hive开发资料
Hive入门

Hive⼊门第⼀章 Hive 基本概念1.1 什么是 HiveApache Hive是⼀款建⽴在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop⽂件中的结构化、半结构化数据⽂件映射为⼀张数据库表,基于表提供了⼀种类似SQL的查询模型,称为Hive查询语⾔(HQL),⽤于访问和分析存储在Hadoop⽂件中的⼤型数据集。
Hive核⼼是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执⾏。
Hive由Facebook实现并开源。
1.2 为什么使⽤Hive使⽤Hadoop MapReduce直接处理数据所⾯临的问题⼈员学习成本太⾼需要掌握java语⾔MapReduce实现复杂查询逻辑开发难度太⼤使⽤Hive处理数据的好处操作接⼝采⽤类SQL语法,提供快速开发的能⼒(简单、容易上⼿)避免直接写MapReduce,减少开发⼈员的学习成本⽀持⾃定义函数,功能扩展很⽅便背靠Hadoop,擅长存储分析海量数据集1.3 Hive与Hadoop的关系从功能来说,数据仓库软件,⾄少需要具备下述两种能⼒:存储数据的能⼒分析数据的能⼒Apache Hive作为⼀款⼤数据时代的数据仓库软件,当然也具备上述两种能⼒。
只不过Hive并不是⾃⼰实现了上述两种能⼒,⽽是借助Hadoop。
Hive利⽤HDFS存储数据,利⽤MapReduce查询分析数据。
这样突然发现Hive没啥⽤,不过是套壳Hadoop罢了。
其实不然,Hive的最⼤的魅⼒在于⽤户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive与MysqlHive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都⼗分相似,但应⽤场景却完全不同。
Hive只适合⽤来做海量数据的离线分析。
Hive的定位是数据仓库,⾯向分析的OLAP系统。
因此时刻告诉⾃⼰,Hive不是⼤型数据库,也不是要取代Mysql承担业务数据处理。
hive编程指南 笔记

hive编程指南笔记一、Hive基础1.Hive是一种基于Hadoop的数据仓库工具,用于处理和分析大规模数据。
2.Hive支持SQL查询语言,称为HiveQL,可以方便地对数据进行查询和分析。
3.Hive的数据存储在HDFS中,通过Hive的数据处理引擎进行查询和分析。
二、Hive安装与配置1.Hive的安装主要包括下载并解压Hive的安装包,配置Hive 的环境变量等。
2.Hive的配置主要包括设置Hive的元数据存储位置、设置Hive 的数据存储位置等。
三、Hive数据类型1.Hive支持多种数据类型,包括基本数据类型和复杂数据类型。
2.基本数据类型包括整数类型、浮点数类型、字符串类型等。
3.复杂数据类型包括数组类型、结构体类型、映射类型等。
四、Hive表操作1.Hive支持创建表、删除表、修改表等操作。
2.创建表时需要指定表的名称、表的存储位置、表的数据类型等信息。
3.删除表时需要指定表的名称。
4.修改表时可以对表的字段进行添加、删除或修改。
五、Hive查询操作1.Hive支持SQL查询语言,可以使用SELECT语句进行数据的查询。
2.Hive还支持聚合函数、连接操作、条件过滤等操作。
3.查询结果可以通过输出到文件或输出到屏幕等方式进行展示。
六、Hive优化与调优1.Hive的查询性能可以通过优化查询语句、调整Hive的参数设置等方式进行优化。
2.Hive的调优包括调整Hive的数据存储位置、调整Hive的执行引擎等。
3.还可以通过使用一些工具和技巧来提高Hive的查询性能,例如使用Hive的缓存机制、使用Hive的并行执行等。
以上是关于Hive编程指南的笔记,希望对您有所帮助。
(完整word版)Java私塾:Hive的原理—— 深入浅出学Hive

Java私塾:Hive的原理——深入浅出学Hive目录:初始HiveHive安装与配置Hive 内建操作符与函数开发Hive JDBChive参数Hive 高级编程Hive QLHive Shell 基本操作hive 优化Hive体系结构Hive的原理配套视频课程第一部分:Hive原理为什么要学习Hive的原理•一条Hive HQL将转换为多少道MR作业•怎么样加快Hive的执行速度•编写Hive HQL的时候我们可以做什么•Hive 怎么将HQL转换为MR作业•Hive会采用什么样的优化方式Hive架构&执行流程Hive执行流程•编译器将一个Hive QL转换操作符•操作符是Hive的最小的处理单元•每个操作符代表HDFS的一个操作或者一道MapReduce作业Operator•Operator都是hive定义的一个处理过程•Operator都定义有:•protected List 〈Operator<?extends Serializable >>childOperators; •protected List <Operator<?extends Serializable >>parentOperators;•protected boolean done; // 初始化值为false•所有的操作构成了Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作Hive执行流程操作符描述TableScanOperator扫描hive表数据ReduceSinkOperator创建将发送到Reducer端的<Key,Value>对JoinOperator Join两份数据SelectOperator选择输出列FileSinkOperator建立结果数据,输出至文件FilterOperator过滤输入数据GroupByOperator GroupBy语句MapJoinOperator/*+mapjoin(t) */LimitOperator Limit语句UnionOperator Union语句•Hive通过ExecMapper和ExecReducer执行MapReduce任务•在执行MapReduce时有两种模式•本地模式•分布式模式ANTLR词法语法分析工具•ANTLR-Another Tool for Language Recognition•ANTLR 是开源的•为包括Java,C++,C#在内的语言提供了一个通过语法描述来自动构造自定义语言的识别器(recognizer),编译器(pars er)和解释器(translator)的框架•Hibernate就是使用了该分析工具Hive编译器编译流程第二部分:一条HQL引发的思考案例HQL•select key from test_limit limit1•Stage-1•TableScan Operator〉Select Operator-> Limit—>File Output Operator•Stage—0•Fetch Operator•读取文件Mapper与InputFormat•该hive MR作业中指定的mapper是:•mapred.mapper。
(完整word版)HIVE说明文档

HIVE说明文档一、HIVE简介:1、HIVE介绍Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。
它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL语句作为数据访问接口。
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据.2、HIVE适用性:它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。
HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。
它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合.hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。
数据是以load的方式加载到建立好的表中。
数据一旦导入就不可以修改。
DML包括:INSERT插入、UPDATE更新、DELETE删除。
3、HIVE结构Hive 是建立在Hadoop上的数据基础架构,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制,Hive定义了简单的累SQL 查询语言,称为HQL,它允许熟悉SQL的用户查询数据,同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理內建的mapper和reducer无法完成的复杂的分析工作。
hive的基础知识 -回复

hive的基础知识-回复Hive的基础知识[Hive的基础知识],作为一个开源的数据仓库基础设施,是构建在Hadoop之上的。
它提供了一个简单方便的方式,让用户能够利用SQL 查询分析大规模的数据。
相对于传统的关系型数据库,Hive的优势在于其可扩展性和容错性。
一、Hive的概述Hive最初由Facebook开发,其目标是为了解决处理大规模数据的难题。
Hive实际上是建立在Hadoop上的一个数据仓库基础设施,可以将结构化数据映射到Hadoop的分布式文件系统(HDFS)上,并提供完整的查询语言。
与传统的关系型数据库相比,使用Hive可以在海量数据上进行更快速的查询和分析,同时还能利用Hadoop的并行处理能力。
二、Hive的架构Hive的架构主要分为三部分:Metastore、Hive Query Language (HQL)和Execution Engine。
1. Metastore(元数据存储)Hive的Metastore存储着Hive的表结构信息,包括表的名称、列的类型、表的分区等。
Metastore可以将这些元数据存储在本地文件系统、MySQL等数据库中。
2. Hive Query Language(HQL)Hive使用Hive Query Language(HQL)作为查询语言,这是一种类似于SQL的语言,用于执行查询和数据处理操作。
HQL可以用来创建表、加载数据、执行查询等。
3. Execution Engine(执行引擎)Hive的执行引擎负责将HQL查询转化为MapReduce操作。
它将HQL查询拆分成一系列的Map和Reduce任务,然后将这些任务提交给Hadoop集群进行执行。
执行引擎可以选择使用Tez、Spark等不同的计算框架。
三、Hive表的创建与数据加载Hive的表可以通过HQL语句来创建,可以指定表的名称、表的字段和字段类型等信息。
以下是一个创建表的示例:sqlCREATE TABLE employees (id INT,name STRING,age INT,department STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;上述示例中,我们创建了一个名为employees的表,有四个字段:id、name、age和department。
hive开发规范及要点

Hive开发规范及编写要点HQL语言操作规范1.hive模糊搜索表show tables like '*name*';show table table_name;2.查看表结构信息desc table_name;3.查看分区信息show partitions table_name;4.根据分区查询数据select table_coulmn from table_name where partition_name = '2014-02-25';5.查看hdfs文件信息hadoop fs -ls /user/hive/warehouse/table_name;6.从文件加载数据进表(overwrite表示覆盖加载)7.加载本地文件load data local inpath '/xxx/xxx/dim_cube.txt' overwrite into table dim.dim_cube_config;8.从查询语句给table插入数据insert overwrite table table_name partition(dt) select * from table_name where dt='2014-01-22' limit 100;9.导出数据到本地系统insert overwrite local directory '/tmp/text' select a.* from table_name a order by 1;hive -e "select day_id,user,count from user_table where day_id in ('2014-03-06','2014-03-07','2014-03-08','2014-03-09','2014-03-10');"> /home/test/test.dat;10.自定义udf函数hive中执行命令add jar /home/hive/jar/my_udf.jar;create temporary function sys_date ascom.taobao.hive.udf.UDFDateSysdate';11.设置Hive执行参数;如:set hive.cli.print.header=true;// 打印列名set hive.cli.print.row.to.vertical=true;// 开启行转列功能, 前提必须开启打印列名功能set hive.cli.print.row.to.vertical.num=1;// 设置每行显示的列数12.查看表文件大小,下载文件到某个目录,显示多少行到某个文件hadoop fs -du hdfs://hadoop:54310/user/warehouse/user_log;13.杀死某个任务在hive shell中执行hadoop job -kill job_201403041453_58315(作业ID)12.删除分区alter table table_name drop partition(dt='2014-03-01');13.添加分区alter table table_name add partition (dt='2008-08-08', country='us')location '/path/to/us/part080808' partition (dt='2008-08-09', country='us');14.hive命令行操作hive -e 'select table_cloum from table'执行一个查询,在终端上显示mapreduce的进度,执行完毕后,最后把查询结果输出到终端上,接着hive进程退出,不会进入交互模式。
Hive培训ppt课件
3*
HIVE基本操Байду номын сангаас实例
1、登录生产环境,ssh 。 [hadoop@hm-nn-ser-01 ~]$ hive
2、查看表 hive (default)> show tables;
4*
HIVE基本操作实例
1* 0
Hive RCFile性能测试数据
1* 1
生产上HIVE表说明
目前生产环境上表名和分区结构说明如下: 三张表:ip_rc、http_rc、pdp_rc 三个分区,根据日期、小时、采集节点进行分区: 日期---pt_date---20140103 小时---pt_hour---2014010312 采集节点---pt_data---1
hive和普通关系数据库的异同hive的数据存储hive没有专门的数据存储格式也没有为数据建立索引用户可以非常自由的组织hive中的表只需要在创建表的时候告诉hive数据中的列分隔符和行分隔符hive就可以解析数据
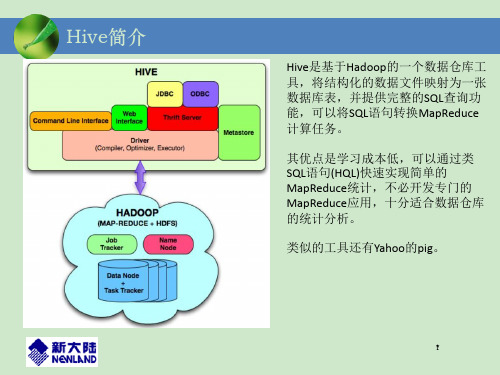
Hive简介
Hive是基于Hadoop的一个数据仓库工 具,将结构化的数据文件映射为一张 数据库表,并提供完整的SQL查询功 能,可以将SQL语句转换MapReduce 计算任务。
1* 2
HIVE语句规范和注意事项
1、Sql测试 由于集群计算资源比较宝贵,建议复杂一些的Sql语句需先在一个小时分区数据测 试,测试无误后生产数据上跑; 2、日期和小时分区 根据日期查找,pt_date条件注意放在where条件首位,在该分区下查找,防止全 表扫描。 3、字符集 Hadoop和Hive都是用UTF-8编码的,所有中文必须是UTF-8编码才能正常使用, 导出数据编码格式也是UTF-8。 4、String数据类型 只能用like进行模糊查询。 5、只有一个reduce的场景:
hive编程指南 笔记

hive编程指南笔记【原创实用版】目录1.Hive 简介2.Hive 的基本概念3.Hive 的安装与配置4.Hive 的编程模型5.Hive 的 QL 语言6.Hive 的应用实例7.Hive 的优缺点正文Hive 是一种基于 Hadoop 的数据仓库工具,可以用来处理和分析大规模的结构化数据。
它允许用户使用类似于 SQL 的查询语言(称为 HiveQL 或 QL)来查询、汇总和分析存储在 Hadoop 分布式文件系统(HDFS)上的数据。
在开始使用 Hive 之前,我们需要了解一些基本的概念。
首先,Hive 中的表对应于关系型数据库中的表,它由行和列组成。
表可以进一步分为内部表和外部表。
内部表是存储在 HDFS 上的数据,而外部表则是指向 HDFS 上的目录。
其次,Hive 中的分区类似于关系型数据库中的索引,它可以根据某一列或多列对表进行划分,以提高查询效率。
要使用 Hive,首先需要在本地或集群上安装 Hadoop,然后配置 Hive。
配置过程包括设置 Hive 的配置文件、初始化 Hive 元数据以及创建所需的表和分区。
Hive 有两种编程模型:MapReduce 和 Tez。
MapReduce 是 Hadoop 的基本编程模型,它将任务分解为一个 Map 阶段和一个 Reduce 阶段。
Tez 是一种新的编程模型,它提供了更多的灵活性和更好的性能。
Hive 的查询语言(HiveQL 或 QL)类似于 SQL,但它也支持一些特定的 Hive 功能,如 JOIN、GROUP BY、ORDER BY 等。
使用 HiveQL,用户可以编写复杂的查询语句来分析和处理数据。
Hive 的应用实例包括数据仓库、数据挖掘、报表生成等。
它可以处理大量的结构化数据,并提供高效的查询和分析功能。
Hive 的优点包括:1)基于 Hadoop,可以充分利用 Hadoop 的分布式处理能力;2)使用类似于 SQL 的查询语言,易于学习和使用;3)支持数据分区,可以提高查询效率;4)可以处理大规模的数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hive是一个基于Hadoop的数据仓库平台。
通过hive,我们可以方便地进行ETL的工作。
hive定义了一个类似于SQL的查询语言:HQL,能够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
本文讲解如何搭建一个Hive平台。
假设我们有3台机器:hadoop1,hadoop2,hadoop3。
并且都安装好了Hadoop-0.19.2(hive支持的Hadoop版本很多),hosts文件配置正确。
Hive部署在hadoop1机器上。
最简单,最快速的部署方案在Hadoop-0.19.2中自带了hive的文件。
版本为0.3.0。
我们首先启动Hadoop:sh $HADOOP_HOME/bin/start-all.sh然后启动hive即可:sh $HADOOP_HOME/contrib/hive/bin/hive这个时候,我们的Hive的命令行接口就启动起来了,你可以直接输入命令来执行相应的hive应用了。
这种部署方式使用derby的嵌入式模式,虽然简单快速,但是无法提供多用户同时访问,所以只能用于简单的测试,无法实际应用于生产环境。
所以,我们要修改hive的默认配置,提高可用性。
搭建多用户的,提供web界面的部署方案目前只用比较多hive版本是hive-0.4.1。
我们将使用这个版本来搭建hive平台。
首先,下载hive-0.4.1:svn co/repos/asf/hadoop/hive/tags/release-0.4.1/ hive-0.4.1然后,修改下载文件里面的编译选项文件shims/ivy.xml,将其修改为如下内容(对应的Hadoop版本为0.19.2)<ivy-module version="2.0"><info organisation="org.apache.hadoop.hive" module="shims"/> <dependencies><dependency org="hadoop" name="core" rev="0.19.2"><artifact name="hadoop" type="source" ext="tar.gz"/></dependency><conflict manager="all" /></dependencies></ivy-module>接下来,我们使用ant去编译hive: ant package编译成功后,我们会发现在build/dist目录中就是编译成功的文件。
将这个目录设为$HIVE_HOME修改conf/hive-default.xml文件,主要修改内容如下:<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:derby://hadoop1:1527/metastore_db;create=true</ value><description>JDBC connect string for a JDBCmetastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>org.apache.derby.jdbc.ClientDriver</value><description>Driver class name for a JDBC metastore</description> </property>在hadoop1 机器上下载并安装apache derby数据库:wget/apache-mirror/db/derby/db-derby-10.5.3.0/ db-derby-10.5.3.0-bin.zip解压derby后,设置$DERBY_HOME然后启动derby的network Server:sh$DERBY_HOME/bin/startNetworkServer -h 0.0.0.0接下来,将$DERBY_HOME/lib目录下的derbyclient.jar与derbytools.jar 文件copy到$HIVE_HOME/lib目录下。
启动Hadoop:sh $HADOOP_HOME/bin/start-all.sh最后,启动hive的web界面:sh $HIVE_HOME/bin/hive --service hwi这样,我们的hive就部署完成了。
我们可以直接在浏览器中输入:http://hadoop1:9999/hwi/进行访问了(如果不行话,请将hadoop1替换为实际的ip地址,如:http://10.210.152.17:9999/hwi/)。
这种部署方式使用derby的c/s模式,允许多用户同时访问,同时提供web界面,方便使用。
推荐使用这种部署方案。
关注Hive的schema我们上面谈到的2中部署方案都是使用derby数据库来保存hive中的schema信息。
我们也可以使用其他的数据库来保存schema信息,如mysql。
可以参考这篇文章了解如果使用mysql来替换derby:/blog/post/2010/02/01/Setting-up-Hadoop Hive-to-use-MySQL-as-metastore.aspx我们也可以使用HDFS来保存schema信息,具体的做法是修改conf/hive-default.xml,修改内容如下:<property><name>hive.metastore.rawstore.impl</name><value>org.apache.hadoop.hive.metastore.FileStore</value><description>Name of the class that implementsorg.apache.hadoop.hive.metastore.rawstore interface. This class is used to store and retrieval of raw metadata objects such as table, database</description></property>主要分为以下几个部分:∙用户接口,包括CLI,Client,WUI。
∙元数据存储,通常是存储在关系数据库如mysql, derby 中。
∙解释器、编译器、优化器、执行器。
∙Hadoop:用HDFS 进行存储,利用MapReduce 进行计算。
1.用户接口主要有三个:CLI,Client 和 WUI。
其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive 副本。
Client 是Hive 的客户端,用户连接至Hive Server。
在启动Client 模式的时候,需要指出Hive Server 所在节点,并且在该节点启动Hive Server。
WUI 是通过浏览器访问Hive。
2.Hive 将元数据存储在数据库中,如mysql、derby。
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3.解释器、编译器、优化器完成HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
生成的查询计划存储在HDFS 中,并在随后有MapReduce 调用执行。
4.Hive 的数据存储在HDFS 中,大部分的查询由MapReduce 完成(包含* 的查询,比如select * from tbl 不会生成MapRedcue 任务)。
Hive 元数据存储Hive 将元数据存储在RDBMS 中,有三种模式可以连接到数据库:∙Single User Mode:此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
∙Multi User Mode:通过网络连接到一个数据库中,是最经常使用到的模式。
∙Remote Server Mode:用于非Java 客户端访问元数据库,在服务器端启动一个MetaStoreServer,客户端利用Thrift 协议通过MetaStoreServer 访问元数据库。
Hive 的数据存储首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive 中的表,只需要在创建表的时候告诉Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在HDFS 中,Hive 中包含以下数据模型:Table,External Table,Partition,Bucket。
1.Hive 中的Table 和数据库中的Table 在概念上是类似的,每一个Table 在Hive 中都有一个相应的目录存储数据。
例如,一个表pvs,它在HDFS 中的路径为:/wh/pvs,其中,wh 是在hive-site.xml 中由${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的Table 数据(不包括External Table)都保存在这个目录中。
2.Partition 对应于数据库中的Partition 列的密集索引,但是Hive 中Partition 的组织方式和数据库中的很不相同。
在Hive 中,表中的一个Partition 对应于表下的一个目录,所有的Partition 的数据都存储在对应的目录中。
例如:pvs 表中包含ds 和city 两个Partition,则对应于ds = 20090801, ctry = US 的HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于ds = 20090801, ctry =CA 的HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA3.Buckets 对指定列计算hash,根据hash 值切分数据,目的是为了并行,每一个Bucket 对应一个文件。