5分钟搞定Stata面板数据分析
(完整word版)STATA面板数据模型操作命令讲解

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
(最新整理)STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(STATA面板数据模型操作命令讲解)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为STATA面板数据模型操作命令讲解的全部内容。
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令 固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F 。
y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2。
y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
5分钟速学stata面板数据回归初学者超实用!

5分钟速学stata面板数据回归初学者超实用!5 分钟速学 Stata 面板数据回归初学者超实用!在当今的数据分析领域,Stata 软件因其强大的功能和易用性而备受青睐。
对于初学者来说,掌握 Stata 中的面板数据回归分析是一项非常有用的技能。
在接下来的 5 分钟里,让我们一起快速了解一下面板数据回归的基础知识和操作步骤。
首先,我们来了解一下什么是面板数据。
面板数据是一种同时包含时间和个体两个维度的数据结构。
比如说,我们研究多个公司在若干年的财务数据,这就是一个典型的面板数据。
与单纯的横截面数据或时间序列数据相比,面板数据能够提供更丰富的信息,有助于我们更好地理解和解释经济现象。
那么,为什么要使用面板数据回归呢?它有几个显著的优点。
一是可以控制个体的异质性,即不同个体之间可能存在的固有差异。
二是能够更好地捕捉动态效应,观察变量随时间的变化。
三是增加了样本量,提高了估计的效率和准确性。
在 Stata 中进行面板数据回归,我们首先需要将数据导入。
假设我们的数据文件是一个 Excel 表格,我们可以使用`import excel` 命令来导入数据。
当然,如果数据是其他格式,如 CSV 等,Stata 也提供了相应的导入命令。
导入数据后,我们需要告诉 Stata 这是一个面板数据,并指定个体标识变量和时间标识变量。
例如,如果我们的数据中,每个公司有一个唯一的代码作为个体标识,每年有一个年份作为时间标识,我们可以使用以下命令:```stataxtset company_id year```接下来,就是选择合适的面板数据回归模型。
常见的模型有固定效应模型和随机效应模型。
固定效应模型假设个体之间的差异是固定的,不随时间变化。
如果我们认为个体的未观测到的特征与解释变量相关,那么就应该选择固定效应模型。
在 Stata 中,可以使用`xtreg y x1 x2, fe` 命令来进行固定效应回归。
随机效应模型则假设个体之间的差异是随机的,与解释变量不相关。
STATA面板数据模型操作命令讲解
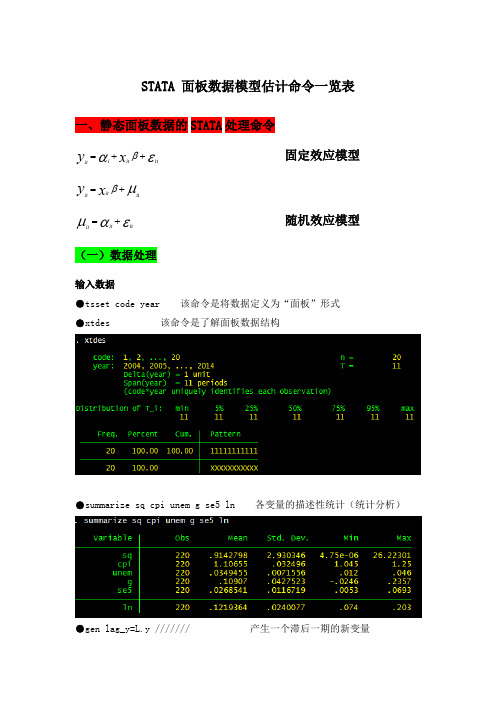
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
chap13_stata面板数据分析

型的回归、固定效应和随机效应模型的拟合、Hausman检 验以及模型预测等内容。
实验操作指导
1 组间效应模型
对于“wage.dta”的数据,我们要分析受教育年数、年龄、工作年数、
现有岗位的任职时间、是否是黑人、是否居住在SMSA区、是否生活 在南方等因素对工资收入的影响。考虑到年龄、工作年数、现有岗位 任职时间等因素对工资收入的影响可能不是线性的,我们先生成这三 个变量的平方项,并在模型中包括这三个变量的水平项和平方项。输 入命令: gen age2=age*age gen exp2=ttl_exp*ttl_exp gen tenure2=tenure*tenure 我们生成变量age、ttl_exp和tenure的平方项,并分别将其命名为age2、 exp2和tenure2。 此外,我们需要由变量race生成一个虚拟变量,来表示是否是黑人。 输入命令: gen byte black = race==2 这里,我们生成新变量black,并令其类型为type。注意,race后为两 个等号。该命令的含义为,对race是2的(黑人)观测值,我们令 black的值为1;对race取其他值的观测值,我们令black的值为0。也就 是说新生成的变量black为虚拟变量,1表示黑人,0表示其他人种。
对于“wage.dta”的数据,我们下面进行固定效应回归。输入命令: xtreg ln_wage grade age age2 ttl_exp exp2 tenure tenure2 black
not_smsa south, fe 这里,选项fe表明是进行固定效应回归分析。
3 随机效应模型
对于“wage.dta”的数据,我们要知道其数据分布情况,
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的 STATA 处理命令固定效应模型随机效应模型(一)数据处理输入数据• tsset code year 该命令是将数据定义为“面板”形式 • xtdes该命令是了解面板数据结构・ xtdescode: 1i 2, ■■■( 20n 工 20 year : 3004, 2005, ■…,2014T =11Delta(year) =1 unit span(year) =11 periods(code*year uniquely identifies eachobservation)Distribution of:min 8%2璃50^ 75% 95%max1111 11111111 11Freq. Percent Cum. Pattern20 100.00 100.00 1111111111120100.00XXXXXXXXXXX・ summarize sc I cpi unem gse5 InvariableObs Mean Std ・ Dev.Mi nMax sq 220 .Q142798 2.9303464.75e-0626.22301cpi2201*10655 *032496 1.045 1. 25 unem22Q .0349455 .0071556 .012 ,046 g220,10907 .0427523 0246 .2357220 .0268541 011671? .0053.0693220.1219364.0240077,074,203• summarize sq cpi unem g se5 In各变量的描述性统计(统计分析)• gen lag_y=L.y ///////产生一个滞后一期的新变量*= Xitit• ;itto U 一 if对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所 有的个体效应整体上显著。
stata分析面板数据

引言概述面板数据(Paneldata)是一种特殊类型的数据,它同时包含了横向和纵向的信息。
对于研究人员来说,面板数据的分析具有重要的意义,因为它可以对个体、时间和个体在不同时间上的变异进行深入研究。
Stata是一种流行的统计软件,具备强大的面板数据分析功能,可以处理各种面板数据相关的统计问题。
本文将介绍Stata分析面板数据的方法与技巧。
正文内容一、数据准备与导入1.定义面板变量:在Stata中,我们需要先将面板数据转换为面板变量。
可以使用“xtset”命令来定义面板变量,并指定个体和时间的标识变量。
例如,命令“xtsetidyear”可以将变量“id”作为个体标识变量,“year”作为时间标识变量。
2.导入面板数据:Stata支持多种数据格式的导入,如Excel、CSV等。
可以使用“importdelimited”命令导入CSV格式的面板数据。
命令格式如下:“importdelimitedfilename,varnames(1)”.其中,filename是文件名,varnames(1)表示将第一行作为变量名。
二、面板数据的描述统计分析1.描述性统计:在面板数据分析中,我们首先需要对数据进行描述性统计。
可以使用“summarize”命令计算平均值、标准差、最小值、最大值等统计指标。
例如,“summarizevarname”可以计算变量varname的平均值、标准差等。
2.变量相关分析:面板数据中的变量通常具有时间序列的特征,因此,变量之间的相关性也具有时间相关性。
可以使用“xtcorr”命令来计算面板数据中变量的相关系数矩阵。
命令格式如下:“xtcorrvar1var2,pwcorr”.其中,var1和var2是需要计算相关系数的变量。
三、面板数据的固定效应模型分析1.固定效应模型简介:固定效应模型是一种常见的面板数据分析方法,它考虑了个体固定效应,并通过个体虚拟变量来捕捉个体固定效应对因变量的影响。
(完整word版)STATA面板数据模型操作命令讲解

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量 gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型.●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型.●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【原创】5分钟搞定Stata面板数据分析简易教程ver2.0作者:张达5分钟搞定Stata面板数据分析简易教程步骤一:导入数据原始表如下,数据请以时间(1998 ,1999,2000, 2001 ??)为横轴,样本名(北京,天津,河北??) 为纵轴1 裁*■■別1A I11 ■u 9K ILEXxl-V,j si aoLL B-iic190 ..1( HJ曲1 1g力«r4 々■l* Mfl 1KM J| JgRi MM3icm*w II7QQ-HQ Siq<XM3 7>D tuff 1'C4 3 4 IftJV-mi KH>loogi liW(0M 3M9WH jaii I MOKai W w ■齐itmxm fill OTI MiltaiK ■5W»U|JTXE HH sia心«9 f Id 叼m in a*ft I*■JtaC如M~4 気HiA|$A rm inoo IM? livra.wvtatr1IJMj X#*4>t1|筑・BF7 ■«|!N I9*V1IRV gw1W1VJ I-J H itW Ml «稠申审砂y li>M l>R Mdw VIM e> mu IM HM 內)944w 命■ n I L BII i mi 靜Ml hw w3K:1ST? *7^ FJE inm ifini uni4 5w 心HtJ TW JTfl 9MI*HAS■ilJto KO >4*461/M31 <141*11诃却4LJt 4ktt VM匸F<MO 4dN,■M I!Wi・】•\ 4 ■R- 呵鬥1皑用MA■J广*»i g Ml* <KM11*K=« 1 31 1MM I“tlM韓!1fi >w g ivt E4M laM■ii T PD w im W i.JV 1P w L*l 1tiZF MM7 <1 H1! liyi将中文地名替换为数字。
注意:表中不能有中文字符,否则会出现错误。
面板数据中不能有空值。
A 4豪««A*bmaHAfl M A辜1*U11 ■■疋***il1 3 T■|v J科■■i £ * isS a 4 fl»■ Aa-fT"iyi4C nv j| if. |f J_■ ■:』 1 I TO E 稱如Mfl 1Rft«MM 17M UQI iWt m >nm ・IM A3 山・・■ HQ RiE04 UJ ■JI 1£*・咗內mt临■AV tm 4131 ItJVtfTW W3 F1M 11 s IT-B 1FM17*K・・Ijfi artf M?MU39 •<n»M M W WPi sy0J1 1S|&Wli fd ■徳xm JC3I Z71I JMI 厂丽10w Jfl>3 17円vag*9 Ifi3h4 .UM 1112 «n«nr l:tA xi y專鲨>■- F A) '2H2 lii B| 1严仝“ #■*‘^2^2 I If<W ・~4 A:fe il-t««■Itlfi M^fli 9731I^QD IM? IW3"IM ELJftfl申血i jjg.j aw XV IM■■卄1山・・Mi V7M|:H MF IQMQ11RV>Mli n>17 »^LMM*啪■i|l-4 帕砂,M)I 卫w IP* S4I V M} HM I ]■■■20冲■理LKlIll i.mi即空it^3 1ST?' I 基fit 虫3UE lar? <7^ 17^i!m. IfiTD|肝』 4 (Jf. w e 祸1 j is*a-h BtJ T A M?M 9MI却」VttC guH ”IM i I4d^t 1/443 R-lfej.!■ W L| H'*40 粘MJt 4Ui VM i?n 1>IV4404dri> im>FT«a 1 26S-4 购!J IJI rj|.列***Ha■丿UK MVt <feW 4>'tt IIF”I巾供I i|Wfl III |KM i< >WI4 IA JJ l>^t14M 一也11 屮処417 PQ HI怕I Til;! t?V 1丸Ml申住F MH H'l 1^7 44, i*11 ■w去除年份的一行,将其余部分复制到stata的data editor中,或保存为csv格式。
4n n建方财歳决需支出中區炳岌出恵氐十ir^i =_r 十L・亠」亠j匸4 E藝巾q-件曹中Ff ■,JI 鼻-;L M > 1* ■«InarLAn」4u ■■* 0•M r* ■严t ■ «11* a.5 *亘*dJ-I■■r«j t*JU ft / U kA・jm i 瞬f1林gt«r*x・■ Aa*朴_ —C Ci F c H] 1fX> JW4lt ■ IT31S* 咖2TH 呻rl砂側紳i3*HaJ HU 1却M|nm*a?r JM 才*g 世¥EH' JM,m Mfii•却** A lf«5is il^i MM f1*阖jg m U14 MJi 切1A M百*tfl?l Ulli ■ M 9・!1叫xna am rji 車1TUI 『PIw1434 IQW WC3* 曲rm:it) 3)11• 3I 1) mn 涎H»丨AK MW ■~!l II72£MM ?araU V.3C WC 44M wn inx IW 1晦:1#"MS I 吟¥$D 1 MM DKl1XM AMI刿・Mf• *1itra um=a* i-HR I»1[如>4^0?Wi 71** JM17 ©I ! t'4 中tK X tZtf1IM34U圍即片W W7I WL w 1 w"WM9'K|-MI)I1*3W9U:1177 昨四ifiWE 4M 4»盹s-gf 771t »0G 4KIJi } 0 E IdM i3it4J4S ma MM11W I71AS 'W s:MA lil 1■鼻4JM皿J$*4i «aA^- ■9-14HPT?i$3EQr«町M口0 «]*44 IM w ISV«rtt «^4 右1V& «anHM齡《讷 1 st >W M?P i£in r m n>■f-4im IM UM 10344 砒«i f*i聲i IW■IMi肚UH诃UftH Ml Ml s -11■輒■ - ,「・r,・J+-A-ZUJI■W J:打开stata,调用数据。
方法一:直接复制到data editor中。
方法二:使用口令:in sheet usi ng 文件路径调用例如:in sheet using C:\STUDY\paper\taxi.csv其中csv格式可用excel的另存为”导出如图:■ 1 1W1T<I|M v«4#■*>>#4w*w3* I 讣• M WH fi-JM mU&Md.AMv VWA7xmr nm JWf MW um負也”mS fVW ■BU*WM❹l耳CM耐鹫1«nj7叭・*4i'feM-4HM?tUJ J?™i Oti9iuie IkLU 3JFH*-b•帕is HM LifNi MMMEMJ47THi iwv59H4'9W n#nam•HU i»L Wil BUM MW MHJ vwlf>W9 IF wu W Ld■HUI Mn nua4JHI t4W«U7t4JVU•EH u14zmi wn mn nm MW 33UI1HHIT 肚4址UM IttK W»»MA li Lh L2THT11 U1srm i y UALZ l-jun ni-i-srKT mw WJ严MR 时林u&MJll■MM44U好I MW4L2A S1Wu込M199K JTS■Mf Mis/ sim4feMI?IMI7 11711 JW?Mit MM EU1 fMMIV It um rnM2M i n«u Wk> FT<W iJW步骤二:调整格式首先请将代表样本的varl重命名口令:rename varl样本名例如:rename varl province也可直接在varl处双击,在弹出的窗口中修改Hariaijlfc Propertie Ekarri?TypebyteFofmat蝴-Og Creite...Wine labelII Manage.Reset Apply接下来将数据转化为面板数据的格式口令:reshape long var, i(样本名)例如:reshape long var, i(provinee)其中var代表的是所有的年份(var2,var3,var4 ??)转化后的格式如图:Data wide long©F diss»31->Number va^idbles7■Aj vciriabl& (6 values^->ksij vurialJles;var£ var3…vor7->vor转化成功后继续重命名,其中」这里代表原始表中的年份,v a r代表该变量的名称口令例如:rename _j yearrename var taxi也可直接在需要修改的名称处双击,在弹出的窗口中修改如图:步骤三:排序口令:sort变量名例如:sort provinee year意思为将province按升序排列,然后再根据排好的province数列排year这一列如图:(虽然很多时候在执行sort前数据就已经符合要求了,但以防万一请务必执行此操作)最后,保存。
至此,一个变量的前期数据处理就完成了,请如法炮制的处理所有的变量,也就是说每个变量都做一个dta文件。
在处理新变量前请使用口令:clear将stata重置这里为方便举例再处理一个名为so2的变量。
如图:这样处理完全部变量:步骤四:合并数据任意打开一个处理过的变量的dta文件作为基础表(推荐使用因变量的dta文件,这里使用so2作为因变量)口令:merge样本名时间using文件路径例如:merge province year using C:\STUDY\paper\taxi.dta意思是将taxi的数据添加到so2的数据表中如图:然后使用口令:tab _merge100%,如图然后使用口令:drop _merge将数据表中的_merge —列去掉,如图:接着重新使用口令:sort样本名时间例如:sort provinee year为新生成的表排序。