scrapy学习笔记_光环大数据Python培训
Python动态网页爬虫技术_光环大数据培训

Python动态网页爬虫技术_光环大数据培训动态网页技术介绍所谓的动态网页,是指跟静态网页相对的一种网页编程技术。
静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。
而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
值得强调的是,不要将动态网页和页面内容是否有动感混为一谈。
这里说的动态网页,与网页上的各种动画、滚动字幕等视觉上的动态效果没有直接关系,动态网页也可以是纯文字内容的,也可以是包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,只要是采用了动态网站技术生成的网页都可以称为动态网页。
互联网每天都在蓬勃的发展,数以万计的在线平台如雨后春笋般不断涌现,不同平台对不同用户的权限、喜好推出不同的个性化内容,传统的静态网页似乎早已不能满足社会的需求。
于是,动态网页技术应运而生,当然,在如今人们对网页加载速度的要求越来越高的要求下,异步加载成为了许多大的站点的首选。
比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。
简单来说,就是把一些根据时间、请求而变化的内容,比如某宝的商品价格、评论,比如某瓣的热门电影评论,再比如某讯的视频等,采用先加载网页整体框架,后加载动态内容的方式呈现。
对于这一类动态页面,如果我们采用前面所说的对付静态网页的爬虫方式去爬,可能收获不到任何结果,因为这些异步加载的内容所在的位置大多是一段请求内容的JS代码。
在某些触发操作下,这些JS代码开始工作,从数据库中提取对应的数据,将其放置到网页框架中相对应的位置,从而最终拼接成我们所能看到的完整的一张页面。
动态网页爬虫技术一之API请求法看似更加复杂的操作似乎给我们的爬虫带来了很大的困扰,但其实也可能给我们带来极大的便利。
我们只需要找到JS请求的API,并按照一定的要求发送带有有效参数的请求,便能获得最为整洁的数据,而不用像以前那样从层层嵌套的HTML代码中慢慢解析出我们想要的数据。
Python数据抓取、分析、挖掘、机器学习和Python分布式计算_光环大数据python培训

Python数据抓取、分析、挖掘、机器学习和Python分布式计算_光环大数据python培训01 数据抓取1、背景调研1)检查robots.txt,了解爬取该网站有哪些限制;2)pip install builtwith;pip install python-whois2、数据抓取:1)动态加载的内容:使用selenium#!/usr/bin/env python# -*- coding: utf-8 -*-from selenium import webdriverfrom mon.keys import Keysimport timeimport sysreload(sys)sys.setdefaultencoding(‘utf8’)driver = webdriver.Chrome(“/Users/didi/Downloads/chromedriver”)driver.get(‘http://xxx’)elem_account = driver.find_element_by_name(“UserName”)elem_password = driver.find_element_by_name(“Password”)elem_code = driver.find_element_by_name(“VerificationCode”) elem_account.clear()elem_password.clear()elem_code.clear()elem_account.send_keys(“username”)elem_password.send_keys(“pass”)elem_code.send_keys(“abcd”)time.sleep(10)driver.find_element_by_id(“btnSubmit”).submit()time.sleep(5)driver.find_element_by_class_name(“txtKeyword”).send_keys(u“x”) #模拟搜索 driver.find_element_by_class_name(“btnSerch”).click()# …省略处理过程dw = driver.find_elements_by_xpath(‘//li[@class=”min”]/dl/dt/a’)for item in dw:url = item.get_attribute(‘href’)if url:ulist.append(url)print(url + “—“ + str(pnum))print(“##################”)2)静态加载的内容(1)正则;(2)lxml;(3)bs4#!/usr/bin/env python# -*- coding: utf-8 -*-string = r‘src=”(http://imgsrc/.baidu/.com.+?/.jpg)” pic_ext=”jpeg”‘ # 正则表达式字符串 urls = re.findall(string, html)import requestsfrom lxml import etreeimport urllibresponse = requests.get(url)html = etree.HTML(requests.get(url).content)res = html.xpath(‘//div[@class=”d_post_content j_d_post_content “]/img[@class=”BDE_Image”]/@src’) # lxmlimport requestsfrom bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, ‘lxml’) # 解析response 并创建BeautifulSoup对象 urls = soup.find_all(‘img’, ‘BDE_Image’)3):反爬与反反爬(1):请求频率;(2):请求头;(3):IP代理;4):爬虫框架:(1):Scrapy(2):Portia02 数据分析1、常用的数据分析库:NumPy:是基于向量化的运算。
从零开始的Python爬虫速成指南_光环大数据Python培训

从零开始的Python爬虫速成指南_光环大数据Python培训0.准备工作需要准备的东西: Python、scrapy、一个IDE或者随便什么文本编辑工具。
1.技术部已经研究决定了,你来写爬虫。
随便建一个工作目录,然后用命令行建立一个工程,工程名为miao,可以替换为你喜欢的名字。
scrapy startproject miao随后你会得到如下的一个由scrapy创建的目录结构在spiders文件夹中创建一个python文件,比如miao.py,来作为爬虫的脚本。
内容如下:import scrapyclass NgaSpider(scrapy.Spider): name = "NgaSpider" host = "/" # start_urls是我们准备爬的初始页start_urls = [ "/thread.php?fid=406", ] # 这个是解析函数,如果不特别指明的话,scrapy抓回来的页面会由这个函数进行解析。
# 对页面的处理和分析工作都在此进行,这个示例里我们只是简单地把页面内容打印出来。
def parse(self, response): print response.body2.跑一个试试?如果用命令行的话就这样:cd miaoscrapy crawl NgaSpider你可以看到爬虫君已经把你坛星际区第一页打印出来了,当然由于没有任何处理,所以混杂着html标签和js脚本都一并打印出来了。
解析接下来我们要把刚刚抓下来的页面进行分析,从这坨html和js堆里把这一页的帖子标题提炼出来。
其实解析页面是个体力活,方法多的是,这里只介绍xpath。
0.为什么不试试神奇的xpath呢看一下刚才抓下来的那坨东西,或者用chrome浏览器手动打开那个页面然后按F12可以看到页面结构。
每个标题其实都是由这么一个html标签包裹着的。
NumPy常用方法总结 光环大数据Python培训班

NumPy常用方法总结光环大数据Python培训班光环大数据Python培训了解到,NumPy是Python的一种开源的数值计算扩展。
这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nestedliststructure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
NumPy(NumericPython)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。
专为进行严格的数字处理而产生。
多为很多大型金融公司使用,以及核心的科学计算组织如:LawrenceLivermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
numpy中的数据类型,ndarray类型,和标准库中的array.array并不一样。
ndarray的创建>>>importnumpyasnp>>>a=np.array([2,3,4])>>>aarray([2,3,4])>>>a.dt ypedtype('int64')>>>b=np.array([1.2,3.5,5.1])>>>b.dtypedtype('float64 ')二维的数组>>>b=np.array([(1.5,2,3),(4,5,6)])>>>barray([[1.5,2.,3.],[4.,5.,6 .]])创建时指定类型>>>c=np.array([[1,2],[3,4]],dtype=complex)>>>carray([[1.+0.j,2.+0 .j],[3.+0.j,4.+0.j]])创建一些特殊的矩阵>>>np.zeros((3,4))array([[0.,0.,0.,0.],[0.,0.,0.,0.],[0.,0.,0.,0. ]])>>>np.ones((2,3,4),dtype=np.int16)#dtypecanalsobespecifiedarray([[ [1,1,1,1],[1,1,1,1],[1,1,1,1]],[[1,1,1,1],[1,1,1,1],[1,1,1,1]]],dtype =int16)>>>np.empty((2,3))#uninitialized,outputmayvaryarray([[3.736039 59e-262,6.02658058e-154,6.55490914e-260],[5.30498948e-313,3.14673309e -307,1.00000000e+000]])创建一些有特定规律的矩阵>>>np.arange(10,30,5)array([10,15,20,25])>>>np.arange(0,2,0.3)#it acceptsfloatargumentsarray([0.,0.3,0.6,0.9,1.2,1.5,1.8])>>>fromnumpyi mportpi>>>np.linspace(0,2,9)#9numbersfrom0to2array([0.,0.25,0.5,0.75, 1.,1.25,1.5,1.75,2.])>>>x=np.linspace(0,2*pi,100)#usefultoevaluatefun ctionatlotsofpoints>>>f=np.sin(x)一些基本的运算加减乘除三角函数逻辑运算>>>a=np.array([20,30,40,50])>>>b=np.arange(4)>>>barray([0,1,2,3]) >>>c=a-b>>>carray([20,29,38,47])>>>b**2array([0,1,4,9])>>>10*np.sin(a )array([9.12945251,-9.88031624,7.4511316,-2.62374854])>>>a<35array([T rue,True,False,False],dtype=bool)矩阵运算matlab中有.*,./等等但是在numpy中,如果使用+,-,×,/优先执行的是各个点之间的加减乘除法如果两个矩阵(方阵)可既以元素之间对于运算,又能执行矩阵运算会优先执行元素之间的运算>>>importnumpyasnp>>>A=np.arange(10,20)>>>B=np.arange(20,30)>>>A+ Barray([30,32,34,36,38,40,42,44,46,48])>>>A*Barray([200,231,264,299,3 36,375,416,459,504,551])>>>A/Barray([0,0,0,0,0,0,0,0,0,0])>>>B/Aarray ([2,1,1,1,1,1,1,1,1,1])如果需要执行矩阵运算,一般就是矩阵的乘法运算>>>A=np.array([1,1,1,1])>>>B=np.array([2,2,2,2])>>>A.reshape(2,2) array([[1,1],[1,1]])>>>B.reshape(2,2)array([[2,2],[2,2]])>>>A*Barray( [2,2,2,2])>>>np.dot(A,B)8>>>A.dot(B)8一些常用的全局函数>>>B=np.arange(3)>>>Barray([0,1,2])>>>np.exp(B)array([1.,2.71828183,7.3890561])>>>np.sqrt(B)array([0.,1.,1.41421356])>>>C=np.array([2. ,-1.,4.])>>>np.add(B,C)array([2.,0.,6.])矩阵的索引分片遍历>>>a=np.arange(10)**3>>>aarray([0,1,8,27,64,125,216,343,512,729]) >>>a[2]8>>>a[2:5]array([8,27,64])>>>a[:6:2]=-1000#equivalenttoa[0:6:2 ]=-1000;fromstarttoposition6,exclusive,setevery2ndelementto-1000>>>aa rray([-1000,1,-1000,27,-1000,125,216,343,512,729])>>>a[::-1]#reversed aarray([729,512,343,216,125,-1000,27,-1000,1,-1000])>>>foriina:...pri nt(i**(1/3.))...nan1.0nan3.0nan5.06.07.08.09.0矩阵的遍历>>>importnumpyasnp>>>b=np.arange(16).reshape(4,4)>>>forrowinb:... print(row)...[0123][4567][891011][12131415]>>>fornodeinb.flat:...prin t(node) (0123456789101112131415)矩阵的特殊运算改变矩阵形状--reshape>>>a=np.floor(10*np.random.random((3,4)))>>>aarray([[6.,5.,1.,5.] ,[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.ravel()array([6.,5.,1.,5.,5.,5.,8. ,9.,5.,5.,9.,7.])>>>aarray([[6.,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.] ])resize和reshape的区别resize会改变原来的矩阵,reshape并不会>>>aarray([[6.,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.reshap e(2,-1)array([[6.,5.,1.,5.,5.,5.],[8.,9.,5.,5.,9.,7.]])>>>aarray([[6. ,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.resize(2,6)>>>aarray([[6 .,5.,1.,5.,5.,5.],[8.,9.,5.,5.,9.,7.]])矩阵的合并>>>a=np.floor(10*np.random.random((2,2)))>>>aarray([[8.,8.]为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。
基于 Python 的 Scrapy 爬虫入门:代码详解_光环大数据人工智能培训

基于 Python 的 Scrapy 爬虫入门:代码详解_光环大数据人工智能培训一、内容分析接下来创建一个爬虫项目,以图虫网为例抓取里面的图片。
在顶部菜单“发现”“标签”里面是对各种图片的分类,点击一个标签,比如“美女”,网页的链接为:https:///tags/美女/,我们以此作为爬虫入口,分析一下该页面:打开页面后出现一个个的图集,点击图集可全屏浏览图片,向下滚动页面会出现更多的图集,没有页码翻页的设置。
Chrome右键“检查元素”打开开发者工具,检查页面源码,内容部分如下:<div class="content"> <div class="widget-gallery"> <ul class="pagelist-wrapper"> <li class="gallery-item...可以判断每一个li.gallery-item是一个图集的入口,存放在ul.pagelist-wrapper下,div.widget-gallery是一个容器,如果使用 xpath 选取应该是://div[@class=”widget-gallery”]/ul/li,按照一般页面的逻辑,在li.gallery-item下面找到对应的链接地址,再往下深入一层页面抓取图片。
但是如果用类似 Postman 的HTTP调试工具请求该页面,得到的内容是:<div class="content"> <div class="widget-gallery"></div></div>也就是并没有实际的图集内容,因此可以断定页面使用了Ajax请求,只有在浏览器载入页面时才会请求图集内容并加入div.widget-gallery中,通过开发者工具查看XHR请求地址为:https:///rest/tags/美女/posts?page=1&count=20&order=weekly&before_timestamp=参数很简单,page是页码,count是每页图集数量,order是排序,before_timestamp为空,图虫因为是推送内容式的网站,因此before_timestamp应该是一个时间值,不同的时间会显示不同的内容,这里我们把它丢弃,不考虑时间直接从最新的页面向前抓取。
python-scapy学习笔记-(1)

python-scapy学习笔记-(1)主要功能函数sniffsniff(filter="",iface="any",prn=function,count=N)filter参数允许我们对Scapy嗅探的数据包指定⼀个BPF(Wireshark类型)的过滤器,也可以留空以嗅探所有的数据包。
例如:嗅探所有的HTTP数据包,tcp port 80的BPF过滤iface参数设置嗅探器所要嗅探的⽹卡,留空则对所有⽹卡进⾏嗅探。
例如:wlan0prn参数指定嗅探到符合过滤器条件的数据包时所调⽤的回调函数,这个回调函数以接受到的数据包对象作为唯⼀的参数。
例如: def pack_callback(packet): print packet.show() sniff(prn=pack_callback,iface="wlan0",count=1)count参数指定你需要嗅探的数据包的个数,留空则默认为嗅探⽆限个此处添加⼀个嗅探mail的源码#coding:utf-8from scapy.all import *def pack_callback(packet):print packet.show()if packet[TCP].payload:mail_packet=str(packet[TCP].payload)if "user" in mail_packet.lower() or "pass" in mail_packet.lower():print "Server:%s"%packet[IP].dstprint "%s"%packet[TCP].payloadsniff(filter="tcp port 110 or tcp port 25 or tcp port 143",prn=pack_callback,iface="wlan0",count=0)。
从零开始学Python_光环大数据python培训

从零开始学Python_光环大数据python培训一、频数统计我们以被调查用户的收入数据为例,来谈谈频数统计函数value_counts。
频数统计,顾名思义就是统计某个离散变量各水平的频次。
这里统计的是性别男女的人数,是一个绝对值,如果想进一步查看男女的百分比例,可以通过下面的方式实现:而在R语言中,table函数就是起到频数统计的作用,另外还提供了更加灵活的prop.table函数,可以直接求出比例。
如上是单变量的频数统计,如果需要统计两个离散变量的交叉统计表,该如何实现?不急,pandas模块提供了crosstab函数,我们来看看其用法:R语言的话,任然使用table函数即可。
二、缺失值处理在数据分析或建模过程中,我们希望数据集是干净的,没有缺失、异常之类,但面临的实际情况确实数据集很脏,例如对于缺失值我们该如何解决?一般情况,缺失值可以通过删除或替补的方式来处理。
首先是要监控每个变量是否存在缺失,缺失的比例如何?这里我们借助于pandas模块中的isnull函数、dropna函数和fillna函数。
首先,我们手工编造一个含缺失值的数据框:其次,使用isnull函数检查数据集的缺失情况:最后,对缺失数据进行处理:删除法dropna函数,有两种删除模式,一种是对含有缺失的行(任意一列)进行删除,另一种是删除那些全是缺失(所有列)的行,具体如下:由于df数据集不存在行全为缺失的观测,故没有实现删除。
替补法fillna函数提供前向替补、后向替补和函数替补的几种方法,具体可参见下面的代码示例:再来看看R语言是如何重现上面的操作的:不幸的是,R中没有删除每行元素都是缺失的观测,我们自定义个函数也可以实现:关于缺失值的替补,在R语言中可以使用Hmisc包中的impute函数,具体操作如下:三、数据映射大家都知道,Python和R在做循环时,效率还是很低的,如何避开循环达到相同的效果呢?这就是接下来我们要研究的映射函数apply。
Python基础知识汇总_光环大数据培训
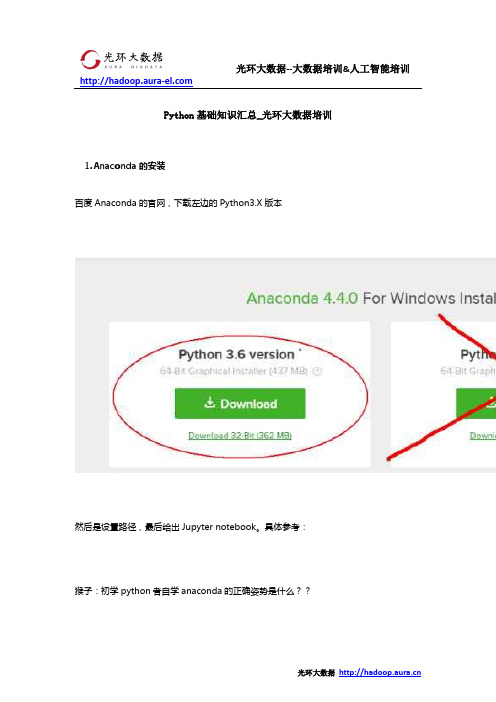
Python基础知识汇总_光环大数据培训1.Anaconda的安装百度Anaconda的官网,下载左边的Python3.X版本然后是设置路径,最后给出Jupyter notebook。
具体参考:猴子:初学python者自学anaconda的正确姿势是什么??不过平时练习的时候我个人习惯用Enthought Canopy,但比起Anaconda有些中文字符的编写不兼容。
下载链接如下:Canopy | Scientific Python Packages & Analysis Environment | Enthought2.Python的四个关键点2.1数据python常用数据类型有5类:(1)字符串(String)在python中字符串用“”或者‘’分隔(2)数字类型:整数,浮点数(3)容器:列表、集合、字典、元祖①列表(List):列表是可变的,方便增加、修改和删减数据。
列表有许多方便的函数,例如:在函数中使用列表时为防止循环的同时使列表发生改变,可以使用L1=L[:]从而复制列表,保持原列表L不变。
②元组(Tuple):元祖是不可变的,使用(),只有一个元素的元祖要加逗号:(9,)③集合(Sets):中学的知识里我们知道,集合的三个特性是:无序性,互异性,确定性。
即集合中不会存在重复元素,在python中用{}表示集合。
集合也有很多相关函数:创建空集:交集并集与做差:判断子集: 清空:删除元素:替换:增加元素:④字典(Dictionary):字典最大的特征是键值对应。
键值对用冒号(:)分割,整个字典用{}隔开。
字典是一个很好用的工具,我们可以通过字典利用增加内存来降低算法的复杂度。
(4)布尔值:True、False(注意大小写)(5)None2.2条件判断if语句可以通过判断条件是否成立来决定是否执行某个语句if-else语句就是在原有的if成立执行操作的基础上,当不成立的时候,也执行另一种操作if-elif-else语句例子:2.3循环循环有for循环while循环两种,我们常用的是for循环while True:可以用来开启循环。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
scrapy学习笔记_光环大数据Python培训一、安装在安装scrapy之前有一些依赖需要安装,否则可能会安装失败,scrapy的选择器依赖于lxml,还有Twisted网络引擎,下面是ubuntu下安装的过程1. linux下安装# 1. 安装xml依赖库$ sudo apt-get install libxml2 libxml2-dev$ sudo apt-get install libxslt1-dev$ sudo apt-get install python-libxml2# 2. 安装lxml$ sudo pip install lxml# 3. 安装Twisted(版本可以换成最新的),用pip也可以,如果失败的话下载源码安装,如下$ wget https:///packages/6b/23/8dbe86fc83215015e221fbd861a545 c6ec5c9e9cd7514af114d1f64084ab/Twisted-16.4.1.tar.bz2#md5=c6d09bdd681 f538369659111f079c29d$ tar xjf Twisted-16.4.1.tar.bz2$ cd Twisted-16.4.1$ sudo python setup.py install# 3. 安装scrapy$ sudo pip install scrapy2. Mac下安装# 安装xml依赖库$ xcode-select —install# 其实相关依赖pip会自动帮我们装上$ pip install scrapymac下安装有时候会失败,建议使用virtualenv安装在独立的环境下,可以减少一些问题,因为mac系统自带python,例如一些依赖库依赖的一些新的版本,而升级新版本会把旧版本卸载掉,卸载可能会有权限的问题二、基本使用1. 初始化scrapy项目我们可以使用命令行初始化一个项目$ scrapy startproject tutorial这里可以查看scrapy更多其他的命令初始化完成后,我们得到下面目录结构scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块, 在这里添加代码 items.py: 项目中的item文件pipelines.py: 项目中的pipelines文件. settings.py: 项目全局设置文件. spiders/ 爬虫模块目录我们先看一下scrapy的处理流程scrapy由下面几个部分组成spiders:爬虫模块,负责配置需要爬取的数据和爬取规则,以及解析结构化数据items:定义我们需要的结构化数据,使用相当于dictpipelines:管道模块,处理spider模块分析好的结构化数据,如保存入库等middlewares:中间件,相当于钩子,可以对爬取前后做预处理,如修改请求header,url过滤等我们先来看一个例子,在spiders目录下新建一个模块DmozSpider.pyimport scrapyclass DmozSpider(scrapy.Spider): # 必须定义name = "dmoz" # 初始urls start_urls =[ "/Computers/Programming/Languages/Python/Books/","/Computers/Programming/Languages/Python/Resources/" ] # 默认response处理函数 def parse(self, response): # 把结果写到文件中filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)打开终端进入根目录,执行下面命令$ scrapy crawl dmoz爬虫开始爬取start_urls定义的url,并输出到文件中,最后输出爬去报告,会输出爬取得统计结果2016-09-13 10:36:43 [scrapy] INFO: Spider opened2016-09-13 10:36:43 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0items/min)2016-09-13 10:36:43 [scrapy] DEBUG: Telnet console listeningon 127.0.0.1:60232016-09-13 10:36:44 [scrapy] DEBUG: Crawled (200) <GET/Computers/Programming/Languages/Python/Resources/> (referer: None)2016-09-13 10:36:45 [scrapy] DEBUG: Crawled (200) <GET/Computers/Programming/Languages/Python/Books/> (referer: None)2016-09-13 10:36:45 [scrapy] INFO: Closing spider (finished)2016-09-13 10:36:45 [scrapy] INFO: Dumping Scrapystats:{'downloader/request_bytes': 548, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 16179, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2016, 9, 13, 2, 36, 45, 585113), 'log_count/DEBUG': 3, 'log_count/INFO': 7, 'response_received_count': 2, 'scheduler/dequeued': 2, 'scheduler/dequeued/memory': 2, 'scheduler/enqueued': 2, 'scheduler/enqueued/memory': 2, 'start_time': datetime.datetime(2016, 9, 13, 2, 36, 43, 935790)}2016-09-13 10:36:45 [scrapy] INFO: Spider closed (finished)这里我们完成了简单的爬取和保存的操作,会在根目录生成两个文件Resources和Books2. 通过代码运行爬虫每次进入控制台运行爬虫还是比较麻烦的,而且不好调试,我们可以通过CrawlerProcess通过代码运行爬虫,新建一个模块run.pyfrom scrapy.crawler import CrawlerProcessfrom scrapy.utils.project import get_project_settingsfrom spiders.DmozSpider import DmozSpider# 获取settings.py模块的设置settings = get_project_settings()process = CrawlerProcess(settings=settings)# 可以添加多个spider# process.crawl(Spider1)#process.crawl(Spider2)process.crawl(DmozSpider)# 启动爬虫,会阻塞,直到爬取完成process.start()参考:/en/latest/topics/practices.html#run-scrapy-from-a-script三、Scrapy类如上面的DmozSpider类,爬虫类继承自scrapy.Spider,用于构造Request 对象给Scheduler1. 常用属性与方法属性name:爬虫的名字,必须唯一(如果在控制台使用的话,必须配置) start_urls:爬虫初始爬取的链接列表parse:response结果处理函数custom_settings:自定义配置,覆盖settings.py中的默认配置方法start_requests:启动爬虫的时候调用,默认是调用make_requests_from_url方法爬取start_urls的链接,可以在这个方法里面定制,如果重写了该方法,start_urls默认将不会被使用,可以在这个方法里面定制一些自定义的url,如登录,从数据库读取url等,本方法返回Request对象make_requests_from_url:默认由start_requests调用,可以配置Request对象,返回Request对象parse:response到达spider的时候默认调用,如果在Request对象配置了callback函数,则不会调用,parse方法可以迭代返回Item或Request 对象,如果返回Request对象,则会进行增量爬取2. Request与Response对象每个请求都是一个Request对象,Request对象定义了请求的相关信息(url, method, headers, body, cookie, priority)和回调的相关信息(meta, callback,dont_filter, errback),通常由spider迭代返回其中meta相当于附加变量,可以在请求完成后通过response.meta访问请求完成后,会通过Response对象发送给spider处理,常用属性有(url, status, headers, body, request, meta, )详细介绍参考官网https:///en/latest/topics/request-response.html#request-objectshttps:///en/latest/topics/request-response.html#response-objects看下面这个例子from scrapy import Spiderfrom scrapy import Requestclass TestSpider(Spider): name = 'test' start_urls =[ "/", ] def login_parse(self, response): ''' 如果登录成功,手动构造请求Request迭代返回 ''' print response for i in range(0, 10): yield Request('/list/1?page={0}'.format(i)) defstart_requests(self): ''' 覆盖默认的方法(忽略start_urls),返回登录请求页,制定处理函数为login_parse ''' return Request('/login', method="POST" body='username=bomo&pwd=123456', callback=self.login_parse) def parse(self, response): ''' 默认请求处理函数 ''' print response四、Selector上面我们只是爬取了网页的html文本,对于爬虫,我们需要明确我们需要爬取的结构化数据,需要对原文本进行解析,解析的方法通常有下面这些普通文本操作正则表达式:reDom树操作:BeautifulSoupXPath选择器:lxmlscrapy默认支持选择器的功能,自带的选择器构建与lxml之上,并对其进行了改进,使用起来更为简洁明了1. XPath选择器XPpath是标准的XML文档查询语言,可以用于查询XML文档中的节点和内容,关于XPath语法,可以参见这里先看一个例子,通过html或xml构造Selector对象,然后通过xpath查询节点,并解析出节点的内容from scrapy import Selectorhtml ='<html><body><span>good</span><span>buy</span></body></html>'sel =Selector(text=html)nodes = sel.xpath('//span')for node in nodes:print node.extract()Selector相当于节点,通过xpath去到子节点集合(SelectorList),可以继续搜索,通过extract方法可以取出节点的值,extract方法也可以作用于SelectorList,对于SelectorList可以通过extract_first取出第一个节点的值通过text()取出节点的内容通过@href去除节点属性值(这里是取出href属性的值)直接对节点取值,则是输出节点的字符串2. CSS选择器除了XPath选择器,scrapy还支持css选择器html = """ <html> <body> <span>good</span> <span>buy</span> <ul> <li class="video_part_lists">aa<li> <liclass="video_part_lists">bb<li> <liclass="audio_part_lists">cc<li> <liclass="video_part_lists"> <a href="/">主页</a> <li> </ul> </body> </html> """sel = Selector(text=html)# 选择class为video_part_lists的li节点lis = sel.css('li.video_part_lists')for li in lis: # 选择a节点的属性 print li.css('a::attr(href)').extract()关于css选择器更多的规则,可以见w3c官网https:///TR/selectors/五、Item类上面我们只是爬取了网页的html文本,对于爬虫,我们需要明确我们需要爬取的结构化数据,我们定义一个item存储分类信息,scrapy的item继承自scrapy.Itemfrom scrapy import Item, Fieldclass DmozItem(Item): title =Field() link = Field() desc = Field()scrapy.Item的用法与python中的字典用法基本一样,只是做了一些安全限制,属性定义使用Field,这里只是进行了声明,而不是真正的属性,使用的时候通过键值对操作,不支持属性访问what, 好坑爹,这意味着所有的属性赋值都得用字符串了,这里有解释(还是没太明白)why-is-scrapys-field-a-dict修改DmozSpider的parse方法class DmozSpider(scrapy.Spider): ... def parse(self, response): for sel in response.xpath('//ul/li'): dmoz_item = DmozItem() dmoz_item['title'] =sel.xpath('a/text()').extract() dmoz_item['link'] =sel.xpath('a/@href').extract() dmoz_item['desc'] =sel.xpath('text()').extract() print dmoz_item六、Pipelinespider负责爬虫的配置,item负责声明结构化数据,而对于数据的处理,在scrapy中使用管道的方式进行处理,只要注册过的管道都可以处理item数据(处理,过滤,保存)下面看看管道的声明方式,这里定义一个预处理管道PretreatmentPipeline.py,如果item的title为None,则设置为空字符串class PretreatmentPipeline(object): def process_item(self, item, spider): if item['title']: # 不让title为空item['title'] = '' return item再定义一个过滤重复数据的管道DuplicatesPipeline.py,当link重复,则丢弃from scrapy.exceptions import DropItemclass DuplicatesPipeline(object): def __init__(self): self.links =set() def process_item(self, item, spider): if item['link']in self.links: # 跑出DropItem表示丢掉数据 raiseDropItem("Duplicate item found: %s" % item) else: self.links.add(item['link']) return item最后可以定义一个保存数据的管道,可以把数据保存到数据库中from scrapy.exceptions import DropItemfrom Database import Databaseclass DatabasePipeline(object): def __init__(self): self.db = Database def process_item(self, item, spider): ifself.db.item_exists(item['id']): self.db.update_item(item) else: self.db.insert_item(item)定义好管道之后我们需要配置到爬虫上,我们在settings.py模块中配置,后面的数字表示管道的顺序ITEM_PIPELINES ={ 'pipelines.DuplicatesPipeline.DuplicatesPipeline': 1,'pipelines.PretreatmentPipeline.PretreatmentPipeline': 2,}我们也可以为spider配置单独的pipelineclass TestSpider(Spider): # 自定义配置 custom_settings ={ # item处理管道'ITEM_PIPELINES':{ 'tutorial.pipelines.FangDetailPipeline.FangDetailPipeline': 1, }, } ...除了process_item方法外,pipeline还有open_spider和spider_closed两个方法,在爬虫启动和关闭的时候调用七、Rule爬虫的通常需要在一个网页里面爬去其他的链接,然后一层一层往下爬,scrapy提供了LinkExtractor类用于对网页链接的提取,使用LinkExtractor需要使用CrawlSpider爬虫类中,CrawlSpider与Spider相比主要是多了rules,可以添加一些规则,先看下面这个例子,爬取链家网的链接from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass LianjiaSpider(CrawlSpider): name = "lianjia" allowed_domains = [""] start_urls = [ "/ershoufang/" ] rules = [ # 匹配正则表达式,处理下一页Rule(LinkExtractor(allow=(r'/ershoufang/pg/s+$', )), callback='parse_item'), # 匹配正则表达式,结果加到url列表中,设置请求预处理函数# Rule(FangLinkExtractor(allow=('/client/', )), follow=True, process_request='add_cookie') ] def parse_item(self, response): # 这里与之前的parse方法一样,处理 pass1. Rule对象Role对象有下面参数link_extractor:链接提取规则callback:link_extractor提取的链接的请求结果的回调cb_kwargs:附加参数,可以在回调函数中获取到follow:表示提取的链接请求完成后是否还要应用当前规则(boolean),如果为False则不会对提取出来的网页进行进一步提取,默认为False process_links:处理所有的链接的回调,用于处理从response提取的links,通常用于过滤(参数为link列表)process_request:链接请求预处理(添加header或cookie等)2. LinkExtractorLinkExtractor常用的参数有:allow:提取满足正则表达式的链接deny:排除正则表达式匹配的链接(优先级高于allow)allow_domains:允许的域名(可以是str或list)deny_domains:排除的域名(可以是str或list)restrict_xpaths:提取满足XPath选择条件的链接(可以是str或list) restrict_css:提取满足css选择条件的链接(可以是str或list) tags:提取指定标签下的链接,默认从a和area中提取(可以是str 或list)attrs:提取满足拥有属性的链接,默认为href(类型为list)unique:链接是否去重(类型为boolean)process_value:值处理函数(优先级大于allow)关于LinkExtractor的详细参数介绍见官网注意:如果使用rules规则,请不要覆盖或重写CrawlSpider的parse 方法,否则规则会失效,可以使用parse_start_urls方法八、Middleware从最开始的流程图可以看到,爬去一个资源链接的流程,首先我们配置spider相关的爬取信息,在启动爬取实例后,scrapy_engine从Spider取出Request(经过SpiderMiddleware),然后丢给Scheduler(经过SchedulerMiddleware),Scheduler接着把请求丢给Downloader(经过DownloadMiddlware),Downloader把请求结果丢还给Spider,然后Spider把分析好的结构化数据丢给Pipeline,Pipeline进行分析保存或丢弃,这里面有4个角色scrapy有下面三种middlewaresSpiderMiddleware:通常用于配置爬虫相关的属性,引用链接设置,Url 长度限制,成功状态码设置,爬取深度设置,爬去优先级设置等 DownloadMiddlware:通常用于处理下载之前的预处理,如请求Header (Cookie,User-Agent),登录验证处理,重定向处理,代理服务器处理,超时处理,重试处理等SchedulerMiddleware(已经废弃):为了简化框架,调度器中间件已经被废弃,使用另外两个中间件已经够用了1. SpiderMiddleware爬虫中间件有下面几个方法process_spider_input:当response通过spider的时候被调用,返回None(继续给其他中间件处理)或抛出异常(不会给其他中间件处理,当成异常处理)process_spider_output:当spider有item或Request输出的时候调动process_spider_exception:处理出现异常时调用process_start_requests:spider当开始请求Request的时候调用下面是scrapy自带的一些中间件(在scrapy.spidermiddlewares命名空间下)UrlLengthMiddlewareRefererMiddlewareOffsiteMiddlewareHttpErrorMiddlewareDepthMiddleware我们自己实现一个SpiderMiddleware为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请大数据领域具有多年经验的讲师,提高教学的整体质量与教学水准。