结构方程模型案例汇总-共18页
结构方程SEM模型案例分析

结构方程SEM模型案例分析什么是SEM模型?结构方程模型(Structural equation modeling, SEM)是一种融合了因素分析和路径分析的多元统计技术。
它的强势在于对多变量间交互关系的定量研究。
在近三十年内,SEM大量的应用于社会科学及行为科学的领域里,并在近几年开始逐渐应用于市场研究中.顾客满意度就是顾客认为产品或服务是否达到或超过他的预期的一种感受。
结构方程模型(SEM)就是对顾客满意度的研究采用的模型方法之一。
其目的在于探索事物间的因果关系,并将这种关系用因果模型、路径图等形式加以表述。
如下图:图: SEM模型的基本框架在模型中包括两类变量:一类为观测变量,是可以通过访谈或其他方式调查得到的,用长方形表示;一类为结构变量,是无法直接观察的变量,又称为潜变量,用椭圆形表示。
各变量之间均存在一定的关系,这种关系是可以计算的。
计算出来的值就叫参数,参数值的大小,意味着该指标对满意度的影响的大小,都是直接决定顾客购买与否的重要因素。
如果能科学地测算出参数值,就可以找出影响顾客满意度的关键绩效因素,引导企业进行完善或者改进,达到快速提升顾客满意度的目的。
SEM的主要优势第一,它可以立体、多层次的展现驱动力分析。
这种多层次的因果关系更加符合真实的人类思维形式,而这是传统回归分析无法做到的。
SEM根据不同属性的抽象程度将属性分成多层进行分析。
第二,SEM分析可以将无法直接测量的属性纳入分析,比方说消费者忠诚度。
这样就可以将数据分析的范围加大,尤其适合一些比较抽象的归纳性的属性。
第三,SEM分析可以将各属性之间的因果关系量化,使它们能在同一个层面进行对比,同时也可以使用同一个模型对各细分市场或各竞争对手进行比较。
SEM模型案例分析某通信分公司屡次位居榜尾,于是痛下决心改革。
该分公司有三类业务:固话业务、小灵通业务以及上网业务。
围绕着这三类业务产品的销售,该通信分公司还提供了售前、售中和售后三个环节多方面的服务。
结构方程模型

• (6)当模型与数据拟合时 ,说明数据并不排斥模 式 ,不能说数据可以确认模式 ,也不能证明某一理 论基础; • (7) 用同一样本数据 ,以相同数目的待估参数和 不同的组合形式可以产生许多不同模型 ,这些等同 模型哪一个更适合于研究问题 ,应按照模式表达的 意义从专业角度来鉴别; • (8)) SEM 不能验证变量间的因果关系。同其他 统计方法一样 ,当模型与样本拟合时 ,只能说该模 型是可供考虑的模型 ,是目前为止尚未被否定的模 型。只有经严格的实验设计控制其他变量的影响 , 才能探讨主要变量的因果效应。绝不能因为使用 了 SEM 便说证明模型正确。严格地说 ,尽管 SEM 不能证明因果关系 ,但它的生命力在于能寻找变量 间最可能的因果关系。
3、结构方程模型的结构
4、结构方程模型的优点 5、结构方程模型中的变量 6、结构方程模型常用图标
1、什么是结构方程模型
结构方程模型( Structural Equation Model)是基于变量 的协方差矩阵来分析变量之间关系的一种统计方法。所以,有 时候也叫协方差结构分析。 我们的课程只考虑线性结构方程模型。
• ③SEM 对样本容量的要求较高 ,也要求模 型必须满足识别条件并且它不能处理真正 的分类变量。
五、应用实例
应用场合
CALIS过程简介
• proc calis语句是必须的,且此语句还可添 加一些选项,这些选项主要包括: • (1)数据集选项,如DATA= 使用的数据 集的名字;INRAM= 使用已存在的并被分 析过的模型;OUTRAM= 将模型的说明存 入输出数据集,备以后INRAM调用。 • (2)数据处理选项,如EDF= 在没有使用 原始数据且未指定样本数N时为模型指定自 由度;NOBS= 指定样本数N。
[结构方程模型][台湾][郑志恒]
![[结构方程模型][台湾][郑志恒]](https://img.taocdn.com/s3/m/20cb11e8e009581b6bd9eb8a.png)
5. Data analysis and result 5.1 Measurement model 測量模式
• 適配度評鑑-指標的判讀及說明: • Table 4 Fit indices for measurement model for the research model
畫圖要謹守圖形規則: 顯現變數:矩形; 潛伏變數:橢圓形; 獨特變數:圓圈; 獨特變數的變異數:半圓形; 影響用直線,且影響方向不要 搞錯; 關係用曲線
結構方程模式的分析過程
模型發展: 概念發生的先後順 序,相互作用不斷 發生的往覆過程。 理 論
模式界定
模式識別 估計與評鑑:
選擇測量變項及蒐集資料
CFI 假設模型與獨立型模型的非中央 性差異
RMSEA 比較理論模式與飽合模式的 差距 AIC 經過簡約調整的模型契合度的波 動性 CAIC 經過簡約調整的模型契合度的 波動性
0-1
>0.95
說明模型較虛無模型的改 善程度,適合小樣本
不受樣本數與模型複離度 影響
0-1
<0.05
越小越好 適用於效度複核非巢套模 式比較 越小越好 適用於效度複核非巢套模 式比較
越小越好 瞭解殘差特性 <0.08 瞭解殘差特性
模型契合度指標的比較
適合度指標指標名稱及性質 GFI 假設模型可以解釋觀察資料之比例
AGFI 考慮模型複雜度後的 GFI PGFI 考慮模型簡約性 NFI 比較假設模型與獨立模型的卡方差異 NNFI 考慮模型複雜度後的 NFI * 指數數值可能會超出範圍之外
範圍 0-1
0-1* 0-1 0-1 0-1*
判斷值 >0.9
>0.9 >0.5 >0.9 >0.9
结构方程模型估计案例
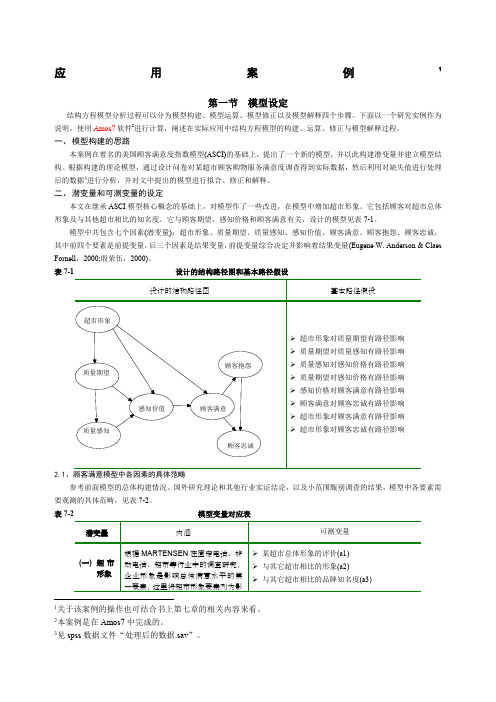
应用案例1第一节 模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、 模型构建的思路本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、 潜变量和可测变量的设定本文在继承ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell ,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss 数据文件“处理后的数据.sav ”。
4正向的,采用Likert10级量度从“非常低”到“非常高”三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
结构方程模型案例

结构方程模型案例结构方程模型 (Structural Equation Modeling, SEM) 是一种统计分析方法,用于建立和检验变量之间的因果关系模型。
这种模型可以用于解决许多复杂的研究问题,如预测变量之间的关系、检验理论模型以及估计和测试不同截面之间的因果关系。
本文将通过一个实际案例来说明如何使用结构方程模型。
案例背景:公司想要了解员工满意度对工作绩效的影响,以及工作环境对员工满意度和工作绩效的影响。
公司采集了员工的满意度、工作绩效和工作环境的数据,并希望通过结构方程模型来分析这些变量之间的关系。
理论模型:基于现有研究和理论,研究者提出了以下理论模型:工作环境->员工满意度->工作绩效变量测量:为了构建结构方程模型,首先需要测量各个变量。
在这个案例中,工作环境通过一个问卷调查来测量,员工满意度通过一个满意度调查来测量,工作绩效通过员工的绩效评价来测量。
每个变量通过多个观测指标来测量,例如,工作环境包括工作安全、工作福利、工作周围环境等指标。
模型估计:模型分析:经过模型估计后,可以进行模型分析来检验理论模型的拟合度。
在这个案例中,我们可以使用路径系数(standardized path coefficients)来解释变量之间的因果关系。
例如,路径系数的大小表示一个变量对另一个变量的直接影响程度,路径系数的方向则表示两个变量之间的关系是正向还是负向。
结果解释:通过模型分析,研究者可以得到一个具有统计显著性的结构方程模型。
然后,研究者可以通过路径系数解释变量之间的关系。
在这个案例中,结果可能显示工作环境对员工满意度有正向影响,员工满意度对工作绩效有正向影响。
这意味着改善工作环境可能会提高员工满意度,从而提高工作绩效。
结论与建议:最后,研究者可以根据结构方程模型的结果提出结论和建议。
在这个案例中,研究者可以建议公司改善工作环境,以提高员工满意度和工作绩效。
此外,研究者还可以进一步研究其他影响员工满意度和工作绩效的因素,以完善这个模型。
结构方程模型估计案例

结构方程模型估计案例
一、案例背景
本案例涉及一所位于美国的研究型大学,本案例旨在通过结构方程模
型估计学生参与大学课程的因素。
为此,本案例采用了一份包含180个受
访者的调查数据,每个受访者均为本校大学生。
二、研究假设
●学生投入的时间越多,他们的学习成绩就会越高。
●当学生有充足的资源可用时,他们的学习成绩会更高。
●学生对学习任务的兴趣和动机越高,他们的学习成绩也会越高。
●学生的学习成绩受到家庭背景和家庭环境的影响。
三、研究模型
本案例选择结构方程模型(SEM)进行模型估计,此模型包含四个变量,即学习时间(T)、学习资源(R)、兴趣/动机(I)和家庭环境(E)。
根据协方差矩阵,这四个变量都会对学生学习成绩(O)产生影响。
四、数据收集
本案例的数据收集工作包括:
1.对学生进行面对面访谈,收集学生投入课程的时间、学习资源、兴
趣/动机和家庭环境的信息,以及他们的学习成绩。
2.使用定量数据分析方法(如SPSS和AMOS)进行数据分析,以获得
研究要求的结果。
三、结构方程模型。
结构方程模型完整版本
3 SEM与几种多元方法的比较
①SEM与传统多元统计方法(多元统计) 传统多元统计方法:检验自变量和因变量的单一关系(多元方差分
析可以处理多个,但是关系也是单一的) SEM:综合多种方法,验证性分析,允许测量误差的存在 ②SEM与典型相关分析(多个自变量与多个因变量之间关系) 典型相关分析:两组随机变量(定性或定量)之间线性密切程度;
1 假设条件
测量模型误差项 , 的均值为零
结构模型的残差项 的均值为零
误差项 , 与因子 , 之间不相关,误差项 与
不相关
残差项 与 , , 之间不相关
2 共变推导
(1)协方差
协方差:利用两个变量间观测值与其均值离差的期望观测两 个变量间的关系强弱。
(2)运算定理 ① C ov(X,X)V ar(X) ② C ov(aXbY,cZdU )acC ov(X,Z)adC ov(X,U )bcC ov(Y,Z)bdC ov(Y,U )
不同潜在变量的两个观测变量的协方差:
C o v(V 1 ,V 4) C o v(1 F 1E 1 , 4F 2E 4) 14 C o v(F 1 ,F 4)1 C o v(F 1 ,E 4)4 C o v(E 1 ,F 2) C o v(E 1 ,E 4) 14 C o v(F 1 ,F 2)142 1
结构模型:反映潜在变量之间因果关系
方程式: 11111
22 112 112
0 0
B
2
1
0 Biblioteka
y11
y 2 1
1
结构方程模型的八种矩阵概念
符号
代表意义
结构模型矩阵
结构方程模型 ppt课件
CONTENTS
01 概念介绍 02 基本原理
03 案例分析
04 实际操作
ppt课件
2
01 概念介绍
1.基本概念
结构方程模型(Structural Equation Modeling, SEM)是一种验证性多元统计分析技术, 是应用线性方程表示观测变量与潜变量之间,以及潜变量之间关系的一种多元统计方法, 其实质是一种广义的一般线性模型。
ppt课件
19
02 基本原理
3.模型拟合——主要拟合度指标
(3)整体模型拟合度
a) χ2卡方拟合指数 检验选定的模型协方差矩阵与观察数据协方差矩阵相匹配的假设。原假设是模型协方差阵等 于样本协方差阵。如果模型拟合的好,卡方值应该不显著。在这种情况下,数据拟合不好的模型被拒绝。
b) RMR 是残差均方根。RMR 是样本方差和协方差减去对应估计的方差和协方差的平方和,再取平均值的平方根。 RMR应该小于0.08,RMR越小,拟合越好。
2.模型评价——参数估计 (1) 假设条件 ① 测量模型误差项δ,ε的均值为零 ② 结构模型的残差项ζ的均值为零 ③ 误差项ε,δ与因子η,ξ之间不相关,误差项ε与δ不相关 ④ 残差项ζ与ξ ,η ,δ之间不相关 (2)参数估计策略 ① 加权最小平方策略(WLS) ② 最大概似法(ML) ③ 无加权最小平方法(ULS) ④ 一般化最小平方法(GLS) ⑤ 渐进分布自由法(ADF)
5
6
结构模型:反映潜在变量之间因果关系
方程式: 1 11 1 1 2 21 1 21 1 2
0 0
B
21
0
结构方程模型的例子
圖一: 圖一:SEM Path Diagram的例子 的例子
δ1 λ1 ζ1
x1
λ2
λ7
y1
ε1
δ2
x2
δ3 λ3
ξ1
γ1
η1
λ8
ε2
y2
λ9 ε3
x3
δ4
λ4
Φ1
γ2
y3
β1
λ10 ε4
x4 y4
λ5
δ5
x5
ξ2
γ3
η2
λ11 ε5
y5
λ12 ε6
δ6
x6
λ6 ζ2
y6
圖一) 註(圖一 圖一
xi (or ksi; ξ1及ξ2)是自變項(Independent Variable;在SEM中稱為 Exogenous variables); (2) eta (η1及η2)是依變項(Dependent Variable;在SEM中稱為Endogenous variables); (3) x1, x2, x3是ξ1的測量項目、測量誤差為delta (δ1, δ2,δ3);x4, x5, x6是 ξ1的測量項目、測量誤差為delta (δ4, δ5,δ6); (4) y1, y2, y3是η1的測量項目、測量誤差為epsilon (ε1, ε2, ε3);y4, y5, y6 是η1的測量項目、測量誤差為epsilon (ε4, ε5, ε6); (5) lambda (λ1到λ12)是各自變項及依變項與其測量項目的關係; (6) gamma (γ1到γ3)是自變項與依變項的關係; (7) beta (β1)是依變項之間的關係; (8) zeta (ζ1及ζ2)是依變項尚未能被自變項及其他依變項解釋到的部分變 異量; (9) phi (Φ1)是自變項之間的關係; (10) 基本假設是:δ與ξ是無關的;ε與η是無關的;ζ與η是無關的;δ, ε及ζ 三者是無關的。 (1)
结构方程模型的例子
y2 =λ8η1 +ε2
x3 =λ3ξ1 +δ3
y3 =λ9η1 +ε3
x4 =λ4ξ2 +δ4
y4 =λ10η2 +ε4
x5 =λ5ξ2 +δ5
y5 =λ11η2 +ε5
x6 =λ6ξ2 +δ6
y6 =λ12η2 +ε6
「结构方程模型」的分析特点
透过所有「观察变项」之间的变异量和共 变量,来验证理如图一的理论模型(因此 有些研究人员也把「结构方程模型」称 为「共变量结构分析」;Covariance Structure Analysis) 。
「Three indicators were established for each multi-item measure by first fitting a single factor solution to each set of items and then averaging the items with highest and lowest loadings to form the first indicator, averaging the items with the next highest and lowest loadings to form the second indicator, and so forth until all items were assigned to one of the three indicators for each variable.
(2)模型二设定的限制较模型一多,例如在图一的模型中 我们再设定γ1和γ3的数值是相同的;及/或Φ1的数值为 零(即两个自变项之间没有关系)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
结构方程模型( Structural Equation,SEM)Modeling20 世纪——主流统计方法技术:因素分析回归分析20 世纪70 年代:结构方程模型时代正式来临结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。
在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。
SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/ 因变量预测模型的参数估计。
结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。
实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。
多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。
结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。
在许多科学领域的研究中,有些变量并不能直接测量。
实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。
人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。
在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。
自变量测量误差的发生会导致常规回归模型参数估计产生偏差。
虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。
只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。
简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。
与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。
通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。
”目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus.结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程(LV之间关系的方程,内部关系),以ACSI模型为例,具体形式如下:测量方程 y =Λyη+εy , x =Λxξ+εx=(1 )结构方程 η=Bη+Гξ+ζ 或 (I- Β)η =Гξ+ζ (2) 其中,η和ξ分别是内生 LV 和外生 LV ,y 和x 分别是和的 MV ,Λx 和Λy 是载荷矩阵,Β和Г 是路径系数矩阵, ε和ζ是残差。
三种分析方法对比线性相关分析: 线性相关分析指出两个随机变量之间的统计联系。
等,没有因变量和自变量之分。
因此相关系数不能反映单指标与总体之间的因果关系测量模式两个变量地位平线性回归分析:线性回归是比线性相关更复杂的方法,它在模型中定义了因变量和自变量。
但它只能提供变量间的直接效应而不能显示可能存在的间接效应。
而且会因为共线性的原因,导致出现单项指标与总体出现负相关等无法解释的数据分析结果。
结构方程模型分结构方程模型是一种建立、估计和检验因果关系模型的模型中既包含有可观测的显在变量,也可能包含无法直接观测的潜在变量。
结构方程模型可以替代多重回归、通径分析、因子分析、协方差分析等方法,清晰分析单项指标对总体的作用和单项指标间的相互关系。
结构方程模型假设条件⑴合理的样本量(James Stevens 的Applied Multivariate Statistics for the Social Sciences 一书中说平均一个自变量大约需要15 个case ;Bentler and Chou (1987)说平均一个估计参数需要5 个case 就差不多了,但前提是数据质量非常好;这两种说法基本上是等价的;而Loehlin (1992)在进行蒙特卡罗模拟之后发现对于包含2~4 个因子的模型,至少需要100 个case ,当然200 更好;小样本量容易导致模型计算时收敛的失败进而影响到参数估计;特别要注意的是当数据质量不好比如不服从正态分布或者受到污染时,更需要大的样本量)⑵连续的正态内生变量(注意一种表面不连续的特例:underlyingcontinuous ;对于内生变量的分布,理想情况是联合多元正态分布即JMVN)⑶模型识别(识别方程)(比较有多少可用的输入和有多少需估计的参数;模型不可识别会带来参数估计的失败)⑷完整的数据或者对不完整数据的适当处理(对于缺失值的处理,一般的统计软件给出的删除方式选项是pairwise 和listwise ,然而这又是一对普遍矛盾:pairwise 式的删除虽然估计到尽量减少数据的损失,但会导致协方差阵或者相关系数阵的阶数n 参差不齐从而为模型拟合带来巨大困难,甚至导致无法得出参数估计;listwise 不会有pairwise 的问题,因为凡是遇到case 中有缺失值那么该case 直接被全部删除,但是又带来了数据信息量利用不足的问题——全杀了吧,难免有冤枉的;不杀吧,又难免影响整体局势)⑸模型的说明和因果关系的理论基础(实际上就是假设检验的逻辑——你只能说你的模型不能拒绝,而不能下定论说你的模型可以被接受)结构方程模型的技术特性:1.SEM具有理论先验性2.SEM同时处理测量与分析问题3.SEM以协方差的运用为核心,亦可处理平均数估计4.SEM适用于大样本的分析——一般而言,大于200 以上的样本,才可称得上是个中型样本。
5.SEM包含了许多不同的统计技术。
6.SEM重视多重统计指标的运用结构方程模型的实施步骤⑴模型设定。
研究者根据先前的理论以及已有的知识,通过推论和假设形成一个关于组变量之间相互关系(常常是因果关系)的模型。
这个模型也可以用路径表明制定变量之间的因果联系。
⑵模型识别。
模型识别时设定SEM模型时的一个基本考虑。
只有建设的模型具有识别性,才能得到系统各个自由参数的唯一估计值。
其中的基本规则是,模型的自由参数不能够多于观察数据的方差和协方差总数。
⑶模型估计。
SEM模型的基本假设是观察变量的反差、协方差矩阵是一套参数的函数。
把固定参数之和自由参数的估计带入结构方程,推导方差协方差矩阵Σ ,使每一个元素尽可能接近于样本中观察变量的方差协方差矩阵S中的相应元素。
也就是,使Σ与S 之间的差异最小化。
在参数估计的数学运算方法中,最常用的是最大似然法(ML)和广义最小二乘法(GLS)。
⑷模型评价。
在已有的证据与理论范围内,考察提出的模型拟合样本数据的程度。
模型的总体拟合程度的测量指标主要有χ2检验、拟合优度指数(GFI)、校正的拟合优度指数(AGFI)、均方根残差(RMR)等。
关于模型每个参数估计值的评价可以用“ t ”值。
⑸模型修正。
模型修正是为了改进初始模型的适合程度。
当尝试性初始模型出现不能拟合观察数据的情况(该模型被数据拒绝)时,就需要将模型进行修正,再用同一组观察数据来进行检验。
探索性分析定义:探索性因子分析法( Exploratory Factor Analysis ,EFA )是一项用来找出多元观测变量的本质结构、并进行处理降维的技术。
因而, EFA 能够将将具有错综复杂关系的变量综合 为少数几个核心因子。
在缺乏坚实的理论基础支撑,有关观测变量内部结构,一般用探索性因子分析。
先用探 索性因子分析产生一个关于内部结构的理论,再在此基础上用验证性因子分析。
但这必须用 分开的数据集来做。
探索性分析步骤:1、辨别、收集观测变量。
按照实际情况收集观测变量,并对其进行观测,获得观测值。
针对总体复杂性和统计基本原理的保证,通常采用抽样的方法收集数据来达到研究目的。
2、获得协方差阵(或 Bravais-Pearson 的相似系数矩阵)。
我们所有的分析都是从原始 数据的协方差阵(或相似系数矩阵)出发的,这样使我们分析得到的数据具有可残差探索性分析的适用情况: 指标 因子负荷 潜变量比性,所以首先要根据资料数据获得变量协方差阵(或相似系数矩阵)。
3、确定因子个数。
有时候你有具体的假设,它决定了因子的个数;但更多的时候没有这样的假设,你仅仅希望最后的到的模型能用尽可能少的因子解释尽可能多的方差。
如果你有k 个变量,你最多只能提取k 个因子。
通过检验数据来确定最优因子个数的方法有很多,例如Kaiser 准则、Scree 检验。
方法的选择由,具体操作时视情况而定。
4、提取因子。
因子的提取方法也有多种,主要有主成分方法、不加权最小平方法、极大似然法等,我们可以根据需要选择合适的因子提取方法。
其中主成分方法一种比较常用的提取因子的方法,它是用变量的线性组合中,能产生最大样品方差的那些组合(称主成分)作为公共因子来进行分析的方法。
5、因子旋转。
因子载荷阵的不唯一性,使得可以对因子进行旋转。
这一特征,使得因子结构可以朝我们可以合理解释的方向趋近。
我们用一个正交阵右乘已经得到的因子载荷阵(由线性代数可知,一次正交变化对应坐标系的一次旋转),使旋转后的因子载荷阵结构简化。
旋转的方法也有多种,如正交旋转、斜交旋转等,最常用的是方差最大化正交旋转。
6、解释因子结构。
最后得到的简化的因子结构是使每个变量仅在一个公共因子上有较大载荷,而在其余公共因子上的载荷则比较小,至多是中等大小。
通过这样,我们就能知道所研究的这些变量是由哪些潜在因素(也就是公共因子)影响的,其中哪些因素是起主要作用的,而哪些因素的作用较小,甚至可以不用考虑。
7、因子得分。
因子分析的数学模型是将变量表示为公共因子的线性组合,由于公共因子能反映原始变量的相关关系,用公共因子代表原始变量时,有时更利于描述研究对象的特征,因而往往需要反过来将公共因子表示为变量的线性组合,即因子得分。
验证性因子分析定义:验证性因子分析是对社会调查数据进行的一种统计分析。
它测试一个因子与想对应的测度项之间的关系是否符合研究者所设计的理论关系。
验证性因子分析(confirmatory factor analysis)的强项在于它允许研究者明确描述一个理论模型中的细节。
因为测量误差的存在,研究者需要使用多个测度项。
当使用多个测度项之后,我们就有测度项的“质量”问题,即效度检验。
而效度检验就是要看一个测度项是否与其所设计的因子有显著的载荷,并与其不相干的因子没有显著的载荷。
对测度模型的检验就是验证性测度模型。
对测度模型的质量检验是假设检验之前的必要步骤。
而验证性因子分析(CFA)是用来检验已知的特定结构是否按照预期的方式产生作用。
残差观测变量负荷潜变量验证性因子分析的步骤:1、定义因子模型。