统计学术语及符号
《统计学》名词解释及公式

第1章统计与统计数据一、学习指导统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。
本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用的一些基本概念。
本章各节的主要内容和学习要点如下表所示。
二、主要术语1. 统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。
2. 描述统计:研究数据收集、处理和描述的统计学分支。
3. 推断统计:研究如何利用样本数据来推断总体特征的统计学分支。
4. 分类数据:只能归于某一类别的非数字型数据。
5. 顺序数据:只能归于某一有序类别的非数字型数据。
6. 数值型数据:按数字尺度测量的观察值。
7. 观测数据:通过调查或观测而收集到的数据。
8. 实验数据:在实验中控制实验对象而收集到的数据。
9. 截面数据:在相同或近似相同的时间点上收集的数据。
10. 时间序列数据:在不同时间上收集到的数据。
11. 抽样调查:从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体特征的数据收集方法。
12. 普查:为特定目的而专门组织的全面调查。
13. 总体:包含所研究的全部个体(数据)的集合。
14. 样本:从总体中抽取的一部分元素的集合。
15. 样本容量:也称样本量,是构成样本的元素数目。
16. 参数:用来描述总体特征的概括性数字度量。
17. 统计量:用来描述样本特征的概括性数字度量。
18. 变量:说明现象某种特征的概念。
19. 分类变量:说明事物类别的一个名称。
20. 顺序变量:说明事物有序类别的一个名称。
21. 数值型变量:说明事物数字特征的一个名称。
22. 离散型变量:只能取可数值的变量。
23. 连续型变量:可以在一个或多个区间中取任何值的变量。
四、习题答案1. D2. D3. A4. B5. A6. D7. C8. B9. A10.A11.C、12.C13.B14.A15.C16.D17.C18.A19.C20.D21.A22.C23.C24.B25.D26.C27.B28.D29.A30.D31.A32.B33.C34.A35.A36.A37.D38.B39.B40.C41.C42.D43.C44.D45.A46.B47.C48.A49.C50.D51.A52.C53.D54.A55.B第2章数据的图表展示一、学习指导数据的图表展示是应用统计的基本技能。
经济学符号

经济学符号
经济学符号是一种表示物理和经济变量的符号。
它们可以帮助经济学家、政策制定者和学者们理解经济系统中各种变量之间的关系及它们所处环境的变化。
经济学符号的分类很多,具体包括统计学符号、经济学理论符号、政治经济学符号等等。
一、统计学符号
1)Δ 代表差异或变化;
2)σ 代表总体标准差;
3)S 标志总体取样的样本数量;
4)α 代表属性间信息熵;
5)β 代表变动项系数;
6)η 代表单位根回归残差;
7)θ 代表斜率;
8)ϩ代表正相关关系;
10)∽ 代表条件概率密度函数。
1)C 代表消费支出;
2)Y 代表国民总收入;
3)R 代表价格指数;
4)V 代表投资;
8)M 代表货币流入量;
9)P 代表物价水平;
10)E 代表效率工资。
3)D 代表贷款;
5)B 代表国际余额;
6)R 代表通货膨胀率;
7)F 代表财政项目;
8)A 代表金融协定;
9)X 代表外部贸易收入;
10)Y 代表国际政策。
总而言之,经济学符号是一个相当独特的概念,它们不仅可以帮助经济学家们识别经济中存在的变量,而且可以帮助他们以更加客观、可量化的方式解释经济模型,从而获得经济分析和政策研究所需要的参考价值。
常用统计术语

常用统计术语一、总体与样本在统计学中,总体是指研究对象的全体,样本是指从总体中选取的一部分个体。
总体的特征称为参数,样本的特征称为统计量。
总体参数常用符号表示,如总体均值用μ表示,总体方差用σ²表示。
二、抽样与抽样误差抽样是指从总体中选取样本的过程,目的是通过样本推断总体的特征。
抽样误差是指由于样本的随机性导致的样本统计量与总体参数之间的差异。
三、描述统计与推断统计描述统计是对收集到的数据进行整理、总结和描绘的过程,常用的描述统计指标有平均数、中位数、标准差等。
推断统计是根据样本数据对总体进行推断的过程,通过样本推断总体的特征。
四、频数与频率频数是某个数值在数据中出现的次数,频率是某个数值在数据中出现的相对比例。
频率可以通过频数除以总样本量得到,通常以百分数或小数形式表示。
五、参数估计与假设检验参数估计是通过样本数据对总体参数进行估计的过程,常用的参数估计方法有点估计和区间估计。
假设检验是根据样本数据对总体参数进行推断的过程,常用的假设检验方法有单样本检验、双样本检验等。
六、相关与回归相关分析是研究两个或多个变量之间关系的统计方法,常用的相关系数有皮尔逊相关系数、斯皮尔曼相关系数等。
回归分析是研究自变量与因变量之间关系的统计方法,常用的回归模型有线性回归、多项式回归等。
七、方差分析与卡方检验方差分析是用于比较两个或多个样本均值之间差异的统计方法,常用的方差分析方法有单因素方差分析、多因素方差分析等。
卡方检验是用于比较观察频数与期望频数之间差异的统计方法,常用的卡方检验有卡方拟合优度检验、卡方独立性检验等。
八、正态分布与偏态分布正态分布是一种对称的连续概率分布,符合正态分布的数据呈钟形分布,均值、中位数和众数相等。
偏态分布是一种不对称的概率分布,偏态分布的数据在均值两侧的分布不对称。
九、标准化与归一化标准化是将数据按照一定的比例进行缩放,使得数据具有相同的尺度,常用的标准化方法有Z-score标准化、Min-Max标准化等。
统计学里的符号与缩写
1
Px 第x百分位数P 样本率
R 极差;样本复相关系数;
x2检验中的行数
r 样本相关系数
RR 相对危险度s 样本标准差
S2 样本方差sb 样本回归系数的标准误S02 合并样本方差sd (样本)差值的标准差
s-d (样本)差值均数的标
准误
sp 样本率的标准误
Sp1-p2 两样本率差的标准误sX 样本均数的标准误SD 标准差SE 标准误
T
X2检验的理论频数;
Wilcoxon秩和检验的统
计量
t t检验的统计量
u 标准正态变量;标准正
态(离)差;u检验的
统计量
X
变量;变量值,观察值;回归中
的自变量
x X变换后的变量或变量
值
Xi
变量X的第i个观察值;第i个
变量
XO 假定均数X 样本均数
Y 变量;变量值,观察值;
回归中的应(因)变量
y Y变换后的变量或变量值
Y 样本均数
符号名称符号名称
α检验水准,显著性水准;第一
类错误的概率
1-α可信度,置信度
β第二类错误的概率;总体回归
系数
1-β检验效能,把握度
ν(n´)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2总体方差χ2χ2检验的统计量
3。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
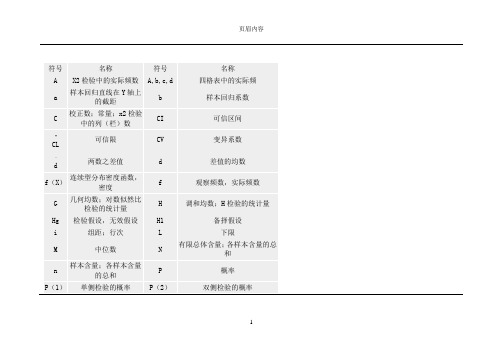
拉丁字母假定均数X样本均数YY变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2总体方差χ2χ2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d四格表中的实际频a样本回归直线在Y轴上的截距b样本回归系数C校正数;常量;x2检验中的列(栏)数CI可信区间--------------------------------------------------------------------------------CL可信限CV变异系数--------------------------------------------------------------------------------d两数之差值d差值的均数f(X)连续型分布密度函数,密度f观察频数,实际频数G几何均数;对数似然比检验的统计量H调和均数;H检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L下限M中位数N有限总体含量;各样本含量的总和n样本含量;各样本含量的总和P概率P(1)单侧检验的概率P(2)双侧检验的概率Px第x百分位数P样本率R极差;样本复相关系数;x2检验中的行数r样本相关系数RR相对危险度s样本标准差S2样本方差sb样本回归系数的标准误S02合并样本方差sd(样本)差值的标准差s-d(样本)差值均数的标准误sp样本率的标准误Sp1-p2两样本率差的标准误sX样本均数的标准误SD标准差SE标准误T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量u标准正态变量;标准正态(离)差;u检验的统计量X变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值Xi变量X的第i个观察值;第i个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 Ααalpha a:lf 阿尔法2 Ββbeta bet 贝塔3 Γγgamma ga:m 伽马4 Δδdelta delt 德尔塔5 Εεepsilon ep`silon 伊普西龙6 Ζζzeta zat 截塔7 Ηηeta eit 艾塔8 Θθthet θit 西塔9 Ιιiot aiot 约塔10 Κκkappa kap 卡帕11 ∧λlambda lambd 兰布达12 Μμmu mju 缪13 Ννnu nju 纽14 Ξξxi ksi 克西15 Οοomicron omik`ron 奥密克戎16 ∏πpi pai 派17 Ρρrho rou 肉18 ∑σsigma `sigma 西格马19 Ττtau tau 套20 Υυupsilon jup`silon 宇普西龙21 Φφphi fai 佛爱22 Χχchi phai 西23 Ψψpsi psai 普西24 Ωωomega o`miga 欧米伽δ(德尔塔)ε(艾普西龙)。
统计学知识点(完整)

根本统计方法第一章 概论1. 总体〔Population 〕:根据研究目确实定的同质对象的全体〔集合〕;样本〔Sample 〕:从总体中随机抽取的局部具有代表性的研究对象。
2. 参数〔Parameter 〕:反映总体特征的统计指标,如总体均数、标准差等,用希腊字母表示,是固定的常数;统计量〔Statistic 〕:反映样本特征的统计指标,如样本均数、标准差等,采用拉丁字字母表示,是在参数附近波动的随机变量。
3. 统计资料分类:定量〔计量〕资料、定性〔计数〕资料、等级资料。
第二章 计量资料统计描述1. 集中趋势:均数〔算术、几何〕、中位数、众数2. 离散趋势:极差、四分位间距〔QR =P 75-P 25〕、标准差〔或方差〕、变异系数〔CV 〕3. 正态分布特征:①X 轴上方关于X =μ对称的钟形曲线;②X =μ时,f(X)取得最大值;③有两个参数,位置参数μ和形态参数σ;④曲线下面积为1,区间μ±σ的面积为68.27%,区间μ±1.96σ的面积为95.00%,区间μ±2.58σ的面积为99.00%。
4. 医学参考值范围的制定方法:正态近似法:/2X u S α±;百分位数法:P 2.5-P 97.5。
第三章 总体均数估计和假设检验1. 抽样误差〔Sampling Error 〕:由个体变异产生、随机抽样造成的样本统计量与总体参数的差异。
抽样误差不可防止,产生的根本原因是生物个体的变异性。
2. 均数的标准误〔Standard error of Mean, SEM 〕:样本均数的标准差,计算公式:/X σσ=3. 降低抽样误差的途径有:①通过增加样本含量n ;②通过设计减少S 。
4. t 分布特征:①单峰分布,以0为中心,左右对称;②形态取决于自由度ν,ν越小,t 值越分散,t 分布的峰部越矮而尾部翘得越高;③当ν逼近∞,X S 逼近X σ, t 分布逼近u 分布,故标准正态分布是t 分布的特例。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x ( 中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t 检验用英文小写t;(5) F 检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P 值前应给出具体检验值,如t 值、字2值、q 值等) 。
以上符号均用斜体。
拉丁字母假定均数X 样本均数YY 变量;变量值,观察值;回归中的应(因)变量y Y 变换后的变量或变量值Y 样本均数希腊字母符号名称符号名称a 检验水准,显著性水准;第一类错误的概率1- a 可信度,置信度B 第二类错误的概率;总体回归系数1- B 检验效能,把握度v(n') 自由度n 总体率卩总体均数p 总体相关系数艺求和的符号(T 总体标准差(T 2 总体方差x 2 x 2检验的统计量符号名称符号名称A X2 检验中的实际频数A,b,c,d 四格表中的实际频a 样本回归直线在丫轴上的截距b 样本回归系数C 校正数;常量;x2 检验中的列(栏)数CI 可信区间CL 可信限CV 变异系数d 两数之差值d 差值的均数f ( X) 连续型分布密度函数,密度f 观察频数,实际频数G 几何均数;对数似然比检验的统计量H 调和均数;H 检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L 下限各样本含量的总和M中位数N 有限总体含量;n样本含量;各样本含量的总和P 概率P(1)单侧检验的概率P (2)双侧检验的概率Px 第x 百分位数P 样本率R 极差;样本复相关系数;x2 检验中的行数r 样本相关系数RR 相对危险度s 样本标准差S2 样本方差sb 样本回归系数的标准误S02 合并样本方差sd (样本)差值的标准差s-d (样本)差值均数的标准误sp 样本率的标准误Sp1-p2 两样本率差的标准误sX 样本均数的标准误SD 标准差SE 标准误T X2 检验的理论频数;Wilcoxon 秩和检验的统计量t t 检验的统计量u 标准正态变量;标准正态(离)差;u 检验的统计量X 变量;变量值,观察值;回归中的自变量x X 变换后的变量或变量值Xi 变量X 的第i 个观察值;第i 个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 A a alpha a:lf 阿尔法2 B B beta bet 贝塔3 r Y gamma ga:m 伽马4 A S delta delt 德尔塔5 E e epsilon ep'silon 伊普西龙6 Z Z zeta zat 截塔7 H n eta eit 艾塔8 0 0 thet 0 it 西塔9 I i iot aiot 约塔10 K K kappa kap 卡帕11 A 入lambda lambd 兰布达12 M 卩mu mju 缪13 N v nu nju 纽14 S E xi ksi 克西15 O o omicron omik'ron 奥密克戎16 n n pi pai 派17 P p rho rou 肉18 刀c sigma 'sigma 西格马19 T T tau tau 套20 Y u upsilon jup'silon 宇普西龙21①© phi fai 佛爱22 X x chi phai 西23 W psi psai 普西24 Q 3 omega o'miga 欧米伽3(德尔塔)£ (艾普西龙)欢迎您的下载,资料仅供参考!致力为企业和个人提供合同协议,策划案计划书,学习资料等等打造全网一站式需求。
关于统计学符号及统计结果的表述

关于统计学符号及统计结果的表述统计学符号是专门用于统计表达及其结果的一种通用语言,可以有效地传达统计学概念和数据的 E 。
一般而言,大多数的统计学符号是由一个或多个字母、数字、箭头和斜杠组成的。
统计学符号的用途:统计学符号可以用来表达统计学概念、建模数据、描述属性、建立运算公式以及展示结果。
统计学符号的说明:一般来说,统计学符号通常被用来描述总体数据,以及它们之间的相互关系和特性(比如均值、方差、离散度等)。
统计学常用变量记号:1.均值(平均数):用μ(μ)来表示。
2.比值:用P来表示。
3.标准差:用σ(sigma)表示。
4. 极差:用D表示。
5. 计数:用N表示。
6. 概率:用符号P表示。
7. 成功率:用符号R表示。
8. 方差:用σ2(sigma的平方)表示。
9. 算术平均数:用A(arithmetic mean)来表示。
10. 方差均等比例:用Y表示。
11. 成绩:用X表示。
12. 中位数:用M(median)来表示。
13. 标准差/均数:用S表示。
14. 偏度度量:用G表示。
15. 全有效率:用V表示。
16. t分布值:用t来表示。
17. 决策界限值:用L表示。
统计结果的表述:1. 统计结果的表述是使用统计数据、描述性统计和推断统计技术对主题进行描述的,概括了它的特征。
2. 对于名义变量,可以使用频率、比例和比率统计表达,它们可以有助于我们了解统计分布。
3. 对于度量变量,可以使用中心趋势及其方差描述它们,这包括均值、中位数、众数、标准差、变异系数等。
4. 回归分析后可以通过R方值/决定系数来衡量线性关系的程度,以及通过t值/p值来判断零假设是否拒绝。
5. 分组比较可以使用t检验、卡方检验、F检验等表达方法来衡量它们之间的统计学差异,也可以使用独立样本t检验来衡量它们的差异。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学术语及符号统计学术语population 母体sample样本cen sus普查sampling 抽样quantitative 量的qualitative/categoric al 质的discrete离散的continuous 连续的populati on parameters 母体参数sample statistics 样本统计量descriptive statistics叙述统计学inferen tial/in ductive statistics 推论...抽样调查(samplii ng survey 单纯随机抽样( simple ran dom sampli ng系统抽样(systematic sampli ng分层抽样(stratified sampli ng 整群抽样(clustersampli ng多级抽样(multistage sampli ng常态分配(Parametric Statistics) 无母数统计学(Non parametric Statistics)实验设计(Design of Experime nt)参数(Parameter)Statistics 统计学Population 母体Sample样本Data analysis 资料分析Statistical table 统计表Statistical chart 统计图Pie chart圆饼图Stem-a nd-leaf display 茎叶图Box plot盒须图Histogram 直方图Bar Chart 长条图Polygon 次数多边图Ogive肩形图Descriptivestatistics叙述统计学Expectation 期望值Mode众数Mean平均数Varianee变异数Sta ndard deviation 标准差Sta ndard error 标准误Covaria nee matrix共变异数矩阵Inferen tial statistics推论统计学Point estimation 点估计Interval estimation 区间估计Con fide nee interval信赖区间Con fide nee coefficient信赖系数Test ingstatistic alhypothesis 统计假设检定Regressi on analysis回归分析An alysis of varianee 变异数分析Correlati on eoeffieient相关系数Sampling survey 抽样调查Cen sus普查Sampling 抽样Reliability 信度Validity 效度Sampli ng error 抽样误差Non-sampli ng error非抽样误差Ran dom sampli ng 随机抽样Simple ran domsampling简单随机抽样法Stratifi ed sampling分层抽样法Cluster sampling 群集抽样法Systematic sampling系统抽样法Two-stage random sampling 两段随机抽样法Convenience sampling 便利抽样Quota sampling 配额抽样Sno wball sampling 雪球抽样Non parametric statistics 无母数统计The sign test 等级检定Wilcox on sig nedrank tests魏克森讯号连续均匀密度等级检定Normal den sities Wilcox on rank 常态密度sum tests魏克森等级和检定Run test连检定法Discrete uniform densities离散的均匀密度Bin omial den sities 二项密度Hypergeometric den sities超几何密度Poisson densities 卜松密度Geometric den sities几何密度Negative bino mial densities负二项密度Con ti nu ous uniform den sitiesExp onential den sities指数密度Gamma densities 伽玛密度Beta densities 贝他密度Multivariat e analysis多变量分析Prin cipal components 主因子分析Discrimi natio n analysis区别分析Cluster analysis 群集分析Factor an alysis 因素分析Survival analysis 存活分析Time series Statisticsanalysis 时间序列分析Lin ear models 线性模式Quality engineering 品质工程Probability theory机率论Statistic al computing 统计计算Statistic al inference 统计推论Stochasti c processes随机过程Decision theory 决策理论Discreteanalysis 离散分析Mathematical statistics数理统计统计学: 母体:Population样本:Sample 资料分析:Dataan alysis统计表:Statistical table统计图:Statistical chart 圆饼图:Pie chart茎叶图:Stem-a nd-leaf display 盒须图:Box plot直方图:Histogram长条图:Bar Chart次数多边图:Polyg on肩形图:Ogive 叙述统计学:Descriptive statistics Con fide nee coefficie nt期望值: 统计假设检定: Expectati on Testi ngstatistic 众数:Mode hypothesis平均数:Mean 回归分析:变异数:Regressi on an alysis Varia nee 变异数分析: 标准差: An alysis of varia nce Stan dard deviati on 相关系数: 标准误:Correlati on coefficientSta ndard error共变异数矩阵:抽样调查:Covariance matrix Sampli ng survey推论统计学:普查:Census Inferen tial statistics 抽样:Sampling 点估计:Point 信度:Reliability estimati on 效度:Validity 区间估计:抽样误差: In terval estimati on Sampli ng error信赖区间:非抽样误差:Con fide nce in terval Non-sampli ng error信赖系数: 随机抽样: Random sampling 等级检定:The简单随机抽样法:sign testSimple ran dom 魏克森讯号等级sampli ng分层抽样法Stratified sampli ng群集抽样法Cluster sampli ng系统抽样法Systematic sampli ng 两段随机抽样法Two-stage ran dom sampli ng便利抽样Convenience sampli ng 配额抽样:Quota sampli ng雪球抽样Sno wball sampli ng 无母数统计Non parametric statistics检定: Wilcox on sig ned rank tests魏克森等级和检定: Wilcox on rank sum tests连检定法:Run test离散的均匀密度Discrete un iform den sities二项密度:Bin omial den sities超几何密度: Hypergeometricden sities卜松密度: Poiss on den sities几何密度: Geometric densities负二项密度:Negative bino mialden sitie,连续均匀密度:Con ti nu ousuniform den sities常态密度:Normal den sities指数密度:Exp onen tial den sities伽玛密度:Gamma den sities贝他密度:Beta den sities多变量分析:Multivariate an alysis 主因子分析:Prin cipal comp onents区别分析:Discrimi natio nan alysis群集分析Cluster an alysis因素分析Factor an alysis存活分析Survival an alysis 时间序列分析Time series an alysis线性模式Lin ear models品质工程Quality engin eeri ng机率论Probability theory统计计算Statistical comput ing统计推论Statistical inference随机过程Stochastic processes决策理论Decisi on theory离散分析:Discrete an alysis数理统计:Mathematicalstatistics统计名词市调辞典众数(Mode)普查(cen sus)指数(Index)问卷(Questi onn aire) 中位数(Median) 信度(Reliability)百分比(Percentage)母群体(Populati on)信赖水准(Con fide nee level)观察法(Observational Survey)假设检定(Hypothesis Test ing) 综合法(Integrated Survey)卡方检定(Chi-square Test) 雪球抽样(Sno wball Sampli ng)差距量表(Interval Scale) 序列偏差(Series Bias)类别量表(Nom in al Scale)次级资料(Sec on dary Data)顺序量表(Ordinal Scale)抽样架构(Sampli ng frame) 比率量表(Ratio Scale)集群抽样(Cluster Sampli ng) 连检定法(Run Test)便利抽样(ConvenienceSampli ng)符号检定(Sign Test)抽样调查(Sampli ng Sur)算术平均数(Arithmetic Mean)非抽样误差(non-sampli ng error)展示会法(Display Survey)调查名词准确效度(Criteri on-Related Validity)元素(Element) 邮寄问卷法(Mail In terview)样本(Sample)信抽样误差(Sampling error) 效度(Validity)封闭式问题(CloseQuesti on)精确度(Precision) 电话访问法(TelephoneIn terview)准确度(Validity) 随机抽样法(Random Sampli ng)实验法(Experime nt Survey)抽样单位(Sampling unit)资讯名词市场调查(Marketi ng Research) 决策树(Decision Trees)容忍误差(Tolerated erro) 资料采矿(Data Mining)初级资料(Primary Data)时间序列(Time-Series Forecasti ng) 目标母体(Target Populatio n)回归分析(Regressi on)抽样偏差(Sampling Bias)趋势分析(Tre nd An alysis)抽样误差(sampling error)罗吉斯回归(Logistic Regressi on)架构效度(Co nstruct Validity) 类神经网络(Neural Network)配额抽样(Quota Sampling)无母数统计检定方法(Non-Parametric Test)人员访问法(Interview) 判别分析法(Discrim inantAn alysis)集群分析法(cluster analysis)规贝V 归纳法(Rules In ducti on)内容效度(Content Validity) 判断抽样(Judgme nt Sampli ng) 开放式问题(Open Questi on) OLAP( On li ne An alytical Process) 分层随机抽样(Stratified Ran dom sampling)资料仓储(Data Warehouse)非随机抽样法(Nonran dom Sampli ng) 知识发现(Kno wledge Discover。