织梦采集规则
DEDECMS采集规则(图文详解)

DEDECMS采集规则(图文详解)默认分类2010-08-08 23:54:21 阅读209 评论0 字号:大中小订阅没有玩过DEDECMS的采集,但还是想了解一下DEDE采集的规则,下面是详细的图文详解,有空的时候看看,留此备用了.第一步、确定采集的网站(我们以DEDE的官方站做为采集站做示范)Quote:/plus/list.php?tid=10第二步、确定被采集站的编码。
打开被采集的网页之后,查看源代码(IE:查看- > 源代码)在之间找到charset 这个,后面就显示网页的编码了,截图的是“gb2312”第三步、采集列表获取规则写法来源网址写法很明显pageno是表示分页页码那么有多页列表的采集就要用“[var:分页]”来替换分页页码,截图如下/ plus/list.php?tid=10&pageno=[var:分页]文章网址需包含网址不能包含这两个一般不用写,用于采集列表范围有很多不需要的连接才用到他来做过滤使用。
上面的网址并没有带有至于 为什么要在前面加上,这个就不要我说了吧。
如果只有一个列表页,那么在来源网址就直接写上网址就OK了。
注意这里,最关键就是这里。
下面就是“采集获取文章列表的规则写法”,就是上面打开的被采集页面的源代码文件,找到文章列表之前和本页面没有其他相同的代码在DedeCms官方站的列表页文章列表之前和之后最近的且没有相同的是“ ”和“ ”,分别写入“起始HTML”和“结束HTML”,写法看截图第四步、采集文章标题,文章内容,文章作者,文章来源等规则写法,分页采集等。
“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”下面讲的是如何采集分页内容看截图圈着的地方截图文档是否分页里面选择“全部列出的分页列表”“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”这里本来还有一张截图的,由于论坛配置,他现在显示在最上面.在文章内容那里点上“分页内容字段”,不选择就不能采集。
DedeCMSV5.6版自动采集功能规则使用基本知识详细讲解教程

DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(一) 2011-05-05 17:09:01 来源: 作者: 【大中小】浏览:5026次评论:0条★★我要投稿★★将此页添加到网摘:DedeCMS采集功能使用基本知识讲解采集是指有着确定方向、明确目的的采撷和记录写作材料的一种活动。
它主要指调查采访和查阅和搜集资料。
采集最主要的作用在于为写作、分析、报表获取直接的和间接的材料。
今天我们讲的采集主要是指网站采集,网站采集的概念主要是:程序按照指定的规则定向获取其他网站数据的一种方式,另一种简单的说法就是将CTRL+C CTRL+V 程序化,系统化,自动化,智能化DedeCMS早期就已经加入了这个采集的功能,以前我们添加网站内容一般都是通过复制、粘贴、编辑然后再发布,这样对于少量的文章还是可以,但如果对于一个新站,什么内容都没有,那就需要复制粘提大量的文章,这是一个重复、枯燥的过程,内容采集就是解决这个问题,将这个重复的操作简化成规则,通过规则进行批量操作。
当然采集还可以通过一些专门的采集器来进行采集,国内比较出名的采集器有火车头。
今天我们这里以DedeCMS程序自带的采集功能来讲解如何使用采集,并介绍如何对采集的内容进行一些批量的管理。
首先我们进入系统后台,打开[采集]-[采集节点管理],在学习使用这个采集工能之前先介绍一些基本的技术知识。
首先我们需要知道HTML基本内容,我们知道浏览器中显示的各种各样的页面其实都是由最基本的HTML组成的,我们可以在我们DedeCMS系统后台发布一篇内容,然后对内容进行一些格式上面的设置。
也就是说我们的页面都是HTML代码经过浏览器解析后显示出来的,这些基本的HTML代码是给机器看的,而解析出来显示的内容是给我们的用户看的,机器其实是一个死东西,他阅读网页不像用户一样,直接看到某一个部分的内容,机器能够看到的是某一部分代码。
DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(二) 2011-05-05 17:09:01 来源: 作者: 【大中小】浏览:5027次评论:0条★★我要投稿★★将此页添加到网摘:例如,我们查看一个网页:,我们很容易就看到这个文档的内容部分,如图中黄色区域。
dede采集文章,过滤规则大全,常用规则

{dede:url value='/text/class1/class1/200609/text_28623.html'}{/dede:url}
{dede:need}{/dede:need}
把这个延伸一下:关于inc_arcpart_view.php
function GetArcList($typeid=0,$row=10,$col=1,$titlelen=30,$infolen=160,
$imgwidth=120,$imgheight=90,$listtype= all ,$orderby= default ,$keyword= ,
这样就把文章里有这些字的地方过滤成空了,不过这样做有时文章会读不通,经常会用到互换
{dede:trim replace= 晋利达俱乐部 }晋利达反赌俱乐部{/dede:trim}
过滤一些电话
过滤400电话
{dede:trim replace= }\d{4}-\d{3}-\d{3}{/dede:trim}
输出结果:/html/guizeceshi/caijibiji/20070327/2044_2.html
这是全部的代码,可导入试下:
复制代码 代码如下:
{!-- 节点基本信息 --}
{dede:item name='论坛范例_工作总结_成功(改)'
{dede:trim}
{/dede:trim}
过滤js
{dede:trim}dede:trim}
过滤未知变量字符
固定(.*)固定
4.dede万能过滤代码
织梦网站后台使用说明书
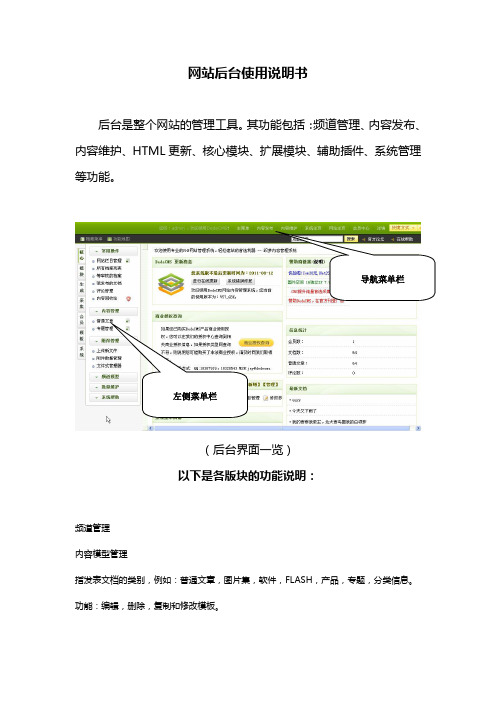
网站后台使用说明书后台是整个网站的管理工具。
其功能包括:频道管理、内容发布、内容维护、HTML更新、核心模块、扩展模块、辅助插件、系统管理等功能。
左侧菜单栏(后台界面一览)以下是各版块的功能说明:频道管理内容模型管理指发表文档的类别,例如:普通文章,图片集,软件,FLASH,产品,专题,分类信息。
功能:编辑,删除,复制和修改模板。
网站栏目管理管理网站所有栏目。
功能:创建顶级栏目,预览栏目页面,查看栏目文档,添加子栏目,修改栏目设置,移动栏目,删除栏目,更新排序,获取js,更新栏目HTML,更新文档HTML。
自由列表管理可以用来生成GOOGLE地图、百度地图等,利于搜索引擎收录。
功能:增加,更改,更新,删除,搜索列表单独页面管理单独页面,不属于网站栏目的页面,可以选择用模板或不用模板。
功能:增加,更改,更新,删除页面。
互动模块设置行业管理用于企业会员——公司资料——主营行业中的内容;在个人会员发布分类信息时用到。
功能:添加主行业,子行业,编辑,删除行业。
地区管理用于网站中需要添加地区的地方。
如:企业会员——企业资料。
功能:添加一级地区,二级地区,编辑,删除地区。
小分类管理相关于栏目的属性,在添加或修改栏目时启用小分类(仅适用于分类信息等互动模型)频道设置文档自定义属性管理使用自定义属性之后,只要给arclist 标记加上 att='ID' 的属性,然后在发布的时候对适合的文档选择专门的属性,那么使用arclist的地方就会按你的意愿显示指定的文档。
功能:滚动显示,头条推荐,幻灯片显示,首页推荐,首页滚动。
软件频道设置关于软件下载频道的一些设置。
功能:链接的显示方式,附件下载方式,是否启用镜像站点,是否显示本地下载链接防采集串混淆在文档中加一些防采集的字符串,防止采集内容。
我加上试了,没出效果来源管理保存文章的来源,在文档发布时直接选择就可以了,不用再输入。
作者管理保存发布文章的作者,在文档发布时直接选择就可以了,不用再输入。
PHPCMS 、帝国及织梦对比分析(十一)之采集功能

提到采集,有些站长抛出鄙夷的眼神,而似乎大部分站长都会觉得是CMS的标配。
在落叶看来采集只是一个功能,一个工具,关键看是采什么,采来后做什么,怎么处理采来的内容。
大家都知道火车头,一般基本用来采文章,但落叶经常用来采集邮箱,CMS间导数据,基至都用来采过QQ号。
火车头的整套流程即使对采集规则了解不多,也很方便来采文章,那么相较之于这种客户端软件,主流CMS中的采集模块,有哪些优缺点呢?本文中落叶对PHPCMS、帝国CMS及DEDECMS的采集功能作些对比,同时也对采集流程细节作些需求分析。
我们知道,通常的采集流程都是通过列表页分页批量获取内容页网址,然后对内容页分析,获取内容标题、文章内容等信息,因为各目标站的结构不同,采集规则会不同,CMS 不可能也不会提供通用的采集规则,那么要考量一款CMS采集模块是否好用基本是由整个采集任务设置流程的易用性、采集的稳定性与效率、采集完入库方便性等方面决定。
1.采集设置流程:整体体验:PHPCMS的任务添加流程中直接在TAB菜单的形式列出来网址采集、内容规则设置、高级设置三步骤,每一步中的结构都和火车头比较像,对火车头采集的比较熟悉用户会觉得PHPCMS的采集设置比较明了。
DEDE中流程类似,只是没有直接将几步列出,后一步的设置的前提是前一步设置正确。
帝国CMS中则是希望用户一口吃饱,从上至下把需要的信息全部列出来。
其实整体都基本三步,没有太明显的区别是,只是三者表现方式的不同给用户的心理感受是不同的。
PHPCMS简洁明了,让用户觉得采集很简单,三下两下就设置好了,新手愿意去尝试。
帝国CMS中用户一进入采集设置界面顿感压力,页面一直下拖,这么多设置项,首先想到的是“算了,换别的采集”,“这么多填到什么时候,填完了能不能提交还是一回事”,而DEDECMS中把采集过程和设置流程整合起来,优点时可以保证每一步都设置正确,但对采集比较熟悉的用户而言,效率偏低,每次都得POST提交一次测试一次。
织梦后台功能整理

OSS层运营支撑系统参考1、核心a) 常用操作i. 网站栏目管理 ii. 所有档案列表 iii. 等审核的档案 iv. 我发布的文档 v. 评论管理 vi. 内容回收站b) 内容管理i. 分类信息 ii. 普通文章 iii. 图片集 iv. 软件 v. 商品 vi. 专题管理c) 附件管理i. 上传新文件 ii. 附件数据管理 iii. 文件式管理器d) 频道模型i. 内容模型管理 ii. 单页文档管理 iii. 联动类别管理 iv. 自由列表管理 v. 自定义表单e) 批量维护i. 更新系统缓存 ii. 文档批量维护 iii. 搜索关键词维护 iv. 文档关键词维护 v. 重复文档检测 vi. 自动摘要|分页 vii. TAG标签管理 viii. 数据库内容替换f) 系统帮助i. 参考文档 ii. 意见建议反馈 iii. 官方交流论坛2、模块a) 模块管理i. 模块管理 ii. 上传新模块 iii. 模块生成向导b) 辅助插件i. 插件管理器 ii. 挑错管理 iii. 百度新闻 iv. 文件管理器 v. 广告管理 vi. 友情链接 vii. 投票模块 viii. bShare分享插件 ix. 站内新闻发布 x. 邮件订阅c) 圈子管理i. 分类设置 ii. 圈子列表 iii. 主题管理d) 邮件订阅i. 会员邮件管理 ii. 订阅期刊管理 iii. 订阅分类管理 iv. 群发期刊管理 v. 获取邮件地址 vi. 邮件列表管理e) 问答管理i. 栏目管理 ii. 问题管理 iii. 答案管理 iv. 幻灯片管理3、生成a) 自动任务i. 一键更新网站 ii. 更新系统缓存b) HTML更新i. 更新主页HTML ii. 更新栏目HTML iii. 更新文档HTML iv. 更新网站地图 v. 更新RSS文件 vi. 获取JS文件 vii. 更新专题HTML4、采集a) 采集管理i. 采集节点管理 ii. 临时内容管理 iii. 导入采集规则 iv. 监控采集模式 v. 采集未下载内容b) 批量维护i. 更新系统缓存 ii. 文档批量维护 iii. 搜索关键词维护 iv. 文档关键词维护 v. 重复文档检测 vi. 自动摘要|分页 vii. TAG标签管理 viii. 数据库内容替换5、会员a) 会员管理i. 注册会员列表 ii. 会员级别设置 iii. 积分头衔设置 iv. 会员模型管理 v. 会员短信管理 vi. 会员留言管理 vii. 会员动态管理 viii. 会员心情管理b) 支付工具i. 点卡产品分类 ii. 点卡产品管理 iii. 会员产品分类 iv. 会员消费记录 v. 商店订单记录 vi. 支付接口设置 vii. 配货方式设置6、模块a) 模板管理i. 默认模板管理 ii. 标签源码管理 iii. 自定义宏标记 iv. 智能标记向导 v. 全局标记测试b) 系统帮助i. 参考文档 ii. 意见建议反馈 iii. 官方交流论坛7、系统a) 系统设置i. 系统基本参数ii. 系统用户管理 iii. 用户组设定 iv. 服务器分布/远程 v. 系统日志管理 vi. 验证安全设置 vii. 图片水印设置 viii. 自定义文档属性 ix. 软件频道设置 x. 防采集串混淆 xi. 随机模板设置 xii. 计划任务管理 xiii. 数据库备份/还原 xiv. SQL命令行工具 xv. 文件校验[S] xvi. 病毒扫描[S] xvii. 系统错误修复[S]b) 支付工具i. 点卡产品分类 ii. 点卡产品管理 iii. 会员产品分类 iv. 会员消费记录 v. 商店订单记录 vi. 支付接口设置 vii. 配货方式设置c) 系统帮助i. 参考文档 ii. 意见建议反馈 iii. 官方交流论坛。
dedecms普通文章接口说明

Dedecms5.7 sp1-sp2文章模型栏目接口使用手册一、简介1、本接口应用于Dedecms5.7 sp1-sp2(20170405版)版普通文章模型栏目文章发布;2、由于数据量大时DEDE生成栏目HTML时的服务器负担很重,因此,发布接口增设了2个控制参数zznomakeindex和zznomakeandcat,分别控制是否生成主页或相关栏目;3、发布时请使用具有管理权限的用户帐号;4、本接口基于Dedecms UTF8版制作,适用于Dedecms GBK/utf-8等版本,应用于其他版本时请自行测试调整;5、在Dedecms utf8版使用本接口时,请在发布规则中选择编码为UTF-8;6、接口文件无须任何改动即可使用,如果你希望增加校验或其他功能,请仔细修改;7、2个接口文件请复制在Dedecms网站管理目录(默认是dede,用户可能有更改)下使用;二、安装接口在接口文件夹中找到接口文件,如图:请将etchk.php、etpost.php等接口文件复制到指定目录,远程FTP上传请使用二进制方式上传,如图:三、配置发布规则1、将范例发布规则文本导入ET2发布配置,或使用软件内置发布规则范例,如图:2、将检查网址和发布网址中的“您的网站”改为您要发布的网站网址,如图:3、在检查网址填上您的栏目ID,如图:4、在参数取值,填上您要发布的栏目ID,如图:在网站后台网站栏目管理处,可以看到各栏目的ID号,如图:4、填上您的账号、密码,注意格式和账号权限,如图:四、接口说明一、检查接口1、接口文件名etchk.php,为保密,请自行修改文件名;2、本接口文件复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;3、主要参数(以下参数附加在检查网址后)主题标题:keyword栏目ID:typeid用于限定检查栏目范围,可不填,可在后台网站栏目管理处查看id;校验码:vercode请自行设定,并在检查接口文件开始处修改vercode使其一致;4、发布配置-文章检查网址处,可以如下填写:http://您的网址/dede/etchk.php?vercode=&typeid=&keyword=<%title%>注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致5、接口文件无须任何改动即可使用,如果你希望增加校验或其他功能,请仔细修改;二、发布接口1、接口文件名etpost.php,为保密,请自行修改文件名;2、本接口文件请复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;注:以下参数名后“=”号为示范取值而用,参数名本身不含“=”号;采集取值的参数项,请在发布规则-发布项中添加,如图:3、基本参数userid会员名参数名pwd密码参数名title主题标题参数名body内容参数名4、主要参数typeid=主栏目ID,可在后台网站栏目管理处查看该id;typeid2=副栏目ID,可不填,可在后台网站栏目管理处查看该id,多个请用英文逗号分隔,如typeid2=3,7,11 ;channelid= 模型ID,默认为1,如果文章模型ID不为1,则用这个参数设置;vercode=安全校验码,请自行设定,并在发布接口文件开始处修改vercode使其一致;zznomakeindex=0 主页生成控制,取值0时,使用DEDE后台“发布文章后马上更新网站主页”的设置,取值1时,禁止生成网站主页;zznomakeandcat=0 栏目生成控制,取值0时,使用DEDE后台“发表文章后马上更新相关栏目”的设置,取值1时,禁止生成相关栏目;注:系统-基本参数-性能选项“arclist标签调用缓存”会影响静态页面生成情况,设为0可解决;5、可选参数ishtml=1是否生成HTML,1为是,0为否;remote=1是否下载远程图片和资源,1为是,0为否,启用本项则在ET 采集规则中不启用文件下载;dellink=0 是否删除非站内链接,1为是,0或空为否;autolitpic=1是否提取第一个图片为缩略图,1为是,0为否,启用本项则picname应留空;picname=缩略图片路径及文件名;ddisremote=0是否远程获取缩略图片,1为是,0为否,启用本项必须使PICNAME的值为有效图片网址;keywords关键字;autokey=1自动获取关键字,1为是,0为否;部分PHP版本过低导致DEDE 的splitword类无效时,仍可使用接口,遇到这种情况时,参数autokey应设为0,以取消自动关键词功能;needwatermark=0图片是否加水印,1为是,0为否,启用本项则在ET中间规则中不应设置图片水印;tags TAG标签;source文章来源;writer作者,留空即为用户名;shorttitle简略标题;description内容摘要;color=标题颜色,格式如#FF0000;flags[]=h文章属性,头条;flags[]=c文章属性,推荐;flags[]=f文章属性,幻灯;flags[]=a文章属性,特荐;flags[]=s文章属性,滚动;flags[]=b文章属性,加粗;flags[]=p文章属性,图片;flags[]=j文章属性,跳转;redirecturl=跳转网址,当文章属性为跳转时生效;sptype=auto分页方式,hand是手动,auto是自动,当使用手动分页时,应将ET分隔符“#-0-#”替换为DEDE分页符“#p#分页标题#e#”;spsize=5自动分页大小,单位Knotpost=0是否禁止评论,1为是,0为否;click=50随机浏览次数最大值;sortup=0文章排序方式,0为默认排序,7为置顶一周,30为置顶一个月,90为置顶三个月,180为置顶半年,360为置顶一年;arcrank=0阅读权限,0为开放浏览,-1为待审核稿件,10为注册会员,50为中级会员,100为高级会员;money=0消费点数;pubdate发布时间;weight=0 权重,越小越靠前;6、增加自定义字段在文章模板使用新增自定义字段数据的时候,除了在发布配置-发布项-参数取值设置数据项和这个自定义字段参数名的关联外,还需要在参数取值里加一行:dede_addonfields=key1,htmltext,其中:key1是字段参数名称,htmltext是字段数据类型,有多个自字义字段的时候用英文分号隔开,如图示:(注:其中key1,key2是示例字段名)7、发布配置-文章检查网址处,可以如下填写:http://您的网址/dede/etpost.php注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致8、接口文件无须任何改动即可使用,如果你希望增加校验或其他功能,请仔细修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便改正,返回信息窗见下图:一、[err]账号密码错误[/err]1、检查发布规则-参数取值-账号密码队列;二、[err]invalid vercode[/err]1、在发布规则-检查网址中填写的vercode 值和检查接口文件中的vercode值不一致;2、在发布规则-参数取值-附件参数队列中填写的vercode值和发布接口文件中的vercode值不一致;三、[err]标题不能为空[/err]:1、使用的采集规则未能正确采集到标题;2、采集规则的数据整理将标题过滤了;3、错误的修改了发布规则-发布项中的标题参数名,正确的参数名请看本文接口说明部分;4、发布规则未开启utf-8编码转换;四、[err]内容不能为空[/err]:1、使用的采集规则未能正确采集到正文数据项;2、采集规则的数据整理将正文数据过滤了;3、错误的修改了发布规则-发布项中的正文参数名,正确的参数名请看本文接口说明部分;4、发布规则未开启utf-8编码转换;五、文章乱码:1、发布规则未开启utf-8编码转换;2、数据整理不当;六、附件上传不成功:1、检查附件保存路径和格式是否正确2、检查附件是否存在3、检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,则文件显示URL和FTP上传目录应一致;3、如果使用保存目录而未使用FTP上传,则文件显示URL应和方案的文件保存目录一致;。
dedecms规则采集和使用教程

大家好!今天给大家录制一个dedecms采集规则编写以及使用教程星期8_淘淘小店地址今天采集的目标站地址选择下面的列表地址编写规则/more-yuleshijianbu-1.html0.节点名称随意编写我们写娱乐事件 如图(1)1.程序编码gbk utf8 程序编码是GB2312和gbk一样如图(1)2.地址批量/more-yuleshijianbu-(*).html如图(1)图13.列表前后代码截取代码在列表页必须只有这样一条代码<div class="more_left_6"><div class="paging"> 如图(2)4.必须包含链接关键词(通用)shtml 如图(2)图25.不得包含关键词主要是过滤文章内容链接不需要的地址如图(2)6.文章标题提取通常都是<title>[内容]</title> 如图(4)图4过滤规则{dede:trim replace=''}要过滤的内容{/dede:trim}{dede:trim replace=''}_娱乐_onlylady女人志{/dede:trim}标题规则这样就OK了如图(5)图57.内容规则提取内容前后截取的代码同样必须是整个页面唯一性的代码<div class="detail_content" id="detail_content">[内容]<!--PAGE-->8.过滤规则提取dedecms过滤规则最重要的地方很多朋友不会使用他本条规则过滤代码如下{dede:trim replace=""}<a([^>]*)>{/dede:trim}{dede:trim replace=""}<script([^>]*)>(.*)</script>{/dede:trim}{dede:trim replace=""}本文导航(.*)键翻页{/dede:trim}{dede:trim replace=""}<div([^.]*)>{/dede:trim}{dede:trim replace=""}</div>{/dede:trim}{dede:trim replace=""}<p style([^.]*)>{/dede:trim}{dede:trim replace=""}>" >点击图片进入下一页>>{/dede:trim}官方提供的过滤规则如下{dede:trim replace=''}<a([^>]*)>(.*)</a>{/dede:trim}{dede:trim replace=''}<script([^>]*)>(.*)</script>{/dede:trim}{dede:trim replace=''}<!--(.*)-->{/dede:trim}{dede:trim replace=''}<table([^>]*)>(.*)</table>{/dede:trim}{dede:trim replace=''}<style([^>]*)>(.*)</style>{/dede:trim}{dede:trim replace=''}<img([^>]*)>{/dede:trim}{dede:trim replace=''}<object([^>]*)>(.*)</object>{/dede:trim}{dede:trim replace=''}<embed([^>]*)>(.*)</embed>{/dede:trim}{dede:trim replace=''}<iframe([^>]*)>(.*)</iframe>{/dede:trim}{dede:trim replace=''}<param([^>]*)>(.*)</param>{/dede:trim}{dede:trim replace=''}<div([^.]*)>{/dede:trim}{dede:trim replace=''}</div>{/dede:trim}下面讲下常用的过滤规则{dede:trim replace=''}<a([^>]*)>(.*)</a>{/dede:trim} a链接的过滤规则但是如果在a链接后面带img图片链接的话只需要改下面规则{dede:trim replace=''}<a([^>]*)>{/dede:trim}js过滤规则{dede:trim replace=''}<script([^>]*)>(.*)</script> {/dede:trim} 一般不用动他是要前后开头<script都会自动把这样的代码干掉{dede:trim replace=''}<div([^.]*)>{/dede:trim}常用如果内容页面有<td width=950 height=100 align=middle>就可以把{dede:trim replace=''}<div([^.]*)>{/dede:trim} 改成{dede:trim replace=''}<td([^.]*)>{/dede:trim} 一次性全部干掉还有就是文字{dede:trim replace=''}</div>{/dede:trim}整段文字过滤{dede:trim replace=''}文字开头(.*)文字结尾{/dede:trim}9.内容分页代码系统提供{path}{file}_{p}{ext} 一般用这个就可以全部解决了不行的话就要在分页代码前后截取如<div class=page>[内容]</div>(1.)全部列出的分页列表(2.)上下页形式或不完整的分页列表(3.)分页列表规则开始: 结束三个选项基本上都可以解决分页难题10.规则采集数据导出方法采集-采集节点管理-勾选需要采集的规则-规则下面点采集如图(6)图6每页采集默认 5 可以按照自己服务器宽带速度适量修改一次采集太多可能会造成采集进度卡停如图7图7间隔时间一般在采集图集的时候需要用到他因为图集在采集标题的时候经常会采集错误导出数据如图8 到图9图8图9。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
茂名门户:茂名Seo:
织梦采集规则
一个大型的资讯网站,频道N多,网站数据也N多,不可能每一条数据都是由网站管理员一条条的来发的!这时候,为了节约人力物力,采集器就诞生了(做优化的朋友,笔者可不推荐你们使用哦)!下面,笔者就用织梦管理系统自带的采集器来采集一个网站的数据给大家演示一下,采集规则是怎么写的!
步骤一:新建一个文章采集节点
1、登录织梦管理后台,依次点击
2、采集>>采集节点管理>>增加新节点>>选择普通文章>>确定
步骤二:填写采集列表规则
1、节点名称:随便(注意你要能分清哦,因为节点多了的话,有可能会搞得自己混
乱)
2、目标页面编码:看目标页面的编码(比如我采集的网站的编码就是GB2312)
3、匹配网址:去到采集目标列表页面,查看它的列表规则!比如说很多网站的列
表的第一面跟其它内页是有很大的差别的,所以我一般不采集目标列表的第一
页!比如说我演示的网站的列表规则是第一页设定一个默认的首页,看不到后
面的实际路径的,如图:
茂名门户:茂名Seo:
所以,我们只能从第二页开始(虽然可以找出第一页,但很多的网站是根本没
第一页的,所以,这里就不说怎么找第一页了),!我们来对比一下,采集目标
页的第二页跟第三页!如图:
可以看到,这两页都是有规律的递增的,第二页就是list_2!第三页就是list_3!
所以,匹配网址我们就写成
上面那个(*)代表的就是列表页面的2,或3,或4,或更多!而第三条横杆那
里,我写了个(*)从 2 到 5 ,这里表示的是,把2到5,每次+1的增加,
匹配至(*)里面,代替(*)!
4、区域开始的HTML:在采集目标列表页打开源代码!在要采集的文章标题前面
的附近找一段在本页是唯一并且其它要采集的的页面也是唯一的html标签!
茂名门户:茂名Seo:
5、区域结束的HTML:在采集目标列表页打开源代码!在要采集的文章标题后面
的附近找一段在本页是唯一并且其它要采集的的页面也是唯一的html标签!
其它的地方,暂时我们还没用到,可以不管!这样,列表页的规则就写好了!
下图是我写好的列表规则截图!
写好了,点击保存信息并进入下一步!如果写正确了规则的话,那这些就会出
现一个有内容的网址获取规则测试:如下图
茂名门户:茂名Seo:
步骤三:填写采集内容规则
1、文章标题:在文章标题前后找两个标签,能识别出标题的!我采集的网站的文
章标题前后唯一标签是<h1>…</h1>,就写成<h1>[内容]</h1>。
2、文章内容:在文章内容前后找两个标签,能识别出内容的!我采集的网站的文
章内容前后唯一标签是<div class="content">…<ul class="page clearfix">,所
以就写成<div class="content">[内容]<ul class="page clearfix">!
其它的功能,也不用管!这里只分享怎么能采到文章!然后,点击保存配置
并预览,如果前面的列表规则跟内容规则都写对了的话,那现在就会预览到
内容了!
茂名门户:茂名Seo:
注意事项
1、选择列表的唯一标签的时候,一定是要在本页是唯一的,并且,在其它的列表页也是要
有个标签,而且也是要唯一的!
2、选择内容的唯一标签的时候,一定是要在本内容页是唯一的,并且,在其它的内容页也
是要有这个标签,而且也是要唯一的!。