数据库2
数据库基础知识2

生产副厂长
技术副厂长
经营副厂长
车间主任
处长
部门经理
层次模型具有层次分明、结构清晰的优点。 层次模型具有层次分明、结构清晰的优点。但只能反映实体 一对多”的联系。 间“一对多”的联系。
网状模型用 图结构” 网状模型用“图结构”来表示数据之间的联 系
网状数据模型反映现实世界较为复杂的事物间的联系。特点是: 网状数据模型反映现实世界较为复杂的事物间的联系。特点是: (1)可以有两个以上的根结点。 可以有两个以上的根结点。 一个父结点可以有多个子结点, (2 ) 一个父结点可以有多个子结点, 一个子结点也可以有多个父 结点。 结点。 专业系
2.1 数据模型概述
2.1.2 数据模型的组成三要素
1、数据结构——用于描述现实世界数据(系统)的静态特性 数据结构——用于描述现实世界数据(系统) ——用于描述现实世界数据 规定数据的存储和表示方式。 规定数据的存储和表示方式。 2、数据操作—用于描述现实世界数据(系统)的动态特性 数据操作—用于描述现实世界数据(系统) 是数据库中各种数据的操作集合以及相应的操作规则。 是数据库中各种数据的操作集合以及相应的操作规则。 如:创建、插入、替换、删除、查询、统计等操作。 创建、插入、替换、删除、查询、统计等操作。 3、数据的约束条件—一组完整性规则的集合 数据的约束条件— 是给定的数据模型中的数据及其联系所具有的制约和依存关 系,用以保证数据的正确、有效、相容。 用以保证数据的正确、有效、相容。 如:有效性规则,参照完整性,触发器等。 有效性规则,参照完整性,触发器等。
层次模型用 树结构” 层次模型用“树结构”来表示数据之间的联系
把客观问题抽象为一个严格的自上而下的层次关系。 把客观问题抽象为一个严格的自上而下的层次关系。 其特点是:(1)只有一个根结点. 其特点是:(1)只有一个根结点. 只有一个根结点 (2) 一 个 父 结 点 可 以 有 多 个 子 结 点 , 但 每 个 子 结点只能有一个父结点。 结点只能有一个父结点。
数据库实验2-数据库及表的创建与管理(DDL应用)

实验二数据库及表的创建与管理(DDL应用)姓名:学号:专业:网络工程班级:20网络工程同组人:无实验日期:一、【实验目的与要求】1.熟悉SQL Server 2005 的环境2.了解使用企业管理器创建数据库的过程和方法3.了解使用企业管理器创建数据库的过程和方法二、【实验准备】1.安装并配置好SQL Server 2005数据库2.设计好数据库创建各参数,准备好测试数据三、【实验要求】1.完成数据库的创建与管理2.完成表的创建与管理。
3. 熟悉SQL Server 2005中企业管理器和查询分析器两个常用管理工具四、【实验内容】1. 数据库创建与管理2. 表的创建、管理及数据操作。
五、【实验步骤】1. 准备工作(1)安装完成SQL Server 2005安装。
(2) 打开企业管理器(3)连接数据库2.数据库的创建与修改准备工作:在C盘下创建目录Exam03,用于存放数据库创建时产生的数据文件。
(1) 数据库的创建使数据定义语句Create Database可以创建数据库,该语句在使用时可指明数据文件和日志文件存放的路径,初始数据文件的大小等参数。
阅读以下是创建数据库SalesDB的SQL语句,理解其功能,并置于查询分析器中执行:create database SalesDBon(name= SalesDB_data,--数据文件的逻辑名称,注意不能与日志逻辑同名filename='C:\Exam03\SalesDB.mdf' ,--物理名称,注意路径必须存在size=20, --数据初始长度为10Mmaxsize=100, --最大长度为100Mfilegrowth=5 --数据文件每次增长1M)log on(name= SalesDB_log,filename='C:\Exam03\SalesDB.ldf ' ,size=20 ,maxsize=50 ,filegrowth=5)在查询分析器中执行上述语句建立数据库SalesDB。
数据库第2章关系数据库练习题
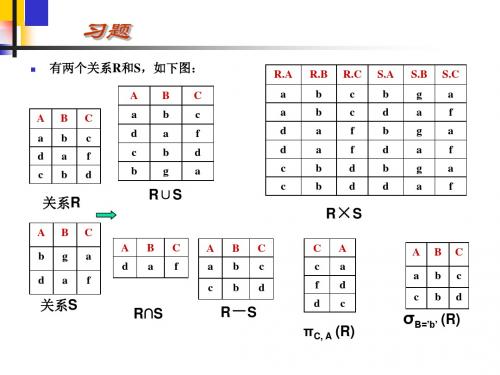
习题
学生关系S (Sno, Sname, Ssex, Sage, Class)
课程关系C (Cno, Cname, DeptName) 学生选课关系R (Sno, Cno, Grade) R)
1.检索所有学生学号、姓名、课程号、成绩 sno,sname,cno,Grade ( S sno,sname ( Cno=‘C02’( S
2.检索学习课程号为C02的学生学号与姓名
R))
sno,sname ( S
sno,sname (S)
Cno=‘C02’ (R)) 优化
sno (Cno=‘C02’ (R)) 再优化
B 2 2 5 D 3 6
C 3 3 6 E 1 2
D 3 6 6
E 1 2 2
R
C=D
S
课堂练习
R
A a b B l n B f
S
C g D h
l
n
x
p
y
x
R×S R R S
R. B S. B
S
R×S
A
a a a b b b
R.B
l l l n n n
S.B
f l n f l n
C
g x p g x p
难题
Sno(2 5 ∧1=4 ( R R) ) 优化: Sno(2 5 ( R
R.sno= R.sno
R) name, Ssex, Sage, Class) 课程关系C(Cno, Cname, DeptName) 学生选课关系R(Sno, Cno, Grade)
数据库原理第二学期习题解答

<数据库原理二>参考习题解答上海大学 董健全5.2 设关系模式R 有n 个属性,在模式R 上可能成立的函数依赖有多少个?其中平凡的FD 有多少个?非平凡的FD 有多少个?解:这个问题是排列组合问题。
FD 形为X →Y ,从n 个属性值中选择属性组成X 共有C 0n+C 1n+ … +C nn=2n 种方法;同理,组成Y 也有2n 种方法。
因此组成X →Y 形式应该有2n ·2n =4n 种方法。
即可能成立的FD 有4n 个。
平凡的FD 要求Y ⊆X ,组合X →Y 形式的选择有:C 0n·C 00+C 1n·(C 01+C 11)+C 2n·(C 02+C 12+C 22)+ … +C nn(C 0n+C 1n+ … C nn)=C 0n·20+C 1n·21+C 2n·22+ … +C nn·2n =(1+2)n =3n 即平凡的FD 有3n 。
因而非平凡的FD 有4n -3n 个。
5.3 对函数依赖X →Y 的定义加以扩充,X 和Y 可以为空属性集,用φ表示,那么X →φ,φ→Y ,φ→φ的含义是什么?答:据推理规则的自反律可知,X →φ和φ→φ是平凡的FD ,总是成立的。
而φ→Y 表示在当前关系中,任意两个元组的Y 值相等,也就是当前关系的Y 值都相等。
5.4 已知关系模式R (ABC ),F 是R 上成立的FD 集,F={ A →B ,B →C },试写出F 的闭包F +。
解:据已知条件和推理规则,可知F +有43个FD :A →φ AB →φ AC →φ ABC →φ B →φ C →φA →A AB →A AC →A ABC →A B →B C →CA →B AB →B AC →B ABC →B B →C φ→φA →C AB →C AC →C ABC →C B →BC A →AB AB →AB AC →AB ABC →AB BC →фA →AC AB →AC AC →AC ABC →AC BC →BA →BC AB →BC AC →BC ABC →BC BC →CA →ABC AB →ABC AC →ABC ABC →ABC BC →BC5.5 设关系模式R (ABCD ),如果规定,关系中B 值与D 值之间是一对多联系,A 值与C 值之间是一对一联系。
数据库查询2

[例32] 查询选修了3门以上课程的学生学号。
[例33]查询每个学生及其选修课程的情况[例34] 对[例33]用自然连接完成。
(结果无重复列)[例35]查询每一门课的间接先修课(即先修课的先修课)[例36] 改写[例33]外连接()SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade FROM Student LEFT JOIN SC ON (Student.Sno=SC.Sno);[例37]查询选修2号课程且成绩在90分以上的所有学生[例38]查询每个学生的学号、姓名、选修的课程名及成绩[例39]查询与“刘晨”在同一个系学习的学生。
此查询要求可以分步来完成①定“刘晨”所在系名②查找所有在IS系学习的学生。
将第一步查询嵌入到第二步查询的条件中[例40]查询选修了课程名为“信息系统”的学生学号和姓名提示:①首先在Course关系中找出“信息系统”的课程号,为3号②然后在SC关系中找出选修了3号课程的学生学号③最后在Student关系中取出Sno和Sname[例41]找出每个学生超过他选修课程平均成绩的课程号。
[例42] 查询其他系中比计算机科学某一学生年龄小的学生姓名和年龄方法一:用any方法二:用聚集函数MIN[例43] 查询其他系中比计算机科学系所有学生年龄都小的学生姓名及年龄。
方法一:用ALL谓词[例44]查询所有选修了1号课程的学生姓名。
思路分析:本查询涉及Student和SC关系在Student中依次取每个元组的Sno值,用此值去检查SC关系若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno= '1',则取此Student.Sname送入结果关系用嵌套查询[例45]查询没有选修1号课程的学生姓名。
[例46] 查询选修了全部课程的学生姓名。
[例47]查询至少选修了学生200215122选修的全部课程的学生号码。
工业数据库 (2)

工业数据库概述工业数据库是一种用于管理和储存工业领域相关数据的数据库。
它可以帮助企业或工厂有效地存储、组织和分析大量的工业数据,提供决策支持和业务洞察。
功能1. 数据存储和管理工业数据库提供功能强大的数据存储和管理能力。
它可以支持多种数据格式,包括结构化数据(如表格数据)、半结构化数据(如 XML 和 JSON)和非结构化数据(如文本、图像和视频)。
用户可以使用数据库管理系统(DBMS)来创建、更新和查询数据库中的数据,保证数据的完整性和一致性。
2. 数据安全和权限管理工业数据库具备安全性和权限管理功能,可以确保数据的机密性和完整性。
通过用户认证和访问控制,只有经授权的用户才能访问和修改数据。
数据的备份和恢复功能也使得数据在故障或灾难发生时能够得到有效的保护和恢复。
3. 数据分析和可视化工业数据库提供数据分析和可视化工具,帮助用户从海量数据中发现有价值的信息和洞察。
用户可以使用数据库的查询语言来进行数据的分析和统计,也可以使用数据可视化工具创建图表、仪表盘和报告,以便更好地理解和共享数据分析结果。
4. 实时数据处理和监控工业数据库支持实时数据处理和监控功能,使得企业和工厂能够对实时数据进行实时处理和监控。
通过与传感器、设备和系统的集成,工业数据库可以接收并处理实时数据,并提供实时监控和告警功能,帮助用户及时发现和解决问题,提高生产效率和质量。
5. 云端部署和扩展性工业数据库可以在云端进行部署,提供弹性和可扩展性的计算和存储资源。
通过云端部署,用户可以根据需求快速扩展数据库的容量和性能,而无需投入大量的硬件和人力资源。
此外,云端部署还使得多个用户能够同时访问和共享数据,促进协作和集成。
应用1. 生产管理和优化工业数据库在生产管理和优化中发挥着重要作用。
通过实时数据的采集和分析,工业数据库可以帮助企业实时监控生产过程中的关键指标,并快速响应异常情况。
通过数据的回顾性分析,工业数据库可以帮助企业识别生产过程中的瓶颈和问题,并提供优化建议。
sci数据库 (2)

SCI数据库1. 简介SCI数据库(Science Citation Index),即科学引文索引,是世界知名的科学文献数据库之一。
由克拉克·卡尔·库尔斯特科学信息研究所(Institute for Scientific Information,简称ISI)创办,并于1964年首次发布。
SCI数据库覆盖了多个学科领域,包括自然科学、工程技术、社会科学等,是全球学术界广泛使用的重要文献检索工具之一。
2. 数据来源SCI数据库的数据来自于全球各个领域的重要学术期刊,包括自然科学、社会科学、医学及工程技术等。
ISI每年都会收集和整理大量的学术期刊文章,将其加入到SCI数据库中。
在数据来源上,SCI数据库有以下特点:•全球范围:SCI数据库涵盖了全球各个国家和地区的学术期刊,包括美国、欧洲、亚洲等地的重要期刊。
•学科广泛:SCI数据库涵盖了多个学科领域,包括物理学、化学、生物学、数学、计算机科学、经济学、社会学等。
•杂志选择:SCI数据库只收录质量较高、具有较高学术影响力的学术期刊,因此其收录的文章大多具有一定的学术价值和影响力。
3. 数据内容SCI数据库的数据内容主要包含以下几个方面:•文章标题与作者:SCI数据库中的每篇文章都有清晰的标题和作者信息,方便用户进行检索和查看。
•摘要和关键词:每篇文章都会提供一段简短的摘要,摘要中概述了文章的主要内容和研究成果,并提供相关的关键词,方便用户进行快速检索。
•引用文献:SCI数据库中的每篇文章都会记录其引用文献,可以方便地查看一篇文章被其他学者引用的情况,进而了解其在学术界的影响力。
•文章全文:除了摘要外,SCI数据库还提供了部分文章的全文内容,方便用户进行更深入的阅读和研究。
•文章标签:SCI数据库对每篇文章进行了分类和标签,用户可以通过选择相应的标签来进行检索,并获取与自己研究领域相关的文章结果。
4. 使用方法为了更好地利用SCI数据库进行学术研究和文献检索,以下是几种常用的使用方法:•关键词检索:可以通过输入相关的关键词来检索SCI数据库中的文章,以获取与自己研究领域相关的文献资源。
数据库第2章SQL_Server数据库的管理与使用教学课件

指定数据库的 默认排序规则
支持该子句是为了与早期版 本的 Microsoft SQL Server 兼 容。
附加数据库
•22
2.3.2 使用T-SQL语言修改数据库
• 在查询分析器中的状态
•23
2.4 数据库的删除
• 2.4.1 使用快捷菜单删除数据库 • 2.4.2 使用Transact-SQL语言删除数据库
•24
2.4.1 使用快捷菜单删除数据库
(1)在企业管理器中删除数据库 (2)在查询分析器中删除数据库
•25
2.4.2 使用T-SQL语言删除数据库
• 语句格式
– DROP DATABASE database_name [ ,...n ] – 例2-10:删除Test_db1
DROP DATABASE Test_db1
– 例2-11:删除Test_db2和Test_db3.
DROP DATABASE Test_db2,Test_db3
• 即分离数据库的逆操作,通过附加数据库,可以将没有加 入SQL Server服务器的数据库文件添加到服务器中。还可 以很方便地在SQL Server 服务器之间利用分离后的数据 文件和事务日志文件组成新的数据库。
•29
2.6 数据备份和还原
• 2.6.1数据备份 • 2.6.2数据还原 • 2.6.3数据备份和还原操作
– 备份的策略 • 是指确定需备份的内容、备份的时间及备份的方式。
– 完全 (全库)备份 – 完全备份加日志备份 – 完全备份加差异备份再加日志备份。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
喻晓和
1
1
关系数据理论(2) 2 3 数据库系统开发与数据库设计
主要 知识点
概念设计、概念模型、ER模型
4
数据库设计案例分析
2014-6-9
喻晓和
2
2.1 关系数据理论的进一步讨论
关系模型三要素
数据结构、数据操作和数据约束。
第1章已经介绍了数据结构、数据约束的知识。关系
模型的数据操作包括:关系代数和关系谓词演算,其
关 系 存 在 的 问 题
这四个特性中,第1个是关系的存储特性异 常,其余3个为操作特性异常。
2.1 关系数据理论的进一步讨论
2.关系规范化与函数依赖 关系规范化理论是数据库设计的指导理论。
• 关系分为不同的规范层级,称为范式(NF:Normal Form)。 • 最低为第一范式,记为1NF。如果有关系R满足1NF的 要求,记为R∈1NF。
其中 θ 是以下运算符中之一: {=,≠,>,≥,<,≤ }。
2.1 关系数据理论的进一步讨论
6
自然联接
与一般的联接相比,自然联接有两个特点: ⑴ 是将两个关系中相同的属性进行相等比较; ⑵ 结果关系中去掉重复的属性。
自然联接运算无须写出连接条件,其表示方法是: 关系1 关系2
2.1 关系数据理论的进一步讨论
管理学概 102004 论 管理学概 102004 论 204002 307101 204002 307101 307010 英语 高等数学 英语 高等数学 程序设计
计算机原 307001 理 307010 307101 程序设计 高等数学
2.1 关系数据理论的进一步讨论
(1)数据冗余度大。 (2)数据修改异常。重复存储的数据在修改时 容易造成不一致。若一个数据只存储一次,则可 避免修改异常。 (3)数据插入异常。发生应该存入的数据而不 能存入的情况,称为数据插入异常。 (4)数据删除异常。这种删除无用数据导致有 意义的数据被删除,称为数据删除异常。
功能是等价的。
本节简要介绍关系代数的知识,以及关系规范化 的有关知识。
2.1 关系数据理论的进一步讨论
• 2.1.1 关系代数
组成关系代数的运算包括:关系的并、交、差、笛 卡儿积运算,以及关系的选择、投影、联接和除运 算。
2.1 关系数据理论的进一步讨论
1
关系的并、交、差运算
要求参与运算的关系必须满足以下的两个条件:
在选择运算的条件表达式中,条件的基本表示方 法是: <属性>θ <值>。
在选择运算式中,应首先了解单个条件的基 本表示方法是: <属性>θ<值> 其中θ 是以下运算符中之一:{=,≠, >,≥,<,≤ }。 例如: 数学>=90 学号=102981
2014-6-9
喻晓和
13
当一个选择运算要用到多个条件,这时, 应将各个单项条件用逻辑运算符NOT(非)、 AND(与)、OR(或)连接起来. 例如: 数学>=90 and 外语>=90 and 体育>90
院长
张建 张建 张建 张建 李龙
课程 号
10200 4 10200 4 20400 2 30710 1 20400 2 30710 1 30701 0 30700 1 30701 0 30710 1
课程名
管理学概论 管理学概论
学分 学分 2 2 6 5 6
成 绩
90 80 75 91 95
范 小 默
1993/04/ 050 男 10 1 1994/10/ 050 女 18 1 1994/10/ 050 女 18 1 1994/10/ 050 女 18 1 1994/04/ 020 女 20 1 1994/04/ 090 女 03 2 1994/04/ 090 女 03 2 1993/11/ 090 男 23 2 1993/11/ 090 男 23 2 1993/11/ 090 男 23 2
① 关系的度数相同(即属性个数相同); ② 对应属性取自相同的域(即两个关系的属性构成 相同)。 在实用时,这两项条件可以理解为参与运算的关系 具有相同的关系模式。
2.1 关系数据理论的进一步讨论
并:设有关系R、S满足上述条件,定义R与S的并
(Union)运算:求出由出现在R或出现在S中所有 元组(去掉重复元组)的集合组成的关系。记作 R∪S。 (Intersection)运算:求出由同时出现在R中和S 中的相同元组的集合组成的关系。记作R∩S。 (Difference)运算:求出由只出现在R中而未在S 中出现的元组的集合组成的关系。记作R-S。
(学号,课程号) 在学院);
(学号,课程号) 所在学院 → 院长; 学号 院 长。
2.1 关系数据理论的进一步讨论
已知R,S关系如表2.6、表2.7所示,则R×S结果见 表2.8。
2.1 关系数据理论的进一步讨论
3
选择
选择(Selection)运算是从一个关系中选取满足条 件的元组组成结果关系。这个运算只有一个运算对 象,运算结果和原关系具有相同的关系模式。
表示方法是:σ条件表达式(关系名)
杨 飞 杨 飞 杨 飞 杨 飞 杨 飞
一
一 一 一 一
高等数学
程序设计
计算机原理
5
4 3 4 5
32
88
84 86 82 92
程序设计 高等数学
学号 姓名 性别
生日 所在学院
院长
课程号 课程名 学分 成绩
在学生信息关系中: • 学号→(姓名,性别,生日,所在学院, 院长); • 课程号→(课程名,学分) 而成绩属性是由(学号,课程号)两个属 性决定的. • (学号,课程号)→ 成绩。 另外,院长是由: • 所在学院→院长 • 应该如何设置主键
2.1 关系数据理论的进一步讨论
• 2.1.2 关系规范化基础
一个关系型数据库由若干个关系组成。组成数据 库的关系“好”还是“不好”?
1.关系的存储特性与操作特性 由于数据库是存储和处理数据的技术,所以要判
断数据库设计的好坏,要从其存储特性和操作特性开
始分析。
2.1 关系数据理论的进一步讨论
2014-6-9
喻晓和
14
2.1 关系数据理论的进一步讨论
对于关系R(表2.10),求σ 结果见表2.11。
A=“a1” AND B=1
(R)。
选择操作的结果是:对关系表的记
录(行)完成了筛选,满足条件的行 提了出来.
2.1 关系数据理论的进一步讨论
4
投影
投影(Project)运算是在给定关系中指定若干属性 (列)组成一个新关系。结果关系的属性由投影运 算式指定,元组是由原关系中的元组去掉没有指定 的属性的分量值后剩下的值组成。 由于去掉了一些属性,结果中可能出现相同元 组,要再次去掉重复元组,所以结果关系的元组可 能少于原关系。 表示方法:π(属性表)(关系名)
交:设有关系R、S满足上述条件,定义R与S的交 差:设有关系R、S满足上述条件,定义R与S的差
R∪S
R∩S
R -S
图2-1 关系的并、交、差示意图
2.1 关系数据理论的进一步讨论
系如表2.1、表2.2所示,则R∪S,R∩S,R-S的结 果见表2.3、表2.4、表2.5。
2.1 关系数据理论的进一步讨论
曾晓 曾晓 曾晓 吴敏
男 女 女 女 女
英语 高等数学 英语
人文
信息管理
信息管理 信息管理 信息管理 信息管理 喻晓和主讲
01307010
01307010 01307021 01307021 01307021 2014-6-9
张宁
张宁 王景 王景 王景
女
女 男 男 男
83.04.03
83.04.03 83.11.23 83.11.23 83.11.23
对于关系R,S,求: ; R S。
关系的并、交、差、笛卡儿积、选择、投影、一般
关 系 代 数 运 算
连接和自然连接,合在一起称为关系代数。
关系代数奠定了关系数据模型的操作基础。其中,
投影、选择和连接是关系操作的核心运算。在各种 关系型DBMS中,都通过不同的方式实现了关系代 数的所有运算功能(主要是SQL)。
• 仅为1NF的关系存储特性和操作特性都不好。通过逐步 加上更多限制,可使关系分别满足2NF、3NF、BCNF 、4NF、5NF的要求。这一过程就是关系规范化的过程 。目前最高范式级别为5NF。
2.1 关系数据理论的进一步讨论
函数依赖 关系中不同的属性具有不同的特性。关系属性间 的相互关系是由数据的内在性质所决定的。函数依赖 反映了属性之间的相互关系。 • 关系中的函数依赖定义是: 设有关系S,X、Y是S上的两个属性或属性组,如 果对于X的每一个取值,都有唯一一个确定的Y值与之 对应,则称属性(组)X函数决定属性(组)Y,或称 属性(组)Y函数依赖于属性(组)X,记为:X→Y。 这里,X是函数依赖的左部,称为决定因素,Y是 函数依赖的右部,称为依赖因素。
X
Y
1002
奥巴马
男
10Biblioteka 65902.1 关系数据理论的进一步讨论
函数依赖分为: 平凡的函数依赖和非平凡的函数依赖。
关 系 函 数 依 赖 分 类
非平凡函数依赖有: (1)部分函数依赖; (2)完全函数依赖; (3)传递函数依赖。
直观看,关系中,函数依赖越少,关系特性越 “好”。 平凡的函数依赖是全体属性决定自身.
如果一个关系中函数依赖的决定因素是 单属性,则这个依赖一定是完全函数依 赖。
再分析学生信息表: 院长属性实际上并
不直接依赖于学号.
其实是通过学号确定所在学院,通过 所在学院确定院长,这种函数依赖被 称为传递的函数依赖。