火车头操作手册-Mg
火车头V7使用教程

火车头V7使用教程火车头V7免费版安装包:/share/link?shareid=271081&uk=4229184399安装后解压到桌面即可,不需要安装安装截图有一定数据库基础和PHP基础的朋友可以自行研究下里面的相关说明,今天介绍的教程,只是针对能够用火车头进行基础操作。
双击ProxyModule这个图标出现上面的对话框(里面的内容是笔者自己采集,初始化并没有这些数据),在正式进入采集之前,我们需要明白到底火车头是如何工作的?火车头的采集部分分为三个步骤,分别是采集目标网址、设置采集内容规则、开始采集。
以/att-5-1.htm这个页面为例,进行具体的操作介绍1、采集目标网址采集目标网址指的的是我们需要对需要采集的URL进行规则设置,简单的说,就是需要对网站的不同栏目下面的列表页进行设置。
点击新建任务,出现下面的对话框填写任务名(看个人习惯,一定要自己能看明白)——游戏网页编码一般都是自动识别,不需要自己修改点击起始网址中的右侧的添加,出现下面的对话框:这部分分为五种采集网址方式,分别是单条网址、批量/多页、文本导入/RSS地址和其它网址格式。
常用的一般就是前三种,RSS一会用到不过不多,至于其他网址格式采集的话,免费版的用不了,需要付费版的。
⏹单条网址就是手动输入一条url信息⏹批量多页这个是用到比较多的,下面我们主要介绍的也是这种⏹文本导入这个和单条网址相类似,就是通过编辑文本进行链接的导入工作那么,我们本次采用的就是批量多页的网址采集方式【地址格式】我们本次的目标页是/att-5-1.htm,那么我们就要找出,这个网站的列表页有什么共性。
通过下面的页码我们可以看出来,/att-5-变量.htm就构成了我们当前栏目下的列表页。
所以我们在地址格式中输入/att-5-1.htm,然后将其中的变量进行下替换,就是采用的后面的(*),/att-5-(*).htm下面是进行下变量的范围设定,这个大家自己应该能够看明白。
火车头工具使用
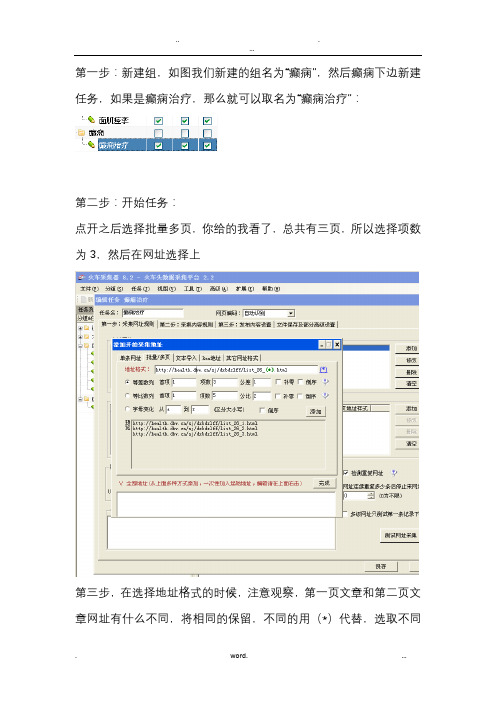
第一步:新建组,如图我们新建的组名为“癫痫”,然后癫痫下边新建任务,如果是癫痫治疗,那么就可以取名为“癫痫治疗”:第二步:开始任务:点开之后选择批量多页,你给的我看了,总共有三页,所以选择项数为3,然后在网址选择上第三步,在选择地址格式的时候,注意观察,第一页文章和第二页文章网址有什么不同,将相同的保留,不同的用(*)代替,选取不同的用(*)代替,可以直接在后边点击,就自动添加了(*)我们观察后发现,地址只有前边的/sj/dxbdzlff/list_26_是相同的,后边会自动变化,所以格式就为/sj/dxbdzlff/list_26_(*).html,第四步,网址选择完成后,单击添加,完成接下来就是多级网址的获取:(这是采集关键)*第五步:必须包含,任意选取其中一篇文章,提取,将不同的用(*)代替。
接下来的关键在地址选择:打开文章列表页:怎样判断代码源里边是独一无二的代码,ctrl+F查找查看源代码:找出标题列表最上边的独一无二的最接近标题的代码,一般都是div class=“”这样的格式,标题列表末尾也是同样选取,同样格式,独一无二末尾:选取完成后点击保存完成后先测试网址采集,就在最下边:测试正确完成后点击保存,接下来进行第二大步。
第二部分:第一步:采集容规则容采集,就比较简单了,任意选取一篇文章,查看源代码:找出标题前后代码:同样代码也是独一无二,双击标题,就可以进入:代码选择完成后确定。
接下来就是容页:同样双击之后查看:容代码的选择完成后,结果如下:但是注意容要添加HTML标签排除全选之后将换行和空格勾去确定之后就差不多完成了。
你也可以随便找一篇页面文章测试下结果:第三部分:第一步,发布容设置:文件模板地址:这个地址就看你把文件在那解压的。
这就算是全部完成了。
接下来就是采集:保存之后,三个全打对勾,开始采集:右键点击,开始任务,完成后只要去你建立的文件夹里边看就可以了。
火车头操作手册-Mg

火车头操作手册目录前言 (1)摘要 (2)第一章基础知识 (3)1.1 HTML 基础知识 (3)1.2 采集基础知识 (5)1.3发布基础知识 (5)1.4正则基础知识 (7)第二章火车头采集篇 (11)2.1 什么是信息采集? (11)2.2 火车头采集器的采集工作流程 (11)2.3 数据的转储 (20)第三章火车头发布篇 (24)3.1火车头发布内容的介绍 (24)3.2 接口文件的介绍.................................................................... 错误!未定义书签。
3.3 发布模块的制作 (26)第四章应用进阶 (38)4.1 火车头+PHP程序 (38)第五章防采技术介绍 (40)5.1 采集器与搜索引擎蜘蛛的区别 (40)5.2 防采集的一些主要措施 (40)5.3 火车头官方谈采集与防采 (42)5.3.1、谈火车头采集器的由来 (42)前言随着公司的日益壮大,产品线的不断拓宽,我们SEM团队也正在快速扩张,同时也带来了一系列问题,比如:团队成员的相互学习与交流,新员工的快速融入问题等。
因此员工学习手册的编写,势在必行。
员工学习手册,是团队成员技术,经验的总结,大家通过学习其他人的工作经验、技术,提高自己,同时团队实习也得到了提升。
而对于新入职的员工,根据前人的总结,经验,可以少走很多弯路,能够帮助他们快速融入集体,使得新人的适应期可以大大缩短,提高了新人培训效率。
在员工学习手册的编写过程中,我与沙亚金参与了《玩转“火车头”》的编写,里面是我们的一些使用火车头的一些心得,和技巧。
希望能够在信息采集,发布这块对大家有所帮助,由于时间,经验等因素,写的过程中也存在许多缺陷,欢迎大家与我们交流,批评指正。
在这里我们要感谢吉总,是他为大家带来了“火车头”。
摘要在这信息大爆炸的时代里,什么最重要?当然是信息。
对于“内容为王”的SEOer来说信息更是无价之宝。
火车头采集器教程演示文稿

三、采集网址
点击向导添加后出现如下界面:批量/多页
三、采集网址
单条网址选项下:
三、采集网址
填写完成后,点击“完成”。则出现以下界面:
三、采集网址
注释: 1、在选择目标站时,最好选择文章更新快,文章质量高(少广告词、图片、链接、 视频、flash等),内容丰富并且在业界有一定权威性的站点。 2、过于滞后的文章不要采集。(例如:08年、09年的文章) 3、在选择列表的过程中最好以站点为单位,不要以某个列表为单位,这样采集效 率会事半功倍。 4、在选择目标站时尽量不要选择动态页,多选择可以用数字或字母(*)代替的 静态页。 5、在采集过程中遇到不需要采集的文章,可以通过“不得包含”功能将其过滤掉。
四、采集内容
第五、责任编辑
双击责任编辑标签,选择“自定义固定格式的数据”,在固定的字符串选项中填写 自己的名称,点击确定,责任编辑设定完成。
四、采集内容
第六、信息来源
双击责任编辑标签,选择“自定义固定格式的数据”,在固定的字符串选项中填写 信息来源,点击确定,信息来源设定完成。
四、采集内容
第七、分页
四、采集内容
第四、信息关键词、meta关键词
查看本页面“源文件” 搜索keywords代码,找到文章关键词部分。如下图:
四、采集内容
將“源代码”中对应的关键词开始代码和结束代码分别输入到开始字符段和结束字 符段中,点击确定,信息关键词和meta关键词标签设置完成。
注释:有些文章关键词部分设有大量广告语或与本文无关的内容,这样的文章关键 词我们不给予采集。可以将标题的采集方法复制到关键词采集中。
四、采集内容
第二、资讯内容
查看本页面“源文件”,找到文章内容部分。如下图:
火车头采集软件使用教程(图文版)

火车采集器V2010SP3版(实现内容自动更新的采集软件)前提:本软件要求电脑安装net framework2.0或2.0以上框架支持。
一、火车采集器V2010SP3版,可供下载地址:/Down/LocoySpider/LocoySpider2010SP3.html二、net framework2.0,可供下载地址:/download/-Fra mework-2.0-For-Win98SE-ME-2000-XP/火车采集器和net framework2.0安装好后,可进行如下操作,操作步骤为:一、1.在一堆文件中,找到如下图标(画有红方框、状似火车头的),并双击打开。
2.打开后可以看到如下界面,看着很复杂,但对于新手而言很多东西是暂时用不到的。
在界面空白处(如下图红框区域内)右击,选择箭头所指“新建站点”。
输入站点名,例如:“西装”,保存即可。
3.在新建站点“西装”(红框区域)处选中再右击,选择从该站点新建任务。
二、第一步:采集网址规则1.先要找到自动更新的内容来源:如经常更新关注度较高的博客、专业网站等,这里我们就拿淘宝论坛举个例子。
找到开始采集地址栏右侧,点击向导添加。
2.添加开始采集地址中的多页类似地址形式前,要分析一下它的类似形式,例:我们在淘宝论坛中搜索“西服”相关内容,然后任意翻阅不同的页数查看它的网页地址。
第一页地址、第二页地址、第三页地址分别为:以此类推,分析出其不同点在于上图红框处的数字变化,因此:假如我们只采集论坛的第一页,就在多页类似地址形式栏粘贴第一页的网址,按一下(*)将选中的数字1替换成(*),再将数字变化改为相应页数:1, 然后点击添加、完成。
3.接着,找到如下图的相应位置分析规则并分别输入:必须包含“thread”,不得包含“post|pc”,任务名:这里设为“第一页”。
【可以点击开始测试网址采集,检测一下是否将网页都采集过来了。
若要返回到刚才上一级页面,点击返回修改设置即可。
火车头采集器用户手册
火车头采集用法下载火车头采集:地址:/Down/火车采集器的安装:火车采集器2010版是绿色软件。
如果您电脑上安装了微软的.NET FrameW ork 2.0框架或更高版本,安装时直接解压缩到您电脑的任何地方即可完成采集器的安装--安装过程不操作注册表和系统文件,不产生任何垃圾文件!如果您安装后程序无法启动,那可能是您电脑没有安装.NET FrameW ork 2.0,请下载微软的.NET FrameW ork 2.0框架或更高版本并安装。
附2.0下载地址:/download/5/6/7/567758a3-759e-473e-bf8f-52154438565a/dotnetfx.exe下载完之后点击d otnetfx.exe安装.NET FrameW ork。
安装完.NET FrameW ork之后打开火车采集器目录,双击目录内的LocoySpider.exe文件启动主程序开始采集之旅。
火车头采集基本流程:系统设置→新建站点→新建任务→采集网址→采集内容→发布内容→抓数据。
1.新建站点:据你自己的需求为任务建立统一的站点,以方便管理。
点击菜单上:站点→新建站点打开如下图:可以填写站点名,站点地址,网址深度(0,代表根据地址直接采内容。
1,代表根据地址采内容地址,然后根据内容地址采内容。
2,代表根据地址采列表地址,然后根据列表地址采内容地址,再根据内容地址采内容。
),站点描述。
2.新建任务:任务是采集器采集数据时的基本工作单元,它一定是建立在站点中的。
采集器通过运行任务来采集发布数据。
任务工作的步骤总体可以分为三步:采网址,采内容,发内容。
一个任务的运行可以任意选择哪几步。
而采集器又可以同时运行多个任务(默认设置是同时最多运行3个任务)。
选择站点点击右键选择“从该站点新建任务”。
任务的编辑界面如图:采集器的使用最主要的就是对任务的设置。
而采集数据可以分为两步,第一步是:采网址,第二步:采内容。
3.采集网址:采网址,就是从列表页中提取出内容页的地址。
火车头简单使用说明
火车头的简单使用说明火车头采集大致分为以下几步:1.建立站点。
2.建立采集规则(包括网址规则和采集规则)。
3.建立发布规则4.采集并发布先说第一步,建立站点。
很简单如下图:可以点上面的整站内容规则,把不同分类的公共标签等些在里面,会比较方便,自己试一下,咱们就按最基本的方法说。
点击保存按钮后,站点被保存,在左侧出列表树出现站点名称。
在名称上面,单击右键,选择从该站点新建任务出现如下对话框:点击向导添加,添加要采集的信息的列表页地址,找到列表页的分页规则,可以批量添加,也可以单页添加,建议先用单页,一是错误少,二十一次采集太多,你不怕把搜索引擎惹怒了。
好了不说废话,上图!点击添加后,单击完成,回到上一页,开始测试网址采集,当然最好添加一些必须有和不得包含的字符,过滤掉没用的链接。
还是看图:用鼠标随便选中一个链接,点浏览页面,看看有没有没用的东西,如果没有,选中一个页面,点击测试该页,出现如下图界面:上图中的标签,是很关键的东西,什么是没用的标签,什么是有用的标签呢?有用的,就是你发表信息的时候能用到的,比如说标题、电话等等。
火车头默认带着的时间、出处等就是没用的,干掉它!那么,怎么样建立标签呢?我拿标题来说一下,其他都类似了。
查看被采集内容页的源文件,找到标题的地方,看看被什么网页标签包围着,就是它了:这样标题就可以采集到了,类似的方法建立其他标签,即可采集到其他内容,下图是我采集:至此,采集部分完成,一些步骤说的比较简单,用的时候再摸索一下吧!然后,打开相应的data文件夹中找到与站点相同名字的文件夹,进入打开ACCESS文件导出数据为excel文件,整理数据之后导入数据库即可。
火车头采集器初学者入门教程

火车头采集器初学者入门教程火车头采集器是一种用于自动采集互联网上的信息的工具,它通过模拟人的操作来访问网页、提取数据,并将数据保存到数据库或文件中。
对于初学者来说,了解火车头采集器的基本原理和使用方法非常重要,下面是一个1200字以上的初学者入门教程。
第一部分:火车头采集器的基本原理火车头采集器的基本原理是通过模拟人的访问行为来采集网页上的信息。
它可以自动化多个任务,包括登录网页、填写表单、点击按钮、翻页等操作。
具体的操作是通过录制和回放的方式实现的,用户可以录制一系列的操作步骤,并通过回放来重复执行这些操作。
2.浏览器模块:用于加载和显示网页内容,并提供操作网页的功能。
3.数据提取器:用于提取网页上的数据,并保存到数据库或文件中。
4.代理服务器:用于模拟IP地址的变化,防止被封禁。
5.定时任务:用于定时执行采集任务,实现自动化采集。
第二部分:火车头采集器的使用方法2.创建新任务打开火车头采集器,点击任务管理器界面上的“新建任务”按钮创建一个新的采集任务。
在弹出的对话框中,输入任务的名称和网址,并选择其它相关设置,比如采集深度、采集速度等。
3.录制操作步骤点击“开始录制”按钮开始录制操作步骤。
在接下来的操作中,火车头采集器会自动记录你的操作并生成相应的脚本代码。
4.回放操作步骤点击“停止录制”按钮停止录制。
然后点击“回放”按钮执行你刚才录制的操作步骤。
火车头采集器会自动打开浏览器,并模拟你的操作来访问网页、填写表单等。
5.数据提取执行完操作步骤后,可以使用数据提取器来提取网页上的数据。
选择你感兴趣的内容,比如一段文字、一张图片等,然后点击提取按钮。
火车头采集器会自动将选中的内容提取出来,并保存到数据库或文件中。
6.设置定时任务如果你希望定时执行采集任务,可以在任务管理器中设置定时任务。
选择你要执行的任务,设置执行时间和频率。
火车头采集器会按照你的设置自动执行任务,并将采集到的数据保存到指定的位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
火车头操作手册目录前言 (1)摘要 (2)第一章基础知识 (3)1.1 HTML 基础知识 (3)1.2 采集基础知识 (5)1.3发布基础知识 (5)1.4正则基础知识 (7)第二章火车头采集篇 (11)2.1 什么是信息采集? (11)2.2 火车头采集器的采集工作流程 (11)2.3 数据的转储 (20)第三章火车头发布篇 (24)3.1火车头发布内容的介绍 (24)3.2 接口文件的介绍.................................................................... 错误!未定义书签。
3.3 发布模块的制作 (26)第四章应用进阶 (38)4.1 火车头+PHP程序 (38)第五章防采技术介绍 (40)5.1 采集器与搜索引擎蜘蛛的区别 (40)5.2 防采集的一些主要措施 (40)5.3 火车头官方谈采集与防采 (42)5.3.1、谈火车头采集器的由来 (42)前言随着公司的日益壮大,产品线的不断拓宽,我们SEM团队也正在快速扩张,同时也带来了一系列问题,比如:团队成员的相互学习与交流,新员工的快速融入问题等。
因此员工学习手册的编写,势在必行。
员工学习手册,是团队成员技术,经验的总结,大家通过学习其他人的工作经验、技术,提高自己,同时团队实习也得到了提升。
而对于新入职的员工,根据前人的总结,经验,可以少走很多弯路,能够帮助他们快速融入集体,使得新人的适应期可以大大缩短,提高了新人培训效率。
在员工学习手册的编写过程中,我与沙亚金参与了《玩转“火车头”》的编写,里面是我们的一些使用火车头的一些心得,和技巧。
希望能够在信息采集,发布这块对大家有所帮助,由于时间,经验等因素,写的过程中也存在许多缺陷,欢迎大家与我们交流,批评指正。
在这里我们要感谢吉总,是他为大家带来了“火车头”。
摘要在这信息大爆炸的时代里,什么最重要?当然是信息。
对于“内容为王”的SEOer来说信息更是无价之宝。
强大的信息资源,可以让我们在SE中处于霸主地位。
说到这里,不禁要问,我们的信息从何而来?我们应该如何处理这些信息?本文将详细介绍,如何采集一个站点,如何转储这些信息,如何在另一个站点发布这些信息,如何防采集,等等。
文章以介绍火车头采集,发布为例。
共分六个部分,基础知识(准备知识),采集部分(包括信息的采集,采集后的信息转储),发布部分(信息的发布),进阶部分(整套实战操作),防采技术,以及附录。
基础知识:该部分对采集、发布所使用到的一些必要知识进行介绍,其中包括HTML 代码的认知,正则表达式,PHP语言(也可以是其网页编辑语言)等。
采集部分:采集分为三小块,一是地址的采集,二是内容的采集,三是数据转储。
分别对采集各部分作详细的介绍。
发布部分:详细介绍发布模块及其制作过程,以及接口模块的介绍。
进阶部分:以Wordpress博客文章发布为实战实例,详细介绍如何向某一博客一次性发布N篇日志,并让该日志以每天M篇的速度自动释放。
防采部分:我们既然能采别人站,那别人也会采我们。
所以我们也要提高防采意识。
在这一部分里,将介绍建站时的一些防采技术。
附录:主要罗列一些火车头辅助工具的下载地址,以及一些火车头论坛。
全文以实例为主,建议大家在看完文章以后,再看一下我们制作的视屏教程,同时跟着视屏,自己动手操作采集一个站点,以加深印象。
第一章基础知识1.1 HTML 基础知识『<form>元素』使用<form>,以及在其间嵌入相关的元素(或称为控件),就可以创建HTML文档一部分的表单。
表单的基本语法:<form method="[get | post]" action="[url]">......</form>【method属性】用于指定向服务器发送表单数据时所用的HTTP方法,可以是get或者post这两只用方法中的一种,get是缺省的方法。
当采用get方法提交表单时,提交的数据被附加到url(在属性action中指定)的末端,作为url的一部分发送到服务器端。
例如:指定action="reg.asp",提交表单后,在浏览器的地址栏中,我们会看到如下信息http://localhost/register.php?user=zhangsan&pwd=123456而post方法是将表单中的信息作为一个数据块发送到服务器。
无论采用哪一种方法,数据的编码都是相同的,格式为name1=value1&name2=value2 。
【属性action】指定对表单进行处理的脚本地址。
也就是表单提交到服务器后,交由谁来处理,在action 属性中指定处理者的url 。
『元素<input>』<input>元素用于接受用户输入的信息,是一个带有属性的空元素,用来创建表单中的控件,语法如下:<input type="type" name="name" size="size" value="value">【type属性】用来指定要创建的控件类型,属性name用来指定控件的名称,处理表单的服务器端脚本可以获得以名称-值对所有表示的表单数据,利用名称,可以获取对应的值。
name属性在表单中并不显示。
属性size用来指定表单控件的初始宽度。
属性value指定控件的初始值。
单行文本输入控件type="text"提交按钮type="submit"重置按钮type="reset"口令输入控件type="password"单选按钮type="radio"复选框type="checkbox"隐藏控件type="hidden"『元素<select>』列表框允许用户从一个下拉列表框(下拉菜单)中选择一项或者多项,其功能和单选按钮或者复选框的功能相同,但是显示的方式不一样。
列表框中的各个选项用<option>元素提供。
『元素<textarea>』如果想让用户在填写信息的时候,输入他的个人简历等信息,那么单行文本控件就不合适,对于接受多行信息的情况下,可以使用多行文本输入控件,它可以容纳较多的信息。
语法:<textarea name="name" rows="n" cols="n">....</textarea>在开始结束标签之间出现的文本,将作为文本输入控件中的初始文本显示。
【属性rows】指定文本输入控件可视区域显示的文本行数.【属性cols】用于指定文本输入控件可视区域显示的宽度。
示例:<form method="get" action="reg.asp">用户名:<input type="text" name="user" size="20" value="游客">密码:<input type="password" name="pwd" size="20">性别:<input type="radio" name="sex" value="1" checked>男<input type="radio" name="sex" value="0">女<br>爱好:<input type="checkbox" name="intersest" value="football">足球<input type="checkbox" name="intersest" value="basketball">篮球<input type="checkbox" name="intersest" value="swimming">游泳<br> 学历:<select size="1" name="education"><option value="" selected>...</option><option value="高中" >高中</option><option value="本科" >本科</option><option value="研究生" >研究生</option></select><br>个人简介:<textarea name="personal" rows="5" cols="30">个人简介</textarea><br> <input type="hidden" name="id" value="1"><input type="reset" value="重设"><input type="submit" value="提交"></form>1.2 采集基础知识当我们浏览一个网站的页面的时候,其实是通过浏览器来解释从网站服务器返回的一段HTML代码,而当我们需要这个页面的内容时,我们只需要得到这个页面的HTML源代码,然后从这些HTML代码中取出我们需要的内容。
举个例子:/ ,如果我们对这个站点的内容比较喜欢,想转载到自己的BLOG上面,第一个方法就是手动复制,粘贴,修改。