字符取模
威尔取模软件GBK字库GB2312字库说明书

威尔取模软件使用介绍(V1.0)一、简介1.1 界面介绍二、我要取几个汉字的字模2.1 取模2.1.1 打开软件2.1.2 在中文字符集文本框中输入要取模的文字,比如“欢迎使用威尔取模软件”,如下图所示。
2.1.3 选择要取模的字体,比如我要取宋体的字模,就选择宋体。
如下图所示。
此处列出的是系统安装的所有字体,如果要取自己下载的字体的模,请先安装该字体。
2.1.4 添加我要取模的字号,宽度,高度等信息。
点击添加按钮,打开添加窗口,如下图所示。
在字号,宽度,高度框中输入你要取模的文字大小。
比如我要取16*16的点阵,就在宽度和高度中输入16、16。
然后计算字号,字号=0.75*宽度。
输入12。
点击添加。
点击添加以后回到主界面,你会发现主界面字号列表框里面就多了一种你刚刚添加的字号了。
这时候点击你刚刚添加的字号选中它,然后再在预览框中输入一个汉字,看看效果。
2.1.5 如果效果不错可以跳过这一步。
如果效果不好有以下两种情况。
1.文字太大或者太小,如下图两种情况所示。
这时候就需要重新设置字号了。
增大或者减小字号。
2.字符不居中,如下图所示。
这时候调节右下方的位置调整滑块,将文字调节居中,如下图所示。
2.1.6 选择要生成C语言格式还是二进制文件格式。
如果是C语言格式,还可以选择是否生成数组的数组名。
2.1.7 假如我只要取我刚刚设置的16*16点阵字体,那么就要选择“取选中字号”,并选中16*16那一列。
如下图所示。
2.1.8 假如我只要取中文字模,那么就勾上取模中文,同时去掉取模英文的勾,如下图所示。
2.1.9 好了,所有设置妥当,可以开始取模啦。
点击“开始取模”。
如果选择的是C语言格式则取模完成后自动弹出结果窗口,如下图所示。
三、我要取整个GBK字库或者GB2312字库的字模3.1 取模3.1.1 打开软件3.1.2 假如我要取整个GBK字库的字模,那么点击右侧“GBK字库”按钮,自动输入GBK字符集所有文字。
JAVA大数类—基础操作(加减乘除、取模、四舍五入、设置保留位数)

JAVA⼤数类—基础操作(加减乘除、取模、四舍五⼊、设置保留位数)当基础数据类型长度⽆法满⾜需求时可以使⽤⼤数类 构造⽅法接受字符串为参数1 BigInteger bInt = new BigInteger("123123");2 BigDecimal bDouble = new BigDecimal("123123.123123124"); 基础操作(取模使⽤divideAndRemainder⽅法,返回的数组第⼆个元素为余数): BigDecimal在做除法时必须设定传⼊精度(保留多少位⼩数),否则会出现异常:ng.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result。
除法还有两个接受不同数量参数的⽅法: 接受两个参数的⽅法: @param divisor value by which this {@code BigDecimal} is to be divided. 传⼊除数 @param roundingMode rounding mode to apply. 传⼊round的模式 三个参数的⽅法: @param divisor value by which this {@code BigDecimal} is to be divided. 传⼊除数 @param scale scale of the {@code BigDecimal} quotient to be returned. 传⼊精度 @param roundingMode rounding mode to apply. 传⼊round的模式 round模式为⼩数取舍模式: BigDecimal.ROUND_UP:最后⼀位如果⼤于0,则向前进⼀位,正负数都如此。
手把手教你光立方取模软件的使用(以字符R为例)

手把手教你光立方取模软件的使用
(以字符R为例)
1、3D8光立方取模软件的视图分为:正视图,侧视图和俯视图,取模时只需要在你想要的视图上操作即可,不必管其他视图的变化
代表光立方的三视图分别是:正视图,侧视图和俯视图
2、用鼠标点击8*8的小方格,白色代表点亮,灰色代表熄灭,数据会显示在下面的hex显示区内
3、将R顺时针旋转180度,将旋转后的图形以白点的形式绘制在正视图的第一个8*8方框内(旋转是为了使图形数据与程序一致)
在正视图中点亮一个“R”的字符
4、找到hex文本框里第八行的第三到六的数据,这四个数据即为有效数据。
(图形不同获得的数据大小不同,总之除零以外的数据都是有效的)
”R”的数据显示在hex数据区内
5、用keil打开程序,找到名为ZIMO.H的文件。
在ZIMO.H里定义了一个名为table_id的数组,用hex文本框里的四个数据替换其中一组,点击保存并编译。
6、打开stc下载软件,如stc-isp-15xx-v6.61。
单片机型号选择stc12c5a60s2,点击“打开程序文件”到你程序文件夹得hex文件里添加后缀为.hex的文件。
7、将下载线一端插在电脑上一端用杜邦线插在spi下载口上(注意:上有标号不要差错)打开电源,点击下载软件的“下载”然后再重启一次电源,当提示操作成功时程序就下载完成了,。
c语言字符串提取数字的各位数字

c语言字符串提取数字的各位数字C语言是一种广泛应用于计算机编程的语言,它具有高效、灵活、可移植等特点。
在C语言中,字符串是一种常见的数据类型,它由一系列字符组成。
在处理字符串时,有时需要提取其中的数字,并将其各位数字分离出来。
本文将介绍C语言中提取数字的各位数字的方法。
首先,我们需要了解C语言中字符串和数字的表示方式。
在C语言中,字符串是由一系列字符组成的数组,以'\0'结尾。
而数字则可以表示为整型或浮点型。
在提取数字的各位数字时,我们需要将字符串转换为数字类型,然后进行分离。
C语言提供了一些函数可以将字符串转换为数字类型,如atoi、atof、strtol等。
其中,atoi函数可以将字符串转换为整型,atof函数可以将字符串转换为浮点型,strtol函数可以将字符串转换为长整型。
这些函数的使用方法如下:```cint atoi(const char *str); // 将字符串转换为整型double atof(const char *str); // 将字符串转换为浮点型long int strtol(const char *str, char **endptr, int base); // 将字符串转换为长整型```其中,str参数为要转换的字符串,endptr参数为指向转换后剩余字符串的指针,base参数为转换时使用的进制。
例如,当base为10时,表示使用十进制进行转换。
接下来,我们可以使用取模和除法运算来分离数字的各位数字。
例如,对于一个整数n,我们可以使用以下代码来分离其各位数字:```cint digit;while(n > 0){digit = n % 10; // 取出个位数字n /= 10; // 去掉个位数字// 对digit进行处理}```对于浮点数,我们可以先将其转换为整型,然后再进行分离。
例如,对于一个浮点数f,我们可以使用以下代码来分离其各位数字:```cint n = (int)f; // 将浮点数转换为整型int digit;while(n > 0){digit = n % 10; // 取出个位数字n /= 10; // 去掉个位数字// 对digit进行处理}```需要注意的是,当浮点数f为负数时,我们需要先将其取绝对值,然后再进行转换和分离。
AscII码字模提取方法
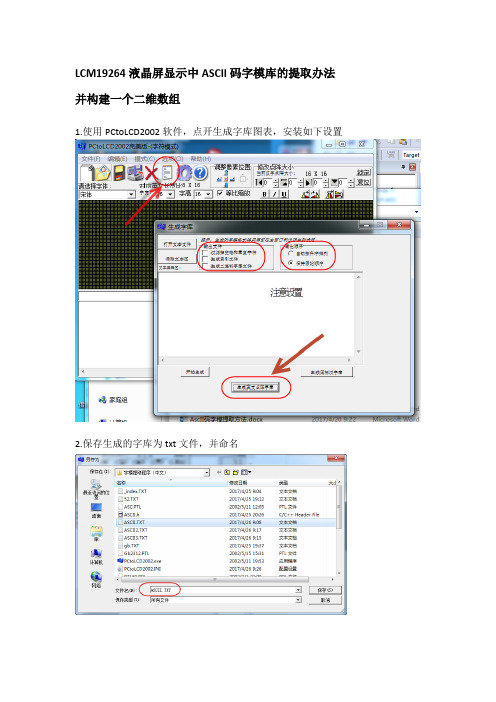
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。
取模运算

数去除这个自然数,若该自然数能被整除,则说明其非素数。
C++实现功能函数:
/* 函数名:IsPrime
函数功能:判别自然数 n 是否为素数。 输入值:int n,自然数 n 返回值:bool,若自然数 n 是素数,返回 true,否则返回 false */
bool IsPrime(unsigned int n) {
<!--[if !supportLineBreakNewLine]--> <!--[endif]--> 基本性质: (1)若 p|(a-b),则 a≡b (% p)。例如 11 ≡ 4 (% 7), 18 ≡ 4(% 7) (2)(a % p)=(b % p)意味 a≡b (% p) (3)对称性:a≡b (% p)等价于 b≡a (% p) (4)传递性:若 a≡b (% p)且 b≡c (% p) ,则 a≡c (% p) 运算规则: 模运算与基本四则运算有些相似,但是除法例外。其规则如下:
说明: 1. 同余式: 正整数 a,b 对 p 取模,它们的余数相同,记做 a ≡ b % p 或者 a ≡ b (mod p)。 2. n % p 得到结果的正负由被除数 n 决定,与 p 无关。 例 如 : 7%4 = 3 , -7%4 = -3 , 7%-4 = 3 , -7%-4 = -3 。
取模运算
取模运算即模运算
模 运 算 即 求 余 运 算 。“模 ” 是 “Mod”的 音 译 ,模 运 算 多 应 用
于程序编写中。 Mod 的含义为求余。模运算在数论和程序设计中都有着广泛的应用,
从 奇 偶 数 的 判 别 到 素 数 的 判 别 ,从 模 幂 运 算 到 最 大 公 约 数 的 求 法 ,从 孙 子 问 题 到 凯 撒
c语言中%用法

在 C 语言中,百分号%是一个运算符,主要用于格式化输出和进行取模运算。
以下是%在 C 语言中的常见用法:
1. 格式化输出(printf 函数):
printf函数中%用于指定格式化输出的内容。
例如,%d表示输出整数,%f表示输出浮点数,%s表示输出字符串等。
2. 取模运算:
%用于进行取模运算,即求余数。
它返回除法运算的余数。
3. 格式化输入(scanf 函数):
scanf函数中也可以使用%来指定输入数据的格式。
4. 预处理器中的宏定义:
在预处理器中,%也可以用于宏定义的参数替换。
这只是%在 C 语言中的一些常见用法。
具体使用时,要根据上下文和具体情况来理解和使用%。
在格式化输出和输入中,%后面通常会跟随格式说明符,而在取模运算中,%用于表示取模操作。
字符取模原理

字符取模原理字符取模原理解析什么是字符取模字符取模是一种常见的编程技巧,用于判断字符串中某个字符在另一个字符集合中是否存在。
利用字符取模可以快速判断某个字符是否包含在一个字符串中,以及计算出字符在字符串中的位置。
字符取模的原理字符取模的原理基于ASCII码表,每个字符都对应一个唯一的ASCII码,范围从0到127。
通过将字符串中的字符与字符集合进行比较,可以根据字符的ASCII码判断字符是否存在于字符集合中。
字符取模的步骤1.将字符串和字符集合转换为ASCII码形式。
2.遍历字符串中的每个字符,并获取字符的ASCII码。
3.检查字符ASCII码是否包含在字符集合的ASCII码范围内。
4.如果包含,则表示字符存在于字符集合中;否则,表示字符不存在于字符集合中。
字符取模的示例以下是一个使用字符取模技巧判断字符串中是否包含某个字符的示例代码:def is_character_exists(string, character):# 获取字符集合的ASCII码character_set = set(ord(c) for c in string)# 获取字符的ASCII码char_ascii = ord(character)# 判断字符是否存在于字符集合中if char_ascii in character_set:return Trueelse:return False字符取模的优势和适用场景字符取模是一种高效的算法,可以快速判断一个字符是否存在于字符串中。
相比于遍历字符串逐个比较字符的方法,字符取模可以大大提高执行效率。
字符取模适用于以下场景: - 判断字符串中是否包含某个特定的字符。
- 在字符串中查找某个字符并获取其位置。
- 对字符串中的字符进行去重操作。
总结字符取模是一种利用字符的ASCII码进行快速判断字符是否存在于字符串中的编程技巧。
它遵循将字符串和字符集合转换为ASCII码,通过比较字符的ASCII码范围来判断字符是否存在的原理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字字符图片取模
12864纵向取模,字节倒序。
直接关系到编程的方法。
(a)数字1 (8*16)(b) 纵向取模,字节倒序(c) 纵向取模
图1:纵向取模
图1(b)采用纵向取模,字节倒序的方式进行取模。
那么生产的字模的表格为:
从第一列开始,取上面的8位,倒序读,0x00;接着取第二列上面的8位,倒序读,0x10;接着取第三列上面的8位,倒序读,0x10;接着取第四列上面的8位,倒序读,0xf8;接着取第五列上面的8位,倒序读,0x00;……
直到这8列上半部分8位都取完,再从先半部分开始,自下而上(倒序),自左往右取完8列。
所以:/*-- 文字: 1 --*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=8x16 --*/
0x00,0x10,0x10,0xF8,0x00,0x00,0x00,0x00,0x00,0x20,0x20,0x3F,0x20,0x20,0x00,0x00
图1(c):纵向取模,方式如图。
/*-- 文字: 1 --*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=8x16 --*/
0x00,0x08,0x08,0x1F,0x00,0x00,0x00,0x00,0x00,0x04,0x04,0xFC,0x04,0x04,0x00,0x00
(a) 横向取模(b) 横向取模,字节倒序
图2:横向取模
横向取模:
/*-- 文字: 北--*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=16x16 --*/
0x04,0x40,0x04,0x40,0x04,0x40,0x04,0x44,0x04,0x48,0x7C,0x50,0x04,0x60,0x04,0x40, 0x04,0x40,0x04,0x40,0x04,0x40,0x04,0x42,0x1C,0x42,0xE4,0x42,0x44,0x3E,0x04,0x00
横向取模,字节倒序:
/*-- 文字: 北--*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=16x16 --*/
0x20,0x02,0x20,0x02,0x20,0x02,0x20,0x22,0x20,0x12,0x3E,0x0A,0x20,0x06,0x20,0x02, 0x20,0x02,0x20,0x02,0x20,0x02,0x20,0x42,0x38,0x42,0x27,0x42,0x22,0x7C,0x20,0x00。