埃森哲-数据挖掘模型DM的分类及说明
Basic_Principle
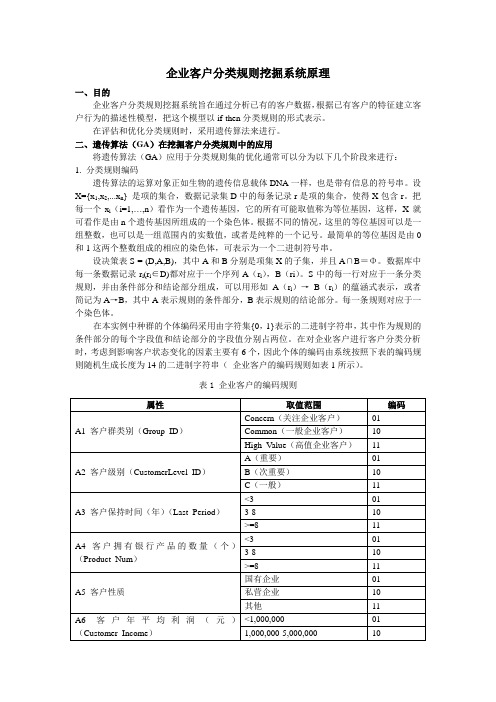
企业客户分类规则挖掘系统原理一、目的企业客户分类规则挖掘系统旨在通过分析已有的客户数据,根据已有客户的特征建立客户行为的描述性模型,把这个模型以if-then分类规则的形式表示。
在评估和优化分类规则时,采用遗传算法来进行。
二、遗传算法(GA)在挖掘客户分类规则中的应用将遗传算法(GA)应用于分类规则集的优化通常可以分为以下几个阶段来进行:1. 分类规则编码遗传算法的运算对象正如生物的遗传信息载体DNA一样,也是带有信息的符号串。
设X={x1,x2,...x n} 是项的集合,数据记录集D中的每条记录r是项的集合,使得X包含r。
把每一个x i(i=1,…,n)看作为一个遗传基因,它的所有可能取值称为等位基因,这样,X就可看作是由n个遗传基因所组成的一个染色体。
根据不同的情况,这里的等位基因可以是一组整数,也可以是一组范围内的实数值,或者是纯粹的一个记号。
最简单的等位基因是由0和1这两个整数组成的相应的染色体,可表示为一个二进制符号串。
设决策表S = (D,A,B),其中A和B分别是项集X的子集,并且A∩B=Φ。
数据库中每一条数据记录r i(r i∈D)都对应于一个序列A(r i),B(ri)。
S中的每一行对应于一条分类规则,并由条件部分和结论部分组成,可以用形如A(r i)→B(r i)的蕴涵式表示,或者简记为A→B,其中A表示规则的条件部分,B表示规则的结论部分。
每一条规则对应于一个染色体。
在本实例中种群的个体编码采用由字符集{0,1}表示的二进制字符串,其中作为规则的条件部分的每个字段值和结论部分的字段值分别占两位。
在对企业客户进行客户分类分析时,考虑到影响客户状态变化的因素主要有6个,因此个体的编码由系统按照下表的编码规则随机生成长度为14的二进制字符串(企业客户的编码规则如表1所示)。
表1 企业客户的编码规则其中客户状态通过在每个月份比较客户各业务账户的余额总和是否比参照值突然升高或降低某个百分比或数值,将客户状态Customer_Status分为活跃客户、稳定客户和流失客户三类。
数据模型 主题域模型

数据模型可以分为多种,其中主题域模型是一种常见的分类方式。
主题域模型通常是在较高层面上对企业数据进行归类、分析的抽象概念,每一个主题通常对应一个宏观层面的业务领域或业务板块。
主题域是数据组织的重要分类方式,也是数据认责的一个重要维度。
主题域的划分通常遵循“不交叉、不重叠、不遗漏”原则。
在数据模型的应用范畴中,数据模型可以分为组织级数据模型和系统应用级数据模型。
组织级数据模型包括主题域模型、概念模型和逻辑模型三类,系统应用级数据模型包括逻辑模型和物理数据模型两类。
主题域模型是在最高层级上以主题概念及其之间的关系为基本构成单元的模型,主题是对数据表达事物本质概念的高度抽象。
概念模型是以数据实体及其之间的关系为基本构成单元的模型,实体名称一般采用标准业务术语命名。
逻辑模型是在概念模型的基础上细化,以数据属性为基本构成单元。
物理模型是逻辑模型在计算机信息系统中的具体实现,依托于特定实现工具的数据结构。
以上内容仅供参考,建议查阅关于数据模型的书籍或者咨询专业人士获取更准确的信息。
数据挖掘应用案例RFM模型分析与客户细分

数据挖掘应用案例RFM模型分析与客户细分RFM模型分析与客户细分是一种常见的数据挖掘应用案例,用于帮助企业理解其客户群体、挖掘潜在商机以及制定有效的市场推广策略。
RFM模型通过对客户最近一次购买时间(Recency)、购买频率(Frequency)以及购买金额(Monetary)进行分析,将客户分成不同的细分群组,以便企业可以有针对性地开展营销活动。
首先,我们来看看如何通过RFM模型分析对客户进行细分。
1. Recency(最近一次购买时间):根据客户最近一次购买时间的间隔,可以将客户分为活跃客户、不活跃客户以及休眠客户等不同群组。
活跃客户是指最近购买时间间隔较短的客户,他们对于企业来说非常有价值,因为他们可能是经常下单的忠实客户,或者是对新产品感兴趣的潜在客户。
不活跃客户是指最近购买时间间隔较长的客户,他们的购买意愿降低,可能需要通过一些特殊的优惠措施来刺激其再次购买。
休眠客户是指最近购买时间间隔很长的客户,他们已经很久没有购买了,通常需要采取一些激励举措才能重新激活他们的购买兴趣。
3. Monetary(购买金额):根据客户的购买金额,可以将客户分为高价值客户、中等价值客户以及低价值客户等不同群组。
高价值客户是指购买金额较大的客户,他们对于企业来说非常有价值,可以为企业带来较高的利润。
中等价值客户是指购买金额适中的客户,他们对于企业来说也是重要的资产,可以通过特殊的优惠措施来提升他们的购买金额。
低价值客户是指购买金额较小的客户,他们通常需要通过一些激励措施来提高其购买金额。
通过对客户的Recency、Frequency和Monetary进行综合分析,可以将客户分为不同的细分群组,例如:1.VIP客户群:最近购买时间较短、购买频率较高、购买金额较大的客户,是企业最重要的客户群体。
企业可以通过特殊的服务和优惠措施来保持他们的忠诚度,并提高他们的购买额。
3.潜力客户群:最近购买时间较短、购买频率较低、购买金额较大的客户,虽然购买频率较低,但购买金额较高,有很大的潜在商机。
埃森哲大数据分析方法

建立模型: 综合考虑业务需求精度、数据情况、花费成本等因素,选择最合适的模型。 在实践中对于一个分析目的,往往运用多个模型,然后通过后续的模型评估,进行优化、调整,以寻求最合适的模型。
注意
判别方法
判别公式
剔除范围
操作步骤
评价
拉依达准则 (3σ准则)
大于μ+3σ 小于μ-3σ
求均值、标准差,进行边界检验,剔除一个异常数据,然后重复操作,逐一剔除
适合用于n>185时的样本判定
肖维勒准则(等概率准则)
大于μ + Zc(n)σ小于μ - Zc(n)σ
求均值、标准差,比对系数读取Zc(n)值,边界检验,剔除一个异常数据,然后重复操作,逐一剔除
业务理解
数据理解
数据准备
建立模型
模型评估
开始
是否明确需求
否
否
数据探索
结构分析
分布特性
特征描述
……
分类与回归
聚类分析
时序模型
关联分析
结构优化
分析结果应用
数据分析框架
图例
流程概要
方法分类
处理方法
模型检验
理解业务背景,评估分析需求
是
是否满足要求
收集数据
否
是
是
建立模型
贝叶斯
神经网络
C4Hale Waihona Puke 5决策树……指数平滑
狄克逊准则
f0 > f(n,α),说明x(n)离群远,则判定该数据为异常数据
将数据由小到大排成顺序统计量,求极差,比对狄克逊判断表读取 f(n,α)值,边界检验,剔除一个异常数据,然后重复操作,逐一剔除
万加特纳优化选择模型

目录一、背景知识 (1)1.模型背景 (1)2.相关概念介绍 (1)二、模型介绍 (2)1.模型假设 (2)2.模型建立 (2)3.模型求解及其经济解释 (4)三、模型实验设计 (4)1.实验目的 (4)2.实验要求 (4)3.实验原理 (5)4.实验过程 (5)5.实验操作 (5)6.实验总结 (9)四、应用案例 (10)五、思考题 (11)六、参考文献 (11)万加特纳优化选择模型一、背景知识1.模型背景项目群方案选优是项目经济评价中重要的组成部分,更是投资者做出最终项目决策的重要依据。
在可选项目数量较少时,投资者可以用列举等直观的方法得到满意的答案。
但在实际的投资项目中,经常包括几个独立型项目而且每个项目中又有众多方案可供选择,这时若列举、比较所有可能的组合并从中选优则非常费时费力。
如果受限制的不仅是资金,还有设备、人员,再加上方案间的约束关系,要想直观的进行项目的选择就更力不从心了。
这种情况下,建立万加特纳优化选择模型是最佳选择。
万加特纳(Weingartner)优化选择模型是将项目中各种约束条件进行分类表述的0-1整数规划模型。
该模型具有不可分性,对原本独立项目的选择只有两种可能:被选取或者被拒绝。
该模型的建立使方案间复杂的相关关系数学化,并在计算机及相应软件的辅助下大大简化了选择过程,提高了工作效率。
2.相关概念介绍从方案比选的角度看,投资方案可分为独立方案和相关方案。
(1)独立方案独立方案指项目的各个方案的现金流都是独立的,各方案的费用和收益在决策前可以独立地确定。
每个方案是否被采纳,只取决于其本身的可行性如何,与其他方案最终选取与否无关。
(2)相关方案相关方案指在项目的多个方案间,接受或否决某一方案,将会改变其他方案的现金流量,或影响其他方案的取舍。
相关的类型主要有:互斥型、依存型、紧密互补型、非紧密互补型等。
①互斥型若a、b为互斥方案,则两方案不能同时被选择,只选择a或者只选择b或者两者都不选择。
DM名词解释

DM名词解释1、DM:直邮(Direct Mail),直复营销(Direct Marketing),数据库营销(Database Marketing), 数据挖掘(Data mining)都可简称DM,但一般意义上的DM,是指直邮(Direct Mail)。
2、直邮(Direct Mail):即直接邮寄广告(直接邮寄信件),在国外也称为目录销售,是指基于广告目的的商业信函。
就是将企业希望表达的相关信息通过信件的方式传递到目标顾客手中,从而达到营销目的。
直邮具有以下的特点:(1)、针对性强——针对目标客户进行广告投放,使宣传一部到位,是目标营销的重要手段。
(2)、灵活高效——可跨时间、空间、形式多样地使用、信息量大;便于收藏和传阅。
(3)、经济实惠——使用资金投入较小,回报率高。
(4)、人情味足——DM起源于书信,有书信特有的亲切感,易为人们接受。
(5)、可测性高——DM能使广告主容易获得目标受众的直接反馈,传播效果易于测量。
(6)、保密性强——发布形式隐蔽,广告策略不易被竞争对手察觉。
3、直邮的操作步骤:制定该次直邮的营销目标,确定需要传递的信息;→筛选数据库,寻找传递信息最有效的接收者;→制定直邮预算和收益模型;→设计制作直邮刊物;→将制作好的刊物邮寄至数据库中的目标消费者;→监测直邮的反馈信息,分析结果,并根据该信息决定后续措施。
4、广义的直邮(DM):社会上将企业直接发放的宣传单页、邮寄的信件、明信片等统称为直邮,并将其视为与大众媒体相对的一种分众传播媒体。
5、直复营销(Direct Marketing):是通过使用一种或多种广告媒介,在任何地方都能有效激发可衡量的回复和(或)达成交易的一个互动的系统,是无店铺销售的一种方式。
根据其所采用媒体的不同,直复营销可分为目录营销、直邮营销、电话营销、电视营销、网络营销、名址数据库营销、一对一营销、个性化营销、关系营销、忠诚度营销等多种形式。
6、直复营销“40-30-20-10”规则:直复营销活动的成功40%取决于接受信息客户群的选取,即要向正确的客户发送信息;30%取决于向选定的客户提供适当的优惠措施(诱因);20%取决于广告的创造力,即文字艺术效果、版面设计等;10%取决于所选择的媒介:邮件、电话、传真、网络、电视、电台、报刊杂志等。
RFM分类方法及模型

RFM顾客分类方法及模型Recency:理论上,上一次消费时间越近的顾客应该是比较好的顾客,对提供即时的商品或是服务也最有可能会有反应。
如果我们能让消费者购买,他们就会持续购买。
Frenquency:消费频率是顾客在限定的期间内所购买的次数。
我们可以说最常购买的顾客,忠诚度相对高于其它顾客。
Monetary:消费金额的意义不言而喻。
一、RFM分类:(参考:Arthur Hughes 顾客五等分模型)1、查询出一年时间内(以查询时间向前推一年计算)所有VIP顾客的最近一次购买时间;2、将靠前(离查询时间最近)20%标记为5,前20%-40%,标记为4,前40%-60%,标记为3,前60%-80%,标记为2,前80%-100%,标记为1。
依次类推,将此项上所有顾客分成5-1五等分;3、查询出在一年内所有VIP顾客的消费频次及购买金额,已同样的方法划出5等并进行5-1的标记;4、将R、F、M三项对应到单个顾客,最终每个顾客将出现一个由三个数字组成的数组;5、将每个顾客对应的三位数相加,作为顾客价值的得分,进行标记。
二、顾客价值及流失监控模型1、顾客价值模型理论上来说,同等的资源投入的情况下,一名超优质顾客的回报将会是优质顾客的5倍,可以推出,在资源有限的前提下,满足顾客的顺序应该也是自上而下的: 1) 要求系统对每个顾客进行评分并归类2) 评分及归类以分店为单位(按照三月内消费次数最高分店计算,如果出现两店消费次数一样算为老店顾客)2、 流失顾客监控模型1 2 3 4 5MR1 2 3 4 5由图可以看出,只有在右下象限的顾客是最需要重点关注并对其进行挽留的,顾客流失项目主要是对此类顾客进行:1)要求系统能自动对各分店此类顾客进行自动标记;R ≥3且M ≥3 :高价值忠诚 R <3且M ≥3 :高价值流失R <3且M <3 :低价值流失 R ≥3且M <3 :低价值忠诚 2)自动显示此类顾客数量及占比情况; 3)能够批量查询此类顾客单个基本资料; 4)查询结果可以导出。
数据挖掘技术与关联规则挖掘算法研究报告

工学博士学位论文数据挖技术与关联规则挖18法研究毛国君工业大学2003年4月单位代码:10005分类号:TP311学号:B200007009密级:工业大学工学博士学位抡文題目:数据挖損技术庁关联規IM挖損算法研究英文题目:DATA MINING TECHNIQUES AND ALGORITHMS FORMINING ASSOCIATION RULES研究生xx: Of ______________________________________ 专i:计算机应用枝术研究方向:人工智能与知识工程导师xx: _____________ 职緘_________________________论文报告授交日期:2003. 4 ____________________ 学位授予日期:授予单位名称和地北:工业大学(市XX区平乐园100号)_____________________________摘要数抵挖掘是致力于数播分析和理解、蝎示数抵内部珞藏知识的技术,它成为未来信息技术应用的重要目标之一。
经il十几年的努力,数抵挖掘产生了许多新概念和方法。
特别是最近几年,一些基本榔念和方法趙于清晰,它的研究正向着更深入的方向发展。
像其它新技术的发展历程一样,数抵挖掘技术也必须经ills念提出、概念接受、广泛研究和探索、逐步应用和大量应用等阶段。
从目前的现状看,大部分学者沃为数掘挖掘的研究仍然处于广泛研究和探索阶貝,迫切需要在基础理论、应用模式、系貌构架以及挖掘算法和挖掘语言等方面ttftfii]新。
关联观IM挖掘是数掘挖掘中成果颇丰而且比较活跌的研究分支,留给研究者的是更深入的课题。
面对大型数播库,关联规则挖掘需耍在挖掘效率、可用性、精确性等方面得到提升。
因此,需耍探索新的挖掘理论和模型;需要利用用户的约束等聚焦挖掘目标;需耍对一些传统的算法alia进;也需要研究新的更有效的算法等。
鉴于目前数播挖掘技术和关联规则挖掘研究的现状和发展范势,在各类基金的支持下,我们选择了这一课題开展相关工作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0.30
0.2
C
男性 纽约
0.55
0.70
0
0
0.2
0.4
0.6
0.8
1
City
群1:纽约
7
群2:台北
指导性分群2
目标变量(分群指导变量):是否订阅了《化妆师》杂志
城市
纽约 台北
目标变量=1 (订阅过《化妆师》)
55% 45%
性别 女性 男性
编码
性别
城市
编码后的 编码后的
性别
城市
1
0.8
A
女性 纽约
10
行为和价值是最能反映客户态度和需求的两个维度
态度决定行为 行为决定价值 关系体验决定满意度 交易关系、客户待遇及产
品满意度决定态度
品牌体验
品牌效应
客户
满意
需求/态度
行为
品牌依附度
关系
$价值$
基于产品种类
的参与 客户态度驱动了客户价值
11
预测模型定义
预测模型是通过对过去数据学习来判断未来某种行为或计量的数学模型,模型目标可 以是逻辑型或连续性变量,模型可以简单的用数学公式Y=F(X)来描述预测模型(X是 n元向量)。每个客户都将通过模型计算获得一个预测值作为业务决策依据之一。
0.90
0.55
0.6
Gender
0.4
B
男性 台北
0.10
0.45
0.2
C
男性 纽约
0.10
0.55
0
0
0.2
群1:女性
8
群2:男性
目标变量=1 90% 10%
1
A
2
BC
0.4
0.6
0.8
1
City
无指导性分群
城市 纽约 台北
随意编码 0 1
性别 女性 男性
编码
性别
城市
编码后 的
编码后 的城市
1C
揭示蕴含于历史数据中的规律 无指导的学习
1
对未来事件的预测 有指导的学习
电信行业中最常用的两种数据挖掘模型是客户分群和预测模型
客户分群模型
• 指导性分群 • 无指导分群
263
145
110
90
70
50
28 128 228 290 360 580 982 1039
预测模型模型
• 回归 • 决策树 • 神经元
15 37349977 O
XX街XX号
16 34506819 P
XX街XX号
17 31663661 Q
XX街XX号
得到模型计 分,选出相 似性高的客 户(红色格 子)
预测模型的建立方法
模型建立
应用1-4月份客户数据和6月份离网数据建立离网预测模型
1月
2月
3月
4月
5月
6月
客户数据
离网数据
模型验证
应用2-5月份客户数据和7月份离网数据进行离网预测模型检验
群1 群3
4
群2 群4
指导性分群定义
指导性分群是在一定的目标变量(或称指导性变量)将客户划分到具有相同行为、价值和 社会属性等的不同组别的分析性工具
群1 群3
5
群2 群4
指导性分群和无指导分群的主要区别——问题
客户 A B C
性别 女性 男性 男性
城市 纽约 台北 纽约
您会怎样将这三个客户进行客户 分群呢?
12
运用已经有 目标行为的 客户的共同 特征,按照 相似程度, 给其他客户 打分
目标客户列表
编号 电话号码
姓名 住址
1 85486643 A
XX街XX号
2 97645756 B
XX街XX号
3 59801486 C
XX街XX号
4 21957216 D
XX街XX号
5 59114637 E
XX街XX号
6 96272059 F
▪ 所有的客户都应该包含在分群模型当中 ▪ 单个的客户和客户群必须一一对应
2月
3月
4月
5月
应用3-6月份客户数据预测9月离网客户
3月
4月
5月
6月
7月
8月
13
挽留行动
子目录
模型的分类与适用范围 模型的评价标准与方法 案例
14
分群模型评估标准
互斥性和穷尽性原则 (Mutually exclusive & Collectively exhaustive)
场合
分群维度
公司组织/ 人员
产业(SIC) 公司大小
关键购买 因素
需要
人人口口统统计计
客户价值 态度/意向
ARPU
盈利能力 与收入相配比的服务
成本
年龄 性别 职业 收入 生活方式 家庭状况
活动/行为
MOU 使用年限 安装时间 持有产品的种类 趋势
一般购买态度 购买心理因素
最最常常见见的的客户战分略群分维群度 维度
子目录
模型的分类与适用范围 模型的评价标准与方法 案例
0
数据挖掘模型按照功能划分主要分为描述性模型和预测性模型两类
技术相关:
无指导性分群
关联规则 (购物篮)
我们的客户是 什么样子的? 他们需要什么
?
如何选取最好的针 对性客户交互方式 ,以保证利润最大
化?
描述性模型 数据挖掘 预测性模型
技术相关: 指导性分群 逻辑回归 线性回归 非线性回归 决策树 神经网络
7%-8% 6%-7% 5%-6% 4%-5% 3%-4% 2%-3% 1%-2% 0%-1%
2
电信业数据挖掘模型主要适用范围
交叉销售
客户分群模型
交易 行为
预测模型
信用 风险
流失倾向 交易价值 响应倾向 客户信用管理
生命周期价值
向上销售
账单催收管理
主动 新客户获取
客户挽留
3
无指导性分群定义
无指导性分群是将客户划分到具有相同行为、价值和社会属性等的不同组别的分析性工具
性别
A
女性 纽约
0
0
Gender
B
男性 台北
1
C
男性 纽约
1
1
A
0 0
0 群1: ?
群 2: ?
9
随意编码 0 1
B
1 City
客户分群常见维度
确定分群维
度
产品与服务的效果认
可
品牌的认知
感觉认知
财务制约 竞争对手
制约性
本地,地区,国家和国际 地点
竞争者的地点和客户服务
地理因素
什么时间 什么地点 如何购买
电信行业中最为广泛使用的预测模型通常是二元逻辑变量预测模型,如客户离网挽留 模型、营销活动相应模型等
Y=F(X)
400 350 300 250 200 150 100
50 0 0
25
50
75
100
黄色格子为 过去表现出 目标行为的 客户;白色 格子为过去 没有目标行 为的客户
寻找已经有 目标行为的 客户的共同 特征
6
指导性分群1
目标变量(分群指导变量):是否订阅了《纽约客》杂志
城市
纽约 台北
目标变量=1 (订阅过《纽约客》)
70% 30%
性别 女性 男性
目标变量=1 45% 55%
编码
性别
城市
编码后的 编码后的
性别
城市
1 0.8
2
1
A
女性 纽约
0.45
0.70
0.6
B
C
A 0.4
Gender
B
男性 台北
0.55
XX街XX号
7 60095245 G
XX街XX号
8 57252087 H
XX街XX号
9 54408928 I
XX街XX号
10 51565770 J
XX街XX号
11 48722611 K
XX街XX号
12 45879453 L
XX街XX号
13 43036294 M
XX街XX号
14 40193136 N
XX街XX号