计量经济学(第二版)赵卫亚编著__习题答案第_三章
计量经济学第二版课后习题答案1-8章 - 编辑版
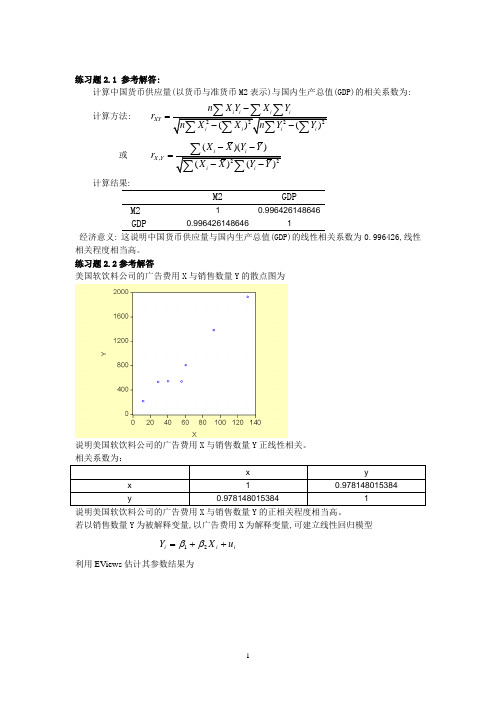
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学教程赵卫亚课后答案

第二章 回归模型思考与练习参考答案2.1参考答案⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。
现实经济中,这些假定难以成立。
要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。
⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。
参数估计的均方误为 MSE ()i i b b ˆ=E ()2ˆi i b b -=D ()i b ˆ=()[]iiu 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。
而参数估计的方差又源于总体方差。
因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。
⑶答:总体回归模型 ()i i i x y E y ε+=样本回归模型i i i e yy +=ˆ i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值()i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i yˆ的偏差。
在概念上类似于i ε,是对i ε的估计。
⑷对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。
但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。
(5)答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。
()()()kk n R R k n Model Total k Model k m Error k Model F 111122--∙-=---=--= 由02>∂∂R F 可知,F 是2R 的单调增函数。
对每一个临界值∂F ,都可以找到一个2∂R 与之对应,当22∂>R R 时便有∂>F F 。
(6)答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。
计量经济学第二版课后习题1-14章中文版答案汇总

第四章习题 1.(1)22ˆ=TSR estScore T =520.4-5.82×22=392.36 (2)ΔTestScore=-5.82×(23-19)=-23.28即平均测试成绩所减少的分数回归预测值为23.28。
(3)core est S T =βˆ0 +βˆ1×CS =520.4-5.82×1.4=395.85 (4)SER 2=∑=-n i u n 1ˆ21i 2=11.5 ∴SSR=∑=ni u1ˆi2=SER 2×(n-2)=11.5×(100-2)=12960.5R 2=T SS ESS =1-T SSSSR =0.08∴TSS=SSR ÷(1-R 2)=12960.5÷(1-0.08)=14087.5=21)(Y ∑=-ni iY∴s Y 2=1-n 121)(Y ∑=-ni iY =14087.5÷(100-1)≈140.30∴s Y ≈11.93 2. (1)①70ˆ=Height eight W =-99.41+3.94×70=176.39 ②65ˆ=Height eight W =-99.41+3.94×65=156.69 ③74ˆ=Height eight W=-99.41+3.94×74=192.15(2)ΔWeight=3.94×1.5=5.91(3)1inch=2.54cm,1lb=0.4536kg①eight Wˆ(kg)=-99.41×0.4536+54.24536.0×94.3Height(cm)=-45.092+0.7036×Height(cm)②R 2无量纲,与计量单位无关,所以仍为0.81③SER=10.2×0.4536=4.6267kg 3.(1)①系数696.7为回归截距,决定回归线的总体水平②系数9.6为回归系数,体现年龄对周收入的影响程度,每增加1岁周收入平均增加$9.6 (2)SER=624.1美元,其度量单位为美元。
计量经济学教程赵卫亚课后答案

第二章 回归模型思考与练习参考答案2.1参考答案⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。
现实经济中,这些假定难以成立。
要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。
⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。
参数估计的均方误为 MSE ()i i b b ˆ=E ()2ˆi i b b -=D ()i b ˆ=()[]iiu 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。
而参数估计的方差又源于总体方差。
因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。
⑶答:总体回归模型 ()i i i x y E y ε+=样本回归模型i i i e yy +=ˆ i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值()i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i yˆ的偏差。
i e 在概念上类似于i ε,是对i ε的估计。
⑷对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。
但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。
(5)答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。
()()()kk n R R k n Model Total k Model k m Error k Model F 111122--•-=---=--= 由02>∂∂RF 可知,F 是2R 的单调增函数。
对每一个临界值∂F ,都可以找到一个2∂R 与之对应,当22∂>R R 时便有∂>F F 。
(6)答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。
计量经济学各章作业习题后附答案

《计量经济学》习题集第一章绪论一、单项选择题1、变量之间的关系可以分为两大类,它们是【】A 函数关系和相关关系B 线性相关关系和非线性相关关系C 正相关关系和负相关关系D 简单相关关系和复杂相关关系2、相关关系是指【】A 变量间的依存关系B 变量间的因果关系C 变量间的函数关系D 变量间表现出来的随机数学关系3、进行相关分析时,假定相关的两个变量【】A 都是随机变量B 都不是随机变量C 一个是随机变量,一个不是随机变量D 随机或非随机都可以4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】A 总量数据B 横截面数据C平均数据 D 相对数据5、下面属于截面数据的是【】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值6、同一统计指标按时间顺序记录的数据列称为【】A 横截面数据B 时间序列数据C 修匀数据 D原始数据7、经济计量分析的基本步骤是【】A 设定理论模型?收集样本资料?估计模型参数?检验模型B 设定模型?估计参数?检验模型?应用模型C 个体设计?总体设计?估计模型?应用模型D 确定模型导向?确定变量及方程式?估计模型?应用模型8、计量经济模型的基本应用领域有【】A 结构分析、经济预测、政策评价B 弹性分析、乘数分析、政策模拟C 消费需求分析、生产技术分析、市场均衡分析D 季度分析、年度分析、中长期分析9、计量经济模型是指【】A 投入产出模型B 数学规划模型C 包含随机方程的经济数学模型D 模糊数学模型10、回归分析中定义【】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】A. 计量经济学准则 B 经济理论准则C 统计准则D 统计准则和经济理论准则12、理论设计的工作,不包括下面哪个方面【】A 选择变量B 确定变量之间的数学关系C 收集数据D 拟定模型中待估参数的期望值13、计量经济学模型成功的三要素不包括【】A 理论B 应用C 数据D 方法14、在经济学的结构分析中,不包括下面那一项【】A 弹性分析B 乘数分析C 比较静力分析D 方差分析二、多项选择题1、一个模型用于预测前必须经过的检验有【】A 经济准则检验B 统计准则检验C 计量经济学准则检验D 模型预测检验E 实践检验2、经济计量分析工作的四个步骤是【】A 理论研究B 设计模型C 估计参数D 检验模型E 应用模型3、对计量经济模型的计量经济学准则检验包括【】A 误差程度检验B 异方差检验C 序列相关检验D 超一致性检验E 多重共线性检验4、对经济计量模型的参数估计结果进行评价时,采用的准则有【】A 经济理论准则B 统计准则C 经济计量准则D 模型识别准则E 模型简单准则三、名词解释1、计量经济学2、计量经济学模型3、时间序列数据4、截面数据5、弹性6、乘数四、简述1、简述经济计量分析工作的程序。
计量经济学(第二版)第三章课后习题答案
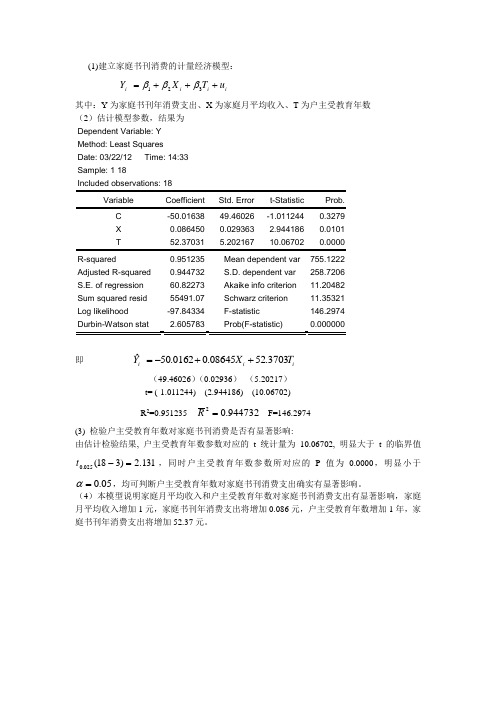
(1)建立家庭书刊消费的计量经济模型: i i i i u T X Y +++=321βββ其中:Y 为家庭书刊年消费支出、X 为家庭月平均收入、T 为户主受教育年数 (2)估计模型参数,结果为Dependent Variable: Y Method: Least Squares Date: 03/22/12 Time: 14:33 Sample: 1 18Included observations: 18C -50.01638 49.46026 -1.011244 0.3279 X 0.086450 0.029363 2.944186 0.0101 R-squared0.951235 Mean dependent var 755.1222 Adjusted R-squared 0.944732 S.D. dependent var 258.7206 S.E. of regression 60.82273 Akaike info criterion 11.20482 Sum squared resid 55491.07 Schwarz criterion 11.35321 Log likelihood -97.84334 F-statistic 146.2974 Durbin-Watson stat2.605783 Prob(F-statistic)0.000000即 i i iT X Y 3703.5208645.00162.50ˆ++-= (49.46026)(0.02936) (5.20217)t= (-1.011244) (2.944186) (10.06702) R 2=0.951235 944732.02=R F=146.2974(3) 检验户主受教育年数对家庭书刊消费是否有显著影响:由估计检验结果, 户主受教育年数参数对应的t 统计量为10.06702, 明显大于t 的临界值131.2)318(025.0=-t ,同时户主受教育年数参数所对应的P 值为0.0000,明显小于05.0=α,均可判断户主受教育年数对家庭书刊消费支出确实有显著影响。
计量经济学(第二版)第三章习题答案

1)建立家庭书刊消费的计量经济模型: i i i i u T X Y +++=321βββ其中:Y 为家庭书刊年消费支出、X 为家庭月平均收入、T 为户主受教育年数 (2)估计模型参数,结果为即 i ii T X Y 3703.5208645.00162.50ˆ++-= (49.46026)(0.02936) (5.20217) t= (-1.011244) (2.944186) (10.06702) R 2=0.951235 944732.02=R F=146.2974(3) 检验户主受教育年数对家庭书刊消费是否有显著影响:由估计检验结果, 户主受教育年数参数对应的t 统计量为10.06702, 明显大于t 的临界值131.2)318(025.0=-t ,同时户主受教育年数参数所对应的P 值为0.0000,明显小于05.0=α,均可判断户主受教育年数对家庭书刊消费支出确实有显著影响。
(4)本模型说明家庭月平均收入和户主受教育年数对家庭书刊消费支出有显著影响,家庭月平均收入增加1元,家庭书刊年消费支出将增加0.086元,户主受教育年数增加1年,家庭书刊年消费支出将增加52.37元。
Dependent Variable: LNYMethod: Least SquaresDate: 03/21/12 Time: 23:11Sample: 1970 1982Variable Coefficient Std. Error t-Statistic Prob.C 2.899899 0.500289 5.796453 0.0002LNX2 -1.205700 0.320662 -3.760041 0.0037R-squared 0.849114 Mean dependent var 1.974525 Adjusted R-squared 0.818937 S.D. dependent var 0.408050 S.E. of regression 0.173631 Akaike info criterion -0.464591 Sum squared resid 0.301478 Schwarz criterion -0.334218 Log likelihood 6.019839 F-statistic 28.13760 Durbin-Watson stat 1.822175 Prob(F-statistic) 0.000078。
计量经济学(第二版)赵卫亚编著__习题答案第_三章

(3)对于双对数模型,分别取权数变量为 W1=1/P、W2=1/RESID^2, 利用 WLS 方法重新估 计模型,分析模型中异方差性的校正情况。 表2 部门 容器与包装 非银行业金融 服务行业 金属与采矿 住房与建筑 一般制造业 休闲娱乐 纸张与林木产品 食品 卫生保健 宇航 消费者用品 电器与电子产品 化工产品 五金 办公设备与计算机 燃料 汽车 R&D 费用 Y 62.5 92.9 178.3 258.4 494.7 1083.0 1620.6 421.7 509.2 6620.1 3918.6 1595.3 6107.5 4454.1 3163.8 13210.7 1703.8 9528.2 销售额 S 6375.3 11626.4 14655.1 21869.2 26408.3 32405.6 35107.7 40295.4 70761.6 80552.8 95294.0 101314.1 116141.3 122315.7 141649.9 175025.8 230614.5 293543.0 利润 P 185.1 1569.5 276.8 2828.1 225.9 3751.9 2884.1 4645.7 5036.4 13869.9 4487.8 10278.9 8787.3 16438.8 9761.4 19774.5 22626.6 18415.4
p 0.0046 p 0.3401
ˆ 7.04 1.2453ln S 0.0619ln P ln y
t= (3.41) (0.24)
R2 0.7954
nr2 4.52 ,
线性模型经检验存在异方差性,2 个解释变量都不显著;而双对数模型经检验不存在异方差性,解 释变量中销售量 S 的影响显著。表明模型函数形式的选择会影响模型的异方差性。 (2)White 检验统计量的伴随概率为 0.0046<0.05,表明线性模型存在异方差性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
得到:
| eI | 0.0353 0.0199X i ,
F=18.16,p=0.00047 F=17.93,p=0.0005 F=16.16,p=0.0008 F=7.05,p=0.02 F=3.79,p=0.067
| eI | 0.5805 0.0001X i2 , | eI | 1.2504 0.3265X i1 / 2 ,
同,所以可以通过分析 Y 的取值特征判断异方差性或自相关性。 (2)误差项和残差项都是反映了模型中解释变量之外其他因素的综合影响,所以可以将误差项 视为随机误差项的近似估计,通过残差分析推断随机误差项的分布特征。
3.8 表 1 中列出了 1995 年北京市规模最大的 20 家百货零售商店的商品销售收入 X 和销售利润 Y 的 统计资料(单位:千万元) 。 (1)根据 Y、X 的相关图分析异方差性; (2)利用 White 检验、Park 检验和 Gleiser 检验进行异方差性检验; (3)利用 WLS 方法估计利润函数。 表1 商店名称 百货大楼 城乡贸易中心 西单商场 蓝岛大厦 燕莎友谊商场 东安商场 双安商场 赛特购物中心 西单购物中心 复兴商业城 解: (1)键入:SCAT X 销售 销售 商店名称 收入 利润 160.0 2.8 贵友大厦 151.8 8.9 金伦商场 108.1 4.1 隆福大厦 102.8 2.8 友谊商业集团 89.3 8.4 天桥百货商场 68.7 4.3 百盛轻工公司 66.8 4.0 菜市口百货商场 56.2 4.5 地安门商场 55.7 3.1 新街口百货商场 53.0 2.3 星座商厦 Y,得到 Y 与 X 的相关图: 销售 收入 49.3 43.0 42.9 37.6 29.0 27.4 26.2 22.4 22.2 20.7 销售 利润 4.1 2.0 1.3 1.8 1.8 1.4 2.0 0.9 1.0 0.5
| eI | 2.2658 45.8763(1 / X i ) ,
| eI | 1.6651 657.95(1 / X i2 ) ,
| eI | 3.4731 15.5396(1 / X i1 / 2 ) , F=9.73,p=0.0059
只要取显著水平α >0.067,所有函数关系都是显著的,所以存在异方差性;其中,由于第一个方程 的 F 统计量值最大,所以 6 个方程中以线性关系最为显著。
解: (1)观察 Y 与 S、lnY 与 lnS 的相关图可知,线性模型的异方差性比双对数模型更加明显。
分别估计线性模型和双对数模型,并进行 White 检验,有关结果为:
ˆ 13.96 0.0126S 0.2398P y
t= (0.70) (1.21)
R2 0.5245
nr 2 15.06 ,
W3 1 / | ei |
W4 1 / ei2
GENR GENR
W3=1/E1 W4=1/E2
然后键入命令依次估计不同权数变量的模型,得到以下估计结果: ① ② ③ ④
ˆ 0.6260 0.0711x y ˆ 0.1573 0.0559x y ˆ 0.7077 0.0388x y ˆ 0.5919 0.0429x y
ˆ ) 原有的计算公式一般会过低估计系数的误差, ˆ) ˆ / S (b ˆ) , S ( b 模型存在自相关性时, 根据 S ( b 而t b
的估计偏低将会导致 t 统计量的偏高, 这样很有可能使得真实的 | t | t / 2 变成 | t | t / 2 ,即错误的拒 绝了 b=0 的原假设;所以,容易将不重要的解释变量误认为有显著影响的变量。 3.5 如何用 DW 统计量检验自相关性?DW 检验有哪些局限性?
- 17 -
(3)权数变量取成: 根据 Park 检验结果,取: W1 1 / X i
1.8394
,
GENR W1=1/X^1.8394 GENR W2=1/X
根据 Gleiser 检验结果,取: W2 1 / X i ,
另外,用残差直接估计总体方差(利用前述已经计算出的 E1、E2) :
ˆX i 得到: ei a
2
1.8394
,F=10.37,F 统计量的伴随概率 p=0.005,函数关系显著,所以存在异方差性。
Gleiser 检验:分别键入以下命令: LS E1 C X LS E1 C X^2 LS E1 C X^(1/2) LS E1 C 1/X LS E1 C 1/X^2 LS E1 C 1/X^(1/2)
ˆ ) ,所以可以根据 DW 的值是(显著的)接近于 0 或者 4、或者接近于 2 来 答:由于 DW 2(1
判断是否存在自相关性。 局限性: 只能检验是否存在一阶自相关性, 检验过程存在无法判断的“盲区”, 不适用于自回归模型。
- 15 -
3.6 利用广义差分法消除自相关性的不利影响时,为什么采用了迭代估计? 答:对变量进行广义差分变换时,需要事先知道随机误差项各期的相关系数,而这些值是未知的, 只能用迭代估计的方法进行近似估计。
- 16 -
从相关图可以明显看出,随着 X 值的增大、Y 的波动幅度也在逐渐增大,即可能存在(递增型的) 异方差性。 (2)异方差性检验 White 检验:在方程窗口中,利用 View 菜单下的残差检验,得到 white 的检验结果:
卡方统计量=8.41,伴随概率=0.015<0.05,所以拒绝同方差的原假设,模型存在异方差性。 Park 检验:分别键入以下命令: LS Y C X GENR E1=abs(RESID) GENR E2=RESID^2 LS log(E2) C log(X)
3.7 异方差性和自相关性都是关于随机误差项的性质,但是, (1)为什么通过对被解释变量 Y 取值情况的分析,可以大致判断模型是否存在异方差性或自相 关性? (2)为什么是通过残差分析来检验模型的异方差性和自相关性? 答: (1)因为 D( i ) D( yi ) ,
COV ( i , j ) COV ( yi , y j ) ,随机误差项与 Y 的方差、协方差相: | ei | 0 1 xih vi
3.3 利用WLS估计消除异方差性的不利影响时,为什么需要构造多个权数变量进行调试? 答:根据WLS估计的要求,权数变量应该取成 wi 1 / D( i ) 1 / i ;但是随机误差项的方差是未知
第三章
3.1 什么是异方差性?异方差性对模型的 OLS 估计有何影响? 答: D( i ) i2 常数,主要影响:OLS 估计非有效估计,难以估算系数的估计误差,t 检验可靠 性降低。
3.2 检验异方差性的 G-Q 检验和 White 检验的原理是否相同?试述 White 检验、Park 检验和 Gleiser 检验的异同之处。 答: (1)G-Q 检验和 White 检验的原理不同,前者通过比较分段回归残差的差异性推断异方差性, 后者通过建立辅助回归模型判断异方差性。 (2)White 检验、Park 检验和 Gleiser 检验:相同点:都是利用辅助回归模型、通过检验残差的波动 与解释变量是否相关来判断异方差性;不同点:所建立的辅助回归模型不同。 White 检验: ei2 0 1 xi 2 xi2 vi Park 检验: 二次函数 指数函数 6 个可线性化函数
- 18 -
(3)对于双对数模型,分别取权数变量为 W1=1/P、W2=1/RESID^2, 利用 WLS 方法重新估 计模型,分析模型中异方差性的校正情况。 表2 部门 容器与包装 非银行业金融 服务行业 金属与采矿 住房与建筑 一般制造业 休闲娱乐 纸张与林木产品 食品 卫生保健 宇航 消费者用品 电器与电子产品 化工产品 五金 办公设备与计算机 燃料 汽车 R&D 费用 Y 62.5 92.9 178.3 258.4 494.7 1083.0 1620.6 421.7 509.2 6620.1 3918.6 1595.3 6107.5 4454.1 3163.8 13210.7 1703.8 9528.2 销售额 S 6375.3 11626.4 14655.1 21869.2 26408.3 32405.6 35107.7 40295.4 70761.6 80552.8 95294.0 101314.1 116141.3 122315.7 141649.9 175025.8 230614.5 293543.0 利润 P 185.1 1569.5 276.8 2828.1 225.9 3751.9 2884.1 4645.7 5036.4 13869.9 4487.8 10278.9 8787.3 16438.8 9761.4 19774.5 22626.6 18415.4
R2 0.5733, R2 0.0106, R2 0.9458, R2 0.9950,
nr2 2.08 , nr2 2.87 , nr2 1.10 , nr2 1.82 ,
p 0.3534 p 0.2381 p 0.5769 p 0.4022
因为 4 个模型 White 检验统计量的 p 值均>0.05,即模型经过 WLS 估计都消除了异方差性;进一步 再比较 R2 得知,模型④的拟合优度最高,所以取该模型为最终估计模型。 3.9 设根据某年全国各地区的统计资料建立城乡居民储蓄函数 Si a bX i i 时(其中,S 为城乡 居民储蓄存款余额,X 为人均收入) ,如果经检验得知: ei2 1.8 X i2 , (1)试说明该检验结果的经济含义; (2)写出利用加权最小二乘法估计储蓄函数的具体步骤; (3)写出使用 EViews 软件估计模型时的有关命令。 解: (1)根据 Park 检验原理得知,模型存在着异方差性,其经济含义为:我国城镇居民各地区储蓄 存款的波动幅度不同,而且收入越高的地区,存款波动的幅度越大。 (2) D( i ) ei2 1.8 X i2