虚拟低音的实现原理及验证方案
虚拟低音的实现原理方案
虚拟低音的实现原理及验证方案背景和理论原理:在当前手持设备或其他消费电子设备中,由于体积和外形的要求,作为发声的喇叭尺寸受到了极大限制,尺寸的限制造成了喇叭对于低音部分无法响应.造成音频部分低音的缺失,无法给消费者提供更高要求的享受.在人耳的研究中发现,人可以对两个高音的差频产生响应,给了听觉上造成低音的感觉,这就是所谓的虚拟低音.实现算法框图图1其中谐波发生器和增益控制器的框图采用MAXBASS公布的算法:如图22这里我们可以看出我们需要做的就是:●提取低音信号和高音信号,需要设计一个高通和低通滤波器,低通滤波器来提取低音信号,高通滤波器来提取高音信号,低通滤波器的截止频率为扬声器的截止频率,在demo 的时候我们做成固定的100HZ.●谐波发生器.●混频器.滤波器滤波器我们采用matlab的FDATOOL工具来实现,然后可以根据工具生成的系数,根据滤波器的结构采用matlab语言自己编写.滤波器可以看见的总共有4个,输入高低滤波的滤波器HPF-IN和LPF-IN,这两个滤波器的功率互补的.HPF-OUT和HPF-IN是一样的.HPF-FB是反馈回路高通滤波器.上图可知,上面提到的4个滤波器的截止频率都是可调的.这里需要注意.一开始我们可以做成频率固定的,因为我们可能并不会做成IC的形式,因此可以在软件中随时调整截止频率.自动幅度控制模块:上图为等响度曲线图,我们可以看出不同的频率,相同的升压变化造成的响度变化是不同的.这里我们定义声压-响度扩展比率,即升压变化/响度变化的值R.在频率为20~700hz,响度为20-80方内:R的值可以近似为:保持谐波响度对声压级的动态特性于基频处一致对于还原虚拟低音的响度和音色十分重要. RR(f,n)定义如下.从上式看出,RR(f,n)和ln(n)及R(f)成正比.而f又同R(f)基本成反比.根据定义得知,我们需要谐波的幅度和基波幅度的比值应该为RR(f,n)Enf=Ef*RR(f,n);而经过混频器后,谐波输出的幅度并不能满足上述条件.需要乘上一个系数H,很明显这个系数和谐波次数和基频频率相关,这将引入计算和实现的复杂度,在这里我们需要简化. 我们知道,声强主要有主谐波决定,通过计算我们得出系数近似H=A0^K;K大概为0.64.A0是输入信号的幅度.A0^K次我们可以采用拟合函数拟合.包络检测:包络检测我们可以用滤波器的方法,也可以用普通的包络检测算法.这里我们采用普通的包络检测算法,包络这里其实就是峰值检测,算法如下:当|x(n)|<xpeak(n-1)时:当|x(n)|>xpeak(n-1)其中:这里ta,tr是两个时间常数,分别含义是跟进峰值时间,和峰值释放时间,这里我们可以设置ta=0.2ms,tr=200ms.单位为毫秒ms.ts是采样时间.单位为秒s.混音算法高音和低音的谐波相加,这里应该需要混音的算法,目前混音的算法有线性相加等算法,我们到时可以根据效果采用一个.总结一下我对混音算法的学习,大概有以下几种方式:1.直接加和2.加和后再除以混音通道数,防止溢出3.加和并箝位,如有溢出就设最大值4.饱和处理,接近最大值时进行扭曲5.归一化处理,全部乘个系数,使幅值归一化。
虚拟现实技术中的声音定位和环境音效原理(二)

虚拟现实技术中的声音定位和环境音效原理近年来,随着科技的不断发展,虚拟现实(VR)技术在各个领域得到了广泛应用。
虚拟现实能够模拟创造出一个虚拟的三维环境,使使用者沉浸其中,仿佛置身于现实世界中。
而声音定位和环境音效的实现,则是虚拟现实技术中一个重要而又复杂的方面。
虚拟现实中的声音定位,是指通过声音在虚拟环境中精确地定位物体或位置的技术。
一旦声音定位得当,虚拟现实的使用者便能够感受到声音的来源和位置,并对其做出相应的反应。
实现声音定位主要依靠两个关键要素:声音的时间差和声音的音量差。
首先,声音的时间差是声音定位的重要依据。
人耳通过分析声音到达左右耳朵的时间差,可以确定声音来源的方位。
虚拟现实技术中的声音定位也利用了这一原理。
通过在虚拟环境中设定声源列表,并使每个声源在不同时间点发出声音,系统可以通过检测声音到达使用者耳朵的时间差,来确定声源的位置。
利用高级算法和声音传播速度等参数,系统还可以计算出声源与使用者之间的距离,从而更准确地定位声源位置。
其次,声音的音量差也是声音定位的重要依据之一。
而这正是利用了人耳通过分析声音到达左右耳朵的音量差来判断声音来源的原理。
在虚拟环境中,声音源与耳朵之间的距离不同,声音到达耳朵的强度也会有所不同。
通过调整声源的音量,虚拟现实技术可以模拟不同距离的声音,让使用者有一种真实的听觉经验。
这种技术对于虚拟现实中的环境音效尤为重要,能够为使用者带来逼真而立体的听觉体验。
除了声音定位,环境音效在虚拟现实技术中也起着至关重要的作用。
环境音效是指通过声音模拟出特定环境的音效,让使用者完全感受到身临其境的效果。
环境音效在游戏、电影及工程模拟等领域被广泛应用,能够提升虚拟现实的沉浸感。
虚拟现实中的环境音效主要通过两个方面来实现。
首先,音源的定位是关键。
在虚拟环境中,声音来自于不同的方向,而使用者需要能准确地感知到它们的来源。
虚拟现实技术中,通过设定音源的方位和距离,并在计算机中建模,可以实现声音源的定位,进而为使用者带来真实的听觉感受。
虚拟现实技术中的声音定位和环境音效原理

虚拟现实技术中的声音定位和环境音效原理引言:随着科技的不断进步,虚拟现实(VR)技术正成为我们生活中越来越重要的一部分。
虚拟现实技术能够通过模拟环境提供沉浸式的体验,而声音是其中至关重要的一部分。
在虚拟现实世界中,声音定位和环境音效原理将用户带入逼真的虚拟体验中。
一、声音定位的重要性虚拟现实技术中的声音定位是指能够准确地定位声源并模拟声音的传播路径,使用户可以感知声音来自何处。
声音定位的准确性直接影响了用户在虚拟现实环境中的身临其境感。
通过准确的声音定位,用户可以感受到声音从左右、前后等不同方向传来,增强了虚拟现实的沉浸感。
二、声音定位的实现原理实现声音定位的一种常见方法是通过耳返(binaural)技术。
这种技术基于头部的耳朵和耳廓对声音的反射和吸收,模拟真实环境中声音传输的路径。
通过分析和模拟声波在耳廓和耳朵的反射特性,系统可以计算出声音在不同方向上到达用户耳朵的差异,从而实现声音的定位。
耳返技术使得虚拟现实中的声音可以栩栩如生地传送到用户的耳朵中,增强了沉浸感和真实感。
三、环境音效的重要性除了声音定位,环境音效也是虚拟现实体验中不可或缺的一部分。
环境音效是利用声音模拟各种环境中的声音特性,从而为用户创造出恰当的氛围和情境。
无论是在森林中、海滩上,或是在城市街道上,环境音效都能够模拟现实世界中的声音,使用户身临其境地感受到不同环境的氛围。
四、环境音效的实现原理环境音效的实现依赖于高级音频编码技术和音效处理。
通过在虚拟现实系统中集成高质量的音效库,系统可以根据用户所处的环境来播放相应的音效。
这些音效不仅包括自然环境中的声音,如风吹树叶、鸟鸣等,还包括背景环境中的声音,如车辆行驶的声音、人群嘈杂的声音等。
通过准确地模拟这些环境音效,虚拟现实系统能够为用户创造出逼真的环境体验,增强用户对虚拟世界的代入感。
五、虚拟现实技术中声音定位和环境音效的应用声音定位和环境音效的应用广泛存在于虚拟现实技术的各个领域。
虚拟低音算法的设计与实现

虚拟低音算法的设计与实现王红梅;刘华平【摘要】先介绍虚拟低音算法中最有代表性的两种算法,MaxxBass算法和EVB Phase Vocoder算法.并给出了基于VB Phase Vocoder方法设计的虚拟低音增强系统,并对虚拟低音增强结果进行对比分析.实验结果表明,该虚拟低音增强系统能产生较为浑厚饱满的低音增强效果.【期刊名称】《电声技术》【年(卷),期】2014(038)011【总页数】4页(P53-56)【关键词】虚拟低音;谐波;增强【作者】王红梅;刘华平【作者单位】浙江天格信息技术有限公司,浙江金华321000;上海大学通信与信息工程学院,上海200072【正文语种】中文【中图分类】TN912.351 引言随着移动互联网时代的到来,手持智能终端的普及率越来越高,各大手机厂商对系统易用性及多媒体表现方面也原来越重视。
在音频方面,手机厂商将好音质等作为推广重点也可以看出,消费者对于多媒体影音方面的要求越来越高。
但同时,智能终端如手机、平板计算机都趋向于纤薄和细小,受到体积尺寸的影响,在这些设备中无法防止尺寸过大的扬声器。
所以,从传统意义上做硬件改进比如增大扬声器尺寸改进材料以及腔体结构已经没有太多提升的空间。
较小的扬声器口径通常其低频谐振频率较高低频放音能力差,也就是低音表现不足。
消费者对高品质音乐的追求和小扬声器低音表现力差的矛盾成为了急需改进的问题。
对于该问题,目前多采用均衡器的方法来解决。
但简单地通过均衡器提高低频能量容易产生信号畸变,并降低扬声器的使用寿命。
而利用虚拟低音增强技术实现的低音增强,则避免了上述问题。
其中,虚拟低音增强方案最有代表性的两个方案分别为 MaxxBass[1]算法和 VB Phase Vocoder算法。
后续章节将分别介绍这两种方法,并给出基于VB Phase Vocoder[2]方法设计的虚拟低音增强系统,并对虚拟低音增强结果进行对比分析。
2 虚拟低音原理虚拟低音来源于一种被称为“虚拟音调[3]”的现象。
设计虚拟现实场景音效的最佳实践

设计虚拟现实场景音效的最佳实践虚拟现实(Virtual Reality,VR)技术正越来越广泛地应用于游戏、培训、教育和医疗等领域。
作为一种全方位的体验,虚拟现实需要音效来打造逼真的环境和身临其境的感觉。
设计虚拟现实场景音效需要考虑多个关键因素,如声音的定位、环境音和互交效果等。
本文将介绍一些设计虚拟现实场景音效的最佳实践。
首先,准确的声音定位是设计虚拟现实场景音效的关键。
虚拟现实的目标是创造出身临其境的感觉,因此声音的定位应该能够准确地反映真实世界的定位。
对于头戴式虚拟现实设备的用户来说,通过耳机传递立体声音效是最常见的方式。
为了实现准确的声音定位,设计师可以使用三维声场建模技术,通过确定声源和听者的位置,计算出声音传播的路径和效果。
此外,考虑用户的头部运动也是重要的,例如头部跟踪技术可以实现根据用户头部的旋转来改变声音的定位。
其次,逼真的环境音效可以增强虚拟现实场景的真实感。
环境音效包括周围的环境声音,如风声、鸟鸣、车辆声等,以及场景内的共鸣和反射声。
环境音效可以通过录制真实世界的声音,或者使用合成技术进行创作。
对于复杂的场景,使用多轨音频编辑软件可以将不同的音效层叠加在一起,以营造更加真实的感觉。
此外,虚拟现实体验常常需要模拟不同的环境,设计师可以根据场景的需求选择合适的环境音效。
再次,互动效果是设计虚拟现实场景音效的重要组成部分。
互动效果可以增加用户的参与感和沉浸感。
例如,当用户触摸一个物体时,可通过触摸声音来模拟真实的触感反馈。
此外,根据用户的行为和动作,可以动态地改变音效的参数和逻辑。
例如,当用户进入一个废弃的建筑物时,可以通过音效传达出阴森、恐怖的感觉。
为了实现互动效果,设计师可以使用虚拟现实平台提供的交互接口和编程语言,与场景中的物体进行交互,并控制音效的变化。
另外,设计虚拟现实场景音效需要考虑用户的舒适度。
音效的响度和频率范围应该在用户的耐受接受范围内,并且要避免过于刺耳或刺激的声音。
虚拟低音技术方案

目录1.简介 (2)1.1.背景 (2)1.2.项目的目的和意义 (3)2.技术方案(如何实现) (3)2.1.项目研究的内容 (3)2.2.项目实现的技术方案 (3)3.功能与技术指标 (4)3.1.功能 (4)3.2.技术指标 (4)4.项目实施的进度与计划 (5)虚拟低音技术方案1.简介1.1.背景音频是多媒体设备的重要部分,没有好的声音,再好的图像,再多的应用的多媒体设备也是有缺陷的。
然而随着目前多媒体设备,当前手持设备及其他消费电子设备中,由于体积和外形的要求,作为发声的喇叭尺寸受到了极大限制。
尺寸的限制造成了喇叭谐振频率较高,因此不可能辐射出低于其谐振频率的信号分量,导致音频部分低音的缺失,无法给消费者提供更高要求的享受。
目前传统的播放重低音的方法有:1、低音炮音箱。
缺点:成本高,功率低,无法集成到日益轻薄要求的平板电视。
2、提高低音补偿。
缺点:效率低,效果也比较有限,失真比较大。
3、功率补偿滤波器。
缺点:效率低,效果也比较有限,失真比较大。
因此我们需要采用一种更好的,更低成本的方法来重放低音。
虚拟低音完全可以满足这个要求。
虚拟低音的原理就是利用“消失的基频”现象,通过低音信号基频的谐波序列在人耳中再现普通扬声器无法达到的低频音调。
在听感上就会让人觉得低音分量更足了,有效弥补了小口径扬声器重放低频不足的问题。
这里采用了人耳的生理学特点来虚拟低音,人耳能够把低音基频的高频段谐波的差频声音听成原来低音基频的音调,这就给我们实现虚拟低音提供了理论基础。
市场上厂商技术现状:1.国内的品牌在数字音效处理上主要采用DTS,SRS,杜比等国外专业音频厂商的技术,在采用他们的技术时,需要昂贵的技术授权费用。
2.国外品牌:一般都有自己专利的音频处理技术。
3.虚拟低音的厂商技术现状,出名的主要有以下几个厂商提供的产品,这几家厂商一般都提供专门的芯片,价格高,增加比较大的成本。
SRS的TruBass;Philips的UltraBass;Maxx的MaxxBass;1.2.项目的目的和意义目前国内基本还没有厂商从事这一块的研究,而研究院作为TCL核心的研究机构,对与开展音频方面的研究是很有必要的。
音频均衡器和音频虚拟器的设计与优化

音频均衡器和音频虚拟器的设计与优化音频均衡器和音频虚拟器是音频处理领域中常见并且重要的工具,它们能够对音频信号进行调整、优化,以获得更好的音质和音效效果。
在本文中,我们将探讨音频均衡器和音频虚拟器的设计原理及优化方法。
一、音频均衡器的设计与优化音频均衡器是一种调整音频频谱平衡的工具,它能够调整不同频段的音量,以改善音频质量。
其设计原理依据于人耳对不同频段声音敏感度的差异,通过增益调整不同频段的音量,使得整体音频呈现均衡的频谱。
1.设计原理音频均衡器通常采用滤波器的方式实现,不同频段可以采用不同的滤波器类型,如低通滤波器、高通滤波器、带通滤波器等。
通过调整滤波器的增益,可以改变该频段的音量大小。
2.优化方法优化音频均衡器的关键在于找到合适的频段划分和增益设置。
一般来说,常用的频段划分包括低频、中频和高频,但具体的划分可以根据不同的音频特性进行调整。
另外,增益的设置需要根据实际需求和音频内容进行调整。
不同音频内容可能需要不同的增益设置,例如对于音乐来说,可以适当增强低频和高频以突出节奏感和明亮度;对于人声来说,可以适当增强中频以提高清晰度和可懂性。
二、音频虚拟器的设计与优化音频虚拟器是一种模拟环境声音的工具,它能够通过音频处理算法将音频信号变换为具有空间感的效果,使听者感受到立体、真实的音响效果。
其设计原理依据于人耳对声音定位和环境效果的感知。
1.设计原理音频虚拟器的设计原理包括了声音定位和混响效果两个方面。
声音定位是通过模拟人耳对声源方向的感知,通常采用声像定位算法实现,将声音源的位置和方向信息编码到音频信号中。
混响效果是通过模拟不同环境中的声音反射和衰减产生的,常用的混响算法包括各向同性模型和波场模型等。
2.优化方法音频虚拟器的优化方法主要包括声音定位和混响效果的调整。
对于声音定位,一个有效的优化方法是通过调整声音源在立体声场中的位置和角度,以达到更准确的声音定位效果。
同时,还可以考虑加入距离和远近感等因素,使得听者能够更真实地感受到声音的位置和距离。
滑动窗口FFT实时频域虚拟低音增强算法

输入 HPF
延时
+ 输出
LPF
谐波产生
能量控制
图 1 虚拟低音增强算法原理框图
首先,输入到系统中的原始音频信号分成两路,一路经 过高通滤波器保留其高频部分;另一路经过低通滤波器取 出其低频部分,分析出低于扬声器截止频率的基频部分,通 过谐波产生系统产生高次谐波,能量控制单元实现响度控 制。最后,将处理好的谐波和高通保留的高频信息合成后输 出。低音增强算法中最重要的部分就是谐波产生系统。
0 100 200 300 400 500 600 700 800 f/Hz
图 5 增强前后信号频谱图
动窗口 FFT 实时频域虚拟低音增强算法基于信号的频域信
息直接确定音频信号的基频频率,再通过变调方式产生高次
谐波,具有交调失真小、精确控制谐波数量和能量优点;同时
采用滑动窗技术,将样点实时处理转换为一段时间的窗口实
35 35
30
25
30
20
25
15
20
10 15
5
0
10
50 100 150 200 250
50 100 150 200 250 300 350
基频 f/Hz
谐波 f/Hz
图 4 频域变调生成谐波频谱图
所以本文采用这种方法产生谐波。选取《渡口》中低音
丰富的一段音乐信号,按照 TP4 的比例生成 2-5 次谐波[7],
2 频域虚拟低音增强算法 频域虚拟低音增强算法主要利用音频信号的频域信 息确定基频频率,再利用变调方式产生高次谐波,从而避 免了非线性畸变。设输入信号经过低通滤波单元后取出低 于扬声器截止频率的低频信号 x(n),n=0,1,2,…N,为信 号长度。设窗函数为矩形窗,则截取 N 点后低频信号的傅 里叶变换(FFT)为: Xn(k)=移Nn=-01 x(n)W-Nnk = Xn(k) ej渍(n,k),k=0,1,2,…N-1(1)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
虚拟低音的实现原理及验证方案
虚拟低音的实现原理及验证方案背景和理论原理:
在当前手持设备或其他消费电子设备中,由于体积和外形的要求,作为发声的喇叭尺寸受到了极大限制,尺寸的限制造成了喇叭对于低音部分无法响应.造成音频部分低音的缺失,无法给消费者提供更高要求的享受.
在人耳的研究中发现,人可以对两个高音的差频产生响应,给了听觉上造成低音的感觉,这就是所谓的虚拟低音.
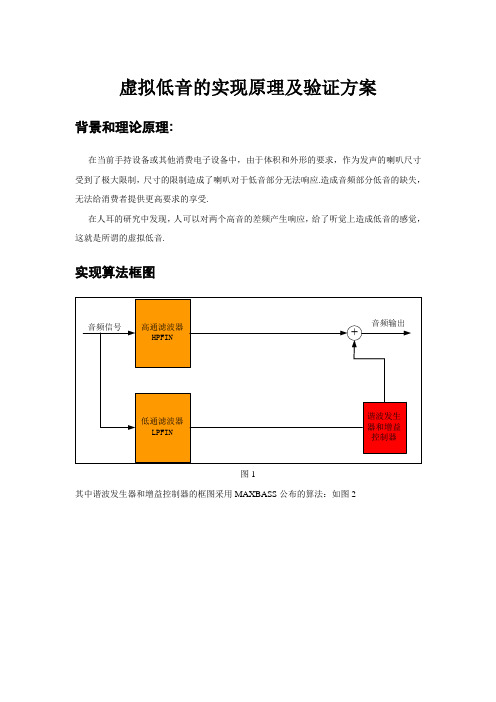
实现算法框图
音频输出高通滤波器音频信号+HPFIN
谐波发生低通滤波器器和增益LPFIN控制器
图1
其中谐波发生器和增益控制器的框图采用MAXBASS公布的算法:如图2
高通滤波器截止谐波输出频率为扬声器截LPFS IN*+止频率100
HPFOUT
1 sample delay包络检测
A(n)高通滤波器截止
频率f1*增益计算G=0.3HPF-FB
图2 A^k(n)
这里我们可以看出我们需要做的就是:
, 提取低音信号和高音信号,需要设计一个高通和低通滤波器,低通滤波器来提取低音信
号,高通滤波器来提取高音信号,低通滤波器的截止频率为扬声器的截止频率,在demo
的时候我们做成固定的100HZ.
, 谐波发生器.
, 混频器.
滤波器
滤波器我们采用matlab的FDATOOL工具来实现,然后可以根据工具生成的系数,根据滤波器的结构采用matlab语言自己编写.滤波器可以看见的总共有4个,输入高低滤波的滤波器HPF-IN和LPF-IN,这两个滤波器的功率互补的.
HPF-OUT和HPF-IN是一样的.
HPF-FB是反馈回路高通滤波器.
上图可知,上面提到的4个滤波器的截止频率都是可调的.这里需要注意. 一开始我们可以做成频率固定的,因为我们可能并不会做成IC的形式,因此可以在软件中随时调整截止频率.
自动幅度控制模块:
上图为等响度曲线图,我们可以看出不同的频率,相同的升压变化造成的响度变化是不同的.这里我们定义声压-响度扩展比率,即升压变化/响度变化的值R.
在频率为20~700hz,响度为20-80方内:R的值可以近似为:
保持谐波响度对声压级的动态特性于基频处一致对于还原虚拟低音的响度和音色十分重要. RR(f,n)定义如下.
从上式看出,RR(f,n)和ln(n)及R(f)成正比.而f又同R(f)基本成反比.
根据定义得知,我们需要谐波的幅度和基波幅度的比值应该为RR(f,n)
Enf=Ef*RR(f,n);
而经过混频器后,谐波输出的幅度并不能满足上述条件.需要乘上一个系数H,
很明显这个系数和谐波次数和基频频率相关,这将引入计算和实现的复杂度,在这
里我们需要简化. 我们知道,声强主要有主谐波决定,通过计算我们得出系数近似
H=A0^K;K大概为0.64.A0是输入信号的幅度.
A0^K次我们可以采用拟合函数拟合.
包络检测:
包络检测我们可以用滤波器的方法,也可以用普通的包络检测算法. 这里我们
采用普通的包络检测算法,包络这里其实就是峰值检测,算法如下: 当
|x(n)|<xpeak(n-1)时:
当|x(n)|>xpeak(n-1)
其中:
这里ta,tr是两个时间常数,分别含义是跟进峰值时间,和峰值释放时间,
这里我们可以设置ta=0.2ms,tr=200ms.单位为毫秒ms.ts是采样时间.单位为秒s.
混音算法
高音和低音的谐波相加,这里应该需要混音的算法,目前混音的算法有线性相
加等算法,我们到时可以根据效果采用一个.
总结一下我对混音算法的学习,大概有以下几种方式:
1.直接加和
2.加和后再除以混音通道数,防止溢出
3.加和并箝位,如有溢出就设最大值
4.饱和处理,接近最大值时进行扭曲
5.归一化处理,全部乘个系数,使幅值归一化。
(只适用于文件)
6.衰减因子法,用衰减因子限制幅值。
具体采用那种方法,我们可以到时根据效果来调整.
难度分析:
从上面看,我们目前的难度主要在滤波器的设计,尤其是功率互补的两个滤波器的设计,我们在这方面并没有经验,滤波器的设计需要很扎实的信号处理,数学等基础,而这方面一般都是工程人员的弱项,需要学习,查阅一些书籍,资料来加强.
这几个滤波器要在满足性能的同时,尽量减少阶数,以便易于实现,做到实时在DSP等
器件里完成.最好一般不要超过6阶.
具体实施:
1. 首先我们选取一段音频,最好有比较丰富的低音的.音乐时间可以在10秒以内.直接在提
取其中一个声道.而且低音基音频率是不变的.
2. 提取基音部分模块
3. 谐波生成部分模块.
4. 先用matlab来仿真.直接在电脑仿真以及耳机输出那边听效果.
工作分工
1.邓益群:
2.魏乃科:
3.施建华:
4.多媒体声所: 协助测试及参数调整.
时间表
时间施建华邓益群,濮怡颖魏乃科 7.11~7.22 学习阅读技术文章,学习阅读技术文章,学习阅读技术文章,
了解音频技术,信号了解音频技术,信号了解音频技术,信号
处理技术.撰写基本处理技术. 处理技术.
的虚拟低音的基本原
理框图和初步开发计
划
7.25~8.05 寻找一段5秒钟左右1.输入功率互补滤波谐波生成:
的音频.特点:低音比器设计. 包括 1.环路,
较丰富,低音的基频 2.包络检测不变.建立一个可以3.混音器设计测试的平台,从电脑
输出到耳机或传统多
媒体音响.
协助魏乃科和邓益群
工作.
8.08~ 根据前期工作的结果根据前期工作的结果根据前期工作的结果待定待定待定。