【精品】编译原理毕业论文报告C-语言词法与语法分析器的实现
编译原理词法分析和语法分析报告 代码(C语言版)
admit=0;
for(in=0;in<cal-1;in++){str[in]=str[in+1];}
str[in]='\0';
cal--;
r_find=r_find->next;
}//:入栈~
if(r_find->line_States==s_find->num&&r_find->rank_Letter==str[0]&&r_find->name=='r'){//:规约
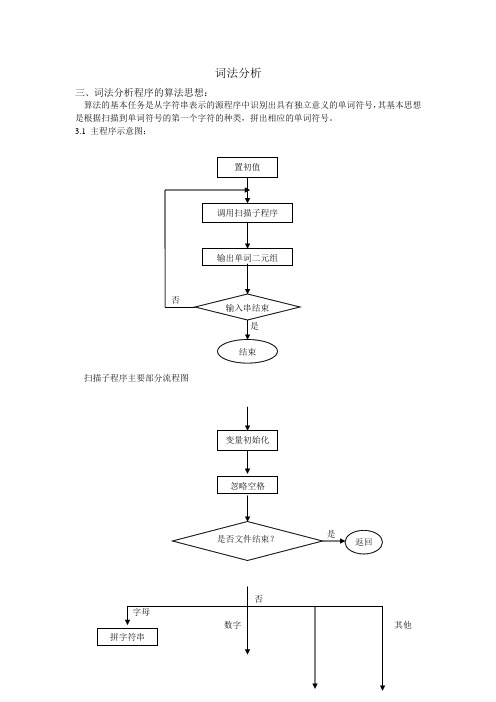
词法分析
三、词法分析程序的算法思想:
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1主程序示意图:
否
是
扫描子程序主要部分流程图
是是
否
字母
数字其他
运算符、符号
界符等符号
否
是
词法分析程序的C语言程序源代码:
//词法分析函数: void scan()
//数据传递:形参fp接收指向文本文件头的文件指针;
//全局变量buffer与line对应保存源文件字符及其行号,char_num保存字符总数。
void scan()
{
char ch;
int flag,j=0,i=-1;
while(!feof(fp1))
{
ch=fgetc(fp1);
flag=judge(ch);
struct Sign *next;
【精编完整版】C语言词法分析器和C-语言语法分析器编译原理毕业论文

(此文档为word格式,下载后您可任意编辑修改!) 《编译原理课程设计》课程报告题目 C语言词法分析器和C-语言语法分析器学生姓名学生学号指导教师提交报告时间 2019 年 6 月 8 日C语言词法分析器1 实验目的及意义1.熟悉C语言词法2.掌握构造DFA的过程3.掌握利用DFA实现C语言的词法分析器4.理解编译器词法分析的工作原理2 词法特点及正则表达式2.1词法特点2.1.1 保留字AUTO, BREAK , CASE , CHAR , CONST , CONTINUE , DEFAULT , DO , DOUBLE , ELSE,ENUM , EXTERN , FLOAT , FOR , GOTO,IF , INT , LONG , REGISTER , RETURN,SHORT , SIGNED , SIZEOF , STATIC , STRUCT , SWITCH , TYPEDEF , UNION , UNSIGNED , VOID,VOLATILE , WHILE,2.1.2 符号+ - * ++ -- += -= *= < <= > >= == != = ; , ( ) [ ] { } * * :2.2 正则表达式whitespace = (newline|blank|tab|comment)+digit=0|..|9nat=digit+signedNat=(+|-)?natNUM=signedNat(“.”nat)?letter = a|..|z|A|..|ZID = letter(letter|digit|“_”)+CHAR = 'other+' STRING = “other+”3 Token定义3.1 token类型3.2 tokenType类型代码4 DFA设计4.1 注释的DFA设计注释的DFA如下所示,一共分为5个状态,在开始状态1时,如果输入的字符为, 则进入状态2,此时有可能进入注释状态,如果在状态2时,输入的字符为*,则进入注释状态,状态将转到3,如果在状态3时,输入的字符为*,则有可能结束注释状态,此时状态将转到状态4,如果在状态4时输入的字符为,则注释状态结束,状态转移到结束状态。
编译原理词法分析和语法分析报告 代码(C语言版)[1]
![编译原理词法分析和语法分析报告 代码(C语言版)[1]](https://img.taocdn.com/s3/m/a1924436453610661ed9f4cc.png)
char ch='\0';
/*从字符缓冲区读取当前字符*/
int count=0;
/*词法分析结果缓冲区计数器*/
static char spelling[10]={""}; /*存放识别的字*/
static char line[81]={""}; /*一行字符缓冲区,最多 80 个字符*/
char *pline;
scaner(); main() {p=0;
printf("\n please input a string(end with '#'):/n"); do{
scanf("%c",&ch); prog[p++]=ch; }while(ch!='#'); p=0; do{ scaner(); switch(syn)
EO
19
B or(即布尔表达式中的 B∨ )
Plus
34
“+”
Times
36
Becomes
38
Op_and
39
Op_or
40
Op_not
41
Rop
42
Lparent
48
Rparent
49
Ident
56
Intconst
57
#define sy_if
0
#define sy_then 1
#define sy_else 2
case '*': syn=15; token[m++]=ch; break;
case '/': syn=16; token[m++]=ch; break;
编译原理课程设计报告C语言词法与语法分析器的实现

编写原理课程设计报告题目:编译原理课程设计C语言词法和语法分析器的实现C-词法和语法分析器的实现1.课程设计目标(1)题目的实用性C语言具有完整语言的基本属性,写C语言的词法分析和语法分析对理解编译原理的相关理论和知识会起到很大的作用。
通过编写C语言词法和语法分析程序,可以对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个清晰的认识和掌握。
(2)C语言的词法描述①语言的关键词:else if int返回void while的所有关键字都是保留字,必须小写。
②特殊符号:+ - * / < <= > >= == != = ;, ( ) [ ] { } /* */③其他标记是ID和NUM,它们由以下正则表达式定义:ID =字母字母*NUM =数字数字*字母= a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示字母,digit表示数字。
小写字母和大写字母是有区别的。
④它由空格、换行符和制表符组成。
空格通常会被忽略。
⑤用常用的C语言符号/*将注释括起来...*/.注释可以放在任何空白位置(也就是注释不能放在标记上),可以多行。
注释不能嵌套。
(3)规划目标能够正确分析程序的词法和语法。
2.分析和设计(1)设计理念a.词汇分析词法分析的实现主要使用有限自动机理论。
有限自动机可以用来描述识别输入字符串中模式的过程,因此也可以用来构造扫描程序。
词法分析器可以很容易地用有限自动机理论来设计。
b.语法分析语法分析采用递归下降分析法。
递归下降法是语法分析中最容易理解的方法。
其主要原理是根据每个非终结符的产生式结构为其构造相应的解析子程序,其中终结符生成匹配命令,非终结符生成过程调用命令。
这种方法被称为递归子例程下降法或递归下降法,因为语法递归的相应子例程也是递归的。
子程序的结构与产生式的结构几乎相同。
(2)程序流程图主程序流程图:词法分析:语法分析:词汇分析子流程图:语法分析子流程图:3.程序代码实现整个词法与语法程序设计在同一个项目中,包含八个文件,分别是main.cpp、parse.cpp、scan.cpp、util.cpp、scan.h、util.h、globals.h和parse.h,其中scan.cpp和scan.h是词法分析程序。
编译原理:c语言词法分析器的实现

编译原理:c语⾔词法分析器的实现编译原理:c语⾔词法分析器的实现⼀、前⾔词法分析和语法分析是编译原理中必要的部分,是需要花费⼀定时间去学习理解的,本⽂简单介绍了使⽤c语⾔如何编写c语⾔的词法分析器。
(ps:完整代码的链接在⽂末)⼆、什么是词法分析器定义词法分析器的功能输⼊源程序,按照构词规则分解成⼀系列单词符号。
单词是语⾔中具有独⽴意义的最⼩单位,包括关键字、标识符、运算符、界符和常量等。
(1) 关键字:是由程序语⾔定义的具有固定意义的标识符。
例如begin,end,if,while都是保留字。
这些字通常不⽤作⼀般标识符。
(2) 标识符:⽤来表⽰各种名字,如变量名,数组名,过程名等等。
(3) 常数 :常数的类型⼀般有整型、实型、布尔型、⽂字型等。
(4) 运算符:如+、-、*、/等等。
(5) 界符 :如逗号、分号、括号、等等。
输出有了对词法分析器的定义,我们编写的词法分析器的输出理所当然应当是如下的形式:(单词,单词属性,id(种别码))如:(if,关键字,3)id通常情况下可以⾃⼰定义,例如⽆符号整数的id可以设为1,只要能区别不同的属性即可。
(ps:如果在编写时有对应的种别码表,照着写就完事⼉了。
)种别码表⽰例单词符号种别码NUM0Letter1main2三、实现过程如何实现1. 读到空格则略过,读下⼀个字符;若读到的是字母,就再接着读,直到读到的既不是字母也不是数字也不是下划线,并将读到的写⼊到token数组;2. 若读到的是数字,直到读到的不是数字或⼩数点,将读到的写⼊到token数组;3. 若读到的是<|>|=,则再读⼊下⼀位,若为=,则该运算符为<=|>=|==,若为其他字符,则返回<|>|=的种别码;4. 若读到的是/,则读下⼀位,若为*,则说明之后为多⾏注释,⼀直读⼊直到读⼊*,并判断下⼀位是否为/,若是则注释结束,不是继续往下⼀位读⼊;若读⼊\n,则⾏数加⼀,若读⼊的字符与以上都不匹配,则报错,并输出出错⾏数;5. 若读到/时,下⼀位⼜读到/,即读到的是单⾏注释,此时判断下⼀位是否为\n,若是,则注释结束,不是则继续读⼊下⼀位。
编译原理词法分析器语法分析器实验报告

printf("请输入各终结符(#号表示结束)Vt[i]:\n");
for(i=0;i<100;i++)
{
scanf("%c",&Vt[i]);
if(Vt[i]=='#')
{
r=i;
break;
}
}
printf("请输入非终结符个数:\n");
scanf("%d",&n);
getchar();
p=s->next;
while(p!=NULL)
{
st[i++]=p->data;
p=p->next;
}
for(j=i-1;j>=0;j--)
printf("%c",st[j]);
for(j=0;j<16-i;j++) //打印对齐格式
printf("%c",' ');
}
char gettop(stackk *s) //返回栈顶元素值
{
stackk *p;
p=(stackk *)malloc(sizeof(stackk));
p->data=x;
p->next=s->next;
s->next=p;
}
void display(stackk *s) //打印现实显示栈内元素
{
stackk *p;
int i=0,j;
char st[100];
#include<string.h>
#include<malloc.h>
C语言编译原理词法分析和语法分析

C语言编译原理词法分析和语法分析编程语言的编写和使用离不开编译器的支持,而编译器的核心功能之一就是对代码进行词法分析和语法分析。
C语言作为一种常用的高级编程语言,也有着自己的词法分析和语法分析规则。
一、词法分析词法分析是编译器的第一阶段,也是将源代码拆分为一个个独立单词(token)的过程。
在C语言中,常见的单词包括关键字(如if、while等)、标识符(如变量名)、常量(如数字、字符常量)等。
词法分析器会根据预定义的规则对源代码进行扫描,并将扫描到的单词转化为对应的符号表示。
词法分析的过程可以通过有限自动机来实现,其中包括各种状态和状态转换规则。
词法分析器通常会使用正则表达式和有限自动机的方法来进行实现。
通过词法分析,源代码可以被分解为一个个符号,为后续的语法分析提供基础。
二、语法分析语法分析是编译器的第二阶段,也是将词法分析得到的单词序列转换为一棵具有语法结构的抽象语法树(AST)的过程。
在C语言中,语法分析器会根据C语言的文法规则,逐句解析源代码,并生成相应的语法树。
C语言的语法规则相对复杂,其中包括了各种语句、表达式、声明等。
语法分析的过程主要通过递归下降分析法、LR分析法等来实现。
语法分析器会根据文法规则建立语法树的分析过程,对每个语法结构进行逐步推导和分析,最终生成一棵完整的语法树。
三、编译器中的词法分析和语法分析在编译器中实现词法分析和语法分析是一项重要的技术任务。
编译器通常会将词法分析和语法分析整合在一起,形成一个完整的前端。
在C语言编译器中,词法分析和语法分析器会根据C语言的词法规则和文法规则,对源代码进行解析,并生成相应的中间表示形式,如语法树或者中间代码。
词法分析和语法分析的结果会成为后续编译器中各个阶段的输入,如语义分析、中间代码生成、目标代码生成等。
编译器的优化和错误处理也与词法分析和语法分析有密切关系。
因此,对词法分析和语法分析的理解和实现对于编译器开发者而言是非常重要的。
最新编译原理课程设计-C-词法扫描器及语法分析器实现

编译原理课程设计-C-词法扫描器及语法分析器实现------------------------------------------作者xxxx------------------------------------------日期xxxx编译原理课程设计报告课题名称:C-词法扫描器及语法分析器实现提交文档学生姓名:提交文档学生学号:同组成员名单: 无指导教师姓名: 金军指导教师评阅成绩:指导教师评阅意见:。
提交报告时间:2014年 6月xx日目录目录ﻩ31 课程设计目标 ............................................ 错误!未定义书签。
2 分析与设计............................................... 错误!未定义书签。
2。
1程序结构......................................... 错误!未定义书签。
3 程序代码实现ﻩ错误!未定义书签。
3.1代码结构.......................................... 错误!未定义书签。
3.2。
1 globals。
h ................................ 错误!未定义书签。
3。
2.2 scan。
c .................................... 错误!未定义书签。
3。
2.3 parser。
c ................................... 错误!未定义书签。
3.4 util。
c ....................................... 错误!未定义书签。
3.5 test。
cppﻩ错误!未定义书签。
4 测试结果ﻩ错误!未定义书签。
4。
1.给出标准测试程序的词法和语法分析结果:ﻩ错误!未定义书签。
4。
1.1 词法分析结果ﻩ错误!未定义书签。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(此文档为word格式,下载后您可任意编辑修改!) 编译原理课程设计报告课题名称:编译原理课程设计C-语言词法与语法分析器的实现提交文档学生姓名:提交文档学生学号:同组成员名单:指导教师姓名:指导教师评阅成绩:指导教师评阅意见:..提交报告时间:年月日C-词法与语法分析器的实现1.课程设计目标(1)题目实用性C-语言拥有一个完整语言的基本属性,通过编写C-语言的词法分析和语法分析,对于理解编译原理的相关理论和知识有很大的作用。
通过编写C-语言词法和语法分析程序,能够对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个比较清晰的了解和掌握。
(2)C-语言的词法说明①语言的关键字:else if int return void while所有的关键字都是保留字,并且必须是小写。
②专用符号:+ - * < <= > >= == != = ; , ( ) [ ] { } * *③其他标记是ID和NUM,通过下列正则表达式定义:ID = letter letter*NUM = digit digit*letter = a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示一个字母,digit表示一个数字。
小写和大写字母是有区别的。
④空格由空白、换行符和制表符组成。
空格通常被忽略。
⑤注释用通常的c语言符号 * . . . * 围起来。
注释可以放在任何空白出现的位置(即注释不能放在标记内)上,且可以超过一行。
注释不能嵌套。
(3)程序设计目标能够对一个程序正确的进行词法及语法分析。
2.分析与设计(1)设计思想a.词法分析词法分析的实现主要利用有穷自动机理论。
有穷自动机可用作描述在输入串中识别模式的过程,因此也能用作构造扫描程序。
通过有穷自动机理论能够容易的设计出词法分析器。
b.语法分析语法分析采用递归下降分析。
递归下降法是语法分析中最易懂的一种方法。
它的主要原理是,对每个非终结符按其产生式结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。
因为文法递归相应子程序也递归,所以称这种方法为递归子程序下降法或递归下降法。
其中子程序的结构与产生式结构几乎是一致的。
(2)程序流程图程序主流程图:词法分析: 语法分析:词法分析子流程图:语法分析子流程图:3.程序代码实现整个词法以及语法的程序设计在一个工程里面,一共包含了8个文件,分别为main.cpp、parse.cpp、scan.cpp、util.cpp、scan..cpp和scan..cpp#include "globals..=TRUE;int TraceParse=TRUE;int Error = F ALSE;int main(int argc,char * argv[])TreeNode * syntaxTree;char pgm[120];scanf("%s",pgm);source=fopen(pgm,"r");if(source==NULL){fprintf(stderr,"File %s not found\n",pgm);exit(1);}listing = stdout;fprintf(listing,"\nC COMPILATION: %s\n",pgm); #if NO_P ARSEwhile(getT oken()!=ENDFILE);#elsesyntaxTree = parse();if(TraceParse){fprintf(listing,"\nSyntaxtree:\n");printTree(syntaxTree);}#endiffclose(source);return 0;}Parse.cpp#include "globals..; * ** function prototypes for recursive calls *static TreeNode * declaration_list(void);static TreeNode * declaration(void);static TreeNode * params(void);static TreeNode * param_list(void);static TreeNode * param(void);static TreeNode * compound_stmt(void);static TreeNode * local_declarations(void);static TreeNode * statement_list(void);static TreeNode * statement(void);static TreeNode * expression_stmt(void);static TreeNode * if_stmt(void);static TreeNode * while_stmt(void);static TreeNode * return_stmt(void);static TreeNode * expression(void);static TreeNode * var(void);static TreeNode * simple_exp(void);static TreeNode * additive_expression(void);static TreeNode * term(void);static TreeNode * factor(void);static TreeNode * args(void);static TreeNode * arg_list(void);static void syntaxError(char * message){ fprintf(listing,"\n>>> ");fprintf(listing,"Syntax error at line %d: %s",lineno,message); Error = TRUE;}*判断读取的字符*static void match(T okenType expected){if(token==expected){token=getT oken( );}else{syntaxError("unexpected token -> ");printT oken(token,tokenString);fprintf(listing," ");}}*进行语法分析,构建语法树*TreeNode * declaration_list(void){TreeNode * t= declaration();TreeNode * p= t;while ((token==INT) || (token==VOID) ){TreeNode *q = declaration();if (q!=NULL) {if (t==NULL) t = p = q;else * now p cannot be NULL either *{p->sibling = q;p = q;}}}return t;}TreeNode * declaration(void){ TreeNode * t = NULL;switch (token){case VOID :case INT :t = newStmtNode(DecK);if(token == INT)t->type =Integer;elset->type = V oid;match(token);switch (token){case ID:t-> = copyString(tokenString);t->kind.stmt = V arDK;match(ID);switch (token){case LZKH:t->kind.stmt = V arDK;t->type = IntArray;match(LZKH);match(NUM);match(RZKH);match(SEMI);break;case LP AREN:t->kind.stmt = FunDK;match(LPAREN);t->child[0] = params();match(RP AREN);t->child[1] = compound_stmt();break;default: match(SEMI);break;}break;default:syntaxError("unexpected token -> ");printT oken(token,tokenString);token = getToken();break;}break;default : syntaxError("unexpected token -> ");printT oken(token,tokenString);token = getToken();break;} * end case *return t;}TreeNode * params(void){TreeNode * t = NULL;if(token == VOID){match(token);t = newStmtNode(ParamList);t->child[0] = newStmtNode(ParamK);t->child[0]->type = V oid;}else if(token == RP AREN)t=NULL;else{t = param_list();}return t;}TreeNode * param_list(void){TreeNode * t = newStmtNode(ParamList);int i = 1;t->child[0] = param();while(token != RP AREN){match(DOT);t->child[i] = param();i++;}return t;}TreeNode * param(void){TreeNode * t = NULL;match(INT);t= newStmtNode(ParamK);t->type=Integer;t->=copyString(tokenString);match(ID);if(token == LZKH){t->type=IntArray;match(LZKH);match(RZKH);}return t;}TreeNode * compound_stmt(void){TreeNode * t = newStmtNode(ComK);match(LDKH);t->child[0] = local_declarations();t->child[1] = statement_list();match(RDKH);return t;}TreeNode * local_declarations(void){TreeNode * t = newStmtNode(LocalDecK);int i=0;while(token == INT || token == VOID){t->child[i] = declaration();i++;}return t;}TreeNode * statement_list(void){TreeNode * t = newStmtNode(StmtList);int i=0;while(token != RDKH){t->child[i] =statement();i++;}return t;}TreeNode * statement(void){TreeNode * t ;switch (token) {case IF : t = if_stmt(); break;case WHILE : t = while_stmt(); break;case ID :case SEMI:t = expression_stmt(); break;case RETURN : t = return_stmt(); break;case LDKH : t=compound_stmt();break;default : syntaxError("unexpected token -> ");printT oken(token,tokenString);token = getToken();break;} * end case *return t;}TreeNode * expression_stmt(void){TreeNode * t = newStmtNode(ExpstmtK);if(token == SEMI)match(SEMI);else{t = expression();match(SEMI);}return t;}TreeNode * if_stmt(void){TreeNode * t = newStmtNode(IfK);if(t!=NULL){match(IF);match(LPAREN);t->child[0] = expression();match(RP AREN);t->child[1] = statement();if (token==ELSE){match(ELSE);if (t!=NULL) t->child[2] = newStmtNode(ElseK);t->child[2]->child[0] = statement();} }return t;}TreeNode * while_stmt(void){TreeNode * t = newStmtNode(WhileK);match(WHILE);match(LPAREN);if (t!=NULL) t->child[0] = expression();match(RP AREN);if (t!=NULL) t->child[1] = statement();return t;}TreeNode * return_stmt(void){TreeNode * t = newStmtNode(RetK);if(token == RETURN)match(RETURN);if(token == SEMI)match(SEMI);else{t->child[0] = expression();match(SEMI);}return t;}TreeNode * expression(void){TreeNode * t = simple_exp();return t;}TreeNode* var(void){TreeNode* t = newExpNode(IdK);if ((t!=NULL) && (token==ID))t-> = copyString(tokenString);match(ID);if(token == LZKH){match(token);t->type = ArrayUnit;t->child[0] = expression();match(RZKH);}return t;}TreeNode * simple_exp(void){TreeNode * t = additive_expression();if(t!=NULL){if (token == L T || token == LE|| token == MT || token == ME||token ==EQ||token ==NEQ){TreeNode * p = newExpNode(OpK);if(p!=NULL){p->attr.op = token;p->child[0] = t;match(token);p->child[1] = additive_expression();t=p;}}}return t;}TreeNode* additive_expression(void){TreeNode * t = term();while(token == PLUS || token == MINUS){TreeNode * p = newExpNode(OpK);p->attr.op = token;p->child[0] = t;match(token);p->child[1] = term();t = p;}return t;}TreeNode * term(void){TreeNode * t = factor();while ((token==TIMES)||(token==OVER)){TreeNode * p = newExpNode(OpK);if (p!=NULL) {p->child[0] = t;p->attr.op = token;match(token);p->child[1] = factor();t = p;}}return t;}TreeNode * factor(void){TreeNode * t = NULL;switch (token){case NUM :t = newExpNode(ConstK);if ((t!=NULL) && (token==NUM))t->attr.val = atoi(tokenString);match(NUM);break;case ID :t = var();if (token == ASSIGN){TreeNode* p = newStmtNode(AssignK);p-> = t->;match(token);p->child[0] = expression();t = p;}if (token == LP AREN ){TreeNode * p = newStmtNode(CallK);p-> = t->;t=p;match(token);p->child[0] = args();match(RP AREN);}break;case LP AREN :match(LPAREN);t = expression();match(RP AREN);break;default:syntaxError("unexpected token -> ");printT oken(token,tokenString);token = getToken();break;}return t;}TreeNode * args(void){TreeNode * t = newStmtNode(ArgList);if(token != RPAREN){t->child[0] = arg_list();return t;}elsereturn NULL;}TreeNode * arg_list(void){TreeNode * t = newStmtNode(ArgK);int i = 1;if(token != RPAREN)t->child[0] = expression();while(token!=RPAREN){match(DOT);t->child[i] = expression();i++;}return t;}TreeNode * parse(void){ TreeNode * t;token = getToken();t =declaration_list();if (token!=ENDFILE)syntaxError("Code ends before file\n"); return t;}scan.cpp#include "globals..(void){ * index for storing into tokenString * int tokenStringIndex = 0;* to be returned *T okenType currentT oken;* current state - always begins at START * StateType state = START;* flag to indicate save to tokenString *int save;while (state != DONE){ int c = getNextChar();save = TRUE;switch (state){ case START:if (isdigit(c))state = INNUM;else if (isalpha(c))state = INID;else if (c == '=')state = INEQUAL;else if (c == '<')state = INLE;else if (c == '>')state = INME;else if ((c == ' ') || (c == '\t') || (c == '\n')) save = FALSE;else if (c== '!')state = INNEQ;else if (c == ''){if(getNextChar()!='*'){ungetNextChar();state = DONE;currentT oken = OVER;break;}else{save = FALSE;state = INCOMMENT;}}else{ state = DONE;switch (c){ case EOF:save = F ALSE;currentT oken = ENDFILE;break;case '+':currentT oken = PLUS;break;case '-':currentT oken = MINUS;break;case '*':currentT oken = TIMES;break;case '(':currentT oken = LPAREN;break;case ')':currentT oken = RP AREN;break;case ';':currentT oken = SEMI;break;case '[':currentT oken=LZKH;break;case ']':currentT oken=RZKH;break;case '{':currentT oken=LDKH;break;case '}':currentT oken=RDKH;break;case ',':currentT oken=DOT;break;default:currentT oken = ERROR;break;}}break;case INCOMMENT:save = FALSE;if (c == EOF){state = DONE;currentT oken = ERROR;}else if(c=='*'){if(getNextChar()==''){state = START;}else{ungetNextChar();}}break;case INNEQ:state=DONE;if(c=='=')currentT oken=NEQ; else{ungetNextChar();save=F ALSE;currentT oken=ERROR; }break;case INEQUAL:state = DONE;if (c == '=')currentT oken = EQ; else{ * backup in the input *ungetNextChar();currentT oken = ASSIGN; }break;case INNUM:if (!isdigit(c)){ * backup in the input *ungetNextChar();save = FALSE;state = DONE;currentT oken = NUM;}break;case INID:if (!isalpha(c)){ * backup in the input *ungetNextChar();save = FALSE;state = DONE;currentT oken = ID;}break;case INLE:state = DONE;if(c== '=')currentT oken = LE;else{ * backup in the input *ungetNextChar();currentT oken = L T;}break;case INME:state = DONE;if(c== '=')currentT oken = ME;else{ * backup in the input *ungetNextChar();currentT oken = MT;}break;case DONE:default: * should never *fprintf(listing,"Scanner Bug: state= %d\n",state);state = DONE;currentT oken = ERROR;break;}if ((save) && (tokenStringIndex <= MAXTOKENLEN))tokenString[tokenStringIndex++] = (char) c;if (state == DONE){ tokenString[tokenStringIndex] = '\0';if (currentT oken == ID)currentT oken = reservedLookup(tokenString);}}if (TraceScan) {fprintf(listing,"\t%d: ",lineno);printT oken(currentT oken,tokenString);}return currentT oken;} * end getT oken *Util.cpp#include "globals.(T okenType token, const char* tokenString) {*根据对应的判断输出判断结果*switch(token){case ELSE:case IF:case INT:case RETURN:case VOID:case WHILE:fprintf(listing, "reserved word: %s\n", tokenString);break;case L T:fprintf(listing,"<\n");break;case EQ:fprintf(listing,"==\n");break;case LP AREN:fprintf(listing,"(\n");break;case RPAREN:fprintf(listing,")\n");break;case SEMI:fprintf(listing,";\n");break;case PLUS:fprintf(listing,"+\n");break;case MINUS:fprintf(listing,"-\n");break;case TIMES:fprintf(listing,"*\n");break;case OVER:fprintf(listing,"\n");break;case ENDFILE:fprintf(listing,"EOF\n");break;case MT:fprintf(listing,">\n");break;case NEQ:fprintf(listing,"!=\n");break;case ASSIGN:fprintf(listing,"=\n");break;case DOT:fprintf(listing,",\n");break;case LZKH:fprintf(listing,"[\n");break;case RZKH:fprintf(listing,"]\n");break;case LDKH:fprintf(listing,"{\n");break;case RDKH:fprintf(listing,"}\n");break;case LZS:fprintf(listing,"*\n");break;case RZS:fprintf(listing,"*\n");break;case ME:fprintf(listing,">=\n");break;case LE:fprintf(listing,"<=\n");break;case NUM:fprintf(listing,"NUM,val= %s\n",tokenString);break;case ID:fprintf(listing,"ID, name= %s\n",tokenString);break;case ERROR:fprintf(listing,"ERROR: %s\n",tokenString);break;default:fprintf(listing,"Unknown token: %d\n",token);}}*this function is used to establish the new stmt node*TreeNode * newStmtNode(StmtKind kind){TreeNode * t = (TreeNode *)malloc(sizeof(TreeNode));int i;if(t==NULL){fprintf(listing, "Out of memory error at line %d\n",lineno);}else{for(i=0;i<MAXCHILDREN;i++){t->child[i]=NULL;}t->sibling=NULL;t->nodekind=StmtK;t->kind.stmt=kind;t->lineno=lineno;}return t;}* Function newExpNode creates a new expressionnode for syntax tree construction*TreeNode * newExpNode(ExpKind kind){TreeNode * t = (TreeNode *)malloc(sizeof(TreeNode));int i;if(t==NULL){fprintf(listing, "Out of memory error at line %d\n",lineno);}else{for(i=0;i<MAXCHILDREN;i++){t->child[i]=NULL;}t->sibling=NULL;t->nodekind=ExpK;t->kind.exp=kind;t->lineno=lineno;t->type=V oid;}return t;}char * copyString(char * s){int n;char * t;if(s==NULL){return NULL;}n=strlen(s)+1;t=(char *)malloc(n);*其作用是在内存的动态存储区中分配一个长度为n的连续空间.保存tokenstring* if(t==NULL){fprintf(listing, "Out of memory error at line %d\n",lineno);}else{strcpy(t,s);*该函数是字符串拷贝函数,用来将一个字符串复制到一个字符数组中。