编译原理第八章习题答案
编译原理期末复习题(含答案)

a. 句型
b. 句子
c. 以单词为单位的程序
d. 文法的开始符
e. 句柄
6、对正规文法描述的语言,以下 有能力描述它。
a.0 型文法
b.1 型文法 c.上下文无关文法 d.右线性文法 e.左线性文法
解答 1、e、a、c 2、a、c、e 3、b、c、d 4、a、c 5、b、c 6、a、b、c、d、e
三、填空题
1、选 c。
2、选 a。
3、选 c。
4、虽然 a 与 b 没有优先关系,但构造优先函数后,a 与 b 就一定存在优先关系了。所以,由 f(a)>g)(b)
或 f(a)<g(b)并不能判定原来的 a 与 b 之间是否存在优先关系:故选 c。
5、如果文法 G 无二义性,则最左推导是先生长右边的枝叶:对于 d,如果有两个不同的是了
6、自下而上分析法采用 、归约、错误处理、
等四种操作。
7、Chomsky 把文法分为
种类型,编译器构造中采用
和
文法,它们分别产
生
和
语言,并分别用
和
自动机识别所产生的语言。
解答 1、空集 终结符 右
2、最左
3、自上而上 自下而上
4、自上而上
5、语法 分析
6、移进 接受
7、4 2 型 3 型 上下文无关语言 正规语言 下推自动机 有限
a. 直接短语
b. 句柄
c. 最左素短语
d. 素短语
13、有文法 G:E→E*T|T
T→T+i|i 句子 1+2*8+6 按该文法 G 归约,其值为 。
a. 23 B. 42 c. 30 d. 17
14、规范归约指 。
a. 最左推导的逆过程
编译原理第8章作业及习题参考答案
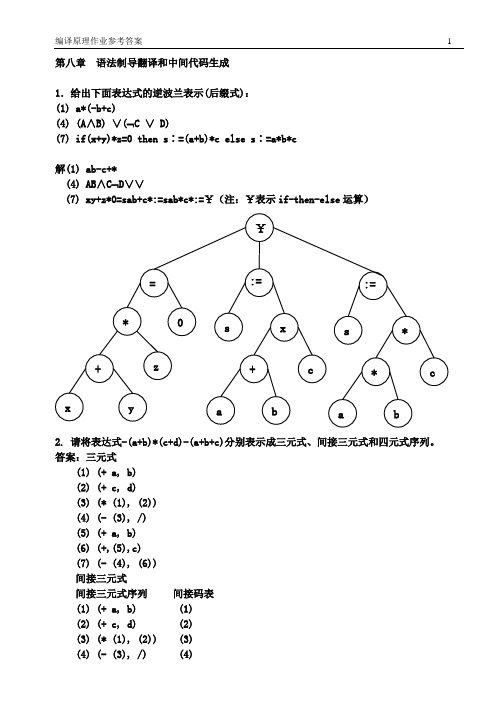
第八章 语法制导翻译和中间代码生成1.给出下面表达式的逆波兰表示(后缀式): (1) a*(-b+c)(4) (A ∧B) ∨(⌝C ∨ D)(7) if(x+y)*z=0 then s ∶=(a+b)*c else s ∶=a*b*c解(1) ab-c+*(4) AB ∧C ⌝D ∨∨(7) xy+z*0=sab+c*:=sab*c*:=¥(注:¥表示if-then-else 运算)2. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
答案:三元式(1) (+ a, b) (2) (+ c, d)(3) (* (1), (2)) (4) (- (3), /) (5) (+ a, b)(6) (+,(5),c) (7) (- (4), (6)) 间接三元式间接三元式序列 间接码表 (1) (+ a, b) (1) (2) (+ c, d) (2) (3) (* (1), (2)) (3) (4) (- (3), /) (4)¥= :=*:=+ xyzs +cxa bs* c*a b(5) (- (4), (1)) (1)(6) (- (4), (5)) (5)(6)四元式(1) (+, a, b, t1) (2) (+, c, d, t2) (3) (*, t1, t2, t3) (4) (-, t3, /, t4)(5) (+, a, b, t5) (6) (+, t5, c, t6) (6) (-, t4, t6, t7)3. 采用语法制导翻译思想,表达式E 的"值"的描述如下: 产生式 语义动作(0) S ′→E {print E.VAL}(1) E →E1+E2 {E.VAL ∶=E1.VAL+E2.VAL} (2) E →E1*E2 {E.VAL ∶=E1.VAL*E2.VAL} (3) E →(E1) {E.VAL ∶=E1.VAL} (4) E →n {E.VAL ∶=n.LEXVAL}如果采用LR 分析法,给出表达式(5 * 4 + 8) * 2的语法树并在各结点注明语义值VAL 。
编译原理一些习题答案

第2章形式语言基础2.2 设有文法G[N]: N -> D | NDD -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9(1)G[N]定义的语言是什么?(2)给出句子0123和268的最左推导和最右推导。
解答:(1)L(G[N])={(0|1|2|3|4|5|6|7|8|9)+} 或L(G[N])={α| α为可带前导0的正整数}(2)0123的最左推导:N ⇒ ND ⇒ NDD ⇒ NDDD ⇒ DDDD ⇒ 0DDD ⇒ 01DD ⇒ 012D ⇒ 0123 0123的最右推导:N ⇒ ND ⇒ N3 ⇒ ND3 ⇒ N23 ⇒ ND23 ⇒ N123 ⇒ D123 ⇒ 0123268的最左推导:N ⇒ ND ⇒ NDD ⇒ DDD ⇒ 2DDD ⇒ 26D ⇒ 268268的最右推导:N ⇒ ND ⇒ N8 ⇒ ND8 ⇒ N68 ⇒ D68 ⇒ 2682.4 写一个文法,使其语言是奇数的集合,且每个奇数不以0开头。
解答:首先分析题意,本题是希望构造一个文法,由它产生的句子是奇数,并且不以0开头,也就是说它的每个句子都是以1、3、5、7、9中的某个数结尾。
如果数字只有一位,则1、3、5、7、9就满足要求,如果有多位,则要求第1位不能是0,而中间有多少位,每位是什么数字(必须是数字)则没什么要求,因此,我们可以把这个文法分3部分来完成。
分别用3个非终结符来产生句子的第1位、中间部分和最后一位。
引入几个非终结符,其中,一个用作产生句子的开头,可以是1-9之间的数,不包括0,一个用来产生句子的结尾,为奇数,另一个则用来产生以非0整数开头后面跟任意多个数字的数字串,进行分解之后,这个文法就很好写了。
N -> 1 | 3 | 5 | 7 | 9 | BNB -> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | B02.7 下面文法生成的语言是什么?G1:S->ABA->aA| εB->bc|bBc G2:S->aA|a A->aS解答:B ⇒ bcB ⇒ bBc⇒ bbccB ⇒ bBc⇒ bbBcc ⇒ bbbccc……A ⇒εA ⇒ aA ⇒ aA ⇒ aA ⇒ aaA ⇒ aa……∴S ⇒ AB ⇒ a m b n c n , 其中m≥0,n≥1即L(G1)={ a m b n c n | m≥0,n≥1} S ⇒ aS ⇒ aA ⇒ aaS ⇒ aaaS ⇒ aA ⇒ aaS ⇒ aaaA ⇒aaaaS ⇒ aaaaa ……∴S ⇒ a2n+1 , 其中n≥0即L(G2)={ a2n+1 | n≥0}2.11 已知文法G[S]: S->(AS)|(b)A->(SaA)|(a)请找出符号串(a)和(A((SaA)(b)))的短语、简单短语和句柄。
第八章课后作业答案
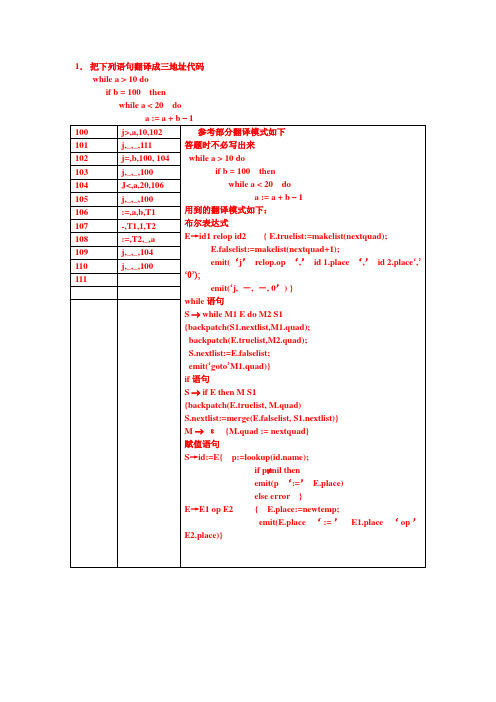
emit(‘j’relop.op‘,’id 1.place‘,’id 2.place‘,’‘0’);
emit(‘j,-,-,0’) }
E→E1 and M E2
{ backpatch(E1.truelist, M.quad);
E.truelist:=E2.truelist;
E.falselist:=merge(E1.falselist,E2.falselist) }
M→{ M.quad:=nextquad }
if语句
Sif E then M S1
{backpatch(E.truelist, M.quad)
S.nextlist:=merge(E.falselist, S1.nextlist)}
a := a + b – 1
用到的翻译模式如下:
布尔表达式
E→id1 relop id2 { E.truelist:=makelist(nextquad);
E.falselist:=makelist(nextquad+1);
emit(‘j’relop.op‘,’id 1.place‘,’id 2.place‘,’‘0’);
emit(p‘:=’E.place)
else error }
E→E1opE2 { E.place:=newtemp;
emit(E.place‘:=’E1.place‘op’E2.place)}
101
j,_,_,111
102
j=,b,100, 104
103
j,_,_,100
104
J<,a,20,106
M→{ M.quad:=nextquad }
编译原理(龙书)课后习题解答(详细)

编译原理(龙书)课后习题解答(详细)编译原理(龙书)课后题解答第一章1.1.1 :翻译和编译的区别?答:翻译通常指自然语言的翻译,将一种自然语言的表述翻译成另一种自然语言的表述,而编译指的是将一种高级语言翻译为机器语言(或汇编语言)的过程。
1.1.2 :简述编译器的工作过程?答:编译器的工作过程包括以下三个阶段:(1) 词法分析:将输入的字符流分解成一个个的单词符号,构成一个单词符号序列;(2) 语法分析:根据语法规则分析单词符号序列中各个单词之间的关系,确定它们的语法结构,并生成抽象语法树;(3) 代码生成:根据抽象语法树生成目标程序(机器语言或汇编语言),并输出执行文件。
1.2.1 :解释器和编译器的区别?答:解释器和编译器的主要区别在于执行方式。
编译器将源程序编译成机器语言或汇编语言等,在运行时无需重新编译,程序会一次性运行完毕;而解释器则是边翻译边执行,每次执行都需要进行一次翻译,一次只执行一部分。
1.2.2 :Java语言采用的是解释执行还是编译执行?答:Java一般是编译成字节码的形式,然后由Java虚拟机(JVM)进行解释执行。
但是,Java也有JIT(即时编译器)的存在,当某一段代码被多次执行时,JIT会将其编译成机器语言,提升代码的执行效率。
第二章2.1.1 :使用BNF范式定义简单的加法表达式和乘法表达式答:<加法表达式> ::= <加法表达式> "+" <乘法表达式> | <乘法表达式><乘法表达式> ::= <乘法表达式> "*" <单项式> | <单项式><单项式> ::= <数字> | "(" <加法表达式> ")"2.2.3 :什么是自下而上分析?答:自下而上分析是指从输入字符串出发,自底向上构造推导过程,直到推导出起始符号。
胡元义版编译原理课后习题答案

则文法G[S′]的LR(0)项目集示范族为 I0:S′→·S I4:S→a· I10:L→S;·L I5 : S→while e· do s I6 : S→begin L·end I7 : L→S· S→·while e do S L→·S S→·begin L end L→·S;L S→·a S→·while e do S
所有外层分程序的符号表都无法找到此标识符,则表
明程序中使用了一个未经说明 ( 定义 )的标识符,此时 可按语法错误予以处理。
8.4 对下列程序,当编译程序编译到箭头所指位 置时,画出其层次表(分程序索引表)和符号表: program stack(output); var m, n:integer; r:real;
w h ile L S ; I4 I7 a s I1 0 I6 b eg in en d I9 w h ile L I1 2 a
图8-2 习题8.5中文法G[S′]的DFA
在 LR(0) 项 目 集 规 范 族 中 , 只 有 I7 含 有 “ 移 进”/“归约”冲突,且该冲突可用SLR(1)方法解决。
图8-1 分程序索引表和符号表示意图
8.5 已知文法G[S]: S→while (e) S S→{L}
S→a
L→S;L L→S
/*a代表赋值句*/
构造该文法的LR型的错误校正分析程序。
【解答】 首先将文法G[S]拓广为G[S′]:(0) S′→S (1) S→while e do S
(2) S→begin L end
号的处理,这就需要用到语法符号的相关属性。为了在需
要时能找到这些语法成分及其相关属性,就必须使用一些 表格来保存这些语法成分及其属性,这些表格就是符号表。
编译原理 第八章

② for(i=6,j=0; j<i; ++j) fun(i); 在六次循环中,i的值保持为6,则可优化为: for(i=6,j=0;j<6; ++j) fun(6);
3. 综合使用常数传播和常数合并进行优化处理 为了对保持定值的所有变量之值进行跟踪,建立一个局部符号表,使 每一个活动的变量在该表中有一个登记项,每当对这些变量进行再定 值时,就相应的修改其登记项中的内容。 例: t1=1; t1+=5; 优化为: t1=6; t2=t1; t2=6;
一. 强度削弱
用一种(或一串)执行时间较短的操作去等价的代替一个操作。 1. x*2n 替换为 x<<n (乘法用左移运算替换) x/2n 替换为 x>>n x%2n 替换为 x&(2n-1) 2. 乘以一个较小的整数可以用多个加法代替 x*=3 替换为 x1=x; x+= x1; x+= x1; 3. 较大整数的乘法可以联合使用位移和加法进行强度削弱优化 x*=9 替换为 x1=x; x*=27 替换为 x1=x; x1<<=3; x1<<=1; x+= x1; x+= x1; x1<<=2; x+= x1; x1<<=1; 4. 对于非算术运算进行强度削弱的情形 x+= x1; 例如:许多机器有多种形式的转移指令, 优化程序可以从其中选择效率更高的指令。
三. 无用变量与无用代码的删除
1. 无用变量:变量的最后一次引用到对该变量再置初值期间,可视为无用 变量。在变量的无用期间,对该变量的所有定值(如赋值)指令均可删去。 例: t=a; t+=5; x=t; …… /*此后的一个时间间隔内,t成为无用变量*/ t=c; /*在t的无用期内,对t的定值可以删除*/ …… t=b; /*t被再次置初值,无用期结束*/ y=t+a;
编译原理第八章

2013年8月21日2时45分
(3) 在符号表的信息栏中引入一个指针域(previous)用以 链接它在同一过程内的前一域名字在表中的下标(相对位 置)。每一层的最后一个域名字,其previous之值为0。这 样,每当需要查找一个新名字时,就能通过DISPLAY找出 当前正在处理的最内层的过程及所有外层的子符号表在栈 符号表中的位置。然后,通过previous可以找到同一过程 内的所有被说明的名字。
2013年8月21日2时45分
8.4 符号表的内容
符号表的信息栏中登记了每个名字的有关的性质,如类型、 种属、大小以及相对数。 对于变量名、数组名和过程名,信息栏中一般有下列信息: (1)变量 类型(整数、实、双实、布尔、字符、复、标号 或指针); 种属(简单变量、数组或记录结构); 长度(所需的存储单元数); 相对数(存储单元数); 若为数组,则记录其内情况向量。
2013年8月21日2时45分
杂凑技术
对于表格处理来说,根本问题在于如何保证查表与填表两 方面的工作都能高效地进行。对于线性表来说,填表快, 查表慢。而对于对折法而言,则填表慢,查表快。杂凑法 正是一种争取查表、填表两方面都能高速进行的统一技术。 这种办法是:假定有一个足够大的区域,这个区域以填写 一张含N项的符号表。构造一个地址函数H。对于地址函 数H有两点要求:第一,函数的计算要简单、高效;第二, 函数值能比较均匀地分布。对于杂凑技术还应设法解决 “地址冲突”的问题。
2013年8月21日2时45分
8.2 整理与查找
符号表作为一个多元组,表中元组的排列组织是构造符号 表的重要成分。在编译程序的整个工作过程中,符号表被 频繁地用来建立表项,找查表项,填充和引用表项的属性 。因此表项的排列组织对该系统运行的效率起着十分重要 的作用。在编译程序中,符号表项的组织传统上采用三种 构造方法。即线性法,二分法及散列法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第八章习题答案
2、请将算术表达式翻-(a+b)*(c+d)+(a+b+c)翻译为:(1)四元式
(2)三元式
(3)间接三元式
答:
(2)三元式
(3)间接三元式
间接码表:
三元式:
4、修改图8.5中计算声明语句中的名字的类型及相对对峙的翻译方案,以允许在一个声明中可以同时声明多个变量名。
答:
翻译方案如下:
P->{ offset:= 0 } D
D-> D;D
D->L
L->id,L1 {
L.type = L1.type;
L.width = L1.width;
enter(id,name,L.type,offset;
Offset:= offset +L.width
}
L->:T{ L.type = T.type;
L.width = T.width;}
T->integer { T.type = integer; T.width:= 4 }
T->real { T.type= real; T.width:= 8 }
T-> array[num] of T1 { T.type:= array(num.val, T1.type);
T.width:= num.val X T1.width }
T->^T1 {T.type:=pointer(T1.type); T.width : = 4 }
7、利用8.11的翻译方案,将下面的赋值语句翻译成三地址代码:
A[i,j] = B[i,j] + C[A[k,l]]+D[i+j]
答:
令:
域宽为w
A的维数为:da1,da2, 不变部分为na, B的维数为db1,db2, 不变部分nb
C的维数为dc,不变部分nc
D的维数为dd,不变部分nd,
t1 := i*db1
t1:= t1+j
t2:= B-nb
t3:=w*t1
t4:=t2[t3]
xb = t4;
t1 := k*da1
t1:= t1+l
t2:= A-na
t3:=w*t1
t4:=t2[t3]
xa = t4;
t1:=xa;
t2:=C-nc;
t3:=w*t1
t4:=t2[t3]
xca:=t4
t1:=i+j;
t2:=D-nd;
t3:=w*t1;
t4:=t2[t3];
xd=t4;
t5:=xb+xca;
t6:=t5+xd;
t1 := i*da1
t1:= t1+j
t2:= A-na
t3:=w*t1
t2[t3]:=t6。