编译原理之有限自动机解析
【编译原理】词法分析:正则表达式与有限自动机基础

【编译原理】词法分析:正则表达式与有限⾃动机基础引⾔: 编译语⾔设计的精髓在于⾃动化过程,即如果要设计⼀门编程语⾔,那么⼀定要设计⼀个⾃动化系统,能够⾃⾏读⼊分析程序员写⼊的程序,将其翻译为机器能够识别的指令等信息。
当然⾼级语⾔的编译不是⼀蹴⽽就的,⽽是通过若⼲步的分解、规约、转换、优化,最后得到⽬标程序。
具体的编译步骤如下: 源程序就是我们写⼊的⾼级语⾔,编译的第⼀步叫做“词法分析”。
词法分析的本质,就是要拆解出语句的每⼀个单词,然后对这个单词的类型进⾏辨识。
⾸先拿中⽂来举例。
⽐如有⼀句话是“我喜欢你”,那么⾸先我们要把这句话拆成“我”、“喜欢”、“你”,然后再逐个分析他们的类型,得到“我”->主语;“喜欢”->谓语;“你”->宾语。
这样我们就把这句话每个单词都分析出来了,也就完成了中⽂的“词法分析”。
那么回到编程语⾔,它的词法分析就是将字符序列转换为单词(Token)序列的过程。
翻译成俗话,就是把我们写的⼤⽚语⾔⽂本分解为⼀个⼀个单词,再输出每个单词的类型。
举⼀个例⼦:int p = 3 + a; 这个语句⾮常简单,即定义⼀个变量p,它的初值为变量a与3的加和。
那么接下来我们要对这个语句进⾏词法分析,⾸先我们要把这段⽂本拆解成单词,拆出来就是'int'、'p'、'='、'3'、'+'、'a'、';'。
对这些单词再进⾏类型的辨识,那么就得到以下结果:语素语⾔类型int关键字p标识符=运算符3数字+运算符a标识符 这样我们就把这段⽂本中的每个单词的类型都分析出来了。
乍⼀看⾮常简单对不对,对于⼈类⽽⾔你只需要⽤⾁眼就可以轻松观察出来每个单词的类型,但对于计算机⽽⾔,它可没有⼈类那样的智能。
如果想要计算机能够识别并分析语素的类型,那就需要我们⼈类来为它构造⼀个⾃动化输⼊和分析的系统。
编译原理与技术 词法分析 (2)(2)
2024/7/1
《编译原理与技术》讲义
20
正规式与有限自动机
✓ R= R1 | R2
Si
S0 Sj
(3)
fi
f0
fj
引入新的终态f0和 (fi,)=f0和(fj,)=f0
2024/7/1
《编译原理与技术》讲义
21
正规式与有限自动机
✓ R= R1 ·R2
(1)
Si
fi
Sj
fj
R1对应的 NFA,Si为初 态,fi为终态
…
2024/7/1
《编译原理与技术》讲义
5
有限自动机的表示
e.g.7 NFA Mn =(, S, S0,F,),其中:
= { 0,1 } , S = {S0, S1 , S2 , S3 , S4 },F={S2 , S4}
(S0,0)= {S0, S3 } (S0,1)= {S0, S1 }
(S1,0)= ∅
有限自动机
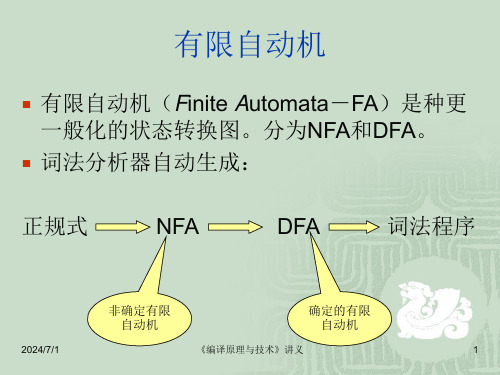
有限自动机(Finite Automata-FA)是种更 一般化的状态转换图。分为NFA和DFA。
词法分析器自动生成:
正规式
NFA
DFA
词法程序
非确定有限 自动机
确定的有限 自动机
2024/7/1
《编译原理与技术》讲义
1
非确定有限自动机-NFA
NFA Mn 是一个五元组 Mn =(, S, S0,F,), 其中:
2024/7/1
《编译原理与技术》讲义
15
比较 DFA 和 NFA(2)
DFA
NFA
容易实现-当输入串结束 由于面临同样输入符号存 时(或不存在相应状态转 在多重状态转换或存在转 换)时,若当前状态为终 换的选择,实现较为复杂。 态即为接受“已读入”的串, 一般地,NFA接受串如果
编译原理第三章 自动机基础(1)

接受空串的 FA的典型特征!
Ⅱ.第二条通路:FA2
+ ① => ①
∴ L(FA1)={ abnc| n≥0 }
b + ① => ④
bb + ① => ④ => ④
…
因而
∴ L(FA2)={ bn| n≥0 }
∴ L(FA)={abnc, bn| n≥0}
3.2.3 有限自动机的两种表现形式
【例3.6】有限自动机 :FA=( Q,∑,S,F, ) 其中: Q={1,2,3,4},∑={a,b,c}, S={1,2}, F={3,4}
9.
={abn|n≥0}
10.7. L((a|b)*)= (L(a|b))*={a,b}*
11. 即:由a,b组成的所有符号串(包括空串)集合。
➢基本图形库
=+>
.=+>
=.+ℓ>
=+ℓ>
A
P: E T
F
T | E +T | E -T F | T *F | T /F i|( E )
=>*, =>+ , =>.* , =>.+ , =>l* , =>l+ , =>.l+ ,=>.l*
如 右图有限自动机:
则 L(FA)的 识别过程如下所
+- ①
a b
b ②
c
b
③-
示:
④-
※ L(FA)的生成(或识别)过程示例:
Ⅰ.第一条通路:FA1 ac
+ ① => ② => ③
+- ①
编译原理之有限自动机
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8}
状态 A
输入符号 ab B
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8}
识别器:是一个程序,取串x作为输入,当 x是语言的句子时,它回答“是”,否则回 答“不是”。 状态转换图(有限自动机)识别器 确定/不确定有限自动机——时空权衡问题
确定有限自动机:快,空间大
2.3 有 限 自 动 机
2.3.1 不确定的有限自动机(简称NFA)
一个数学模型,它包括: 状态集合S;
缺点:1、输入字 符包括
NFA能到达的所有状态:s1, s2, …, sk,则 DFA到达状态{s1, s2, …, sk}
2.3 有 限 自 动 机
输入符号
状态 a
b
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7}
状态 A
输入符号 ab
a
2
3
开始
0
1
a
b
6
7
8
9
输入符号 ab BC BD
a
2
3
开始
2.2 词法记号的描述与识别
有限自动机算法

有限自动机算法
有限自动机算法是一种常见的计算机科学算法,也称为状态机算法或有限状态自动机算法。
它是一种用来识别字符串的算法,通常被用于文本处理、编译器设计、自然语言处理等领域。
有限自动机算法基于有限状态自动机的理论,将一个字符串视为一个字符序列,通过状态转移来确定字符串是否符合特定的语法规则。
有限自动机算法通常分为两种类型:确定有限自动机(DFA)和非确
定有限自动机(NFA)。
DFA是一种状态转移图,其中每个状态都有一个唯一的出边,对于一个输入字符,只有一种可能的转移路径。
NFA则允许一个状态拥有多个出边,每一条出边代表一个可能的转移路径,同时,NFA还可以在不确定的情况下选择一条转移路径。
有限自动机算法的核心思想是将一个字符串逐个字符地输入到
状态机中,根据状态转移的规则,判断当前字符是否满足预定的语法规则。
如果符合规则,状态机将进入下一个状态,直到整个字符串被处理完毕。
如果最终状态符合预定要求,那么这个字符串将被认为是合法的。
总的来说,有限自动机算法是一种高效的字符串处理算法,它可以用来判断字符串是否符合特定的语法规则。
在文本处理、编译器设计、自然语言处理等领域中有广泛的应用。
- 1 -。
编译原理--有限自动机

(4)S∈K,是唯一的初态;
(5)Z是K的子集,是一个终态集,终态也称为可接收状态或 结束状态。
12
确定的有穷自动机DFA的表示
3.2.1 状态转换图
设DFA有m个状态,n个输入字符,那么这个图含有m 个状态结,每个结点最多有n条箭弧射出和别的结点相连接, 每条弧用Σ中的一个不同输入符号作记号。整个图含有唯一 的一个初态和若干个(可以0个)终态结。
10
3.2 有穷自动机的形式定义
DFA: Deterministic Finite Automata NFA: Nondeterministic Finite Automata
DFA的定义
定义3.1 一个确定的有穷自动机(DFA) M是一个五元组: M = ( K, Σ, f, S, Z )
(1)K是一个非空有穷集合,它的每一个元素称为一个状态;
解:该DFA M的状态图:
0
a
b b
1
a 2
a
3 b
a, b
14
确定的有穷自动机DFA的表示(续)
3.2.2 状态转换矩阵
矩阵的行表示状态,列表示输入字符,矩 阵元素表示相应的状态行在输入字符列下的新 的状态,即f(k,a)的值。
15
例2(题同1)
解:该DFA M的矩阵表示
状态 0 1 2 3 字符 a 1 3 1 3 b 2 2 3 3
例1:(1)到此为止是偶数个a和偶数个b; (2)到此为止是奇数个a和偶数个b; (3)到此为止是偶数个a和奇数个b; (4)到此为止是奇数个a和奇数个b。 根据每种可能性设计一个状态,并根据可能的输入 符号来设计状态之间的转移条件。 a a 2 b b b 3 a a b
1
编译原理 第三章 有限自动机与词法分析器
第三章有限自动机与词法分析器3.1词法分析3.1.1词法分析器的功能在第二章里我们已介绍了词法分析的基本问题。
计算机存储是二进制式的,因此,任何一种程序和数据在计算机内部均被表示为二进制表示。
实际上,当程序员每按键盘中的一个键时,自动往计算机里输入一个相应的八位二进制码,称这种码为ASCII码。
当程序员敲完程序时将它保存到自己事先起好名的文件中,因此,程序在计算机文件中的表示是ASCII码序列(末尾有文件结束码)。
编译器总是要用某种程序设计语言来写,而任何一种语言的程序其操作对象必须是该语言所规定的数据。
编译器的操作对象是程序中的各种语法单位,如<常量声明>,<类型声明>,<变量声明>,<过程声明>,<表达式>,<语句>,<变量>等等,因此,必须把它们都表示成某种数据结构形式,而它们的最小单位是所谓的单词,故首当其充的是要把每个单词转换成一种数据形式,通常称它们为TOKEN。
词法分析器的任务就是,从源程序的ASC码(用高级语言的术语来说是字符串)序列逐个地拼出单词,并将构造相应TOKEN数据表示。
词法分析器可有两种,一种是它作为语法分析的一个子程序,一种是它作为编译器的独立一遍。
前一种情形,词法分析器不断地被语法分析器所调用,每调用一次词法分析器将从源程序的字符序列拼出一个单词,并将其TOKEN值返回给语法分析器。
后一种情形则不同,即不是被别的部分不断地调用,而是完成编译器的独立一遍任务,具体说将整个源程序的字符序列转换成TOKEN序列,并将其交给语法/语义分析器。
实际的编译器一般都采用子程序方式,但是为了独立地介绍词法分析、语法分析和语义分析的概念和技术,我们将词法分析部分分离出来即作为独立一遍的词法处理器来介绍。
从实际的角度来说,这种方法有以下缺点:一是因为它要生成TOKEN列,自然多占用空间;二是因为要保存所有的TOKEN,需要耗费更多的时间。
编译原理及实现技术:3.词法分析__DFA——确定有限自动机

注意的问题
特殊的状态 “死状态”
缺省 状态
缺省 转换函数
确定有限自动机( DFA)的定义 DFA的表示
DFA接受的集合 应用实例
用DFA描述单词 自动机的实现 注意的问题
自自动动机机等等价价
自动机等价
对于两个DFA M1和M2 若有L(M1)=L(M2),则称M1和M2等 价
习题
aQ
b
V
b
确定有限自动机 (DFA)的定义
DFA的表示
DFA接受的集 DFA接受的集合合
DFA接受的集合
对于*中的任何字符串t, 若存在一条从初始
结点到某一终止结点的路径,且这条路上所
有弧的标记符连接成的字符串等于t,则称t可
为DFA M所接受(识别)
DFA M 所能接受的字符串的全体记为L(M)
S0=0, Z={2}
确定有限自动机 (DFA)的定义
DDFFAA的的表表示示
DFA的表示
状态转换矩阵
列标用 自动机的输入字符 表示 行标用 状态 来表示 矩阵元素 表示自动机的状态转换函数 标识初始状态和终止状态:一般约定,
第一行表示开始状态S0 ,或在右上角 标注“+”;右上角标有“*”或“-” 的状态为终止状态 ;
设计一个DFA 使其能接受被4整除的二进制数
DFA接受的集合 应用实例
用DFA描述单词
自自动动机机的的实实现现
自动机的实现
直接转换法
针对状态数不太多的情况,用双重switch 语句来实现。
状态转换矩阵
自动机存储在矩阵中,状态比较多,每次 都去查表,跳转。
确定有限自动机( DFA)的定义 DFA的表示
DFA接受的集合 应用实例
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
简单的正则式d->a
a
0
1
正则式d->ab
a
b
0
1
2
正则式d->a|b
a
0
1
b
正规式d->a*
a 0
自动机的定义
正规式d->a?
字符a出现一次或者0次
a
0
1
练习
正规式d->a(a|b)*
请画出它的状态转换图
a
a
0
1
b
2.2 词法记号的描述与识别
2.2.4 转换图 relop < | < = | = | < > | > | > =
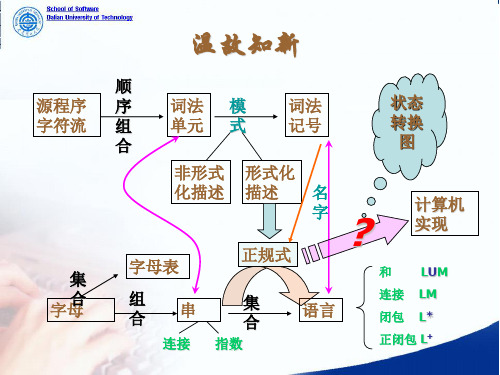
温故知新
源程序 字符流
集 Байду номын сангаас母合
顺 序 词法 模 组 单元 式 合
词法 记号
状态 转换 图
非形式 形式化
化描述 描述 名
字
?
正规式
字母表
和
计算机 实现
LUM
组 合
串
集 合
连接 指数
语言
连接 LM 闭包 L* 正闭包 L+
词法记号的识别
词法记号的识别
等同于对字符串的匹配过程
这个匹配过程可以基于有限状态机来完成
• 关系算符的转换图
=
2 return(relop, LE)
1
>
3 return(relop, NE)
<
开始 0
=
other
* return(relop, LT) 4
5 return(relop, EQ)
>
=
7 return(relop, GE)
6
other 8 * return(relop, GT)
状态
A B C
输入符号 ab BC B
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8} C = {1, 2, 4, 5, 6, 7} D = {1, 2, 4, 5, 6, 7, 9}
状态
A B C
状态
A B
输入符号 ab B
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8} C = {1, 2, 4, 5, 6, 7}
状态
A B
输入符号 ab BC
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
NFA能到达的所有状态:s1, s2, …, sk,则 DFA到达状态{s1, s2, …, sk}
2.3 有 限 自 动 机
输入符号
状态 a
b
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7}
状态 A
输入符号 ab
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8}
状态 A
输入符号 ab B
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8}
2.2 词法记号的描述与识别
空白的转换图
delim blank | tab | newline ws delim+
开始
delim
delim
other
*
20
21
22
2.3 有 限 自 动 机
? 正规式
状态转换图
有限自动机
计算机 实现
等价
不确定有 限自动机
确定有限 自动机
2.3 有 限 自 动 机
• 唯一的初态 s S;
• 终态集合F S;
b
优点:1、输入字 符不包括
2、一个状态对于 某个字符,只可能 存在唯一条输出边
b
识别语言
(a|b)*ab 的DFA
开始
a
0
b
1
2
a a
2.3 有 限 自 动 机
2.3.3 NFA到DFA的变换
子集构造法 DFA的一个状态是NFA的一个状态集合 读了输入a1 a2 … an后,
2.2 词法记号的描述与识别
标识符和保留字的转换图
id letter (letter | digit )* letter或digit
开始
9
letter
10
other
*
11 return(install_id( ))
1、检查保留字表,如果在表中发现该词法单元则返回 相应的记号并退出,否则转向2 2、该词法单元是标识符,在符号表中查找,若找到该 词法单元则返回该条目的指针并退出,否则执行3 3、在符号表中建立一个新的条目,把该词法单元填入, 并返回此新条目的指针
输入符号集合;
2、一个状态对于 某个字符,可能有
转换函数move : S ({}) P(S); 多条输出边
状态s0是开始状态;
F S是接受状态集合。
a
识别语言 (a|b)*ab
开始 0
a
1b
2
的NFA
b
2.3
• NFA的转换表
状态
有限自动机 优点:快速定位 缺点:字母表过大 或大部分转换状态 为空集时浪费空间 输入符号
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8} C = {1, 2, 4, 5, 6, 7}
状态
A B C
输入符号 ab BC
a
2
3
开始
0
1
a
b
6
7
8
9
b
4
5
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8} C = {1, 2, 4, 5, 6, 7}
a
b
0
{0, 1}
{0}
1
{2}
2
识别语言
(a|b)*ab 的NFA
a
开始
a
0
1b
2
b
2.3 有 限 自 动 机
例 识别aa*|bb*的NFA
a
a
1
2
开始
0
b
b
3
4
2.3 有 限 自 动 机
2.3.2 确定的有限自动机(简称DFA)
一个数学模型,包括:
• 状态集合S;
• 输入字母表;
• 转换函数move : S S;
输入符号 ab BC BD
a
2
3
开始
识别器:是一个程序,取串x作为输入,当 x是语言的句子时,它回答“是”,否则回 答“不是”。 状态转换图(有限自动机)识别器 确定/不确定有限自动机——时空权衡问题
确定有限自动机:快,空间大
2.3 有 限 自 动 机
2.3.1 不确定的有限自动机(简称NFA)
一个数学模型,它包括: 状态集合S;
缺点:1、输入字 符包括
2.2 词法记号的描述与识别
无符号数的转换图
num digit+ (.digit+)? (E (+ | )? digit+)?
E
digit
digit
digit digit
开始
12
digit
13
.
digit
14
15
E
+/ digit
16
17
18
other
other
other
*
19
return( install_num( ) )