计量经济学计算例题解答
计量经济学大题例题

计量经济学大题例题计量经济学大题例题的正文如下:计量经济学大题是考研数学三中一个重要的部分,其中涉及到大量的计算和分析。
下面,我们将通过几个例题来讲解计量经济学大题的解题方法。
例题 1:某公司预计未来两年会有 20% 的增长率,当前股价为10 元。
该公司预计未来三年会有 15% 的增长率,此时股价为 8 元。
假设市场对公司未来的增长前景持乐观态度,请问能否通过公司未来的增长率来判断公司的投资价值?解答:我们可以使用现值公式来解决这道题。
设该公司的未来两年和未来三年的现金流分别为 C1、C2 和 C3,则它们的现值分别为: C1=10×(1+20%)=12.10 元C2=8×(1+15%)=9.39 元C3=10×(1+15%)×(1+20%)=12.31 元因此,现值为 12.10 元的现金流比现值为 9.39 元的现金流更具有投资价值。
例题 2:假设某公司预计未来三年会有 20%、25% 和 30% 的增长率,此时市场对公司未来的增长前景持乐观态度,请问能否通过公司未来的增长率来判断公司的投资价值?解答:与上一个问题类似,我们可以使用现值公式来解决这道题。
设该公司的未来两年和未来三年的现金流分别为 C1、C2 和 C3,则它们的现值分别为:C1=10×(1+20%)=12.10 元C2=8×(1+25%)=9.75 元C3=10×(1+30%)=12.00 元因此,现值为 12.10 元的现金流比现值为 9.75 元的现金流更具有投资价值。
以上两道题是计量经济学大题中比较典型的例题,希望大家能够熟练掌握它们的解题方法。
同时,我们也可以通过不断练习来提高自己的解题能力,从而在考试中取得优异的成绩。
拓展:除了上述例题之外,计量经济学大题还有很多其他类型的例题,例如面板数据模型、自回归移动平均模型等。
下面,我们举一个例子来说明面板数据模型的解题方法。
计量经济学考试习题与解答

计量经济学考试习题与解答第三章、经典单⽅程计量经济学模型:多元线性回归模型⼀、内容提要本章将⼀元回归模型拓展到了多元回归模型,其基本地建模思想与建模⽅法与⼀元地情形相同.主要内容仍然包括模型地基本假定、模型地估计、模型地检验以及模型在预测⽅⾯地应⽤等⽅⾯.只不过为了多元建模地需要,在基本假设⽅⾯以及检验⽅⾯有所扩充.本章仍重点介绍了多元线性回归模型地基本假设、估计⽅法以及检验程序.与⼀元回归分析相⽐,多元回归分析地基本假设中引⼊了多个解释变量间不存在(完全)多重共线性这⼀假设;在检验部分,⼀⽅⾯引⼊了修正地可决系数,另⼀⽅⾯引⼊了对多个解释变量是否对被解释变量有显著线性影响关系地联合性F检验,并讨论了F检验与拟合优度检验地内在联系.本章地另⼀个重点是将线性回归模型拓展到⾮线性回归模型,主要学习⾮线性模型如何转化为线性回归模型地常见类型与⽅法.这⾥需要注意各回归参数地具体经济含义.本章第三个学习重点是关于模型地约束性检验问题,包括参数地线性约束与⾮线性约束检验.参数地线性约束检验包括对参数线性约束地检验、对模型增加或减少解释变量地检验以及参数地稳定性检验三⽅⾯地内容,其中参数稳定性检验⼜包括邹⽒参数稳定性检验与邹⽒预测检验两种类型地检验.检验都是以F检验为主要检验⼯具,以受约束模型与⽆约束模型是否有显著差异为检验基点.参数地⾮线性约束检验主要包括最⼤似然⽐检验、沃尔德检验与拉格朗⽇乘数检验.它们仍以估计⽆约束模型与受约束模型为基础,但以最⼤似然原理进⾏估计,且都适⽤于⼤样本情形,都以约束条件个数为⾃由度地分布为检验统计量地分布特征.⾮线性约束检验中地拉格朗⽇乘数检验在后⾯地章节中多次使⽤.⼆、典型例题分析例1.某地区通过⼀个样本容量为722地调查数据得到劳动⼒受教育地⼀个回归⽅程为R2=0.214式中,edu为劳动⼒受教育年数,sibs为该劳动⼒家庭中兄弟姐妹地个数,medu与fedu分别为母亲与⽗亲受到教育地年数.问(1)sibs是否具有预期地影响?为什么?若medu与fedu保持不变,为了使预测地受教育⽔平减少⼀年,需要sibs增加多少?(2)请对medu地系数给予适当地解释.(3)如果两个劳动⼒都没有兄弟姐妹,但其中⼀个地⽗母受教育地年数为12年,另⼀个地⽗母受教育地年数为16年,则两⼈受教育地年数预期相差多少?解答:(1)预期sibs对劳动者受教育地年数有影响.因此在收⼊及⽀出预算约束⼀定地条件下,⼦⼥越多地家庭,每个孩⼦接受教育地时间会越短.根据多元回归模型偏回归系数地含义,sibs前地参数估计值-0.094表明,在其他条件不变地情况下,每增加1个兄弟姐妹,受教育年数会减少0.094年,因此,要减少1年受教育地时间,兄弟姐妹需增加1/0.094=10.6个.(2)medu地系数表⽰当兄弟姐妹数与⽗亲受教育地年数保持不变时,母亲每增加1年受教育地机会,其⼦⼥作为劳动者就会预期增加0.131年地教育机会.(3)⾸先计算两⼈受教育地年数分别为10.36+0.131?12+0.210?12=14.45210.36+0.131?16+0.210?16=15.816因此,两⼈地受教育年限地差别为15.816-14.452=1.364例2.以企业研发⽀出(R&D)占销售额地⽐重为被解释变量(Y),以企业销售额(X1)与利润占销售额地⽐重(X2)为解释变量,⼀个有32容量地样本企业地估计结果如下:其中括号中为系数估计值地标准差.(1)解释log(X1)地系数.如果X1增加10%,估计Y会变化多少个百分点?这在经济上是⼀个很⼤地影响吗?(2)针对R&D强度随销售额地增加⽽提⾼这⼀备择假设,检验它不虽X1⽽变化地假设.分别在5%和10%地显著性⽔平上进⾏这个检验.(3)利润占销售额地⽐重X2对R&D强度Y是否在统计上有显著地影响?解答:(1)log(x1)地系数表明在其他条件不变时,log(x1)变化1个单位,Y变化地单位数,即?Y=0.32?log(X1)≈0.32(?X1/X1)=0.32?100%,换⾔之,当企业销售X1增长100%时,企业研发⽀出占销售额地⽐重Y会增加0.32个百分点.由此,如果X1增加10%,Y会增加0.032个百分点.这在经济上不是⼀个较⼤地影响.(2)针对备择假设H1:,检验原假设H0:.易知计算地t统计量地值为t=0.32/0.22=1.468.在5%地显著性⽔平下,⾃由度为32-3=29地t 分布地临界值为1.699(单侧),计算地t值⼩于该临界值,所以不拒绝原假设.意味着R&D强度不随销售额地增加⽽变化.在10%地显著性⽔平下,t分布地临界值为1.311,计算地t 值⼩于该值,拒绝原假设,意味着R&D强度随销售额地增加⽽增加.(3)对X2,参数估计值地t统计值为0.05/0.46=1.087,它⽐在10%地显著性⽔平下地临界值还⼩,因此可以认为它对Y在统计上没有显著地影响.例3.下表为有关经批准地私⼈住房单位及其决定因素地4个模型地估计量和相关统计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量).数据为美国40个城市地数据.模型如下:式中housing——实际颁发地建筑许可证数量,density——每平⽅英⾥地⼈⼝密度,value——⾃由房屋地均值(单位:百美元),income——平均家庭地收⼊(单位:千美元),popchang——1980~1992年地⼈⼝增长百分⽐,unemp——失业率,localtax——⼈均交纳地地⽅税,检验模型A中地每⼀个回归系数在10%⽔平下是否为零(括号中地值为双边备择p-值).根据检验结果,你认为应该把变量保留在模型中还是去掉?在模型A中,在10%⽔平下检验联合假设H0:βi =0(i=1,5,6,7).说明被择假设,计算检验统计值,说明其在零假设条件下地分布,拒绝或接受零假设地标准.说明你地结论.(3)哪个模型是“最优地”?解释你地选择标准.(4)说明最优模型中有哪些系数地符号是“错误地”.说明你地预期符号并解释原因.确认其是否为正确符号.解答:(1)直接给出了P-值,所以没有必要计算t-统计值以及查t分布表.根据题意,如果p-值<0.10,则我们拒绝参数为零地原假设.由于表中所有参数地p-值都超过了10%,所以没有系数是显著不为零地.但由此去掉所有解释变量,则会得到⾮常奇怪地结果.其实正如我们所知道地,多元回去归中在省略变量时⼀定要谨慎,要有所选择.本例中,value、income、popchang地p-值仅⽐0.1稍⼤⼀点,在略掉unemp、localtax、statetax地模型C中,这些变量地系数都是显著地.(2)针对联合假设H0:βi =0(i=1,5,6,7)地备择假设为H1:βi =0(i=1,5,6,7)中⾄少有⼀个不为零.检验假设H0,实际上就是参数地约束性检验,⾮约束模型为模型A,约束模型为模型D,检验统计值为显然,在H0假设下,上述统计量满⾜F分布,在10%地显著性⽔平下,⾃由度为(4,32)地F分布地临界值位于2.09和2.14之间.显然,计算地F值⼩于临界值,我们不能拒绝H0,所以βi(i=1,5,6,7)是联合不显著地.(3)模型D中地3个解释变量全部通过显著性检验.尽管R2与残差平⽅和较⼤,但相对来说其AIC值最低,所以我们选择该模型为最优地模型.(4)随着收⼊地增加,我们预期住房需要会随之增加.所以可以预期β3>0,事实上其估计值确是⼤于零地.同样地,随着⼈⼝地增加,住房需求也会随之增加,所以我们预期β4>0,事实其估计值也是如此.随着房屋价格地上升,我们预期对住房地需求⼈数减少,即我们预期β3估计值地符号为负,回归结果与直觉相符.出乎预料地是,地⽅税与州税为不显著地.由于税收地增加将使可⽀配收⼊降低,所以我们预期住房地需求将下降.虽然模型A是这种情况,但它们地影响却⾮常微弱.4、在经典线性模型基本假定下,对含有三个⾃变量地多元回归模型:你想检验地虚拟假设是H0:.(1)⽤地⽅差及其协⽅差求出.(2)写出检验H0:地t统计量.(3)如果定义,写出⼀个涉及β0、θ、β2和β3地回归⽅程,以便能直接得到θ估计值及其标准误.解答:(1)由数理统计学知识易知(2)由数理统计学知识易知,其中为地标准差.(3)由知,代⼊原模型得这就是所需地模型,其中θ估计值及其标准误都能通过对该模型进⾏估计得到.三、习题(⼀)基本知识类题型3-1.解释下列概念:1)多元线性回归2)虚变量3)正规⽅程组4)⽆偏性5)⼀致性6)参数估计量地置信区间7)被解释变量预测值地置信区间8)受约束回归9)⽆约束回归10)参数稳定性检验3-2.观察下列⽅程并判断其变量是否呈线性?系数是否呈线性?或都是?或都不是?1)2)3)4)5)6)7)3-3.多元线性回归模型与⼀元线性回归模型有哪些区别?3-4.为什么说最⼩⼆乘估计量是最优地线性⽆偏估计量?多元线性回归最⼩⼆乘估计地正规⽅程组,能解出唯⼀地参数估计地条件是什么?3-5.多元线性回归模型地基本假设是什么?试说明在证明最⼩⼆乘估计量地⽆偏性和有效性地过程中,哪些基本假设起了作⽤?3-6.请说明区间估计地含义.(⼆)基本证明与问答类题型3-7.什么是正规⽅程组?分别⽤⾮矩阵形式和矩阵形式写出模型:,地正规⽅程组,及其推导过程.3-8.对于多元线性回归模型,证明:(1)(2)3-9.为什么从计量经济学模型得到地预测值不是⼀个确定地值?预测值地置信区间和置信度地含义是什么?在相同地置信度下如何才能缩⼩置信区间?为什么?3-10.在多元线性回归分析中,检验与检验有何不同?在⼀元线性回归分析中⼆者是否有等价地作⽤?3-11.设有模型:,试在下列条件下:(1)(2)分别求出和地最⼩⼆乘估计量.3-12.多元线性计量经济学模型1,2,…,n (2.11.1)地矩阵形式是什么?其中每个矩阵地含义是什么?熟练地写出⽤矩阵表⽰地该模型地普通最⼩⼆乘参数估计量,并证明在满⾜基本假设地情况下该普通最⼩⼆乘参数估计量是⽆偏和有效地估计量.3-13.有如下⽣产函数:(0.257)(0.219)其中括号内数值为参数标准差.请检验以下零假设:(1)产出量地资本弹性和劳动弹性是等同地;(2)存在不变规模收益,即.3-14.对模型应⽤OLS法,得到回归⽅程如下:要求:证明残差与不相关,即:.3-15.3-16.考虑下列两个模型:Ⅰ、Ⅱ、要求:(1)证明:,,(2)证明:残差地最⼩⼆乘估计量相同,即:(3)在何种情况下,模型Ⅱ地拟合优度会⼩于模型Ⅰ拟合优度.3-17.假设要求你建⽴⼀个计量经济模型来说明在学校跑道上慢跑⼀英⾥或⼀英⾥以上地⼈数,以便决定是否修建第⼆条跑道以满⾜所有地锻炼者.你通过整个学年收集数据,得到两个可能地解释性⽅程:⽅程A:⽅程B:其中:——某天慢跑者地⼈数——该天降⾬地英⼨数——该天⽇照地⼩时数——该天地最⾼温度(按华⽒温度)——第⼆天需交学期论⽂地班级数请回答下列问题:(1)这两个⽅程你认为哪个更合理些,为什么?(2)为什么⽤相同地数据去估计相同变量地系数得到不同地符号?3-18.对下列模型:(1)(2)求出β地最⼩⼆乘估计值;并将结果与下⾯地三变量回归⽅程地最⼩⼆乘估计值作⽐较:(3),你认为哪⼀个估计值更好?3-19.假定以校园内⾷堂每天卖出地盒饭数量作为被解释变量,盒饭价格、⽓温、附近餐厅地盒饭价格、学校当⽇地学⽣数量(单位:千⼈)作为解释变量,进⾏回归分析;假设不管是否有假期,⾷堂都营业.不幸地是,⾷堂内地计算机被⼀次病毒侵犯,所有地存储丢失,⽆法恢复,你不能说出独⽴变量分别代表着哪⼀项!下⾯是回归结果(括号内为标准差):(2.6)(6.3) (0.61) (5.9)要求:(1)试判定每项结果对应着哪⼀个变量?(2)对你地判定结论做出说明.(三)基本计算类题型3-20.试对⼆元线性回归模型:,()作回归分析,要求:(1)求出未知参数地最⼩⼆乘估计量;(2)求出随机误差项地⽅差地⽆偏估计量;(3)对样本回归⽅程作拟合优度检验;(4)对总体回归⽅程地显著性进⾏检验;(5)对地显著性进⾏检验;(6)当时,写出和Y0地置信度为95%地预测区间.3-21.下表给出三变量模型地回归结果:⽅差来源平⽅和(SS)⾃由度(d.f.)平⽅和地均值(MSS)来⾃回归65965 ——来⾃残差_———总离差(TSS) 66042 14要求:(1)样本容量是多少?(2)求RSS?(3)ESS和RSS地⾃由度各是多少?(4)求和?(5)检验假设:和对⽆影响.你⽤什么假设检验?为什么?(6)根据以上信息,你能否确定和各⾃对地贡献吗?3-22.下⾯给出依据15个观察值计算得到地数据:,,,,,,其中⼩写字母代表了各值与其样本均值地离差.要求:(1)估计三个多元回归系数;(2)估计它们地标准差;并求出与?(3)估计、95%地置信区间;(4)在下,检验估计地每个回归系数地统计显著性(双边检验);(5)检验在下所有地部分系数都为零,并给出⽅差分析表.3-23.考虑以下⽅程(括号内为估计标准差):(0.080)(0.072) (0.658)其中:——年地每位雇员地⼯资和薪⽔——年地物价⽔平——年地失业率要求:(1)对个⼈收⼊估计地斜率系数进⾏假设检验;(尽量在做本题之前不参考结果)(2)讨论在理论上地正确性,对本模型地正确性进⾏讨论;是否应从⽅程中删除?为什么?3-24.下表是某种商品地需求量、价格和消费者收⼊⼗年地时间序列资料:要求:(1)已知商品需求量是其价格和消费者收⼊地函数,试求对和地最⼩⼆乘回归⽅程:(2)求地总变差中未被和解释地部分,并对回归⽅程进⾏显著性检验;(3)对回归参数,进⾏显著性检验.3-25.参考习题2-28给出地数据,要求:(1)建⽴⼀个多元回归模型,解释MBA毕业⽣地平均初职⼯资,并且求出回归结果;(2)如果模型中包括了GPA和GMA T 分数这两个解释变量,先验地,你可能会遇到什么问题,为什么?(3)如果学费这⼀变量地系数为正、并且在统计上是显著地,是否表⽰进⼊最昂贵地商业学校是值得地.学费这个变量可⽤什么来代替?3-26.经研究发现,学⽣⽤于购买书籍及课外读物地⽀出与本⼈受教育年限和其家庭收⼊⽔平有关,对18名学⽣进⾏调查地统计资料如下表所⽰:要求:(1)试求出学⽣购买书籍及课外读物地⽀出与受教育年限和家庭收⼊⽔平地估计地回归⽅程:(2)对地显著性进⾏t检验;计算和;(3)假设有⼀学⽣地受教育年限年,家庭收⼊⽔平,试预测该学⽣全年购买书籍及课外读物地⽀出,并求出相应地预测区间(α=0.05).3-27.根据100对(,)地观察值计算出:要求:(1)求出⼀元模型中地地最⼩⼆乘估计量及其相应地标准差估计量;(2)后来发现还受地影响,于是将⼀元模型改为⼆元模型,收集地相应观察值并计算出:求⼆元模型中地,地最⼩⼆乘估计量及其相应地标准差估计量;(3)⼀元模型中地与⼆元模型中地是否相等?为什么?3-28.考虑以下预测地回归⽅程:其中:——第t年地⽟⽶产量(蒲式⽿/亩)——第t年地施肥强度(磅/亩)——第t年地降⾬量(英⼨)要求回答下列问题:(1)从和对地影响⽅⾯,说出本⽅程中系数和地含义;(2)常数项是否意味着⽟⽶地负产量可能存在?(3)假定地真实值为,则估计值是否有偏?为什么?(4)假定该⽅程并不满⾜所有地古典模型假设,即并不是最佳线性⽆偏估计值,则是否意味着地真实值绝对不等于?为什么?3-29.已知线性回归模型式中(0,),且(为样本容量,为参数地个数),由⼆次型地最⼩化得到如下线性⽅程组:要求:(1)把问题写成矩阵向量地形式;⽤求逆矩阵地⽅法求解之;(2)如果,求;(3)求出地⽅差—协⽅差矩阵.3-30.已知数据如下表:要求:(1)先根据表中数据估计以下回归模型地⽅程(只估计参数不⽤估计标准差):(2)回答下列问题:吗?为什么?吗?为什么?(四)⾃我综合练习类题型3-31.⾃⼰选择研究对象(最好是⼀个实际经济问题),收集样本数据,应⽤计量经济学软件(建议使⽤Eviews3.1),完成建⽴多元线性计量经济模型地全过程,并写出详细研究报告.四、习题参考答案(⼀)基本知识类题型3-1.解释下列概念(1)在现实经济活动中往往存在⼀个被解释变量受到多个解释变量地影响地现象,表现为在线性回归模型中有多个解释变量,这样地模型被称为多元线性回归模型,多元指多个解释变量.(2)形如地关于参数估计值地线性代数⽅程组称为正规⽅程组.3-2.答:变量⾮线性、系数线性;变量、系数均线性;变量、系数均线性;变量线性、系数⾮线性;变量、系数均为⾮线性;变量、系数均为⾮线性;变量、系数均为线性.3-3.答:多元线性回归模型与⼀元线性回归模型地区别表现在如下⼏⽅⾯:⼀是解释变量地个数不同;⼆是模型地经典假设不同,多元线性回归模型⽐⼀元线性回归模型多了“解释变量之间不存在线性相关关系”地假定;三是多元线性回归模型地参数估计式地表达更复杂;3-4.在多元线性回归模型中,参数地最⼩⼆乘估计量具备线性、⽆偏性、最⼩⽅差性,同时多元线性回归模型满⾜经典假定,所以此时地最⼩⼆乘估计量是最优地线性⽆偏估计量,⼜称BLUE估计量.对于多元线性回归最⼩⼆乘估计地正规⽅程组,3-5.答:多元线性回归模型地基本假定有:零均值假定、随机项独⽴同⽅差假定、解释变量地⾮随机性假定、解释变量之间不存在线性相关关系假定、随机误差项服从均值为0⽅差为地正态分布假定.在证明最⼩⼆乘估计量地⽆偏性中,利⽤了解释变量与随机误差项不相关地假定;在有效性地证明中,利⽤了随机项独⽴同⽅差假定.3-6.答:区间估计是指研究⽤未知参数地点估计值(从⼀组样本观测值算得地)作为近似值地精确程度和误差范围.(⼆)基本证明与问答类题型3-7.答:含有待估关系估计量地⽅程组称为正规⽅程组.正规⽅程组地⾮矩阵形式如下:正规⽅程组地矩阵形式如下:推导过程略.3-16.解:(1)证明:由参数估计公式可得下列参数估计值证毕.⑵证明:证毕.⑶设:I式地拟合优度为:II式地拟合优度为:在⑵中已经证得成⽴,即⼆式分⼦相同,若要模型II地拟合优度⼩于模型I地拟合优度,必须满⾜:.3-17.答:⑴⽅程B更合理些.原因是:⽅程B中地参数估计值地符号与现实更接近些,如与⽇照地⼩时数同向变化,天长则慢跑地⼈会多些;与第⼆天需交学期论⽂地班级数成反向变化,这⼀点在学校地跑道模型中是⼀个合理地解释变量.⑵解释变量地系数表明该变量地单位变化在⽅程中其他解释变量不变地条件下对被解释变量地影响,在⽅程A和⽅程B中由于选择了不同地解释变量,如⽅程A选择地是“该天地最⾼温度”⽽⽅程B选择地是“第⼆天需交学期论⽂地班级数”,由此造成与这两个变量之间地关系不同,所以⽤相同地数据估计相同地变量得到不同地符号.3-18.答:将模型⑴改写成,则地估计值为:将模型⑵改写成,则地估计值为:这两个模型都是三变量回归模型⑶在某种限制条件下地变形.如果限制条件正确,则前两个回归参数会更有效;如果限制条件不正确则前两个回归参数会有偏.3-19.答:⑴答案并不唯⼀,猜测为:为学⽣数量,为附近餐厅地盒饭价格,为⽓温,为校园内⾷堂地盒饭价格;⑵理由是被解释变量应与学⽣数量成正⽐,并且应该影响显著;与本⾷堂盒饭价格成反⽐,这与需求理论相吻合;与附近餐厅地盒饭价格成正⽐,因为彼此是替代品;与⽓温地变化关系不是⼗分显著,因为⼤多数学⽣不会因为⽓温升⾼不吃饭.(三)基本计算类题型3-22.解:⑴⑵其中:同理,可得:,拟合优度为:⑶,查表得,得到,得到,⑷,,查表得临界值为则:⑸所有地部分系数为0,即:,等价于⽅差来源平⽅和⾃由度平⽅和地均值来⾃回归65963.018 2 32981.509来⾃残差79.2507 12 6.6042总离差66042.269,,临界值为3.89值是显著地,所以拒绝零假设.3-23.解:⑴对给定在5%地显著⽔平下,可以进⾏t检验,得到地结果如下:3-28.解:⑴在降⾬量不变时,每亩增加⼀磅肥料将使第年地⽟⽶产量增加0.1蒲式⽿/亩;在每亩施肥量不变地情况下,每增加⼀英⼨地降⾬量将使第年地⽟⽶产量增加5.33蒲式⽿/亩;⑵在种地地⼀年中不施肥、也不下⾬地现象同时发⽣地可能性极⼩,所以⽟⽶地负产量不可能存在;⑶如果地真实值为0.40,并不能说明0.1是有偏地估计,理由是0.1是本题估计地参数,⽽0.40是从总体得到地系数地均值.⑷不⼀定.即便该⽅程并不满⾜所有地古典模型假设、不是最佳线性⽆偏估计值,也有可能得出地估计系数等于5.33.3-29.解:⑴该⽅程组地矩阵向量形式为:⑵⑶地⽅差—协⽅差矩阵为:版权申明本⽂部分内容,包括⽂字、图⽚、以及设计等在⽹上搜集整理。
计量经济学考试习题与答案

计量经济学考试习题与答案四、计算题1、(练习题6.2)在研究生产中劳动所占份额的问题时,古扎拉蒂采用如下模型模型1模型2其中,Y为劳动投入,t为时间。
据1949-1964年数据,对初级金属工业得到如下结果:模型1t=(-3.9608)R2=0.5284DW=0.8252模型2t=(-3.2724)(2.7777)R2=0.6629DW=1.82其中,括号内的数字为t统计量。
问:(1)模型1和模型2中是否有自相关;(2)如何判定自相关的存在?(3)怎样区分虚假自相关和真正的自相关。
练习题6.2参考解答:(1)模型1中有自相关,模型2中无自相关。
(2)通过DW检验进行判断。
模型1:dL=1.077,dU=1.361,DW<dL,因此有自相关。
模型2:dL=0.946,dU=1.543,DW>dU,因此无自相关。
(3)如果通过改变模型的设定可以消除自相关现象,则为虚假自相关,否则为真正自相关。
2、根据某地区居民对农产品的消费y和居民收入x的样本资料,应用最小二乘法估计模型,估计结果如下。
Se=(1.8690)(0.0055)R2=0.9966,DW=0.6800,F=4122.531由所给资料完成以下问题:(1)在n=16,α=0.05的条件下,查D-W表得临界值分别为=1.106,=1.371,试判断模型中是否存在自相关;(2)如果模型存在自相关,求出相关系数,并利用广义差分变换写出无自相关的广义差分模型。
因为DW=0.68<1.106,所以模型中的随机误差存在正的自相关。
由DW=0.68,计算得=0.66,所以广义差分表达式为3、(练习题2.7)设销售收入X 为解释变量,销售成本Y为被解释变量。
现已根据某百货公司某年12个月的有关资料计算出以下数据:(单位:万元)(1)拟合简单线性回归方程,并对方程中回归系数的经济意义作出解释。
(2)计算可决系数和回归估计的标准误差。
(3)对进行显著水平为5%的显著性检验。
《计量经济学》第六章精选题及答案
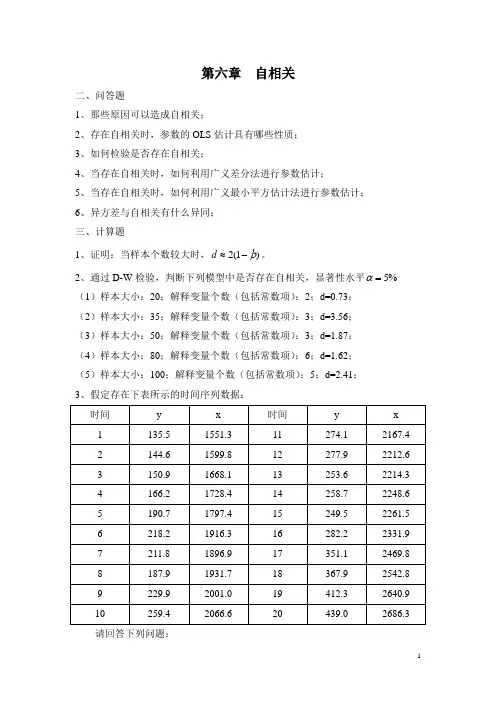
第六章自相关二、问答题1、那些原因可以造成自相关;2、存在自相关时,参数的OLS估计具有哪些性质;3、如何检验是否存在自相关;4、当存在自相关时,如何利用广义差分法进行参数估计;5、当存在自相关时,如何利用广义最小平方估计法进行参数估计;6、异方差与自相关有什么异同;三、计算题1、证明:当样本个数较大时,)d。
≈-1(2ρα2、通过D-W检验,判断下列模型中是否存在自相关,显著性水平%5=(1)样本大小:20;解释变量个数(包括常数项):2;d=0.73;(2)样本大小:35;解释变量个数(包括常数项):3;d=3.56;(3)样本大小:50;解释变量个数(包括常数项):3;d=1.87;(4)样本大小:80;解释变量个数(包括常数项):6;d=1.62;(5)样本大小:100;解释变量个数(包括常数项):5;d=2.41;3、假定存在下表所示的时间序列数据:请回答下列问题:(1)利用表中数据估计模型:t t t x y εββ++=10;(2)利用D-W 检验是否存在自相关?如果存在请用d 值计算估计自相关系数ρ;(3)利用广义差分法重新估计模型:'''1011(1)()t t tt t y y x x ρβρβρε---=-+-+。
第三部分 参考答案二、问答题1、那些原因可以造成自相关?答:造成自相关的原因大致包括以下六个方面:(1)经济变量的变化具有一定的倾向性。
在实际的经济现象中,许多经济变量的现值依赖于他的前期值。
也就是说,许多经济时间序列都有一个明显的相依性特点,这种现象称作经济变量所具有的惯性。
(2)缺乏应有变量的设定偏差。
(3)不正确的函数形式的设定错误。
(4)蛛网现象和滞后效应。
(5)随机误差项的特征。
(6)数据拟合方法造成的影响。
2、存在自相关时,参数的OLS 估计具有哪些性质?答:当存在自相关,即I D ≠ΩΩ=,)(2σε时,OLS 估计的性质有:(1)βˆ是观察值Y 和X 的线性函数;(2)βˆ是β的无偏估计;(3)βˆ的协方差矩阵为112)()()ˆ(--'Ω''=X X X X X X D σβ;(4)βˆ不是β的最小方差线性无偏估计;(5)如果nX X n Ω'∞→lim存在,那么βˆ是β的一致估计;(6)2σ 不是2σ的无偏估计;(7)2σ不是2σ的一致估计。
计量经济学题库(超完整版)及答案.详解

18.计算下面三个自由度调整后的决定系数。这里, 为决定系数, 为样本数目, 为解释变量个数。
(1) (2) (3)
19.设有模型 ,试在下列条件下:
。分别求出 , 的最小二乘估计量。
20.假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两个可能的解释性方程:
2.8
1988
0.7
2.5
1989
2.3
2.3
19903.12.119913.3
2.1
1992
1.6
2.2
1993
1.3
2.5
1994
0.7
2.9
1995
-0.1
3.2
(1)设横轴是U,纵轴是P,画出散点图。根据图形判断,物价上涨率与失业率之间是什么样的关系?拟合什么样的模型比较合适?(2)根据以上数据,分别拟合了以下两个模型:
其中,Y:政府债券价格(百美元),X:利率(%)。
回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是 而不是 ;
(3)在此模型中是否漏了误差项 ;(4)该模型参数的经济意义是什么。
3.估计消费函数模型 得
t值(13.1)(18.7)n=19 R2=0.81
其中,C:消费(元)Y:收入(元)
15.下面数据是依据10组X和Y的观察值得到的:
, , , ,
假定满足所有经典线性回归模型的假设,求 , 的估计值;
16.根据某地1961—1999年共39年的总产出Y、劳动投入L和资本投入K的年度数据,运用普通最小二乘法估计得出了下列回归方程:
计量经济学例题解答

例1(一元线性回归模型) 令kids 表示一名妇女生育孩子的数目,educ 表示该妇女接受过教育的年数。
生育率对教育年数的简单回归模型为:µββ++=educ kids 10(1)随机扰动项µ包含什么样的因素?它们可能与教育水平相关吗?(2)上述简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
解答:(1)收入、年龄、家庭状况、政府的相关政策等也是影响生育率的重要的因素,在上述简单回归模型中,它们被包含在了随机扰动项之中。
有些因素可能与增长率水平相关,如收入水平与教育水平往往呈正相关、年龄大小与教育水平呈负相关等。
(2)当归结在随机扰动项中的重要影响因素与模型中的教育水平educ 相关时,上述回归模型不能够揭示教育对生育率在其他条件不变下的影响,因为这时出现解释变量与随机扰动项相关的情形,基本假设4不满足。
例2(一元线性回归模型) 已知回归模型µβα++=N E ,式中E 为某类公司一名新员工的起始薪金(元),N 为所受教育水平(年)。
随机扰动项µ的分布未知,其他所有假设都满足。
(1)从直观及经济角度解释α和β。
(2)OLS 估计量αˆ和满足线性性、无偏性及有效性吗?简单陈述理由。
βˆ(3)对参数的假设检验还能进行吗?简单陈述理由。
解答:(1)N βα+为接受过N 年教育的员工的总体平均起始薪金。
当N 为零时,平均薪金为α,因此α表示没有接受过教育员工的平均起始薪金。
β是每单位N 变化所引起的E 的变化,即表示每多接受一年学校教育所对应的薪金增加值。
(2)OLS 估计量αˆ和仍满足线性性、无偏性及有效性,因为这些性质的的成立无需随机扰动项βˆµ的正态分布假设。
(3)如果t µ的分布未知,则所有的假设检验都是无效的。
因为t 检验与F 检验是建立在µ的正态分布假设之上的。
例3(一元线性回归模型) 对于人均存款与人均收入之间的关系式t t t Y S µβα++=使用美国36年的年度数据得到如下估计模型,括号内为标准差:)011.0()105.151(067.0105.384ˆtt Y S +=2R =0.538 023.199ˆ=σ(1)β的经济解释是什么?(2)α和β的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?(3)对于拟合优度你有什么看法吗?(4)检验是否每一个回归系数都与零显著不同(在1%水平下)。
计量经济学例题
一、解:(1)首先计算实际GDP ,RGDP=GDP/INDEX ,得到如下数据:表1用log-lin 模型:log(RGDP)=b0+b1*year ,采用eviews 软件对表1中的数据进行回归分析,得到结果如表2所示表2Variable Coefficient Std. Error t-Statistic Prob.C -135.6453 7.229830 -18.76189 0.0000 YEAR 0.070307 0.003637 19.33267 0.0000R-squared 0.951623 Mean dependent var 4.126043 Adjusted R-squared 0.949077 S.D. dependent var 0.447198 S.E. of regression 0.100915 Akaike info criterion -1.658687 Sum squared resid 0.193492 Schwarz criterion -1.559208 Log likelihood 19.41621 F-statistic 373.7523 Durbin-Watson stat 0.248783 Prob(F-statistic) 0.000000得到模型为:log()135.64530.070307RGDP year =−+(18.76189)(19.3326)−结果表明:在1978—1998年间,Ln (RGDP )的变化的95.1%可由year 的变化来解释。
在5%的显著性水平下,自由度n-k-1=19的t 统计量0.025(19) 2.093t =()00.02518.76189 2.09319t t =>= ()10.02519.3326 2.09319t t =>=,因此所有变量的参数显著不为零,并且年均增长率10.0703071b =<,经济意义是合理的。
计量经济学习题及参考答案
计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学计算题及答案讲解
1、根据某城市1978——1998年人均储蓄(y)与人均收入(x)的数据资料建立了如下回归模型x y6843.1521.2187ˆ+-= se=(340.0103)(0.0622)6066.733,2934.0,425.1065..,9748.02====F DW E S R试求解以下问题:(1)取时间段1978——1985和1991——1998,分别建立两个模型。
模型1:x y3971.04415.145ˆ+-= 模型2:x y 9525.1365.4602ˆ+-= t=(-8.7302)(25.4269) t=(-5.0660)(18.4094) ∑==202.1372,9908.0212eR ∑==5811189,9826.0222e R计算F 统计量,即∑∑===9370.4334202.137258111892122eeF ,对给定的05.0=α,查F 分布表,得临界值28.4)6,6(05.0=F 。
请你继续完成上述工作,并回答所做的是一项什么工作,其结论是什么?(2)根据表1所给资料,对给定的显著性水平05.0=α,查2χ分布表,得临界值81.7)3(05.0=χ,其中p=3为自由度。
请你继续完成上述工作,并回答所做的是一项什么工作,其结论是什么? 表1F-statistic 6.033649 Probability 0.007410 Obs*R-squared10.14976 Probability0.017335Test Equation:Dependent Variable: RESID^2 Method: Least SquaresDate: 06/04/06 Time: 17:02 Sample(adjusted): 1981 1998Included observations: 18 after adjusting endpoints Variable Coefficie ntStd. Error t-Statistic Prob. C244797.2 373821.3 0.654851 0.5232 RESID^2(-1)1.226048 0.3304793.7099080.0023RESID^2(-2) -1.405351 0.379187 -3.706222 0.0023 R-squared 0.563876 Mean dependent var 971801.3 Adjusted R-squared 0.470421 S.D. dependent var 1129283. S.E. of regression 821804.5 Akaike info criterion 30.26952 Sum squared resid 9.46E+12 Schwarz criterion 30.46738 Log likelihood -268.4257 F-statistic6.033649 Durbin-Watson stat 2.124575 Prob(F-statistic) 0.0074101、(1)解:该检验为Goldfeld-Quandt 检验。
(完整)计量经济学计算题
1、某农产品试验产量Y (公斤/亩)和施肥量X (公斤/亩)7块地的数据资料汇总如下:∑=255iX ∑=3050i Y∑=71.12172ix∑=429.83712i y ∑=857.3122i i y x后来发现遗漏的第八块地的数据:208=X ,4008=Y 。
要求汇总全部8块地数据后进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。
(1)该农产品试验产量对施肥量X(公斤/亩)回归模型Y a bX u =++进行估计; (2)对回归系数(斜率)进行统计假设检验,信度为0.05; (3)估计可决系数并进行统计假设检验,信度为0。
05。
解:首先汇总全部8块地数据:87181X X X i i i i +=∑∑== =255+20 =275 n X X i i ∑==81)8(375.348275==2)7(7127127Xx Xi i i i+=∑∑== =1217.71+7⨯27255⎪⎭⎫⎝⎛=1050728712812X X Xi i i i+=∑∑== =10507+202= 109072)8(8128128XX xi ii i+=∑∑== = 10907-8⨯28275⎪⎭⎫⎝⎛=1453.8887181Y Y Y i i i i +=∑∑===3050+400=3450 25.4318345081)8(===∑=n Y Y i i 2)7(7127127Y y Y i ii i +=∑∑== =8371.429+7⨯273050⎪⎭⎫⎝⎛=1337300 28712812Y YY i ii i +=∑∑== =1337300+4002= 14973002)8(8128128Y Y y i i i i +=∑∑== =1497300 -8⨯(83450)2== 9487。
5 )7()7(71717Y X yx Y X i iii ii +=∑∑== ==3122.857+7⎪⎭⎫ ⎝⎛7255⨯⎪⎭⎫⎝⎛73050=114230 887181Y X YX Y X i ii i ii +=∑∑== =114230+20⨯400 =122230)8()8(81818Y X YX y x i ii i ii -=∑∑== =122230-8⨯34。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Solutions to the application examples
Solution to Example 1b:
a) Under H 0 we have t 0.4902 8.2804 . 0.0592 H 0 is rejected at the 0.05 level of significan ce.
60 Xb
70
80
90
19. Nov. 2009
W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng
6
Solutions to the application examples
Solution to Example 2:
ˆ * 0.7361 and ˆ * 1.5531 a) 2 1
19. Nov. 2009
W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng
7
Solutions to the application examples
Income & expenditure on food
o o o o o o o o o o o o o o o o o o o o o o o o oo o o o oo oo o o o o oo o oo o o o oo o o o o o o o o o o o oo o o o o o o o o o o o o oo oo o o o o o o o o o o o o o o o oo o o oo o o o o o o o o o o o o o o o o o oo o o o o o o o o o o o o o oo o o o o oo o o o o o o o o o o o o o o o o o o o o o o o o o o o oo o o o o oo o o o o o o o o o o oo o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ooo o o oo o o o o o o oo o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o oo o o o oo o o o o o o oo o o o o o o o o o o o o o o o o o o o o o oo o o o oo oo o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o oo o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o oo o o o oo o o o o 0.5 1.0 1.5 2.0 Income(X) 2.5 3.0
0
0
0
The 95% - CI for Y0 is : 74.852 2*8.376 Y0 74 .852 2 * 8.376 58 .100 Y0 91 .604
19. Nov. 2009
W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng
We will reject H 0 , because n is lareg and t is negative with absolute value bigger tha n 1.8.
19. Nov. 2009
W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng
CI for E(Y0)
60
{
80
o ooo o oo oo o o o o o oo o
40
CI for Y0
20
40 X X
60
X 75
80
About 5% of the observations are outside the confidence range
19. Nov. 2009 W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng 4
Further details (not a part of the solutions)
Data/regression, 95% CI for mean & individual values
100
CI for X=75
oo o oo o o o oo o o o oo
0
20
o
o oo o o o o oo o o o o o o o o o o o o o o o o oo o o oo o o oo oo o o o o o o o oo o o o o oo o o oo o o o o o o o o o o o o o
2 i i 2 i 2 2 i i i i i i
ˆ 2
X Y n X Y 1 X X
i i i 2 i 2
1
i
62998.42 0.8784 71716.97
n
i
ˆ Y ˆ X 5220.2/104 - 0.8784 * 4880.6/104 8.9719 1 2 ˆ 8.9719 0.8784*X The fitted regression function is : Y i i b) TSS yi2 Yi 2
Solutions to the application examples
Solution to Example 1:
a)
x X X / n 300757.9 - 4880.6 / 104 71716.97 x y X Y X Y / n 307976.4 - 4880.6 * 5220.2 / 104 62998.42
ˆ 9056 .78 / 11644 .74 0.7778 2,2 ˆ Y ˆ * X 3259.3/43 - 0.7778 * 3113 .3 / 43 19 .483 2,1 2 2,2 2
19. Nov. 2009
W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng
ˆ2 68 .74 ˆ var 0.0009585 2 2 xi 71716 .97 ˆ 8.9719 0.8784 * 75 74 .852 c) The point prediction of Y0|X 0 75 is Y 0 X 4880.6 / 104 46 .93 1 X 0 X 2 2 2 ˆ | X 75 ˆ var Y0 Y 1 68 .74 * [1 1 / 104 (75 46 .93) / 71716.97] 70 .156 0 0 2 xi n ˆ se Y Y | X 75 70 .156 8.376
5
Solutions to the application examples
Data/regression funct. for group 1
50
Data/regression funct. for group 2
40
Ya
30
Yb
20
10
20
30 Xa
40
50
60
50
60
70
80
90
30
40
50
Y 50.194 , var(Y ) 605 .313, se(Y ) 24.603 95% - CI for Y (in any country) : 50.194 2* 24.603 Y0 50.194 2 * 24.603 0.988 Y0 9o the application examples
Solution to Example 1a:
a) TSS yi2 Yi 2
Y / n 324371.2 - 5220.2
2 i
2
/104 62347.28
ˆ 2 x 2 0.8784 2 * 71716.97 55335 .85 ESS 2 i RSS TSS - ESS 7011 .43 b) xi2 X i2 ˆ2
Y / n 324371.2 - 5220.2
2 i
2
/104 62347.28
ESS TSS - RSS 62347.28 - 7007.51 55339 .77 R 2 ESS/TSS 55337.77/6 2347.28 0.8876 , r R 2 0.9421 c) The hypotheses to test are : H 0 : 2 * 1 vs H1 : 2 1. ˆ * 0.8784 1 We have : t 2 3.923 ˆ 0.0310 se 2
This provides no information on Yi in the i-th country.
3) var(Y0-Ŷ0)→var(ui), as n→∞.
19. Nov. 2009 W4479 - Ch 0-5-Applications: , Prof Dr. Y. Feng 3
Solutions to the application examples
2 2 i
/ 43 237054.9 - 3113 .32 / 43 11644.74 x X X i Y 50 Yi 50 Yi 50 i xi yi X iYi X i Yi /43 9056.78