数据流体系结构风格4
2022年职业考证-软考-系统架构设计师考试全真模拟易错、难点剖析AB卷(带答案)试题号:62

2022年职业考证-软考-系统架构设计师考试全真模拟易错、难点剖析AB卷(带答案)一.综合题(共15题)1.单选题基于构件的软件开发中,构件分类方法可以归纳为三大类:()根据领域分析的结果将应用领域的概念按照从抽象到具体的顺序逐次分解为树形或有向无回路图结构 ;()利用Facet描述构件执行的功能、被操作的数据、构件应用的语境或任意其他特征;()使得检索者在阅读文档过程中可以按照人类的联想思维方式任意跳转到包含相关概念或构件的文档。
问题1选项A.关键字分类法B.刻面分类法C.语义匹配法D.超文本方法问题2选项A.关键字分类法B.刻面分类法C.语义匹配法D.超文本方法问题3选项A.关键字分类法B.刻面分类法C.语义匹配法D.超文本方法【答案】第1题:A第2题:B第3题:D【解析】第1题:本题考查的是构件管理相关知识。
目前,已有的构件分类方法可以分为三大类,分别是关键字分类法、刻面分类法和超文本组织方法。
关键字分类法:是一种最简单的构件库组织方法,其基本思想是:根据领域分析的结果将应用领域的概念按照从抽象到具体的顺序逐次分解为树状或有向无回路图结构。
每个概念用一个描述性的关键字表示。
不可分解的原子级关键字包含隶属于它的某些构件。
第一空描述的是关键字分类法,选择A选项。
刻面分类法:在刻面分类机制中,定义若干用于刻画构件特征的“面”(facet),每个面包含若干概念,这些概念表述构件在面上的特征。
刻画可以描述构件执行的功能、被操作的数据、构件应用的语境或任意其他特征。
第二空描述的是刻面分类法,选择B选项。
超文本组织方法:超文本组织方法与基于数据库系统的构件库组织方法不同,它基于全文检索技术,主要思想是:所有构件必须辅以详尽的功能或行为说明文档;说明中出现的重要概念或构件以网状链接方式相互连接;检索者在阅读文档的过程中可按照人类的联系思维方式任意跳转到包含相关概念或构件的文档;全文检索系统将用户给出的关键字与说明文档中的文字进行匹配,实现构件的浏览式检索。
2022年职业考证-软考-系统架构设计师考试全真模拟全知识点汇编押题第五期(含答案)试卷号:27

2022年职业考证-软考-系统架构设计师考试全真模拟全知识点汇编押题第五期(含答案)一.综合题(共15题)1.案例题某企业委托软件公司开发一套包裹信息管理系统,以便于对该企业通过快递收发的包裹信息进行统一管理,在系统设计阶段,需要对不同快递信息的包裹单信息进行建模,其中,邮政包裹单如图2-1所示:图2-1 包裹详情单【问题1】(13分)请说明关系型数据库开发中,逻辑数据模型设计过程包含哪些任务?根据图2-1 包裹详情单应该设计出哪些关系模式的名称,并指出每个关系模式的主键属性。
【问题2】(6分)请说明什么是超类实体?结合图中包裹单信息,试设计一种超类实体,给出完整的属性列表。
【问题3】(6分)请说明什么是派生属性?结合图2-1中包裹单信息说明哪个属性是派生属性。
【答案】【问题1】逻辑数据模型设计过程包含的任务:(1)构建系统上下文数据模型,包含实体及实体之间的联系:(2)绘制基于主键的数据模型,为每个实体添加主键属性;(3)构建全属性数据模型,为每个实体添加非主键属性:(4)利用规范化技术建立系统规范化数据模型。
包裹单的逻辑数据模型中包含的实体: (1)收件人(主键:电话);(2)寄件人(主键:电话);(3)包裹单(主键:编号)。
【问题2】超类实体是将多个实体中相同的属性组合起来构造出的新实体。
用户(姓名、电话、单位名称、详细地址)【问题3】派生属性是指某个实体的非主键属性由该实体其他非主键属性决定。
包裹单中的总计是由资费、挂号费、保价费、回执费计算得出,所以是派生属性。
【解析】【问题1】数据库设计分为概念结构设计、逻辑结构设计物理结构设计:概念设计也称为概念结构设计,其任务是在需求分析阶段产生的需求说明书的基础上,按照特定的方法将它们抽象为一个不依赖于任何DBMS的数据模型,即概念模型。
概念模型的表现形式即ER模型。
逻辑设计也称为逻辑结构设计,其主要任务是将概念设计阶段设计好的E-R图转换为与选用的具体机器上的DBMS所支持的数据模型相符合的逻辑结构(如:关系模式)。
分析比较KWIC系统实现四种不同体系结构风格

分析比较KWIC系统实现四种不同体系结构风格:班级:学号:院系:一、实验目的 (3)二、实验容 (3)三、实验要求与实验环境 (3)四、实验操作 (3)1数据流风格:批处理序列;管道/过滤器 (3)2采用调用/返回风格:主程序/子程序、面向对象风格、层次结构 (4)3仓库风格:数据库系统、超文本系统、黑板系统 (5)4独立构件风格:进程通讯、事件系统 (5)五实验总结 (6)一、实验目的通过KWIC 实例分析,理解和掌握软件体系结构风格设计与实现。
二、实验容多种软件风格设计与实现KWIC 实例:1.采用主/子程序体系结构风格实现KWIC 关键词索引系统2.采用面向对象体系架构风格实现KWIC 关键词索引系统3.采用管道过滤体系架构风格实现KWIC 关键词索引系统4.采用事件过程调用体系架构风格实现KWIC 关键词索引系统三、实验要求与实验环境熟练掌握基于主/子程序体系结构风格的KWIC 关键词索引系统,在此基础上,完成基于面向对象体系架构风格的KWIC 关键词索引系统设计与实现。
选做基于管道过滤体系架构风格的KWIC 关键词索引系统;选做基于事件过程调用体系架构风格的KWIC 关键词索引系统。
四、实验操作1数据流风格:批处理序列;管道/过滤器管道-过滤器风格将系统的功能逻辑建立为部件集合。
每个部件实例完成一个对数据流的独立功能处理,它接收数据流输入,进行转换和增量后进行数据流输出。
连接件是管道机制,它将前一个过滤器的数据流输出传递给后一个过滤器作为数据流输入。
连接件也可能会进行数据流的功能处理,进行转换或增量,但连接件进行功能处理的目的是为了适配前一个过滤器的输出和后一个过滤器的输入,而不是为了直接承载软件系统的需求。
各个过滤器可以并发执行。
每个过滤器都可以在数据输入不完备的情况下就开始进行处理,每次接到一部分数据流输入就处理和产生一部分输出。
这样,整个的过滤器网络就形成了一条流水线。
设计词汇表:Pipe, Filter构件和连接件类型构件:Filter连接件:Pipe例子:传统编译器优缺点:优点:易于理解并支持变换的复用。
数据流体系结构风格4

数据流体系结构风格4在当今数字化的时代,计算机系统的体系结构风格多种多样,其中数据流体系结构风格是一种具有独特特点和应用场景的重要类型。
数据流体系结构风格的核心思想是数据的流动驱动计算的执行。
在这种风格中,数据被视为系统的核心,而计算则是对数据的处理和转换。
与传统的控制流体系结构不同,数据流体系结构更加强调数据的流动和处理的并行性。
让我们先来看一个简单的例子来理解数据流体系结构。
假设有一个图像处理系统,它需要对输入的图像进行一系列的操作,比如灰度化、滤波、边缘检测等。
在传统的体系结构中,这些操作可能会按照顺序依次执行,一个操作完成后再进行下一个操作。
但在数据流体系结构中,只要输入的数据准备好,各个操作就可以同时进行,大大提高了处理的效率。
数据流体系结构风格的一个显著特点是高度的并行性。
由于数据的流动和处理是相互独立的,不同的数据处理单元可以同时对不同的数据进行操作,从而实现并行计算。
这种并行性使得系统能够在更短的时间内处理大量的数据,特别适用于那些对性能要求极高的应用,如科学计算、大数据处理等。
另一个重要特点是数据的确定性。
在数据流体系结构中,计算的结果只取决于输入的数据,而不受其他因素的影响。
这意味着只要输入的数据相同,每次计算的结果都是确定的,这为系统的可靠性和可预测性提供了保障。
然而,数据流体系结构风格也并非完美无缺。
它在灵活性方面可能存在一定的局限性。
由于数据的流动和处理是高度固定的,对于那些需要频繁更改计算流程或处理逻辑的应用,可能不太适用。
在实际应用中,数据流体系结构风格常常与其他体系结构风格相结合,以充分发挥各自的优势。
例如,在一个复杂的系统中,可能会在某些对性能要求极高的部分采用数据流体系结构,而在其他需要更高灵活性的部分则采用控制流体系结构。
为了实现数据流体系结构,需要相应的硬件和软件支持。
在硬件方面,需要具备能够快速传输和处理大量数据的能力,例如高速的总线、多核处理器等。
在软件方面,需要有专门的编程语言和开发工具,以便能够方便地描述和实现数据流的计算过程。
体系结构风格

体系结构风格
通用体系结构风格表
数据流系统 调用和返回系统 独立构件
虚拟机
批处理序列 主子程序
通信进程
解释器
数据中心系统 数据库
管道过滤器 面向对象系统 时间系统
基于规则系统 超文本系统
多级分层
黑板
体系结构风格
? 管道过滤器(PIPES AND FILTERS)
? 构件:管道,过滤器 ? 管道过滤器通用的结构
? 管线(Pipelines):限制系统的拓扑结构只能是过滤器的线 性序列
? 有界管道( Bounded Pipes):限制了在管道中能容纳的数据 量
? 类型定义管道( Typed Pipes):明确定义了在两个过滤器间 传输的数据类型
? Examples:编译器/信号处理/分布式系统
体系结构风格
? 必须修改所有显式调用它的其它对象,并消除由此带来的一些副作 用。例如,如果 A使用了对象B,C也使用了对象 B,那么,C对B的 使用所造成的对 A的影响可能是料想不到的
体系结构风格
? 事件驱动,隐式调用(EVENT-BASED, IMPLICITINVOCATION)
? 基于事件的隐式调用风格的思想是构件不直接调用一个过程, 而是触发或广播一个或多个事件。系统中的其它构件中的过 程在一个或多个事件中注册,当一个事件被触发,系统自动 调用在这个事件中注册的所有过程,这样,一个事件的触发 就导致了另一模块中的过程的调用。
? 优点:
? 因为对象对其它对象隐藏它的表示,所以可以改变一个对象的表示, 而不影响其它的对象
? 设计者可将一些数据存取操作的问题分解成一些交互的代理程序的 集合
? 缺点:
? 为了使一个对象和另一个对象通过过程调用等进行交互,必须知道 对象的标识。只要一个对象的标识改变了,就必须修改所有其他明 确调用它的对象。
软件体系结构风格综述

LOGO
数据抽象和面向对象组织
对象A
对象B
优点:对象对它的客 户隐藏了自己的表示, 所以对象可以不影响 这些客户就改变其实 现方法
对象C
缺点:对象之间的交互 必须知道对方的标识,增 强了对象之间的依赖关 系,降低了独立性。而且 一旦一个对象身份改变 , 则必须修改所有与之相 关的对象,进而可能带来 副作用问题。
LOGO
参考文献
[1]GARLAN D ,SHAW M. An Introduction to Software Architecture[R] . CMU-CS94-166 ,1994. [2]Liliana Dobrica and Eilaniemela. A Survey on Software Architecture Analysis Methods[J]. IEEE Transactions on Software Engineering,2002, 28(7):638- 653. [3]SHAW M, CLEMENTS P . A field guide to boxology : preliminary classification of architectural styles for software systems[C]//Proc of the 21st International Computer Software and Applications Conference . Washington DC: IEEE Computer Society , 1997: 6-13. [4]ABOWD G, ALLEN R, GARLAN D. Using style to understand descriptions of software architecture[J] .Software Engineering Notes , 1993 , 18(5) : 9-20 . [5]PERRY D E, WOLF A L . Foundations for the study of software architecture[J] . ACM SIGSOFT Software Engineering Notes ,1992, 17(4) : 40-52 . [6]李树澍.软件体系结构风格综述[J]. 安庆师范学院学报, 2006,12(4):1-4. [7]何炎祥,黄浩,石莉,张戈,李超. 软件体系结构中五种常见风格的剖析[J]. 计算机工 程,2000,26(10):30-32. [8]张广泉. 软件体系结构: 概念、风格与描述语言[J]. 重庆师范学院学 报,2000,17(3):1-5. [9]毛斐巧,齐德昱. 软件体系结构风格研究现状及存在的问题[J]. 计算机应用研 究,2008,25(8):2270-2273.
分析比较KWIC系统实现四种不同体系结构风格

分析比较KWIC系统实现四种不同体系结构风格KWIC系统(Keyword in Context)是一种文本处理系统,它通过对输入的文本进行预处理,将每个单词的关键字移到字母表序的最前面,从而方便用户查找和理解文本。
在实现KWIC系统的过程中,可以采用不同的体系结构风格。
本文将分析和比较KWIC系统实现的四种不同体系结构风格。
1.面向过程风格:面向过程风格是一种传统的体系结构风格,它以功能为中心,通过一系列的子程序来实现系统的功能。
在KWIC系统中,面向过程风格可以将各个功能模块划分为不同的子程序,如输入模块、处理模块和输出模块。
输入模块负责读取文本数据,处理模块负责对文本数据进行预处理,输出模块负责将处理后的文本数据进行显示或存储。
面向过程风格的优点是结构清晰,易于理解和维护。
然而,面向过程风格缺乏灵活性和可重用性,随着系统功能的扩展和变化,其复杂性和维护成本会增加。
2.面向对象风格:面向对象风格是一种基于对象和类的体系结构风格,它将系统划分为多个对象,每个对象都具有属性和方法。
在KWIC系统中,面向对象风格可以将输入、处理和输出等功能划分为不同的对象,对象之间通过消息传递来实现协作。
输入对象负责读取文本数据,处理对象负责对文本数据进行预处理,输出对象负责将处理后的文本数据进行显示或存储。
面向对象风格的优点是可重用性和灵活性强,易于扩展和维护。
然而,面向对象风格的缺点是易于产生过度设计和过度集成的问题,增加系统的复杂性和开发成本。
3.数据流风格:数据流风格是一种基于数据流和处理器之间的依赖关系的体系结构风格,它将系统看作一系列的数据流和处理器。
在KWIC系统中,数据流风格可以将输入、处理和输出等功能看作数据流,并将数据流之间的依赖关系表示为处理器的输入和输出。
处理器负责对输入的数据流进行处理,生成输出的数据流。
数据流风格的优点是模块化和并行化程度高,易于理解和调试。
然而,数据流风格的缺点是系统结构复杂,难以维护和扩展。
软件架构风格整理记忆
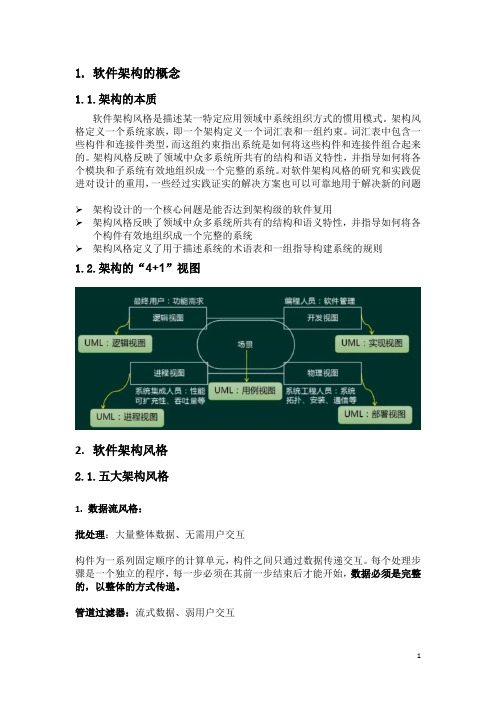
1.软件架构的概念1.1.架构的本质软件架构风格是描述某一特定应用领域中系统组织方式的惯用模式。
架构风格定义一个系统家族,即一个架构定义一个词汇表和一组约束。
词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。
架构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。
对软件架构风格的研究和实践促进对设计的重用,一些经过实践证实的解决方案也可以可靠地用于解决新的问题➢架构设计的一个核心问题是能否达到架构级的软件复用➢架构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个构件有效地组织成一个完整的系统➢架构风格定义了用于描述系统的术语表和一组指导构建系统的规则1.2.架构的“4+1”视图2.软件架构风格2.1.五大架构风格1.数据流风格:批处理:大量整体数据、无需用户交互构件为一系列固定顺序的计算单元,构件之间只通过数据传递交互。
每个处理步骤是一个独立的程序,每一步必须在其前一步结束后才能开始,数据必须是完整的,以整体的方式传递。
管道过滤器:流式数据、弱用户交互每个构件都有一组输入和输出,构件读输入的数据流,经过内部处理,然后产生输出数据流。
这个过程通常是通过对输入数据流的变换或计算来完成的,包括通过计算和增加信息以丰富数据、通过浓缩和删除以精简数据、通过改变记录方式以转化数据和递增地转化数据等。
这里的构件称为过滤器,连接件就是数据流传输的管道,将一个过滤器的输出传到另一个过滤器的输入。
早期编译器就是采用的这种架构。
要一步一步处理的,均可考虑采用此架构风格。
2.调用/返回风格:主程序/子程序:单线程控制,把问题划分为若干个处理步骤,构件即为主程序和子程序,子程序通常可合成为模块。
过程调用作为交互机制,即充当连接件的角色。
调用关系具有层次性,其语义逻辑表现为主程序的正确性取决于它调用的子程序的正确性面向对象:构件是对象,对象是抽象数据类型的实例。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Connectors: A pipe connects a source and a sink filter (连 接件:管道,连接一个源和一个目的过滤器)
– Pipes move data from a filter output to a filter input (转发数据 流) – Data is a stream of ―objects‖ (数据是特定类型的“对象”流)
过滤器对数据流的五种变换类型
过滤器读取与处理数据流的方式
Incrementally transform data from the source to the sink (递增的读取和消费数据流)
– 在输入被完全消费之前,输出便产生了。
过滤器的一些基本特征
Filters are independent entities, i.e.,
数据流风格的基本构件(COMPONENT)
Components: data processing components(基本构件:数据处理)
– Interfaces are input ports and output ports ( 构件接口:输入端口和 输出端口) – Input ports read data; output ports write data (从输入端口读取数据, 向输出端口写入数据) – Computational model: read data from input ports, compute, write data to output ports (计算模型:从输入端口读数,经过计算/处理,然 后写到输出端口)
– no context in processing streams (无上下文信息) – no state preservation between instantiations (不保留状态) – no knowledge of upstream/downstream filters (对其他过 滤器无任何了解) – collections can be used to buffer the data passed through pipes: files,arrays, dictionaries, trees, etc. (可使用数据缓 冲区临时保存数据流)
Pipe between two processes in a distributed system (e.g., Internet Sockets)
– Stream contents limited to "raw bytes" – Protocols implement high-level abstractions (e.g., pass pipes as reference, pass COBA object references)
Topology: Connectors define data flow graph (连接器定 义了数据流图,形成拓扑结构)
1 过滤器(Filter)
Incrementally transform some of the source data into sink data(目标:将源数据变换成目标数据) Stream to stream transformation (从“数据流”������ “数据流”的变换)
– Push: data source pushes data in downstream direction (推式:前面的过滤器把新产生的数据推入管 道) – Pull: data sink pulls data from upstream direction (拉式:随后的过滤器从管道中拉出所需数据) – Push/pull: a filter is actively pulling from upstream, computing, and pushing downstream (推拉式:过滤 器以循环的方式,从管道中拉出其输入数据,并将其处 理产生的数据压入后续管道)
软件体系结构及应用 4 数据流体系结构风格
主要内容
ቤተ መጻሕፍቲ ባይዱ
4.1 4.2 4.3 4.4
数据流体系结构风格的基本特征 管道-过滤器(pipe-and-filter) 批处理(batch sequential) 批处理与管道-过滤器的比较
4.1 数据流体系结构风格 的基本特征
数据流风格的直观理解
– enrich data by computation and adding information (通过计算 和增加信息来丰富数据) – refine by distilling data or removing irrelevant data (通过浓缩 和删减来精炼数据) – transform data by changing its representation (通过改变数据 表现方式来转化数据) – decompose data to multiple streams (将一个数据流分解为多 个数据流) – merge multiple streams into one stream (将多个数据流合并 为一个数据流)
– Stream may contain references to shared language objects
Pipe between two processes on a single host computer (e.g., UNIX Named Pipes)
– stream may contain references to shared OS objects (e.g., files)
过滤器的分类:主动与被动
Active filter: drivers the data flow on the pipes. (主动过滤器:驱动数据流动, pull+push)
Passive filter: is driven by the data flow on the (input/output)pipes. (被动过滤器:被管道中 的输入或输出数据流所驱动) Attention:系统中至少有一个主动过滤器(可以来自 外部环境,如用户输入)
每个处理步骤(过滤器)都有一组输入和输出,过滤器 从管道中读取输入的数据流,经过内部处理,然后产 生输出数据流并写入管道中。
Pipe-And-Filter风格的基本构成
Components: Filters — process data streams (构件:过滤 器,处理数据流)
– A filter encapsulates a processing step (algorithm or computation) (一个过滤器封装了一个处理步骤) – Data source and data sink are particular filters (数据源点和数 据终止点可以看作是特殊的过滤器)
A data flow system is one in which
– the availability of data controls the omputation (数 据的可用性决定着处理<计算单元>是否执行) – the structure of the design is dominated by orderly motion of data from process to process (系统结构:数 据在各处理之间的有序移动) – in a pure data flow system, there is no other interaction between processes (在纯数据流系统中,处理 之间除了数据交换,没有任何其他的交互)
• 蓄水池
2 管道(Pipe)
Move data from a filter’s output to a filter’s input (or to a device or file)(作用:在过滤器之间传送数据)
– One way flow from one data source to one data sink (单向流) – A pipe may implement a buffer (可能具有缓冲区) – Pipes form data transmission graph (管道形成传输 图)
数据流风格的连接件(CONNECTOR)
Connectors: data flow (data stream) (连接件:数据流)
– Uni-directional, usually asynchronous, buffered (单向、通常是异步、 有缓冲) – Interfaces are reader and writer roles (接口角色:reader和writer) – Computational model (计算模型: 把数据从一个处理的输出端口 传送到另一个处理的输入端口)