SPSS 描述性分析解析
第3章 SPSS描述性统计分析

Step01 打开主窗口
选择菜单栏中的【Analyze(分析)】→ 【Descriptive Statistics(描述性统计)】 →【Explore(探索)】命令,弹出【Explor e(探索)】对话框,该对话框是探索性分析的 主操作窗口。
Step02 选择分析变量
在【Explore(探索)】对话框左侧的【候选变 量】清单中,选取一个或多个待分析变量, 将它们移入右侧的【Dependent List(因 变量列表)】列表框中,表示要进行探索性 分析的变量。
3.2.2 描述统计分析的SPSS操作详解
Descriptives 过程是连续资料统计描述应用 最多的一个过程,它可对变量进行描述性统 计分析计算,并列出一系列相应的统计指标。 这和其他过程相比并无不同。但该过程还有 个特殊功能,就是可将原始数据转换成标准 化值,并以变量的形式保存。
Step01:打开主窗口
Step04 选择标签值
从候选变量列表框中选择一个变量作为标识变 量,并将其移入【Label Cases by(标注 个案)】列表框中。选择标识变量的作用在 于,若系统在数据探索时发现异常值,便可 利用标识变量加以标记,便于用户找这些异 常值。如果不选择它,系统默认以id变量作 为标识变量。
Step05 选择输出类型
Step04:选择输出图形类型
Step05:完成操作
(1)基本统计结果输出
频数分析基本统计结果
N Percentiles
Valid Missing 25 50 75
38 0 18.00 20.00 23.00
表3-2 频数分析表
(2)频数分析表输出
频数分析表
Valid
14 15 16 17 18 19 20 21 22 23 24 26 27 Tota l
SPSS统计分析方法及应用解析

SPSS统计分析方法及应用解析SPSS(统计软件包社会科学)是一种用于统计分析的软件包,广泛应用于社会科学领域,包括心理学、教育学、经济学等。
它提供了各种统计分析方法和功能,可以帮助研究人员从数据中提取有用的信息,并生成统计报告和图表。
本文将介绍一些常用的SPSS统计分析方法及其应用。
1.描述性统计分析描述性统计分析是对数据进行整体概括和描述的方法,包括计算平均值、标准差、频数和百分比等。
研究人员可以通过SPSS进行描述性统计分析,了解数据的分布情况和基本特征,为后续的统计推断提供基础。
2.t检验t检验是一种用于比较两个样本均值差异是否显著的方法。
SPSS提供了独立样本t检验和配对样本t检验两种方法。
研究人员可以根据实际研究设计选择适当的方法,通过SPSS计算得出t值和p值,以判断两组样本均值差异是否显著。
3.方差分析方差分析是一种用于比较两个或多个样本均值差异是否显著的方法。
SPSS提供了单因素方差分析和多因素方差分析两种方法。
研究人员可以通过SPSS计算得出方差分析表和p值,以判断不同组别之间的均值差异是否显著。
4.相关分析相关分析是一种用于研究两个或多个变量之间关系强度和方向的方法。
SPSS提供了皮尔逊相关系数和斯皮尔曼相关系数两种方法。
研究人员可以通过SPSS计算得出相关系数和p值,以判断变量之间的关系是否显著。
5.回归分析回归分析是一种用于研究自变量与因变量之间关系的方法。
SPSS提供了线性回归、多元回归和逐步回归等方法。
研究人员可以通过SPSS计算得出回归方程和回归系数,以预测因变量的值,并评估自变量对因变量的影响程度。
6.因子分析因子分析是一种用于降维和归纳分析多个变量之间的相关性的方法。
SPSS提供了主成分分析和因子分析两种方法。
研究人员可以通过SPSS计算得出因子载荷和因子得分,以解释变量之间的共性和变异。
此外,SPSS还提供了聚类分析、判别分析、生存分析等其他统计分析方法,以满足研究人员对不同问题的需求。
SPSS描述性统计分析PPT课件

LOGO
4.4 探索性分析
打开“统计量”对话框,选中“描述性”及“M-估计量” 选项; 打开“探索:图”对话框,选中“按因子水平分组”、“ 茎叶图”、“带检验的正态图”等选项。 打开“探索:选项”,选中“按列表排除个案”选项。
第3步 运行结果及分析: “成绩”按科目分组的案例处理摘要表
表中显示“成绩”按 “科目”分组后各组的 有效个案数、个案缺失 数及缺失比例等 。
打开“频率(F)”对话框,将“教育”和 “收入”加入到“变量”列表框中。 打开“统计量”对话框,选中“百分位数”
“众数”,并在“百分位数”中添加30.0、 60.0、90.0; 打开“图表”对话框,选中“直方图”及后 面的复选框
LOGO 表4.1
4.2 频率分析
第3步 主要结果及分析:
统计量表
LOGO
4.1 基本描述性统计量的定义及计算
4.1.2 描述离散程度的统计量பைடு நூலகம்
1.样本方差(Variance) 2.样本标准差(Std. deviation) 3.极差(Range) 4.均值标准误差(Standard Error of Mean)
LOGO
4.1 基本描述性统计量的定义及计算
4.1.3 描述总体分布形态的统计量
例如,调查消费者拥有数码产品的数量,首先分析受访 者的总人数、家庭收入情况、受教育程度、性别等,获取样 本是否具有总体代表性、抽样是否存在系统偏差等信息。这 些可以通过频率分析来实现,经过频率分析可以得到如下结 果: (1)频率分布表:该表中包含频率、各频率占总样本数的 百分比、有效百分比、累计百分比。 (2)统计图:用统计图形展示变量的取值状况,频率分析 中提供的统计图形可以是条形图、饼图或者直方图。
SPSS常见数据分析方法比较

SPSS常见数据分析方法比较SPSS(Statistical Package for the Social Sciences)是一种流行的统计分析软件,被广泛应用于社会科学研究和商业分析领域。
SPSS提供了各种数据分析方法,帮助用户从数据中提取有用的信息和洞察。
本文将介绍SPSS中常见的数据分析方法,并进行比较。
一、描述性统计分析描述性统计分析是在数据收集和处理阶段非常重要的一步。
通过计算变量的均值、中位数、标准差、最大值、最小值等指标,了解数据的基本分布情况。
SPSS提供了丰富的描述性统计分析方法,包括频数分析、分布分析、交叉报表等。
这些方法可以帮助用户对数据进行初步的分析和认识,为后续的数据分析提供基础。
二、假设检验假设检验是统计分析中常用的方法,用于判断样本数据与总体参数之间的差异是否显著。
SPSS提供了多种假设检验方法,包括t检验、方差分析(ANOVA)、卡方检验等。
这些方法可以帮助用户进行单样本或多样本的假设检验,判断不同组别的数据是否存在显著差异,从而提供统计依据。
三、相关分析相关分析用于研究两个或多个变量之间的关系。
SPSS提供了多种相关分析方法,包括Pearson相关系数分析、Spearman相关系数分析、回归分析等。
这些方法可以帮助用户判断两个变量之间的线性或非线性关系,揭示变量之间的相互关联。
四、回归分析回归分析是一种用于研究因变量与自变量之间关系的统计方法。
SPSS提供了多种回归分析方法,包括线性回归、逻辑回归、多元回归等。
这些方法可以帮助用户建立数学模型,预测因变量的取值,并判断自变量对因变量的影响程度。
五、因子分析因子分析是一种用于探索性因素之间关系的统计方法。
SPSS提供了多种因子分析方法,包括主成分分析、因子旋转等。
这些方法可以帮助用户降维处理多个相关变量,提取出共同因子,并理解变量之间的结构关系。
六、聚类分析聚类分析是一种将个体或对象进行分类的方法,将相似的个体或对象归为一类,不相似的个体或对象归为不同类。
SPSS描述性统计分析
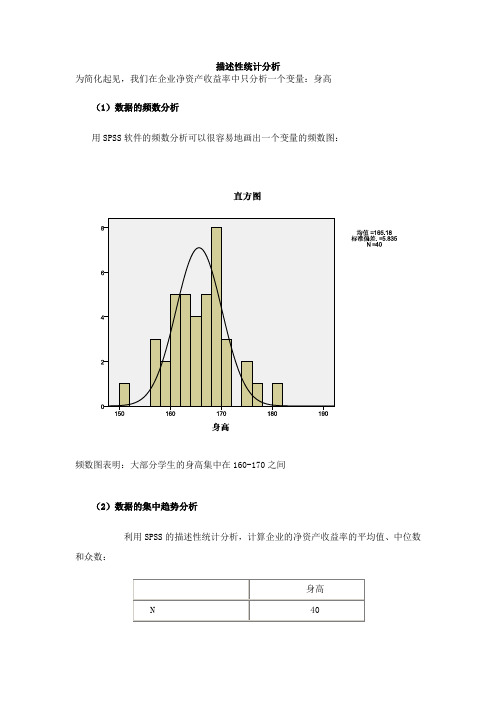
描述性统计分析
为简化起见,我们在企业净资产收益率中只分析一个变量:身高
(1)数据的频数分析
用SPSS软件的频数分析可以很容易地画出一个变量的频数图:
频数图表明:大部分学生的身高集中在160-170之间
(2)数据的集中趋势分析
利用SPSS的描述性统计分析,计算企业的净资产收益率的平均值、中位数和众数:
共有40名学生被调查者参与了全国的平均身高的调查;身高均值(Mean)165.18、中位数(Median)165.5、众数(Mode)168;总体满意度均值、中位数、众数,与前面的频数分析结果差异很小。
(3)数据的离散程度和分布分析:
同样利用SPSS软件的描述性统计分析,可以得出企业的净资产收益率的离散程度和分布指标:
身高的标准差(Std. Deviation) 5.835、方差(Variance)34.046;“身高”标准差5.835、方差34.046,说明不同样本对变量打分的差异程度很大。
“身高”变量的偏度(Skewness)0.098,右偏;峰度(Kurtosis)0.401,尖顶峰度;“身高”变量偏度0.098、峰度0.401,说明数据不符合正态分布
(注:专业文档是经验性极强的领域,无法思考和涵盖全面,素材和资料部分来自网络,供参考。
可复制、编制,期待你的好评与关注)。
SPSS数据分析—描述性统计分析

SPSS数据分析—描述性统计分析描述性统计分析是一种针对数据本身的分析方法,通过使用统计学指标来描述数据的特征。
这种分析方法看似简单,但实际上却是许多高级分析的基础工作。
很多高级分析方法都对数据有一定的假设和适用条件,这些可以通过描述性统计分析来判断。
我们也会发现,许多分析方法的结果中都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三个方面:集中趋势、离散趋势和数据分布情况。
描述集中趋势的指标包括均值、众数和中位数,其中均值包括截尾均值、几何均值和调和均值等。
描述离散趋势的指标包括频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数和变异系数等。
需要注意的是,连续型变量和离散型变量的指标有所不同。
由于许多统计分析都有一个正态分布的假设,因此我们经常关注数据的分布特征。
常用峰度系数和偏度系数来描述数据偏离正态分布的程度。
也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值。
SPSS用于描述性统计分析的过程大部分都在分析-描述统计菜单中,另有一个在比较均值-均值菜单。
虽然这几个过程用途不同,但基本上都可以输出常用的指标结果。
分析-描述统计-频率过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值。
此外,该过程最主要的作用是输出频数表。
分析-描述统计-描述过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
分析-描述统计-探索过程是在原有数据进行描述性统计的基础上,更进一步的描述数据。
与前两种过程相比,它能提供更详细的结果。
分析-描述统计-比率过程主要用于对两个连续变量间的比率进行描述分析。
输出的结果比较简单,只是指标的汇总表格。
分析-描述统计-交叉表过程主要用于分类变量的描述性统计。
它可以完成频数分布和构成比的分析,也经常被用来做列联表的推断分析。
SPSS数据分析—描述性统计分析

描述性统计分析是针对数据本身而言,用统计学指标描述其特征的分析方法,这种描述看似简单,实际上却是很多高级分析的基础工作,很多高级分析方法对于数据都有一定的假设和适用条件,这些都可以通过描述性统计分析加以判断,我们也会发现,很多分析方法的结果中,或多或少都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三大内容:1.集中趋势2.离散趋势3.数据分布情况描述集中趋势的指标有均值、众数、中位数,其中均值包括截尾均值、几何均值、调和均值等。
描述离散趋势的指标有频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数、变异系数等。
注意:连续型变量和离散型变量的指标有所不同。
由于很多统计分析都有一个正态分布的假设,因此我们经常也会关注数据的分布特征,常用峰度系数和偏度系数来描述数据偏离正态分布的程度,也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值SPSS用于描述性统计分析的过程大部分都在分析—描述统计菜单中,另有一个在比较均值—均值菜单,虽然这几个过程用途不同,但是基本上都可以输出常用的指标结果。
一、分析—描述统计—频率此过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值,此外,该过程最主要的作用是输出频数表,结果举例如下:二、分析—描述统计—描述看起来似乎这个过程才是正统的描述统计分析过程,实际上该过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
三、分析—描述统计—探索探索性分析是对原有数据进行描述性统计的基础上,更进一步的描述数据,和前两种过程相比,它能提供更详细的结果。
四、分析—描述统计—比率该过程主要用于对两个连续变量间的比率进行描述分析输出的结果比较简单,只是指标的汇总表格,在此略去五、分析—描述统计—交叉表分类变量的描述性统计比较简单,主要就是看频数分布和构成比,基本用交叉表一个过程就可以完成,该过程虽然放在描述统计中,但是由于功能丰富,也经常被用来做列联表的推断分析。
在报告中使用SPSS进行描述性统计分析

在报告中使用SPSS进行描述性统计分析引言:描述性统计分析是统计学的基础分析方法之一,它可以通过数值和图表来描述数据的基本特征。
随着科学技术的发展,SPSS(Statistical Product and Service Solutions)软件成为了描述性统计分析的重要工具之一。
本文将探讨在报告中如何使用SPSS进行描述性统计分析,并列出以下六个标题进行详细论述。
一、数据收集与准备数据收集是进行描述性统计分析的首要步骤。
在报告中,我们需要明确数据的来源与采集方法,并进行相关数据的准备和清洗。
使用SPSS软件时,可以利用其提供的数据导入和数据清洗功能,例如删除重复数据、填补缺失值等。
二、数据的中心趋势测度中心趋势测度是描述数据分布的重要指标,主要包括均值、中位数和众数。
在报告中,我们可以通过SPSS软件计算得到这些指标,并通过文字描述和图表展示来展示数据的中心位置,帮助读者更好地理解数据的分布特征。
三、数据的离散程度测度离散程度测度反映了数据的离散程度,常用的指标包括标准差、方差和四分位数间距。
在报告中,我们可以使用SPSS软件计算得到这些指标,并通过文字描述和图表展示来揭示数据的离散程度,帮助读者了解数据的变异情况。
四、数据的分布形态测度分布形态是描述数据分布曲线的特征,常用的指标包括偏度和峰度。
在报告中,我们可以通过SPSS软件计算得到这些指标,并通过文字描述和图表展示来展示数据的分布形态,帮助读者理解数据是否服从特定的分布规律。
五、数据间的关系分析数据间的关系分析能够帮助我们了解变量之间的相关性。
在报告中,我们可以利用SPSS软件进行相关性分析,计算得到相关系数,并通过文字描述和图表展示来展示变量之间的关系。
此外,我们还可以使用SPSS软件进行回归分析和方差分析,探索更深入的变量之间的关系。
六、结果的可视化展示在报告中,除了通过文字描述,更加直观有效的方式是通过图表展示结果。
SPSS软件提供了多种图表类型供我们选择,包括柱状图、折线图、散点图等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
经济与管理学院
第三讲 描述性分析
实验目的 摘要性分析的诸个过程,完成许多统计学 指标,对于计量资料,可完成均数、标准差、 标准误等指标的计算;对于计数和一些等级资 料,可完成构成比率等指标的计算。
2018/11/1
例:30名学生的考试成绩:SPSS练习21 打开【分析】选择【频率】
三 峡 大 学 Frequencies过程(频数分析) 第一节 经济与管理学院
2018/11/1
三峡大学
经济与管理学院
若要做等距分组进行频数描述如何操作? 如分成:60以下 60—70 70—80 80—90 90以上
2018/11/1
三峡大学
经济与管理学院
练习:
某百货公司连续40天的商品销售额如下 (单位:万元)
41 46 35 42 25 36 28 36 29 45 46 37 47 37 34 37 38 37 30 49 34 36 37 39 30 45 44 42 38 43 26 32 43 33 38 36 40 44 44 35
.580 1.121 2.336
Hale Waihona Puke .580 1.121三峡大学
经济与管理学院
第四节 交互分析(crosstabs)
• 基本功能:适用于两个或两个以上变量交叉分类 形成列联表,对变量的关联性进行分析。数量变 量和类别变量都可以进行。 • 常用于检验两类假设,即变量间的独立性假设与 比例一致性假设。 • 独立性假设检验同意群样本在两个变量上的反应, 以判断在总体范围内两变量之间的关系。 • 比例一致性假设检验,首先从两个总体范围内抽 取两个样本(同一总体抽取2个样本),然后根据 两个样本反应推论两个总体是否相同。
(1)根据以上的数据进行适当的分组,编制频数 分布表,并绘制频数分布的直方图; (2)计算适当的统计指标对该百货公司这40天的 销售情况进行描述说明。
2018/11/1
三峡大学
经济与管理学院
多重反应下的频次分析
基本功能:对每一项目对应多个反应(如多项 选择)的数据进行频次分析。 菜单位置:【分析】—【多重响应】—【定义变 量集】—【频率】 例:你主要的新闻渠道包括哪些?(可多选) 1报纸 2 电视 3杂志 4 广播 5互联网 6 朋友/家人 步骤:第一步:录入,把每个选项视为一个变量,变 量的数目与选项的数目相等。最好把每个多选项统 一编码,以便于分析数据。
三峡大学
经济与管理学院
系统以ZCJ为变量名将原始数据转换成标准z 分值,存放在原数据库中,亦即变量的标准化过 程。
2018/11/1
三峡大学
经济与管理学院
第三节 Explore过程(探索分析)
调用此过程可对变量进行更为深入详尽的描 述性统计分析,故称之为探索性统计。 它在一般描述性统计指标的基础上,增加有 关数据其他特征的文字与图形描述,显得更加细 致与全面,有助于用户思考对数据进行进一步分 析的方案。
2018/11/1
三峡大学
经济与管理学院
2018/11/1
度量变量 选择直方 图
名义和序 号变量一 般选择条 形图或饼 图
三峡大学
经济与管理学院
Bootstrap法又称为自助法,是以现 有样本为基础的模拟抽样判断法, 可用于研究某统计量的分布特征, 特别适用于那些难以用常规方法处 理的参数区间估计,假设检验等问 题。其提出是基于参数估计准确性 考察的目的,目前已发展到几乎统 计学所有领域。提供了一条确保所 建模型的稳定性和可靠性的有效途 径,它通过对原始样本进行有放回 的重置抽样,进而估计某个估计量 的抽样分布。
描述统计量
标准 N 全距 极小值 极大值 和 均值 方差 偏度 峰度 差 统计 统计 标准 统计 统计 统计 统计 量 统计量 统计量 统计量 统计量 量 误 量 量 量 标准误 量 标准误 成绩 30 41 51 92 2.E3 74.90 2.01 11.01 121.3 .427 -.599 .833 1 5 34 .283 有效的 N 30 (列表状 2018/11/1 态)
2018/11/1
三峡大学
经济与管理学院
打开【分析】—【描述统计】—【探索】 例:男女各15名学生的考试成绩,试分析成绩与性 别是否有关系。 见SPSS练习21
2018/11/1
描述 SEX 三 峡 大 学 统计量 成绩 男 均值 71.80 经济与管理学院 均值的 95% 置信区间 下 65.04 限 上78.56 限 5% 修整均值 72.11 中值 71.00 方差 148.88 6 标准差 12.202 极小值 51 极大值 87 范围 36 四分位距 20 偏度 -.196 峰度 -1.244 女 均值 78.00 均值的 95% 置信区间 下 72.99 限 上 83.01 限 5% 修整均值 78.00 中值 77.00 方差 81.857 标准差 9.047 极小值 64 极大值 92 范围 28 四分位距 17 2018/11/1 偏度 .310 峰度 -1.082 标准误 3.151
2018/11/1
三峡大学
第二节 Descriptives过程(描述性分析)
调用此过程可对变量进行描述性统计分析, 计算并列出一系列相应的统计指标,且可将原始 数据转换成标准Z分值并存入数据库,所谓Z分值 是指某原始数值比其均值高或低多少个标准差单 位,高的为正值,低的为负值,相等的为零。
经济与管理学院
2018/11/1
三峡大学
经济与管理学院
第二步:【多重响应】—【定义变量集】
2018/11/1
三峡大学
经济与管理学院
第三步:【多重响应】—【定义变量集】—【频率】
$a1 频率 响应 N 获取新闻 报纸 主要渠道a 电视 杂志 广播 互联网 朋友/家人/同事 总计 a. 组 802 794 243 171 1031 145 3186 个案百分 百分比 比 25.2% 72.3% 24.9% 7.6% 5.4% 32.4% 4.6% 100.0% 71.5% 21.9% 15.4% 92.9% 13.1% 287.0%
如:1班分数的均值和标准差分别为78.53和 9.43,而2班的均值和标准差分别为70.19和7.00。 试问1班的90分是不是比2班的82分成绩更好? (Z1=1.22, Z2=1.69)
2018/11/1
x x z s
三峡大学
经济与管理学院
例:30名学生的考试成绩:SPSS练习21 1.打开【分析】—【描述统计】—【描述】