基于ALBERT的中文命名实体识别方法
命名实体识别算法

命名实体识别算法
命名实体识别(Named Entity Recognition,NER)是指抽取文本中具有特定意义的
实体,如人名、地名、机构名等。
它是自然语言理解中比较重要的一步,也是处理语言问
题的基础技术。
主要内容包括词法分析、词性标注、命名实体识别和关系抽取等。
命名实体识别在计
算机领域又称实体抽取(Entity Extraction),主要指从文本中抽取学识、时间、地点
和机构等主要实体,是语言处理的一个重要过程,也是语言理解的重要基础。
中文命名实体识别的基本流程包括:1、分词;2、词性标注;3、实体角色标注。
词
法分析是中文分词和词性标注的一个过程,可以使用相关的软件和算法,如深度学习算法
或分词系统,来实现自动分词及词性标注;词性标注很重要,可以选择相应的词性标注,
使实体更准确。
实体角色标注是指根据文本和实体之间的关系,为实体打上不同的角色,
如被动实体、客体、动作主体、时间等,从而明确实体的环境及角色的关系体系。
除了基于统计的算法外,近几年,深度学习技术也被应用于中文命名实体识别,如RNN、LSTM、CNN、BERT等技术,它们可以直接基于文本,识别出文章中的实体,具有较高的准确性。
总之,中文命名实体识别是一个复杂的技术问题,它涉及到自然语言处理、深度学习、机器学习和大数据技术等多方面,可以通过多层次的算法结合,实现准确、高效的中文命
名实体识别。
中文命名实体识别方法研究

中文命名实体识别方法研究一、本文概述随着信息技术的飞速发展,自然语言处理(NLP)技术在各个领域的应用越来越广泛。
作为NLP的重要分支,命名实体识别(Named Entity Recognition,简称NER)技术对于从海量文本数据中抽取结构化信息具有至关重要的作用。
中文命名实体识别作为NER在中文语境下的具体应用,其研究不仅对于提升中文文本处理技术的智能化水平具有重要意义,同时也有助于推动中文信息处理领域的创新发展。
本文旨在探讨中文命名实体识别方法的研究现状与发展趋势,分析不同方法的优缺点,并在此基础上提出一种基于深度学习的中文命名实体识别方法。
我们将对中文命名实体识别的基本概念和重要性进行阐述,接着回顾传统的命名实体识别方法,包括基于规则的方法、基于统计的方法以及基于特征工程的方法。
然后,我们将重点介绍基于深度学习的中文命名实体识别方法,包括卷积神经网络(CNN)、循环神经网络(RNN)以及注意力机制等,并分析它们在中文命名实体识别任务中的应用效果。
本文还将讨论当前中文命名实体识别研究中面临的挑战和问题,如实体边界的模糊性、实体类型的多样性以及跨领域适应性等。
针对这些问题,我们将提出一些可能的解决方案和改进方向,以期为未来中文命名实体识别技术的发展提供参考和借鉴。
我们将对中文命名实体识别的未来发展趋势进行展望,探讨新技术、新方法和新应用对中文命名实体识别领域的影响,以及如何利用这些技术和方法推动中文信息处理技术的进步和发展。
二、中文命名实体识别的基本方法中文命名实体识别(Named Entity Recognition, NER)是自然语言处理(Natural Language Processing, NLP)领域的一项重要任务,旨在从文本中识别出具有特定意义的实体,如人名、地名、组织名等。
这些实体在文本中扮演着重要的角色,对于理解文本含义、挖掘信息以及实现自然语言理解等任务具有重要意义。
使用StandfordcoreNLP进行中文命名实体识别
使⽤StandfordcoreNLP进⾏中⽂命名实体识别因为⼯作需要,调研了⼀下Stanford coreNLP的命名实体识别功能。
Stanford CoreNLP是⼀个⽐较厉害的⾃然语⾔处理⼯具,很多模型都是基于深度学习⽅法训练得到的。
先附上其官⽹链接:https://stanfordnlp.github.io/CoreNLP/index.htmlhttps:///nlp/javadoc/javanlp/https:///stanfordnlp/CoreNLP本⽂主要讲解如何在java⼯程中使⽤Stanford CoreNLP;1.环境准备3.5之后的版本都需要java8以上的环境才能运⾏。
需要进⾏中⽂处理的话,⽐较占⽤内存,3G左右的内存消耗。
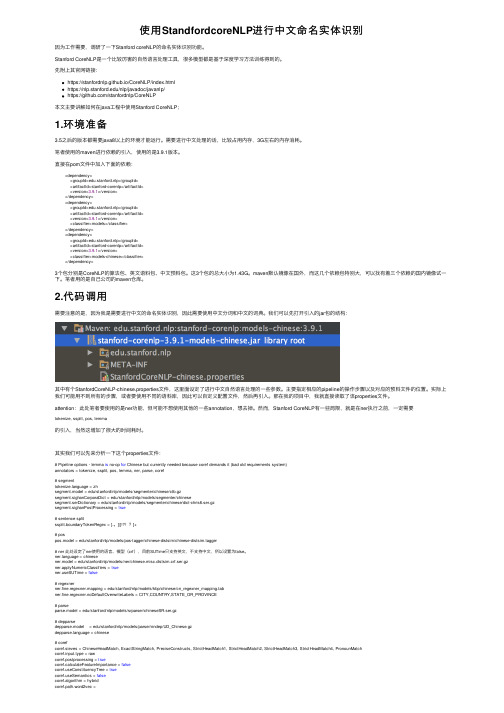
笔者使⽤的maven进⾏依赖的引⼊,使⽤的是3.9.1版本。
直接在pom⽂件中加⼊下⾯的依赖:<dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp</artifactId><version>3.9.1</version></dependency><dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp</artifactId><version>3.9.1</version><classifier>models</classifier></dependency><dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp</artifactId><version>3.9.1</version><classifier>models-chinese</classifier></dependency>3个包分别是CoreNLP的算法包、英⽂语料包、中⽂预料包。
融合注意力机制的RoBERTa-BiLSTM-CRF语音对话文本命名实体识别

义特征和后向语义特征结合,计算公式如式(7)所示 :
→ ht
=
LSTM →( xt
)
← ht
=
← LSTM
(
xt
)
(7)
ht =
<
ht →,
← ht
>
其中 ht 的目的是通过前向 LSTM 获得正向语义信息,
ht 的目的是通过后向 LSTM 获得反向语义信息。
步骤 4 :意识水平对不同的上下文数据给予不同的关
命名实体识别 (Named Entity Recognition,NER) 获 取有关子任务的信息,搜索分配给文本的对象,并将其 分类到预定义的类别中。命名实体识别是自然语言处理 中的热点研究方向之一,用于识别和分类文本中的相关 实体的类别。命名实体识别的准确度,决定下游任务的 效果,是自然语言处理领域的基础问题 [1]。 1 研究现状
入层的 token 序列表达为向量的形式,由 token 嵌入、
分句嵌入和位置嵌入组成。这 3 个嵌入层本质上都等同
于静态的词嵌入层,由嵌入矩阵负责执行基于索引的查
表工对于处理后的 token 序列中第 i 个 token,其向量表
示如式(1)所示 :
ei =wtoken (ti ) + wseg ( segi ) + wpos (i)
果的稳定性,应计算 5 个测试结果的平均电流和每个模
型的输出精度、召回率以及 F1-score 评价结果,如表 2 所示。
表 2 各模型评价指标 Tab.2 Evaluation indexes of each model
模型
精准率 召回率 F1-score
RoBERTa-BiLSTM-Att-CRF 89.10% 89.00% 89.0%
嵌入知识图谱信息的命名实体识别方法

第50卷第3期2021年5月内蒙古师范大学学报(自然科学版)Journal of Inner Mongolia Normal University(Natural Science Edition)Vol.50No.3May2021嵌入知识图谱信息的命名实体识别方法阎志刚,李成城,林民(内蒙古师范大学计算机科学技术学院,内蒙古呼和浩特010022)摘要:在大规模文本语料库上预先训练的BERT(bidirectional encoder representation from transformers, BERT)等神经语言表示模型可以较好地从纯文本中捕获丰富的语义信息。
但在进行中文命名实体识别任务时,由于命名实体存在结构复杂、形式多样、一词多义等问题,识别效果不佳。
基于知识图谱可以提供丰富的结构化知识,从而更好地进行语言理解,提出了一种融合知识图谱信息的中文命名实体识别方法,通过知识图谱中的信息实体增强语言的外部知识表示能力。
实验结果表明,与BERT、OpenAI GPT.ALBERT-BiLSTM-CRF等方法相比,所提出的方法有效提升了中文命名实体的识别效果,在MSRACMicrosott Research Asia,MSRA)与搜狐新闻网标注数据集上F i值分别达到了95.4%与93)%。
关键词:自然语言处理;命名实体识别;知识图谱;深度学习;知识嵌入中图分类号:TP391.1文献标志码:A文章编号:1001—8735(2021)03—0275—08doi:10.3969/j.issn.1001—8735.2021.03.014命名实体识别(named entity recognition,NER)是将文本中的命名实体定位并分类为预定义实体类别的过程[]。
近年来,基于深度学习的NER模型成为主导,深度学习是机器学习的一个领域,它由多个处理层组成,可以学习具有多个抽象级别的数据表示[2]。
神经网络模型RNN[](recurrent neural network, RNN)有长期记忆的性能并能解决可变长度输入,在各个领域都表现出良好的性能,但会伴有梯度消失的问题。
探索自然语言处理技术中的命名实体识别方法与应用

探索自然语言处理技术中的命名实体识别方法与应用命名实体识别(NER)是自然语言处理(NLP)中的一项重要任务,其目的是从文本中识别和提取出具有特定意义的实体,例如人名、地名、组织机构名等。
在本文中,我们将探索自然语言处理技术中的命名实体识别方法与应用。
一、命名实体识别方法1. 传统方法传统的命名实体识别方法主要基于规则和特征工程,通过手动构建规则和设计特征来识别实体。
例如,通过正则表达式匹配人名的常见特征,或者通过词性标注结构判断是否为地名等。
这些方法需要领域专家的经验和专业知识,并且难以适应不同语料和领域的变化。
2. 机器学习方法随着机器学习方法的发展,命名实体识别在NLP领域中得到了更广泛的应用。
常见的机器学习方法包括:支持向量机(SVM)、条件随机场(CRF)和深度学习等。
这些方法通过训练模型来学习文本中实体的特征表示和分类信息,从而实现自动化的命名实体识别。
3. 深度学习方法深度学习在命名实体识别中取得了显著的突破。
基于神经网络的深度学习模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)和注意力机制等,在命名实体识别中取得了较高的准确率。
这些方法通过多层次的抽象和表示学习,能够更好地捕捉文本中实体之间的语义关系和上下文信息。
二、命名实体识别应用1. 信息抽取命名实体识别可用于信息抽取任务中,帮助自动提取结构化的数据。
例如,从新闻文章中识别和提取出人物姓名、公司机构等关键信息,以构建知识图谱或数据库。
这种应用广泛应用在舆情监控、金融市场分析等领域。
2. 问答系统命名实体识别可用于问答系统中,帮助系统理解用户提问的语义和意图。
通过识别问题中的实体,系统可以更准确地搜索和提供相关的答案。
例如,当用户提问“世界杯的历史?”时,命名实体识别可以帮助系统识别出问题中的“世界杯”,从而提供与世界杯相关的历史信息。
3. 智能推荐命名实体识别可用于智能推荐系统中,帮助系统理解用户的兴趣和需求。
通过识别用户历史行为中的实体,系统可以更准确地推荐相关的商品、新闻或服务。
使用自然语言处理技术进行中文命名实体识别的技巧

使用自然语言处理技术进行中文命名实体识别的技巧中文命名实体识别是一项关键的自然语言处理技术,旨在识别和分类文本中的重要实体,如人名、地名、组织机构等。
随着互联网和大数据的发展,越来越多的文本数据产生,并且这些数据中包含了大量的命名实体信息。
因此,使用自然语言处理技术进行中文命名实体识别成为了重要的研究领域。
在进行中文命名实体识别时,有一些技巧可以帮助提高识别的准确性和效率。
以下是一些常用的技巧和方法:1. 语料库构建:首先要构建一个高质量的语料库来训练和测试命名实体识别模型。
语料库的选择要广泛涵盖不同领域的文本,确保能够覆盖各种类型的命名实体。
2. 特征选择:在进行命名实体识别时,选择合适的特征对于获得好的性能是至关重要的。
常用的特征包括词性标注、上下文信息、词频统计等。
特征选择需要根据具体任务和语料库进行调整和优化。
3. 机器学习算法:命名实体识别通常使用机器学习算法来训练模型。
常用的机器学习算法包括条件随机场(CRF)、支持向量机(SVM)和深度学习模型(如循环神经网络)。
选择合适的算法对于获得准确的识别结果非常重要。
4. 实体词典和规则库:在进行中文命名实体识别时,可以建立实体词典和规则库来辅助识别。
实体词典包含了已知的实体名称,可以用于匹配和识别。
规则库可以包括一些上下文规则和语法规则,帮助提高识别准确性。
5. 命名实体分块:在命名实体识别中,通常需要进行分块处理,将文本中的实体划分为不同的类别。
这可以通过各种技术来实现,如规则匹配、机器学习算法等。
分块处理是识别任务的关键一步,需要根据实际情况进行调整和优化。
6. 预处理和后处理:在进行命名实体识别之前,可以进行一些预处理操作,如分词、词性标注等,以准备输入数据。
在识别完成后,还可以进行一些后处理操作,如去除重复实体、纠正错误等,以提高识别结果的质量。
7. 评估和改进:对命名实体识别系统进行评估和改进是不可或缺的一步。
可以使用各种评估指标,如准确率、召回率和F1值等,来评估模型的性能。
基于深度学习的中文命名实体识别算法在医疗领域的应用研究

基于深度学习的中文命名实体识别算法在医疗领域的应用研究基于深度学习的中文命名实体识别算法在医疗领域的应用研究摘要:随着电子健康记录的广泛应用,对医疗文本进行自动化的处理和分析已经成为一个重要的研究领域。
其中,命名实体识别是医疗文本处理的关键技术之一。
本文针对中文医疗文本的特点,使用深度学习方法设计了一个中文医疗命名实体识别算法,并在真实的医疗数据集上进行了实验评估。
关键词:深度学习;命名实体识别;中文医疗文本;医疗领域1.引言医疗领域的文本数据量庞大且复杂,包括电子病历、医学论文、临床指南等。
这些文本中涉及了丰富的医学实体,如疾病、药品、手术等,对这些实体进行自动化的识别和解析对于提高医疗数据的处理效率和质量具有重要意义。
传统的基于规则和规则模板的命名实体识别方法在面对复杂多变的医疗文本时存在一定的局限性,无法很好地适应不同类型的实体和不同表达形式。
而深度学习方法在自然语言处理领域取得了显著的成果,为医疗命名实体识别提供了新的思路和技术。
2.相关工作近年来,基于深度学习的命名实体识别技术已经在多个领域取得了令人瞩目的成果。
例如,在英文和中文的新闻、社交媒体等文本数据上进行的实验表明,基于深度学习的命名实体识别方法在准确度和泛化能力上都有显著的提升。
对于医疗领域的命名实体识别任务,一些研究者也已经开始探索基于深度学习的方法。
例如,使用卷积神经网络(CNN)进行实体识别的研究发现,在医疗领域的数据集上能够取得较好的效果。
此外,还有一些研究使用长短时记忆网络(LSTM)和条件随机场(CRF)等模型进行命名实体识别,也取得了不错的结果。
然而,这些研究大多针对英文文本进行实验,针对中文医疗文本的研究还很有限。
中文医疗文本与英文医疗文本在语法和表达方式上存在一定的差异,因此需要针对中文医疗文本的特点进行研究和算法设计。
3.方法本文使用深度学习的方法设计了一个中文医疗命名实体识别算法。
算法的核心思想是使用神经网络对中文医疗文本进行特征提取和实体识别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.1. BERT 预训练语言模型
在自然语言处理任务中,语言模型是一个重要概念,其任务是计算语言序列
w1
,
w2
,,
wn
的出现概率
DOI: 10.12677/csa.20应用
邓博研,程良伦
p ( w1, w2 ,, wn ) :
n
= p ( S ) p (w1, w2 ,= , wn ) ∏ p ( w | w1, w2 ,, wi−1 )
DOI: 10.12677/csa.2020.105091
884
计算机科学与应用
邓博研,程良伦
以推导中文文本中命名实体的字符嵌入,在微博数据集上实现了较大的性能改进。Johnson 等人提出了一 种综合嵌入方法,CWPC_BiAtt [10],将字符嵌入、词语嵌入和词性嵌入依照顺序进行拼接以获得它们之 间的依存关系,并采用注意力机制捕获当前位置内容与任何位置之间的联系,在 MSRA 数据集和微博 NER 语料库上获得了较高的精度和召回率。
Lan 等人提出的 ALBERT 具有很好的减少参数的效果,但参数的减少必然带来性能的损失。为提升 下游任务的性能,本文提出结合 BiLSTM-CRF 模型的 ALBERT-BiLSTM-CRF 模型,并在 MSRA 公开的 中文命名实体识别数据集上达到了 95.22%的 F1 值。
3. ALBERT-BiLSTM-CRF 模型
以上方法的探索证明了字符嵌入与词语嵌入在中文命名实体识别任务中的有效性,而在 Devlin 等人 提出 BERT 后,其输出的词嵌入所具有的良好的语义表达效果,使针对预训练语言模型的研究成为热点。 在中文电子病历的命名实体识别任务中,Dai 等人[11]与 Jiang 等人[12]使用 BERT-BiLSTM-CRF 模型获 得了优于其他模型的效果。Cai 等人[13]先通过 BERT 预训练语言模型增强字符的语义表示,然后将字符 嵌入输入 BiGRU-CRF 进行训练,最终得到了优于最佳模型的效果。Gong 等人[14]使用 BERT 训练汉字 嵌入,将其与汉字根基表示法联系起来,并将结果放入 BiGRU-CRF 模型中,在中文数据集上取得了良 好的效果。为进一步提升 BERT 在中文 NER 任务上的表现,Cui 等人提出了全字掩码(WWM) [15],实验 表明该方法可以带来显著收益。
Computer Science and Application 计算机科学与应用, 2020, 10(5), 883-892 Published Online May 2020 in Hans. /journal/csa https:///10.12677/csa.2020.105091
2. 相关工作
与英文不同,中文构成较为复杂,不仅在语义上存在字符与词语的区分,还有笔划与部首等额外信 息。Dong 等人应用融合了字符嵌入和部首级表示的 BiLSTM-CRF 模型[6],在没有精心调整特征的情况 下取得了更好的效果。Xiang 等人提出了一种字词混合嵌入(CWME)方法[7],可以结合下游的神经网络模 型有效地提高性能。Zhang 等人提出了 Lattice LSTM [8],对输入字符序列以及与词典匹配的所有潜在词 进行编码,显式地利用了字符信息和词序信息,避免了分词错误,并在 MSRA 公开的中文命名实体识别 数据集上达到了 93.18%的 F1 值。针对微博数据集等口语化较多的语料,Xu 等人提出了 ME-CNER [9],
尽管 BERT 具有非常优异的性能表现,但由于其庞大的参数量,很多研究者开始研究如何在保持一 定性能的情况下压缩 BERT 的规模。Michel 等人发现,在测试时移除大量注意力表头也不会对性能产生 显著影响[16]。Wang 等人提出了一种基于低秩矩阵分解与强化的拉格朗日 L0 范数正则化的新型结构化 修剪方法[17],在任何稀疏度级别上都可以显著实现推理加速。Shen 等人提出了一种新的逐组量化方案, 并使用基于 Hessian 的混合精度方法进一步压缩模型[18]。Lan 等人[5]提出的 ALBERT 采用两种参数减少 技术以降低内存消耗并提高 BERT 的训练速度,同时使用了一种自我监督的损失以提高训练效果。
摘要
在中文命名实体识别任务中,BERT预训练语言模型因其良好的性能得到了广泛的应用,但由于参数量
文章引用: 邓博研, 程良伦. 基于 ALBERT 的中文命名实体识别方法[J]. 计算机科学与应用, 2020, 10(5): 883-892. DOI: 10.12677/csa.2020.105091
Chinese Named Entity Recognition Method Based on ALBERT
Boyan Deng, Lianglun Cheng School of Computers, GDUT, Guangzhou Guangdong
Received: Apr. 20th, 2020; accepted: May 5th, 2020; published: May 12th, 2020
关键词
中文命名实体识别,ALBERT,预训练语言模型,BiLSTM,条件随机场
Copyright © 2020 by author(s) and Hans Publishers Inc. This work is licensed under the Creative Commons Attribution International License (CC BY 4.0). /licenses/by/4.0/
邓博研,程良伦
过大、训练时间长,其实际应用场景受限。针对这个问题,提出了一种基于ALBERT的中文命名实体识 别模型ALBERT-BiLSTM-CRF。在结构上,先通过ALBERT预训练语言模型在大规模文本上训练字符级别 的词嵌入,然后将其输入BiLSTM模型以获取更多的字符间依赖,最后通过CRF进行解码并提取出相应实 体。该模型结合ALBERT与BiLSTM-CRF模型的优势对中文实体进行识别,在MSRA数据集上达到了 95.22%的F1值。实验表明,在大幅削减预训练参数的同时,该模型保留了相对良好的性能,并具有很 好的可扩展性。
本文将 ALBERT 预训练语言模型与 BERT 预训练语言模型在 MSRA 公开的中文命名实体识别数据 集上进行对比,并结合 BiLSTM-CRF 模型,构建 ALBERT-BiLSTM-CRF 模型,在数据集上进行了进一 步实验验证,结果表明 ALBERT 预训练语言模型保留了相对良好的性能,并具有很好的可扩展性。
模型主要由三部分构成,分别为 ALBERT 预训练语言模型、BiLSTM 层和 CRF 层。以 ALBERT 的 编码输出作为 BiLSTM 层的输入,再在 BiLSTM 的隐藏层后加一层 CRF 层用以解码,最终得到每个字符 的标注类型。具体结构如图 1。
Figure 1. ALBERT-BiLSTM-CRF Model 图 1. ALBERT-BiLSTM-CRF 模型
Abstract
The BERT pre-trained language model has been widely used in Chinese named entity recognition due to its good performance, but the large number of parameters and long training time has limited its practical application scenarios. In order to solve these problems, we propose ALBERT-BiLSTM-CRF, a model for Chinese named entity recognition task based on ALBERT. Structurally, the model firstly trains character-level word embeddings on large-scale text through the ALBERT pre-training language model, and then inputs the word embeddings into the BiLSTM model to obtain more inter-character dependencies, and finally decodes through CRF and extracts the corresponding entities. This model combines the advantages of ALBERT and BiLSTM-CRF models to identify Chinese entities, and achieves an F1 value of 95.22% on the MSRA dataset. Experiments show that while greatly reducing the pre-training parameters, the model retains relatively good performance and has good scalability.
Keywords
Chinese Named Entity Recognition, ALBERT, Pre-Trained Language Model, BiLSTM, CRF
基于ALBERT的中文命名实体识别方法
邓博研,程良伦 广东工业大学,广东 广州
收稿日期:2020年4月20日;录用日期:2020年5月5日;发布日期:2020年5月12日
Open Access
1. 引言
命 名 实 体 识 别 (Named Entity Recognition, NER) 任 务 一 直 是 自 然 语 言 处 理 (Natural Language Processing, NLP)领域中的研究热点,主要采用序列标注的方式,获取文本中具有特定意义的实体。从早 期基于规则和字典的方法开始,历经传统机器学习方法和深度学习方法,到近两年来的预训练语言模型, 研究者们进行了不断的尝试与探索。