput){try{ICTCLAS30 testICTCLAS30 = new ICTCLAS30();String argu = ".";if (testICTCLAS30.ICTCLAS_Init(argu.getBytes("GB2312")) == false){System.out.println("Init Fail!");return;}//分词高级接口testICTCLAS30.nativeProcAPara(sInput.getBytes("GB2312"));//指纹提取long iFinger = testICTCLAS30.ICTCLAS_FingerPrint();System.out.println("finger: " + iFinger);//释放分词组件资源testICTCLAS30.ICTCLAS_Exit();}catch (Exception ex){}}public static int reverseBytes(int i){return i >>> 24 | i >> 8 & 0xff00 | i << 8 & 0xff0000 | i << 24;}}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
两天我开始看ICTCLAS的实现代码了,和吕震宇的感觉完全一样,代码真的是糟糕透顶,呵呵,非常同情吕震宇和Sinboy能够那么认真地把那些代码读完。
有了你们辛苦、认真的分析工作,让我更容易的读懂ICTCLAS的代码了,谢谢了。
阅读过程中注意到了他们分析中有些地方有点小错误。
ICTCLAS的命名好像没有正统的学过数据结构一样,对于数据结构的命名非常富有想象力,完全没有按照数据结构上大家公认的术语命名,所以给代码的读者带来很大的迷惑性。
所以我们在看名字的时候一定要抛开名字看实现,看本质,看他们到底是个啥。
呵呵。
首先就是CQueue的问题,CQueue虽然叫Queue,但是它不是FIFO的Queue。
那它是什么呢?CQueue是优先级队列Priority Queue和Stack的杂交。
但是没有半点FIFO的Queue的概念在里面。
CQueue元素有一个权重eWeight,这个权重如果不为0(或者说互相之间不等),那么CQueue 此时的含义是按照权重由小到大排序的优先级队列。
如果CQueue的所有元素的eWeight都相等,(在ICTCLAS代码里就是都为0),此时CQueue 就演变为FILO的Stack,栈。
因此这个CQueue才会有Push和Pop两种插入和删除元素的命名。
呵呵,挂着羊头卖的是狗肉,还是两只狗。
对于C#、C++、Java来说,类库里面都有现成的优先级队列和栈的实现,而且可以用List<T>重载小于号(C++)、重载CompareTo()(C#,Java)List.Sort()来代替优先级队列实现和并且具有和作者一样的Iterator的功能。
那个CQueue完全可以省略掉。
然后是Dynamic Array。
动态数组?非也。
这个是用来表示稀疏图的邻接表,每一个元素表示的是图上的一条边。
对于非稀疏的图往往喜欢用NxN的数组来表示N个节点的连接关系。
而对于稀疏图来说,无疑会浪费大量的空间,于是往往采用记录邻接两点的边的方式来记录图。
作者为了能够让以后调用的时候方便,对于起点和终点进行排序(或者说维护了顺序)。
对起点排序,就是代码中所谓的RowFirst,对于终点进行排序就是ColumnFirst。
那为何作者叫DynamicArray呢?其实也不难想象,首先是因为邻接表实际上就是边的一个列表,也可以看为数组。
但是边的数量是在变化的,而不是最开始就可以知道的。
因此这个数组是动态的。
于是就叫动态数组了。
汗。
对于DynamicArray,我们也完全可以用List<>.Sort()的方式来实现,对于C++来说,我们需要定义2个functor,分别是起点优先比较和终点优先比较。
对于Java和C#也有类似的定义比较函数的办法。
因此这个DynamicArray(),可以扔掉了。
没必要用这么一个奇怪的东西。
接下来我把NShortPath中的最主要的三个函数int Output(int **nResult,bool bBest,int *npCount);int ShortPath();void GetPaths(unsigned int nNode,unsigned int nIndex,int**nResult=0,bool bBest=false);的代码和分析帖在下面,分析都写在注释里了。
在具体开始之前,我先明确一个东西,在中科院的论文里称求解多个最优路径问题为N最短路径问题(N-Shortest Paths),如果你google你会发现没有多少有用的结果,其实不然。
不知道是不是作者不了解国际上对该问题的讨论,这个问题应该称为k shortest path(即K最短路径问题)。
这个问题也已经有了不错的解法,David Eppstein分别在1994年和1997年已经给出了大约复杂度为O(m + n log n + kn)的解法。
而中科院论文里面的解法的复杂度还是比较高的:O(n*N*k)。
(两个复杂度的字母含义不同,定义请看原论文)。
所以,如果可能,再次实现ICTCLAS的算法的朋友可以考虑抛开中科院的求k shortest path的解法,而使用国际上比较流行的解法。
BTW: 问一下,吕震宇,你有什么比较可爱点的称呼么?呵呵,我这么直呼大名在中文的习惯里似乎不太礼貌。
:)int CNShortPath::ShortPath()...{unsigned int nCurNode=1,nPreNode,i,nIndex;ELEMENT_TYPE eWeight;PARRAY_CHAIN pEdgeList;// 循环从1开始,即从第二个节点开始。
遍历所有节点。
for(;nCurNode<m_nV ertex;nCurNode++)...{CQueue queWork;// 有CNShortPath调用的上下文可知,入口的m_apCost为列优先排序的CDynamic Array。
// 换句话说就是:// list<Edge> m_apCost;// list.sort(m_apCost, less_column_first());// 下面这行代码是将该列的边的起始链表元素赋予pEdgeList,以方便遍历。
// 算法上的含义是取得图上终点为nCurNode的所有边,并将第一条边放入pEdgeList进行对所有边的遍历。
eWeight=m_apCost->GetElement(-1,nCurNode,0,&pEdgeList);//Get all the edgeswhile(pEdgeList!=0 && pEdgeList->col==nCurNode)...{// nPreNode是当前边的起点nPreNode=pEdgeList->row;// eWeight是当前边的长度eWeight=pEdgeList->value;//Get the value of edges// 对于dijkstra算法来说,我们需要知道当前节点(终点)的通过不同的前方的点到原点的距离// 并且从中知道最短的路径,然后我们会更新当前节点的父节点和当前节点到原点的距离。
// 在这个修改后的多最短路径算法中,我们将(当前节点的父节点,当前节点通过该父节点到原点的距离)视为一个配对// 我们保留一个为m_nV alueKind大小的数组,记录这些可能的配对,而不仅仅是保留最小的。
// 下面这个循环就是将所有可能的组合放到优先级队列中,然后将来可以从优先级队列中选取前m_nV alueKind。
// 这里循环范围限定到m_nV alueKind主要是考虑以后所需要的不会超过这么多个值。
// 这里放入优先级队列的是前向节点和长度,相当于是路径,而不是长度的值的列表,与后面表达的意思不同。
for(i=0;i<m_nV alueKind;i++)...{// 如果起点>0,即判断起点是不是第一个节点。
if(nPreNode>0)//Push the weight and the pre nodeinfomation...{// 起点不是第一个节点。
// 判断起点到原点的总长度在索引值为i的时候是不是无穷大。
// 如果无穷大了,就说明前一个点已经无法到达了,说明没有更多到前面节点的路径了// 也不必继续向优先级队列中放入点了。
if(m_pWeight[nPreNode-1][i]==INFINITE_V ALUE)break;// 将起点,索引值i,和终点到原点的总长度压入优先级队列。
queWork.Push(nPreNode,i,eWeight+m_pWeight[nPreNode-1][i]);}else...{// 起点为第一个节点。
// 将起点,索引值i,和当前边的长度压入优先级队列queWork.Push(nPreNode,i,eWeight);break;}}//end for// 换到下一条边。
pEdgeList=pEdgeList->next;}//end while//Now get the result queue which sort as weight.//Set the current node information// 将起点到原点的长度,对于每个索引值都初始化为无穷。
for(i=0;i<m_nV alueKind;i++)...{m_pWeight[nCurNode-1][i]=INFINITE_V ALUE;}//memset((void *),(int),sizeof(ELEMENT_TYPE)*);//init the weighti=0;// 进行循环,索引值小于想要的索引值时,并且优先级队列不为空。
// 在这里面的i表达的是长度的值的索引,并不代表不同的路径,同一个i 可能对应多个路径。
// 这个循环过后,m_pWeight[nCurNode-1][] 为可能存在的前m_nV alueKind 个长度值。
// 并且把前m_nV alueKind个路径压入m_nParent对应的队列中。
//while(i<m_nV alueKind&&queWork.Pop(&nPreNode,&nIndex,&eWeight)!=-1)...{//Set the current node weight and parent// 从以长度为优先级的队列中,提取第一个(最短的)记录。
// 将该记录的起点给nPreNode,索引给nIndex,长度给eWeight// 如果起点到原点的长度为无穷。
(这在第一次循环的时候显然是无穷)// 就将这个长度设为最短边的长度。
if(m_pWeight[nCurNode-1][i]==INFINITE_V ALUE)m_pWeight[nCurNode-1][i]=eWeight;else if(m_pWeight[nCurNode-1][i]<eWeight)//Next queue...{// 否则,如果起点到原点的长度小于当前边的长度// 递增索引值,换到下一套选择值去。
如果到达了最大索引值就退出循环。
i++;//Go next queue and record next weight// 既然这里有是否会大于最大索引值的判断,何必在while条件里面加那个条件呢?if(i==m_nV alueKind)//Get the last positionbreak;// 将起点到原点的长度,下一个索引值(i+1),设为队列中元素的长度。
m_pWeight[nCurNode-1][i]=eWeight;}else...{// 如果起点到原点的长度== 队列中的长度,那么只向当前节点,当前索引的父节点中插入一个配对。