sqc基础库使用手册
sqlite 数据库使用说明

sqlite 数据库使用说明SQLite是一种嵌入式关系型数据库管理系统,它占用非常少的资源并具有轻量级的特性。
以下是对SQLite数据库的使用说明。
我们需要在系统中安装SQLite。
可以从SQLite官方网站上下载并安装适合您的操作系统版本。
一旦安装完成,我们可以使用命令行工具或使用SQLite提供的GUI工具(如SQLite Studio、DB Browser for SQLite等)来管理和操作数据库。
创建数据库:我们可以使用以下命令创建一个新的SQLite数据库文件:```sqlite3 mydatabase.db```这将创建名为mydatabase.db的SQLite数据库文件。
如果文件已经存在,它将打开该文件。
创建数据表:通过命令行工具,我们可以使用SQL语句来创建数据表。
例如,以下是创建一个名为students的数据表的示例:```CREATE TABLE students (id INTEGER PRIMARY KEY, name TEXT, age INTEGER);```在这个示例中,我们创建了一个具有id、name和age列的students表。
插入数据:要将数据插入到数据表中,可以使用INSERT语句。
例如,以下是一个将数据插入到students表的示例:```INSERT INTO students (name, age) VALUES ('John Doe', 25);```这个示例将一个名为John Doe且年龄为25的学生插入到students表中。
查询数据:要从数据表中检索数据,可以使用SELECT语句。
例如,以下是检索所有学生记录的示例:```SELECT * FROM students;```这将返回students表中的所有记录。
更新和删除数据:要更新数据表中的记录,可以使用UPDATE语句。
例如,以下是将id为1的学生的年龄更新为30的示例:```UPDATE students SET age = 30 WHERE id = 1;```要删除数据表中的记录,可以使用DELETE语句。
sqc编程培训

宿主变量的使用
输入宿主变量 输入宿主变量规定需要在语句执行期间从应用程序传递给数据库管 理器的值。例如,在下面的SQL语句中将使用一个输入宿主变 理器的值。例如,在下面的 语句中将使用一个输入宿主变 量: SELECT name FROM candidate WHERE name = < input host variable > 输出宿主变量 输出宿主变量规定需要在语句执行期间从数据库管理器传递给应用 程序的值。例如,在下面的SQL语句中将使用一个输出宿主变 程序的值。例如,在下面的 语句中将使用一个输出宿主变 量: SELECT INTO < output host variable > FROM candidate WHERE name = ‘ HUTCHISON ’
宿主变量的使用
在INSERT语句中的使用 语句中的使用 SQL语句 语句 INSERT INTO TEMPL (EMPNO, LASTNAME) VALUES (‘000190’, ‘JONES’) 嵌入程序的SQL语句 嵌入程序的 语句 EXEC SQL INSERT INTO TEMPL (EMPNO, LASTNAME) VALUES (:empno, :name); 在SET和WHERE子句中的使用 和 子句中的使用 SQL语句 语句 UPDATE TEMPL SET SALARY = SALARY *1.05 WHERE JOBCODE = 54 嵌入程序的SQL语句 嵌入程序的 语句 EXEC SQL UPDATE TEMPL SET SALARY = SALARY * :percent WHERE JOBCODE = :code
指示符变量
在实际中,有些对象的值未知,我们用空值表示。 在实际中,有些对象的值未知,我们用空值表示。当我们选择 数据时,如果是空值,宿主变量的内容将不会被改变, 数据时,如果是空值,宿主变量的内容将不会被改变,是随机 的。DB2数据库管理器提供了一个机制去通知用户返回数据是 数据库管理器提供了一个机制去通知用户返回数据是 空值,这个机制就是指示符变量。 空值,这个机制就是指示符变量。 指示符( 指示符(indicator)变量是一种特殊的宿主变量类型,它用来 )变量是一种特殊的宿主变量类型, 表示列的空值或非空值。 表示列的空值或非空值。当这些宿主变量作为输入进入数据库 中时,应当在执行SQL语句之前由应用程序对它们设置值。当 语句之前由应用程序对它们设置值。 中时,应当在执行 语句之前由应用程序对它们设置值 这些宿主变量作为数据库的输出使用时, 这些宿主变量作为数据库的输出使用时,这些指示符由应用程 序定义,但由DB2更新和将它们返回。然后,在结果被返回时 更新和将它们返回。 序定义,但由 更新和将它们返回 然后, 应用程序应当检查这些指示符变量的值。 ,应用程序应当检查这些指示符变量的值。 指示符变量的定义: 指示符变量的定义: 指示符变量的定义与宿主变量的定义方法相同, 指示符变量的定义与宿主变量的定义方法相同,都需要在 BEGIN DECLARE SECTION和END DECLARE SECTION之 和 之 间定义,并且数据类型与SQL数据类型 数据类型SMALLINT对应,在C 对应, 间定义,并且数据类型与 数据类型 对应 语言中为SHORT类型。 类型。 语言中为 类型
SQL Server数据库教程(第3版)(SQL Server 2012)源代码使用说明

SQL Server数据库教程(第3版)(SQL Server 2012)源代码使用说明1. 学生成绩数据库stsc该数据库是贯穿全书的重要数据库,参见本书346页“附录B学生成绩数据库stsc的表结构和样本数据”。
stsc数据库有student、course、score、teacher、lecture 5个表,这5个表的表结构和样本数据都在本书第346页至第348页的附录B中。
2. 创建数据库stsc、创建表和插入样本数据(1)启动SQL Server Management Studio,屏幕出现SQL Server Management Studio窗口,单击窗口左上方工具栏“新建查询”按钮,右边出现查询分析器编辑窗口。
(2)打开“学生成绩数据库stsc建库建表和插入样本数据源代码”文件→选中全部代码→复制,在查询分析器编辑窗口中光标闪烁处右单击,在弹出的菜单中选择“粘贴”,单击“执行”按钮,约数秒钟,就可建好数据库stsc和上述5个表及插入样本数据。
3. 例题源代码的操作(1)启动SQL Server Management Studio,屏幕出现SQL Server Management Studio窗口,单击窗口左上方工具栏“新建查询”按钮,右边出现查询分析器编辑窗口。
(2)在"SQL Server数据库教程(第3版)(SQL Server 2012)例题源代码”中,有各章例题源代码。
打开所需章的例题源代码文件→选中指定例题的代码→复制,在查询分析器编辑窗口中光标闪烁处右单击,在弹出的菜单中选择“粘贴”,单击“执行”按钮,就可得到该例题的运行结果。
4. 商店实验数据库storeexpm建库建表和插入样本数据该数据库在实验中多次用到。
storeexpm数据库包含5个表:部门表DeptInfo、员工表EmplInfo、订单表OrderInfo、订单明细表DetailInfo、商品表GoodsInfo。
Autodesk Vault SQL Cluster 配置指南说明书

Autodesk®VaultSQL Cluster Configuration for Autodesk Vault ServerContents Introduction (3)Purpose (3)Example (3)Configuring SQL Failover Cluster Instances (4)Add a SQL Server Node (12)Installing Autodesk Vault (16)Verify Failover Failover (17)IntroductionThis document is a guideline on how to configure Microsoft SQL Server as a cluster to work with Autodesk Vault server. This document does not cover best practices for SQL Server or the cluster configuration. Autodesk recommends consulting with Microsoft’s documentation for configuration and best practice details.PurposeAutodesk Vault functions in a SQL failover cluster configuration in which it is unaware of the cluster and does not requirereconfiguration of Vault if and when a failover occurs. This is known as the AlwaysOn Failover Cluster Instances (FCI). Moreinformation about this configuration can be found at AlwaysOn Failover Cluster Instances . Before configuring this feature, Windows Server must be configured for Windows Server Failover Clustering (WSFC). This document does not cover this configuration; please refer to Microsoft’s documentation.ExampleThis document illustrates the following configuration.Domain Controller SQL Server(SQL1)SQLVault Server dk SQL Server(SQL2)SQLCluster StorageConfiguring SQL Failover Cluster InstancesOnce the Windows is configured as a Windows failover cluster for SQL, it is time to install the Microsoft SQL Server software.1. Insert the SQL Server installation media in the first SQL Server (SQL1), and from the root folder, double-click Setup.exe.2. The Installation Wizard starts the SQL Server Installation Center. To create a new cluster installation of SQL Server, click NewSQL Server failover cluster installation on the installation page.3. The System Configuration Checker runs a discovery operation on your computer. To continue, Click OK.4. To continue, click Next.5. On the Setup Support Files page, click Install to install the Setup support files.6. The System Configuration Checker verifies the system state of your computer before Setup continues. After the check iscomplete, click Next to continue.7. On the Product key page, indicate whether you are installing a free edition of SQL Server, or whether you have a PID key for aproduction version of the product.8. On the License Terms page, read the license agreement, and then select the checkbox to accept the license terms andconditions. Click Next to continue.9. On the Feature Selection page, select the following components for the installation. Click Next to continue.10. On the Instance Configuration page, type a name in the SQL Server Network Name field. This name is used to identify theSQL Server failover cluster. Select the Named Instance and type AutodeskVault in the Named Instance field. Click Next.11. Use the Cluster Resource Group page to specify the cluster resource group name where SQL Server virtual server resourceswill be located. Click Next to continue.12. On the Cluster Disk Selection page, select the shared cluster disk resource for your SQL Server failover cluster. The clusterdisk is where the SQL Server data will be located. More than one disk can be specified.Click Next to continue.13. On the Cluster Network Configuration page, specify the network resources for your failover cluster instance:Network Settings — Specify the IP type and IP address for your failover cluster instance.Click Next to continue.14. On the Server Configuration — Service Accounts page, specify login accounts for SQL Server services. If more informationon configuring service accounts - see Server Configuration - Service Accounts. Click Next to continue.15. On the Database Engine Configuration page on the Server Configuration tab, select Mixed Mode and type the password thatwill be used for the system administrator (SA) account.16. On the Data Directories tab, specify the location of the database files. Click Next to continue.17. Continue through the remaining pages to complete the installation.Add a SQL Server Node1. Insert the SQL Server installation media in the first SQL Server (SQL1), and from the root folder, double-click Setup.exe.2. On the Cluster Node Configuration page, select the Cluster Network to join. Click Next to continue.3. On the Cluster Network Configuration page, specify the network resources for your failover cluster instance:Network Settings — Specify the IP type and IP address for your failover cluster instance.Click Next to continue.4. On the Server Configuration — Service Accounts page, specify login accounts for SQL Server services. If more informationon configuring service accounts - see Server Configuration - Service Accounts. Click Next to continue.5. Continue to click Next to complete the installation.Installing Autodesk Vault1. On a separate server on the network, insert the Vault Server and run the Setup.exe.2. On the Server Configuration page, configure the installation for a remote SQL server and enter the SQL Server Network Nameof the Cluster.3. When using a remote SQL instance, a shared network folder is required as a transition area between the SQL instance andthe Autodesk Data Management Server. The shared network folder can be located on the same computer as the SQLinstance or a different computer and must be accessible by both the data management server and SQL. The spacerequirement for the shared folder is equal to the total of all database files. Choose a location with sufficient space andperformance. Enter the UNC path to the shared network folder or click Browse to locate the shared folder on the network.Note: Both the user account under which the Autodesk Vault Server is running as well as the user account under which the SQL instance is operating need read/write access to the shared network folder.4. Complete the installation and start the Vault Server console to create a vault.Verify Failover1. Launch the Failover Cluster Manager and select the Roles node.2. Right-click on the Roles node and click Move -> Select Node…3. Select the SQL2 server or second node and wait for the failover to complete.4. Launch the Vault Server console and verify that Vault is still functioning correctly.Autodesk [and other products] are registered trademarks or trademarks of Autodesk, Inc., and/or its subsidiaries and/or affiliates in the USA and/or other countries. All other brand names, product names, or trademarks belong to their respective holders. Autodesk reserves the right to alter product and services offerings, and specifications and pricing at any time without notice, and is not responsible for typographical or graphical errors that may appear in this document. © 2016 Autodesk, Inc. All rights reserved.。
【免费】SQC(中文)ver+111
step1 存在差异吗?改善了吗?
statistical quality control 6/27 【差异的检定】
钱田君 :明白了。也就要是通过统计计算,找到一个恰如其分的说法。 统计猫 :孺子可教也! 不要单纯地比较平均值就判断存在差异。 李小龙 :也就是说要同时考虑平均值和数据偏差才能把握到真实的情况。 钱田君 :明白了明白了!赶紧教我具体的检定方法吧。 统计猫 :我先强调一点,我并不是要大家去死记检定的手法哦。 重要的是思考方法!好~那我们一起来学习吧。 注意事项 检定今年相对去年的改善状态时,在检定平均值的差之前, 很重要一点是要确认偏差(分散)的变化。 你觉得比去年好的时候,是因为平均值得到改善呢? 还是因为偏差变小了呢?检定的对象因你所关心的事项而异。
去年的结果 112 104 123 109
今年的结果 101 112 105 110
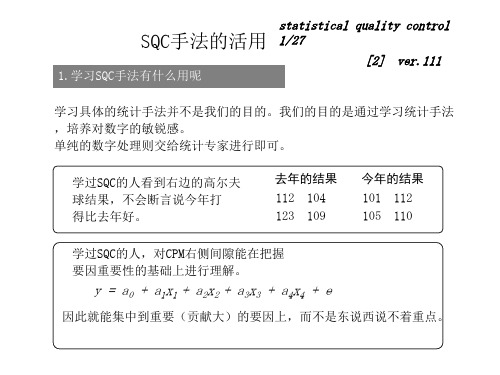
学过SQC的人,对CPM右侧间隙能在把握 要因重要性的基础上进行理解。
y = a0 + a1x1 + a 2x2 + a3x3 + a 4x4 + e
因此就能集中到重要(贡献大)的要因上,而不是东说西说不着重点。
2. SQC手法的学习手顺
【分散分析】
统计猫
统计猫
statistical quality control 12/27
step2 收集了大量数据,那么如何处理这些数据呢
练习问题 2
【分散分 析】
在化学药品制造工位改变温度Ai、触媒种类Bj的条件进行了调查对收量的影响的实 验。解析这个吧。 温度/触媒 A1 A2 A3 A4 B1 8.8 9.8 9.4 8.5 B2 8.6 8.9 9.0 8.4 B3 7.6 9.0 8.5 7.8
SQL Server 2019 数据库系统用户手册说明书

5 Make faster, better decisions
Use data virtualization to combine and query a variety of external relational and non-relational data sources without moving or replicating data.
Mission critical security 4
Access rich, interactive reports and enterprise reporting for better analysis and decision-making.
Create, deploy, and manage mobile and paginated reports with rich visualizations in SQL Server Reporting Services. Author beautiful reports with Power BI Desktop. Publish Power BI reports to the cloud or Power BI Report Server in SQL Server 2019, and distribute and consume reports across devices. Consume interactive dashboards and reports, both online and offline, with mobile reporting on iOS, Android, and Windows devices.
建库系统使用说明书

建库系统使用说明书建库操作基本流程.建库工作要求布置,单机版操作培训。
发布信息收集表收集学生、教工基本信息。
.把单机版分发到各年级、各班、各科组进行数据录入。
.各年级、各班、各科组以学校代码压缩上报,学校建库负责人接收合并。
.学校建库负责人审核后上报到省网和市网上,如果没有条件上网的由上级主管部门代上报到网上。
第一次也可以由镇收齐审核后上报到网上。
.学校数据作出修改,都要及时上传到网上。
每学期的第一个月及最后一个月必须上传更新一次。
一、软件下载进入以下网址:、找到标题为“建库系统......”,根据说明指引进行下载。
二、安装与删除双击执行下载后的自动解压缩“建库系统(第版)”文件,按提示将系统安装至某一安装目录,例如“:\建库系统”。
进入安装目录,双击“建库系统”文件,便可进入系统。
为方便日后使用,可以建立快捷方式,复制到桌面。
删除系统只需要把安装目录以及建立的快捷方式删除即可。
本软件是绿色软件,不会影响原电脑的配置。
三、系统使用主要操作顺序是主菜单由左至右,栏目菜单由上至下而操作。
以下按一般流程分别绍:()、初始设置()、初始化:删除与本校或本地区无关的数据,以便提高电脑操作速度.()、单位信息学校信息是基础数据库的重要组成部分.录入学校信息后,才能够对教师库、学生库等进行操作。
学校基础信息正确与否,将直接影响以后数据的生成,因此,要对各项信息逐一进行核实,特别是区划代码,要求细化到学校所在地的镇级码.“功能菜单查询筛选”:系统安装后,把年学年初统计报表提供的学校信息,罗列了出来,单位数很多,可以通过本功能,快速找到本地区的学校,以便进行核实修改。
修改学校代码要慎重,需要经上级教育主管部门同意后才能更改.以今年为准,学校代码一经确定,以后就不能更改了.录入了教工库或学生库等以后,如果需要更改学校代码,要使用”数据更正学校代码更改”功能更改.学校代码请按照年月份学年初报表中学校代码编写,不得随意更改。
sqc基础库使用手册

sqc基础库使⽤⼿册SqcLib库接⼝定义新的sqc基础库采⽤c++封装,开发⼈员只需要从基础类Db2Tools派⽣⾃⼰的业务类。
然后重载基础类的busiLogic⽅法,就可以完成⾃⼰业务逻辑处理。
具体的处理流程为:1、在基础类Db2Tools的run⽅法中完成对具体应⽤参数的解析。
2、run⽅法调⽤busiLogic⽅法,完成具体的业务逻辑3、busiLogic⽅法中调⽤基础类的常⽤数据库访问⽅法,完成对数据库的操作。
4、在基础类的数据库访问⽅法中,除完成指定的数据库操作外,同时完成⽇志输出和相关事务控制。
[⽇志的输出⽬录为profile⽂件中定义的AGENTTRACEDIR⽬录,如果没有定义,取默认路径]1函数列表1.1数据库类(Db2Tools)该类有两个主要功能:1、实现数据库访问2、完成对具体业务逻辑调⽤和事务控制●connDb函数原形:int connDb(const char *m_para_conn)⽤途:连接数据库参数:m_para_conn:数据库名dbname返回:1.输⼊的数据库参数不对2.密码参数环境变量设置错误3.数据库连接失败0.数据库连接成功●busiLogic函数原形:int busiLogic(void)⽤途:业务逻辑⼊⼝参数:返回:●run函数原形:int run(int argc,char *argv[])⽤途:实例开始⼊⼝参数:argc:参数个数Argv:参数数组(通常取main函数⼊⼝参数)返回:0:成功,其它:失败函数原形:int db2RunstatTab(char *tabname,char *file,int line)⽤途:对表做runstats参数:tabname:输⼊需要runstats的表名,schema.tabname或者tabname(schema默认为⽤户名)返回:-1:失败0:成功●db2Insert函数原形:int db2Insert(char *sqlstr,char *tabname,char *file,int line)⽤途:提交insert语句参数:sqlstr:insert sql语句file:line:返回:-1:失败0:成功●db2Update函数原形:int db2Update(char *sqlstr,char *tabname,char *file,int line)⽤途:提交update语句参数:sqlstr:update sql语句file:line:返回:-1:失败0:成功●db2Delete函数原形:int db2Delete(char *sqlstr,char *tabname,char *file,int line)⽤途:提交delete语句参数:sqlstr:delete sql语句file:line:返回:-1.失败0.成功●db2DropTab函数原形:int db2DropTab(char *tabname,char *file,int line)参数:tabname:需要删除的表名,schema.tabnamefile:line:返回:-1:删除失败1:表不存在0:成功●db2DelAll函数原形:int db2DelAll(char *tabname, char *file,int line)⽤途:清空该表中的全部数据参数:tabname:需要删除的表名,schema.tabnamefile:line:返回:-1:删除失败1:表不存在0:成功●db2CreTab函数原形:int db2CreTab(char *sqlstr,char *tabname,char *file,int line)⽤途:新建⼀张表参数:返回:-1:建表失败1:表已经存在0:建表成功●db2GrantTab函数原形:int db2GrantTab(char *user,char *tabname,char *file,int line)⽤途:表付权函数,只能付select权限,⼀次只能给⼀个⽤户或者组付权参数:返回:●dbRrefreshTab函数原形:int dbRrefreshTab(char *tabname,char *file,int line)⽤途:同步刷新表参数:返回:1.2⽇期类(DateFormat)完成读⽇期的各种运算函数原形:CdateFormat (std::string pat)⽤途:构造函数参数:pat:输⼊⽇期的格式●getMonthRoll函数原形:string getMonthRoll(int interval)⽤途:获得输⼊⽉份偏移interval后的⽉份参数:interval:偏移量返回:返回yyyymm 格式的⽇期●getDateRoll函数原形:string getDateRoll(int intverval)⽤途:获得输⼊⽇期偏移interval后的⽇期参数:interval:偏移量返回:返回yyyymmdd格式的⽇期●getYearRoll函数原形:string getYearRoll(int intverval)⽤途:获得输⼊年偏移interval后的年份参数:interval:偏移量返回:返回yyyy格式的⽇期●setPattern函数原形:int setPattern(std::string strFormat)⽤途:指定输⼊⽇期值的格式(%Y%m%d, %Y-%m-%d)参数:strFormat:输⼊的⽇期格式返回:-1:执⾏失败0:执⾏成功●getPattern函数原形:string getPattern ( )⽤途:返回⽇期值的格式参数:strTime:输⼊的⽇期返回:-1:执⾏失败0:执⾏成功●dateParsing⽤途:把表⽰时间的字符串strTime按pattern格式转换成tm结构的⽇期时间结构参数:strTime:输⼊的⽇期返回:-1:执⾏失败0:执⾏成功●getLastDay函数原形:string getLastDay ()⽤途:返回指定⽉份的最后⼀天参数:返回:返回yyyymmdd格式的⽇期●getFirstDay函数原形:string getFirstDay()⽤途:返回指定⽉份的第⼀天参数:返回:返回yyyymmdd格式的⽇期●getQuater函数原形:string getQuater ()⽤途:返回当前⽉份所在的季度参数:返回:季度(1、2、3、4)1.3⽇志类完成⽇志数据●writeLogTrace函数原形:int writeLogTrace(char *m_proname,int m_ddh,int m_rwh,int m_cmdstatus,char *promptMsg1,char *promptMsg2,char *file,int line,char *fpath)⽤途:写ss⽇志到指定⽬录下参数:●open_trace函数原形:int open_trace(char * tast_name)⽤途:打开trace⽂件参数:tast_name:程序名返回:TRACE_FD:会产⽣该全局变量,指向⽂件的指针1.4控制表类●synTab函数原形:int synTab(FILE *trace,char *sqlstr,char *tabname,char *file,int line)⽤途:向同步申请表中插⼊需要同步的表tabname:需要同步的表名file:⽂件名line:⾏号返回:●writeSysLog函数原形:int writeSysLog(FILE *trace,int status,char *file,int line)⽤途:向统⼀通信表中插⼊程序成功失败⽇志参数:trace:⽇志⽂件句柄status:程序成功失败标识file:⽂件名line:⾏号返回:errorLog2memset函数详细说明1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SqcLib库接口定义
新的sqc基础库采用c++封装,开发人员只需要从基础类Db2Tools派生自己的业务类。
然后重载基础类的busiLogic方法,就可以完成自己业务逻辑处理。
具体的处理流程为:
1、在基础类Db2Tools的run方法中完成对具体应用参数的解析。
2、run方法调用busiLogic方法,完成具体的业务逻辑
3、busiLogic方法中调用基础类的常用数据库访问方法,完成对数据库的操作。
4、在基础类的数据库访问方法中,除完成指定的数据库操作外,同时完成日志输出和相关事务控制。
[日志的输出目录为profile文件中定义的AGENTTRACEDIR目录,如果没有定义,取默认路径]
1函数列表
1.1数据库类(Db2Tools)
该类有两个主要功能:
1、实现数据库访问
2、完成对具体业务逻辑调用和事务控制
●connDb
函数原形:int connDb(const char *m_para_conn)
用途:连接数据库
参数:m_para_conn:数据库名dbname
返回:1.输入的数据库参数不对
2.密码参数环境变量设置错误
3.数据库连接失败
0.数据库连接成功
●busiLogic
函数原形:int busiLogic(void)
用途:业务逻辑入口
参数:
返回:
●run
函数原形:int run(int argc,char *argv[])
用途:实例开始入口
参数:argc:参数个数
Argv:参数数组
(通常取main函数入口参数)
返回:0:成功,其它:失败
●db2RunstatTab
函数原形:int db2RunstatTab(char *tabname,char *file,int line)
用途:对表做runstats
参数:tabname:输入需要runstats的表名,schema.tabname或者tabname(schema默认为用户名)
返回:-1:失败
0:成功
●db2Insert
函数原形:int db2Insert(char *sqlstr,char *tabname,char *file,int line)
用途:提交insert语句
参数:
sqlstr:insert sql语句
file:
line:
返回:-1:失败
0:成功
●db2Update
函数原形:int db2Update(char *sqlstr,char *tabname,char *file,int line)
用途:提交update语句
参数:
sqlstr:update sql语句
file:
line:
返回:-1:失败
0:成功
●db2Delete
函数原形:int db2Delete(char *sqlstr,char *tabname,char *file,int line)
用途:提交delete语句
参数:
sqlstr:delete sql语句
file:
line:
返回:-1.失败
0.成功
●db2DropTab
函数原形:int db2DropTab(char *tabname,char *file,int line)
用途:删除表
参数:
tabname:需要删除的表名,schema.tabname
file:
line:
返回:-1:删除失败
1:表不存在
0:成功
●db2DelAll
函数原形:int db2DelAll(char *tabname, char *file,int line)
用途:清空该表中的全部数据
参数:tabname:需要删除的表名,schema.tabname
file:
line:
返回:-1:删除失败
1:表不存在
0:成功
●db2CreTab
函数原形:int db2CreTab(char *sqlstr,char *tabname,char *file,int line)
用途:新建一张表
参数:
返回:-1:建表失败
1:表已经存在
0:建表成功
●db2GrantTab
函数原形:int db2GrantTab(char *user,char *tabname,char *file,int line)
用途:表付权函数,只能付select权限,一次只能给一个用户或者组付权参数:
返回:
●dbRrefreshTab
函数原形:int dbRrefreshTab(char *tabname,char *file,int line)
用途:同步刷新表
参数:
返回:
1.2日期类(DateFormat)
完成读日期的各种运算
●CdateFormat
函数原形:CdateFormat (std::string pat)
用途:构造函数
参数:pat:输入日期的格式
●getMonthRoll
函数原形:string getMonthRoll(int interval)
用途:获得输入月份偏移interval后的月份
参数:
interval:偏移量
返回:返回yyyymm 格式的日期
●getDateRoll
函数原形:string getDateRoll(int intverval)
用途:获得输入日期偏移interval后的日期
参数:
interval:偏移量
返回:返回yyyymmdd格式的日期
●getYearRoll
函数原形:string getYearRoll(int intverval)
用途:获得输入年偏移interval后的年份
参数:
interval:偏移量
返回:返回yyyy格式的日期
●setPattern
函数原形:int setPattern(std::string strFormat)
用途:指定输入日期值的格式(%Y%m%d, %Y-%m-%d)
参数:strFormat:输入的日期格式
返回:-1:执行失败
0:执行成功
●getPattern
函数原形:string getPattern ( )
用途:返回日期值的格式
参数:strTime:输入的日期
返回:-1:执行失败
0:执行成功
●dateParsing
函数原形:int dateParsing(std::string strTime)
用途:把表示时间的字符串strTime按pattern格式转换成tm结构的日期时间结构参数:strTime:输入的日期
返回:-1:执行失败
0:执行成功
●getLastDay
函数原形:string getLastDay ()
用途:返回指定月份的最后一天
参数:
返回:返回yyyymmdd格式的日期
●getFirstDay
函数原形:string getFirstDay()
用途:返回指定月份的第一天
参数:
返回:返回yyyymmdd格式的日期
●getQuater
函数原形:string getQuater ()
用途:返回当前月份所在的季度
参数:
返回:季度(1、2、3、4)
1.3日志类
完成日志数据
●writeLogTrace
函数原形:int writeLogTrace(char *m_proname,int m_ddh,int m_rwh,int m_cmdstatus,char *promptMsg1,char *promptMsg2,char *file,int line,char *fpath)
用途:写ss日志到指定目录下
参数:
●open_trace
函数原形:int open_trace(char * tast_name)
用途:打开trace文件
参数:tast_name:程序名
返回:TRACE_FD:会产生该全局变量,指向文件的指针
1.4控制表类
●synTab
函数原形:int synTab(FILE *trace,char *sqlstr,char *tabname,char *file,int line)
用途:向同步申请表中插入需要同步的表
参数:trace:日志文件句柄
sqlstr:同步sql语法
tabname:需要同步的表名
file:文件名
line:行号
返回:
●writeSysLog
函数原形:int writeSysLog(FILE *trace,int status,char *file,int line)
用途:向统一通信表中插入程序成功失败日志
参数:trace:日志文件句柄
status:程序成功失败标识
file:文件名
line:行号
返回:
errorLog。