最优匹配(KUHN MUNKRAS算法)
最大化指派问题匈牙利算法

最大化指派问题匈牙利算法匈牙利算法,也称为Kuhn-Munkres算法,是用于解决最大化指派问题(Maximum Bipartite Matching Problem)的经典算法。
最大化指派问题是在一个二分图中,找到一个匹配(即边的集合),使得匹配的边权重之和最大。
下面我将从多个角度全面地介绍匈牙利算法。
1. 算法原理:匈牙利算法基于增广路径的思想,通过不断寻找增广路径来逐步扩展匹配集合,直到无法找到增广路径为止。
算法的基本步骤如下:初始化,将所有顶点的标记值设为0,将匹配集合初始化为空。
寻找增广路径,从未匹配的顶点开始,依次尝试匹配与其相邻的未匹配顶点。
如果找到增广路径,则更新匹配集合;如果无法找到增广路径,则进行下一步。
修改标记值,如果无法找到增广路径,则通过修改标记值的方式,使得下次寻找增广路径时能够扩大匹配集合。
重复步骤2和步骤3,直到无法找到增广路径为止。
2. 算法优势:匈牙利算法具有以下优势:时间复杂度较低,匈牙利算法的时间复杂度为O(V^3),其中V是顶点的数量。
相比于其他解决最大化指派问题的算法,如线性规划算法,匈牙利算法具有更低的时间复杂度。
可以处理大规模问题,由于时间复杂度较低,匈牙利算法可以处理大规模的最大化指派问题,而不会因为问题规模的增加而导致计算时间大幅增加。
3. 算法应用:匈牙利算法在实际中有广泛的应用,例如:任务分配,在人力资源管理中,可以使用匈牙利算法将任务分配给员工,使得任务与员工之间的匹配最优。
项目分配,在项目管理中,可以使用匈牙利算法将项目分配给团队成员,以最大程度地提高团队成员与项目之间的匹配度。
资源调度,在物流调度中,可以使用匈牙利算法将货物分配给合适的运输车辆,使得货物与运输车辆之间的匹配最优。
4. 算法扩展:匈牙利算法也可以扩展到解决带权的最大化指派问题,即在二分图的边上赋予权重。
在这种情况下,匈牙利算法会寻找一个最优的匹配,使得匹配边的权重之和最大。
Kuhn-Munkres算法

Kuhn-Munkres算法KmKuhn-Munkres算法⼀种⽤于进⾏⼆分图完全匹配的算法前pre技能匈⽛利算法及增⼴路标顶对于图G(U∪V,E)。
对于x∈U,定义Lx i。
对于i∈V。
定义Ly i。
这个玩意叫做标顶,是⼀种⼈为构造的数值。
⽤于进⾏⼆分图完全匹配可⾏标顶对于所有的边,假设权值是W,⽅向是x→y,则是算法执⾏中,恒定满⾜Lx x+Ly y≥W相等⼦图相等⼦图包括U∪V,但只包括满⾜W=Lx x+Ly y的边若相等⼦图有完全匹配,则原图有完全匹配实现概括通过更改标顶,找出相等⼦图。
实现具体扩⼤相等⼦图假设当前相等⼦图⽆法进⾏完全匹配,则⾄少有⼀个点u,从其出发⽆法找到增⼴路则我们需要修改标顶,使更多的边参与进来。
假设我们现在已经知道了⼀个M,这个M是使其他边增加到相等⼦图的最⼩标顶修改量然后我们令所有的Lx i减去M,所有的Ly i加上M正确性?假设我们现在在相等⼦图中在U中已经被匹配的点x,则我们规定x∈A,否则x∈A′相似的,对于x∈V,若x已经被匹配上,则x∈B,否则x∈B′对于⼀条边(x→y,权值(代价)是W)若x∈A,y∈B,仍满⾜Lx x+Ly y=W若x∈A′,y∈B′,则为Lx x+Ly y≥W,即是原本就不在交替路中的的依旧不在若x∈A′,y∈B,则Lx x+Ly y增加,不会被添加进⼊若x∈A,y∈B′,则Lx x+Ly y有所减少,可能会被添加其他关于若x∈A′,y∈B,则Lx x+Ly y增加,不会被添加进⼊若x∈A,y∈B′,则Lx x+Ly y有所减少,可能会被添加对于上边这句,是为了保证在将⼀个点x,x∈U进⾏匹配时,只会相应的引⼊y,y∈V,⽽不会引⼊U中的点。
M如何计算?M的⼤⼩取决于没有被加到相等⼦图中的最⼤边的⼤⼩,即是Lx x+Ly y−W⽽这个我们在寻找增⼴路的时候就可以顺带更新。
其他M的贪⼼选取保证了最⼤权。
个⼈理解是损失最⼩的代价,使其可以加⼊到相等⼦图代码using std::max;using std::min;const int maxn=500;const int inf=0x7fffffff;int M[maxn][maxn];int m[maxn][maxn];int lx[maxn],ly[maxn],mins[maxn],pat[maxn];int S[maxn],T[maxn],tot;int vis[maxn];int n;bool find(int x){S[x]=1;for(int i=1;i<=n;i++){if(T[i]) continue;int s=lx[x]+ly[i]-m[x][i];if(!s){T[i]=1;if(!pat[i]||find(pat[i])){pat[i]=x;return true;}}elsemins[i]=min(mins[i],s);}return false;}int KM(){for(int i=1;i<=n;i++) lx[i]=-inf;for(int i=1;i<=n;i++)for(int j=1;j<=n;j++)lx[i]=max(lx[i],m[i][j]),ly[i]=0;memset(pat,0,sizeof(pat));for(int i=1;i<=n;i++){for(int j=1;j<=n;j++)mins[j]=inf;while(1){memset(T,0,sizeof(T));memset(S,0,sizeof(S)); if(find(i)) break;int Min=inf;for(int j=1;j<=n;j++) Min=min(Min,mins[j]);for(int j=1;j<=n;j++){if(S[j]) lx[j]-=Min;if(T[j]) ly[j]+=Min;}}}int ans=0;for(int i=1;i<=n;i++)ans+=m[pat[i]][i];return ans;}Processing math: 100%。
kuhntucker定理

kuhntucker定理Kuhn-Tucker定理是最优化理论中的一个重要定理,用于描述在约束条件下的极值问题。
该定理给出了一组必要条件,使得一个非线性规划问题的解可以被判定为最优解。
以下是Kuhn-Tucker定理的主要内容:设给定一个非线性规划问题,目标函数为f(x),约束条件为g_i(x) ≤0,h_i(x) = 0,其中x 是决策变量,g_i(x) 和h_i(x) 是约束函数。
Kuhn-Tucker定理的主要结论是:如果x* 是一个可行解,并且满足一定条件(Kuhn-Tucker条件),那么x* 就是一个最优解。
Kuhn-Tucker条件包括以下几个方面:1. 约束条件的可行性:所有的约束条件必须满足,即g_i(x*) ≤0 和h_i(x*) = 0。
2. 梯度条件:目标函数的梯度和约束条件的梯度的线性组合必须为零,即存在拉格朗日乘子λ_i 和μ_i,使得满足以下条件:∇f(x*) + ∑[λ_i∇g_i(x*)] + ∑[μ_i∇h_i(x*)] = 03. 非负性条件:拉格朗日乘子λ_i 和μ_i 必须非负,即λ_i ≥0 和μ_i ≥0。
4. 互补松弛条件:拉格朗日乘子与约束条件的乘积为零,即λ_i * g_i(x*) = 0 和μ_i * h_i(x*) = 0。
这意味着当某个约束条件不活跃(对应的λ_i 为零)时,该约束条件的梯度应为零;当某个等式约束条件不是活跃约束(对应的μ_i 为零)时,该等式约束条件的梯度应为零。
通过满足上述Kuhn-Tucker条件,可以验证一个解是否为非线性规划问题的最优解。
需要注意的是,Kuhn-Tucker定理是一个必要条件定理,即如果一个解不满足Kuhn-Tucker条件,则它不一定是最优解。
因此,在应用Kuhn-Tucker定理时,还需要进一步考虑其他可能的情况和条件,以确保找到真正的最优解。
最优匹配
④ 对与xi邻接且尚未给标号的yj都给定标号i. 若所有的 yj 都是M的饱和点,则转向⑤,否则 逆向返回. 即由其中M的任一个非饱和点 yj 的标 号i 找到xi ,再由 xi 的标号k 找到 yk ,…,最后由 yt 的标号s找到标号为0的xs时结束,获得M-增广路 xs yt … xi yj , 记E(P) ={xs yt , … , xi yj },重新记M 为M⊕E(P),将所有标记标号清空,转向①.
二部图的最佳匹配算法: 可行顶点标号法(Kuhn-Munkres算法):
算法基本思想:通过点标记将赋权图转化为非赋权 图,再用匈牙利算法求最大匹配
求完备二部赋权图G = (X, Y, E, F )的最佳匹 配算法迭代步骤: 设G =(X, Y, E, F)为完备的二部赋权图,L是 其一个初始可行点标记,通常取 L(x) = max {F (x y) | y∈Y}, x∈X, L(y) = 0, y∈Y.
二部图赋权矩阵
Y:
y1
y2
邻接矩阵
二部图的匹配及其应用
Hall定理 设G = ( X, Y, E )为二部图, 则① G存在 饱和X的每个点的匹配的充要条件是 对任意S X ,有 | N (S ) | ≥ | S | . 其中, N (S ) = {v | u∈S, v与u相邻}. ② G存在完美匹配的充要条件是 对任意S X 或S Y 有 | N (S ) | ≥ | S | .
解 ① 取初始匹配M={x2 y2 , x3 y3 , x5 y5} ② 给X中M的两个非饱和点x1,x4都给以标号0和标 记* (如下图所示).
二部图的匹配及其应用
例18:求下图的最大匹配。 *0 *2 *3
匈亚利算法:
*0
km匹配算法流程

km匹配算法流程The KM matching algorithm, also known as the Kuhn-Munkres algorithm, is a classic method for solving the assignment problem in operations research. It aims to find the optimal assignment of a set of tasks to a set of agents, minimizing the total cost of the assignments. The algorithm is based on the concept of a cost matrix, where each element represents the cost of assigning a particular task to a particular agent.KM匹配算法,也称为Kuhn-Munkres算法,是运筹学中解决分配问题的经典方法。
其目标是为一系列任务找到一系列代理的最优分配,以最小化分配的总成本。
该算法基于成本矩阵的概念,其中每个元素表示将特定任务分配给特定代理的成本。
The KM algorithm proceeds in several steps. Firstly, it initializes the cost matrix and introduces slack variables to represent the difference between the cost of a particular assignment and the minimum cost row or column. Then, it searches for zero-cost assignments, which represent optimal matches between tasks and agents. If no zero-cost assignments are found, the algorithm proceeds to the next step.KM算法包括几个步骤。
最大权匹配KM算法

最大权匹配KM算法
KM算法(Kuhn–Munkres算法,也称为匈牙利算法)是由Kuhn于
1955年和Munkres于1957年分别提出的,用于解决二分图最大匹配问题。
该算法的核心思想是基于匈牙利算法的增广路径,通过构建一个增广路径
来不断更新匹配,直到无法找到增广路径为止。
算法流程如下:
2.从G的每个未匹配顶点开始,通过增广路径将其标记为可增广点;
3.当存在增广路径时,将匹配的边进行反向操作,直到不存在增广路径;
4. 利用增广路径的反向操作可以修改lx和ly的值,使其满足特定
约束条件;
5.通过相等子图的扩展来实现增广路径的;
6.重复步骤3-5,直到不存在更多的增广路径;
7.返回找到的最大匹配。
具体实现时,对于增广路径的可以利用DFS或BFS等方法进行,当找
到一个增广路径时,通过反向操作修改匹配情况,并更新lx和ly的值。
同时,算法还可以使用增广路径来调整优化标号,以减少匹配时间。
KM算法是一种高效的解决最大权匹配问题的方法,其时间复杂度为
O(V^3),其中V为图的顶点数。
算法的核心思想是利用二分图中的相等子
图来查找增广路径,并通过修改顶点的标号来实现最大匹配。
总之,最大权匹配KM算法是一个解决带权无向二分图最大匹配问题
的高效算法,通过不断寻找增广路径并调整顶点的标号来实现最大权匹配。
它的思想简单而有效,可以广泛应用于各种实际问题中。
匈牙利匹配算法的原理

匈牙利匹配算法的原理匈牙利匹配算法(也被称为二分图匹配算法或者Kuhn-Munkres算法)是用于解决二分图最大匹配问题的经典算法。
该算法由匈牙利数学家Dénes Kőnig于1931年提出,并由James Munkres在1957年进行改进。
该算法的时间复杂度为O(V^3),其中V是图的顶点数。
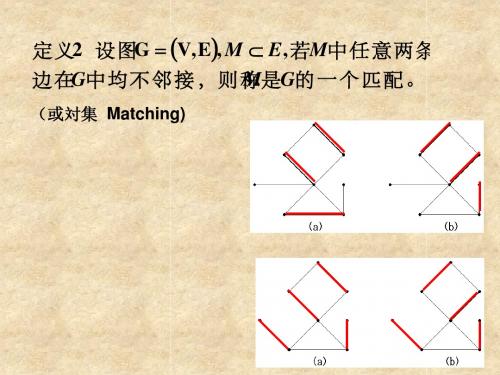
匹配问题定义:给定一个二分图G=(X,Y,E),X和Y分别代表两个不相交的顶点集合,E表示连接X和Y的边集合。
图中的匹配是指一个边的集合M,其中任意两条边没有公共的顶点。
匹配的相关概念:1.可增广路径:在一个匹配中找到一条没有被占用的边,通过这条边可以将匹配中的边个数增加一个,即将不在匹配中的边添加进去。
2. 增广路径:一个可增广路径是一个交替序列P=v0e1v1e2v2...ekvk,其中v0属于X且不在匹配中,v1v2...vk属于Y且在匹配中,e1e2...ek在原图中的边。
3.增广轨:一个交替序列形如V0E1V1E2...EkVk,其中V0属于X且不在匹配中,V1V2...Vk属于Y且在匹配中,E1E2...Ek在原图中的边。
增广轨是一条路径的特例,它是一条从X到Y的交替序列。
1.初始时,所有的边都不在匹配中。
2.在X中选择一个点v0,如果v0已经在匹配中,则找到与v0相连的在Y中的顶点v1、如果v1不在匹配中,则(v0,v1)是可增广路径的第一条边。
3. 如果v1在匹配中,则找到与v1相连的在X中的顶点v2,判断v2是否在匹配中。
依此类推,直到找到一个不在匹配中的点vn。
4.此时,如果n是奇数,则(n-1)条边在匹配中,这意味着我们找到了一条增广路径。
如果n是偶数,则(n-1)条边在匹配中,需要进行进一步的处理。
5.如果n是偶数,则将匹配中的边和非匹配中的边进行颠倒,得到一个新的匹配。
6.对于颠倒后的匹配,我们再次从第2步开始,继续寻找增广路径。
7.重复步骤2到步骤6,直到找不到可增广路径为止,此时我们得到了最大匹配。
Ku二分图最大权匹配(KM算法)hn

Kuhn-Munkres 算法Maigo 的 KM 算法讲解(的确精彩)KM 算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转 化为求完备匹配的问题的。
设顶点 Xi 的顶标为 A[i],顶点 Yi 的顶标为 B[i],顶点 Xi 与 Yj 之间的边权为 w[i,j]。
在算法执行过程中 的任一时刻,对于任一条边(i,j), A[i]+B[j]>=w[i,j]始终成立。
KM 算法的正确 性基于以下定理: * 若由二分图中所有满足 A[i]+B[j]=w[i,j]的边(i,j)构成的子图 (称做相等子 图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
这个定理是显然的。
因为对于二分图的任意一个匹配,如果它包含于相 等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相 等子图,那么它的边权和小于所有顶点的顶标和。
所以相等子图的完备匹配 一定是二分图的最大权匹配。
初始时为了使 A[i]+B[j]>=w[i,j]恒成立,令 A[i]为所有与顶点 Xi 关联的边 的最大权,B[j]=0。
如果当前的相等子图没有完备匹配,就按下面的方法修改 顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个 X 顶点,我们 找不到一条从它出发的交错路。
这时我们获得了一棵交错树,它的叶子结点 全部是 X 顶点。
现在我们把交错树中 X 顶点的顶标全都减小某个值 d,Y 顶 点的顶标全都增加同一个值 d,那么我们会发现:两端都在交错树中的边(i,j),A[i]+B[j]的值没有变化。
也就是说,它原来属于 相等子图,现在仍属于相等子图。
两端都不在交错树中的边(i,j),A[i]和 B[j]都没有变化。
也就是说,它原来属于 (或不属于)相等子图,现在仍属于(或不属于)相等子图。
X 端不在交错树中,Y 端在交错树中的边(i,j),它的 A[i]+B[j]的值有所增大。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
最优匹配(Kuhn_Munkras算法)
//**Start of PerfectMatch*******************************
//Name:PerfectMatch by Kuhn_Munkras O(n^3)
//Description:w is the adjacency matrix,nx,ny are the size of x and y, //lx,ly are the lables of x and y,fx[i],fy[i]is used for marking
//whether the i-th node is visited,matx[x]means x match matx[x], //maty[y]means y match maty[y],actually,matx[x]is useless,
//all the arrays are start at1
int nx,ny,w[MAXN][MAXN],lx[MAXN],ly[MAXN];
int fx[MAXN],fy[MAXN],matx[MAXN],maty[MAXN];
int path(int u)
{
int v;
fx[u]=1;
for(v=1;v<=ny;v++)
if((lx[u]+ly[v]==w[u][v])&&(fy[v]<0)){
fy[v]=1;
if((maty[v]<0)||(path(maty[v]))){
matx[u]=v;
maty[v]=u;
return(1);
}//end of if((maty[v]...
}//end of if((lx[u]...
return(0);
}//end of int path()
int PerfectMatch()
{
int ret=0,i,j,k,p;
memset(ly,0,sizeof(ly));
for(i=1;i<=nx;i++){
lx[i]=-INF;
for(j=1;j<=ny;j++)
if(w[i][j]>lx[i])
lx[i]=w[i][j];
}//end of for(i...
memset(matx,-1,sizeof(matx));
memset(maty,-1,sizeof(maty));
for(i=1;i<=nx;i++){
memset(fx,-1,sizeof(fx));
memset(fy,-1,sizeof(fy));
if(!path(i)){
i--;
p=INF;
for(k=1;k<=nx;k++)
if(fx[k]>0)
for(j=1;j<=ny;j++)
if((fy[j]<0)&&(lx[k]+ly[j]-w[k][j]<p))
p=lx[k]+ly[j]-w[k][j];
for(j=1;j<=ny;j++)ly[j]+=(fy[j]<0?0:p);
for(k=1;k<=nx;k++)lx[k]-=(fx[k]<0?0:p);
}//end of if(!path(i))
}//end of for(i...
for(i=1;i<=ny;i++)ret+=w[maty[i]][i];
return ret;
}//end of int PerfectMatch()
//**End of PerfectMatch*********************************。