多重共线性
第四章 多重共线性

二、产生多重共线性的背景
多重共线性产生的经济背景主要有几种情形: 1.经济变量之间具有相同的变化趋势。 2.模型中包含滞后变量。 3.利用截面数据建立模型也可能出现多重共线性。 4.样本数据的原因。
6
第二节 多重共线性的后果
一、完全多重共线性产生的后果
1.参数的估计值不确定 2.参数估计值的方差无限大
Cov( ˆ2 ,
ˆ3 )
(1
r223 )
r23 2
x22i
x32i
随着共线性增加,r23趋于1,方差将增大。同样 协方差的绝对值也增大,它们增大的速度决定于
方差扩大(膨胀)因子(variance inflation factor, VIF)
VIF
1
1 r223
这时
Var(ˆ2 )
4.多重共线性严重时,甚至可能使估计的回归系数 符号相反,得出完全错误的结论。(如引例)
18
第三节 多重共线性的检验
本节基本内容: 简单相关系数检验法 方差扩大因子法 直观判断法 病态指数检验法 逐步回归法
19
一、简单相关系数检验法 简单相关系数检验法是利用解释变量之间的线性 相关程度去判断是否存在严重多重共线性的一种 简便方法。适用于只有两个变量的情形。
2
x32i 0
同理
ˆ3
这说明完全多重共线性时,参数估计量的方差将 变成无穷大。
9
关于方差的推导
Var(ˆ2 )
x32i (x22i ) (x32i )
(x2i x3i )2
2
1 X21 X 1 X22
1 X2n
多重共线性

多重共线性多重共线性(multicollinearity )的特征● 多重共线性是指一个回归模型中的一些或全部解释变量之间存在有一种“完全”或准确的线性关系:0...2211=+++k k X X X λλλ其中k λλλ,...,,21为常数,但不同时为零。
● 0...2211≈+++k k X X X λλλ, 近似的多重共线性● 通过巴伦坦图做简单的描述。
共线性部分可用两圆圈的重叠部分来衡量。
重叠部分越大,共线性程度越高。
● 我们定义的多重共线性仅对X 变量之间的线性关系而言,它们之间的非线性关系并不违反无多重共线性的假设i i i i u X X Y +++=2210βββ多重共线性的后果●如果多重共线性是完全的,诸X变量的回归系数将是不正确的,并且它们的标准误差为无穷大●如果多重共线性是不完全的,那末,虽然回归系数可以确定,却有较大的标准误差,意思是,系数不能以很高的精确或准精确加以估计,这会导致:-参数估计不精确,也不稳定-参数估计量的标准差较大,影响系数的显著性检验●多重共线性产生的后果具有一定的不确定性●在近似的多重共线性的情况下,只要模型满足CLRM 假定,回归系数就为BLUE,但特定的样本估计量并不一定等于真值。
多重共线性的来源(1)许多经济变量在时间上由共同变动的趋势,如:收入,投资,消费(2)把一些经济变量的滞后值也作为解释变量在模型中使用,而解释变量和滞后变量通常相关,如:消费和过去的收入多重共线性一般与时间序列有关,但在横截面数据中也经常出现多重共线性的检验● 多重共线性是普遍存在的,造成的后果也比较复杂,对多重共线性的检验缺少统一的准则- 对有两个解释变量的模型,作散点图,或相 关系数,或拟和优度R平方。
- 对有多个解释变量的模型,分别用一个解释 变量对其它解释变量进行线性回归,计算拟 和优度22221,...,,k R R R- 考察参数估计值的符号,符不符合理论 - 增加或减少解释变量,考察参数估计值的变 化- 对比拟和优度和t检验值多重共线性的修正方法● 增加样本观测值,如果多重共线性是由样本引起的,可以通过收集更多的观测值增加样本容量。
多重共线性

第二章知多元线性回归模型参数向量的最小二乘估计量为: 1 X X X Y 这一表达式成立的前提条件是解释变量X 1 , X 2 , X k 之间没有多重共线性. 如果矩阵X 不是满秩的,则X X 也不是满秩的.必有: X X 0, 从而 X X 不存在, OLS失效, 此时称该模型存在完全的多重共线性.
解释变量的精确线性组合表示,它们的相关系数的绝对值为1.
X s ,h =
Var X is Var X ih ch cs
n
Cov( X is , X ih )
n
n i 1
( X is X is )( X ih X ih )
2
i1 ( X is X is )
则:
x y x
i1 i 2 i1
, 而1与 2却无法估计.
2 在近似共线性下OLS参数估计量的方差变大
我们前面已论述, 在近似共线性下,虽然可以得到OLS估计量: ) X X 1 2 Var (
由于此时 X X 0, 引起 X X 主对角线元素较大, 即 i的方差较大.
1
对此, 如果我们合并两个(或多个)高度线性相关的变量, 可以使用OLS , 但两个(或多个)变量前的参数将无法估计. 例如,对于回归模型:Yi 0 1 X i1 2 X i 2 i i 1, 2 , n 如果有:X i 2 X i1 , 合并两变量 : Yi 0 1 2 X i1 i , 令 1 2 ,
n
( X ih X ih ) i1
n 2
2
1 X s , h 1 在近似的多重共线性下则得不到这样的精确线性组合, 它们的相关系数的绝对值近似为1.
第四章多重共线性

2
x2j VIFj
注意:R2j 是多个解释变量辅助回归的多重可决系数,
而相关系数 r223只是说明两个变量的线性关系 。
(一元回归中可决系数的数值等于相关系数的平方)
17
方差扩大因子的作用
由
R2j 越大
VIFJ 1 (1 R2j ) 多重共线性越严重
VIFj越大
VIFj的大小可以反映解释变量之间存在多重共线性的严重
1 x22i (1
r223 )
2
x22i
1 (1 r223)
2
x22i
VIF2
当 r23 增大时,VIF2 增大, Var(ˆ2 ) 也会增大 ,
思考: 当 r23 0 时 Var(ˆ2) 2
x22i
(与一元回归比较)
当 r23 1 时 Var(ˆ2 )
(见前页结论) 8
三、当多重共线性严重时,甚至可能使估计
在总体中部分或全部解释变量可能没有线性关系,但是 在具体获得的样本中仍可能有共线性关系,因此多重共线 性问题本质上是一种样本现象。
正因为如此,我们无法对多重共线性问题进行统计假设 检验,只能设法评价解释变量之间多重共线性的严重程度。
5
第二节 多重共线性产生的后果
从参数估计看,在完全无多重共线性时,各解释变量都独
Kt
Kt
ln Qt ln A ln Lt ln Kt ln u
(ln Lt 与 ln Kt 有多重共线性) ln Qt ln A ln Lt ln u
Kt
Kt 22
三、截面数据与时间序列数据的结合
有时在时间序列数据中多重共线性严重的变量,在截 面数据中不一定有严重的共线性
假定前提:截面数据估计出的参数在时间序列中变化不大
多重共线性

第四章 多重共线性第一节 什么是多重共线性一、多重共线性的含义所谓多重共线性,不仅包括解释变量之间完全(精确)的线性关系,还包括解释变量之间近似的线性关系。
对于解释变量23,,,k X X X ,如果存在不全为零的数123,,,,k λλλλ ,能使得12233i i k ki X X X λλλλ++++ =0 ,(i =1,2,,n )——即解释变量的数据矩阵的列向量组线性相关。
则称解释变量23,,,k X X X 之间存在着完全的线性关系。
用数据表示,解释变量的数据矩阵为X =213112232223111k k nnkn X X X XX X X X X ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦当()r X <k 时,也说明解释变量23,,,k X X X 之间存在着完全的线性关系。
当存在完全共线性时,至少有一个变量(列向量)可以用其余的变量(列向量)线性表出。
在实际问题中,完全的共线性并不多见。
常见的情形是解释变量23,,,k X X X 之间存在不完全的共线性,这是指存在不全为零是数123,,,,k λλλλ ,使得12233λλλλ+++++ i i k ki i X X X v =0(i =1,2,,n )其中i v 是随机变量。
这表明此时解释变量之间只是一种近似的线性关系。
二、产生多重共线性的背景1.经济变量之间具有共同的变化趋势2.模型中包含滞后变量3.利用截面数据建立模型也可能出现共线性4. 样本数据自身的原因第二节 多重共线性产生的后果完全共线性时,矩阵X X '不可逆,参数估计式ˆβ=1()X X X Y -''不存在,OLS 无法应用。
不完全的共线性时,1()X X -'也存在,可以得到参数的估计值,但是对计量经济分析可能会产生一系列影响。
一、参数估计量的无偏性依然成立不完全共线性时ˆ()E β=1()E X X X Y -''⎡⎤⎣⎦=1()()E X X X X U β-''⎡⎤+⎣⎦=β+()1()X X X E U -''=β二、参数OLS 估计值方差扩大 如二元回归模型i Y =12233i i i X X u βββ+++中的2X 与3X 为不完全的共线性时,2X 与3X 之间的相关系数23r 可由下式给出223r=2232223()x x x x∑∑∑容易证明2ˆ()Var β=222223(1)i x r σ-∑3ˆ()Var β=222323(1)ixr σ-∑随着共线性的程度增加,23r 的绝对值趋于1,两个参数估计量的方差也增大。
多重共线性
多重共线性“多重共线性”一词由R. Frisch 1934年提出,它原指模型的解释变量间存在线性关系。
1.非多重共线性假定 rk (X 'X ) = rk (X ) = k解释变量不是完全线性相关的或接近完全线性相关的。
| r x i x j | ≠1, | r x i x j | 不近似等于1。
就模型中解释变量的关系而言,有三种可能。
(1)r x i x j = 0,解释变量间非线性相关,变量间相互正交。
这时已不需要多重回归,每个参数βj 都可以通过y 对x j 的一元回归来估计。
(2)| r x i x j | = 1,解释变量间完全共线性。
此时模型参数将无法确定。
直观地看,当两变量按同一方式变化时,要区别每个解释变量对被解释变量的影响程度就非常困难。
(3)0 < | r x i x j | < 1,解释变量间存在一定程度的线性相关。
实际中常遇到的是这种情形。
随着共线性程度的加强,对参数估计值的准确性、稳定性带来影响。
因此我们关心的不是有无多重共线性,而是多重共线性的程度。
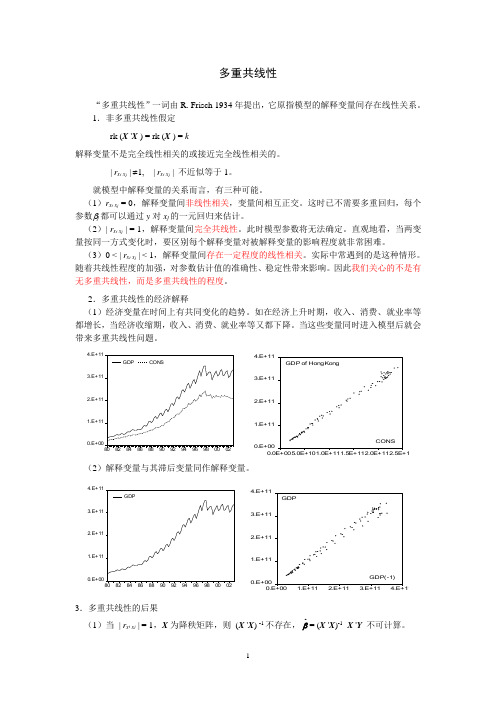
2.多重共线性的经济解释(1)经济变量在时间上有共同变化的趋势。
如在经济上升时期,收入、消费、就业率等都增长,当经济收缩期,收入、消费、就业率等又都下降。
当这些变量同时进入模型后就会带来多重共线性问题。
0.E+001.E+112.E+113.E+114.E+11808284868890929496980002GDPCONS0.E +001.E +112.E +113.E +114.E +110.0E +005.0E +101.0E +111.5E +112.0E +112.5E +11C O N SG D P o f H o n g K o n g(2)解释变量与其滞后变量同作解释变量。
0.E+001.E+112.E+113.E+114.E+11808284868890929496980002GDP0.E+001.E+112.E+113.E+114.E+110.E+001.E+112.E+113.E+114.E+11GDP(-1)GDP3.多重共线性的后果(1)当 | r x i x j | = 1,X 为降秩矩阵,则 (X 'X ) -1不存在,βˆ= (X 'X )-1 X 'Y 不可计算。
Chapter10多重共线性MultiCollinearity(计量经济学-武汉大学,彭红枫)

则称为解释变量间存在完全共线性 (perfect multicollinearity)。
2020/5/1
Hongfeng Peng Department of
3
Finance, Wuhan University
近似共线性
如果存在一组不全为0的数,使得 1X1+ 2X2+…+ kXk +vi=0 i=1,2,…,n
Chapter 10
多重共线性 MultiCollinearity
主讲:彭红枫
武汉大学经济与管理学院金融系 Copyright© Hongfeng Peng 2006 Wuhan
University
10.1 多重共线性的性质
• 定义:
– 狭义:模型中一些或全部解释变量之间存在 一种完全的线性关系(完全共线性)。
– 广义:模型中一些或全部解释变量之间存在 一种完全或非完全的线性关系(近似共线 性)。
2020/5/1
Hongfeng Peng Department of
2
Finance, Wuhan University
完全共线性
如果存在一组不全为0的数,使得 1X1+ 2X2+…+ kXk=0 i=1,2,…,n
2020/5/1
Hongfeng Peng Department of
13
Finance, Wuhan University
• 10.12 • 10.24 • 10.30
习题
2020/5/1
Hongfeng Peng Department of
14
Finance, Wuhan University
导致多重共线性的可能原因
第七章 多重共线性

2
X 1i 1 r 2
2
ˆ 同理:Var b2
2
X 2i 1 r 2
2
第二节
多重共线性的影响后果
2
ˆ 当完全不共线时,r=0, Var b1
X
2 1i
当不完全共线时,r越接近1,相关程度越高, bi Var ˆ 越大,参数估计值越不准确。
第四节
多重共线性的解决方法
三、逐步回归法 (1)计算因变量对每一个解释变量的回归方程,并分别 进行统计检验,从中选取最合适的基本回归方程。 (2)逐一引入其他解释变量,重新进行回归,在模型中 每个解释变量均显著,参数符号正确, R 2 值有所提高的前 提下,从中再选取最合适的二元回归方程。 (3)在选取的二元回归方程的基础上以同样的方式引 入第三解释变量;如此引入,直至无法引入新变量为止。
第四节
多重共线性的解决方法
(2)如果历年的平均收入弹性与近期的收入弹性 近似相等,就可以用 a2代替原模型中的 b2 。将原模 ln y a2 ln I b0 b1 ln P 型变为 y1 ln y a2 ln I 令:
p1 ln P 再利用时间序列数据求出价格弹性 b1 以及 b0即可。
第四节
多重共线性的解决方法
二、间接剔除重要的解释变量 1、利用已知信息 所谓已知信息,就是在建立模型之前,根据经 济理论、统计资料或经验分析,已知的解释变量之 间存在某种关系。为了克服模型的多重共线性,可 以将解释变量按已知关系加以处理。
第四节
多重共线性的解决方法
例如:柯布-道格拉斯生产函数
y aL K e
ln y / K ln a ln L / K
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
虽然x2和x3的水平之可能高度相关,但是,其差分形式相关 程度往往较低。因此,一阶差分回归常能减低多重共线性 的严重程度。(对于横截面数据,一阶差分不适用。 差分法的问题:随机误差项可能存在序列相关;损失了一 次观测值,因而减少了一个自由度,如果样本容量本身就 不大,这可能会有影响。
六、多重共线的克服
2 2 x i )(
3i ) ( xBiblioteka 2 3 x i)( x
i x 3i )( y
2i x 3i ) x
2
ˆ ) Var( 2
3i ) 2i x
2
2 2 2 x i (1 r23 )
yi 1 ( 2 3 ) x2i i 或将x3i=x2i 代入原模型: 令 2 3 *
ˆ *有唯一解
偏回归系数无确定解的含义:无法从所给样本中将x2和x3的影响分离出来: 当x2发生变化时,x3也按一个倍数因子改变。
三、多重共线的实际后果
完全多重共线是一种极端情形,非完全多重共线更常见。 非完全多重共线下,OLS估计量仍是最优线性无偏估计量, 但有如下后果:
ˆ ) Var( 2
4. 补充新数据:以二元回归为例
ˆ ) Var( 2
2
2 2 2 x ( 1 r t 23 )
当r23给定时,增加新样本,通常可以使 ˆ 的方差,使我们能更准确地估计 。 从而减少 2 2
2 2 x t 增大,
习题:
现有美国70-83年进口(百万美元)、GNP (10亿美元)和消费者价格指数(CPI)数据。 请考虑一下模型:
ln yt 1 2 ln pt 3 ln I t t
在时间序列数据中,价格和收入变量一般都有高度共 线的趋势。如果作上述回归时存在高度共线问题,可 利用横截面数据估计收入弹性3,因为这些数据都产 生于一个时间点上,价格还不至于有多大变化。令收 ˆ ,原回归可化为: 入弹性的横截面估计为 3
三、多重共线的实际后果
由于方差膨胀,接受零假设更为容易, 出现多个偏回归系数单零t检验不显著。
ˆ 2 t ˆ ) se( 2 ˆ ) , t se( 2
虽然单零检验不显著,但是联合检验(F 检验)却显著,总的拟合优度也很高。 OLS估计量及其标准误对数据的小变化敏 感。
四、多重共线产生的原因
yt=b1+b12x2t+1t
E(b12 ) = 2 + 3 b32 b12是的一个有偏且非一致的估 计,无法得到反映x2对y的净影响的系数2
六、多重共线的克服
3. 差分法:时间序列数据间往往有较强的相关性, 减小相关性的方法是形成一次差分方程:
yt yt 1 2 ( x2t x2,t 1 ) 3 ( x3t x3,t 1 ) t 其中: t t t 1
二、完全多重共线的估计问题
以二元回归为例:
ˆ 2 (
yi 1 2 x2i 3i x3i i
i x 2i )( y (
0 0 ∴如果出现完全多重共线,则偏回归系数是不确定的,其标 准误是无穷大。 ˆ , var( ˆ ) 设:x3i=x2i (r23=1) 代入上式: 2 2
容许度与方差膨胀因子
容许度TOL i (1 Ri2 ) 方差膨胀因子VIFi 1 1 Ri2 1 TOLi
经验规则:VIF>10 则说该变量是高度 共线的。
六、多重共线的克服
1. 横截面数据与时间序列数据并用
例如研究汽车需求,假定有销售量、平均价 格和消费者收入的时间序列数据,模型为:
五、多重共线的识别
注意:多重共线是个程度问题,而不是有无问 题。 识别方法:
R2值高,F检验显著,但显著t值少。 回归元间有高度两两相关(充分而非必要条件)。 本征值(eigenvalues)和病态指数(condition index)
病态指数CI 最大本征值 最小本征值
病态指数CI在10-30之间,中强多重共线 CI>30,严重多重共线
yt* 1 2 ln pt t ˆ ln I 其中:y * ln y
t t 3 t
六、多重共线的克服
2. 剔除变量:对严重多重共线,最简单的做法之 一是剔除共显著变量之一。但从模型中剔除一 个变量,可能导致设定偏误。
yt=1+2x2t+3x3t+t 剔除一变量后变为:
1
2
2 2 2 x ( 1 r i 23 )
∴估计精度较低
2 1 r23
VIF
称为方差膨胀因子
VIF表明:估计量的方差由于多重共线的出现而膨胀起来。
当r23=0.7时,VIF=1.96 ˆ ) var( 当r23=0.9时,VIF=5.76 即: 2 是r23为零时的5.76倍。 ˆ ) 是无共线时的10倍。 var( 当r23=0.95时,VIF=10.26 即: 2
数据采集方法:解释变量取值范围过小; 模型或从中取样的总体本身的特点
例:在作电力消费对收入和住房面积的回归 时,一般来说,收入较高的家庭住房面积也 较大。
2 如多项式回归:yi 0 1xi 2 xi i
模型设定问题
一个过度决定的模型:
解释变量个数>样本容量
一、多重共线性的性质
完全多重共线:对解释变量x1, x2, … xk, 如果存在一组不全为0的常数1、2、… k,使得: 1x1i+ 2x2i+ …+ kxki=0 非完全多重共线:包括变量间交互相关 情形如下: 1x + 2x + …+ kx + =0 1i 2i ki i
五、多重共线的识别
辅助回归:作每一个xi对其余x变量的回归, 并计算R2,记为 Ri2 。这种回归叫辅助回归, 以辅助y对x的回归。然后计算统计量:
Fi Ri2 /(k 2) (1 Ri2 ) /(n k 1)
~(k-2, n-k+1)的F分布
当Fi显著时,认为xi与其余的x有共线性。