ELK日志分析系统
基于大数据的ELK日志分析系统研究及应用
基于大数据的ELK日志分析系统研究及应用作者:李志民孙林檀吴建军张新征来源:《科学与信息化》2019年第28期摘要基于ELK的日志分析系统研究分析是为了有效的解决当下物联网应用日志处理效率低的问题。
因此,本文首先阐述了基于ELK的日志分析平台,然后总结了对系统日记群集优化大方法,从而提高日志分析系统的运行效率和排查异常的速度。
关键词 ELK;日志分析系统;Elasticsearch日志设计信息系统的重要组成部分,是系统运行、性能分析以及故障诊断的重要来源。
随着科学技术的不断发展和互联网技术的广泛应用,不断增加了系统的日志量,随着日志的应用范围的扩大和复杂程度的增加,传统日志的分析方式和效率已经不能适信息系统对日志的需求。
为了满足信息时代的发展需要,下面就基于ELK的日志分析系统进行相关的研究分析工作。
1 基于ELK的日志分析平台随着实时分析技术的不断发展和成熟应用,在日志领域出现了新的分析系统-ELK,ELK 实时日志分析平台主要运用了Kiba-na(数据可视分析平台)、Logstash(日志采集工具)、Elasticsearch(分布式搜索引擎)[1]。
这些技术的应用可以让系统的运行维护人员在庞大的日志信息量中及时找到所需要管理和维护的信息,从而实现了对日志系统的分析。
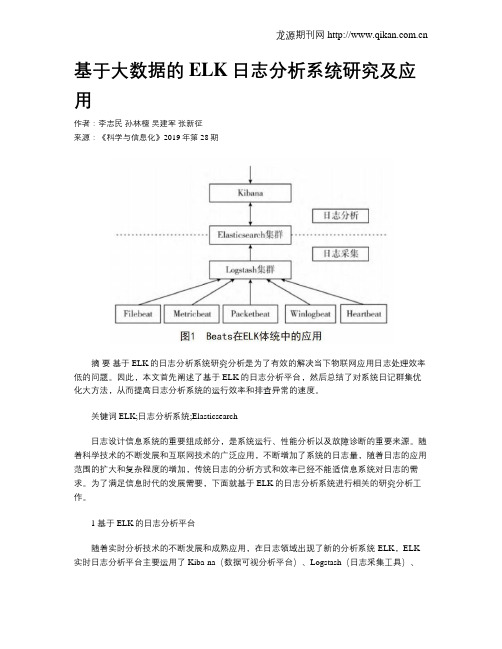
1.1 日志分析系统整体架构完整的日志系统是有日志的储存系统、采集系统、解析系统化以及可视化分析系统共同组成的。
日志采集工具是日志的主要采集器,在多台机器当中都有分布,它可以对非结构的日志进行解析,然后把解析的结果传输到分布式搜索引擎中;分布式搜索引擎可以完成全文检索的功能,属于储存日志的中央系统;而Kibana组件的存在不仅可以对分布式搜索引擎中的日志进行可视化操作[2],还可以进行统计分析和高级搜索。
但是日记采集工具及要完成对日志的采集工作又要完成解析工作,这样不仅会致系统的性能下降,严重的时候还会影响工作的进展。
而Beats的推广和应用有效解决了这一问题,图1为Beatsde在系统框架中的应用:Beats在进行信息采集和解析工作的时候可以针对不同的日志格式和来源使用不同的采集器,Beats采集器包括了5中不同种类和功能的日志采集器,分别为:Filebeat、Metricbest、Packetbeat、Winlogbeat、Heartbeat。
elk的组成

elk的组成(原创实用版)目录1.ELK 的含义2.ELK 的组成部分3.各组成部分的功能与作用4.ELK 的应用场景正文ELK(Elasticsearch、Logstash、Kibana)是一个基于开源软件的日志分析系统,广泛应用于大数据处理、实时数据分析和可视化等领域。
下面我们将详细介绍 ELK 的组成及其功能与作用。
1.ELK 的含义ELK 是一个缩写,分别代表 Elasticsearch、Logstash 和 Kibana 三款开源软件。
Elasticsearch 是一款分布式搜索引擎,能够实现对海量数据的快速搜索、分析和存储。
Logstash 是一款数据收集引擎,负责从各种数据源采集数据,并将数据进行处理后传输给 Elasticsearch。
Kibana 是一款数据可视化工具,可以方便地对 Elasticsearch 中的数据进行分析和可视化。
2.ELK 的组成部分(1)Elasticsearch:Elasticsearch 是一款高性能的分布式搜索引擎,能够实现对海量数据的实时搜索、分析和存储。
它采用倒排索引技术,能够大幅提高搜索速度。
同时,Elasticsearch 还支持多种数据类型,如文本、数字、日期等,适应各种复杂场景。
(2)Logstash:Logstash 是一款数据收集引擎,可以接收来自各种数据源的数据,如日志文件、数据库、消息队列等。
Logstash 支持多种插件,可以根据需要进行数据过滤、转换和增强。
经过处理后的数据被传输到 Elasticsearch 进行存储和分析。
(3)Kibana:Kibana 是一款数据可视化工具,可以方便地对Elasticsearch 中的数据进行分析和可视化。
通过 Kibana,用户可以轻松生成各种报表、仪表盘和图表,实时监控数据变化,发现数据中的规律和趋势。
3.各组成部分的功能与作用(1)Elasticsearch:负责存储、分析和搜索数据,提供高性能的搜索功能。
ELK日志分析系统

ELK⽇志分析系统⼀、ELK 概述1、ELK简介 ELK平台是⼀套完整的⽇志集中处理解决⽅案,将 ElasticSearch、Logstash 和 Kiabana 三个开源⼯具配合使⽤,完成更强⼤的⽤户对⽇志的查询、排序、统计需求。
ElasticSearch:是基于Lucene(⼀个全⽂检索引擎的架构)开发的分布式存储检索引擎,⽤来存储各类⽇志。
Elasticsearch 是⽤ Java 开发的,可通过 RESTful Web 接⼝,让⽤户可以通过浏览器与 Elasticsearch 通信。
Elasticsearch 是个分布式搜索和分析引擎,优点是能对⼤容量的数据进⾏接近实时的存储、搜索和分析操作。
Logstash:作为数据收集引擎。
它⽀持动态的从各种数据源搜集数据,并对数据进⾏过滤、分析、丰富、统⼀格式等操作,然后存储到⽤户指定的位置,⼀般会发送给 Elasticsearch。
Logstash 由JRuby 语⾔编写,运⾏在 Java 虚拟机(JVM)上,是⼀款强⼤的数据处理⼯具,可以实现数据传输、格式处理、格式化输出。
Logstash 具有强⼤的插件功能,常⽤于⽇志处理。
Kiabana:是基于 Node.js 开发的展⽰⼯具,可以为 Logstash 和 ElasticSearch 提供图形化的⽇志分析 Web 界⾯展⽰,可以汇总、分析和搜索重要数据⽇志。
Filebeat:轻量级的开源⽇志⽂件数据搜集器。
通常在需要采集数据的客户端安装 Filebeat,并指定⽬录与⽇志格式,Filebeat 就能快速收集数据,并发送给 logstash 进⾏解析,或是直接发给 Elasticsearch 存储,性能上相⽐运⾏于 JVM 上的 logstash 优势明显,是对它的替代。
2、为什么要使⽤ ELK ⽇志主要包括系统⽇志、应⽤程序⽇志和安全⽇志。
系统运维和开发⼈员可以通过⽇志了解服务器软硬件信息、检查配置过程中的错误及错误发⽣的原因。
ELK日志分析系统

ELK日志分析系统ELK日志分析系统是一种常用的开源日志管理和分析平台。
它由三个主要组件组成,即Elasticsearch、Logstash和Kibana,分别用于收集、存储、分析和可视化日志数据。
本文将介绍ELK日志分析系统的原理、特点和应用场景等。
ELK日志分析系统具有以下几个特点。
首先,它是一个开源系统,用户可以自由获取、使用和修改代码,满足各种定制化需求。
其次,它具有高度的可扩展性和灵活性,可以处理海量的日志数据,并支持实时查询和分析。
再次,它采用分布式架构,可以部署在多台服务器上,实现高可用性和负载均衡。
最后,它提供了丰富的可视化工具和功能,让用户可以直观地了解和分析日志数据,发现潜在的问题和异常。
ELK日志分析系统在各种场景下都有广泛的应用。
首先,它可以用于系统日志的监控和故障诊断。
通过收集和分析系统的日志数据,可以及时发现和解决问题,保证系统的正常运行。
其次,它可以用于应用程序的性能监控和优化。
通过分析应用程序的日志数据,可以找到性能瓶颈和潜在的问题,并采取相应的措施进行优化。
再次,它可以用于网络安全监控和威胁检测。
通过分析网络设备和服务器的日志数据,可以及时发现并应对潜在的安全威胁。
最后,它还可以用于业务数据分析和用户行为追踪。
通过分析用户的访问日志和行为日志,可以了解用户的偏好和行为模式,为业务决策提供依据。
然而,ELK日志分析系统也存在一些挑战和限制。
首先,对于大规模的日志数据,ELK系统需要消耗大量的存储和计算资源,对硬件设施和系统性能要求较高。
其次,ELK系统对日志的结构有一定的要求,如果日志数据过于复杂或不规范,可能会造成数据解析和处理的困难。
再次,ELK系统对于数据的实时性要求较高,以保证用户能够在短时间内获取到最新的数据和分析结果。
最后,对于非技术人员来说,ELK系统的配置和使用可能较为复杂,需要一定的培训和专业知识。
总之,ELK日志分析系统是一种功能强大且灵活的日志管理和分析工具,可以帮助用户实现日志数据的收集、存储、分析和可视化展示。
ELK日志分析系统搭建

ELK日志分析系统搭建elk套件是指elasticsearch、logstash、kibana三件套,它们可以组成一套日志分析和监控工具。
本文说明安装过程和典型的配置过程,由于三个软件各自的版本号太多,建议采用官网(https://www.elastic.co/downloads)推荐的搭配组合,版本不搭会引起好多其他问题。
本文具体安装版本如下:elasticsearch版本:2.4.0logstash版本:2.4.0kibana版本:4.6.1redis版本:3.2.1jdk版本:1.8.0操作系统版本:Centos7.0ELK的典型部署图如下:安装过程1、安装Java下载JDK压缩包。
一般解压到 /user/local/ 下,形成 /usr/local/jdk1.8.0/bin 这种目录结构。
配置JAVA_HOME 环境变量:echo 'export JAVA_HOME=/usr/local/jdk1.8.0' >> ~/.bashrc 。
2、安装logstash使用root用户进行安装,实际上解压后直接运行就可以了# tar -zxvf logstash-2.4.0.tar.gz# cd logstash-2.4.0可通过bin/logstash -e 'input {stdin{}} output {stdout{}}'测试[root@localhost logstash-2.4.0]# bin/logstash -e 'input {stdin{}} output {stdout{}}'Settings: Default pipeline workers: 8Pipeline main started键入:hello elktest显示:2016-10-20T03:55:59.121Z localhost.localdomain hello elktest 表示把从标准输入设备输入的内容再通过标准输出设备输出。
项目实战14—ELK企业内部日志分析系统

项⽬实战14—ELK企业内部⽇志分析系统本⽂收录在⼀、els、elk 的介绍1、els,elkels:ElasticSearch,Logstash,Kibana,Beatselk:ElasticSearch,Logstash,Kibana① ElasticSearch 搜索引擎 ElasticSearch 是⼀个基于Lucene的搜索引擎,提供索引,搜索功能。
它提供了⼀个分布式多⽤户能⼒的全⽂搜索引擎,基于RESTful web接⼝。
Elasticsearch是⽤Java开发的,并作为Apache许可条款下的开放源码发布,是当前流⾏的企业级搜索引擎。
设计⽤于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使⽤⽅便② Logstash 接收,处理,转发⽇志的⼯具 Logstash 是⼀个开源的服务器端数据处理流⽔线,它可以同时从多个数据源获取数据,并将其转换为最喜欢的"存储"(Ours is Elasticsearch, naturally.)③ Beats:采集⽇志信息(加上beats 就是els),GO开发的,所以⾼效、很快 Filebeat:Log Files Metricbeat:Metrics Packetbeat:Network Data Winlogbeat:Windows Event Logs Heartbeat:Uptime Monitoring④ Kibana:独⽴的、美观的图形数据展⽰界⾯ Kibana 让你可视化你的Elasticsearch数据并导航Elastic Stack,所以你可以做任何事情,从凌晨2:00分析为什么你得到分页,了解⾬⽔可能对你的季度数字造成的影响。
2、实验前准备①环境准备机器名称IP配置服务⾓⾊els192.168.1.101(私)192.168.10.101(公)elasticsearch(搜索引擎)logstash192.168.1.102(私)192.168.10.102(公)logstash(⽇志处理)redis(缓冲队列)filebeat192.168.1.103(私)192.168.10.103(公)filebeat(⽇志收集)httpd/mysql(⽣成⽇志)kibana192.168.1.104(私)192.168.10.104(公)kibana(展⽰界⾯)②修改主机名、hosts⽂件,确保节点直接能通过主机名连通[root@els ~]# hostnamectl set-hostname [root@logstash ~]# hostnamectl set-hostname [root@filebeat ~]# hostnamectl set-hostname [root@kibana ~]# hostnamectl set-hostname centos7 修改主机名:[root@els ~]# hostnamectl set-hostname 主机名③修改hosts[root@els ~]# vim /etc/hosts192.168.1.101 192.168.1.102 192.168.1.103 192.168.1.104 互相测试[root@els ~]# ping ④关闭防⽕墙、selinux[root@els ~]# iptables -F[root@els ~]# setenforce 0⑤同步时间[root@els ~]# systemctl restart chronyd⼆、安装搭建elasticsearch 和head 插件1、安装elasticsearch Elasticsearch 是⼀个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种⽤例。
ELK+Kafka集群日志分析系统
ELK+Kafka集群⽇志分析系统ELK+Kafka集群分析系统部署因为是⾃⼰本地写好的word⽂档复制进来的。
格式有些出⼊还望体谅。
如有错误请回复。
谢谢!⼀、系统介绍 2⼆、版本说明 3三、服务部署 31) JDK部署 32) Elasticsearch集群部署及优化 33) Elasticsearch健康插件安装 134) Shield之elasticsearch安全插件 155)Zookeeper集群搭建 156)Kafka集群搭建 177)测试Kafka和Zookeeper集群连通性 198) Logstash部署 209) Kibana部署 20四、系统使⽤⽰例 221) Logstash 作为kafka⽣产者⽰例 222) Logstash index 消费kafka⽰例 23⼀、系统介绍随着实时分析技术的发展及成本的降低,⽤户已经不仅仅满⾜于离线分析。
下⾯来介绍⼀下架构这是⼀个再常见不过的架构了:(1)Kafka:接收⽤户⽇志的消息队列(2)Logstash:做⽇志解析,统⼀成json输出给Elasticsearch(3)Elasticsearch:实时⽇志分析服务的核⼼技术,⼀个schemaless,实时的数据存储服务,通过index组织数据,兼具强⼤的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能⼒是众多公司选择ELK stack的重要原因。
(5)Zookeeper: 状态管理,监控进程等服务⼆、版本说明本次系统为:Centos6.5 64位Java版本为:1.8.0_74Elasticsearch为:2.4.0Logstash :2.4.0Kibana:4.6.1Shield:2.0+Kafka:2.10-0.10.0.1Zookeeper:3.4.9相应的版本最好下载对应的插件。
三、服务部署1) JDK部署下载JDK包到/data⽬录下解压,并将变量导⼊/etc/profile末尾。
基于ELK的日志分析与异常检测系统的设计与实现
基于ELK的日志分析与异常检测系统的设计与实现基于ELK的日志分析与异常检测系统的设计与实现一、引言随着信息技术的不断发展,大规模分布式系统越来越复杂,其日志数据量也越来越庞大。
如何高效地分析和处理这些日志数据成为了一个迫切需要解决的问题。
本文将介绍一种基于ELK (Elasticsearch、Logstash和Kibana)的日志分析和异常检测系统的设计与实现。
二、ELK架构概述ELK是一个开源的日志分析平台,其中Elasticsearch作为分布式搜索引擎用于存储和检索大量的日志数据;Logstash用于日志的收集、过滤和转发;Kibana作为可视化工具展示数据。
三、系统设计1. 数据收集为了收集分布式系统产生的日志数据,我们需要在每个节点上安装Logstash,并配置相应的输入插件,如filebeat,以实时读取日志文件。
同时,为了增加实时性,我们可以使用消息队列,如Kafka,将日志数据传输到Logstash中。
2. 数据过滤在Logstash中,我们可以配置不同的过滤器来过滤和处理日志数据。
例如,我们可以使用grok模式匹配来提取特定的字段,使用date插件来解析时间戳,使用mutate插件来修改日志中的字段等。
通过合理配置过滤器,可以将原始的日志数据转化为结构化的数据,方便后续的分析和可视化。
3. 数据存储过滤后的数据将被存储到Elasticsearch中。
Elasticsearch作为一个分布式搜索引擎,具有高性能和高可扩展性,可以快速地存储和检索大量的日志数据。
4. 数据可视化Kibana作为ELK的可视化工具,提供了丰富的图表和仪表盘,可以帮助用户直观地理解和分析日志数据。
用户可以通过Kibana自定义查询条件、创建仪表盘、设置监控告警等,以满足自己的需求。
四、异常检测算法设计在日志数据中,异常通常体现为与正常行为模式不一致的事件。
为了检测异常,我们可以使用机器学习算法,如聚类、分类和时间序列分析等。
基于ELK的实时日志分析系统
基于ELK的实时日志分析系统ELK是一个开源的日志管理工具,它由三个独立但协作的组件组成:Elasticsearch、Logstash和Kibana。
ELK可以用于实时的日志分析,它可以帮助用户在大量的日志数据中实时、可视化和分析数据。
首先,Elasticsearch是一个分布式引擎,它可以快速地存储、和分析大规模的数据。
它使用倒排索引的方式来存储数据,并提供了灵活的全文、过滤和聚合功能。
对于实时日志分析系统来说,Elasticsearch可以作为一个集中的存储和索引引擎,用于存储和检索大量的日志数据。
其次,Logstash是一个用于数据收集、转换和发送的工具。
它可以从不同的数据源中收集日志数据,如文件、数据库、网络等,并对数据进行预处理、清洗和转换。
同时,Logstash也可以将处理后的数据发送到不同的目标,如Elasticsearch、消息队列等。
对于实时日志分析系统来说,Logstash可以负责收集应用程序生成的日志数据,并将其发送到Elasticsearch中进行索引和存储。
最后,Kibana是一个用于可视化和分析数据的工具。
它提供了一个直观的Web界面,用户可以通过查询和过滤数据来生成各种图表和图形,如柱状图、饼图、地图等。
Kibana还支持用户创建自定义的仪表板和报表,以便更方便地监控和分析日志数据。
对于实时日志分析系统来说,Kibana可以作为一个前端界面,供用户可视化和分析存储在Elasticsearch中的日志数据。
基于ELK的实时日志分析系统可以帮助用户实时地监控和分析应用程序的日志数据。
用户可以通过Kibana的查询功能,快速和过滤感兴趣的日志数据,并通过可视化工具生成图表和报表。
这样,用户可以更方便地分析日志数据,并及时发现应用程序的异常和问题。
此外,ELK还具有高可靠性和可扩展性的特点。
Elasticsearch作为一个分布式系统,可以水平地扩展以处理大规模的数据,并提供高可用性和容错性。
ELK日志分析系统
ELK日志分析系统ELK日志分析系统(Elasticsearch, Logstash, Kibana)是一种用于实时数据分析和可视化的开源工具组合。
它结合了Elasticsearch、Logstash和Kibana这三个工具,可对大量的日志数据进行收集、存储、和分析,并通过直观的可视化界面展示分析结果。
本文将对ELK日志分析系统的原理、功能和应用进行介绍。
2. 数据存储和索引:ELK日志分析系统使用Elasticsearch作为底层存储和索引引擎。
Elasticsearch是一个高性能、分布式的和分析引擎,能够实时地处理大规模的数据,并提供复杂的、聚合和分析功能。
Elasticsearch使用倒排索引来加快速度,并支持多种查询和分析方式,如全文、聚合查询、时序分析等。
3. 数据和查询:ELK日志分析系统通过Elasticsearch提供强大的和查询功能。
用户可以使用简单的关键字查询或复杂的过滤条件来和筛选数据。
同时,Elasticsearch还支持模糊、近似和正则表达式等高级方式,以便更精确地找到所需的数据。
4. 数据可视化和分析:ELK日志分析系统的另一个重要功能是数据的可视化和分析。
通过Kibana工具,用户可以创建自定义的仪表板和图表,展示日志数据的各种指标和趋势。
Kibana支持多种图表类型,如柱状图、折线图、饼图等,并提供交互式过滤和数据透视功能,以帮助用户更好地理解和分析数据。
ELK日志分析系统在实际应用中具有广泛的用途。
首先,它可以用于系统监控和故障排查。
通过收集和分析系统日志,可以实时监控系统的运行状态,并及时发现和解决潜在的问题。
其次,ELK日志分析系统可以用于安全事件检测和威胁分析。
通过分析网络和应用日志,可以识别潜在的安全威胁,提高系统的安全性。
此外,ELK日志分析系统还可以用于运营分析、业务分析和市场分析等领域,帮助企业更好地理解和利用日志数据,提升业务效率和竞争力。
总之,ELK日志分析系统是一种功能强大的实时数据分析和可视化工具组合。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ELK日志分析系统一、ELK日志分析系统介绍1.1传统的日志统计及分析方式日志主要包括系统日志、应用程序日志和安全日志。
系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。
经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。
如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。
这样是不是感觉很繁琐和效率低下。
当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
1.2 ELK介绍开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。
(1)、Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
(2)、Logstash是一个完全开源的工具,可以对日志进行收集、过滤,并将其存储供以后使用(如:搜索)。
(3)、Kibana 也是一个开源和免费的可视化工具,可以为Logstash 和ElasticSearch 提供的日志分析友好的Web 界面,可以帮助汇总、分析和搜索重要数据日志。
1.2.1 Elasticsearch介绍Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,Lucene是当前行业内最先进、性能最好的、功能最全的搜索引擎库。
但Lucene只是一个库。
无法直接使用,必须使用Java作为开发语言并将其直接集成到应用中才可以使用,而且Lucene非常复杂,需要提前深入了解检索的相关知识才能理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
但Elasticsearch不仅仅值是Lucene库和全文搜索,它还有以下用途:► 分布式的实时文件存储,每个字段都被索引并可被搜索► 分布式的实时分析搜索引擎► 可以扩展到上百台服务器,处理PB级结构化或非结构化数据1.2.2 Elasticsearch基础概念Elasticsearch有几个核心概念。
从一开始理解这些概念会对整个学习过程有莫大的帮助。
(1)、接近实时(NRT)Elasticsearch是一个接近实时的搜索平台。
意味着检索一个文档直到这个文档能够被检索到有一个轻短暂的延迟(通常是1秒)。
(2)、集群(cluster)集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。
这个名字很重要,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也可以。
(3)、节点(node)节点是值集群中的具体服务器,作为集群的一部分,它可存储数据,参与集群的索引和搜索功能。
和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机名字,这个名字会在服务启动时赋予节点。
这个名字对于管理者非常重要,因为在管理过程中,需要确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
节点可以通过配置集群名称的方式来加入一个指定的集群。
默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,那么各节点将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,可以拥有任意多个节点。
并且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
(4)、索引(index)索引是指一个拥有相似特征的文档的集合。
比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
每个索引均由一个名字来标识(必须全部是小写字母的),并且当要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
“索引”有两个意思:A.作为动词,索引指把一个文档“保存”到ES 中的过程,某个文档被索引后,就可以使用ES 搜索到这个文档B.作为名词,索引指保存文档的地方,相当于数据库概念中的“库”为了方便理解,我们可以将ES 中的一些概念对应到我们熟悉的关系型数据库上:在一个集群中,可以定义任意多的索引。
(5)、类型(type)在一个索引中,可以定义一种或多种类型。
类型是指索引的一个逻辑上的分类/分区,其语义可自定义。
通常情况下,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设运营一个博客平台并且将所有的数据存储到一个索引中。
在这个索引中,可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
(6)、文档(document)文档是指可被索引的基础信息单元。
比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。
文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个普遍存在的互联网数据交互格式。
在一个index/type里面,可以存储任意多的文档。
注意,尽管一个文档物理上存在于一个索引之中,但文档必须被赋予一个索引的type。
(7)、分片和复制(shards & replicas)一个索引可以存储超出单个节点磁盘限制的大量数据。
比如以下情况,一个具有10亿文档的索引占据1TB的磁盘空间,而集群中任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决此问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当创建一个索引的时候,可以指定想要的分片的数量。
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:A.允许水平分割/扩展内容容量B.允许在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量至于一个分片怎样分布,它的文档怎样聚合搜索请求,是完全由Elasticsearch管理的,用户对此是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点无原因就处于离线状态,或者由于任何原因消失了的情况下,Elasticsearch提供一个故障转移机制,它允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:A.在分片/节点失败的情况下,提供了高可用性。
因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
B.扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行总之,每个索引可以被分成多个分片。
一个索引也可以被复制0次(意思是没有复制)或多次。
一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建的时候指定。
在索引创建之后,可以在任何时候动态地改变复制的数量,但是事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
1.2.3 Logstash介绍Logstash的主要功能是收集和过滤,类似于shell中的管道符“|”。
它的工作过程是将数据进行收集,并对收集的入职根据策略进行分类和过滤,最后进行输出.实际上,Logstash 是用不同的线程来实现收集、过滤、输出功能的,可运行top 命令然后按下H 键查看线程。
数据在线程之间以事件的形式流传。
并且,logstash 可以处理多行事件。
Logstash 会给事件添加一些额外信息。
其中最重要的就是@timestamp,是用来标记事件的发生时间。
因为这个字段涉及到Logstash 的内部流转,所以必须是一个json对象,如果自定义给一个字符串字段重命名为@timestamp 的话,Logstash会直接报错,那么就需要使用filters/date插件来管理这个特殊字段。
额外信息还包括以下几个概念:A.host 标记事件发生在哪里。
B.type 标记事件的唯一类型。
C.tags 标记事件的某方面属性。
这是一个数组,一个事件可以有多个标签。
也可以自定义个事件添加字段或者从事件里删除字段。
事实上事件本身就是是一个Ruby对象。
1.2.4 Kibana介绍Kibana是一个开源的分析与可视化平台,用于和Elasticsearch一起使用,可以用kibana 搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
Kibana对大量数据的呈现非常清晰。
它简单、基于浏览器的接口能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。
本次安装部署的Kibana版本为4.3.1版本,对应Elasticsearch版本为2.4.6版本。
二 ELK安装配置2.1 系统架构介绍此架构的工作流程是Logstash agent(shipper)监控并过滤客户端日志,将过滤后的日志内容发给Redis(indexer),此处的Redis既充当消息队列的角色,由于其优越的持久化机制也被用来做缓存,然后Logstash Server(indexer)从Redis的对应位置拿出日志数据,并将其输出到ElasticSearch中,ElasticSearch获取到数据后开始生产索引,然后使用Kibana 进行页面展示。
这是一个完成的日志收集、存储、检索流程。
2.2 安装ElasticsearchOS:Centos 6.5elk-node1:10.20.20.48elk-node2:10.20.20.47在两台主机上分别安装Elasticsearch。