数据挖掘期末考试计算题及答案
数据挖掘考试题及答案

数据挖掘考试题及答案### 数据挖掘考试题及答案#### 一、选择题(每题2分,共20分)1. 数据挖掘的目的是发现数据中的:- A. 错误- B. 模式- C. 异常- D. 趋势答案:B2. 以下哪项不是数据挖掘的常用算法:- A. 决策树- B. 聚类分析- C. 线性回归- D. 神经网络答案:C3. 关联规则挖掘中,Apriori算法用于发现:- A. 频繁项集- B. 异常值- C. 趋势- D. 聚类答案:A4. K-means算法是一种:- A. 分类算法- B. 聚类算法- C. 预测算法- D. 关联规则挖掘算法答案:B5. 以下哪个指标用于评估分类模型的性能:- A. 准确率- B. 召回率- C. F1分数- D. 所有以上答案:D#### 二、简答题(每题10分,共30分)1. 描述数据挖掘中的“过拟合”现象,并给出避免过拟合的策略。
答案:过拟合是指模型对训练数据拟合得过于完美,以至于失去了泛化能力。
避免过拟合的策略包括:使用交叉验证、正则化技术、减少模型复杂度、获取更多的训练数据等。
2. 解释什么是“数据清洗”以及它在数据挖掘中的重要性。
答案:数据清洗是指从原始数据中识别并纠正(或删除)错误、重复或不完整的数据的过程。
它在数据挖掘中至关重要,因为脏数据会导致分析结果不准确,影响最终的决策。
3. 描述“特征选择”在数据挖掘中的作用。
答案:特征选择是数据挖掘中用来降低数据维度、提高模型性能和减少计算成本的过程。
通过选择最有信息量的特征,可以去除冗余或无关的特征,从而提高模型的准确性和效率。
#### 三、应用题(每题25分,共50分)1. 假设你正在分析一个电子商务网站的用户购买行为,描述你将如何使用数据挖掘技术来识别潜在的营销机会。
答案:首先,我会使用聚类分析来识别不同的用户群体。
然后,通过关联规则挖掘来发现不同用户群体的购买模式。
接着,利用分类算法来预测用户可能感兴趣的产品。
历年数据挖掘期末考试试题及答案

历年数据挖掘期末考试试题及答案2019年春选择题1. 关于数据挖掘下列叙述中,正确的是:- A. 数据挖掘只是寻找数据中的有用信息- B. 数据挖掘就是将数据放置于数据仓库中,方便查询- C. 数据挖掘是指从大量有噪音数据中提取未知、隐含、先前未知的、重要的、可理解的模式或知识- D. 数据挖掘就是从数据中提取出数值型变量2. 下列关于聚类分析的说法中,正确的是:- A. 聚类分析是无监督研究- B. 聚类分析的目的是找到一组最优特征- C. 聚类分析只能用于数值型变量- D. 聚类分析是一种监督研究方法3. 一般的数据挖掘流程包括以下哪些步骤:- A. 数据采集- B. 数据清洗- C. 数据转换- D. 模型构建- E. 模型评价- F. 模型应用- G. A、B、C、D、E- H. A、B、C、D、E、F- I. B、C、D、E、F- J. C、D、E、F简答题1. 什么是数据挖掘?介绍一下数据挖掘的流程。
数据挖掘是从庞大、复杂的数据集中提取有价值的、对决策有帮助的信息。
包括数据采集、数据清洗、数据转换、模型构建、模型评价和模型应用等步骤。
2. 聚类分析和分类分析有什么不同?聚类分析和分类分析都是数据挖掘的方法,不同的是聚类分析是无监督研究,通过相似度,将数据集分为不同的组;分类分析是监督研究,通过已知的训练集数据来预测新的数据分类。
也就是说在分类中有“标签”这个中间过程。
3. 请介绍一个你知道的数据挖掘算法,并简单阐述它的流程。
Apriori算法:是一种用于关联规则挖掘的算法。
主要流程包括生成项集、计算支持度、生成候选规则以及计算可信度四步。
首先生成单个项集,计算各项集在数据集中的支持度;然后根据单个项集生成项集对,计算各项集对在数据集中的支持度;接着从项集对中找出支持度大于某个阈值的,生成候选规则;最后计算规则的置信度,保留置信度大于某个阈值的规则作为关联规则。
数据挖掘考试题库及答案

数据挖掘考试题库及答案一、选择题1. 数据挖掘是从大量数据中提取有价值信息的过程,以下哪项不是数据挖掘的主要任务?A. 预测B. 分类C. 聚类D. 数据可视化答案:D2. 以下哪种技术不属于数据挖掘的常用方法?A. 决策树B. 支持向量机C. 关联规则D. 数据仓库答案:D3. 数据挖掘中,以下哪项技术常用于分类和预测?A. 神经网络B. K-均值聚类C. 主成分分析D. 决策树答案:D4. 在数据挖掘中,以下哪个概念表示数据集中的属性?A. 数据项B. 数据记录C. 数据属性D. 数据集答案:C5. 数据挖掘中,以下哪个算法用于求解关联规则?A. Apriori算法B. ID3算法C. K-Means算法D. C4.5算法答案:A二、填空题6. 数据挖掘的目的是从大量数据中提取______信息。
答案:有价值7. 在数据挖掘中,分类任务分为有监督学习和______学习。
答案:无监督8. 决策树是一种用于分类和预测的树形结构,其核心思想是______。
答案:递归划分9. 关联规则挖掘中,支持度表示某个项集在数据集中的出现频率,置信度表示______。
答案:包含项集的记录中同时包含结论的记录的比例10. 数据挖掘中,聚类分析是将数据集划分为若干个______的子集。
答案:相似三、判断题11. 数据挖掘只关注大量数据中的异常值。
()答案:错误12. 数据挖掘是数据仓库的一部分。
()答案:正确13. 决策树算法适用于处理连续属性的分类问题。
()答案:错误14. 数据挖掘中的聚类分析是无监督学习任务。
()答案:正确15. 关联规则挖掘中,支持度越高,关联规则越可靠。
()答案:错误四、简答题16. 简述数据挖掘的主要任务。
答案:数据挖掘的主要任务包括预测、分类、聚类、关联规则挖掘、异常检测等。
17. 简述决策树算法的基本原理。
答案:决策树算法是一种自顶向下的递归划分方法。
它通过选择具有最高信息增益的属性进行划分,将数据集划分为若干个子集,直到满足停止条件。
浙江财经大学数据挖掘期末考试试卷以及答案

浙江财经大学数据挖掘期末考试试卷以及答案某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?() [单选题] *A. 关联规则发现(正确答案)聚类分类D. 自然语言处理以下两种描述分别对应哪两种对分类算法的评价标准?(a) 警察抓小偷,描述警察抓的人中有多少个是小偷的标准。
(b) 描述有多少比例的小偷给警察抓了的标准。
[单选题]A. Precision, Recall(正确答案)B. Recall, PrecisionC. Precision, ROCD. Recall, ROC将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务? [单选题] *A. 频繁模式挖掘B. 分类和预测C. 数据预处理(正确答案)D. 数据流挖掘当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?() [单选题] *A. 分类B. 聚类(正确答案)C. 关联分析D. 隐马尔可夫链什么是 KDD? [单选题] *A. 数据挖掘与知识发现(正确答案)B. 领域知识发现C. 文档知识发现D. 动态知识发现使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?() [单选题] *A. 探索性数据分析(正确答案)B. 建模描述C. 预测建模D. 寻找模式和规则为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?() [单选题] *A. 探索性数据分析B. 建模描述(正确答案)C. 预测建模D. 寻找模式和规则建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?() [单选题] *A. 根据内容检索B. 建模描述C. 预测建模(正确答案)D. 寻找模式和规则用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?() [单选题] *A. 根据内容检索(正确答案)B. 建模描述C. 预测建模D. 寻找模式和规则下面哪种不属于数据预处理的方法? [单选题] *A变量代换B离散化C聚集D估计遗漏值(正确答案)假设 12 个销售价格记录组已经排序如下: 5, 10, 11, 13, 15,35, 50, 55,72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。
大数据挖掘及应用期末试题及答案

大数据挖掘及应用期末试题及答案一、概述大数据挖掘是指通过对大量数据的收集、整理和分析,从中发现有用的信息、模式和关联性。
在当今信息化时代,大数据挖掘已成为各行各业重要的工具和手段。
本文将介绍大数据挖掘的一些基本概念,并给出一份期末试题及答案作为例子。
二、大数据挖掘的基本概念1. 数据收集与整理大数据挖掘的第一步是收集和整理数据,这些数据可以来源于各种渠道,如社交媒体、传感器、日志文件等。
数据收集的质量和准确性对后续的挖掘过程至关重要。
2. 数据预处理大数据挖掘中,数据预处理是不可或缺的环节。
该过程主要包括数据清洗、缺失值处理、异常值检测和数据变换等。
通过数据预处理,可以提高挖掘结果的准确性和可信度。
3. 特征选择与提取在大数据挖掘中,一个重要的任务是选择和提取出对于挖掘目标最有用的特征。
这可以通过各种方法来实现,如信息增益、相关性分析、主成分分析等。
4. 数据挖掘算法大数据挖掘涉及多种挖掘算法,如聚类、分类、关联规则、时序分析等。
这些算法可以帮助挖掘出数据中的隐藏规律和模式。
5. 模型评估与优化挖掘得到的模型需要进行评估和优化,以保证其准确性和可靠性。
评估指标可以包括准确率、召回率、F1值等。
三、大数据挖掘及应用期末试题以下是一份大数据挖掘及应用的期末试题,供同学们进行自主学习和思考:试题一:数据清洗请简述数据清洗的作用,并列举三种常见的数据清洗方法。
试题二:特征选择假设你要对一家电商平台的用户进行分类,以便进行个性化推荐。
你会选择怎样的特征来进行分类?请简要说明你的理由。
试题三:聚类分析假设你正在研究一款新药的效果,并希望对病人进行分类。
请问聚类分析是否适用于这个场景?如果适用,请简要描述一下你会采用的聚类算法,并解释其原理。
试题四:关联规则挖掘你正在研究一家超市的销售情况,希望发现一些产品之间的关联规则。
请列举出一条可能的关联规则,并解释其意义。
四、大数据挖掘及应用期末试题答案答案一:数据清洗数据清洗是指对数据集中的异常值、噪声数据和缺失值进行处理,以提高数据质量和挖掘结果的准确性。
数据挖掘测试题及答案

数据挖掘测试题及答案一、选择题1. 数据挖掘的目的是:A. 数据清洗B. 数据转换C. 模式发现D. 数据存储答案:C2. 以下哪项不是数据挖掘的常用算法?A. 决策树B. 聚类分析C. 线性回归D. 关联规则答案:C二、填空题1. 数据挖掘中的_________是指在大量数据中发现的有意义的模式。
答案:知识2. 一种常用的数据挖掘技术是_________,它用于发现数据中隐藏的分组。
答案:聚类三、简答题1. 简述数据挖掘与数据分析的区别。
答案:数据挖掘是一种自动或半自动的过程,旨在从大量数据中发现模式和知识。
数据分析通常涉及更具体的查询和问题,使用统计方法来理解数据。
2. 描述什么是关联规则挖掘,并给出一个例子。
答案:关联规则挖掘是一种用于发现变量之间有趣关系的技术,特别是变量之间的频繁模式、关联或相关性。
例如,在市场篮子分析中,关联规则挖掘可以用来发现顾客购买行为中的模式,如“购买面包的顾客中有80%也购买了牛奶”。
四、计算题1. 给定以下数据集,计算支持度和置信度:| 事务ID | 购买的商品 |||-|| 1 | A, B || 2 | A, C || 3 | B, C || 4 | A, B, C || 5 | B, D |(1) 计算项集{A}的支持度。
(2) 计算规则A => B的置信度。
答案:(1) 项集{A}的支持度为4/5,因为A出现在4个事务中。
(2) 规则A => B的置信度为3/4,因为A和B同时出现在3个事务中,而A出现在4个事务中。
五、论述题1. 论述数据挖掘在电子商务中的应用,并给出至少两个具体的例子。
答案:数据挖掘在电子商务中的应用非常广泛,包括:- 客户细分:通过数据挖掘技术,商家可以识别不同的客户群体,为每个群体提供定制化的服务或产品。
- 推荐系统:利用关联规则挖掘,电商平台可以推荐用户可能感兴趣的商品,提高用户满意度和购买率。
- 欺诈检测:通过分析交易模式,数据挖掘可以帮助识别异常行为,预防信用卡欺诈等风险。
数据挖掘导论期末考试试题

数据挖掘导论期末考试试题# 数据挖掘导论期末考试试题## 一、选择题(每题2分,共20分)1. 数据挖掘的常用技术不包括以下哪一项?A. 决策树B. 聚类分析C. 神经网络D. 线性回归2. 在数据挖掘中,以下哪个算法主要用于分类问题?A. K-meansB. KNNC. AprioriD. ID33. 以下哪个术语与数据挖掘中的关联规则挖掘无关?A. 支持度(Support)B. 置信度(Confidence)C. 准确度(Precision)D. 先行项(Antecedent)4. 数据挖掘中的“过拟合”是指模型:A. 过于简单,不能捕捉数据的复杂性B. 过于复杂,不能很好地泛化到新数据C. 与数据完全一致,没有误差D. 只适用于特定类型的数据5. 在数据预处理中,数据清洗的目的是什么?A. 增加数据量B. 提高数据质量C. 降低数据的维度D. 转换数据格式## 二、简答题(每题10分,共30分)1. 简述数据挖掘中的“异常检测”是什么,并给出一个实际应用的例子。
2. 解释什么是“特征选择”,并说明它在数据挖掘中的重要性。
3. 描述数据挖掘中的“集成学习”概念,并举例说明其优势。
## 三、计算题(每题25分,共50分)1. 给定一组数据集,包含以下属性:年龄、收入、购买产品。
使用Apriori算法找出频繁项集,并计算相应的支持度和置信度。
(假设最小支持度阈值为0.5,最小置信度阈值为0.7)| 交易ID | 年龄 | 收入 | 购买产品 ||||||| 1 | 25 | 50000| 手机 || 2 | 30 | 60000| 手机,电脑 || 3 | 35 | 70000| 电脑 || ... | ... | ... | ... |2. 假设你有一个客户数据库,包含客户的性别、年龄、年收入和购买历史。
使用决策树算法建立一个模型,预测客户是否会购买新产品。
请描述决策树的构建过程,并给出可能的决策树结构。
数据挖掘习题及解答-完美版
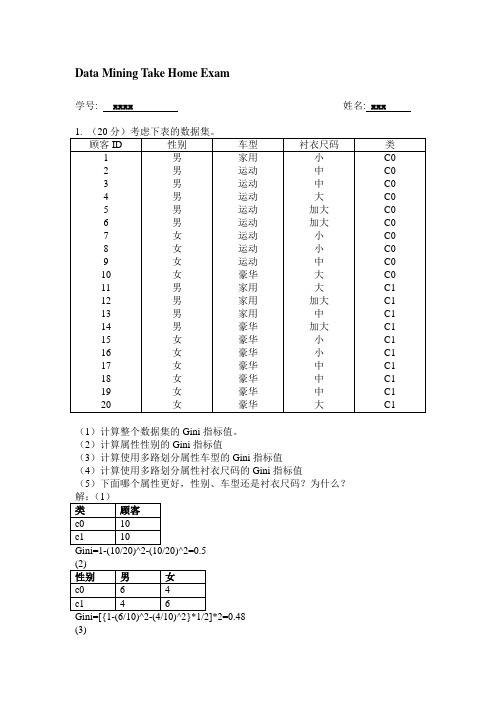
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
题一:
一阶项目集支持度
a5
b4
c2
d5
e3
f4
g6
一阶频繁集支持度
a5
b4
d5
f4
g6
二阶候选集支持度ab3
ad4
af2
ag5
bd3
bf1
bg3
df3
dg4
fg3
二阶频繁集支持度
ad4
ag5
dg4
三阶候选集支持度
adg4
三阶频繁集支持度
adg4
题二
Distance(G,A)2=0.1; Distance(G,B)2=0.03; Distance(G,C)2=0.11 Distance(G,D)2=0.12; Distance(G,E)2=0.16; Distance(G,F)2=0.05 G的三个最近的邻居为B,F,A,因此G的分类为湖泊水
Distance(H,A)2=0.03; Distance(H,B)2=0.18; Distance(H,C)2=0.22
Distance(H,D)2=0.03; Distance(H,E)2=0.21; Distance(H,F)2=0.16 H的三个最近的邻居为A,D,F,因此H的分类为冰川水
题三
首先计算各属性的信息增益
Gain(Ca+浓度)=0
Gain(Mg+浓度)=0.185
Gain(Na+浓度)=0
Gain(Cl-浓度)=0.32
选择 Cl-
计算各属性的信息增益
Gain(Ca+浓度)=0
Gain(Mg+浓度)=0.45
Gain(Na+浓度)=0.24
选择Mg+
Cl-浓度
冰川水?
高低
Cl-浓度
冰川水Mg+浓度
高低
高低
计算各属性的信息增益
Gain(Ca+浓度)=0.24
Gain(Na+浓度)=0.91
Cl-浓度
高低
冰川水Mg+浓度
高低
Na+浓度湖泊水
高低
湖泊水冰川水
题四
P(Ca+浓度=低,Mg+浓度=高,Na+浓度=高,Cl-浓度=低| 类型=冰川水)*P(冰川水)
=P(Ca+浓度=低| 类型=冰川水)* P(Mg+浓度=高| 类型=冰川水)* P(Na+浓度=高| 类型=冰川水)* P(Cl-浓度=低| 类型=冰川水) *P(冰川水)
=0.5*0.75*0.5*0.5*0.5=0.0468
P(Ca+浓度=低,Mg+浓度=高,Na+浓度=高,Cl-浓度=低| 类型=湖泊水)*P(湖泊水)
=P(Ca+浓度=低| 类型=湖泊水)* P(Mg+浓度=高| 类型=湖泊水)* P(Na+浓度=高| 类型=湖泊水)* P(Cl-浓度=低| 类型=湖泊水) *P(湖泊水)
=0.5*0.25*0.5*1*0.5=0.03123
第一个样本为冰川水
P(Ca+浓度=高,Mg+浓度=高,Na+浓度=低,Cl-浓度=高| 类型=冰川水)*P(冰川水)
=P(Ca+浓度=高| 类型=冰川水)* P(Mg+浓度=高| 类型=冰川水)* P(Na+浓度=低| 类型=冰川水)* P(Cl-浓度=高| 类型=冰川水) *P(冰川水)
=0.5*0.75*0.5*0.5*0.5=0.0468
P(Ca+浓度=高,Mg+浓度=高,Na+浓度=低,Cl-浓度=高| 类型=湖泊水)*P(湖泊水)
=P(Ca+浓度=高| 类型=湖泊水)* P(Mg+浓度=高| 类型=湖泊水)* P(Na+浓度=低| 类型=湖泊水)* P(Cl-浓度=高| 类型=湖泊水) *P(湖泊水)
=0.5*0.25*0.5*0*0.5=0
第二个样本为冰川水
题五
A,B,C,D,E,F,G之间的距离矩阵如下表
根据距离矩阵建立的树如下
题六
第一次迭代以A ,B 作为平均点,对剩余的点根据到A 、B 的距离进行分配 {A,C,D,E,F,G,H}, {B} 计算两个簇的平均点 (6.5, 1.7), (4, 5)
第二次迭代,对剩余的点根据到平均点的距离进行分配,得到两个簇 {D,E,F,H}和{A,B,C,G} 计算两个簇的平均点
B C D A
E F G
(9.1, 0.5), (3.25, 3.75)
第三次迭代,对剩余的点根据到平均点的距离进行分配,得到两个簇{D,E,F,H}和{A,B,C,G}
由于所分配的簇没有发生变化,算法终止。
. .。