指数分布的矩估计和极大似然估计
概率论与数理统计第七章-1矩估计法和极大似然估计法

μ1 h1 (θ1 , θ2 , μ j h j (θ1 , θ2 , μk hk (θ1 , θ2 ,
, θk ) , θk ) , θk )
, μk ) , μk ) , μk )
数理统计
从这 k 个方程中解出
θ1 g1 ( μ1 , μ2 , θ j g j ( μ1 , μ2 , θk gk ( μ1 , μ2 ,
数理统计
定义 用样本原点矩估计相应的总体原点矩 ,
用样本原点矩的连续函数估计相应的总体原点矩的 连续函数, 这种参数点估计法称为矩估计法 . 矩估计法的具体做法如下 设总体的分布函数中含有k个未知参数 θ1 , θ2 , 那么它的前k阶矩 μ1 , μ2 ,
, θk ,
, μk , 一般
l xi P{ X xi ;1 , 2 , , k } l E ( X l ) l 1 hl (1 , 2 , , k ) x l p ( x; , , , )dx 1 2 k
2 1
b μ1 3( μ2 μ12 )
于是 a , b 的矩估计量为
总体矩
a A1 3( A2 A12 ) 3 n 2 X ( X X ) , i n i 1
3 n 2 b X ( X X ) n i 1 i
样本矩
数理统计
例2 设总体 X 的均值 μ和方差 σ 2 ( 0) 都存
数理统计
点估计问题的一般提法 设总体 X 的分布函数 F ( x; )的形式为已
知, 是待估参数 . X 1 , X 2 ,, X n 是 X 的一个样 本, x1 , x2 ,, xn 为相应的一个样本值 .
数理统计7:矩法估计(MM)、极大似然估计(MLE),定时截尾实验

数理统计7:矩法估计(MM)、极⼤似然估计(MLE),定时截尾实验在上⼀篇⽂章的最后,我们指出,参数估计是不可能穷尽讨论的,要想对各种各样的参数作出估计,就需要⼀定的参数估计⽅法。
今天我们将讨论常⽤的点估计⽅法:矩估计、极⼤似然估计,它们各有优劣,但都很重要。
由于本系列为我独⾃完成的,缺少审阅,如果有任何错误,欢迎在评论区中指出,谢谢!⽬录Part 1:矩法估计矩法估计的重点就在于“矩”字,我们知道矩是概率分布的⼀种数字特征,可以分为原点矩和中⼼矩两种。
对于随机变量X⽽⾔,其k阶原点矩和k阶中⼼矩为a_k=\mathbb{E}(X^k),\quad m_k=\mathbb{E}[X-\mathbb{E}(X)]^k,特别地,⼀阶原点矩就是随机变量的期望,⼆阶中⼼矩就是随机变量的⽅差,由于\mathbb{E}(X-\mathbb{E}(X))=0,所以我们不定义⼀阶中⼼矩。
实际⽣活中,我们不可能了解X的全貌,也就不可能通过积分来求X的矩,因⽽需要通过样本(X_1,\cdots,X_n)来估计总体矩。
⼀般地,由n个样本计算出的样本k阶原点矩和样本k阶中⼼矩分别是a_{n,k}=\frac{1}{n}\sum_{j=1}^{n}X_j^k,\quad m_{n,k}=\frac{1}{n}\sum_{j=1}^{n}(X_j-\bar X)^k.显然,它们都是统计量,因为给出样本之后它们都是可计算的。
形式上,样本矩是对总体矩中元素的直接替换后求平均,因此总是⽐较容易计算的。
容易验证,a_{n,k}是a_k的⽆偏估计,但m_{n,k}则不是。
特别地,a_{n,1}=\bar X,m_{n,2}=\frac{1}{n}\sum_{j=1}^{n}(X_j-\bar X)^2=\frac{n-1}{n}S^2\xlongequal{def}S_n^2,⼀阶样本原点矩就是样本均值,⼆阶样本中⼼矩却不是样本⽅差,⽽需要经过⼀定的调整,这点务必注意。
矩估计与极大似然估计的典型例题

关于矩估计与极大似然估计的典型例题例1,设总体X 具有分布律⎟⎟⎠⎞⎜⎜⎝⎛−−22)1()1(2321~θθθθX 其中10<<θ为未知参数。
已经取得了样本值1,2,1321===x x x ,试求参数θ的矩估计与极大似然估计。
解:(i )求矩估计量,列矩方程(只有一个未知参数)XX E =−=−×+−×+=θθθθθ23)1(3)1(22)(22得6523432x 32X 3=−=−=−=矩θ(ii ii)求极大似然估计,写出似然函数,即样本出现的概率)求极大似然估计,写出似然函数,即样本出现的概率),,()(332211x X x X x X P L ====θ)1,2,1(321====X X X P )1()2()1(321=×=×==X P X P X P )1(2)1(2522θθθθθθ−=×−×=对数似然)1ln(ln 52ln )(ln θθθ−++=L 0115)(ln =−−=θθθθd L d 得极大似然估计为65ˆ=极θ例2,某种电子元件的寿命某种电子元件的寿命((以h 记)X 服从双参数指数分布服从双参数指数分布,,其概率密度为⎪⎩⎪⎨⎧≥−−=其他,0],/)(exp[1)(µθµθx x x f 其中0>µθ,均为未知参数,自一批这种零件中随机抽取n 件进行寿命试验,设它们的失效时间分别为.,,2,1n x x x L (1)求µθ,的最大似然估计量;(2)求µθ,的矩估计量。
解:(1)似然函数,记样本的联合概率密度为∏===ni i n x f x x x f L 12,1)();,,()(µθµθ,,L ⎪⎩⎪⎨⎧≥−−=∏=其他,0,,,]/)(exp[12,11µθµθn n i i x x x x L ⎪⎩⎪⎨⎧>≤−−=∑=)1()1(1,0),/)(exp(1xx n x ni i n µµθµθ在求极大似然估计时在求极大似然估计时,,0)(=µθ,L 肯定不是最大值的似然函数值,不考虑这部分,只考虑另一部分。
2.2 矩估计和最大似然估计

求未知参数 ( , 2 ) 的矩估计量. 解 分别用样本均值 X 和二阶中心矩(未修正样本方
差) M 2* 估计 EX 和 DX ,得 和 2 的联立方程组:
1 2 X exp , 2 M * (e 1) exp2 2 . 2
于是,得 和 2 的矩估计量:
* 2 X M 2 2 , ˆ ln ˆ . ln 1 2 M* X 2 X 2
* 2 2
1 2
.
二、最大似然估计法
1、最大似然原理 一个试验有若干个可能的结果 A,B,C, ,若在一次 试验中结果 A 出现, 则一般认为试验条件对结果 A 出现有利, 也即 A 出现的概率最大。
2
关于 和 2 解方程组:
1 ln X 2, ln X 2 2 2 , 2
* ln M 2 ln(e 1) 2 2 ln(e 1) ln X 2;
2 2
ln(e
2
* * M2 M2 2 1) ln 2 , e 1 2 , X X * M2 2 ˆ ln 1 2 ; X
第 3 页 共 13 页
2.2 矩估计和最大似然估计
* ˆ X 3M2 a 所以 a , b 的矩估计为 * ˆ b X 3M 2
矩估计和极大似然估计
^ 2
1 n
n i1
Xi2
2
X .
14/22
即
ˆ X ,
ˆ 2
1 n
n i 1
(Xi
X )2.
故,均值,方差2的矩估计为
ˆ ˆ
X, 2 1
n
n
(X
i1
i
X )2
即
n 1S2. n
15/22
如:正态总体N(, 2) 中和2的矩估计为
)2
i1 2
(2 ) e , 2
n 2
1
2
2
n i1
( xi )2
对数似然函数为
ln
L(,
2
)
n 2
ln( 2
)
n 2
ln
2
1
2
2
n
( xi
i1
)2,
35/22
似然方程组为
ln L(, 2 ) 1 2
ln L(, 2 )
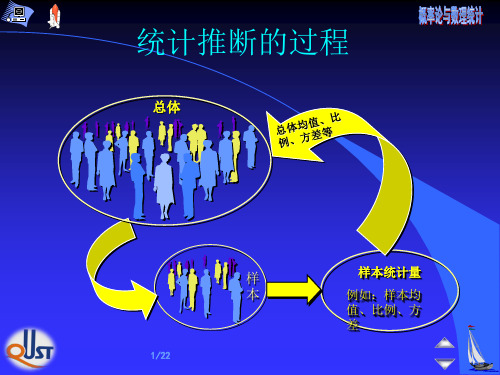
X1, X2 , … , Xn . 依样本对参数θ 做出估计,或估计参数θ 的 某个已知函数 g(θ ) 。 这类问题称为参数估计。
参数估计包括:点估计和区间估计。
4/22
为估计参数 µ,需要构造适当的统计量 T( X1, X2 , … , Xn ),
一旦当有了样本,就将样本值代入到该统计 量中,算出一个值作为µ的估计, 称该计算 值为 µ的一个点估计。
7/22
总体 k 阶原点矩 ak E(X k ),
样本 k 阶原点距
Ak
1 n
均匀分布的矩估计和极大似然估计

一、概述矩估计和极大似然估计是统计学中常用的两种参数估计方法,它们在众多领域中都有着重要的应用。
本文将对均匀分布的矩估计和极大似然估计进行深入探讨,分析它们的特点和适用范围,并对两种方法的优缺点进行比较和总结。
二、均匀分布的矩估计1. 均匀分布的概念和特点均匀分布是概率论中常见的一种离散型随机变量分布,它具有概率密度函数f(x) = 1/(b-a),其中a和b分别为分布的起始值和终止值。
均匀分布的特点是在[a, b]区间内各个数值出现的概率相等。
2. 均匀分布的矩估计方法均匀分布的参数估计通常采用矩估计方法。
矩估计是利用样本矩来估计总体矩,其基本思想是将样本矩与总体矩相等,通过方程求解得到参数的估计值。
对于均匀分布而言,可以通过样本均值和样本方差来进行参数估计,具体的计算过程可以通过数学推导来进行详细阐述。
三、均匀分布的极大似然估计1. 极大似然估计的基本原理极大似然估计是统计学中另一种常用的参数估计方法,其基本思想是在给定样本条件下,寻找最大化似然函数的参数值作为估计值。
对于均匀分布而言,可以通过求解似然函数的一阶导数为0的方程来得到参数的极大似然估计值,具体的推导过程也需要进行详细的分析和阐述。
2. 极大似然估计与矩估计的比较极大似然估计与矩估计在参数估计的方法和理论基础上存在着一定的差异,它们在不同情况下各有优劣。
通过比较两种方法在均匀分布参数估计中的应用,可以得出它们在精确度、稳定性和有效性等方面的优缺点,为使用者提供更多的参考依据。
四、实例分析通过实际的数据样本和模拟实验,可以对均匀分布的矩估计和极大似然估计进行对比分析。
选择适当的参数和样本规模,比较两种方法得到的参数估计值与真实值之间的偏差情况,从而验证两种方法的可靠性和有效性。
五、结论通过对均匀分布的矩估计和极大似然估计的深入研究和分析,可以得出它们在不同情况下各有优劣,适用范围也有所不同。
在实际应用中,需要根据具体问题的特点选择合适的参数估计方法,以保证估计结果的准确性和可靠性。
极大似然估计和矩估计

极大似然估计和矩估计
极大似然估计和矩估计是统计学中常用的参数估计方法。
极大似然估计是指在给定一组观测数据的情况下,寻找最能解释这些数据的模型参数值的方法。
具体而言,我们需要在模型的参数空间中找到一个使得观测数据的似然函数最大的参数值。
似然函数是参数的函数,描述了给定参数下观测数据出现的概率。
极大似然估计的优点是它是渐进无偏的、有效的和一致的,但缺点是它需要知道分布函数的形式,并且在计算中可能会受到样本量的限制。
矩估计是指通过样本矩来估计未知参数的方法。
这些样本矩可以看作是从总体矩中抽取的矩的估计,因此矩估计也称为矩法。
矩估计的优点是它不需要知道分布函数的形式,可以使用有限的样本数据进行估计,并且可以用于多维参数的估计。
但矩估计的缺点是它可能会受到样本量的限制,且估计结果通常比极大似然估计的结果更不精确。
总的来说,极大似然估计和矩估计都是重要的参数估计方法,具有各自的优缺点和适用范围。
在实际应用中,我们可以根据数据的特点和需要进行选择。
- 1 -。
极大似然估计和广义矩估计

05
案例分析
极大似然估计的案例
线性回归模型
在回归分析中,极大似然估计常用于估计线性回归模型的参数。通过最大化似然 函数,可以得到最佳线性无偏估计,使得预测值与实际观测值之间的误差最小。
正态分布参数估计
极大似然估计在正态分布的参数估计中也有广泛应用。例如,假设一组数据来自 正态分布,我们可以通过极大似然估计来估计均值和方差。
极大似然估计和广义矩估 计
• 引言 • 极大似然估计 • 广义矩估计 • 极大似然估计与广义矩估计的比较 • 案例分析 • 总结与展望
01
引言
主题简介
极大似然估计
极大似然估计是一种参数估计方 法,基于观测数据的概率分布模 型,通过最大化似然函数来估计 未知参数。
广义矩估计
广义矩估计是一种非参数估计方 法,通过最小化一系列矩(如一 阶矩、二阶矩等)的离差来估计 未知参数。
唯一性
在某些条件下,极大似然估计具有唯一性,即真实参 数值是极大似然函数的唯一最大值。
极大似然估计的步骤和实现
1 2
定义似然函数
根据数据分布和模型假设,定义似然函数。
求导并求解
对似然函数求导,并使用优化算法求解导数为零 的点,得到参数的极大似然估计值。
3
验证估计值
使用验证数据集验证估计值的准确性和有效性。
3. 优化目标函数
实现
使用优化算法(如牛顿法、拟牛顿法等) 最小化目标函数,以找到最优的模型参数 。
在编程语言(如Python、R等)中,可以 使用相应的统计库(如statsmodels、 EMMA等)来方便地实现广义矩估计。
04
极大似然估计与广义矩估计的比较
相似之处
理论基础
01
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
指数分布的矩估计和极大似然估计
指数分布是一种常见的概率分布,它在统计学中有着广泛的应用。
在实际应用中,我们需要对指数分布的参数进行估计,以便更好地理解和分析数据。
本文将介绍指数分布的矩估计和极大似然估计方法。
一、指数分布的概念
指数分布是一种连续概率分布,它的概率密度函数为:
f(x) = λe^(-λx) (x≥0)
其中,λ是分布的参数,表示单位时间内事件发生的平均次数。
指数分布的期望和方差分别为1/λ和1/λ^2。
二、矩估计
矩估计是一种常用的参数估计方法,它基于样本矩与理论矩之间的对应关系来估计参数。
对于指数分布,我们可以利用样本均值和方差来估计参数λ。
样本均值为:
X = (1/n)Σxi
样本方差为:
S^2 = (1/n)Σ(xi - X)^2
根据指数分布的期望和方差公式,我们可以得到:
E(X) = 1/λ
Var(X) = 1/λ^2
将样本均值和方差代入上式,得到:
X = 1/λ
S^2 = 1/λ^2
解出λ,即可得到参数的矩估计值。
三、极大似然估计
极大似然估计是一种常用的参数估计方法,它基于样本观测值的概率分布来估计参数。
对于指数分布,我们可以利用样本观测值的概率密度函数来估计参数λ。
样本观测值的概率密度函数为:
L(λ|x) = Πf(xi) = Πλe^(-λxi) = λ^n e^(-λΣxi)
取对数,得到:
lnL(λ|x) = nlnλ - λΣxi
对λ求导,令导数等于0,得到:
dlnL(λ|x)/dλ = n/λ - Σxi = 0
解出λ,即可得到参数的极大似然估计值。
四、总结
指数分布是一种常见的概率分布,它在统计学中有着广泛的应用。
在实际应用中,我们需要对指数分布的参数进行估计,以便更好地理解和分析数据。
本文介绍了指数分布的矩估计和极大似然估计方法,它们都是常用的参数估计方法,可以帮助我们更准确地估计指数分布的参数。