Fisher线性分类器
线性分类器设计fisher准则
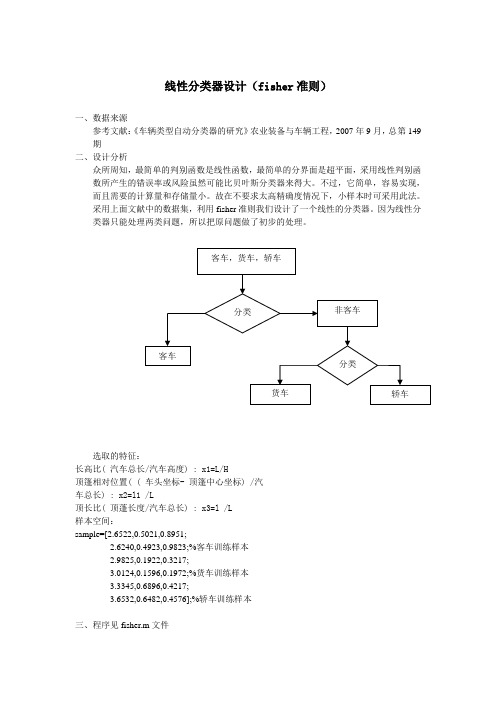
线性分类器设计(fisher准则)一、数据来源参考文献:《车辆类型自动分类器的研究》农业装备与车辆工程,2007年9月,总第149期二、设计分析众所周知,最简单的判别函数是线性函数,最简单的分界面是超平面,采用线性判别函数所产生的错误率或风险虽然可能比贝叶斯分类器来得大。
不过,它简单,容易实现,而且需要的计算量和存储量小。
故在不要求太高精确度情况下,小样本时可采用此法。
采用上面文献中的数据集,利用fisher准则我们设计了一个线性的分类器。
因为线性分类器只能处理两类问题,所以把原问题做了初步的处理。
选取的特征:长高比( 汽车总长/汽车高度) : x1=L/H顶篷相对位置( ( 车头坐标- 顶篷中心坐标) /汽车总长) : x2=l1 /L顶长比( 顶蓬长度/汽车总长) : x3=l /L样本空间:sample=[2.6522,0.5021,0.8951;2.6240,0.4923,0.9823;%客车训练样本2.9825,0.1922,0.3217;3.0124,0.1596,0.1972;%货车训练样本3.3345,0.6896,0.4217;3.6532,0.6482,0.4576];%轿车训练样本三、程序见fisher.m文件四、结果分析原文章中采用的的改进的BP神经网络算法,能很好的实现分类的效果。
而在这里我们挑了6个训练集样本和3个测试集样本,也很好的实现了分类效果。
但是,若对于大样本来说,贝叶斯分类器的效果更好。
下图就是采用线性分类器的效果图。
客车样本和非客车样本1 1.2 1.4 1.6 1.82 2.2 2.4 2.6 2.83客车样本和非客车样本1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.92。
机器学习实验1-Fisher线性分类器设计

一、实验意义及目的掌握Fisher分类原理,能够利用Matlab编程实现Fisher线性分类器设计,熟悉基于Matlab算法处理函数,并能够利用算法解决简单问题。
二、算法原理Fisher准则基本原理:找到一个最合适的投影周,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
内容:(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类三、实验内容(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数程序清单:clcclear all%10*3样本数据w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-0.35,.47,0.034;0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-0.12,0.054,-0.063];w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-0.39,-0.48,0.11;0.34,-0.079,0.14;-0.3,-0.22,2.2;1.1,1.2,-0.46;0.18,-0.11,-0.49];W1=w1';%转置下方便后面求s1W2=w2';m1=mean(w1);%对w1每一列取平均值结果为1*3矩阵m2=mean(w2);%对w1每一列取平均值结果为1*3矩阵S1=zeros(3);%有三个特征所以大小为3S2=zeros(3);for i=1:10%1到样本数量ns1=(W1(:,i)-m1)*(W1(:,i)-m1)';s2=(W2(:,i)-m2)*(W2(:,i)-m2)';S1=S1+s1;S2=S2+s2;endsw=S1+S2;w_new=transpose(inv(sw)*(m1'-m2'));%这里m1m2是行要转置下3*3 X 3*1 =3*1 这里提前转置了下跟老师ppt解法公式其实一样%绘制拟合结果数据画图用y1=w_new*W1y2=w_new*W2;m1_new=w_new*m1';%求各样本均值也就是上面y1的均值m2_new=w_new*m2';w0=(m1_new+m2_new)/2%取阈值%分类判断x=[-0.7 0.0470.58 -0.40.089 1.04 ];m=0; n=0;result1=[]; result2=[];for i=1:2%对待观测数据进行投影计算y(i)=w_new*x(:,i);if y(i)>w0m=m+1;result1(:,m)=x(:,i);elsen=n+1;result2(:,n)=x(:,i);endend%结果显示display('属于第一类的点')result1display('属于第二类的点')result2figure(1)scatter3(w1(1,:),w1(2,:),w1(3,:),'+r'),hold onscatter3(w2(1,:),w2(2,:),w2(3,:),'sg'),hold onscatter3(result1(1,:),result1(2,:),result1(3,:),'k'),hold onscatter3(result2(1,:),result2(2,:),result2(3,:),'bd')title('样本点及实验点的空间分布图')legend('样本点w1','样本点w2','属于第一类的实验点','属于第二类的实验点')figure(2)title('样本拟合结果')scatter3(y1*w_new(1),y1*w_new(2),y1*w_new(3),'b'),hold onscatter3(y2*w_new(1),y2*w_new(2),y2*w_new(3),'sr')(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置最优方向w 的直线投影后的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类决策边界取法:分类结果:四、实验感想通过这次实验,我学会了fisher线性判别相关的分类方法,对数据分类有了初步的认识,尽管在过程中有不少中间量不会算,通过查阅网络知识以及模式识别专业课ppt等课件帮助,我最终完成了实验,为今后继续深入学习打下良好基础。
Fisher线性分类器通俗解释及MATLAB、Python实现

Fisher线性分类器通俗解释及MATLAB、Python实现⼀、通俗的解释:问题提出:还是以iris的数据为例,有A、B、C三种花,每⼀类的特征都⽤4维特征向量表⽰。
现在已知⼀个特征向量,要求对应的类别,⽽我们⼈可以直接通过眼睛看⽽作出分类的是在⼀维⼆维三维空间,⽽不适应这样的四维数据。
启⽰:假设有这样的⼀个⽅向向量,其与特征向量进⾏内积运算(即向⽅向向量的投影)后,结果为⼀个数值,若同类的特征向量投影后聚集在⼀起,不同类的特征投影后相对分散,那么,我们的⽬的就达到了。
⽬标:这样就有了⽅向,即要寻找⼀个独特的⽅向,使其达到我们的要求。
注:具体的推导过程,参看教科书,另外,在求解极值的时候,利⽤了矩阵论中的向量导数运算。
⼆、MATLAB程序:clearA=[5.1,3.5,1.4,0.24.9,3.0,1.4,0.24.7,3.2,1.3,0.24.6,3.1,1.5,0.25.0,3.6,1.4,0.25.4,3.9,1.7,0.44.6,3.4,1.4,0.35.0,3.4,1.5,0.24.4,2.9,1.4,0.24.9,3.1,1.5,0.15.4,3.7,1.5,0.24.8,3.4,1.6,0.24.8,3.0,1.4,0.14.3,3.0,1.1,0.15.8,4.0,1.2,0.25.7,4.4,1.5,0.45.4,3.9,1.3,0.45.1,3.5,1.4,0.35.7,3.8,1.7,0.35.1,3.8,1.5,0.35.4,3.4,1.7,0.25.2,4.1,1.5,0.15.5,4.2,1.4,0.24.9,3.1,1.5,0.15.0,3.2,1.2,0.25.5,3.5,1.3,0.24.4,3.2,1.3,0.25.0,3.5,1.6,0.6 5.1,3.8,1.9,0.44.8,3.0,1.4,0.35.1,3.8,1.6,0.24.6,3.2,1.4,0.25.3,3.7,1.5,0.2 5.0,3.3,1.4,0.2 7.0,3.2,4.7,1.4];B=[6.4,3.2,4.5,1.5 6.9,3.1,4.9,1.55.5,2.3,4.0,1.36.5,2.8,4.6,1.55.7,2.8,4.5,1.36.3,3.3,4.7,1.6 4.9,2.4,3.3,1.0 6.6,2.9,4.6,1.3 5.2,2.7,3.9,1.4 5.0,2.0,3.5,1.05.9,3.0,4.2,1.56.0,2.2,4.0,1.0 6.1,2.9,4.7,1.45.6,2.9,3.6,1.36.7,3.1,4.4,1.4 5.6,3.0,4.5,1.55.8,2.7,4.1,1.06.2,2.2,4.5,1.5 5.6,2.5,3.9,1.15.9,3.2,4.8,1.86.1,2.8,4.0,1.3 6.3,2.5,4.9,1.5 6.1,2.8,4.7,1.25.5,2.4,3.8,1.1 5.5,2.4,3.7,1.05.8,2.7,3.9,1.26.0,2.7,5.1,1.65.4,3.0,4.5,1.56.0,3.4,4.5,1.6 6.7,3.1,4.7,1.5 6.3,2.3,4.4,1.3 5.6,3.0,4.1,1.3 5.5,2.5,4.0,1.35.5,2.6,4.4,1.26.1,3.0,4.6,1.4 5.8,2.6,4.0,1.2 5.0,2.3,3.3,1.0 5.6,2.7,4.2,1.3 5.7,3.0,4.2,1.25.7,2.9,4.2,1.36.2,2.9,4.3,1.3 5.1,2.5,3.0,1.1 5.7,2.8,4.1,1.3];C=[6.3,3.3,6.0,2.5 5.8,2.7,5.1,1.9 7.1,3.0,5.9,2.1 6.3,2.9,5.6,1.86.5,3.0,5.8,2.27.6,3.0,6.6,2.1 4.9,2.5,4.5,1.7 7.3,2.9,6.3,1.86.7,2.5,5.8,1.87.2,3.6,6.1,2.5 6.5,3.2,5.1,2.0 6.4,2.7,5.3,1.97.7,2.6,6.9,2.36.0,2.2,5.0,1.56.9,3.2,5.7,2.35.6,2.8,4.9,2.07.7,2.8,6.7,2.06.3,3.4,5.6,2.46.4,3.1,5.5,1.86.0,3.0,4.8,1.86.9,3.1,5.4,2.16.7,3.1,5.6,2.46.9,3.1,5.1,2.35.8,2.7,5.1,1.96.8,3.2,5.9,2.36.7,3.3,5.7,2.56.7,3.0,5.2,2.36.3,2.5,5.0,1.96.5,3.0,5.2,2.06.2,3.4,5.4,2.35.9,3.0,5.1,1.8];%⽅法⼀:先将A作为⼀类,BC作为⼀类NA=size(A,1);NB=size(B,1);NC=size(C,1);A_train=A(1:floor(NA/2),:);%训练数据取1/2(或者1/3,3/4,1/4)B_train=B(1:floor(NB/2),:);C_train=C(1:floor(NC/2),:);A_test=A((floor(NA/2)+1):end,:);B_test=B((floor(NB/2)+1):end,:);C_test=C((floor(NC/2)+1):end,:);A_train=A_train;D_train=[B_train;C_train];A_test=A_test;D_test=[B_test;C_test];for i=1:size(A_train,1)S1=S1+(A_train(i,:)-u1)'*(A_train(i,:)-u1);endfor i=1:size(D_train,1)S2=S2+(D_train(i,:)-u2)'*(D_train(i,:)-u2);endSw=S1+S2;w1=(inv(Sw)*(u1-u2)')';w1=w1./norm(w1);y0=w1*(u1+u2)'/2;% a1=w*u1'% d1=w*u2'r1=0;for i=1:size(D_test,1)if w1*D_test(i,:)'<y0r1=r1+1;endendrate_D=r1/size(D_test,1)r2=0;for i=1:size(A_test,1)if w1*A_test(i,:)'>y0r2=r2+1;endendrate_A=r2/size(A_test,1)三、Python程序:from sklearn import discriminant_analysisfrom sklearn.model_selection import train_test_splitimport numpydata = numpy.genfromtxt('iris.csv', delimiter=',', usecols=(0,1,2,3)) target = numpy.genfromtxt('iris.csv', delimiter=',', usecols=(4), dtype=str) t = numpy.zeros(len(target))t[target == 'setosa'] = 1t[target == 'versicolor'] = 2t[target == 'virginica'] = 3#print(clf.predict([data[3]]))。
使用Fisher线性判别方法的提取分类器

文, 用 , … 分别表示 个个体分类器 , , … } 。
1 问题 形 式化 描述 及个 体分 类器 训练
对分 类问题而 言 , 问题 域为 类 对象 , 类别标 签分别为
,
, , 。每—个样本可以表示成一个 d 的权重特征向 J …, , 维
个体 分类器 训练指从 数据集 中训练 获得这 个分 类器 的过
p tr En iern n pia o s 2 1 4 ( 4 :3 - 3 . ue g e ig a d Ap l t n . 0 0。6 I ) 1 2 1 4 n ci
Ab t a t I r e o ei n t e aii ewe n n e ld ca s ir n mp o e f c n tb l y o o i e , n a p o c sr c : n od r t l mi ae rl t t b t e e s mb e ls i e a d i r v e e t a d sa i t f c mbn r a p r a h vy f s f i
e ta t ca sfes xr ci ng l si r ba e o Fih r i e r ic i n n a lss s o o e I c n e uc ca sfe s c wih ih i e in, i sd n s e ln a ds rmi a t nay i i pr p s d.t a r d e l s i r pa e i t hg dm nso
FISHER分类

Fisher 线性判别分类器成员姓名: 学号:莫文敏 201111921217 赵越 201111921229 顾瑞煌 201111921104一、实验目的1.实现基于FISHER 分类的算法程序;2.能够根据自己的设计加深对FISHER 分类的认识;3.掌握FISHER 分类的原理、特点。
二、实验设备1.手提电脑2.MATLAB三、FISHER 算法原理线性判别函数的一般形式可表示成0)(w X W X g T +=其中⎪⎪⎪⎭⎫ ⎝⎛=d x x X 1 ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=d w w w W 21但是,在应用统计方法解决模式识别的问题时,经常会遇到“维数风暴”的问题,因此压缩特征空间的维数在此时十分重要,FISHER 方法实际上是涉及维数压缩的问题。
把多为特征空间的点投影到一条直线上,就能把特征空间压缩成一维,这在数学上是很容易做到的。
但是在高维空间里很容易一分开的样品,把它们投射到任意一条直线上,有可能不同类别的样品就混在一起,无法区分了,如图5-16(a )所示,投影1x 或2x 轴无法区分。
若把直线绕原点转动一下,就有可能找到一个方向,样品投射到这个方向的直线上,各类样品就能很好地分开,如图5-16(b )所示。
因此直线方向的选择是很重要的。
一般来说总能找到一个最好的方向,使样品投射到这个方向的直线上很容易分开。
如何找到这个最好的直线方向以及如何实现向最好方向投影的变换,这正是FISHER 算法要解决的基本问题,这个投影变换正是我们寻求的解向量*W 。
样品训练集以及待测样品的特征总数目为n ,为找到最佳投影方向,需要计算出各类样品的均值、样品类内离散度矩阵i S 和总类间矩阵w S 、样品类间离散度矩阵b S ,根据FISHER 准则找到最佳投影向量,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行一维Y 空间的投影,判断它的投影点与分界点的关系将其归类。
fisher

权值向量为: • w=(-0.8894, 0.1154, -0.0006, -0.1002, 0.0890, 0.0914, -4.1878, -0.0092)T. 决策面方程为
: l x 0.8894 0.1154 x1 0.0006 x2 0.1002 x3
0.089 x4 0.0914 x5 4.1878 x6 0.0092 x7 0
④ 利用两个类别的先验概率确定分类阈值
w T μ1 μ 2 ln P1 P2 2 N 2 (3.58)
⑤ 当样本维数m和样本数N都很大时,可采用 Bayes决策规则,从而获得一种在一维空间的 最优分类器。见《模式识别》pp.90。
3.5 Fisher分类器
3.5 Fisher分类器 (Fisher Linear Discriminant)
• Fisher判别法是历史上最早提出的判别方法之
一,其基本思想是将n类m维数据集尽可能地投
影到一个方向(一条直线),使得类与类之间
尽可能分开。从形式上看,该方法就是一种所
谓的“降维”处理方法。为简单起见,我们以
两类问题1和2的分类来说明Fisher判别法的原
• 附表为最终分类结果。可以看出,仍只有9和29 两个样本被错分。值得注意的是,这时以分类 器输出是否大于或小于零来决定样本的类别, 且分类器的实际输出不再是单纯的1或-1。 • 可以算出,这时分类器的实际输出与目标输出 之间的误差平方和为 • E=(y(:,1:1)-y(:,2:2))'*(y(:,1:1)-y(:,2:2))=11.4223.
理,如图3.7所示。
xk
1
均值2
均值1
wn 最不利投影方向
w*
实验二Fisher线性判别分类器

实验二 Fisher 线性判别分类器本实验旨在让同学进一步了解分类器的设计概念,理解并掌握用Fisher 准则函数确定线性决策面方法的原理及方法,并用于实际的数据分类。
一、实验原理线性判别函数的一般形式可表示成0()T g w =+X W X 其中12d x x x ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭ X 12d w w w ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭W 根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:2122212()()F m m J S S -=+ W *112()W S -=-W m m上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。
另外,该式这种形式的运算,我们称为线性变换,其中12-m m 是一个向量,1-WS 是W S 的逆矩阵,如12-m m 是d 维,W S 和1-W S 都是d ×d 维,得到的*W 也是一个d 维的向量。
向量*W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量*W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W ,如2~~210m m W +-= 或者 m N N m N m N W ~~~2122110=++-= 或当1)(ωp 与2)(ωp 已知时可用[]⎥⎦⎤⎢⎣⎡-+-+=2)(/)(ln 2~~2121210N N p p m m W ωω ……当W 0确定之后,则可按以下规则分类,2010ωω∈→->∈→->X w X W X w X W T T二、实验内容已知有两类数据1ω和2ω,1ω中数据点的坐标对应一一如下:数据:x 1 =0.2331 1.5207 0.6499 0.7757 1.0524 1.19740.2908 0.2518 0.6682 0.5622 0.9023 0.1333-0.5431 0.9407 -0.2126 0.0507 -0.0810 0.73150.3345 1.0650 -0.0247 0.1043 0.3122 0.66550.5838 1.1653 1.2653 0.8137 -0.3399 0.51520.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099y 1=2.3385 2.1946 1.6730 1.6365 1.7844 2.01552.0681 2.1213 2.4797 1.5118 1.9692 1.83401.87042.2948 1.7714 2.3939 1.5648 1.93292.2027 2.4568 1.7523 1.6991 2.4883 1.7259 2.0466 2.0226 2.3757 1.7987 2.0828 2.0798 1.9449 2.3801 2.2373 2.1614 1.9235 2.2604 z1=0.5338 0.8514 1.0831 0.4164 1.1176 0.55360.6071 0.4439 0.4928 0.5901 1.0927 1.07561.0072 0.4272 0.4353 0.9869 0.4841 1.0992 1.0299 0.7127 1.0124 0.4576 0.8544 1.1275 0.7705 0.4129 1.0085 0.7676 0.8418 0.8784 0.9751 0.7840 0.4158 1.0315 0.7533 0.9548 数据点的对应的三维坐标为2x2 =1.4010 1.23012.0814 1.1655 1.3740 1.1829 1.7632 1.9739 2.4152 2.5890 2.8472 1.9539 1.2500 1.2864 1.2614 2.0071 2.1831 1.79091.3322 1.1466 1.7087 1.59202.9353 1.46642.9313 1.8349 1.8340 2.5096 2.7198 2.3148 2.0353 2.6030 1.2327 2.1465 1.5673 2.9414 y2 =1.0298 0.9611 0.9154 1.4901 0.8200 0.9399 1.1405 1.0678 0.8050 1.2889 1.4601 1.4334 0.7091 1.2942 1.3744 0.9387 1.2266 1.18330.8798 0.5592 0.5150 0.9983 0.9120 0.71261.2833 1.1029 1.2680 0.7140 1.2446 1.3392 1.1808 0.5503 1.4708 1.1435 0.7679 1.1288 z2 =0.6210 1.3656 0.5498 0.6708 0.8932 1.43420.9508 0.7324 0.5784 1.4943 1.0915 0.76441.2159 1.3049 1.1408 0.9398 0.6197 0.66031.3928 1.4084 0.6909 0.8400 0.5381 1.37290.7731 0.7319 1.3439 0.8142 0.9586 0.73790.7548 0.7393 0.6739 0.8651 1.3699 1.1458三、实验要求1) 请把数据作为样本,根据Fisher 选择投影方向W 的原则,使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,求出评价投影方向W 的函数,并求使)(w J F 取极大值的*w 。
模式识别:线性分类器

模式识别:线性分类器一、实验目的和要求目的:了解线性分类器,对分类器的参数做一定的了解,理解参数设置对算法的影响。
要求:1. 产生两类样本2. 采用线性分类器生成出两类样本的分类面3. 对比线性分类器的性能,对比参数设置的结果二、实验环境、内容和方法环境:windows 7,matlab R2010a内容:通过实验,对生成的实验数据样本进行分类。
三、实验基本原理感知器基本原理:1.感知器的学习过程是不断改变权向量的输入,更新结构中的可变参数,最后实现在有限次迭代之后的收敛。
感知器的基本模型结构如图1所示:图1 感知器基本模型其中,X输入,Xi表示的是第i个输入;Y表示输出;W表示权向量;w0是阈值,f是一个阶跃函数。
感知器实现样本的线性分类主要过程是:特征向量的元素x1,x2,……,xk是网络的输入元素,每一个元素与相应的权wi相乘。
,乘积相加后再与阈值w0相加,结果通过f函数执行激活功能,f为系统的激活函数。
因为f是一个阶跃函数,故当自变量小于0时,f= -1;当自变量大于0时,f= 1。
这样,根据输出信号Y,把相应的特征向量分到为两类。
然而,权向量w并不是一个已知的参数,故感知器算法很重要的一个步骤即是寻找一个合理的决策超平面。
故设这个超平面为w,满足:(1)引入一个代价函数,定义为:(2)其中,Y是权向量w定义的超平面错误分类的训练向量的子集。
变量定义为:当时,= -1;当时,= +1。
显然,J(w)≥0。
当代价函数J(w)达到最小值0时,所有的训练向量分类都全部正确。
为了计算代价函数的最小迭代值,可以采用梯度下降法设计迭代算法,即:(3)其中,w(n)是第n次迭代的权向量,有多种取值方法,在本设计中采用固定非负值。
由J(w)的定义,可以进一步简化(3)得到:(4)通过(4)来不断更新w,这种算法就称为感知器算法(perceptron algorithm)。
可以证明,这种算法在经过有限次迭代之后是收敛的,也就是说,根据(4)规则修正权向量w,可以让所有的特征向量都正确分类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2013-9-12
ICL,wenzs@
2
Classification Problem
Classification Problem:
Mapping M: X->C X is the Instances of the problem C is the known set of class
17
Strategy to determine w0
Several advised method
y0=(m1’+ m2’)/2 y0=(N1m1’+ N2m2’)/(N1+N2)
……
2013-9-12
ICL,wenzs@
18
FDF
VS
SVM
Fisher’s Linear Classification
ICL,wenzs@
7
2-Classes
Simple->Complex
Consider 2-Classes problem
2-Classes problem
X->{0,1} Concept learning
2013-9-12
ICL,wenzs@
8
=> Sbw* –λSωw*=0 => Sbw* =λSωw* => Sω-1Sbw* =λw*
1. The eigenvector of Sω-1Sb 2. w*= Sω-1(m1-m2)
2013-9-12 ICL,wenzs@ 15
The best “w”
Optimization problem
Mathematic solution
Lagrange Lemma of Maximization
2013-9-12
ICL,wenzs@
14
Lagrange method
Let wTSωw=c≠0 L(w,λ)= wTSbw –λwTSωw
Classifier’s task
(narrow sense)
Given a classified sample X={x1,…,xN} and C={c1,…,ck}, Mapping? Given a unclassified sample X and the count of classes
ICL,wenzs@ 11
2013-9-12
Numerical Characters
Class Mean Vector
Inter Divergence Matrix
Class Divergence Matrix
2013-9-12 ICL,wenzs@ 12
2013-9-12 ICL,wenzs@ 9
2013-9-12
ICL,wenzs@
10
Fisher’s Discriminant
Fisher’s Discriminant Function (FDF)
Fisher’s Principle
Maximize JF(w)
Feature Vector
For every x∈X, x is represented as vector (x1,…,xn) xi (1 ≤ i ≤ n) is called feature of x
2013-9-12 ICL,wenzs@ 3
Classifier
Cluster
cluster unconsidered in this report
2013-9-12
ICL,wenzs@
4
Linear Classifier
Find n linear function gi(x) i=1,…,n
M(x)= argmax{gi(x) }
High dimension -> 1-D w*->ok, what about w0?
w0 is a threshold g(x)= w*x+w0
If g()>0, x∈C1; If g(x)<0, x∈C2 If g(x)=0?
2013-9-12
ICL,wenzs@
Maximize JF(w)
Linear SVM
Maximize “margin”
2013-9-12
ICL,wenzs@
19
2013-9-12
ICL,wenzs@
20
Conclusion
Provide an approach to transform problem from high dimension to 1-D linear space Limited to linear discriminant Simple but still used
Fisher’s Linear Classifier
Machine Learning Seminar
2013-9-12
ICL,wenzs@
1
Content
Classifier, Linear Classifier Fisher’s Discriminant Function The best project vector Comparison with Linear SVM Conclusion
i
2013-9-12
ICL,wenzs@
5
Project Vector
2013-9-12
ICL,wenzs@
6
Discriminant Function
Different Criterion
Fisher Perceptron SVM ……
2013-9-12
Transformation
y1-y2=(wTx1+w0)-(wTx2+w0) = wT(x1-x2) (m1’-m2’)2= wTSbw D12+D22=wT(S1+S2)w= wTSωw
2013-9-12
ICL,wenzs@
13
Find the best “w”
Lemma of Maximization
/yujs/papers/ pdf/max.pdf w*=Sω-1(m1-m2)
Despite of scale, w* is
2013-9-12
ICL,wenzs@
16
Remain Problem
2013-9-12
ICL,wenzs@
21
Ronald Aylmer Fisher
(1890-1962)
Brilliant biologists Development of methods suitable for small samples Discovery of the precise distributions of many sample statistics Invention of analysis of variance.