中南大学编译原理实验报告
编译原理实验报告

编译原理实验报告一、实验目的和要求本次实验旨在对PL_0语言进行功能扩充,添加新的语法特性,进一步提高编译器的功能和实用性。
具体要求如下:1.扩展PL_0语言的语法规则,添加新的语法特性;2.实现对新语法的词法分析和语法分析功能;3.对扩展语法规则进行语义分析,并生成中间代码;4.验证扩展功能的正确性。
二、实验内容1.扩展语法规则本次实验选择扩展PL_0语言的语句部分,添加新的控制语句,switch语句。
其语法规则如下:<switch_stmt> -> SWITCH <expression> CASE <case_list><default_stmt> ENDSWITCH<case_list> -> <case_stmt> , <case_stmt> <case_list><case_stmt> -> CASE <constant> : <statement><default_stmt> -> DEFAULT : <statement> ,ε2.词法分析和语法分析根据扩展的语法规则,需要对新的关键字和符号进行词法分析,识别出符号类型和记号类型。
然后进行语法分析,建立语法树。
3.语义分析在语义分析阶段,首先对switch语句的表达式进行求值,判断其类型是否为整型。
然后对case语句和default语句中的常量进行求值,判断是否与表达式的值相等。
最后将语句部分生成中间代码。
4.中间代码生成根据语法树和语义分析的结果,生成对应的中间代码。
例如,生成switch语句的跳转表,根据表达式的值选择相应的跳转目标。
5.验证功能的正确性设计一些测试用例,验证新语法的正确性和扩展功能的实用性。
三、实验步骤与结果1.扩展语法规则,更新PL_0语法分析器的词法规则和语法规则。
中南大学编译原理实验报告

实验1《词法分析程序设计与实现》实验学时: 4 实验地点:二综实验日期:一、实验目的加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析二、实验内容自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。
词法分析程序的实现可以采用任何一种编程语言和编程工具。
从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)三、实验方法用java或者C语言写出分析器四、实验步骤1.定义目标语言的可用符号表和构词规则;2.依次读入源程序符号,对源程序进行单词切分和识别,直到源程序结束;3.对正确的单词,按照它的种别以<种别码,值>的形式保存在符号表中;对不正确的单词,做出错误处理五、实验结果定义种别码final int NONE = 0;final int DELIMITER = 1; // 操作符运算符final int VAR = 2; // 字符变量final int Num = 3; // 数字final int COMMAND = 4; // 关键字// final int QUOTEDSTR=5; //带引号的字符串// 程序终结符end of programfinal String EOP = "#";// 声明关键字final int unKnowKeyword = 0;final int FI = 1;final int IF = 2;final int THEN = 3;final int WHILE = 4;final int DO = 5;final int END = 6;final int ELSE = 7;final int TO = 8;final int READ = 9;final int WRITE = 10;final int EOL = 11;六、实验结论由文件读入和控制台输出,良好的控制了要解析的句子过长的麻烦,实验结果也符合预期七、实验小结完成了词法编译器,很好的了解了底层编译过程中的词法分析关键代码:main.javapackage cn.main;import java.io.BufferedInputStream;import java.io.BufferedReader;import java.io.InputStreamReader;import cn.method.*;class Main{public static void main(String args[]){BufferedReader br =new BufferedReader(newInputStreamReader(System.in));try {System.out.println("请输入你要解析的文件");String filename=br.readLine();filename="src/cn/file/"+filename;CharacterAnalysis ob = new CharacterAnalysis(filename);ob.scanDisegn();} catch(Exception e) {}}}CharacterAnalysis.javapackage cn.method;import java.io.BufferedReader;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;public class CharacterAnalysis {// 声明处理字符的类型final int NONE = 0;final int DELIMITER = 1; // 操作符运算符final int VAR = 2; // 字符变量final int Num = 3; // 数字final int COMMAND = 4; // 关键字// final int QUOTEDSTR=5; //带引号的字符串// 程序终结符end of programfinal String EOP = "#";// 声明关键字final int unKnowKeyword = 0;final int FI = 1;final int IF = 2;final int THEN = 3;final int WHILE = 4;final int DO = 5;final int END = 6;final int ELSE = 7;final int TO = 8;final int READ = 9;final int WRITE = 10;final int EOL = 11;private char[] prog;private int progIdx;private String token;private int tokType;private int kwToken;final int PROG_SIZE = 100000;// 将关键字的外部表示,和内部表示保存在一个名为KwTable的表中Keyword kwTable[] = { new Keyword("fi", FI), new Keyword("if", IF), new Keyword("then", THEN), new Keyword("while", WHILE),new Keyword("do", DO), new Keyword("end", END),new Keyword("else", ELSE), new Keyword("to", TO),new Keyword("read", READ), new Keyword("write", WRITE) };public CharacterAnalysis(String programName) throws IOException { char tempbuf[] = new char[PROG_SIZE];int size;size = loadProgram(tempbuf, programName);if (size != -1) {prog = new char[size];System.arraycopy(tempbuf, 0, prog, 0, size);}}// 读入一个需要分析的程序private int loadProgram(char[] p, String fname) throws IOException { int size = 0;try {FileReader fr = new FileReader(fname);BufferedReader br = new BufferedReader(fr);size = br.read(p, 0, PROG_SIZE);fr.close();} catch (FileNotFoundException exc) {System.out.print("没有找到该文件!");}if (p[size - 1] == (char) 31)size--;return size;}// 分析程序代码private void getToken() throws IOException {tokType = NONE;token = "";kwToken = unKnowKeyword;if (progIdx == prog.length) {token = EOP;return;}// 跳过空格符while (progIdx < prog.length && isSpaceOrTab(prog[progIdx])) progIdx++;// handle crlfif (prog[progIdx] == '\r') {progIdx += 2;kwToken = EOL;token = "\r\n";return;}// 扫描完所有的字符,end programif (progIdx == prog.length) {if (progIdx == prog.length) {token = EOP;tokType = DELIMITER;return;}}if (isDelim(prog[progIdx])) {// 是一个操作符,或者是运算符token += prog[progIdx];progIdx++;// if(progIdx>=prog.length)break;tokType = DELIMITER;} else if (Character.isLetter(prog[progIdx])) {// 是一个字符变量while (!isDelim(prog[progIdx])) {token += prog[progIdx];progIdx++;if (progIdx >= prog.length)break;}kwToken = lookUp(token);// 如果是字符变量,用var标记,否则是关键字,用command标记if (kwToken == unKnowKeyword)tokType = VAR;elsetokType = COMMAND;} else if (Character.isDigit(prog[progIdx])) {// 是一个数字字符while (!isDelim(prog[progIdx])) {token += prog[progIdx];progIdx++;if (progIdx >= prog.length)break;}tokType = Num;}}// 判断字符是否是操作符private boolean isDelim(char c) {if (("\r, +-*/:<>=();".indexOf(c) != -1))return true;return false;}boolean isSpaceOrTab(char c) {if (c == ' ' || c == '\t')return true;return false;}// 查找字符串是否为关键字private int lookUp(String s) {int i;// Convert to lowercase.s = s.toLowerCase();// 查找字符串是否为关键字for (i = 0; i < kwTable.length; i++)if (kwTable[i].keyword.equals(s))return kwTable[i].keywordindex;return unKnowKeyword; // 不是一个关键字}// 对代码进行输出处理public void scanDisegn() throws IOException {// 对代码扫描do {getToken();// 扫描到字符是变量if (tokType == VAR) {System.out.println(token + " " + "29");}// 扫描到字符是关键字else if (tokType == COMMAND) {switch (kwToken) {case FI:System.out.println("fi" + " " + "1");break;case IF:System.out.println("if" + " " + "2");break;case THEN:System.out.println("then" + " " + "3");break;case WHILE:System.out.println("while" + " " + "4");break;case DO:System.out.println("do" + " " + "5");break;case END:System.out.println("end" + " " + "6");break;case ELSE:System.out.println("else" + " " + "7");break;case TO:System.out.println("to" + " " + "8");break;case READ:System.out.println("read" + " " + "9");break;case WRITE:System.out.println("write" + " " + "10");break;}}// 扫描到字符是数字else if (tokType == Num) {System.out.println(token + " " + "28");}// 扫描到字符是操作符else if (tokType == DELIMITER) {if (token.equals("+"))System.out.println(token + " " + "14");if (token.equals("-"))System.out.println(token + " " + "15");if (token.equals("*"))System.out.println(token + " " + "16");if (token.equals("/"))System.out.println(token + " " + "17");if (token.equals(":="))System.out.println(token + " " + "18");if (token.equals("<"))System.out.println(token + " " + "20");if (token.equals("<>"))System.out.println(token + " " + "21");if (token.equals("<="))System.out.println(token + " " + "22");if (token.equals(">"))System.out.println(token + " " + "23");if (token.equals(">="))System.out.println(token + " " + "24");if (token.equals("="))System.out.println(token + " " + "25");if (token.equals(";"))System.out.println(token + " " + "26");if (token.equals("("))System.out.println(token + " " + "27");if (token.equals(")"))System.out.println(token + " " + "28");}} while (!token.equals(EOP));System.out.println("#" + " " + "30");System.out.println("程序分析完毕");}}Keyword.javapackage cn.method;public class Keyword {String keyword;int keywordindex;Keyword(String str,int t){keyword=str;keywordindex=t;}}实验二预测分析法设计与实现一、实验目的加深对语法分析器工作过程的理解;加强对预测分析法实现语法分析程序的掌握;能够采用一种编程语言实现简单的语法分析程序;能够使用自己编写的分析程序对简单的程序段进行语法翻译。
编译原理实验报告

编译原理实验报告班级姓名:学号:自我评定:实验一词法分析程序实现一、实验目的与要求通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。
二、实验内容根据教学要求并结合学生自己的兴趣和具体情况,从具有代表性的高级程序设计语言的各类典型单词中,选取一个适当大小的子集。
例如,可以完成无符号常数这一类典型单词的识别后,再完成一个尽可能兼顾到各种常数、关键字、标识符和各种运算符的扫描器的设计和实现。
输入:由符合或不符合所规定的单词类别结构的各类单词组成的源程序。
输出:把单词的字符形式的表示翻译成编译器的内部表示,即确定单词串的输出形式。
例如,所输出的每一单词均按形如(CLASS,VALUE)的二元式编码。
对于变量和常数,CLASS字段为相应的类别码;VALUE字段则是该标识符、常数的具体值或在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符串;常数表登记项中则存放该常数的二进制形式)。
对于关键字和运算符,采用一词一类的编码形式;由于采用一词一类的编码方式,所以仅需在二元式的CLASS字段上放置相应的单词的类别码,VALUE字段则为“空”。
另外,为便于查看由词法分析程序所输出的单词串,要求在CLASS字段上放置单词类别的助记符。
三、实现方法与环境词法分析是编译程序的第一个处理阶段,可以通过两种途径来构造词法分析程序。
其一是根据对语言中各类单词的某种描述或定义(如BNF),用手工的方式(例如可用C语言)构造词法分析程序。
一般地,可以根据文法或状态转换图构造相应的状态矩阵,该状态矩阵同控制程序便组成了编译器的词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。
构造词法分析程序的另外一种途径是所谓的词法分析程序的自动生成,即首先用正规式对语言中的各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程序所应进行的语义处理工作,然后由一个所谓词法分析程序的构造程序对上述信息进行加工。
编译原理实验报告

编译原理实验报告一、实验概述本次实验旨在设计并实现一个简单的词法分析器,即实现编译器的第一个阶段,词法分析。
词法分析器将一段源程序代码作为输入,将其划分为一个个的词法单元,并将其作为输出。
二、实验过程1.设计词法规则根据编程语言的规范和所需实现的功能,设计词法规则,以明确规定如何将源程序代码分解为一系列的词法单元。
2.实现词法分析器采用合适的编程语言,根据所设计的词法规则,实现词法分析器。
词法分析器的主要任务是读入源程序代码,并将其根据词法规则进行分解,生成对应的词法单元。
3.测试词法分析器设计测试用例,用于检验词法分析器的正确性和性能。
测试用例应包含各种情况下的源程序代码。
4.分析和修正错误根据测试过程中发现的问题,分析产生错误的原因,并进行修正。
重复测试和修正的过程,直到词法分析器能够正确处理所有测试用例。
三、实验结果我们设计了一个简单的词法分析器,并进行了测试。
测试用例涵盖了各种情况下的源程序代码,包括正确的代码和错误的代码。
经过测试,词法分析器能够正确处理所有的测试用例。
词法分析器将源程序代码分解为一系列的词法单元,每个词法单元包含了单词的种类和对应的值。
通过对词法单元的分析,可以进一步进行语法分析和语义分析,从而完成编译过程。
四、实验总结通过本次实验,我深入了解了编译原理的词法分析阶段。
词法分析是编译器的第一个重要阶段,它将源程序代码分解为一个个的词法单元,为后续的语法分析和语义分析提供基础。
在实现词法分析器的过程中,我学会了如何根据词法规则设计词法分析器的算法,并使用编程语言实现词法分析器。
通过测试和修正,我掌握了调试和错误修复的技巧。
本次实验的经验对我今后的编程工作有很大帮助。
编译原理是计算机科学与技术专业的核心课程之一,通过实践能够更好地理解和掌握其中的概念和技术。
我相信通过进一步的学习和实践,我能够在编译原理领域取得更大的成果。
编译原理实验报告

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。
编译原理实验报告

编译原理实验报告编译原理实验报告一、实验目的1. 了解编译器的基本原理和工作过程;2. 掌握编译器设计和实现的基本方法和技巧;3. 通过设计和实现一个简单的编译器,加深对编程语言和计算机系统的理解和认识。
二、实验原理编译器是将高级语言程序翻译成机器语言程序的一种软件工具。
它由编译程序、汇编程序、链接程序等几个阶段组成。
本次实验主要涉及到的是编译程序的设计和实现。
编译程序的基本原理是将高级语言程序转换为中间代码,再将中间代码转换为目标代码。
整个过程可以分为词法分析、语法分析、语义分析、代码生成和代码优化几个阶段。
三、实验内容本次实验的设计目标是实现一个简单的四则运算表达式的编译器。
1. 词法分析根据规定的语法规则,编写正则表达式将输入的字符串进行词法分析,将输入的四则运算表达式划分成若干个单词(Token),例如:运算符、操作数等。
2. 语法分析根据定义的语法规则,编写语法分析程序,将词法分析得到的Token序列还原成语法结构,构建抽象语法树(AST)。
3. 语义分析对AST进行遍历,进行语义分析,判断表达式是否符合语法规则,检查语义错误并给出相应的提示。
4. 代码生成根据AST生成目标代码,目标代码可以是汇编代码或者机器码。
四、实验过程和结果1. 首先,根据输入的表达式,进行词法分析。
根据所定义的正则表达式,将输入的字符串划分成Token序列。
例如:输入表达式“2+3”,经过词法分析得到的Token序列为["2", "+", "3"]。
2. 然后,根据语法规则,进行语法分析。
根据输入的Token序列,构建抽象语法树。
3. 接着,对抽象语法树进行语义分析。
检查表达式是否符合语法规则,给出相应的提示。
4. 最后,根据抽象语法树生成目标代码。
根据目标代码的要求,生成汇编代码或者机器码。
五、实验总结通过本次实验,我对编译器的工作原理有了更深入的认识,掌握了编译器设计和实现的基本方法和技巧。
中南大学软件学院编译原理实验报告

中南大学软件学院编译原理实验报告《320144X1(编译原理)》实验报告项目名称编译原理专业班级软件工程1403学号姓名温睿诚实验成绩:批阅教师:年月日"!="};String[] spilt = {",", "(", ")", "{", "}", ";"};五类,分别是关键字、标识符、常数、运算符以及分隔符。
然后逐个字符读入,对于关键字或标识符这类英文单词开始的单词,用空格隔开,其他可以用分隔符、运算符、空格、回车等。
读入一个单词后对照一开始的五类分析出是哪一类,符合后交给语法分析器处理。
实现过程:import java.io.*;import java.util.ArrayList;/*** Created by 温睿诚on 2016/5/11/0011. */public class CiFa {String[] keyword = {"if", "int"};ArrayList<String> biaoshi = new ArrayList<>();ArrayList<Integer> changshu = new ArrayList<>();String[] yunsuan = {"+", "=", "-", ">", "==", "!="};String[] spilt = {",", "(", ")", "{", "}", ";"};//记录结果的符号表//用什么数据结构呢?//当前单词StringBuilder str = new StringBuilder("");//下一个要读的字符char now;//一个栈ArrayList<Character> stack = new ArrayList<>();private void put() {stack.add(new Character(now));}private char pop() {if (stack.size() > 0) {return ((Character) stack.remove(stack.size() -1)).charValue();} else {return 0;}}//错误信息String errorMsg;Reader reader = null;public static void main(String[] args) {CiFa cifa = new CiFa();cifa.fenXi(args[0]);}private void fenXi(String filename) {//读取文件File file = new File(filename); try {reader = new InputStreamReader(newFileInputStream(file));} catch (FileNotFoundException e) {System.out.println("读取文件字符失败!");e.printStackTrace();}//不断读取字符直到结束getChar();int result;//使用预测分析法YuFa yuFa = new YuCeFenXi();boolean flag = true;while (!(now < 0 || now >= 65535)) {//根据返回数值查找或插入,错误则打印并提示。
编译原理实验报告
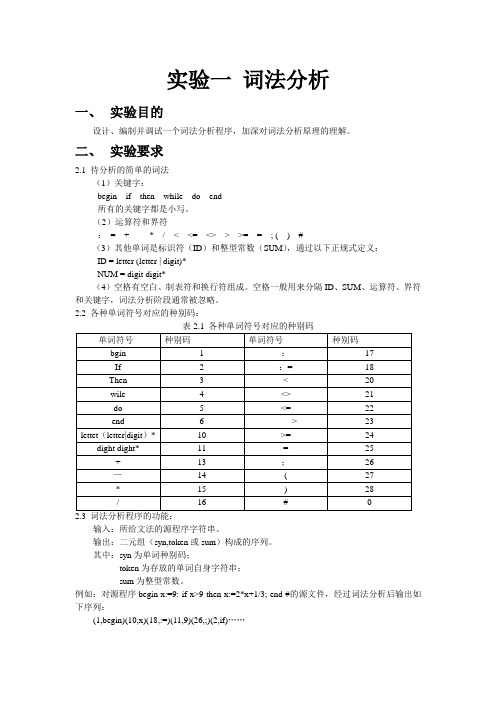
实验一词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:表2.1 各种单词符号对应的种别码单词符号种别码单词符号种别码bgin 1 :17If 2 := 18Then 3 < 20wile 4 <> 21do 5 <= 22end 6 > 23lettet(letter|digit)* 10 >= 24 dight dight* 11 = 25 + 13 ;26—14 ( 27* 15 ) 28/ 16 # 02.3 词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验1《词法分析程序设计与实现》实验学时: 4 实验地点:二综实验日期:一、实验目的加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析二、实验内容自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。
词法分析程序的实现可以采用任何一种编程语言和编程工具。
从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)三、实验方法用java或者C语言写出分析器四、实验步骤1.定义目标语言的可用符号表和构词规则;2.依次读入源程序符号,对源程序进行单词切分和识别,直到源程序结束;3.对正确的单词,按照它的种别以<种别码,值>的形式保存在符号表中;对不正确的单词,做出错误处理五、实验结果定义种别码final int NONE = 0;final int DELIMITER = 1; // 操作符运算符final int VAR = 2; // 字符变量final int Num = 3; // 数字final int COMMAND = 4; // 关键字// final int QUOTEDSTR=5; //带引号的字符串// 程序终结符end of programfinal String EOP = "#";// 声明关键字final int unKnowKeyword = 0;final int FI = 1;final int IF = 2;final int THEN = 3;final int WHILE = 4;final int DO = 5;final int END = 6;final int ELSE = 7;final int TO = 8;final int READ = 9;final int WRITE = 10;final int EOL = 11;六、实验结论由文件读入和控制台输出,良好的控制了要解析的句子过长的麻烦,实验结果也符合预期七、实验小结完成了词法编译器,很好的了解了底层编译过程中的词法分析关键代码:main.javapackage cn.main;import java.io.BufferedInputStream;import java.io.BufferedReader;import java.io.InputStreamReader;import cn.method.*;class Main{public static void main(String args[]){BufferedReader br =new BufferedReader(newInputStreamReader(System.in));try {System.out.println("请输入你要解析的文件");String filename=br.readLine();filename="src/cn/file/"+filename;CharacterAnalysis ob = new CharacterAnalysis(filename);ob.scanDisegn();} catch(Exception e) {}}}CharacterAnalysis.javapackage cn.method;import java.io.BufferedReader;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;public class CharacterAnalysis {// 声明处理字符的类型final int NONE = 0;final int DELIMITER = 1; // 操作符运算符final int VAR = 2; // 字符变量final int Num = 3; // 数字final int COMMAND = 4; // 关键字// final int QUOTEDSTR=5; //带引号的字符串// 程序终结符end of programfinal String EOP = "#";// 声明关键字final int unKnowKeyword = 0;final int FI = 1;final int IF = 2;final int THEN = 3;final int WHILE = 4;final int DO = 5;final int END = 6;final int ELSE = 7;final int TO = 8;final int READ = 9;final int WRITE = 10;final int EOL = 11;private char[] prog;private int progIdx;private String token;private int tokType;private int kwToken;final int PROG_SIZE = 100000;// 将关键字的外部表示,和内部表示保存在一个名为KwTable的表中Keyword kwTable[] = { new Keyword("fi", FI), new Keyword("if", IF), new Keyword("then", THEN), new Keyword("while", WHILE),new Keyword("do", DO), new Keyword("end", END),new Keyword("else", ELSE), new Keyword("to", TO),new Keyword("read", READ), new Keyword("write", WRITE) };public CharacterAnalysis(String programName) throws IOException { char tempbuf[] = new char[PROG_SIZE];int size;size = loadProgram(tempbuf, programName);if (size != -1) {prog = new char[size];System.arraycopy(tempbuf, 0, prog, 0, size);}}// 读入一个需要分析的程序private int loadProgram(char[] p, String fname) throws IOException { int size = 0;try {FileReader fr = new FileReader(fname);BufferedReader br = new BufferedReader(fr);size = br.read(p, 0, PROG_SIZE);fr.close();} catch (FileNotFoundException exc) {System.out.print("没有找到该文件!");}if (p[size - 1] == (char) 31)size--;return size;}// 分析程序代码private void getToken() throws IOException {tokType = NONE;token = "";kwToken = unKnowKeyword;if (progIdx == prog.length) {token = EOP;return;}// 跳过空格符while (progIdx < prog.length && isSpaceOrTab(prog[progIdx])) progIdx++;// handle crlfif (prog[progIdx] == '\r') {progIdx += 2;kwToken = EOL;token = "\r\n";return;}// 扫描完所有的字符,end programif (progIdx == prog.length) {if (progIdx == prog.length) {token = EOP;tokType = DELIMITER;return;}}if (isDelim(prog[progIdx])) {// 是一个操作符,或者是运算符token += prog[progIdx];progIdx++;// if(progIdx>=prog.length)break;tokType = DELIMITER;} else if (Character.isLetter(prog[progIdx])) {// 是一个字符变量while (!isDelim(prog[progIdx])) {token += prog[progIdx];progIdx++;if (progIdx >= prog.length)break;}kwToken = lookUp(token);// 如果是字符变量,用var标记,否则是关键字,用command标记if (kwToken == unKnowKeyword)tokType = VAR;elsetokType = COMMAND;} else if (Character.isDigit(prog[progIdx])) {// 是一个数字字符while (!isDelim(prog[progIdx])) {token += prog[progIdx];progIdx++;if (progIdx >= prog.length)break;}tokType = Num;}}// 判断字符是否是操作符private boolean isDelim(char c) {if (("\r, +-*/:<>=();".indexOf(c) != -1))return true;return false;}boolean isSpaceOrTab(char c) {if (c == ' ' || c == '\t')return true;return false;}// 查找字符串是否为关键字private int lookUp(String s) {int i;// Convert to lowercase.s = s.toLowerCase();// 查找字符串是否为关键字for (i = 0; i < kwTable.length; i++)if (kwTable[i].keyword.equals(s))return kwTable[i].keywordindex;return unKnowKeyword; // 不是一个关键字}// 对代码进行输出处理public void scanDisegn() throws IOException {// 对代码扫描do {getToken();// 扫描到字符是变量if (tokType == VAR) {System.out.println(token + " " + "29");}// 扫描到字符是关键字else if (tokType == COMMAND) {switch (kwToken) {case FI:System.out.println("fi" + " " + "1");break;case IF:System.out.println("if" + " " + "2");break;case THEN:System.out.println("then" + " " + "3");break;case WHILE:System.out.println("while" + " " + "4");break;case DO:System.out.println("do" + " " + "5");break;case END:System.out.println("end" + " " + "6");break;case ELSE:System.out.println("else" + " " + "7");break;case TO:System.out.println("to" + " " + "8");break;case READ:System.out.println("read" + " " + "9");break;case WRITE:System.out.println("write" + " " + "10");break;}}// 扫描到字符是数字else if (tokType == Num) {System.out.println(token + " " + "28");}// 扫描到字符是操作符else if (tokType == DELIMITER) {if (token.equals("+"))System.out.println(token + " " + "14");if (token.equals("-"))System.out.println(token + " " + "15");if (token.equals("*"))System.out.println(token + " " + "16");if (token.equals("/"))System.out.println(token + " " + "17");if (token.equals(":="))System.out.println(token + " " + "18");if (token.equals("<"))System.out.println(token + " " + "20");if (token.equals("<>"))System.out.println(token + " " + "21");if (token.equals("<="))System.out.println(token + " " + "22");if (token.equals(">"))System.out.println(token + " " + "23");if (token.equals(">="))System.out.println(token + " " + "24");if (token.equals("="))System.out.println(token + " " + "25");if (token.equals(";"))System.out.println(token + " " + "26");if (token.equals("("))System.out.println(token + " " + "27");if (token.equals(")"))System.out.println(token + " " + "28");}} while (!token.equals(EOP));System.out.println("#" + " " + "30");System.out.println("程序分析完毕");}}Keyword.javapackage cn.method;public class Keyword {String keyword;int keywordindex;Keyword(String str,int t){keyword=str;keywordindex=t;}}实验二预测分析法设计与实现一、实验目的加深对语法分析器工作过程的理解;加强对预测分析法实现语法分析程序的掌握;能够采用一种编程语言实现简单的语法分析程序;能够使用自己编写的分析程序对简单的程序段进行语法翻译。