java 基础知识之hadoop源码阅读必备(一)
Hadoop源代码分析_之hadoop配置及启动(1)-----classpath与配置文件
* strings. If no such property is specified, then <code>null</code> * is returned. Values are whitespace or comma delimted. */ public String[] getStrings(String name) {
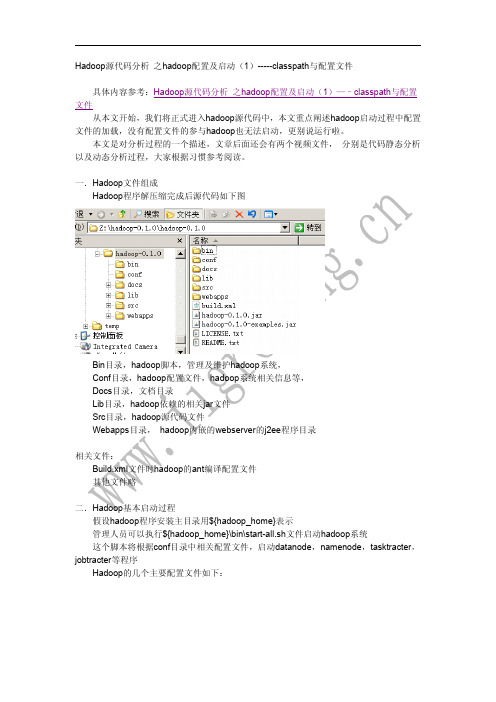
我们打开hadoop的源代码项目(eclipse的java项目)
如下图,我们打开如上目录及java源代码文件
双击左侧 main函数的节点, 然后右面显示相关源代码, 然后在 “runAndWait(new Configuration());”函数调用处,右击鼠标,弹出相关对话框,选择“open Declaration” 选项, 可以直接使用快捷方式 F3按键,可以快速到达相关源代码处 代码如下: private static void runAndWait(Configuration conf) throws IOException {
String valueString = get(name); // 重点语句,负责初始化相关代码,我们需要跟踪进入相 关代码
if (valueString == null) return null;
StringTokenizer tokenizer = new StringTokenizer (valueString,", \t\n\r\f"); List values = new ArrayList(); while (tokenizer.hasMoreTokens()) {
一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)

⼀起学Hadoop——使⽤IDEA编写第⼀个MapReduce程序(Java和Python)上⼀篇我们学习了MapReduce的原理,今天我们使⽤代码来加深对MapReduce原理的理解。
wordcount是Hadoop⼊门的经典例⼦,我们也不能免俗,也使⽤这个例⼦作为学习Hadoop的第⼀个程序。
本⽂将介绍使⽤java和python编写第⼀个MapReduce程序。
本⽂使⽤Idea2018开发⼯具开发第⼀个Hadoop程序。
使⽤的编程语⾔是Java。
打开idea,新建⼀个⼯程,如下图所⽰:在弹出新建⼯程的界⾯选择Java,接着选择SDK,⼀般默认即可,点击“Next”按钮,如下图:在弹出的选择创建项⽬的模板页⾯,不做任何操作,直接点击“Next”按钮。
输⼊项⽬名称,点击Finish,就完成了创建新项⽬的⼯作,我们的项⽬名称为:WordCount。
如下图所⽰:添加依赖jar包,和Eclipse⼀样,要给项⽬添加相关依赖包,否则会出错。
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所⽰:依次点击Modules和Dependencies,然后选择“+”的符号,如下图所⽰:选择hadoop的包,我⽤得是hadoop2.6.1。
把下⾯的依赖包都加⼊到⼯程中,否则会出现某个类找不到的错误。
(1)”/usr/local/hadoop/share/hadoop/common”⽬录下的hadoop-common-2.6.1.jar和haoop-nfs-2.6.1.jar;(2)/usr/local/hadoop/share/hadoop/common/lib”⽬录下的所有JAR包;(3)“/usr/local/hadoop/share/hadoop/hdfs”⽬录下的haoop-hdfs-2.6.1.jar和haoop-hdfs-nfs-2.7.1.jar;(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”⽬录下的所有JAR包。
hadoop源码编译

hadoop源码编译Hadoop是目前最流行的分布式计算框架之一,广泛应用于大数据领域。
为了更好地理解Hadoop的内部运行机制,我们有时需要对其源码进行深入研究和编译。
下面就来一步步讲解如何编译Hadoop源码。
一、环境准备在开始编译Hadoop源码之前,需要安装一些必备的软件和环境。
首先要确保已经安装了Java JDK和Maven,其中Java JDK的版本应该至少是1.7或1.8,而Maven则需要3.0以上的版本。
其次需要安装SSH,这是Hadoop用于节点之间通信和管理的必备组件。
最后需要下载Hadoop源码压缩包,解压到本地文件夹。
二、修改配置文件在进行编译过程之前,还需要修改一些Hadoop的配置文件。
具体来说,需要先修改pom.xml文件中的Hadoop版本号,确保与本地安装的版本一致。
然后需要修改hadoop-common-project/hadoop-common/src/main/conf/hadoop-metrics2.properties文件中的hostname值,确保与你当前的主机名一致。
三、编译源码当所有环境准备工作完成后,就可以开始编译Hadoop源码了。
首先需要在hadoop源码文件夹下运行以下命令,生成configure脚本:$ ./bootstrap.sh接着需要执行configure命令,生成Makefile:$ ./configure这个命令会检查编译环境,并根据环境配置参数。
最后,你需要执行make命令来编译Hadoop源码:$ mvn package -Pdist,native -DskipTests -Dtar以上命令会编译生成Hadoop发布版本,并将所有生成的二进制文件打成一个.tar包。
编译过程需要一定的时间,具体取决于你的电脑性能和网络速度。
四、启动HadoopHadoop源码编译完成之后,就可以启动它了。
首先需要将生成的.tar包解压到一个文件夹中:$ tar xf hadoop-x.x.x.tar.gz然后使用以下命令添加环境变量:$ export HADOOP_HOME=/path/to/hadoop-x.x.x$ export PATH=$PATH:$HADOOP_HOME/bin至此,Hadoop就已经编译成功并且可以在本地运行了。
hadoop原理及组件

hadoop原理及组件Hadoop是一个开源的分布式计算框架,旨在处理大规模数据集。
它提供了一个可靠、高效和可扩展的基础设施,用于存储、处理和分析数据。
本篇文章将详细介绍Hadoop的原理以及其核心组件。
一、Hadoop原理Hadoop的核心原理包括数据分布式存储、数据切分、数据复制和数据计算等。
首先,Hadoop使用HDFS(分布式文件系统)进行数据存储,支持大规模数据的存储和读取。
其次,Hadoop采用了MapReduce 模型对数据进行分布式计算,通过将数据切分为小块进行处理,从而实现高效的计算。
此外,Hadoop还提供了Hive、HBase等组件,以支持数据查询和分析等功能。
二、Hadoop核心组件1.HDFS(Hadoop分布式文件系统)HDFS是Hadoop的核心组件之一,用于存储和读取大规模数据。
它支持多节点集群,能够提供高可用性和数据可靠性。
在HDFS中,数据被分成块并存储在多个节点上,提高了数据的可靠性和可用性。
2.MapReduceMapReduce是Hadoop的另一个核心组件,用于处理大规模数据集。
它采用分而治之的策略,将数据集切分为小块,并分配给集群中的多个节点进行处理。
Map阶段将数据集分解为键值对,Reduce阶段则对键值对进行聚合和处理。
通过MapReduce模型,Hadoop能够实现高效的分布式计算。
3.YARN(资源调度器)YARN是Hadoop的另一个核心组件,用于管理和调度集群资源。
它提供了一个统一的资源管理框架,能够支持多种应用类型(如MapReduce、Spark等)。
YARN通过将资源分配和管理与应用程序解耦,实现了资源的灵活性和可扩展性。
4.HBaseHBase是Hadoop中的一个列式存储系统,用于大规模结构化数据的存储和分析。
它采用分布式架构,支持高并发读写和低延迟查询。
HBase与HDFS紧密集成,能够快速检索和分析大规模数据集。
5.Pig和HivePig和Hive是Hadoop生态系统中的两个重要组件,分别用于数据管道化和数据仓库的构建和管理。
Hadoop源代码eclipse编译教程

源代码eclipse编译教程一见/hadoopor@1.下载Hadoop源代码Hadoop各成员源代码下载地址:/repos/asf/hadoop,请使用SVN 下载,在SVN浏览器中将trunk目录下的源代码check-out出来即可:请注意只check-out出SVN上的trunk目录下的内容,如:/repos/asf/hadoop/common/trunk,而不是/repos/asf/hadoop/common,原因是/repos/asf/hadoop/common目录下包括了很多非源代码文件,并且很庞大,会导致需要很长的check-out时间。
建议组织成如下图所示的目录结构,以保持本地的目录结构和SVN上的目录结构一致:2.准备编译环境2.1.Hadoop代码版本本教程所采用的Hadoop是北京时间2009-8-26日上午下载的源代码,和hadoop-0.19.x 版本的差异可能较大。
2.2.联网编译Hadoop会依赖很多第三方库,但编译工具Ant会自动从网上下载缺少的库,所以必须保证机器能够访问Internet。
2.3.java编译Hadoop要求使用1.6或更新的JDK,可以从:/javase/downloads/index.jsp上下载JDK。
安装好之后,请设置好JAVA_HOME环境变量,如下图所示:2.4.Ant和Cygwin需要使用Ant工具来编译Hadoop,而Ant需要使用到Cygwin提供的一些工具,如sed 等,可以从:/ivy/download.cgi下载Ant,从/下载Cygwin(Cygwin的安装,请参考《在Windows上安装Hadoop教程》一文)。
安装好之后,需要将Ant和Cygwin的bin目录加入到环境变量PATH中,如下图所示:在安装Cygwin时,建议将SVN安装上,因为在Ant编译过程中会通过SVN下载些文件,但这个不是必须的,下载不成功时,并未见出错,编译仍然可以成功。
Hadoop基础入门指南

Hadoop基础入门指南Hadoop是一个基于Java的开源分布式计算平台,能够处理大规模数据存储和处理任务。
它是处理大数据的一种解决方案,被广泛应用于各种领域,例如金融、医疗、社交媒体等。
本文将介绍Hadoop的基础知识,帮助初学者快速入门。
一、Hadoop的三大模块Hadoop有三个核心模块,分别是HDFS(Hadoop分布式文件系统)、MapReduce、和YARN。
1. HDFS(Hadoop分布式文件系统)HDFS是Hadoop的存储模块,它可以存储大量的数据,并在多台机器之间进行分布式存储和数据备份。
HDFS将文件切割成固定大小的块,并复制多份副本,存储在不同的服务器上。
如果某个服务器宕机,数据仍然可以从其他服务器中获取,保障数据的安全。
2. MapReduceMapReduce是Hadoop的计算模块,它可以对存储在HDFS上的大量数据进行分布式处理。
MapReduce模型将大数据集划分成小数据块,并行处理这些小数据块,最后将结果归并。
MapReduce模型包含两个阶段:Map阶段和Reduce阶段。
Map阶段:将输入的大数据集划分成小数据块,并将每个数据块分配给不同的Map任务处理。
每个Map任务对数据块进行处理,并生成键值对,输出给Reduce任务。
Reduce阶段:对每个键值对进行归并排序,并将具有相同键的一组值传递给Reduce任务,进行汇总和计算。
3. YARNYARN是Hadoop的资源管理器,它负责分配和管理Hadoop集群中的计算资源。
YARN包含两个关键组件:ResourceManager和NodeManager。
ResourceManager:管理整个集群的资源,包括内存、CPU等。
NodeManager:运行在每个计算节点上,负责监控本地计算资源使用情况,并与ResourceManager通信以请求或释放资源。
二、Hadoop的安装与配置在开始使用Hadoop之前,需要进行安装和配置。
Hadoop源码分析

Hadoop源代码分析于泓烈 200921060171一、引言一个分布式系统基础架构,有Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
下面列举hadoop主要的一些特点:(1)扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
(2)成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。
这些服务器群总计可达数千个节点。
(3)高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
(4)可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
二、NameNode和DataNode介绍一个典型的HDFS系统包括一个NameNode和多个DataNode。
NameNode维护名字空间;而DataNode存储数据块。
DataNode负责存储数据,一个数据块在多个DataNode中有备份;而一个DataNode对于一个块最多只包含一个备份。
所以我们可以简单地认为DataNode上存了数据块ID和数据块内容,以及他们的映射关系。
hadoop源码_hdfs启动流程_1_NameNode

hadoop源码_hdfs启动流程_1_NameNode执⾏start-dfs.sh脚本后,集群是如何启动的?本⽂阅读并注释了start-dfs脚本,以及namenode和datanode的启动主要流程流程源码。
阅读源码前准备源码获取拉取Apache Hadoop官⽅源码⽤idea打开...切换到想看的版本...这⾥⽤的最新版本3.3.1阅读⽬标本篇的阅读⽬标是搞明⽩hadoop中的start-dfs.sh启动脚本执⾏后都做了什么,hadoop中的NameNode,DataNode启动过程等⼤致流程,不会细追细节。
start-dfs.sh ⼲了什么hdfs集群的启动命令为:start-dfs.sh, 脚本的位置在下图中:![image-脚本中⼤致分位两块内容,第⼀部分是调⽤hdfs-config.sh脚本配置hdfs以及hadoop的参数以及环境等,第⼆部分是启动datanode、namenode以及secondary namenode等等。
我们的重点是看第⼆部分的启动流程。
hdfs-config 简述start-dfs.sh中启动hdfs-config.sh的代码如下:# let's locate libexec...if [[ -n "${HADOOP_HOME}" ]]; thenHADOOP_DEFAULT_LIBEXEC_DIR="${HADOOP_HOME}/libexec"elseHADOOP_DEFAULT_LIBEXEC_DIR="${bin}/../libexec"fiHADOOP_LIBEXEC_DIR="${HADOOP_LIBEXEC_DIR:-$HADOOP_DEFAULT_LIBEXEC_DIR}"# shellcheck disable=SC2034HADOOP_NEW_CONFIG=trueif [[ -f "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh"elseecho "ERROR: Cannot execute ${HADOOP_LIBEXEC_DIR}/hdfs-config.sh." 2>&1exit 1fi在hdfs-config.sh脚本中会尝试启动hdfs-evn.sh脚本(如果存在)之后会检查以及设置HDFS的各种参数,例如:# turn on the defaultsexport HDFS_AUDIT_LOGGER=${HDFS_AUDIT_LOGGER:-INFO,NullAppender}export HDFS_NAMENODE_OPTS=${HDFS_NAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_SECONDARYNAMENODE_OPTS=${HDFS_SECONDARYNAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_DATANODE_OPTS=${HDFS_DATANODE_OPTS:-"-Dhadoop.security.logger=ERROR,RFAS"}export HDFS_PORTMAP_OPTS=${HDFS_PORTMAP_OPTS:-"-Xmx512m"}# depending upon what is being used to start Java, these may need to be# set empty. (thus no colon)export HDFS_DATANODE_SECURE_EXTRA_OPTS=${HDFS_DATANODE_SECURE_EXTRA_OPTS-"-jvm server"}export HDFS_NFS3_SECURE_EXTRA_OPTS=${HDFS_NFS3_SECURE_EXTRA_OPTS-"-jvm server"}再之后会启动hadoop-config.sh脚本:# shellcheck source=./hadoop-common-project/hadoop-common/src/main/bin/hadoop-config.shif [[ -n "${HADOOP_COMMON_HOME}" ]] &&[[ -e "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh" ]]; then. "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh"elif [[ -e "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh"elif [ -e "${HADOOP_HOME}/libexec/hadoop-config.sh" ]; then. "${HADOOP_HOME}/libexec/hadoop-config.sh"elseecho "ERROR: Hadoop common not found." 2>&1exit 1fihadoop-config.sh是最基本的、公⽤的环境变量配置脚本,会再调⽤etc/hadoop/hadoop-env.sh脚本。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
java 程序员你真的懂java吗?
一起来看下hadoop中的如何去使用java的
大数据是目前IT技术中最火热的话题,也是未来的行业方向,越来越多的人参与到大数据的学习行列中。
从最基础的伪分布式环境搭建,再到分布式环境搭建,再进入代码的编写工作。
这时候码农和大牛的分界点已经出现了,所谓的码农就是你让我做什么我就做什么,我只负责实现,不管原理,也不想知道原理。
大牛就开始不听的问自己why?why?why?于是乎,很自然的去看源码了。
然而像hadoop这样的源码N多人参与了修改和完善,看起来非常的吃力。
然后不管如何大牛就是大牛,再硬的骨头也要啃。
目前做大数据的80%都是从WEB开发转变过来的,什么spring mvc框架、SSH框架非常熟悉,其实不管你做了多少年的WEB开发,你很少接触到hadoop中java代码编写的风格,有些人根本就看不懂什么意思。
下面我来介绍下hadoop源码怎么看。
hadoop体现的是分布式框架,因此所有的通信都基于RPC来操作,关于RPC的操作后续再介绍。
hadoop源码怎么看系列分多个阶段介绍,下面重点介绍下JA V A基础知识。
一、多线程编程
在hadoop源码中,我们能看到大量的类似这样的代码
return executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
//方法类
}
下面简单介绍下java的多线程编程
启动一个线程可以使用下列几种方式
1、创建一个Runnable,来调度,返回结果为空。
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(new Runnable() {
@Override
public void run() {
System.out.println("runnable1 running.");
}
});
这种方式启动一个线程后,在后台运行,不用等到结果,因为也不会返回结果
2、创建一个Callable,来调度,有返回结果
Future<String> future1 = executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
// TODO Auto-generated method stub
//具体执行一些内部操作
return "返回结果了!";
}
});
System.out.println("task1: " + future1.get());
这种启动方式一直等到call的方法体执行完毕后,并返回结果了才继续执行下面的代码二、内部类实现
hadoop中同样能看到大量这样形式的代码
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
这是一个典型的内部类实现,PrivilegedExceptionAction是一个接口,里面有一个run方法需要实现,程序调用的时候,会执行里面的submitter.submitJobInternal方法体
为了方便大家理解,我写了一个模拟程序来演示
先定义一个接口类
public interface TransactionAction {
void execute() throws Exception;
}
再定义一些模板方法,参数对象是一个接口来处理相关业务
public class TemplateAction {
public void transactionProcess(TransactionAction action, ActionEvent event){
System.out.println("lock");
try {
action.execute();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("unlock");
}
}
调用过程
public void doSome(){
TemplateAction t=new TemplateAction();
//public void transactionProcess(TransactionAction action, ActionEvent event)
event2 =new ActionEvent ();
event2.setMsg("内部类");
final DoAction doaction=new DoAction();
t.transactionProcess(new TransactionAction() {
@Override
public void execute() throws Exception {
// TODO Auto-generated method stub
doaction.sayWhatEvent(event2);
}
}, new ActionEvent());
}
运行结果如下:
lock
say:内部类
unlock
上面的内部类执行过程很明确,到底execute何时执行不是由dosome来设定,而是由TemplateAction中的transactionProcess来确定
三、枚举类型
枚举类型比较容易理解,例如在我们习惯定义一些常量,
static int ACTION_TYPE=0; //0表示初始,1表示启动,2表示运行中3表示停止
程序中我们这样判断
if(ACTION_TYPE==1){
doSomeThing()
}
例如:
// TODO Auto-generated method stub
JobState state = JobState.DEFINE;
if(state==JobState.RUNNING){
System.out.println("运行状态");
}else{
System.out.println("初始状态");
}
if(jobType==0){
System.out.println("初始状态");
}else if(jobType==1){
System.out.println("启动状态");
}。