四川大学编译原理期末复习总结
《编译原理》期末复习资料(完整版)
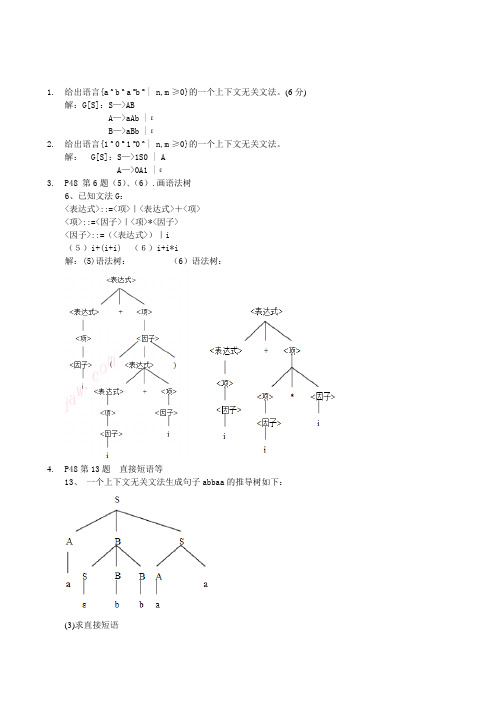
1.给出语言{a n b n a m b m | n,m≥0}的一个上下文无关文法。
(6分)解:G[S]:S—>ABA—>aAb |εB—>aBb |ε2.给出语言{1 n 0 m 1 m0 n | n,m≥0}的一个上下文无关文法。
解:G[S]:S—>1S0 | AA—>0A1 |ε3.P48 第6题(5)、(6).画语法树6、已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i(5)i+(i+i) (6)i+i*i解:(5)语法树:(6)语法树:4.P48第13题直接短语等13、一个上下文无关文法生成句子abbaa的推导树如下:(3)求直接短语解:直接短语有:a ε bP102例题6.1及其分析.( 后加画语法树)例6.1 设文法G[S]为:(1)S—>aAcBe(2)A—>b(3)A—>Ab(4)B—>d对输入串abbcde#进行分析,检查该符号串是否是G[S]的句子。
步骤符号栈输入符号串动作(1)# abbcde# 移进(2)#a bbcde# 移进(3)#ab bcde# 归约(A—>b)(4)#aA bcde#移进(5)#aAb cde# 归约(A—>Ab)(6)#aA cde# 移进(7)#aAc de# 移进(8)#aAcd e# 归约(B—>d)(9)#aAcB e# 移进(10)#aAcBe # 归约(S—>aAcBe)(11)#S # 接受一、计算分析题(60%)1、正规式→ NFA→ DFA→最简DFAP72第1题(1)、(4);第一题1、构造下列正规式相应的DFA.(1)1(0|1)*101解:先构造NFA0 1S AA A ABAB AC ABAC A ABZABZ AC AB除S,A外,重新命名其他状态,令AB为B、AC为C、ABZ为D,因为D含有Z(NFA的终态),所以0 1S AA A BB C BC A DD C B(4) b((ab)*|bb)*ab解:先构造NFA得到DFA如下所示:P72第4题(a)4、把下图确定化和最小化解:确定化:a b0 01 101 01 11 0、{1},其中A为初态,A,B为终态,因此有:a bA B CB B CC A最小化::初始分划得终态组{A,B},非终态组{C}Π0:{A,B},{C},对终态组进行审查,判断A和B是等价的,故这是最后的划分。
编译原理复习总结

编译原理复习总结⼀、编译器概述1、名词解释1.1解释下列名词源语⾔:被翻译器翻译的语⾔,⽤于书写源程序的语⾔。
⽬标语⾔:被翻译器翻译之后得到的语⾔,⽤于书写⽬标程序的语⾔翻译器:能够完成从⼀种语⾔到另⼀种语⾔的变换的软件编译器:⼀种特殊的翻译器,要求⽬标语⾔⽐源语⾔低级解释器:解释器是不同于编译器的另⼀种语⾔处理器。
解释器不像编译器那样通过翻译来⽣成⽬标程序,⽽是直接执⾏源程序所指定的运算。
2、编译阶段1.2典型的编译器可以划分成⼏个主要的逻辑阶段?各阶段的主要功能是什么?典型的编译器可以划分成七个主要的逻辑阶段,分别是词法分析器、语法分析器、语义分析器、中间代码⽣成器、独⽴于机器的代码优化器、代码⽣成器、依赖于机器的代码优化器。
各阶段的主要功能:(1)词法分析器:词法分析阅读构成源程序的字符流,按编程语⾔的词法规则把它们组成词法记号流。
(2)语法分析器:按编程语⾔的语法规则检查词法分析输出的记号流是否符合这些规则,并依据这些规则所体现出的该语⾔的各种语⾔构造的层次性,⽤各记号的第⼀元建成⼀种树形的中间表⽰,这个中间表⽰⽤抽象语法的⽅式描绘了该记号流的语法情况。
(3)语义分析器:使⽤语法树和符号表中的信息,依据语⾔定义来检查源程序的语义⼀致性,以保证程序各部分能有意义地结合在⼀起。
它还收集类型信息,把它们保存在符号表或语法树中。
(4)中间代码⽣成器:为源程序产⽣更低级的显⽰中间表⽰,可以认为这种中间表⽰是⼀种抽象机的程序。
(5)独⽴于机器的代码优化器:试图改进中间代码,以便产⽣较好的⽬标代码。
通常,较好是指执⾏较快,但也可能是其他⽬标,如⽬标代码较短或⽬标代码执⾏时能耗较低。
(6)代码⽣成器:取源程序的⼀种中间表⽰作为输⼊并把它映射到⼀种⽬标语⾔。
如果⽬标语⾔是机器代码,则需要为源程序所⽤的变量选择寄存器或内存单元,然后把中间指令序列翻译为完成同样任务的机器指令序列。
(7)依赖于机器的代码优化器:试图改进⽬标机器代码,以便产⽣较好的⽬标机器代码。
编译原理课程期末总结

编译原理课程期末总结一、引言编译原理是计算机科学与技术专业必修的一门课程,主要讲授计算机程序语言的组织规则和程序的翻译方法。
本学期的编译原理课程,从基本概念开始,逐渐深入到词法分析、语法分析、语义分析和代码生成等内容。
通过学习编译原理,我对程序的编写和翻译有了更深入的理解,并且提高了编写高效程序的能力。
本文将对本学期编译原理课程的学习内容以及个人体会进行总结和归纳。
二、课程学习内容1. 基本概念在编译原理的第一节课中,老师给我们介绍了编译原理的基本概念。
编译器是将源语言程序翻译成目标语言程序的一种软件。
它包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段。
我们学习了编译器的整体结构和各个阶段的作用。
2. 词法分析词法分析是编译器的第一阶段,它负责将源程序分割成一个个单词(Token)。
在本学期的编译原理课程中,我们学习了正则表达式、DFA(Deterministic Finite Automaton)和NFA(Nondeterministic Finite Automaton)的概念。
通过实践,我了解了如何用正则表达式描述词法单元的集合,并将正则表达式转化为NFA和DFA。
3. 语法分析语法分析是编译器的第二阶段,它负责将词法分析得到的单词序列解析成语法树。
在本学期的编译原理课程中,我们学习了上下文无关文法和语法分析算法。
我通过实现LL(1)语法分析器和LR(1)语法分析器,深入理解了语法分析的原理与方法。
4. 语义分析语义分析是编译器的第三阶段,它负责对语法树进行静态检查和语义处理。
在本学期的编译原理课程中,我们学习了符号表的管理和使用、类型检查和类型转换等内容。
通过实践,我掌握了如何设计和实现一个简单的语义分析器。
5. 中间代码生成中间代码生成是编译器的第四阶段,它负责将语法树转化为中间代码。
在本学期的编译原理课程中,我们学习了三地址码和四元式的表示方法,以及中间代码的生成和优化等内容。
川大编译原理复习要点

1.编译的各个阶段扫描程序(scanner)在这个阶段编译器实际阅读源程序(通常以字符流的形式表示)。
扫描程序执行词法分析(Lexical analysis):它将字符序列收集到称作记号(t o k e n)的有意义单元中,记号同自然语言,如英语中的字词相似。
语法分析程序(parser)语法分析程序从扫描程序中获取记号形式的源代码,并完成定义程序结构的语法分析(syntax analysis),这与自然语言中句子的语法分析类似。
语法分析定义了程序的结构元素及其关系。
通常将语法分析的结果表示为分析树(parse tree)或语法树(syntax tree)。
语义分析程序(semantic analyzer)分析程序的静态语义,包括包括声明和类型检查。
源代码优化程序(source code optimizer),代码生成器(code generator),目标代码优化程序(target code optimizer)。
2.编译器的前端(front end),后端(back end),遍(passes)扫描程序、分析程序和语义分析程序是前端,代码生成器是后端。
编译器发现,在生成代码之前多次处理整个源程序很方便。
这些重复就是遍(p a s s)3.编译器,汇编器和解释器之间的区别解释程序是如同编译器的一种语言翻译程序。
它与编译器的不同之处在于:它立即执行源程序而不是生成在翻译完成之后才执行的目标代码。
汇编程序是用于特定计算机上的汇编语言的翻译程序。
有时,编译器会生成汇编语言以作为其目标语言,然后再由一个汇编程序将它翻译成目标代码。
4.扫描,分析(语法,词法)的任务扫描的任务是将源程序读作字符文件并将其分为若干个记号扫描程序的任务是从源代码中读取字符并形成由编译器的以后部分(通常是分析程序)处理的逻辑单元。
由扫描程序生成的逻辑单元称作记号(t o k e n)分析的任务是确定程序的语法,或称作结构分析程序的任务是从由扫描程序产生的记号中确定程序的语法结构,以及或隐式或显式地构造出表示该结构的分析树或语法树5.上下文无关文法,最左推导,BNF,EBNF,乔姆斯基文法层次上下文无关文法说明程序设计语言的语法结构,利用了与正则表达式中极为类似的命名惯例和运算。
《编译原理》期末复习资料汇总

《编译原理》期末复习资料【题1】1.(a|b)*(aa|bb)(a|b)*画出状态转换图。
Ia Ib①1,2,3 2,3,4 2,3,5②2,3,4 2,3,4,6,7,8 2,3,5③2,3,5 2,3,4 2,,3,5,6,7,8④2,3,4,6,7,8 2,3,4,6,7,8 2,3,5,7,8⑤2,3,5,6,7,8 2,3,4,7,8 2,3,5,6,7,8⑥2,3,5,7,8 2,3,4,7,8 2,3,5,6,7,8⑦2,3,4,7,8 2,3,4,6,7,8 2,3,5,7,8Ia Ib1 2 32 4 33 2 54 4 65 7 56 7 57 4 6新的状态转换图如下:(1)A={1,2,3},B={4,5,6,7} Aa={2,4} ×(2)A={1,3},B={2},C={4,5,6,7} Aa={2}⊂B,Ab={3,5} ×(3)A={1},B={2},C={3},D={4,5,6,7}(单元素可以不用看,必有,古先看D)Da={4,7}⊂D,Db={5,6}⊂D,Aa={2}⊂B,Ab={3}⊂C,Ba={4}⊂D,Bb={3}⊂C,Ca={2}⊂B,Cb={5}⊂C,则有baA B CB D CC B DD D D2.(a*|b*)b(ba)*的状态转换图。
Ia Ib①1,2,3,4 2,4 3,4,5,6,8②2,4 2,4 5,6,8③3,4,5,6,8 --- 3,4,5,6,7,8④5,6,8 --- 7⑤3,4,5,6,7,8 6,8 3,4,5,6,7,8⑥7 6,8 ---⑦6,8 --- 7Ia Ib1 2 32 2 43 --- 54 --- 65 7 56 7 ---7 --- 6新的状态转换图如下:化简:(用终结状态与非终结状态,然后输出状态一致分一类)。
(1)A={1,2,6},B={3,4,5,7} Aa={2} ×(2)A={1,2},B={6},C={3,4,7},D={5} Cb={5,6} ×(只要有一个不属于任何一个集合,就不行) (3)A={1,2},B={6},C={3},D={4,7},E={5} Ab={3,4} × (4) A={1},B={2},C={6},D={3},E={4,7},F={5} Aa={2}⊂B ,Ab={3}⊂D ,Ba={2}⊂B ,Bb={4}⊂E ,Ca={7}⊂E ,Db={5}⊂F ,Eb={6}⊂C ,Fa={7}⊂E ,Fb={5}⊂Fa b A B D B B E C E --- D --- F E --- C FEF[注意事项]:[知识要点]:正则表达式:******|,|,)|(,)|(,)(,,|,ab a b a a b a a b a ab ab b a a{}a a aaa aa a a ,,,,*ε⇔;{}b a a b a ,)b (|⇔或;{}ab b a ab ⇔)(和;(){},,,,*ababab abab ab ab ε⇔;()()()(){} ,,,,,,||||*baba aabb aab b a b a b a b a b a ε⇔⇔()*|b a a 是最左边一个字母一定是a ,其余字母为b a 、的任意组合,不包括ε。
四川大学编译原理复习要点

四川大学编译原理复习要点2013版一、编译器各个阶段的功能,输入、输出,前端、后端1)词法分析:将字符序列收集到称作记号(t o k e n)的有意义单元中扫描程序输入:源代码输出:记号2)语法分析:从扫描程序中获取记号形式的源代码,并完成定义程序结构的语法分析,语法分析定义了程序的结构元素及其关系。
输入:记号输出:语法树3)语义分析程序:分析程序的静态语义,包括声明和类型检查。
输入:语法树输出:注释树4)源代码优化程序:编译器通常包括许多代码改进或优化步骤。
绝大多数最早的优化步骤是在语义分析之后完成的,而此时代码改进可能只依赖于源代码。
【对源代码进行优化,并产生中间代码】输入:注释树输出:中间代码5)目标代码生成:得到中间代码,生成目标机器的代码代码生成器输入:中间代码输出:目标代码6)目标代码优化程序:编译器改进由代码生成器生成的目标代码。
输入:目标代码输出:目标代码扫描程序、分析程序和语义分析程序是前端,代码生成器是后端,前后端分开的好处:可以给编译器带来更方便的可移植性,此时的编译器既能改变源代码,又能改变目标代码。
【遍】编译器发现,在生成代码之前多次处理整个源程序很方便,这些重复就是遍。
首遍是从源中构造一个语法树或中间代码,在它之后的遍是由处理中间表示、向它增加信息、更换结构或生成不同的表示组成二、解释器和编译器的区别与联系?读入源语言后,解释器和编译器都要进行词法分析、语法分析和语义分析,之后,二者开始有所分别。
解释器在语义分析后选择了直接执行语句;编译器在语义分析后选择将将语义存储成某一种中间语言,之后通过不同的后端翻译成不同的机器语言(可执行程序)编译器是把源语言(如C,Pascal,java等高级语言)转换为目标语言(汇编语言、机器语言等低级语言),要产生目标代码。
解释器是以一个源语言(C,Pascal,java等高级语言)为输入,一边解释一边执行源程序,但不产生目标代码。
三、算法描述(伪代码)p41构造一个扫描程序的自动过程:正则表达式→NFA→DFA→程序1、正则表达式→NFA(1)建立字母表。
编译原理复习汇总
复习汇总一、第一章概述1.文法与自动机的等价1)0型文法—图灵机2)1型文法—线性有界非确定图灵机3)2型文法—非确定下推自动机4)3型文法—有限状态自动机2.编译技术的应用1)语法制导的结构化编辑器2)程序格式化工具3)软件测试工具4)程序理解工具5)高级语言的翻译工具6)等等3.从面向机器的语言到面向人类的语言(结合第二章第9小点理解)1)面向机器的语言:机器指令,汇编语言2)面向人类的语言:通用程序设计语言,数据查询语言,形式化描述语言(正规式,产生式)等等。
4.各语言的分类(结合第二章第9小点理解)1)过程式语言,面向对象语言:通用程序设计语言。
2)函数语言:面向特点领域的,递归特性。
例如LISP语言3)说明性,非算法式语言:LEX/YACC,SQL。
4)脚本式语言:Shell语言5.语言之间的转换(李静PPT41)1)高级语言之间的转换一般称为预处理或转换。
2)高级语言翻译成汇编语言或机器语言称之为编译。
3)把汇编语言翻译成机器语言称之为汇编。
4)将一个汇编语言程序汇编为可在另一台机器上运行的机器指令称之为交叉汇编。
5)把机器语言翻译成汇编语言称之为反汇编。
6)把汇编语言翻译成高级语言称之为反编译。
6.编译器和解释器1)编译器●源程序的翻译和翻译后的程序的运行是两个不同的阶段。
◆编译阶段:用户输入源程序,经过编译器的处理,生成目标程序。
◆目标程序的运行阶段:根据要求输入数据,得出结果。
2)解释器(凡是可以采用编译器的地方均可以采用解释器)●解释器把翻译和运行结合到一起,编译一段源程序,紧接着就执行它。
这种方式称为解释。
7.解释器的优点(对比与编译器)1)具有较好的动态特性。
2)具有较好的移植特性。
8.解释器的缺点(对比于编译器)1)相比于编译器需花费大量的时间。
2)占用更多的内存空间。
9.编译器的工作阶段(结合第二章6小点红色部分理解)1)源程序->词法分析器->语法分析器->语义分析器->中间代码生成器->代码优化器->目标代码生成器->目标代码2)工作过程中的每个阶段均采用了符号表管理器,出错处理器。
编译原理-期末复习
编译原理-期末复习编译原理⼀、单选题1、将编译程序分为若⼲个“遍”是为了()。
BA.提⾼程序的执⾏效率B.使程序的结构更加清晰C.利⽤有限的机器内存并提⾼机器的执⾏效率D.利⽤有限的机器内存但降低了机器的执⾏效率2、构造编译程序应掌握()。
DA.源程序B.⽬标语⾔C.编译⽅法D.以上三项都是3、变量应当()。
CA.持有左值B.持有右值C.既持有左值⼜持有右值D.既不持有左值也不持有右值4、编译程序绝⼤多数时间花在()上。
DA.出错处理B.词法分析C.⽬标代码⽣成D.管理表格5、()不可能是⽬标代码。
DA.汇编指令代码B.可重定位指令代码C.绝对指令代码D.中间代码6、编译程序是对()。
DA.汇编程序的翻译B.⾼级语⾔程序的解释执⾏C.机器语⾔的执⾏D.⾼级语⾔的翻译7、正规式M1和M2等价是指()。
CA.M1和M2的状态数相等B.M1和M2的有象弧条数相等C.M1和M2所识别的语⾔集相等D.M1和M2状态数和有象弧条数相等8、如果⽂法G是⽆⼆义的,则它的任何句⼦()。
AA.最左推导和最右推导对应的语法树必定相同。
B.最左推导和最右推导对应的语法树可能相同。
C.最左推导和最右推导必定相同。
D.可能存在两个不同的最左推导,但它们对应的语法树相同。
9、⽂法G:S→S+T|TT→T*P|PP→(S)|i句型P+T+i的短语有()BA.i,P+TB. P,P+T,i,P+T +iB.P+T + i D. P,P+T,i10、产⽣正规语⾔的⽂法为()。
DA.0型B.1型C.2型D.3型11、⽂法G:S→b|?|(T)T→T?S|S则FIRSTVT(T)=() CA.{b,?,(}B.{b,?,)}C.{b,?,(,?}D.{b,?,),?}12、给定⽂法:A→bA | cc,下⾯的符号串中,为该⽂法句⼦的是()。
A①cc ②bcbc ③bcbcc ④bccbcc ⑤bbbcc可选项有:A.①B.①③④⑤C.①④D.①④⑤13、采⽤⾃上⽽下分析,必须()。
编译原理期末考试复习整理(详细列出考试重点+重点例题)
编译原理期末考试复习整理(详细列出考试重点+重点例题)本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March目录第一章 (3)词法分析: (3)语义法分析 (3)中间代码 (3)第二章 (3)1.根据语言写出文法 (4)2.根据文法写语,描述其特点(必考大题2-3类型) (4)3.文法的规范推导、语法树、短语、句柄(必考大题,2-7,2-11) (6)第三章 (11)1.给出一个正规文法 (左线性、右线性方法),写出其状态转换图(必考) (11)1.1右线性文法写出状态转换图 (必考) (11)1.2状态转换图写出右线性文法G (12)1.3左线性文法写出状态转换图 (必考) (13)2.非确定自动机的确定化 (14)第四章 (15)第五章 (15)属性文法与属性翻译文法 (15)逆波兰式(大题) (16)四元式(大题) (16)第一章词法分析:分析源程序的结构,判断它是否是相应程序设计语言的合法程序语义法分析的任务是根据语言的语义规则对语法分析得到的语法结构进行静态的语义检查(确定类型、类型与运算合法性检查、识别含义等),并且转换成另一种内部形式(语义树)表示出来或者直接用目标语言表示出来。
中间代码是一种结构简单、含义明确的记号系统,这种记号系统可以设计为多种多样的形式,重要的设计原则为两点:一是容易生成;二是便于优化、移值;三是容易将它翻译成目标代码第二章文法G定义为四元组(V N,V→,P,S )其中V N为非终结符号(或语法实体,或变量)集;V→为终结符号集;P为产生式(也称规则)的集合; V N,V→和P是非空有穷集。
S称作识别符号或开始符号,它是一个非终结符,至少要在一条产生式中作为左部出现。
V N和V→不含公共的元素,即V N ∩V→ = φ,通常用V 表示V N∪ V→,V称为文法G的字母表或字汇表。
四川大学编译原理期末试卷4套+复习资料
(2012-2013学年第2学期)一.简答题1.符号表的作用是什么?为了达到对其插入删除等操作的复杂度为O(1),需将其组织成什么数据结构。
2.分析树和语法书的区别。
3.什么是正规集。
4.什么叫句子,什么叫句型。
5.二义文法一定不是LL(1)二.给定文法 S→AA→A+A|B++ B→y1.画出句子y+++y++的分析树2.给出句子y+++y++的最右推导三.给定正则表达式(a|b)*abb1.使用thompson构造法构造等价的NFA。
2.用子集法对(1)得到的NFA进行确定化和最小化,得到等价的最小DFA。
3.使用双层多分支语句实现(2)得到的DFA。
写出伪代码。
四.给定文法statement→if-stmt|other|eif-stmt→if(exp)statement else-partelse-part→else statement|eexp→0|1写出递归下降子程序的伪代码。
五.给定文法S→[SX]|aX→e|+SY|YbY→e|-SXc1.对文法中的每一个非终结符构造First集和Follow集。
2.构造LL(1)分析表3.基于分析表,使用LL(1)对句子[a+a-ac]进行自顶向下的语法分析,给出每一步的动作及分析栈和输入串的变化情况。
六.给定文法E→E+T|TT→T*F|FF→(E)|id1.构造LR(0)项目的DFA:2.构造SLR(1)的分析表3.利用2得到的分析表对id+id*id进行自顶向下的语法分析。
七.1.给出构造Follow集合的算法描述2.给出SLR(1)算法的描述(2010-2011学年第2学期)1. 简答题 (12分)(1) 编译器的前端和后端分别包括哪几个阶段?前后端分开有什么好处?(2) 解释器和编译器有什么本质区别?(3) 词法分析和语法分析的功能分别是什么?(4) 分析树与抽象语法树有什么不同?2. 已知字母表∑= {a, b, c}∑上的语言L具有以下特征:(5分)(1) 若出现a,则其后至少紧跟两个c;(2) 若出现b,则其后至少紧跟一个c。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、简答题1.什么是编译程序答:编译程序是一种将高级语言程序(源程序)翻译成低级语言(目标程序)的程序。
将高级程序设计语言程序翻译成逻辑上等价的低级语言(汇编语言,机器语言)程序的翻译程序。
2.请写出文法的形式定义答:一个文法G抽象地表示为四元组 G=(Vn,Vt,P,S)–其中Vn表示非终结符号–Vt表示终结符号,Vn∪Vt=V(字母表),Vn∩Vt=φ–S是开始符号,–P是产生式,形如:α→β(α∈V+且至少含有一个非终结符号,β∈V*)3.语法分析阶段的功能是什么答:在词法分析的基础上,根据语言的语法规则,将单词符号串分解成各类语法短语(例:程序、语句、表达式)。
确定整个输入串是否构成语法上正确的程序。
4.局部优化有哪些常用的技术答:优化技术1—删除公共子表达式优化技术2—复写传播优化技术3—删除无用代码优化技术4—对程序进行代数恒等变换(降低运算强度)优化技术5—代码外提优化技术6—强度削弱优化技术7—删除归纳变量优化技术简介——对程序进行代数恒等变换(代数简化)优化技术简介——对程序进行代数恒等变换(合并已知量)5.编译过程分哪几个阶段答:逻辑上分五个阶段:词法分析、语法分析、语义分析与中间代码生成、代码优化、目标代码生成。
每个阶段把源程序从一种表示变换成另一种表示。
6. 什么是文法答:文法是描述语言的语法结构的形式规则。
是一种工具,它可用于严格定义句子的结构;用有穷的规则刻划无穷的集合;文法是被用来精确而无歧义地描述语言的句子的构成方式;文法描述语言的时候不考虑语言的含义。
7. 语义分析阶段的功能是什么答:对语法分析所识别出的各类语法范畴分析其含义,进行初步的翻译(翻译成中间代码);并对静态语义进行审查。
8.代码优化须遵循哪些原则答:等价原则:不改变运行结果有效原则:优化后时间更短,占用空间更少合算原则:应用较低的代价取得较好的优化效果9.词法分析阶段的功能是什么答:逐个读入源程序字符并按照构词规则切分成一系列单词任务:读入源程序,输出单词符号—滤掉空格,跳过注释、换行符—追踪换行标志,指出源程序出错的行列位置—宏展开,……10.什么是符号表答:符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。
这些信息一般以表格形式存储于系统中。
如常数表、变量名表、数组名表、过程名表、标号表等等,统称为符号表。
对于符号表组织、构造和管理方法的好坏会直接影响编译系统的运行效率。
11.什么是属性文法答:是在上下文无关文法的基础上,为每个文法符号(含终结符和非终结符)配备若干个属性值,对文法的每个产生式都配备了一组属性计算规则(称为语义规则)。
在语法分析过程中,完成语义规则所描述的动作,从而实现语义处理。
12.什么是基本块答:是指程序中一顺序执行的语句序列,其中只有一个入口语句和一个出口语句,入口是其第一个语句,出口是其最后一个语句。
13.代码优化阶段的功能是什么答:对已产生的中间代码进行加工变换,使生成的目标代码更为高效(时间和空间)。
14.文法分哪几类答:文法有四种:设有G=(Vn,Vt,P,S),不同类型的文法只是对产生式的要求不同:0型文法(短文文法):G的每个产生式αβ满足:α∈V+且α中至少含有一个非终结符,β∈V*1型文法(上下文有关文法):如果G的每个产生式αβ均满足|β|>=|α|,仅当Sε除外,但S不得出现在任何产生式的右部2型文法(上下文无关文法):G的每个产生式为Aβ, A是一非终结符,β∈V*3型文法(正规文法):G的每个产生式的形式都是:AαB或Aα,其中A,B是非终结符,α是终结符串。
(右线性文法)。
15.循环优化常用的技术有哪些答:代码外提;强度削弱;删除归纳变量。
16.什么是算符优先文法答:算符文法G的任何终结符a,b之间要么没有优先关系,若有优先关系,至多有中的一种成立,则G为一算符优先文法。
二、计算题(一)推导、最左推导、最右推导和语法树,复习表达式文法及相关例题。
1. 表达式的推导例:G = ({E}, {i, +, *, (, ) } , P , E)P:E E+E | E*E | (E) | i答:表达式(i)和(i+i)*i的推导:E (E) (i)E E*E (E)*E (E + E)*E (i + E)*E (i + i)*E (i + i)*iE E*E E*i (E)* i (E + E)*i (E+ i)*i (i + i)*i(i+i)*i的最左推导过程:E E*E (E)*E (E + E)*E (i + E)*E (i + i)*E (i + i)*i(i+i)*i的最右推导过程:E E*E E*i (E + E)*i (E+ i)*i (i + i)*i2.语法树例:对文法G = ({E}, {i, +, *, (, ) } , P , E)P:E E + E | E * E | ( E ) | i答:句子(i+i)*i 的语法树:例:G = ({E}, {i, +, *, (, ) } , P , E)P:E E + E | E * E | ( E ) | i答:句子( i * i + i)的语法树:(1) E (E) (E + E) (E * E + E) (i * E + E) (i *i + i)(二)给定语言求文法(三)逆波兰式(四)将for语句和if语句翻译成相应的四元式序列(五) 短语、素短语、最左素短语,FirstVT集和LastVT集的求解方法(复习第四章算符优先文法相关内容)1.短语、素短语、最左素短语集和LastVT集的求解方法例:设文法为:E' →#E#;T→F;E→E+T;F→P↑F | P;E→T ;P→(E);T→T*F;P→i;3. 算符优先文法算符优先文法的定义:三、综合题的确定化和最小化(参看课件第三章62页:例5)2.自顶向下分析(参看课件第四章(1)67页:综合练习)例:求对应于下述文法的预测分析表:E TE'E' +TE' |εT FT'T' *FT' |εF (E) |i答:1)首先求first集:2)由于εFirst(E'), εFirst(T'), 求E'和T'的Follow集: 3)根据集合的值填表,得到:例:设文法G(S):S→(L) | aS | aL→L,S | S(1)消除左递归和回溯;(2)计算每个非终结符的First和Follow集;(3)构造预测分析表。
答:(1) 消除左递归和回溯:(2)(3)构造预测分析表:分析方法(参看课件第四章(3)28页及30页)(附)1.短语、直接短语、句柄例:考虑如下文法: E =>T | E+TT =>F | T*FF =>i | (E)求句型i1 * i2 + i3的短语、直接短语和句柄答:E => F * i2 + i3 E => i1 * F + i3 E => i1 * i2 + FE => T + i3(T =>T*F =>i1 * i2)F=>iE => i1 * i2 + i3因此:短语有:i1, i2, i3, i1*i2, i1*i2+i3直接短语有:i1, i2 , i3句柄是:i1i2 + i3 不是短语,因为E => i1 * E (E =>i2 +i3)2.什么是语法制导翻译语法制导翻译:定义翻译所必须的语义属性和语义规则,一般不涉及计算顺序。
语法制导翻译(Syntax-Directed Translations):–一个句子的语义翻译过程与语法分析过程同时进行。
在文法中,文法符号有明确的意义,文法符号之间有确定的语义关系。
属性描述语义信息,语义规则描述属性间的的关系,将语义规则与语法规则相结合,在语法分析的过程中计算语义属性值。
翻译程序:把一种语言程序转换成另一种语言程序,且在功能上是相同的这样的程序。
编译程序:把高级语言转换成低级语言,且在功能上是相同的这样的程序。
解释程序:边解释边执行源程序的程序。
区别:编译程序有中间代码,而解释程序没有。
编译过程的五个阶段:1、词法分析任务:对构成源程序的字符串进行扫描和分解,识别出一个个单词。
2、语法分析任务:在词法分析的基础上,根据语言规则,把单词符号串分解成各类语法单位。
3、语义分析和中间代码产生任务:对语法分析所识别出的各类语法范畴,分析其含义并进行初步翻译。
4、优化任务:对前段产生的中间代码进行加工变换,以期在最后阶段能产生出更为高效的目标代码。
5、目标代码生成任务:把中间代码变换成特定机器上的低级语言代码。
编译程序的七个部分词法分析器,语法分析器、语义分析与中间代码产生器、优化器、目标代码生成器、表格管理和出错处理。
编译程序生成的五个办法:机器语言、高级语言、移植、自编译方式和使用工具自动生成。
词法规则:指单词符号的形成规则。
(也就是正规式)语法规则:规定了如何从单词符号形成更大的结构。
就是语法单位的形成规则。
空字:不包含任何符号的序列。
闭包:中所有的符号组成的集合。
上下文无关文法是指:所定义的语法范畴是完全独立于这种范畴可能出现的环境的文法。
上下文无关文法的四个组成部分:一组终结符号、一组非终结符号、一个开始符号和一组产生式。
终结符号也就是不可再分的基本符号。
非终结符号是用来代表语法范畴,表示一定符号串的集合。
开始符号是语言中我们最感兴趣的语法范畴。
产生式是定义语法范畴的书写规则。
句子:文法中从开始符号推导的终结符号串。
句型:从开始符号推导的符号串语言:文法中所有句子的集合。
程序语言的单词符号分为五种:关键字、标识符、常数、运算符和界符。
二元式表示:(种类,属性)正规式的运算符有三种:或,连接和闭包。
优先顺序是:闭包,连接,或。
DFA怎么识别字:若存在一条从初态结点到某一终态结点的通路,且这条通路上所有弧的标记符连接成的字是a,则称a可为DFA所识别。
DFA怎么识别空字:若DFA的初态结点同时又是终态结点,则空字可为DFA所识别。
NFA 怎么识别字:若存在一条从某一初态结点到终态结点的通路,且这条通路上所有弧的标记字依序连接成的字等于a,则称a可为NFA识别。
NFA怎么识别空字:若M的某些结点即是初态又是终态结点,或者存在一条从某个初态结点到某个终态结点的空通路,那么,空字可为M所识别。
语言的语法结构是用上下文无关文法描述的。
语法分析分为两类:自上而下分析法,自下而上分析法。
自上而下分析法面临的问题:1.文法的左递归问题。
2.回溯3.成功可能是暂时的,产生虚假匹配。
4.难于知道输入串中出错的确切位置。