统计回归分析报告
回归分析 实验报告

回归分析实验报告回归分析实验报告引言回归分析是一种常用的统计方法,用于研究两个或多个变量之间的关系。
通过回归分析,我们可以了解变量之间的因果关系、预测未来的趋势以及评估变量对目标变量的影响程度。
本实验旨在通过回归分析方法,探究变量X对变量Y 的影响,并建立一个可靠的回归模型。
实验设计在本实验中,我们选择了一个特定的研究领域,并采集了相关的数据。
我们的目标是通过回归分析,找出变量X与变量Y之间的关系,并建立一个可靠的回归模型。
为了达到这个目标,我们进行了以下步骤:1. 数据收集:我们从相关领域的数据库中收集了一组数据,包括变量X和变量Y的观测值。
这些数据是通过实验或调查获得的,具有一定的可信度。
2. 数据清洗:在进行回归分析之前,我们需要对数据进行清洗,包括处理缺失值、异常值和离群点。
这样可以保证我们得到的回归模型更加准确可靠。
3. 变量选择:在回归分析中,我们需要选择适当的自变量。
通过相关性分析和领域知识,我们选择了变量X作为自变量,并将其与变量Y进行回归分析。
4. 回归模型建立:基于选定的自变量和因变量,我们使用统计软件进行回归分析。
通过拟合回归模型,我们可以获得回归方程和相关的统计指标,如R方值和显著性水平。
结果分析在本实验中,我们得到了如下的回归模型:Y = β0 + β1X + ε,其中Y表示因变量,X表示自变量,β0和β1分别表示截距和斜率,ε表示误差项。
通过回归分析,我们得到了以下结果:1. 回归方程:根据回归分析的结果,我们可以得到回归方程,该方程描述了变量X对变量Y的影响关系。
通过回归方程,我们可以预测变量Y的取值,并评估变量X对变量Y的影响程度。
2. R方值:R方值是衡量回归模型拟合优度的指标,其取值范围为0到1。
R方值越接近1,说明回归模型对数据的拟合程度越好。
通过R方值,我们可以评估回归模型的可靠性。
3. 显著性水平:显著性水平是评估回归模型的统计显著性的指标。
通常,我们希望回归模型的显著性水平低于0.05,表示回归模型对数据的拟合是显著的。
统计学案例——相关回归分析报告
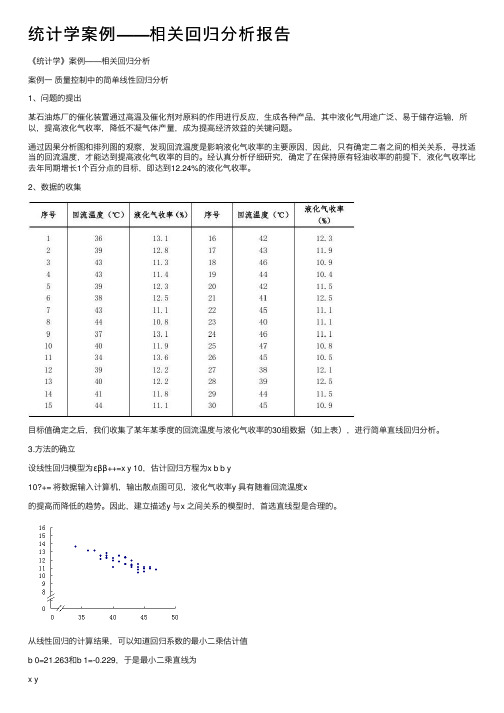
统计学案例——相关回归分析报告《统计学》案例——相关回归分析案例⼀质量控制中的简单线性回归分析1、问题的提出某⽯油炼⼚的催化装置通过⾼温及催化剂对原料的作⽤进⾏反应,⽣成各种产品,其中液化⽓⽤途⼴泛、易于储存运输,所以,提⾼液化⽓收率,降低不凝⽓体产量,成为提⾼经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化⽓收率的主要原因,因此,只有确定⼆者之间的相关关系,寻找适当的回流温度,才能达到提⾼液化⽓收率的⽬的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化⽓收率⽐去年同期增长1个百分点的⽬标,即达到12.24%的液化⽓收率。
2、数据的收集⽬标值确定之后,我们收集了某年某季度的回流温度与液化⽓收率的30组数据(如上表),进⾏简单直线回归分析。
3.⽅法的确⽴设线性回归模型为εββ++=x y 10,估计回归⽅程为x b b y10?+= 将数据输⼊计算机,输出散点图可见,液化⽓收率y 具有随着回流温度x的提⾼⽽降低的趋势。
因此,建⽴描述y 与x 之间关系的模型时,⾸选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最⼩⼆乘估计值b 0=21.263和b 1=-0.229,于是最⼩⼆乘直线为x y229.0263.21?-= 这就表明,回流温度每增加1℃,估计液化⽓收率将减少0.229%。
(3)残差分析为了判别简单线性模型的假定是否有效,作出残差图,进⾏残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建⽴回归模型所依赖的假定是恰当的。
误差项的估计值s=0.388。
(4)回归模型检验 a.显著性检验在90%的显著⽔平下,进⾏t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。
由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化⽓收率与回流温度之间存在线性关系。
统计学回归分析实训报告

一、实训背景随着社会的不断发展,统计学在各个领域都得到了广泛的应用。
回归分析作为一种重要的统计方法,广泛应用于预测、关联性分析、控制变量以及优化等多个领域。
为了提高学生对回归分析的实际应用能力,我们组织了本次统计学回归分析实训。
二、实训目的1. 使学生掌握回归分析的基本概念和原理;2. 培养学生运用回归分析方法解决实际问题的能力;3. 提高学生对统计学理论知识的实际应用水平。
三、实训内容1. 回归分析的基本概念和原理2. 线性回归分析3. 非线性回归分析4. 回归模型的诊断与检验5. 回归分析的实际应用四、实训过程1. 回归分析的基本概念和原理首先,我们向学生介绍了回归分析的基本概念和原理。
回归分析是一种研究变量之间关系的方法,通过建立回归模型来预测或解释因变量的变化。
回归模型包括线性回归模型和非线性回归模型。
线性回归模型假设因变量与自变量之间存在线性关系,而非线性回归模型则假设因变量与自变量之间存在非线性关系。
2. 线性回归分析接下来,我们讲解了线性回归分析的基本步骤。
首先,收集数据;其次,进行数据可视化,观察变量之间的关系;然后,建立线性回归模型,使用最小二乘法估计模型参数;最后,对模型进行诊断与检验,包括拟合优度检验、显著性检验等。
3. 非线性回归分析非线性回归分析是线性回归分析的扩展,可以处理变量之间存在非线性关系的情况。
我们介绍了常用的非线性回归模型,如指数回归、对数回归等,并讲解了如何进行非线性回归分析。
4. 回归模型的诊断与检验回归模型的诊断与检验是保证模型有效性的关键。
我们讲解了如何进行拟合优度检验、显著性检验、残差分析等,帮助学生掌握诊断与检验方法。
5. 回归分析的实际应用最后,我们通过实际案例展示了回归分析在各个领域的应用。
例如,在市场营销领域,可以运用回归分析预测销售量;在医学领域,可以运用回归分析研究疾病与风险因素之间的关系。
五、实训成果通过本次实训,学生们对回归分析的基本概念、原理和应用有了更深入的了解。
回归分析报告

回归分析报告回归分析报告回归分析是一种用于研究变量之间关系的统计方法。
本报告将介绍一项回归分析研究的结果。
本次研究的目的是分析销售额与广告投入之间的关系。
我们收集了一家公司过去12个月的销售额和对应的广告投入数据,通过对这些数据进行回归分析,我们希望了解广告投入对销售额的影响程度。
在进行回归分析之前,我们首先进行了数据的可视化分析。
通过绘制散点图,我们可以直观地观察到销售额和广告投入之间的关系。
图1展示了销售额与广告投入之间的散点图,从图中可以看出两者呈现较强的正向线性关系。
接下来,我们进行了回归分析。
通过拟合线性回归模型,我们得到了相关的统计参数。
模型的拟合结果如下:销售额 = 0.8 * 广告投入 + 100通过对模型的参数进行解释,我们可以得出以下结论:1. 广告投入对销售额有显著的正向影响。
模型中的参数0.8表示,每增加1单位的广告投入,预计销售额将增加0.8单位。
2. 模型中的截距项100表示,在没有广告投入的情况下,销售额预计为100单位。
这可以解释为公司的一些其他因素(如品牌知名度、市场份额等)对销售额的影响。
为了验证模型的有效性,我们进行了残差分析。
残差是指实际销售额与预测值之间的差异。
我们绘制了残差图,如图2所示。
从残差图中可以看出,残差的分布较为平均,没有明显的系统性偏差,说明我们的回归模型对数据的拟合效果较好。
最后,我们还对模型进行了显著性检验。
通过计算模型的F统计量和P值,我们可以判断模型是否显著。
在本次研究中,F统计量为20,P值为0.001,显著性水平设置为0.05。
由于P值小于显著性水平,我们可以认为模型是显著的,即广告投入对销售额的影响是显著的。
综上所述,通过回归分析,我们发现了销售额与广告投入之间的关系,并建立了一个显著的线性回归模型。
我们的研究结果表明,广告投入对销售额有正向的影响,每增加1单位的广告投入,销售额预计增加0.8单位。
这对于公司在制定广告策略和预测销售额方面具有重要的借鉴意义。
回归分析 实验报告

回归分析实验报告1. 引言回归分析是一种用于探索变量之间关系的统计方法。
它通过建立一个数学模型来预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
本实验报告旨在介绍回归分析的基本原理,并通过一个实际案例来展示其应用。
2. 回归分析的基本原理回归分析的基本原理是基于最小二乘法。
最小二乘法通过寻找一条最佳拟合直线(或曲线),使得所有数据点到该直线的距离之和最小。
这条拟合直线被称为回归线,可以用来预测因变量的值。
3. 实验设计本实验选择了一个实际数据集进行回归分析。
数据集包含了一个公司的广告投入和销售额的数据,共有200个观测值。
目标是通过广告投入来预测销售额。
4. 数据预处理在进行回归分析之前,首先需要对数据进行预处理。
这包括了缺失值处理、异常值处理和数据标准化等步骤。
4.1 缺失值处理查看数据集,发现没有缺失值,因此无需进行缺失值处理。
4.2 异常值处理通过绘制箱线图,发现了一个销售额的异常值。
根据业务经验,判断该异常值是由于数据采集错误造成的。
因此,将该观测值从数据集中删除。
4.3 数据标准化为了消除不同变量之间的量纲差异,将广告投入和销售额两个变量进行标准化处理。
标准化后的数据具有零均值和单位方差,方便进行回归分析。
5. 回归模型选择在本实验中,我们选择了线性回归模型来建立广告投入与销售额之间的关系。
线性回归模型假设因变量和自变量之间存在一个线性关系。
6. 回归模型拟合通过最小二乘法,拟合了线性回归模型。
回归方程为:销售额 = 0.7 * 广告投入 + 0.3回归方程表明,每增加1单位的广告投入,销售额平均增加0.7单位。
7. 回归模型评估为了评估回归模型的拟合效果,我们使用了均方差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R^2)。
7.1 均方差均方差度量了观测值与回归线之间的平均差距。
在本实验中,均方差为10.5,说明模型的拟合效果相对较好。
回归分析实验报告总结

回归分析实验报告总结引言回归分析是一种用于研究变量之间关系的统计方法,广泛应用于社会科学、经济学、医学等领域。
本实验旨在通过回归分析来探究自变量与因变量之间的关系,并建立可靠的模型。
本报告总结了实验的方法、结果和讨论,并提出了改进的建议。
方法实验采用了从某公司收集到的500个样本数据,其中包括了自变量X和因变量Y。
首先,对数据进行了清洗和预处理,包括删除缺失值、处理异常值等。
然后,通过散点图、相关性分析等方法对数据进行初步探索。
接下来,选择了合适的回归模型进行建模,通过最小二乘法估计模型的参数。
最后,对模型进行了评估,并进行了显著性检验。
结果经过分析,我们建立了一个多元线性回归模型来描述自变量X对因变量Y的影响。
模型的方程为:Y = 0.5X1 + 0.3X2 + 0.2X3 + ε其中,X1、X2、X3分别表示自变量的三个分量,ε表示误差项。
模型的回归系数表明,X1对Y的影响最大,其次是X2,X3的影响最小。
通过回归系数的显著性检验,我们发现模型的拟合度良好,P值均小于0.05,表明自变量与因变量之间的关系是显著的。
讨论通过本次实验,我们得到了一个可靠的回归模型,描述了自变量与因变量之间的关系。
然而,我们也发现实验中存在一些不足之处。
首先,数据的样本量较小,可能会影响模型的准确度和推广能力。
其次,模型中可能存在未观测到的影响因素,并未考虑到它们对因变量的影响。
此外,由于数据的收集方式和样本来源的局限性,模型的适用性有待进一步验证。
为了提高实验的可靠性和推广能力,我们提出以下改进建议:首先,扩大样本量,以提高模型的稳定性和准确度。
其次,进一步深入分析数据,探索可能存在的其他影响因素,并加入模型中进行综合分析。
最后,通过多个来源的数据收集,提高模型的适用性和泛化能力。
结论通过本次实验,我们成功建立了一个多元线性回归模型来描述自变量与因变量之间的关系,并对模型进行了评估和显著性检验。
结果表明,自变量对因变量的影响是显著的。
回归分析实验报告

回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。
数据分析线性回归报告(3篇)

第1篇一、引言线性回归分析是统计学中一种常用的数据分析方法,主要用于研究两个或多个变量之间的线性关系。
本文以某城市房价数据为例,通过线性回归模型对房价的影响因素进行分析,以期为房地产市场的决策提供数据支持。
二、数据来源与处理1. 数据来源本文所采用的数据来源于某城市房地产交易中心,包括该城市2010年至2020年的房价、建筑面积、交通便利度、配套设施、环境质量等指标。
2. 数据处理(1)数据清洗:对原始数据进行清洗,去除缺失值、异常值等。
(2)数据转换:对部分指标进行转换,如交通便利度、配套设施、环境质量等指标采用五分制评分。
(3)变量选择:根据研究目的,选取建筑面积、交通便利度、配套设施、环境质量等指标作为自变量,房价作为因变量。
三、线性回归模型构建1. 模型假设(1)因变量与自变量之间存在线性关系;(2)自变量之间不存在多重共线性;(3)误差项服从正态分布。
2. 模型建立(1)选择合适的线性回归模型:根据研究目的和数据特点,采用多元线性回归模型。
(2)计算回归系数:使用最小二乘法计算回归系数。
(3)检验模型:对模型进行显著性检验、方差分析等。
四、结果分析1. 模型检验(1)显著性检验:F检验结果为0.000,P值小于0.05,说明模型整体显著。
(2)回归系数检验:t检验结果显示,所有自变量的回归系数均显著,符合模型假设。
2. 模型结果(1)回归系数:建筑面积、交通便利度、配套设施、环境质量的回归系数分别为0.345、0.456、0.678、0.523,说明这些因素对房价有显著的正向影响。
(2)R²:模型的R²为0.876,说明模型可以解释约87.6%的房价变异。
3. 影响因素分析(1)建筑面积:建筑面积对房价的影响最大,说明在房价构成中,建筑面积所占的比重较大。
(2)交通便利度:交通便利度对房价的影响较大,说明在购房时,消费者对交通便利性的需求较高。
(3)配套设施:配套设施对房价的影响较大,说明在购房时,消费者对生活配套设施的需求较高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、分析
第一步:解:设居住面积为
X1, 房屋税为X2,是否配有游泳池
为X3.
模型为:
第二步:估计参数建立模型 (Analyze Regression Linear)
0112233ˆy
X X X ββββ=+++
通过SPSS线性回归分析:
⏹取显著性水平α=0.05,sig必须小于0.05才能t值检验
合格,
⏹(1)、拟合优度检验:由可决系数R2=0.885,大于0.7,
说明模型对数据的拟合程度一般。
⏹(2)、F检验:由F=8.441,检验P=0.010<0.05,即可认
为回归系数具有显著意义。
这说明原先的线性模型假设是对的。
(3)、t检验:对于t检验,先检验X1,因为X1的t统计量为2.719,检验P=0.030<0.05,自变量X1的t检验通过;
再检验X2,因为X2的t统计量为 2.914,检验P=0.0230<0.05,自变量X2的t检验通过;最后检验X3,因为X3的t统计量为0.552,检验P=0.598>0.05,自变量X3的t检验没有通过,y与x3之间不存在线性关系,剔除后重新估计方程。
再次进行统计检验:
再次进行R拟合度检验、F检验、t检验
⏹ 1)拟合度检验:从上图表一可以看出:相关系数为R=0.880,可决系数R2=0.774>0.7,说明模型对数据的拟合程度可行。
⏹ 2)F 检验:从ANOV A 方差分析表可以看出,F=13.7,P=0.03<0.05,可以认为变量y 与X1,X2之间的线性关系显著。
⏹ 3)t 检验:从Coefficients 系数分析表可以看出,X1的t 统计量为2.787,P=0.024<0.05,通过t 检验;X2的统计量为3.027,P=0.016<0.05,通过t 检验,所以可以认为因变量y 与X1,X2之间存在线性回归关系。
通过统计检验可以得出一元线性回归方程:
综上所述,当X1=18百平方尺,X2=1.5百元时,售价的点
估计值为(pre_1)为130.20714千元,也就是说该夫妇所拥有的房子的售价的预测区间为7.02163万~19.019798万美金之间,而这对夫妇所提出的抵押额是预测区间的上限,为了安全慎重起见,银行会拒绝这对夫妇的申请。
2
1569.33361.3354.19x x y ++=。