多元统计分析习题3.6
应用多元统计分析答案详解汇总_高惠璇[1]
![应用多元统计分析答案详解汇总_高惠璇[1]](https://uimg.taocdn.com/5f0eb38784868762caaed582.webp)
e
1 2 ( x2 2 x1 x2 14 x2 ) 2
dx2
1 e 2
1 2 ( 2 x1 22 x1 65 ) 2
e
1 2 ( x2 2 x2 ( x1 7 ) ( x1 7 ) 2 ) 2
比较上下式相应的系数,可得:
1 2 1 12 2 2 2 12 1 1 2 1 2 2 2 22 1 2 1 2 2 2 2 2 1 2 1 2 1 14 2 2 2 2 2 1 2 1 2 1 2 1 2
x1 y2 (2)第二次配方.由于 x2 y1 y2
14
第二章
2 1 2 2 2 1 2 1 2 2
多元正态分布及参数的估计
2 x x 2 x1 x2 22 x1 14 x2 65 y y 22 y2 14( y1 y2 ) 65 y 14 y1 49 y 8 y2 16 ( y1 7) ( y2 4)
由定理2.3.1可知X1 +X2 和X1 - X2相互独立.
4
第二章
(2) 因
多元正态分布及参数的估计
1 2 2 2(1 ) 0 X1 X 2 ~ N2 , Y 2(1 ) 0 X1 X 2 1 2
O 2(1 2 ) O 2(1 2 )
由定理2.3.1可知X(1) +X(2)和X(1) -X(2) 相 互独立.
7
第二章
(2) 因
(1) (2)
《多元统计分析》第三版例题习题数据文件..
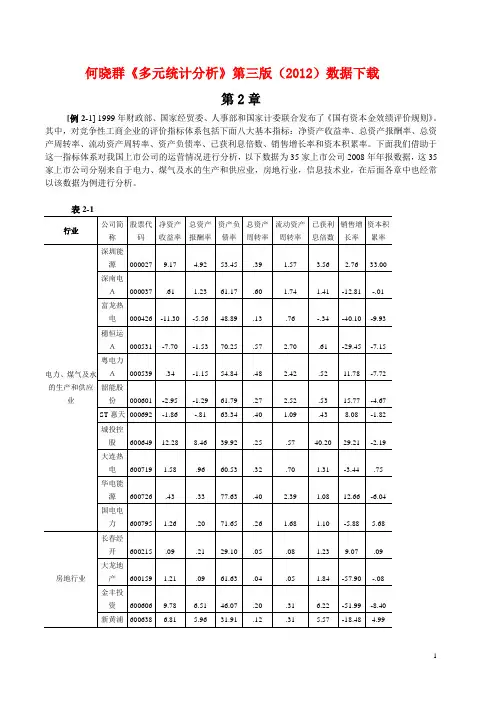
何晓群《多元统计分析》第三版(2012)数据下载第2章[例2-1] 1999年财政部、国家经贸委、人事部和国家计委联合发布了《国有资本金效绩评价规则》。
其中,对竞争性工商企业的评价指标体系包括下面八大基本指标:净资产收益率、总资产报酬率、总资产周转率、流动资产周转率、资产负债率、已获利息倍数、销售增长率和资本积累率。
下面我们借助于这一指标体系对我国上市公司的运营情况进行分析,以下数据为35家上市公司2008年年报数据,这35家上市公司分别来自于电力、煤气及水的生产和供应业,房地行业,信息技术业,在后面各章中也经常以该数据为例进行分析。
习题3.今选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省份。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口的比例等五项能够较好的说明各地区社会经济发展水平的指标。
验证一下边远及少数民族聚居区的社会经济水平与全国平均水平有无显著差异。
数据来源:《中国统计年鉴》(1998)。
5项指标的全国平均水平μ0=(6212.01 32.87 2972 9.5 15.78)/第3章例3-1 若我们需要将下列11户城镇居民按户主个人的收入进行分类,对每户作了如下的统计,结果列于表3-1。
在表中,“标准工资收入”、“职工奖金”、“职工津贴”、“性别”、“就业身份”等称为指标,每户称为样品。
若对户主进行分类,还可以采用其他指标,如“子女个数”、“政治面貌”等,指标如何选择取决于聚类的目的。
表3-1 某市2001年城镇居民户主个人收入数据X1 职工标准工资收入 X5 单位得到的其他收入X2 职工奖金收入 X6 其他收入X3 职工津贴收入 X7 性别X4 其他工资性收入 X8 就业身份X1 X2 X3 X4 X5 X6 X7 X8540.00 0.0 0.0 0.0 0.0 6.00 男国有1137.00 125.00 96.00 0.0 109.00 812.00 女集体1236.00 300.00 270.00 0.0 102.00 318.00 女国有1008.00 0.0 96.00 0.0 86.0 246.00 男集体1723.00 419.00 400.00 0.0 122.00 312.00 男国有1080.00 569.00 147.00 156.00 210.00 318.00 男集体1326.00 0.0 300.00 0.0 148.00 312.00 女国有1110.00 110.00 96.00 0.0 80.00 193.00 女集体1012.00 88.00 298.00 0.0 79.00 278.00 女国有1209.00 102.00 179.00 67.00 198.00 514.00 男集体1101.00 215.00 201.00 39.00 146.00 477.00 男集体例3-3English Norwegian Danish Dutch German FrenchOne En en een ein unTwo To to twee zwei deuxThree Tre tre drie drei troisFour Fire fire vier vier quatreFive Fem fem vijf funf einqSix Seks seks zes sechs sixseven Sju syv zeven siebcn septEight Ate otte acht acht huitNine Ni ni negen neun neufTen Ti ti tien zehn dixSpanish Italian Polish Hungarian FinnishUno uno jeden egy yksiDos due dwa ketto kaksiTres tre trzy harom kolmecuatro quattro cztery negy neuaCinco cinque piec ot viisiSeix sei szesc hat kuusiSiete sette siedem het seitsemanOcho otto osiem nyolc kahdeksaunueve nove dziewiec kilenc yhdeksanDiez dieci dziesiec tiz kymmenen例3-4X1 食品支出(元/人)X5 交通和通讯支出(元/人)X2 衣着支出(元/人)X6 娱乐、教育和文化服务支出(元/人)X3 家庭设备、用品及服务支出(元/人)X7 居住支出(元/人)X4 医疗保健支出(元/人)X8 杂项商品和服务支出(元/人)X1 X2 X3 X4 X5 X6 X7 X8 辽宁1772.14 568.25 298.66 352.20 307.21 490.83 364.28 202.50 浙江2752.25 569.95 662.31 541.06 623.05 917.23 599.98 354.39 河南1386.76 460.99 312.97 280.78 246.24 407.26 547.19 188.52 甘肃1552.77 517.16 402.03 272.44 265.29 563.10 302.27 251.41 青海1711.03 458.57 334.91 307.24 297.72 495.34 274.48 306.45例3-5x1 人均粮食支出(元/人) x5 人均衣着支出(元/人)x2 人均副食支出(元/人)x6 人均日用杂品支出(元/人)x3 人均烟、酒、饮料支出(元/人)x7 人均水电燃料支出(元/人)x4 人均其他副食支出(元/人)x8 人均其他非商品支出(元/人)第4章[例4-1] 判别分析的一个重要应用是用于动植物的分类当中,最著名的一个例子是1936年Fisher的鸢尾花数据(Iris Data)。
多元统计分析期末试题及标准答案

多元统计分析期末试题及答案————————————————————————————————作者:————————————————————————————————日期:22121212121~(,),(,),(,),,1X N X x x x x x x ρμμμμσρ⎛⎫∑==∑=⎪⎝⎭+-1、设其中则Cov(,)=____.10312~(,),1,,10,()()_________i i i i X N i W X X μμμ='∑=--∑L 、设则=服从。
()1234433,492,3216___________________X x x x R -⎛⎫ ⎪'==-- ⎪⎪-⎝⎭=∑、设随机向量且协方差矩阵则它的相关矩阵4、__________, __________,________________。
215,1,,16(,),(,)15[4()][4()]~___________i p p X i N X A N T X A X μμμμ-=∑∑'=--L 、设是来自多元正态总体和分别为正态总体的样本均值和样本离差矩阵,则。
12332313116421(,,)~(,),(1,0,2),441,2142X x x x N x x x x x μμ-⎛⎫⎪'=∑=-∑=-- ⎪ ⎪-⎝⎭-⎛⎫+ ⎪⎝⎭、设其中试判断与是否独立?(),123设X=xx x 的相关系数矩阵通过因子分析分解为211X h =的共性方差111X σ=的方差21X g =1公因子f 对的贡献121330.93400.1280.9340.4170.8351100.4170.8940.02700.8940.44730.8350.4470.1032013R ⎛⎫- ⎪⎛⎫⎛⎫⎪-⎛⎫ ⎪ ⎪⎪=-=-+ ⎪ ⎪ ⎪ ⎪⎝⎭ ⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪ ⎪⎝⎭11262(90,58,16),82.0 4.310714.62108.946460.2,(5)( 115.6924)14.6210 3.17237.14.5X S μ--'=-⎛⎫ ⎪==-- ⎪ ⎪⎝⎭0、对某地区农村的名周岁男婴的身高、胸围、上半臂围进行测量,得相关数据如下,根据以往资料,该地区城市2周岁男婴的这三个指标的均值现欲在多元正态性的假定下检验该地区农村男婴是否与城市男婴有相同的均值。
多元统计分析习题操作及分析

例2.1> data2.1<-read.table("clipboard",header=T)> lm.salary<-lm(y~x1+x2+x3+x4,data=data2.1)> summary(lm.salary)Call:lm(formula = y ~ x1 + x2 + x3 + x4, data = data2.1)Residuals:Min 1Q Median 3Q Max-12924.2 -4588.1 -269.6 1756.2 25215.7Coefficients:Estimate Std. Error t value Pr(>|t|) (Intercept) 48386.0620 11237.2882 4.306 0.000155 ***x1 1.6831 0.1302 12.929 5.01e-14 ***x2 -34.5520 130.2602 -0.265 0.792570x3 -13.0004 13.7882 -0.943 0.353043x4 808.3223 547.8017 1.476 0.150144---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 7858 on 31 degrees of freedom Multiple R-squared: 0.919, Adjusted R-squared: 0.9086 F-statistic: 87.95 on 4 and 31 DF, p-value: < 2.2e-16从以上输出结果可以看出,回归方程的F值为87.95,相应的P值为,说明回归方程是显著的,但t检验对应的p值则显示常数项和x1是显著的,而x2,x3,x4不显著。
多元统计分析练习题

多元统计分析练习题一、主成分练习题填空题1.主成分分析是通过适当的变量替换,使新变量成为原变量的___________,并寻求_________的一种方法。
2.主成分分析的基本思想是______________。
3.主成分的协方差矩阵为_________矩阵。
4.主成分表达式的系数向量是_______________的特征向量。
5.原始变量协方差矩阵的特征根的统计含义是________________。
6.原始数据经过标准化处理,转化为均值为____,方差为____的标准值,且其________矩阵与相关系数矩阵相等。
7.因子载荷量的统计含义是_____________________________。
8.样本主成分的总方差等于_____________。
9.变量按相关程度为,在__________程度下,主成分分析的效果较好。
10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________________。
11.SPSS 中主成分分析采用______________命令过程。
计算题1.设三个变量(x1,x2,x3)的样本协方差矩阵为:2121002222222<<−⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡r s rs r s s r s r s s 试求主成分及每个主成分的方差贡献率。
2.在一项研究中,测量了376只鸡的骨骼,并利用相关系数矩阵进行主成分分析,见下表: Y1 Y2 Y3 Y4 Y5 Y6 头长x1 头宽x2 肱骨x3 尺骨x4 股骨x5 胫骨x6 0.35 0.33 0.44 0.44 0.43 0.44 0.53 0.70 0.19 0.25 0.28 0.22 0.76 -0.64 -0.05 -0.02 -0.06 -0.05 -0.05 0.00 0.53 0.48 0.51 0.48 -0.04 0.00 0.19 0.15 0.67 0.70 0.00 0.04 0.59 0.63 0.48 0.15 特征值4.570.710.410.170.080.06解释6个主成分的实际意义。
实用多元统计分析相关习题学习资料

实用多元统计分析相关习题练习题一、填空题1.人们通过各种实践,发现变量之间的相互关系可以分成(相关)和(不相关)两种类型。
多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。
2.总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。
3.回归方程显著性检验时通常采用的统计量是(S R/p)/[S E/(n-p-1)]。
4.偏相关系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的)的相关系数。
5.Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。
6.主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求(降维)的一种方法。
7.主成分分析的基本思想是(设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来替代原来的指标)。
8.主成分表达式的系数向量是(相关系数矩阵)的特征向量。
9.样本主成分的总方差等于(1)。
10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。
主成分的协方差矩阵为(对称)矩阵。
主成分表达式的系数向量是(相关矩阵特征值)的特征向量。
11.SPSS中主成分分析采用(analyze—data reduction—facyor)命令过程。
12.因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部分为(特殊因子)。
13.变量共同度是指因子载荷矩阵中(第i行元素的平方和)。
14.公共因子方差与特殊因子方差之和为(1)。
15.聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏程度)进行科学的分类。
16.Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。
17.Q型聚类统计量是(距离),而R型聚类统计量通常采用(相关系数)。
多元统计分析习题3.6
习题3.61992年美国总统选举的三位候选人为布什、佩罗特、克林顿。
从支持三位候选人的选民中分别假定三组都服从富哦元正态分布,检验这三组的总体均值是否有显著性差异(a=0.05).解:分析:该题自变量为三位候选人,因变量为年龄段和受教育程度。
从自变量来看要进行方差分析,从因变量来看是二元分析,所以最终确定使用多变量分析.具体操作:1.打开spss,录入数据,如图,被投票人:1、布什 2、佩罗特 3、克林顿2.在spss窗口中选择分析——一般线性模型——多变量,调出多变量分析主界面,将年龄段和受教育程度移入因变量框中,被投票人移入固定因子框中.3.结果解释:协方差矩阵等同性的 Box检验aBox 的 M 7.574F 1.198df1 6df2 80975.077Sig. .304检验零假设,即观测到的因变量的协方差矩阵在所有组中均相等。
a. 设计 : 截距 + 被投票人结果说明:此Box检验的协方差矩阵为三位候选人每个人的支持者的年龄段和受教育程度的协方差矩阵。
因为sig>0.05,所以差异不显著,即各个因变量的协方差矩阵在所有三个候选人组中是相等的。
可以对其进行多元方差分析。
多变量检验a效应值 F 假设 df 误差 df Sig.截距Pillai 的跟踪.922 330.834b 2.000 56.000 .000 Wilks 的 Lambda .078 330.834b 2.000 56.000 .000 Hotelling 的跟踪11.815 330.834b 2.000 56.000 .000 Roy 的最大根11.815 330.834b 2.000 56.000 .000被投票人Pillai 的跟踪.226 3.637 4.000 114.000 .008 Wilks 的 Lambda .779 3.725b 4.000 112.000 .007 Hotelling 的跟踪.277 3.807 4.000 110.000 .006 Roy 的最大根.249 7.109c 2.000 57.000 .002a. 设计 : 截距 + 被投票人b. 精确统计量c. 该统计量是 F 的上限,它产生了一个关于显著性级别的下限。
(完整版)多元统计分析课后练习答案
第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
多元统计分析习题与答案
多元统计分析习题与答案多元统计分析是一种在社会科学研究中广泛应用的方法,它通过同时考虑多个变量之间的关系,帮助研究者更全面地理解和解释现象。
在本文中,我将分享一些多元统计分析的习题和答案,希望能够帮助读者更好地掌握这一方法。
习题一:相关分析假设你正在研究一个学生的学习成绩和他们每天花在学习上的时间之间的关系。
你收集了100个学生的数据,学习成绩用分数表示,学习时间用小时表示。
以下是你的数据:学习成绩(X):75, 80, 85, 90, 95, 70, 65, 60, 55, 50学习时间(Y):5, 6, 7, 8, 9, 4, 3, 2, 1, 0请计算学习成绩和学习时间之间的相关系数,并解释其含义。
答案一:首先,我们需要计算学习成绩和学习时间之间的协方差和标准差。
根据公式,协方差可以通过以下公式计算:协方差= Σ((X - X平均) * (Y - Y平均)) / (n - 1)其中,X和Y分别表示学习成绩和学习时间,X平均和Y平均表示它们的平均值,n表示样本数量。
标准差可以通过以下公式计算:标准差= √(Σ(X - X平均)² / (n - 1))根据以上公式,我们可以得出学习成绩和学习时间之间的协方差为-22.5,标准差分别为18.03和2.87。
然后,我们可以通过以下公式计算相关系数:相关系数 = 协方差 / (X标准差 * Y标准差)根据以上公式,我们可以得出相关系数为-0.93。
由于相关系数接近于-1,可以得出结论:学习成绩和学习时间之间存在强烈的负相关关系,即学习时间越长,学习成绩越低。
习题二:多元线性回归假设你正在研究一个人的身高(X1)、体重(X2)和年龄(X3)对其收入(Y)的影响。
你收集了50个人的数据,以下是你的数据:身高(X1):160, 165, 170, 175, 180, 185, 190, 195, 200, 205体重(X2):50, 55, 60, 65, 70, 75, 80, 85, 90, 95年龄(X3):20, 25, 30, 35, 40, 45, 50, 55, 60, 65收入(Y):5000, 5500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500请利用多元线性回归分析,建立一个预测人的收入的模型,并解释模型的结果。
2019年秋季多元统计分析考试答案共10页word资料
《多元统计分析》课程试卷答案A 卷2009年秋季学期开课学院:理考试方式:√闭卷、开卷、一纸开卷、其它 考试时间:120 分钟班级 姓名 学号散卷作废。
一、(15分)设()∑⎪⎪⎪⎭⎫ ⎝⎛=,~3321μN x x x X ,其中⎪⎪⎪⎭⎫ ⎝⎛-=132μ,⎪⎪⎪⎭⎫ ⎝⎛=∑221231111,1.求32123x x x +-的分布;2. 求二维向量⎪⎪⎭⎫ ⎝⎛=21a a a ,使3x 与⎪⎪⎭⎫⎝⎛'-213x x a x 相互独立。
解:1.32123x x x +-()CX x x x ∆⎪⎪⎪⎭⎫⎝⎛-=321123,则()C C C N CX '∑,~μ。
(2分)其中:μC ()13132123=⎪⎪⎪⎭⎫ ⎝⎛--=,()9123221231111123=⎪⎪⎪⎭⎫ ⎝⎛-⎪⎪⎪⎭⎫ ⎝⎛-='∑C C 。
(4分)所以32123x x x +-()9,13~N (1分)2. ⎪⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛'-2133x x a x x =AX x x x a a ∆⎪⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛--321211100,则()A A A N AX '∑,~2μ。
(1分)其中:订线装μA ⎪⎪⎭⎫ ⎝⎛++-=⎪⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛--=132113211002121a a a a,(1分) ⎪⎪⎭⎫ ⎝⎛+--+++--+--='⎪⎪⎭⎫ ⎝⎛--⎪⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛--='∑2422322222110022123111111002121222121212121a a a a a a a a a a a a a a A A (2分)要使3x 与⎪⎪⎭⎫⎝⎛'-213x x a x 相互独立,必须02221=+--a a ,即2221=+a a 。
因为2221=+a a 时2422321212221+--++a a a a a a 0>。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题3.6
1992年美国总统选举的三位候选人为布什、佩罗特、克林顿。
从支持三位候选人的选民中分别
假定三组都服从富哦元正态分布,检验这三组的总体均值是否有显著性差异(a=0.05).
解:分析:该题自变量为三位候选人,因变量为年龄段和受教育程度。
从自变量来看要进行方差分析,从因变量来看是二元分析,所以最终确定使用多变量分析.
具体操作:
1.打开spss,录入数据,如图,
被投票人:1、布什 2、佩罗特 3、克林顿
2.在spss窗口中选择分析——一般线性模型——多变量,调出多变量分析主界
面,将年龄段和受教育程度移入因变量框中,被投票人移入固定因子框中.
3.结果解释:
协方差矩阵等同性的 Box
检验a
Box 的 M 7.574
F 1.198
df1 6
df2 80975.077
Sig. .304
检验零假设,即观测到的因
变量的协方差矩阵在所有
组中均相等。
a. 设计 : 截距 + 被投票
人
结果说明:此Box检验的协方差矩阵为三位候选人每个人的支持者的年龄段和受教育程度的协方差矩阵。
因为sig>0.05,所以差异不显著,即各个因变量的协方差矩阵在所有三个候选人组中是相等的。
可以对其进行多元方差分析。
多变量检验a
效应值 F 假设 df 误差 df Sig.
截距Pillai 的跟踪.922 330.834b 2.000 56.000 .000 Wilks 的 Lambda .078 330.834b 2.000 56.000 .000 Hotelling 的跟踪11.815 330.834b 2.000 56.000 .000 Roy 的最大根11.815 330.834b 2.000 56.000 .000
被投票人Pillai 的跟踪.226 3.637 4.000 114.000 .008 Wilks 的 Lambda .779 3.725b 4.000 112.000 .007 Hotelling 的跟踪.277 3.807 4.000 110.000 .006 Roy 的最大根.249 7.109c 2.000 57.000 .002
a. 设计 : 截距 + 被投票人
b. 精确统计量
c. 该统计量是 F 的上限,它产生了一个关于显著性级别的下限。
结果说明:被投票人在四种统计方法中的sig均小于0.05,所以差异显著,即三组的总体均值有显著性差异
误差方差等同性的Levene检验结果:
结果说明:只考虑单个变量,年龄段或者受教育程度,每位候选人的20名支持者的随机误差是否有显著性差异。
因为sig>0.05,差异不显著,所以三位候选人的20名支持者的随机误差相等。
可以进行单因素方差分析。
主体间效应的检验:
主体间效应的检验
源因变量III 型平方
和
df 均方 F Sig.
校正模型
年龄段X1 13.300a 2 6.650 7.078 .002
受教育程度X2 3.033b 2 1.517 1.442 .245
截距年龄段X1 360.150 1 360.150 383.353 .000 受教育程度X2 138.017 1 138.017 131.225 .000
被投票人年龄段X1 13.300 2 6.650 7.078 .002 受教育程度X2 3.033 2 1.517 1.442 .245
误差年龄段X1 53.550 57 .939 受教育程度X2 59.950 57 1.052
总计年龄段X1 427.000 60 受教育程度X2 201.000 60
校正的总计
年龄段X1 66.850 59
受教育程度X2 62.983 59
a. R 方 = .199(调整 R 方 = .171)
b. R 方 = .048(调整 R 方 = .015)
结果说明:被投票人一行中,年龄段的sig<0.05,差异显著,即支持三位候选人的选民中,年龄段之间存在显著差异;而受教育程度的sig>0.05,差异不显著,即支持三位候选人的选民中,受教育程度差异不显著。