(最新)JSF+Spring+Hibernate的实例讲解
SpringMVC+Spring+Hibernate框架整合原理,作用及使用方法

SpringMVC+Spring+Hibernate框架整合原理,作⽤及使⽤⽅法SSM框架是spring MVC ,spring和mybatis框架的整合,是标准的MVC模式,将整个系统划分为表现层,controller层,service层,DAO层四层使⽤spring MVC负责请求的转发和视图管理spring实现业务对象管理,mybatis作为数据对象的持久化引擎原理:SpringMVC:1.客户端发送请求到DispacherServlet(分发器)2.由DispacherServlet控制器查询HanderMapping,找到处理请求的Controller3.Controller调⽤业务逻辑处理后,返回ModelAndView4.DispacherSerclet查询视图解析器,找到ModelAndView指定的视图5.视图负责将结果显⽰到客户端Spring:我们平时开发接触最多的估计就是IOC容器,它可以装载bean(也就是我们中的类,当然也包括service dao⾥⾯的),有了这个机制,我们就不⽤在每次使⽤这个类的时候为它初始化,很少看到关键字new。
另外spring的aop,事务管理等等都是我们经常⽤到的。
Mybatis:mybatis是对jdbc的封装,它让数据库底层操作变的透明。
mybatis的操作都是围绕⼀个sqlSessionFactory实例展开的。
mybatis通过配置⽂件关联到各实体类的Mapper⽂件,Mapper⽂件中配置了每个类对数据库所需进⾏的sql语句映射。
在每次与数据库交互时,通过sqlSessionFactory拿到⼀个sqlSession,再执⾏sql命令。
使⽤⽅法:要完成⼀个功能:1. 先写实体类entity,定义对象的属性,(可以参照数据库中表的字段来设置,数据库的设计应该在所有编码开始之前)。
2. 写Mapper.xml(Mybatis),其中定义你的功能,对应要对数据库进⾏的那些操作,⽐如 insert、selectAll、selectByKey、delete、update等。
Hibernate+Spring多数据库解决方案

Hibernate+Spring多数据库解决方案我以前在项目中的探索和实践,写出来与大家分享。
大家有其他好的方式,也欢迎分享。
环境:JDK 1.4.x , Hibernate 3.1, Spring 2.0.6, JBOSS4.0, 开发模式: Service + DAO我们项目中需要同时使用多个数据库. 但 Hibernate 不能直接支持,为此我们对比了网上网友的方案,自己做了一点探索。
1. Demo需求我们的项目使用一个全省的公共库加十多个地市库的架构。
本文主要说明原理,将需求简化为两库模型。
主库:User管里,主要是系统管理,鉴权等数据;订单库:Order 管理,存放订单等业务性数据。
2. 原理:1) Hibernate 的每个配置文件对应一个数据库,因此多库需要做多个配置文件。
本文以两个为例:主库 hibernate_sys.cfg.xml,订单库 hibernate_order.cfg.xml每个库,Hibernate 对应一个 sessionFactory 实例,因此Hibernate 下的多库处理,就是在多个 sessionFactory 之间做好路由。
2) sessionFactory 有个 sessionFactory.getClassMetadata(voClass) 方法,返回值不为空时,表示该 VO 类在该库中(hbm.xml文件配置在了对应的hibernate.cfg.xml中),该方法是数据路由的核心和关键所在。
因此, User.hbm.xml 配置在 hibernate_sys.cfg.xml ,Order数据位于配置到 hibernate_order.cfg.xml3)多库处理时,需要使用 XA 事务管理。
本例中使用 Jboss4.0 来做JTA事务管理;用JOTM,其他应用服务器原理相同。
3. 实现1)为做多 sessionFactory 实例的管理,设计 SessionFactoryManager 类,功能就是做数据路由,控制路由的核心是 sessionFactoryMap 属性,它按dbFlag=sessionFactory 的方式存储了多个库的引用。
Struct2、Hibernate3、Spring3框架搭建实战

Struct2、Hibernate3、Spring3框架搭建实战采⽤⽬前最新的struts-2.3.1.2、hibernate3.6.10.Final、spring-framework-3.1.1.RELEASE开发包,以及eclipse-jee-indigo-SR2-win32、apache-tomcat-7.0.27服务器、JDK6和mysql5做开发环境,参考了前辈的⼀篇相关⽂章,改正了其中的错误和疏漏,克服了公司分配的“新”机器每⼩时⾃动重启三次的困难,终于把环境给搭好了。
整个过程中遵循的⼀个原则是,避免引⼊⽤不到的jar包,以求搭建⼀个最⼩的SSH 运⾏环境。
⾸先创建⼀个Dynamic web project 输⼊任意名字如SSHBase。
第⼀步:加载Spring环境我们需要引⼊的包有:org.springframework.asm-3.1.1.RELEASE.jarorg.springframework.beans-3.1.1.RELEASE.jarorg.springframework.context-3.1.1.RELEASE.jarorg.springframework.core-3.1.1.RELEASE.jarorg.springframework.expression-3.1.1.RELEASE.jarorg.springframework.jdbc-3.1.1.RELEASE.jarorg.springframework.web-3.1.1.RELEASE.jarorg.springframework.orm-3.1.1.RELEASE.jar由于spring默认开启了⽇志,还需要加⼊commons-logging的jar包,否则会报错。
建议不要⼀次性加⼊应该先加最核⼼的运⾏代码看缺少什么加什么,这样就不会加多余的包进来了,spring3已经把包按功能分开,不像以前⼀个包,这样更灵活,只要运⾏我们需要的功能,⽽没⽤到的就不⽤在硬性的添加进来。
达梦Hibernate Spring集成开发示例
达梦Hibernate Spring集成开发示例DM是武汉华工达梦数据库有限公司推出的新一代高性能、高安全性的数据库产品。
它具有开放的、可扩展的体系结构,高性能事务处理能力,以及低廉的维护成本。
DM是完全自主开发的数据库软件,其安全级别达到了国内所有数据库产品中的最高级---B1级。
在这里我准备用时下比较流行的开发工具,Hibernate和Spring,达梦数据库。
以及MyEclipse来完成一个简单的应用。
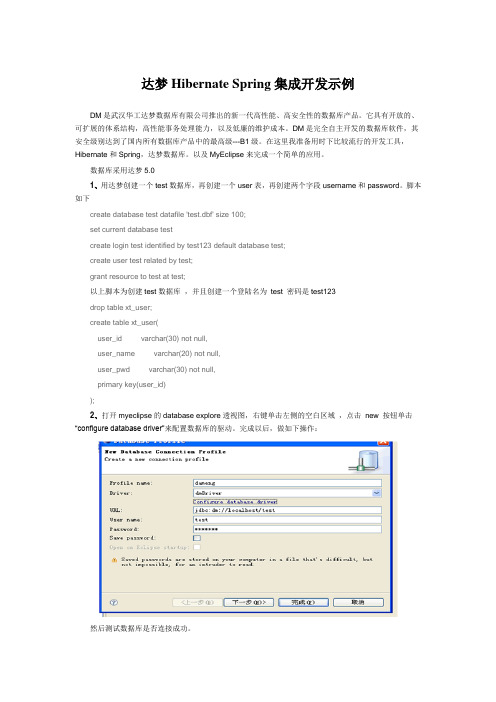
数据库采用达梦5.01、用达梦创建一个test数据库,再创建一个user表,再创建两个字段username和password。
脚本如下create database test datafile 'test.dbf' size 100;set current database testcreate login test identified by test123 default database test;create user test related by test;grant resource to test at test;以上脚本为创建test数据库,并且创建一个登陆名为test 密码是test123drop table xt_user;create table xt_user(user_id varchar(30) not null,user_name varchar(20) not null,user_pwd varchar(30) not null,primary key(user_id));2、打开myeclipse的database explore透视图,右键单击左侧的空白区域,点击new 按钮单击“configure database driver”来配置数据库的驱动。
完成以后,做如下操作:然后测试数据库是否连接成功。
如果测试成功显示如下图:1.新建一个web项目testSpring 2.引入Spring包注意:这里为了省得以后再添加spring的相关包,所以一次性的选中了所有的包。
SHJ整合文档

</property>
</bean>
g、定义实现接口的业务目标类
<bean id="chargeItemServiceTarget" class="com.synchrobit.synchrofms.bo.implement.ChargeItemServiceImp">
a、数据源(一个连接池)
<bean id="dataSource" class="mons.dbcp.BasicDataSource">
注:mon.dbcp.BasicDataSource是一个数据库连接池的类,可以用于数据库连接的池化。
b、这样各自的jar包就自动的加入到项目中了。
c、各自自动加入的配置文件和java类分别为:
Spring: applicationContext.xml
Hibernate: hibernate.cfg.xml
JSF:faces-config.xml
2、spring配置文件applicationContext.xml中的配置
<value>classpath:hibernate.cfg.xml</value>
</property>
<property name="mappingResources">
<list>
<value>com/synchrobit/synchrofms/pojo/TChargeItem.hbm.xml</value>
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
基于JSF和Hibernate技术的Web应用开发研究

以使 We b应用开发更加简单 。
1 .传 统 J P 发 存在 的 问题 S 开
基于 J F和 Hie a S br t n e集成框 架所 开发的 We b应 用系 统
J P是 一 个 基 于 Jv S aa的 We 户 界 面 开 发 标 准 技 术 , b用 是
H ML页 面 揉 和 的 问题 。 T
2 SF技 术 .J
【
4 w ̄ eg bN J
…
趼
l 请模 I 求型
久 对 l 持化 象 l
更模 l 新型
l
Jv e e ae ቤተ መጻሕፍቲ ባይዱS 1 一 种 用 于 构 建 W e a a r r cs JF 是 Sv F b应 用 程 序 的
-
于 显 示 逻 辑 的 HT ML和 用 于 业 务 逻 辑 的 Jv aa代 码 , 得 页 面 使
设 计 与 程 序 开 发 无 法 分 离 ;S JP另 一 个 更 大 的 缺 陷 是 脚 本 不 能 重 用 , 常 常 导 致 开 发 者 不 得 不 在 JP页 面之 间进 行 复 制 一 这 S 粘 贴 操 作 , 而 使 得 程 序 的调 试 和 设 计 极 其 错 综 复 杂 。而 标 签 库 从 T g i 为 J P的 补 充 , Jv 代 码 从 JP 中 剥 离 , 只 是 aLb作 S 将 aa S 也 有 限 地 实 现 了 表 现 与 逻 辑 的 分 离 , 始 终 没 有 摆 脱 代 码 和
在 Srlt 基 础 上 提 供 了 页 面 模 板 创 建 文 本 内 容 ( HT ) eve 的 如 ML
的机 制 , 能与 J F很 好 的集 成 。 它 S
最经典的hibernate教程 从入门到精通 第一篇(共四篇)

• </session-factory>
准备3:添加实体类和映射文件(UserInfo.hbm.xml)
使用Hibernate的7个步骤:
1、 Configuration 7、 关闭Session 2、 创建 SessionFactory
6、 提交事务 5、
3、 打开 Session 4、 开始一个事务
2-1):添加配置文件 -- hibernate.cfg.xml
<session-factory> <property name="connection.url"> jdbc:microsoft:sqlserver://localhost:1433;Database=pubs </property> <property name="ername">sa</property> <property name="connection.password">pwd</property> <property name="connection.driver_class"> com.microsoft.jdbc.sqlserver.SQLServerDriver </property> <property name="dialect"> org.hibernate.dialect.SQLServerDialect </property> <property name="show_sql">true</property> <mapping resource="com/aptech/jb/entity/User.hbm.xml" /> </session-factory>
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
JSF+Spring+Hibernate的实例讲解使用JSF建立一个真实的Web应用程序不是没有意义的任务,这篇文章介绍了如何将JSF与Sping Framework和Hibernate集成,并且给出了使用这些技术建立这个真实的Web应用程序的最佳实践和设计指导JavaServer Faces(JSF)技术是J2EE应用程序的一个新的用户接口框架,它非常适合基于MVC(Model-View-Controller)体系结构的应用程序。
已经有大量的文章介绍JSF。
然而,很多文章都是站在理论研究的层面上,没有挑战一个真实的企业开发。
很多问题没有解决,例如,JSF怎样全面适合MVC体系结构?JSF如何与其他JAVA框架集成?业务逻辑应该放在JSF的backing beans里面吗?怎样处理JSF里面的安全问题?最重要的是你怎样使用JSF建立一个真实的Web应用程序?这篇文章涉及所有这些问题。
它向你展示如何集成其他特定的Java框架,Spring Framework和Hibernate,它示范怎样去创建一个叫JCatalog的Web应用程序,一个在线的产品目录系统。
这篇文章使用JCatalog例子,介绍了Web应用程序设计的每一个阶段,包括业务需求收集,分析,技术选择,高层体系结构和详细设计。
这篇文章论述了JCatalog里面好的和不好的技术,示范了应用程序设计中一些关键方面的方法和步骤。
这篇文章是写给正在从事基于J2EE Web应用程序的Java架构师,开发者,它不是对JSF、Spring Framework和Hibernate的入门教程。
如果您对这些领域不熟悉,请参考文章最后的资源链接。
例子应用程序的功能需求这篇文章的例子应用程序JCatalog是一个真实的Web应用程序,例子足够现实是为了决定应用程序架构而进行意味深长的讨论的基础。
我通过介绍JCatalog项目的需求开始。
我在这里谈到后面贯穿于整个文章的内容是为了演示技术选择和体系结构设计。
设计Web应用程序的第一步是收集系统的功能需求,这个例子应用程序是一个典型的电子商务应用系统。
用户能浏览产品目录和查看产品细节,管理员能管理产品目录。
功能还可以增加,举例来说,为了开发一个成熟的电子商务系统,可以添加库存管理和订单处理的功能。
用例用例分析被用于去访问例子应用程序的功能需求,图1是应用程序的用例图。
图1 用例图一个用例图确定在一个系统中的参与者以及参与者可以执行的操作。
例子应用中7个用例必须被实现。
参与者中的User能浏览产品目录和察看产品细节。
一旦用户以Administrator身份连接到系统,他就能创建新产品,编辑存在的产品,删除老的产品。
业务规则JCatalog 必须符合下面的业务规则:每个产品有一个唯一的产品ID每个产品至少属于一个目录产品ID一旦被创建就不能改变假定对于产品的设计和实现,我们做下面的假定。
英语是默认语言;不要求国际化目录中不超过500种产品目录的更新不频繁页面流图2显示了所有JCatalog的页面和它们之间的转换。
图2 页面流图应用程序有两组页面:公共的国际互联网和管理员的企业内部网。
企业内部网只有对那些成功登陆到系统的用户有效。
产品概要页面是公用的,它作为产品目录的内容包含在一个HTML框架里面。
产品列表是一个特殊的目录,只能被管理员看见,它包含创建、编辑和删除产品的链接。
图3是目录页的一个模型。
理想情况下,每一个页面所有的控制和必要的内容明细的模型应该被包含在需求文档里面。
图3 目录页面模型高级体系结构设计下一步的设计是Web应用程序的高级体系结构设计,它包括将应用程序细分成功能组件以及将这些组件划分到各自所属的层。
高级体系结构设计独立于使用的技术。
多层体系结构一个多层体系结构将整个系统划分成清晰的单元——客户端、表示层、业务逻辑层、集成层和企业信息系统(EIS),这保证了清晰的责任划分以及可维护性和可扩展性。
三层或多层系统已经被证明比没有业务逻辑层的客户-服务器系统具有更多的可升级性和柔韧性。
客户端是数据模型被消费和呈现的地方。
对于一个Web应用程序,客户层通常是Web浏览器。
基于浏览器的瘦客户不包含表示逻辑;它依赖于表示层。
表示层使用业务逻辑层为用户服务,它知道怎样去处理一个客户请求,怎样去和业务逻辑层结合以及怎样去选择下一个试图去显示。
业务逻辑层包含一个应用程序的业务对象和业务服务。
它从表示层接受请求,基于请求处理业务逻辑,作为访问EIS层资源的的中介。
业务逻辑层组件使用许多系统级别的服务,例如,安全管理、事物管理和资源管理。
集成层是业务逻辑层和EIS层之间的桥梁。
它封装了与EIS层相结合的逻辑。
有时,集成层和业务逻辑层的结合是作为中间层被提到。
应用程序数据在EIS层被持久化,包括关系数据库,面向对象数据库和遗留系统。
JCatalog 的体系结构设计图4显示了JCatalog的高级体系结构设计以及它怎样适合多层体系结构。
图4 高级体系结构图应用程序使用了一个多层的非分布式的体系结构,图4显示应用程序层和每一层技术选择的划分。
它也用于应用程序的部署图。
对于一个可配置的体系结构,表示层、业务逻辑层和集成层被定位在同样的Web容器。
定义良好的接口隔离了每一层的职责。
可配置的体系结构使应用程序简单和可升级。
对于表示层,经验告诉我们,最好的实践是选择一个存在的,被验证的Web应用框架,远比设计开发一个定制的框架好。
我们有几个Web应用框架可供选择,举例来说,Struts、WebWork和JSF。
对于JCatalog项目,我们使用JSF。
对于业务逻辑层,不是使用EJB(Enterprise JavaBeans)就是使用POJO(plain old Java objects)。
如果应用程序是分布式的,EJB具有远程接口是一个较好的选择。
因为JCatalog是一个典型的没有远程访问请求的Web应用程序,POJO在Spring框架的帮助下,用于实现业务逻辑层。
Pure JDBC(Java Database Connectivity):这是最灵活的实现方法;然而,低级的JDBC和不好的JDBC代码工作是麻烦的,执行的不好。
Entity beans:一个容器管理持久化(CMP,container-managed persistence)的entity bean是隔离数据访问代码和处理O/R(object- relational) mapping数据持久化的昂贵的方法。
它是一个以应用服务器为中心的解决办法。
一个entity bean不和特定的数据库紧耦合,但是应用程序和EJB容器进耦合。
O/R mapping framework:一个O/R影射的框架采用以对象为中心的方法实现数据持久化。
一个以对象为中心的应用程序是容易开发和高度轻便的。
在这个领域内存在几个框架——JDO(Java Data Objects),Hibernate,Toplink。
CocoBase是一个新的例子。
在例子应用程序中我们使用HIbernate。
现在,让我们讨论将应用程序的每一个层联合起来设计的问题。
因为JSF相对来说是一个新技术,我强调一下它的使用。
表现层和JavaServer Faces(JSF)表现层收集用户输入,呈现数据,控制页面导航,代替用户与业务逻辑层交互。
表现层也能校验用户输入,维护应用程序的会话状态。
下面的章节,我讨论表现层的设计考虑和模式以及我选择JSF去实现JCatalog项目的表现层的原因。
MOdel-View-Controller(MVC)MVC是Java蓝皮书(BluePrints)中推荐的交互式应用程序体系结构设计模式。
MVC分别设计关注的问题,因此减少了代码的重复,集中控制,使应用程序更具扩展性。
MVC也帮助开发者使用不同的技术集合,集中他们核心的技术,通过定义清晰的接口进行合作。
MVC是表现层的体系结构设计模式。
JavaServer FaceJSF是一个基于Java的Web应用程序服务端的用户接口组件框架。
JSF包括表示UI组件和管理其状态的API;处理事件,服务端校验,数据转换;定义页面导航;支持国际化和可访问性;提供所有这些特点的扩展能力。
它还包括两个为JSP定制的标签库,一个用于表示JSP页面内的UI 组件,一个用于配置服务端的对象组件。
JSF和MVCJSF很适合基于MVC的表现层体系结构。
它提供动作和表现之间清楚地划分。
它影响了UI组件和Web层概念,不限定你去使用特定的脚本技术或者标记语言。
JSF backing beans 是model层(后面的章节有关于backing beans 的更多内容)。
它们也包含动作,这是控制层的扩展,代理用户对业务逻辑层的请求。
请注意,从整体应用程序的体系结构来看,业务逻辑层也能被作为Model层提到。
使用JSF定制标签的JSP页面是视图层。
Faces Servlet提供控制者的功能。
为什么用JSFJSF不仅仅只是另一个Web框架,下面是JSF与其他Web框架不同的特点:象Swing一样面向对象的Web应用程序开发:服务端有状态的UI组件模型,具有事件监听和操作者,开始了面向对象Web应用程序开发。
Backing-bean管理:Backing beans是页面中JavaBeans组件和UI组件的联合。
Backing-bean 管理UI组件对象定义和对象执行应用程序特殊过程以及控制数据的分离。
JSF在正确的范围内执行存储和管理这些backing-bean实例。
可扩展的UI组件模型:JSF UI组件是组成JSF应用程序用户接口可配置、可复用的元素。
你能扩展标准的UI组件和开发更多的复杂组件。
举例来说,菜单条和树型构件。
灵活的表现模型:一个renderer分隔一个UI组件的功能和视图。
多个renderer能被创建,用于定义相同或不同客户端上同样组件的不同外观。
可扩展的转化和校验模型:基于标准的转换者和校验者,你能开发定制的转换者和校验者,它们提供最好的模型保护。
尽管JSF很强大,但是现在还不成熟。
组件、转换者和校验者是JSF基本的。
每一个校验模型不能处理组件和校验者之间多对多的校验。
另外,JSF定制标签不能和JSTL(JSP Standard Tag Library)无缝结合。
在下面的部分,我讨论用JSF实现JCatalog项目时几个关键方面和设计决定。
首先讨论JSF中managed beans和backing beans的定义和使用。
然后,我介绍JSF中怎样处理安全、分页、缓存、文件上传、校验和错误消息定制。
Managed bean,backing bean,view object和domain object modelJSF介绍了两个新的术语:managed bean 和 backing bean。